基于欧氏距离解缠的多角度跨库人脸表情识别
2021-11-23梁广
梁 广
(中国科学技术大学 网络空间安全学院,安徽 合肥230026)
0 引言
如今,人脸表情识别相关研究的热度逐渐上升。相应的技术也应用于教育质量评估、刑事审讯等多个领域。然而,当前的很多研究主要关注于相同数据库上的人脸表情识别,即训练样本和测试样本都来自于同一个数据库。由于不同表情数据库在人种、背景和光照等存在差异,表情识别的效果受到很大的影响[1]。同时,人脸图片也包含多个不同姿势,不同姿势之间的差异也导致了表情识别准确率的下降。研究者当前也在研究降低数据库和姿势所带来影响的方法。
由于姿势的差异对表情识别有明显的影响,研究人员提出了三大类方法来消除表情识别中的姿态差异: 姿势规范化方法[2];单分类器方法[3-4];姿势鲁棒的特征方法[5-8]。由于正脸的表情识别准确率高于侧脸,研究者使用姿势规范化的方法将侧脸图像转换成正脸图像来进行识别表情。然而,用来测试的目标数据库通常缺失同一个人的正- 侧脸数据对。这也导致了侧脸图像在通过生成式对抗网络[9](Generative Adversarial Networks,GAN) 生成正脸的过程中存在失真,影响表情识别效果。对于单分类器方法,研究者使用单个分类器来识别多种姿势下的表情。这种方法需要大量不同姿势的图像来训练单一分类器,而现实中很难得到足够多的多角度图像。而姿势鲁棒的特征方法尝试训练一个编码器来生成对姿势差异鲁棒的表情特征。这种方法在特征层面降低了表情特征中的姿势噪声,同时不需要大量的目标数据库样本,也无需生成伪样本。因此本模型选择了姿势鲁棒的特征方法来降低姿势差异。
另外,数据库的差异同样影响了表情识别。为保持相关工作的表述一致性,本文也将原数据库和目标数据库分别称作原域和目标域。研究人员主要使用两种方法来降低数据库的偏差: 基于核方法的迁移学习[10-11];对抗领域自适应的方法[12-14]。最常用的核方法是最大平均差异(Maximum Mean Discrepancy,MMD)。研究人员使用MMD 来逼近不同领域的不同域特征的距离,从而实现领域自适应。然而这种方法的计算时间成本较高。对抗领域自适应方法使用原域的知识来提升目标域的学习。因为表情特征学习过程中具有更好的灵活性,所以该模型选择了领域对抗自适应方法来消除域偏差。
上述的方法要么关注了数据库的偏差,要么关注了姿势的差异,但还没有方法同时兼顾这两个因素。因此本文提出了基于欧式距离的特征解缠自适应(Euclidean Distance Disentanglement Adaption,EDDA)方法来同时解决这两个问题。图1 展示了本文方法的主要创新点。该框架包含三个分支: 表情分支,姿势分支和数据库分支。图中的球体代表了一个高维的单位球,即一个半径唯一的高维球。而图1 中的右上方的小圆代表了针对表情特征的对比学习策略。该方法将三个属性的特征映射到单位球体的表面,通过对三个点的距离最大化来解缠三个特征。当解缠不同属性特征的时候,会压缩相同属性特征的空间。为了解决这个问题,引入了对比学习损失。该损失拉近了同一个批次中相同表情特征的距离,同时疏离了不同表情特征的距离。另外,为了利用原数据库的知识来辅助目标数据库的训练,引入了对抗领域自适应。
总之,为了解决跨库和多姿势的表情识别,本文实现了如下三个策略: 一是本文提出了一个基于欧式距离的解缠方法来移除别的属性在表情特征中的噪声;二是为了解决不同表情的特征聚集的问题,本模型引入了对比学习损失;三是本模型引入了对抗领域自适应方法来逼近原数据库和目标数据库的表情特征分布。最后,通过在公开的数据库上进行多组实验,充分证明了该模型的有效性。
1 相关工作
1.1 姿势鲁棒的表情识别
姿势鲁棒的表情识别方法可以分为三大类: 姿势规范化方法、单分类器方法、姿势鲁棒的表情特征方法。
姿势规范化的方法会将侧脸的照片转换到正脸,再进行表情识别。Lai 等人[2]构造了一个多任务的基于GAN 的框架。该方法使用GAN 来将一张表情图片从侧脸转换到正脸,同时保留个体和表情一致,然后利用生成的正脸图像来训练表情分类器。而对于大角度的侧脸图像,生成图像的伪影效果影响很大。
单分类器方法通过大量的不同姿势的人脸表情来训练一个通用的分类器。Zhang 等人[4]构建了一个联合姿势和表情的模型来识别人脸。通过使用GAN 来生成多种姿势和表情的图片,然后利用这些图像训练一个单一的分类器。这类方法依赖于大量生成的图像,而因为高分辨率的图像很难生成,所以该类方法也受到图像模糊的影响。本文的方法避开了生成图像的问题。
谈及姿势鲁棒的特征方法。Zhang 等人[15]提出了一个传统手工特征-- 尺度不变特征转换(Scale Invariant Feature Transform,SIFT) 的算法。他们从每张图片中提取出SIFT 特征,并输入到深度神经网络中来拟合神经识别的机制。该方法使用映射层来学习不同面部标定点的可识别特征,并和表情特征整合在一起辅助识别表情。上述的方法要求先预测姿势,再进行表情识别。如果姿势预测出错了,表情识别的效果就会被严重地影响。而本文的方法不需要提前检测角度。
1.2 跨库鲁棒的表情识别
对跨库鲁棒的表情识别方法可以主要分为三大类: 迁移学习的核方法、图卷积方法、对抗领域自适应的方法。
核方法将原域和目标域样本映射到高维的希尔伯特空间,并且通过使相同表情特征的距离逼近来消除域偏差。其中,Li 等人[10]创造了一个深度表情迁移网络来解决原域和目标域的偏差。该方法在深度学习中引入了最大均值差异来降低数据库差异,并且提出了一个基于类的灵活加权参数机制来近似两个域的分布。然而,这个方法中的权重参数调节依赖于目标域的伪标签,错误的伪标签会降低表情识别的准确率。本文的方法不存在这种问题。
图卷积方法建立了人脸图像局部特征之间的关系图来减少域的偏差。Xie 等人[17]提出了一个对抗图卷积自适应的框架。首先,该方法利用每个域的样本建立了一个抓捕图像整体和局部相关性的图。该方法学习了每个域的每个类的分布,同时提取了整体- 局部的特征来初始化图的节点。最后通过引入图卷积网络,来传播信息给每个域内的整体局部的特征,从而探索它们之间的相互关系以及不同域间的协同适应。然而,目前的图卷积方法的可扩展性差,在工程实践中存在局限性。
对于对抗领域自适应的方法。该类方法通过缩小原域和目标域之间的特征差异来减小域偏差。Tzeng[12]提出了一个对抗可区分的领域自适应方法。该方法通过生成器和判别器的对抗来实现领域的自适应。利用GAN 的损失,它们得以逼近两个域的特征分布。总的来说,上述的这些方法主要关注域偏差,而忽略了位姿的变化。本文所提出的方法同时考虑了数据库和位姿的差异,实现了更好的识别效果。
2 问题描述


另外,为了解缠不同属性的特征,使得表情特征对姿势和跨数据库足够鲁棒,提出了式(3 ) 所对应的策略。其中,fe表示表情相关的特征;fp表示表情相关的特征;而fd表示域相关的特征。通过梳理这三种属性的特征的分布来使之解缠。

3 方法
整体框架如图2 所示。该框架共包含6个组件: 原域编码器Es、目标域编码器Et、表情分类器Ce、姿势分类器Cp、域分类器Cd和表情判别器De。除了上述组件,图2 还包含图1 中所展示的两个损失lArea和lContrastive。lArea损失用来解缠不同属性的特征;lContrastive损失,即对比学习损失。我们通过编码器获得三个属性特征。表情、姿势和域的分类器Ce、Cp和Cd则对相应的特征进行分类。面积损失中,三个顶点为三个相应属性的特征。通过最大化lArea,三个属性的特征在欧式高维空间上得以疏离,从而实现解缠。由于目标域没有表情和姿势的标签,通过使用ResNet 网络来得到相应的伪标签。在对比学习的策略里,通过lContrastive损失来调整Es,使得不同表情的特征在解缠的过程中不压缩在一起。另外,为了将原域的知识迁移到目标域中,通过表情判别器De来判断特征来自于哪个域,从而进行特征对抗。

图2 基于空间解缠的多姿态跨数据库表情识别方法框架图
3.1 骨干网络
如图2 所示,构建了三个分支来识别表情姿势和域。在学习分类样本所属哪个域的过程中引入了部分目标域的图像。在这个过程中,关于表情和姿势标签,目标域的样本仅使用ResNet -50 预测的伪标签。

3.2 基于欧氏距离的特征解缠
为了解缠多种属性的特征,提出了基于欧氏距离的特征解缠方法。该方法将一个批次样本的三种属性的特征映射到单位球体的表面。球体上不同属性的特征分离,不同属性的特征在分布上解缠。

为了计算这三个属性端点构成的三角形区域的面积,使用海伦公式来计算高维向量之间三角形的面积。同时,这个解缠方法也为更多属性的空间解缠提供了一个初步的框架。这个面积的损失如式(7) 定义所示。在这里fe(i)、fp(i) 和fd(i) 代表对应特征的第i维特征分量,a、b和c分别代表两两特征间的欧氏距离。解缠的策略如式(8) 所示,最大化这个区域的面积。

3.3 表情特征的对比学习
如前所述,解缠的过程会压缩相同属性的特征。因此,对比学习被引入来解决不同表情的特征聚集的问题。对比学习的损失定义如式(9) 所示。在这个表达式里,x代表输入的当前要计算的特征,x+代表与x相同表情的特征,x-代表与x不同表情的特征。引用了Prannay[18]工作中的对比学习策略的设置。在这个式子中,f(x)Tf(x+) 是通过x和x+的点乘来实现的。

从上式可以看出,分子越大,分母越小时,相同标签的表情特征会越接近,而不同标签的表情特征会越远离。如式(10) 所示,我们通过最大化该损失来疏离不同标签的表情特征。

3.4 特征对抗学习
在原域的样本经过训练之后,得到了一个好的表情编码器和分类器。于是可以通过对抗学习将原域的知识迁移到目标域。其中,De表示一个表情的判别器。Ee和De进行了一个最大最小的对抗游戏。De尽力来分辨表情特征来自原域还是目标域。Ee尽力提取出可以迷惑De的特征。通过两个组件的多轮对抗学习,得以实现领域知识的迁移。
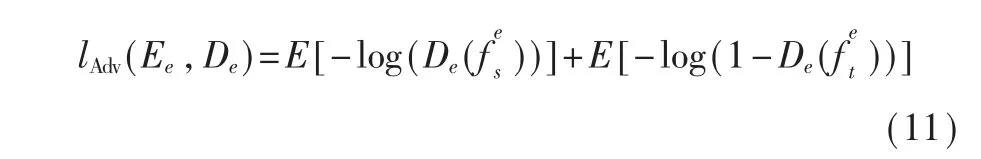
3.5 综合的学习
式(12) 整合了前述的所有的损失。式中每项损失前的拉丁字母α 、β 、γ 、δ 和ε 分别表示该损失相应的超参数。而min 和max 下面的各个组件表示在对loss 损失的最小化或最大化操作时所要反向传播更新的参数。

4 实验
本方法在8个公开的数据库上进行了实验。这8个数据库分别是: RAF - BD[19]、CK +[20]、JAFFE[21]、SFEW[22]、FER2013[23](Facial Expression Recognition 2013 Dataset,FER2013)、ExpW[24]、多Multi-PIE[25]和BU-3DFE[26]。
4.1 实验条件
RAF-DB 和FER-2013 的图片都由互联网收集而来,因此图片具有很多种风格。RAF-DB 数据库包含29672 张脸部图片。FER-2013 包含35887 张图片。两个数据库都标注了7个基础的表情。由于RAF-DB 包含大量的样本,同时为了方便与之前的工作作比较,将RAF-DB 作为主要的原数据库。
CK + 数据库中的样本是用来做人脸表情分析的,所以该数据库中的人脸图像是在实验室控制的环境下采集的。参照之前Li[27]的工作的设置,选择了每个序列的第一帧(自然帧) 和巅峰的三帧。
JAFFE 数据库包含213 张表情照片。这些照片采集自10 位日本的女性学生。该数据库包含7个基础的表情,其数据是在实验控制状态下采集的。由于这个数据库的样本都是亚洲女性,该数据库的民族偏差和性别偏差很明显。
SFEW 数据库包含1766 张图片。该数据库中的人脸表情图像采集自37 部不同的电影,所以该数据库同样是一个自然环境下的数据库,不是实验控制状态下的数据库,风格多样。另外,该数据库同样由7个基础的表情标注。
Multi - PIE 数据库包含755370 张图片,由6个基础的表情标注。该数据库在实验室环境采集,同时拥有角度标签。BU -3DFE 数据库包含100个人的2500 张表情图片模型。同样含有6个基本表情,并在实验控制环境下采集。选择了1200 张来自于Multi-PIE 的图片和7655 张来自BU -3DFE 的包含5个角度(±30°,0°和90°)的图片来训练ResNet 网络。
实验设置主要参考Xie 的工作[17]和Han[28]的工作。设置了RAF-DB 作为原数据库,多个数据库作为目标数据库来进行跨库的实验。另外,为了加强验证,参照Sun[29]的实验设置将CK+ 作为原数据库进行了实验。除了对比工作之外,还做了消融实验。在消融实验中,将RAF - DB 设置为原数据库,CK +设置为目标数据库。
4.2 实现细节
为了规范所有的样本来适配到输入层,使用了OpenCV 来检测脸部,裁剪图片并重整图片为128×128 像素的图片。编码器包涵有一个输入层,四个下采样层和四个残差层。每一个卷积层后面都跟随一个实例归一化层和一个线性整流函数。通过三个编码器分支,分别得到了表情、姿势和域相关的特征。每个特征在编码后重整为一个512 维的向量。特征解缠在这个向量上进行。在训练各属性特征解过程中,部分目标域数据库的样本被引入来辅助训练。此时,目标域的样本使用ResNet-50 模型预测的伪标签。而为了不受伪标签的影响,在训练对比学习损失的时候,只使用了原数据库中的样本来进行训练模型。实验采用交叉熵函数作为损失函数。
4.3 实验对比
所提出的方法与以下的工作进行了对比:Altinier[30]的工作,Hasani[31]的工作,Zavarez[32]的工作,Mollahosseini[33]的工作,深度表情迁移网络[10](Deep Emotion Transfer Network,DETN ),条件表情自适应网络[27](Emotion - Conditional Adaption Network,ECAN ),条件对抗领域自适应[34](Conditional Adversarial Domain Adaption,CADA) 等方法。
这些工作主要将RAF-DB 设置为原数据库。表1的上半部分的对比工作的准确率是从相应的文章中收集到的,而下半部分的准确率是引用自Xie[17]的工作。另外,如表2 所示,也对比了一些以CK + 为原域的工作。

表1 以RAF-DB 为原数据库的实验对比表 (%)

表2 以CK+为原库的实验对比表(%)
通过实验的对比结果,证明了所提方法的有效性。如在表1 最后一行所示,所提出的方法以RAF -DB 为原数据库,各目标数据库CK +、JAFFE 、SFEW 、FER -2013 和ExpW 的准确率比最好的工作高出1.86%、1.04%、1.36%、0.21% 和0.62%。所提方法的准确率均值为67.15%,比当前准确率均值最高的AGRA 的方法高出1.02%。在以CK+ 为原数据库的实验中,本文方法的准确率也有很大的提升。
4.4 消融实验
为了进一步验证所提出的策略有效性,同时展开了消融实验。消融实验的结果如表3 所示,最左侧一列表示本文中不同策略组合的模型。其中EDDACe表示仅有表情分类骨干网络的模型。EDDAAdv表示仅仅给骨干分类网络添加了对抗领域学习策略的模型。EDDAED表示仅仅给骨干分类网络增加了欧氏距离解缠策略的模型。EDDAAdv+ED表示给骨干网络添加了上述两个策略的模型。而EDDA 指本文提出的方法,也即包含下述完整的三个策略的网络:欧氏距离解缠、对比学习、领域对抗自适应。表3中最右边一列表示每个数据库的准确率的均值。通过准确率比较,可以看出三个策略的有效性。

表3 消融实验 (%)
5 结论
整体来讲,本文提出了一个基于欧式距离面积最大化的特征解缠模型,从而使多姿态跨库表情识别效果得到了有效的提升。该模型包含三个策略:基于欧式距离的特征解缠,对比学习和对抗领域自适应。在这个模型中,通过减少姿势和数据库的差异来提纯表情特征,使其更具鲁棒性。通过与当前最好的工作对比,验证了所提出方法的有效性。当进一步细分人脸属性的时候,仍可以利用本文的框架在更高维度上解缠特征,从而提高识别的效果。
