多兵种交战中作战指数迭代计算方法及收敛性研究
2021-11-18巫银花
张 昊,巫银花,吴 涛,文 韬,朱 智
(1.海军指挥学院作战实验室,南京 210016;2.海军指挥学院训练管理系,南京 210016)
0 引言
在多兵种交战问题中,作战指数评估的目标是科学衡量各兵种在作战过程中的作用,它是指挥员制定军事决策方案的重要依据。各兵种的火力分配策略是军事决策的重要内容,合理的火力分配策略能够增强兵种战斗力,从而提高兵种的作战指数。因此,作战指数是制定火力分配策略的前提,火力分配策略又对作战指数有重要影响,这反映了军事哲学中兵种的战斗力与战法的辩证关系。由于兵种的作战指数和火力分配策略之间相互依赖,必须从整体上对两者进行统一处理。在多兵种兰彻斯特方程条件下,本文借鉴强化学习理论,根据兵种作战指数和火力分配策略之间的相互递推关系,采用迭代计算方法进行统一处理,详细考察不同更新策略对迭代收敛速度和稳定性的影响。
1 问题来源
对于大规模多兵种交战问题,兵种作战指数评估是进行军事决策的重要依据。目前,研究人员提出了多种作战指数评估方法,包括模糊综合评价方法[1-2]、层次分析方法[3-4]、指数法[5-6]和概率影响图方法[7]等。这些方法需要结合专家的经验知识,采用定性定量相结合方法进行综合处理,其存在的主要缺点是研究结果依赖于相关专家的能力水平和主观判断,难以科学衡量结果的优劣。
沙基昌教授强调作战问题研究应基于严谨的数学理论,提出了基于多兵种交战兰彻斯特方程的规范交战模式理论,通过对作战指数和火力分配策略进行整体处理,给出了最优解的图论求解方法[8]。规范交战模式理论涉及高等数学理论,计算复杂度高,实践应用难度较大。
在多兵种交战中,兵种的作战指数和火力分配策略之间相互依赖,需要有机结合起来进行统一处理。兵种的作战指数是制定火力分配策略的重要依据,对于我方每一型兵种,其火力分配策略的目标是寻求对敌方打击的最大化,这需要综合考察该型兵种对敌方各兵种毁伤能力与作战指数的乘积,其中的最大项对应的敌方兵种即为我方的最优火力分配目标。火力分配策略又能影响其作战指数评估结果,火力分配策略确定了兵种的打击目标,直接影响该兵种的作战效果,从而事实上影响其作战指数。
兵种作战指数和火力分配策略之间的相互依赖关系[8],类似于强化学习理论中Q 值和动作策略的相互依赖关系[9]。在强化学习理论中,智能体采取某行为策略与环境进行交互并获得奖励,然后根据奖励值大小改进智能体行为策略,持续学习以寻求奖励值最大化。Q 学习方法[10]是强化学习理论的重要方法,对于智能体的每个状态si,初始化一个效用值qi,称作Q 值;智能体执行某动作的回报定义为该动作的直接奖励加上后序状态的效用值;智能体优先选择执行回报最大的动作,然后利用该回报值更新原状态的Q 值,循环执行直至所有状态的Q值收敛。Q 学习方法用Q 值描述了智能体在各个状态时获取回报的能力,智能体在各状态时最优动作策略为选择回报最大的动作。对于多兵种交战问题,兵种作战指数描述了其在作战过程中的作用,兵种的最优火力分配策略需要寻求其作战效果的最大化。通过类比研究可以发现,多兵种交战问题与强化学习理论在概念和原理上有相通之处,借鉴强化学习理论相关成果研究多兵种交战问题,能够启发研究思路。
2 问题分析与求解
对于大规模多兵种交战问题,兰彻斯特方程是描述其作战过程的基础数学模型:

为了击败对方,提升我方兵种的作战效果,需要对各兵种火力分配系数的取值进行优化,寻求对敌方打击的最大化。由于各方均有多型兵种,不同兵种的价值是未知的,从而难以统一度量和比较某兵种攻击对敌方不同目标时的价值差异。为统一度量各兵种的价值,需要对各型兵种的重要性进行加权比较。
需要注意的是,毁伤系数矩阵中各列的最大项并不一定是各型兵种的最优火力分配目标。在某些情况下,为了保护本方的高价值兵种,本方的其他兵种往往会攻击敌方目标中对我方高价值兵种威胁较大的兵种,从而体现了本方不同兵种之间的掩护作用,在某种程度上反映了兰彻斯特方程模型条件下的多兵种协同作战。权衡“打击敌方兵种”和“掩护本文兵种”,是各型兵种火力分配的一个难题。量化各型兵种在作战过程的作用和重要性,是解决上述难题的关键。
各型兵种对于作战过程的作用和重要性,即作战指数,是制定火力分配策略的重要依据。在作战指数已知条件下,从某兵种对敌方目标兵种毁伤系数和目标兵种作战指数乘积中,选择出最大的项,即对应最优的火力分配目标。因此,最优火力分配策略依赖于作战指数。
兵种的作战指数反映了该兵种对于作战过程的作用和重要性,采取的火力分配策略必然影响该兵种的作战效能。在火力分配策略已知条件下,某兵种的作战指数,应正比于其对敌方目标兵种毁伤系数和目标兵种作战指数的乘积。因此,兵种的作战指数又依赖于其采取的火力分配策略。
对于多兵种交战兰彻斯特方程,兵种的作战指数和火力分配策略是相互依赖的两组未知量,难以直接求解。借鉴强化学习理论中Q 学习方法对Q 值和行为策略的迭代更新过程,可采取迭代计算方法求解各兵种的作战指数和火力分配策略。如图1 所示,作战指数迭代计算方法的基本思想为:首先初始化各兵种作战指数取值,然后以最大化打击敌方作战指数为目标,制定当前各兵种的最优火力策略,之后再根据该火力分配策略对敌方作战指数毁伤程度,重新评估各兵种的作战指数;循环上述作战指数与火力分配策略的相互推算步骤,直至结果收敛到稳定值。
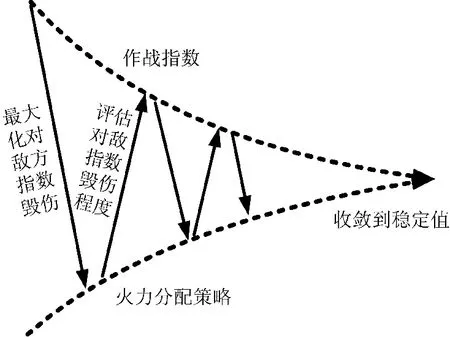
图1 作战指数迭代计算方法基本思想
基于上述基本思想,作战指数迭代计算方法的主要步骤为:


上述主要步骤中,第6)步的更新率α 取值对迭代计算方法的收敛速度和稳定性有重要影响,需要进一步详细考察。
3 收敛性与更新策略
为了提高作战指数迭代计算方法的收敛速度和稳定性,需要对主要步骤中第6)步进行适当调整,考察不同更新策略的效果。在整个迭代计算过程中,可采取一种相对简洁的策略,更新率α 始终选取某固定值,考察不同的固定值对收敛过程的影响;另一种比较灵活的策略是采取动态更新策略,迭代计算过程中动态调整更新率α 和更新梯度,进一步提高作战指数的收敛速度和稳定性。
3.1 固定更新率
在作战指数迭代计算方法中,固定更新率的不同取值对作战指数迭代过程有重要影响,下面通过算例进行详细考察。
算例1 设定甲乙方的兵种数量均为4 个,其毁伤系数矩阵为:
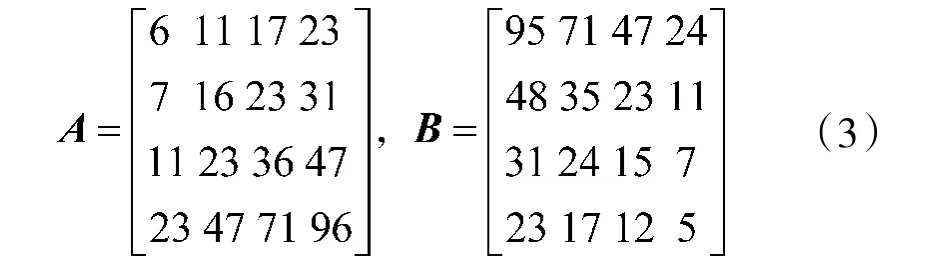
毁伤系数矩阵A 和B 是特殊构造的,其中每行的唯一偶数项对应于理论最优火力分配,甲方各兵种作战指数理论值分别为0.1、0.2、0.3 和0.4,乙方各兵种作战指数理论值分别0.4、0.3、0.2 和0.1。依据规范交战模式理论的图论求解方法,交战模式的核心循环对应于该毁伤系数矩阵中的偶数项,进而可以推算出各兵种作战指数理论值,详见文献[8]。后面将利用简单直观的作战指数迭代计算方法,快速求解各兵种作战指数理论值。
算例1 考察了更新率α 不同取值条件下双方作战指数的收敛过程,如图2 所示,更新率α 取值分别为0.01、0.1 和0.99,随着迭代次数的增加,双方各兵种的作战指数逐步收敛到理论值。算例1 表明,本文提出的方法能够正确收敛到理论结果,当更新率α 取值较大时,该方法在迭代初期具有较快的收敛速度,但在迭代后期容易引起振荡;当更新率α 取值较小时,该方法在迭代初期收敛速度较慢,但在迭代后期的稳定性较好。

图2 更新率α 不同取值时作战指数变化过程
为了验证算例1 中观测到的现象是否具有普遍性,下面在大规模多兵种条件交战下考察作战指数的收敛过程。算例2 中,甲乙方兵种数量均为100个,其毁伤系数矩阵中各元素为区间[0,1]范围内的随机值,共进行100 次实验,考察各方所有兵种作战指数的均方误差变化过程。算例2 的实验结果如图3 所示,随着迭代次数的增加,作战指数均方误差逐步减小并趋近于0,表明提出的方法在大样本条件下仍然具有良好的收敛性。
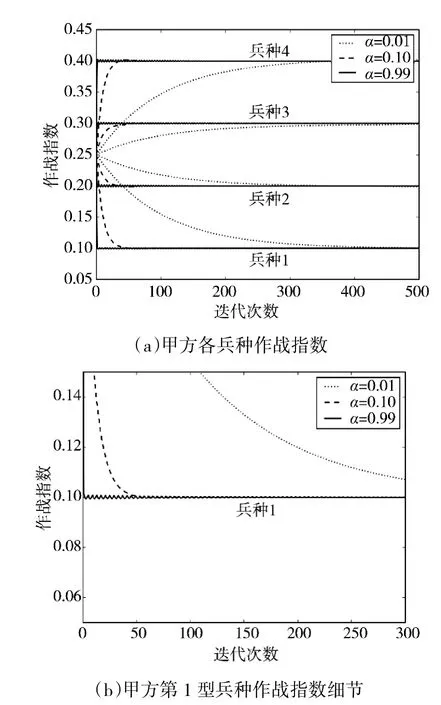
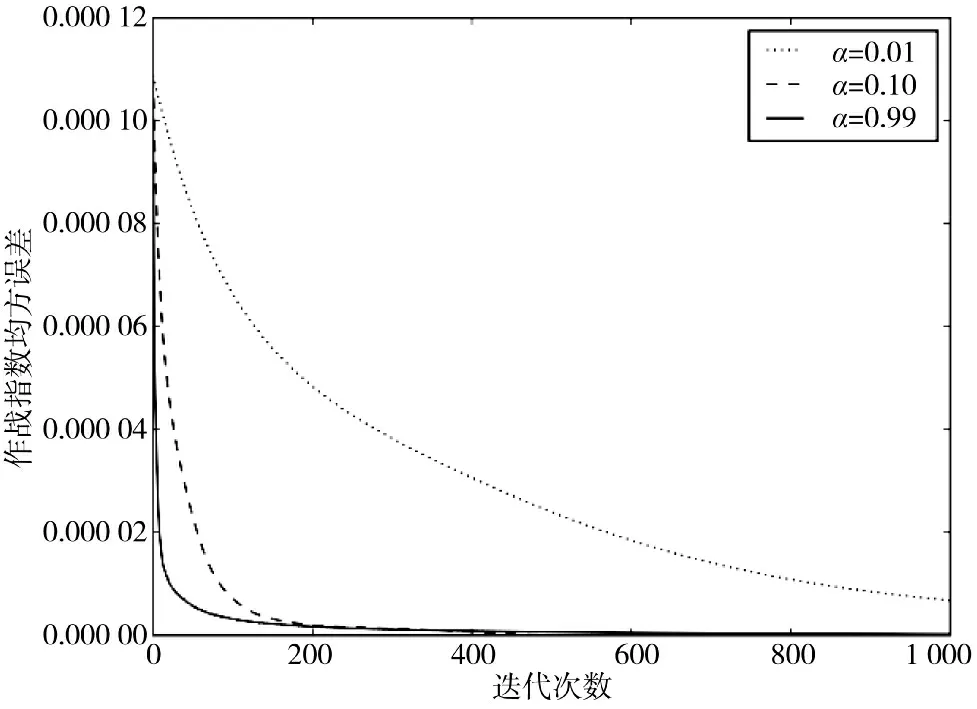
图3 更新率α 不同取值时作战指数均方误差变化过程
通过以上算例可以发现,本文提出的方法能够正确收敛到理论值,当更新率α 取值较大时,收敛速度较快,但后期容易振荡;当更新率α 取值较小时,收敛速度较慢,但后期相对平稳。为了兼顾收敛速度和稳定性两个指标,需要考虑动态更新策略。
3.2 动态更新策略
当更新率α 取固定值时,其取值较小时在迭代运算前期收敛速度偏小,其取值较大时在后期容易发生振荡,为了克服以上两个缺点,可采取动态更新策略,使得迭代运算在前期更新率取值较大,在后期更新率取值较小。下面着重考察两种动态更新策略,包括更新率指数递减方法和动量梯度方法。
3.2.1 指数递减方法
更新率指数递减方法指更新率随迭代次数增加以负指数函数的形式减小,其形式为

其中,α(t)表示在第t 步迭代时的更新率取值,参数k 表示递减强度,参数z0表示终态更新率。负指数函数α(t)是单调递减函数,当t 取值较小时,其函数值较大;当t 取值较大时,其函数值较小。该方法在某种程度上兼顾了更新率α 取值较大和较小时的优点,直觉上能够提高迭代运算的收敛速度和稳定性。
下面继续针对算例1,采取更新率指数递减方法进行作战指数迭代计算,其结果如图4 所示,随着迭代次数的增加,作战指数振荡幅度逐渐减小,提高了收敛稳定性。当终态更新率z0取值较大时,作战指数振荡幅度较大;当终态更新率z0取值较小时,作战指数振荡幅度较小;当递减强度k 取值较大时,收敛速度相对较慢,但振荡幅度较小;当递减强度k 取值较小时,收敛速度较快,但易产生振荡。对于更新率指数递减方法,迭代计算以降低后期收敛速度为代价来减少振荡,提高了收敛稳定性。
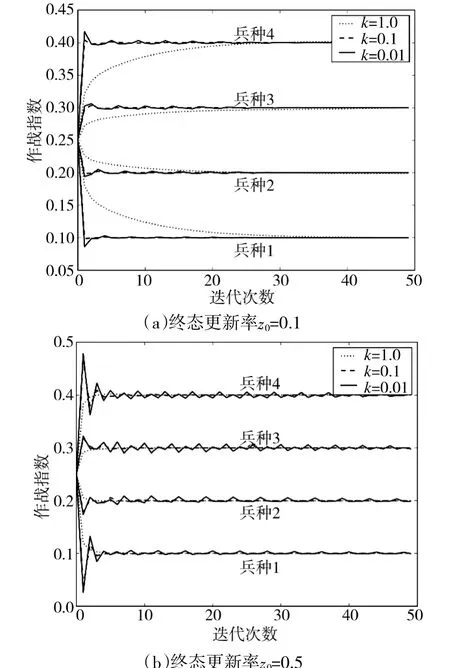
图4 更新率指数递减时甲方作战指数变化过程
3.2.2 动量梯度方法
动量梯度方法[11]能够在减少振荡的同时不降低收敛速度,是一种更为高效的方法。动量梯度方法通过累积历史梯度来抵消当前梯度的振荡。如图5(a)所示,迭代计算从初始值P 点开始,沿折线逐步向终点O 迭代收敛,显然,其迭代折线沿总体趋势线(虚线)上下振荡,若能消除在总体趋势线垂直方向的振荡,可加快迭代收敛速度和稳定性。若当前梯度与历史累积梯度方向近似相反,两者相加时相互抵消,从而减小振荡(图5(b));若当前梯度与历史累积梯度方向近似一致,两者相加时长度增加,从而提高收敛速度(图5(c))。观察图2(b)和图2(d),可以发现,当兵种作战指数振荡时,相邻迭代周期的梯度方向近似相反,当前梯度加上历史累积梯度可抵消当前梯度的振荡;当兵种作战指数没有振荡时,相邻迭代周期的梯度方向近似相同,当前梯度加上历史累积梯度可增加长度,提高收敛速度。
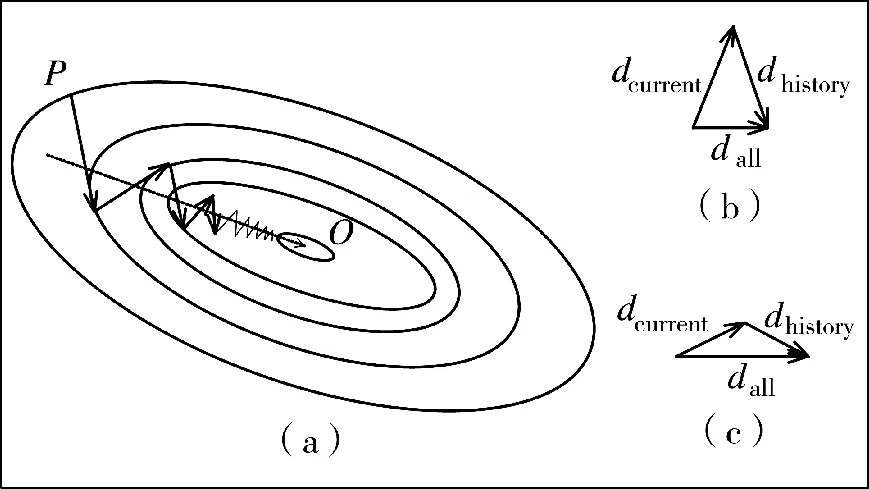
图5 动量梯度方法

下面继续针对算例1,采取动量梯度方法进行作战指数迭代运算,运算结果如下页图6 所示,动量梯度方法能够减小迭代过程中的振荡,提高迭代收敛速度和稳定性。当动量强度β 取值较大时,迭代过程中易产生较大幅度的长周期振荡;当动量强度β 取值较小时,振荡幅度减小甚至消失;当更新率α 取值较大时,振荡幅度较大,反之,则振荡幅度较小。动量梯度方法中,在迭代运算前期,相邻迭代周期的梯度方向近似一致,两者相加增大,提高了收敛速度;在迭代运算后期,相邻迭代周期的梯度方向近似相反,两者抵消减小振荡,提高了收敛稳定性。
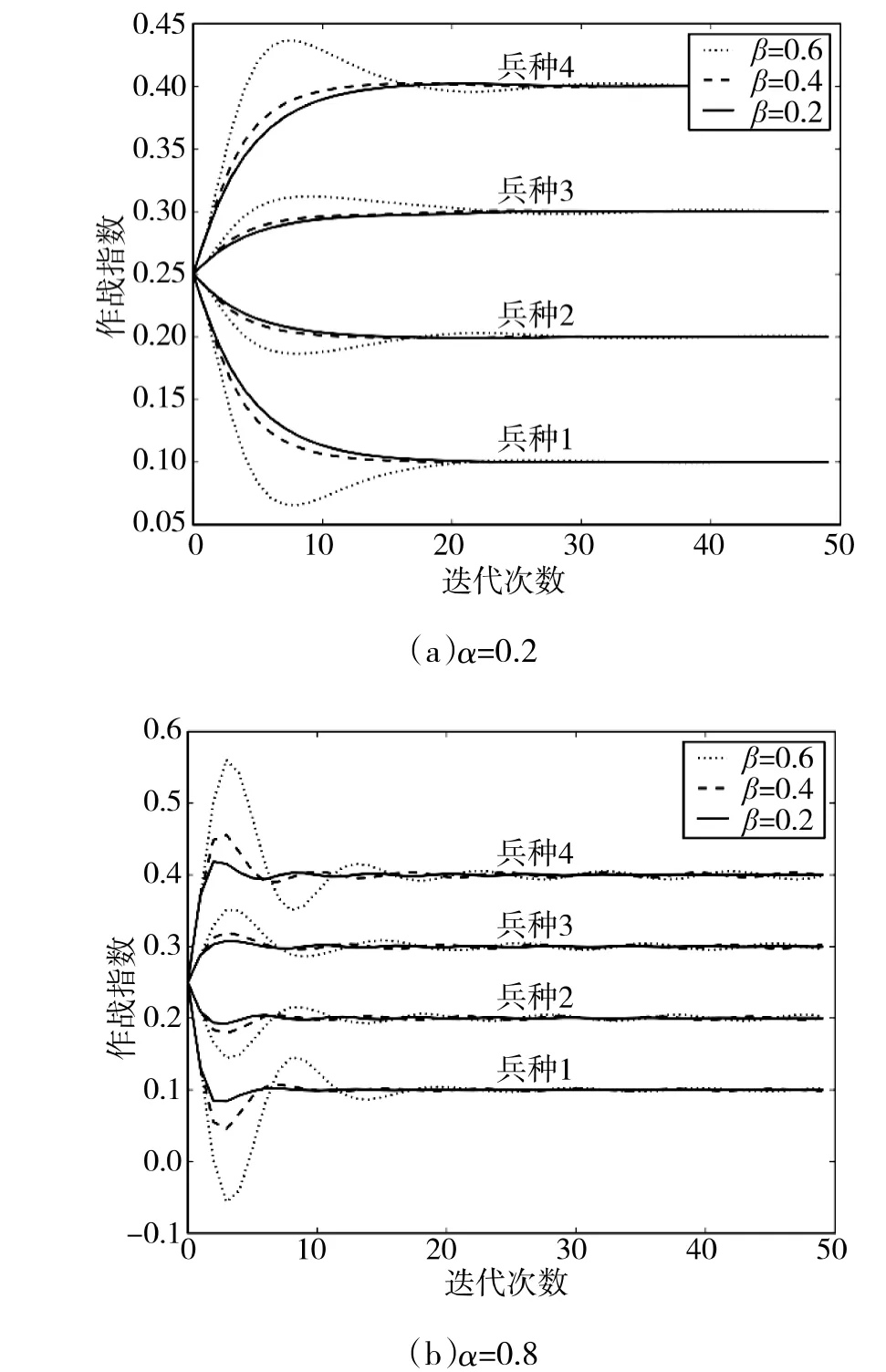
图6 动量梯度方法时甲方作战指数变化过程
3.3 小结
更新策略能够影响作战指数迭代计算方法的收敛速度和稳定性。对于固定更新率方法,当更新率α 取值较大时,收敛速度较快但容易振荡;当更新率α 取值较小时,收敛稳定性较好但收敛速度较慢。针对不同更新率α 取值的优缺点,更新率指数递减方法通过动态降低迭代后期的更新率取值,使迭代计算在前期具有较大的更新率,在后期更新率较小,从而综合了更新率α 不同取值的优点,兼顾了收敛速度和稳定性,具有思路简单直接的特点。动量梯度方法考虑了历史累积梯度方向与当前梯度方向的异同,利用两者相加时增强或抵消的性质,同时提高了收敛速度和稳定性,具有较好的自适应性。
4 结论
在多兵种交战问题中,评估各兵种的作战指数是进行军事决策的重要依据。对于多兵种交战兰彻斯特方程,各兵种的作战指数和火力分配策略之间的相互依赖关系,类似于强化学习理论中的Q 值和动作策略的相互依赖关系。本文通过类比研究,利用作战指数和火力分配策略的递推关系,提出了作战指数迭代计算方法,重点考察了固定更新率、指数递减方法和动量梯度方法对迭代过程的影响,通过调节更新率、递减强度和动量强度等超参数取值,提高了迭代收敛速度和稳定性。实验表明,提出的方法能够快速稳定收敛到最优解,具有简单直观、便于计算的优点,为军事理论研究和指挥决策提供有力定量支撑。
