基于结构与细节层分解的暗光照图像增强模型
2021-11-07汪雷宇郝世杰
汪雷宇, 韩 徐, 郝世杰
(合肥工业大学 计算机与信息学院,安徽 合肥 230601)
随着成像设备的发展,相机的分辨率、曝光时间等性能都有极大改善,拍摄出来的图像可以得到很好的质量。但由于拍摄环境的复杂性,常常导致图像视觉效果并不理想。例如,由于暗光和逆光等情况,图像对比度较低,图像细节被黑暗隐藏,降低了图像的视觉质量,也为各种后续处理任务带来了不利影响。因此,研究图像暗光增强方法,提高图像内容可视度,具有重要的研究价值。
基于暗光增强深度网络[1]在重构图像时难以生成完整的细节,从而导致增强结果略显模糊。为解决这一问题,本文从Retinex理论[2]中得到了启发。根据Retinex理论,一张图像S可以视作光照图像L和反射率图像R的乘积。其中:光照图像L反映了拍摄环境下的光照分布情况;反射率图像R表示物体的反射性质图像,即图像场景的内在属性,光照的改变不会对反射率图像R产生影响。
暗光增强的根本任务是对光照层进行改变,这一任务在理论上不会改变物体表面的纹理细节。而基于深度网络的方法[1]在试图重构图像时,不但要估计出成像场景中新的光照分布,还要重构出所有的图像细节。而后者对于暗光增强任务而言,是完全没有必要的。基于上述分析,本文提出了一种分而治之的思路:根据图像分解的方法,将图像的结构层(base layer)和细节层(detail layer)进行分离,其中结构层才是光照衰变的根本原因,因此本文利用深度学习技术对结构层进行增强处理,而细节层基本保持不变。基于上述思路,本文提出了一种基于图像分解的光照增强模型,通过一种边缘保留滤波器来有效分解彩色图像明度层,得到细节层和结构层信息;结构层通过光照增强模块进行处理,增强后的结果经过图像组合和颜色空间变换得到最终的结果,其模型结构如图1所示。基于上述思路,本文能够在增强图像对比度的同时能够很好地保持图像的细节信息,确保了增强后图像的视觉质量。
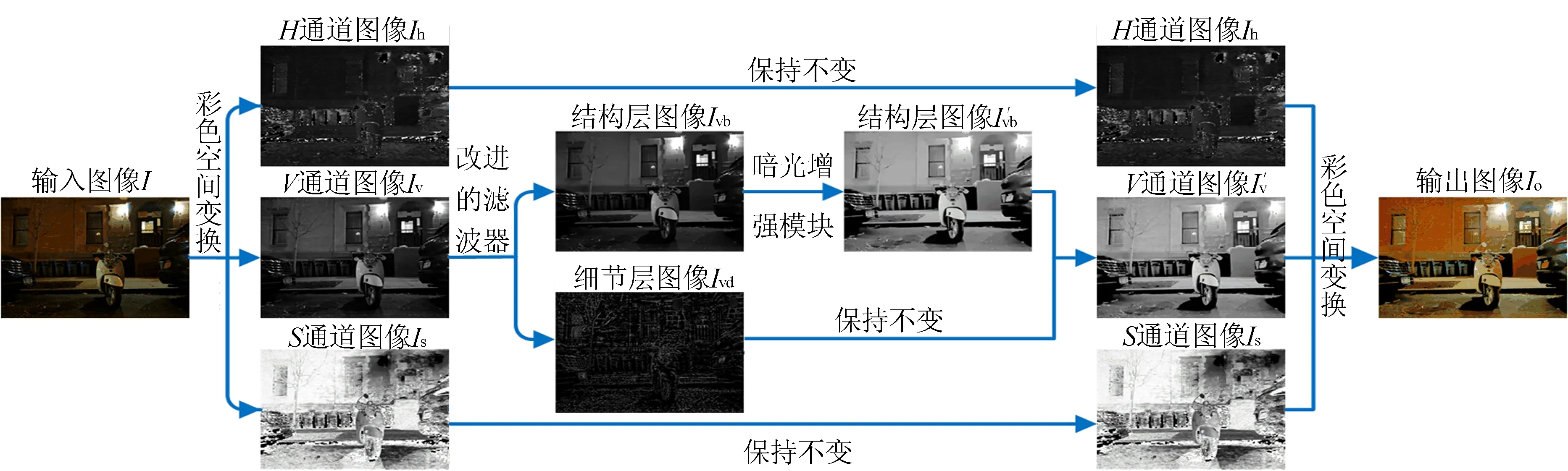
图1 本文模型的模型结构示意图
为便于展示,图1中细节层图像Ivd为增强10倍的效果图。
1 相关工作
1.1 Retinex相关算法
Retinex是一种常用的建立在科学实验和科学分析基础上的图像增强方法,通过几十年的不断发展,从单尺度Retinex算法[2](single-scale retinex, SSR)改进成多尺度加权平均的Retinex算法[3](multi-scale retinex, MSR),再发展成带彩色恢复的多尺度Retinex算法(multi-scale retinex with color restoration, MSRCR);相比较而言,MSR在实现图像动态范围的压缩同时保持了较好的色感。但SSR和MSR都普遍存在偏色的问题,为了改善此问题,MSRCR在MSR的基础上,加入了色彩恢复因子C来调节由于图像局部区域对比度增强而导致颜色失真的缺陷。此外,在Retinex的基础上还提出了简化的Retinex 模型[4],通过在R、G和B通道中找到最大值来分别估计每个像素的照度,然后对照度图进行完善来达到增强的效果。
1.2 基于融合的方法
在基于融合算法对图像进行暗光增强方面,可以从单张输入图像得到增强后的结果。文献[5]首先通过Retinex理论得到图像的原始亮度分量,然后设法得到全局亮度增强的亮度分量和局部对比度增强的亮度分量,最后通过拉普拉斯金字塔对上述3种亮度分量进行融合,得到增强后的亮度分量。另外,也可以从多张输入图像得到增强后的结果。文献[6]在拥有多张相同场景但不同曝光程度图像的情况下,通过设置权重矩阵,给曝光良好的像素分配较大的权重值,给曝光不足的像素分配较小的权重值,通过融合这些不同曝光程度的图像得到曝光程度良好的图像。
1.3 基于深度学习的方法
文献[7]提出了堆叠稀疏去噪自动编码器(stacked sparse denoising autoencoder,SSDA)网络模型。在此基础上,文献[1]提出了一种基于端到端的暗光增强深度网络(deep autoencoder approach to natural low-light image enhancement,LLNet)。
LLNet图像增强算法的训练数据为成对图像,包括暗光图像和正常光照图像,整个网络通过堆叠多层的稀疏降噪编码器,学习到暗光图像的深层特征,然后通过对应的稀疏降噪解码器对深层特征进行解码重构;在重构的过程中,需要尽可能地保证重构后的图像能够接近正常光照图像,但是该算法在重构图像时难以生成完整的细节,从而导致增强结果略显模糊。
受Retinex理论的启发,并结合卷积神经网络技术,文献[8]提出了RetinexNet模型,它采用两阶段式先分解后增强的步骤。在第1阶段,对图像进行解耦,得到光照图和反射图;在第2阶段,对前面得到的光照图进行增强,增强后的光照图和原来的反射图相乘得到增强结果。
目前基于深学习的图像暗光增强工作主要有以下2点局限性:
(1) 成对的训练数据难以获取,这使得深度神经网络的训练变的十分困难。
(2) 很难设计得到一种端到端的神经网络结构。
针对成对的训练图像难以获取这个问题,研究人员通过不同的方法进行尝试。一方面,可以在现有图像的基础上通过技术处理得到相对应的图像;例如文献[9-11]均采用了该种方法,虽然效果很好,但是得到的图像仍然无法完美地模拟真实情况。另一方面,技术人员利用成像技术得到更加自然的图像对。文献[12]提出了SID(see-in-the-dark)数据集,通过控制曝光时间得到自然的图像序列,效果显著,但时间和精力花费较大。由于成对的训练图像难以获取,部分研究人员转向了对训练集要求相对较低的无监督学习模式。在文献[13]中,不需要输入-输出图像对,只需要一组“好”图像(用于输出图像的真实值)和一组想要增强的“坏”图像(用于输入图像)就可以完成EnlightenGAN模型的训练,对数据集的要求大大降低。
2 本文方法
2.1 本文框架
借助于LLNet网络,本文提出了一种基于结构与细节层分解的暗光照图像增强模型,利用边缘保持滤波器将图像结构层和细节层进行分解,利用自编码器网络处理图像结构层,对图像细节层加以保留。
首先将原始彩色图像I由RGB彩色模型空间转换到HSV彩色模型空间,提取出H、S和V通道分量,并表示为Ihsv={Ih,Is,Iv}。
然后通过保边缘滤波器对V通道分量Iv进行分层处理,得到相对应的V通道细节层分量Ivd和V通道结构层分量Ivb;紧接着将V通道结构层分量Ivb通过光照增强模块进行亮度增强,得到V通道结构层分量Ivb的增强图像Ivb′,并将得到的增强图像Ivb′和V通道细节层分量Ivd重新组合,得到V通道的增强图像Iv′。
最后将三通道分量{Ih,Is,Iv′}融合得到Ihsv′并由HSV彩色模型空间转换到RGB彩色模型空间,获得最终的输出图像Io。
2.2 改进的保边缘滤波器
在模型中,为实现高效的图像结构-细节分解,提出了一种改进的保边缘滤波器。通过构建总变分模型,并设计了基于快速傅里叶变换的计算方法。本节重点描述改进的保边缘滤波器相关部分的工作。
滤波器的损失函数表示为:
(1)
L=lgS,
其中:S为输出图像;L为输入图像;下标V表示V通道分量;λ为正则化参数,用来平衡前后两项的系数;γ为分母比例参数;为离散微分,在本文中,它包括有水平方向x和垂直方向y;Ω为r×r大小规模的局部图像块。在(1)式中,第1项考虑了初始图像IV与输出图像S之间的保真度,它使得平滑的S与输入Iv之间的差最小;第2项考虑了结构感知平滑度,使S的偏导数最小。
(1)式可表示成如下最小化问题,即
(2)
L=lgS,
其中:W为平滑权重;λ为正则化参数;S为S上的离散微分,可分为X方向和Y方向。
(2)式可以通过交替方向最小化(alternating direction method of multipliers,ADMM)技术来有效地解决。
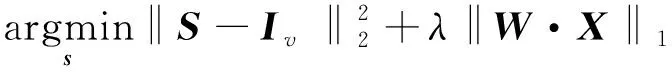
s.t.X=S
(3)
(3)式的增强拉格朗日函数可以表示如下:

(4)
其中:〈·,·〉为2个矩阵的内积运算;ρ为正罚标量;Y为拉格朗日乘数。(4)式中存在S、X、W、ρ和Y共5个未知变量。通过ADMM方法对(4)式中的未知变量进行迭代求解。
对于未知变量S:

(5)
对(5)式进行求导,得到:
2(S-Iv)+ρk-1DT(DS-Xk-1)+
DTYk-1=0
(6)
其中:D为输入图像的微分运算结果,可分为Dx和Dy,分别代表输入图像在X和Y方向上的微分运算结果。
对(6)式进行化简,可得:
(7)
对(7)式直接进行求解,可得:
(8)
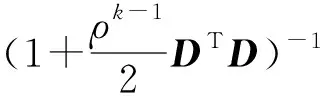
(9)
进而可以得到(10)式,即
Sk=
(10)
其中:F表示傅里叶变换;F-1表示傅里叶逆变换;F*表示共轭傅里叶变换。
对于X有:
(11)
由(11)式可得:
(12)
其中,Jα(x)=sgn(x)max(|x|-α,0)。
同理,对于W、ρ和Y,有
(13)
ρk=ηρk-1, (η>1)
(14)
Yk=Xk-1+ρk-1(Sk-Xk)
(15)
其中,Lk-1=lgSk-1。
通过上述运算,得到关于输入图像Iv的平滑结果S,即图像的结构层信息Ivb。
2.3 光照增强模块
光照增强模块借助深度学习技术,使用文献[1]中的LLNet网络为主体框架,构成了encoder-decoder形式,该模块的输入为结构层图像Ivb,输出为增强图像Ivb′。
模块由3层去噪自编码器(denoising autoencoder,DA)构成,具体的节点数为:输入为17×17像素的块图像,即289个输入单元;后面的隐藏单元数分别为867、578、289、578、867;最后为输出单元,输出单元具有与输入相同的尺寸,即289。其中,第1层DA有867个隐藏单元;第2层DA有578个隐藏单元;第3层DA有289个隐藏单元,通过最小化重建图像和正常光照图像之间的均方误差达到训练效果。整个训练过程包括预训练和微调2个阶段。在预训练阶段,每个DA层都通过误差反向传播进行训练,以最小化稀疏正则化重建损失,其损失函数为:
(16)

在通过预训练对权重进行初始化之后,使用误差反向传播算法对整个预训练网络进行微调,最小化给定的损失函数为:
(17)
其中:L为DA层的数量;W(l)为堆叠神经网络的第l层的权重矩阵。
3 实验部分
3.1 实验说明
在本文模型中,暗光增强模块通过Python 2.7、Theano 1.0.3版本实现,其余部分均通过Matlab代码使用3.4 GHz CPU和8 G RAM的计算机实现。
在建筑给排水的部署实施过程中,难免会遇到各种困难。因为各个建筑物的设计不同,所以对应的给排水设计也应该不同。建筑给排水设计人员应该参照建筑的施工设计图纸,然后进行实地考察,再设计给排水施工图纸。在设计施工图纸的过程中,设计人员要认真负责,足够自信,并且要严格遵守国家关于建筑工程施工的法律法规。设计完图之后,要进行相应的模拟测试。模拟测试要根据施工的环境特点,设置对应的模拟实验环境,争取在最大程度上保证模拟测试环境与真实施工环境相一致,这样才能保证测试结果的可信度。测试完毕后,设计人员需要根据测试结果,对设计图纸进行相应的修改,使其达到最佳的效果。
通过收集暗光增强领域的常用测试图像和在现实生活中拍摄得到的图像作为本文中的测试图像,它们包含各种场景和亮度条件。本文的模型配置参数如下:滤波器的参数有k、r、λ和γ,k和r在本文中为固定参数,k=10,r=3。其中:k为图像处理过程中的迭代次数;r为滤波半径;λ为正则化参数;γ为分母比例参数。λ和γ在本文中存在多个数值,通过不同的数值作对比实验,借此确定最终的选值。
训练数据方面,通过训练数据生成方法(伽马校正和添加高斯噪声)来模拟低光环境,从而得到成对的训练数据用于训练模型。每对训练数据包括正常光照图像和相对应的模拟低光环境下生成的暗光图像。
对198对训练图像对进行分块处理,每张图像得到2 500个图像块,最终得到495 000对图像块,其中60%作为训练集,20%作为验证集,20%作为测试集。
在预训练阶段,每层的迭代次数为30次;在微调阶段,设置的迭代次数为2 000次,在迭代到470次左右时验证集损失达到最小。
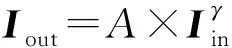
3.2 对比实验
本小节的对比实验分为2个部分:
(1) 验证改进的保边缘滤波器的有效性。一方面对滤波器的参数变化带来的影响做直观的对比实验;另一方面为了观察改进的保边缘滤波器对输出结果的影响,通过采用不同参数配置的模型做直观的结果对比。
滤波器参数λ、γ调整的对比效果如图2、图3所示。由图2、图3可以看出,改进的滤波器有2个参数影响对图像的处理效果,分别为λ和γ。具体来说,通过固定其中一个参数,然后改变另外一个参数来查看对滤波结果的影响。

图2 λ=0.01,滤波器参数γ调整的对比效果

图3 γ=0.6,滤波器参数λ调整的对比效果
不同参数的滤波器对最终效果的影响(k=10,r=3)如图4所示。图4中:第1行为原始图像和经过不同参数模型处理后得到的图像;第2行为部分区域放大图;第3行为对应参数模型提取的结构层图像。

图4 不同参数的滤波器对最终效果的影响
从图2~图4可以看出,随着λ和γ不断增大,滤波器对图像结构层的提取趋向于平滑,能够得到更全面的细节层信息,但是结构层趋于平滑的程度越大,暗光增强模块在重构过程中的伪影效果就越严重,从图4的第2行可以明显看出。鉴于此,在后面的模型选择中,参数定为k=10,r=3,λ=0.01,γ=0.6。
本文选定滤波器参数为k=10,r=3,λ=0.01,γ=0.6的模型,并将其与一些经典的暗光增强模型进行对比,包括基于深度神经网络的模型[1,8]、基于直方图的模型[14]和基于简化的Retinex的模型[15],上述模型的方法均为开源,文中关于上述模型的参数使用的均是开源代码中的默认值。
基于上述模型和本文模型给出了增强的结果展示如图5和图6所示,并逐一与本文模型进行对比,可以得到以下观察结果。

图5 多种暗光增强模型的效果对比

图6 多种暗光增强模型的效果对比(局部放大)
文献[1]在图像的暗光增强方面效果比较显著,但是图像的纹理细节部分存在比较明显的丢失,图像整体偏向于模糊,图6中的屋角放大区域可以很明显地看到细节信息的丢失。文献[8]在保留细节方面优于文献[1],但经过文献[8]处理后的图像在图像风格上存在着较大的改变,偏向于过度增强整个图像场景,图像风格趋于动漫化。文献[14]的处理效果在细节的保留方面具有很大的优势,但是在主要目的暗光增强方面却存在着较大的欠缺,该模型的增强效果收效甚微。文献[15]的结果在图像的轮廓部分出现一些伪影效果,图像的轮廓鲜明突出,图像风格发生变化,影响视觉展示。
另外,图6的天空放大区域,文献[8]和文献[15]的结果存在着明显的伪影现象,文献[1]、文献[14]和本文模型基本不存在伪影问题。
本文模型是基于文献[1]中的LLNet网络模型发展而来,其初衷是为了更好地保留增强图像的细节信息。针对这一部分,文中对本文模型和LLNet[1]网络模型做了相对应的对比实验,如图7所示,可以很明显地得到以下2点结论:
(1) 在纹理细节方面,由于改进的滤波器的作用,本文能够在增强图像对比度的同时很好地保持图像的细节信息,使得增强图像在细节方面更加丰富,给人更好的视觉效果,确保了增强后图像的视觉质量。
(2) 在暗光增强方面,本文模型的增强效果略优于LLNet[1]网络模型,整体的效果更加的明亮。

图7 本文模型与LLNet的效果比较
为了进行模型间的量化对比,对文献[1]、文献[8]、文献[14]、文献[15]和本文模型进行打分评定。对比实验选用了31张图像,打分人数为10人,分数区间为1~5分,其中1分代表图像展示效果最差,5分代表图像展示效果最好,分数为整数,对模型的分数进行平均,得到最终评分。在图像评分过程中,仅仅提供如下打分规则:① 对比增强后图像的亮度与原始图像相比是否有提高;② 增强后图像的整体灰度分布是否合理;③ 增强后的图像是否引入外来噪声,破坏了图像的自然效果。
具体评分结果见表1所列。

表1 不同模型增强图像评分结果
由表1可知,相比较其他4种模型,本文模型在整体效果上有较大的优势,说明了本文模型的适用性和有效性。
4 结 论
本文基于 LLNet[1]网络模型,提出了一种基于结构与细节层分解的暗光照图像增强模型,该模型对各种照明条件均具有鲁棒性,在不同类型的照明条件下都能很好地工作,有效地避免了过度增强或增强不足的情况。相比于传统的基于自编码器网络的方法,本文模型可以在有效改善暗光图片的可视度前提下,仍能很好地保持图像的细节信息,提高了图像的丰富度。在后续的工作中,计划在一个统一的框架中实现细节增强和低光增强的任务,或者参考文献[16]的手段尝试将暗光增强技术融入到目标检测任务中。
