如何正确运用χ2检验
——拟合优度检验与SAS实现
2021-11-04胡纯严胡良平
胡纯严 ,胡良平 ,2*
(1.军事科学院研究生院,北京 100850;2.世界中医药学会联合会临床科研统计学专业委员会,北京 100029*通信作者:胡良平,E-mail:lphu927@163.com)
在进行列联表资料的独立性分析和/或广义线性回归模型[1]分析中,常会涉及“拟合优度检验”和“失拟检验”等内容[1-4]。本文将介绍有关概念、各种检验方法的计算公式以及基于SAS软件[5]实现计算的方法。
1 有关基本概念
1.1 拟合优度检验的定义和种类
所谓拟合优度检验,就是评价基于某种假设或回归模型推算出按顺序排列的一组期望频数与相应观察频数之间一致性的一种检验方法[1,5]。拟合优度检验常涉及以下两个统计学问题:其一,检验某种假设是否成立。例如:在列联表资料分析中可能会提出“某些属性变量之间存在独立性”的假设,此时的检验被称为“独立性拟合优度检验”;又例如:在展示一组单变量资料的频数分布时,可能会提出“该组资料服从正态分布、Poisson分布或二项分布”的假设,此时的检验被称为“分布拟合优度检验”。其二,检验所拟合的某个回归模型对所描述资料的变化趋势是否吻合,此时的检验被称为“回归模型拟合优度检验”。
从功能上来划分,拟合优度检验可分为四种:①独立性拟合优度检验(常用于列联表资料的独立性检验);②线性拟合优度检验(常用于定量因变量的线性回归分析中,以判断是否需要采取更复杂的方法或非线性回归模型);③分布拟合优度检验(以判断给定的资料是否服从某种特定的概率分布,如正态分布、Poisson分布或二项分布);④回归模型拟合优度检验(以判断当前所构建的回归模型与给定资料的吻合程度)”。从检验统计量所服从的分布来划分,拟合优度检验可分为三种:①F分布(常用于线性回归模型的分析之中);②经验分布(即柯尔莫哥洛夫检验);③χ2分布(常用于除线性回归模型分析之外的其他场合)。从构造检验统计量的方法来划分,拟合优度检验可分为三种:①方差分析法(常用于线性回归模型的分析);②似然比法(常用于除线性回归模型分析之外的其他场合);③观测频数与理论频数之偏差的平方和法(常用于除线性回归模型分析之外的其他场合)。这三种划分方法在内容上存在交叉和重叠。因篇幅所限,本文仅介绍基于“χ2检验统计量”的拟合优度检验方法[5-9]。
1.2 失拟检验及其与拟合优度检验的关系
所谓失拟检验,就是对回归函数是否为自变量的线性函数进行的检验[2]。失拟检验最早出现在简单线性回归模型的分析过程中,用以检验采用简单线性回归模型是否可以取代曲线回归模型。若失拟检验的结果为P>0.05,表明用简单线性回归模型可以取代曲线回归模型;反之亦然。在SAS/STAT的REG过程中,在进行多重线性回归分析时,也可以进行失拟检验[5]。值得注意的是:在线性回归分析中所做的失拟检验是F检验(也叫做方差分析),而不是χ2检验。在SAS/STAT的LOGISTIC过程中,将“Hosmer-Lemeshow检验”列入“拟合优度检验(Goodness of fit tests)”标题之下,但在指定“选项(lackfit=)”时,却又将其归类于“失拟检验”之中;然而,在SAS/STAT的PROBIT过程中,将“失拟检验”与“拟合优度检验”视为同一种检验[5]。正因如此,在下文中,统一称为“拟合优度检验”,而不特别区分何时为“拟合优度检验”,何时为“失拟检验”。
2 Pearson’s拟合优度检验
2.1 可以应用的三种场合
Pearson’s拟合优度检验可以应用于下列三种场合[1-5]:①列联表资料独立性假定的拟合优度检验;②单变量频数分布的分布拟合优度检验;③除线性回归模型分析之外的其他回归模型的拟合优度检验。
2.2 Pearson’s拟合优度检验统计量
2.2.1 独立性拟合优度检验统计量
在进行R×C列联表(包括2×2列联表)资料的独立性检验时,Pearson’s拟合优度检验统计量的形式见式(1):
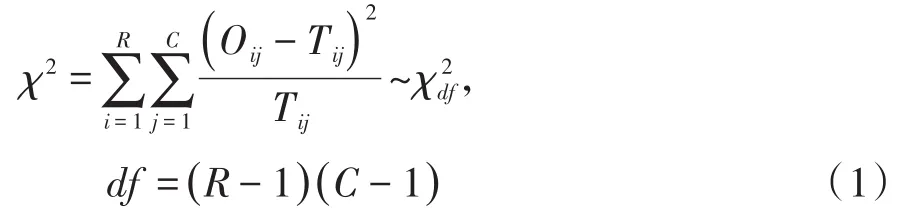
在式(1)中,χ2服从自由度为df=(R-1)(C-1)的χ2分布;R和C分别代表二维列联表的“行数”与“列数”。
2.2.2 分布拟合优度检验统计量
在推断一组单变量定量资料服从何种频数分布时,Pearson’s拟合优度检验统计量的形式见式(2):
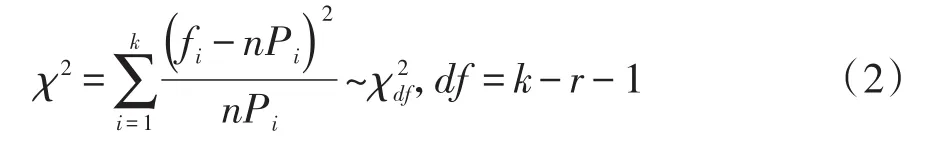
在式(2)中,χ2服从自由度为df=k-r-1的χ2分布;k为资料中不同数据个数或分组数;r为假定概率分布函数中待估参数的个数;fi为定量变量的第i观测值(需要由小到大排序,在实际使用中,应是第i个组的组中值)所对应的观测频数;Pi为与fi对应的频率;n为总样本含量;nPi为基于设定概率分布推算出来的理论频数。
值得注意的是:各nPi应大于等于5,否则,需要将相邻的数据或组进行合并,以满足前述的前提条件。
2.2.3 回归模型拟合优度检验统计量
2.2.3.1 在SAS/STAT的GENMOD过程中的定义
在SAS/STAT的GENMOD过程中,Pearson’s拟合优度检验统计量的定义见式(3):
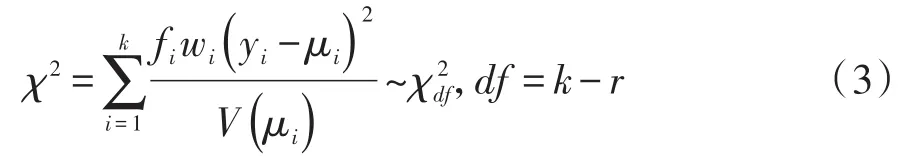
在式(3)中,χ2服从自由度为df=k-r的χ2分布;k为资料中不同数据个数或分组数;fi、wi、yi、μi和V(μi)分别代表第i个组的“频数”“权重”“因变量的取值”“yi的期望值”和“yi的方差”;r为所构建的回归模型中待估参数的个数(包括截距项)。值得注意的是:广义线性模型涵盖面很宽泛,其因变量通常涉及以下常见概率分布,例如:正态分布、Poisson分布、伽玛分布、逆高斯分布、二项分布、多项分布、负二项分布、零膨胀Poisson分布和零膨胀负二项分布等;依据不同的概率分布,yi、μi和V(μi)将取不同的值或计算公式,限于篇幅,不再赘述。
2.2.3.2 在SAS/STAT的LOGISTIC过程中的定义
在SAS/STAT的LOGISTIC过程中,Pearson’s拟合优度检验统计量的定义见式(4):
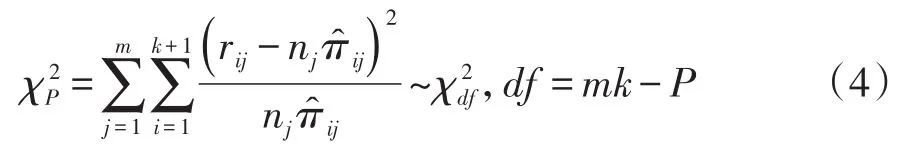
2.2.3.3 在SAS/STAT的PROBIT过程中的定义
在SAS/STAT的PROBIT过程中,Pearson’s拟合优度检验统计量的定义见式(5):

3 偏差或称似然比拟合优度检验
3.1 可以应用的场合
偏差或称似然比拟合优度检验的应用场合较少,目前仅应用于回归模型拟合优度检验和检验整个回归模型中全部参数是否都为0。
3.2 偏差拟合优度检验统计量
3.2.1 在SAS/STAT的GENMOD过程中的定义
在SAS/STAT的GENMOD过程中[5],偏差拟合优度检验统计量的定义见式(6):
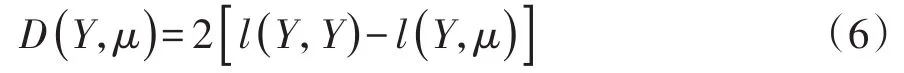
在式(6)中,Y与μ分别代表因变量的向量与因变量预测均值向量;l(Y,Y)和l(Y,μ)分别代表含有全部自变量的回归模型的似然函数的自然对数与含有部分自变量的回归模型的似然函数的自然对数;D(Y,μ)服从自由度为df=n-q的χ2分布,这里,n和q分别代表总样本含量与所构建的回归模型中待估参数的个数(包括截距项)。
3.2.2 在SAS/STAT的LOGISTIC过程中的定义
在SAS/STAT的LOGISTIC 过程中[5],偏差拟合优度检验统计量的定义见式(7):
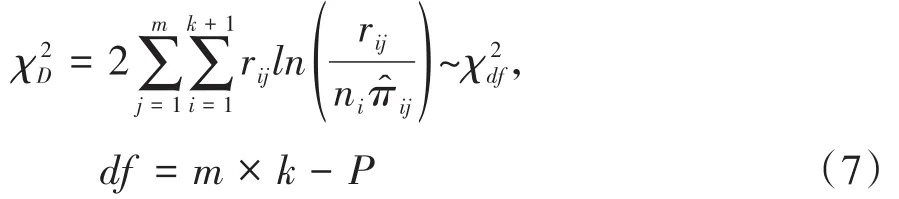
3.2.3 在SAS/STAT的PROBIT过程中的定义
在SAS/STAT的PROBIT过程中[5],偏差拟合优度检验统计量的定义见式(8):
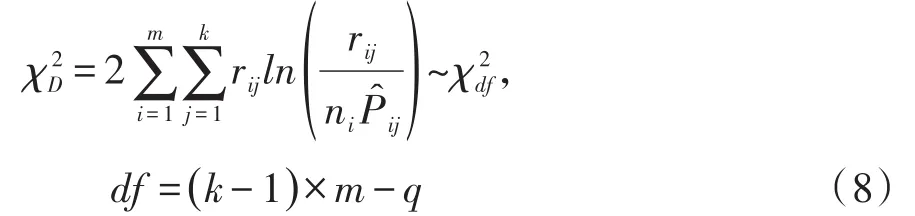
4 Hosmer-Lemeshow拟合优度检验
4.1 概述
前面介绍的Pearson’s拟合优度检验与偏差拟合优度检验都是基于数据分组之上的,当资料中存在连续性变量时,就不可避免地会出现某些组中的样本含量很少,甚至只有1~2个样本,这种现象被称为“稀疏资料”。事实上,前面提及的两种拟合优度检验要求各组样本含量应大于等于5,否则,其检验结果不可靠。针对“稀疏资料(某些组中没有重复数据)”,Hosmer和Lemeshow于2000年提出了一种新的拟合优度检验方法,该拟合优度检验统计量近似服从χ2分布[5]。
4.2 二值因变量条件下Hosmer-Lemeshow拟合优度检验统计量
二值因变量条件下Hosmer-Lemeshow拟合优度检验统计量见式(9):
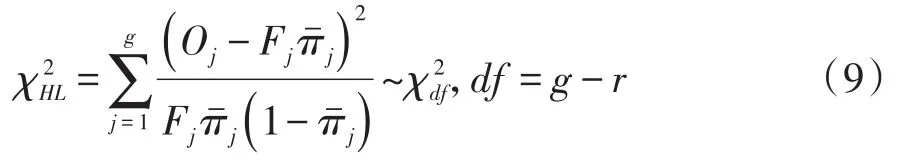
4.3 多值因变量条件下Hosmer-Lemeshow拟合优度检验统计量
多值因变量条件下Hosmer-Lemeshow拟合优度检验统计量[5]见式(10):
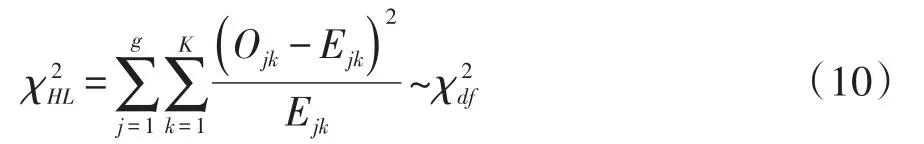
5 稀疏资料拟合优度检验
5.1 概述
尽管Hosmer-Lemeshow拟合优度检验对稀疏资料具有一定的校正能力,但它仍然需要将资料分组后才能进行计算。当资料中“稀疏情形”非常严重时,其检验效能将会明显下降。为此,统计学家提出了另外6种稀疏资料拟合优度检验方法。迄今为止,这些方法仅适用于因变量为二值变量的logistic回归模型之中[5]。设j代表事件出现的预测概率,代表拟合模型的协方差矩阵。
5.2 不需对资料进行分组的稀疏资料拟合优度检验法
5.2.1 信息矩阵检验
Orme于1988年将White于1982年提出的“一般错误指定检验”应用于二项反应资料。设Xj为第j个观测的设计向量(即由全部协变量形成的向量),于是,XjX'j就是信息矩阵。通过信息矩阵XjX'j的右上角矩阵,将设计向量Xj展开成为一个新向量,记为Vech(Xj)。通过将Xj尺度化,通过将Vech(Xj)尺度化。使用残差ej=Yj-j的二项形式创建新反应变量的值Y*,其表达式见式(11):

构建Y*关于展开后的协变量的多重线性回归模型,求出该模型的回归平方和,这个平方和服从自由度为df的χ2分布。这里,df等于尺度化后的Vech(Xj)中未退化的协变量的数目。基于此方法产生的检验结果在拟合优度检验表中的标签为“信息矩阵”。
5.2.2 信息矩阵对角线检验
Kuss于2002年修改了上述“信息矩阵检验”方法,即仅通过信息矩阵XjX'j对角线上的元素,将设计向量Xj展开成为一个新向量,记为Vech(Xj)。基于此方法产生的检验结果在拟合优度检验表中的标签为“信息矩阵对角”。
5.2.3 Osius-Rojek检验
Osius和Rojek于1992年用固定格渐近方法推导出 Pearson’sχ2统计量的均值和方差,均值为m,即子总体的个数(即“组数”);方差的计算方法见式(12):
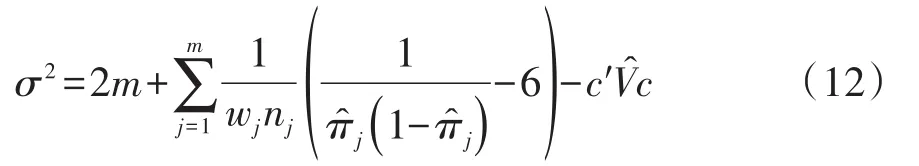

基于式(13)可得到Osius-Rojek检验统计量见式(14):

在式(14)中,B的定义见式(13);为服从自由度为1的χ2分布的检验统计量。
5.2.4 未加权的残差平方和检验
Hosmer等于1997年在Copas于1989年提出的基本公式的基础上,构造出未加权的残差平方和检验统计量,见式(15):
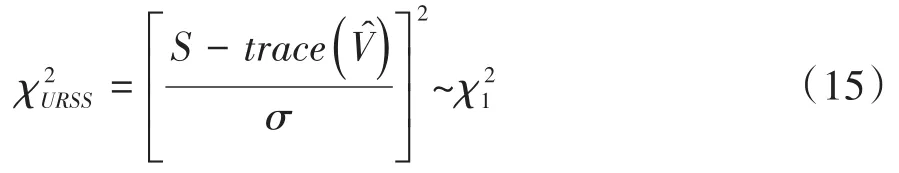
在式(15)中,σ为回归的残差标准差,其他符号的含义分别如下:

5.2.5 Spiegelhalter检验
Spiegelhalter于1986年基于Brier评分推导出一个检验统计量,见式(18):
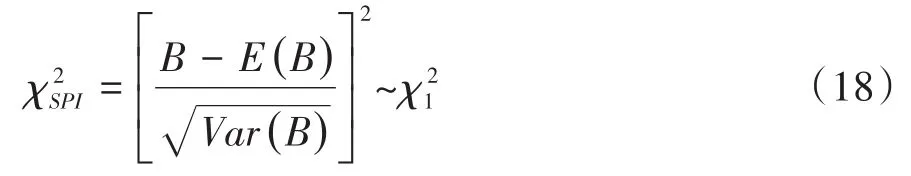
在式(18)中,各符号的含义如下:
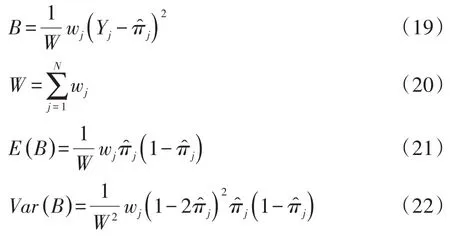
5.2.6 Stukel检验
Stukel于1988年提出了如下方法,在现有模型中增加两个新变量,然后检验这两个新变量是否为无统计学意义的变量。对于二值反应变量而言,设ηj=X'jβ,I(·)代表指示变量,增加的两个新变量如下:

然后,应用“评分检验(说明:此检验常被用于检验模型中部分回归系数是否为0)”检验这个大模型(指增加两个新变量后的模型)与已拟合的模型(即未增加新变量的模型)之间差异是否有统计学意义。若检验的结果为“P>0.05”,说明原先已拟合的模型对资料的拟合效果满意。
6 实例与SAS实现
6.1 问题与数据
【例1】为探讨新生儿乙肝病毒宫内感染的危险因素,某医科大学流行病学教研室于2004年-2005年收集了145例HBsAg阳性孕妇及其145例新生儿作为研究对象,检测新生儿出生24小时内血清中HBV DNA,以判断是否发生了乙肝病毒宫内感染,新生儿血清HBV DNA阳性者为发生宫内感染,阴性者为未发生宫内感染。同时检测孕妇血清中HBVDNA(阴性=0,阳性=1)、HbeAg(阴性=0,阳性=1),所得资料见表1[10],试分析新生儿乙肝宫内感染的影响因素。
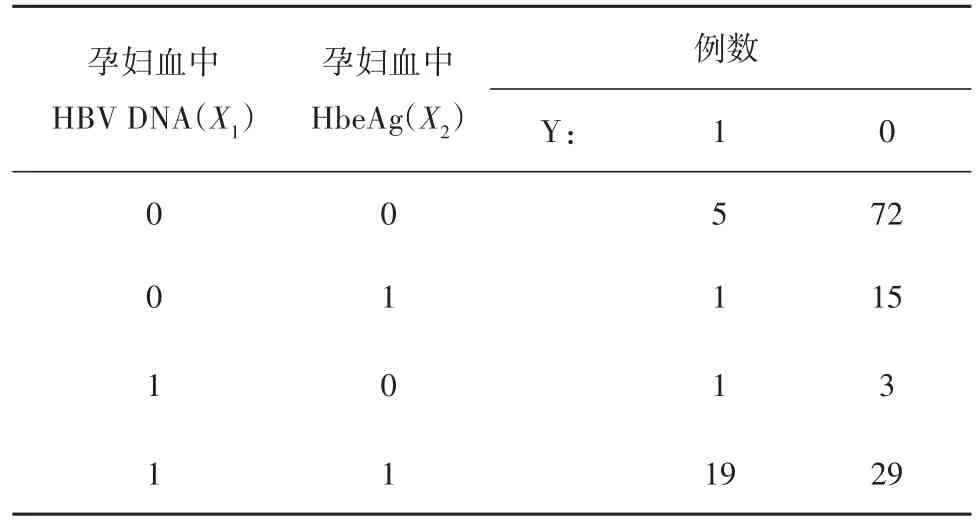
表1 145例孕妇及其新生儿血清HBV相关指标检测结果
【分析与解答】设所需要的SAS程序如下:

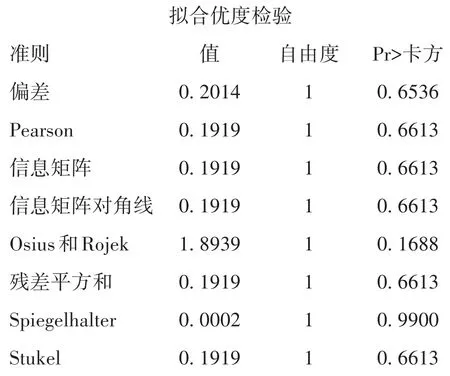
以上输出的是“拟合优度检验”结果,前两行是最常用的方法,后六行是稀疏资料拟合优度检验结果,P均>0.05,说明所构建的回归模型对资料的拟合效果好。

以上输出的是“模型拟合统计量”,它们只能相对反映模型对资料的拟合效果,因为它们不是假设检验的结果,只有在有两个或两个以上模型时,才可根据模型拟合统计量的数值,判断哪个模型对资料的拟合效果相对更好(例如,各种“R2”值越大越好,AIC、AICC和SC的值越小越好)。

以上输出的是“Hosmer和Lemeshow拟合优度检验”结果,因P=0.9085>0.05,说明所构建的回归模型对资料的拟合效果较好,不存在“失拟”问题。
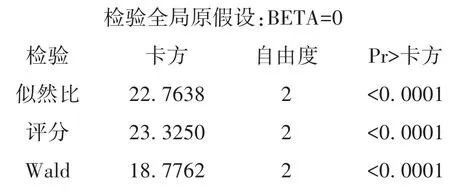
以上输出的是“检验全局原假设:BETA=0”的结果,三种检验方法所得结果和结论基本一致,即认为回归模型中的回归系数不全为0,所构建的回归模型具有一定的实用价值。
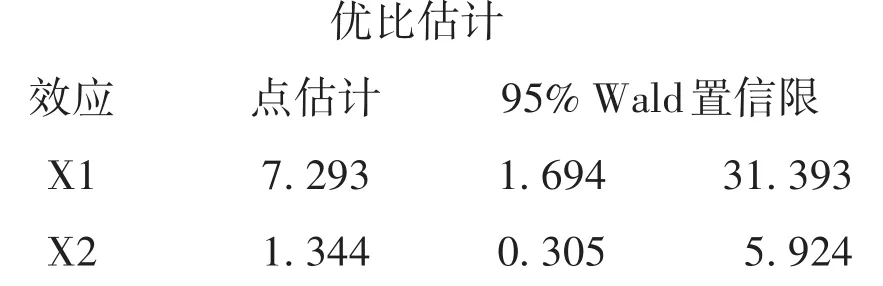
以上输出的是“优比估计”结果,X2的95%Wald置信区间包括“1”,表明X2的两个水平对结果的影响接近相等;X1的,其95%Wald置信区间为[1.694,31.393],未包括“1”,表明X1的两个水平之间对结果的影响是不同的,即“孕妇血中HBV DNA(X1)”为阳性条件下“新生儿出现乙肝病毒宫内感染”的概率是“孕妇血中HBV DNA(X1)”为阴性条件下“新生儿出现乙肝病毒宫内感染”概率的7.293倍。
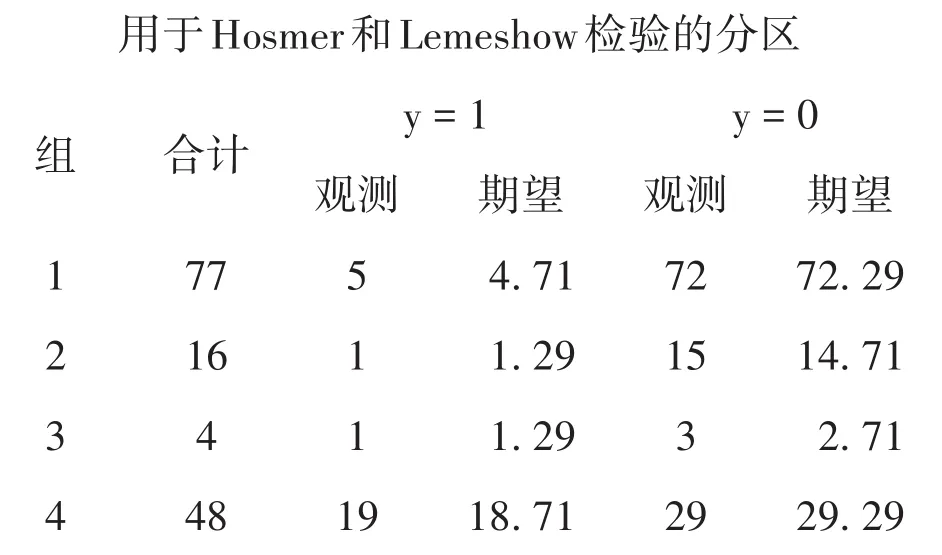
以上输出的是“用于Hosmer和Lemeshow检验的分区”结果,实际上就是将全部资料划分成4个组。

以上输出的是“最大似然估计分析”结果,此结果表明:X2的回归系数与0之间的差别无统计学意义,表明“孕妇血中HbeAg(X2)”是否为“阳性”对“新生儿是否出现乙肝病毒宫内感染”的影响可以忽略不计。要想获得更简洁的回归模型,可以淘汰掉自变量X2后重新拟合logistic回归模型。
【统计结论与专业结论】由多种拟合优度检验结果可知,所拟合的回归模型对资料的拟合效果满意;由回归系数的检验结果可知,孕妇血中HBV DNA(X1)是新生儿乙肝宫内感染的主要影响因素。
7 讨论与小结
7.1 讨论
拟合优度检验与失拟检验在本质上是相同的,都是用来评价某种假设(例如独立性假设或关于资料来自某种分布的假设)是否成立或所拟合的回归模型与资料的吻合程度。其微小差别在于:拟合优度检验一般要求将资料整理成一维频数表或高维频数表资料形式,当检验结果为P>0.05时,表明所做的假设成立或所拟合的回归模型与资料的变化趋势是吻合的;当检验结果为P≤0.05时,表明所做的假设可能不成立或所拟合的回归模型与资料的变化趋势不够吻合;然而,失拟检验一般要求在自变量或自变量向量取特定值的条件下应做多次重复试验,采用失拟检验的目的是揭示资料中所包含的“曲线变化的成分”是否足够多。当检验结果为P>0.05时,表明所拟合的回归模型与资料的变化趋势是吻合的;当检验结果为P≤0.05时,表明所拟合的回归模型与资料的变化趋势不够吻合,分析者需要构建更复杂的回归模型或非线性回归模型。
7.2 小结
本文介绍了9种拟合优度检验方法,它们的主要应用场合是评价广义线性回归模型(包括logistic回归模型)对资料的拟合效果。其中,偏差拟合优度检验和Pearson’s拟合优度检验最常用;Hosmer-Lemeshow拟合优度检验对稀疏资料具有一定的校正作用;当资料的稀疏程度十分严重时,需要使用专门用于稀疏资料的6种拟合优度检验。本文结合一个实例并借助SAS软件实现了全部9种拟合优度检验,对SAS输出结果做了解释,给出了统计结论和专业结论。
