基于嵌入式设备应用的CNN 加速器的设计研究*
2021-10-26王红亮程佳风
王红亮,程佳风
(中北大学电子测量技术国家重点实验室,山西 太原 030051)
近年来,卷积神经网络的使用领域越来越普遍,其模型复杂度不断提升。然而卷积神经网络的运算过程具有高度并行性和重复性的特点,随着网络层数的不断深入,卷积神经网络的计算密集和存储密集特性日益凸显,成为实现快速高效CNN 网络的限制。于是为了提升CNN 的设计性能[1-5],基于GPU,ASIC,FPGA 的不同加速器被相继提出。
基于GPU[6-7]的CNN 加速器能够很好地实现软硬件的结合,促进神经网络训练时的加速效果。然而GPU 的能耗巨大,其硬件结构固定,限制了卷积神经网络在嵌入式设备的应用。与GPU 相比较,ASIC 芯片[8]具有功耗低,体积小,计算性能高的特点,也可以实现对CNN 的加速训练。但ASIC 芯片灵活性极低,开发周期较长,研发成本极高,使得它不适用于结构灵活多变的卷积神经网络。FPGA[9]具备高性能,低功耗,可灵活配置的特点,已有的基于FPGA 的CNN 加速器的研究表明,FPGA 比GPU和CPU 不仅具有更好的加速效果,而且能耗方面也远远低于GPU,但由于FPGA 灵活性差且Verilog HDL 开发门槛较高,开发周期长,在一定程度上限制了FPGA 在人工智能领域运用的普及。因此Xilinx 推出了一种基于高级语言进行FPGA 设计的综合工具。通过引入高层次综合(High-Level Synthesis tool,HLS)工具,在代码生成时可以快速优化FPGA 硬件结构,提高执行效率,降低开发难度,在开发过程中可以快速验证和修改算法,及时查看算法的实际效果,缩短开发周期。
以实现CNN 在嵌入式应用场景下的快速高效部署为目的,设计并实现了一种基于FPGA 的高性能、低功耗、可配置的CNN 加速器。该加速器充分利用FPGA 良好的计算性能和并行性特征,使其获得更好地实时性,同时由于FPGA 实现的加速器能够降低系统功耗,使得卷积神经网络更好地应用到移动设备上。
1 典型的卷积神经网络
采用一种典型的手写数字识别网络CNN LeNet5[10]模型对系统进行测试,模型结构如图1 所示,总共包含6 层网络结构,其中卷积层有2 个,池化层有2 个,全连接层有2 个。网络的输入为28 pixel×28 pixel×1 pixel 大小图片,输入图像依次经过conv1、pool1、conv2、pool2、inner1、relu1、inner2 层后,得到10 个特征值,然后在softmax 分类层中将10 个特征值概率归一化得出最大概率值即为分类结果。网络中的各种参数设置如表1 所示。
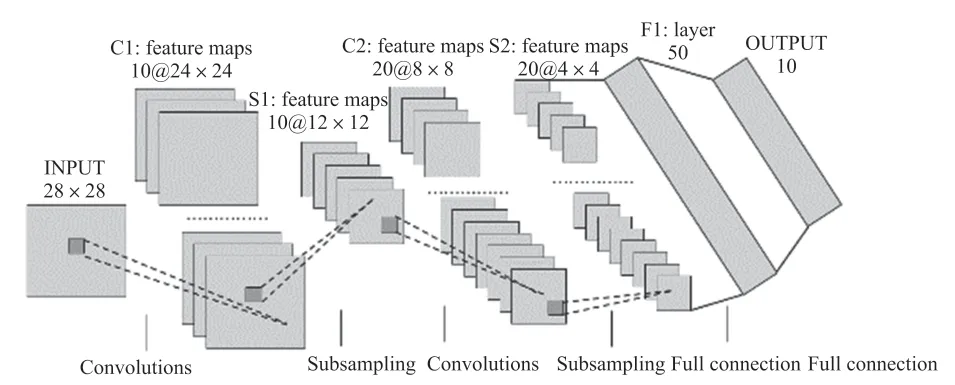
图1 典型的手写数字识别网络结构
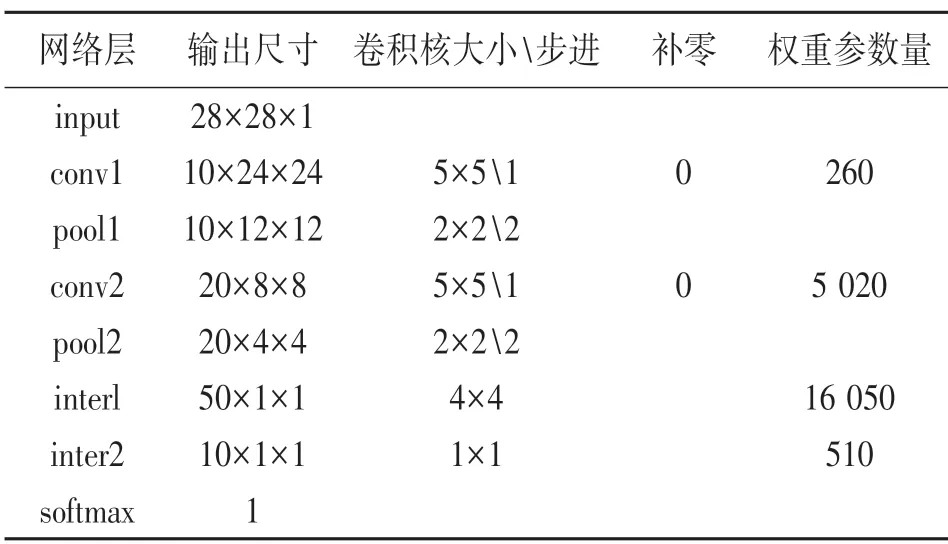
表1 网络参数表
由表1 可以计算出,该CNN 网络总共的权重参数量为260+5 020+16 050+510=21 840 个变量,接下来会对输入特征参数和权重参数等都将进行定点量化,将32 bit 的浮点数定点量化为16 bit 的定点数,因此这21 840 个变量都将用ap_int(16)来存储,将大约消耗43 kB 的存储资源,采用的PYNQZ2 有足够的存储空间用于存放这些变量。
2 高层次综合技术
2.1 HLS 基本原理
高层次综合工具[11](High-Level Synthesis tool,HLS)是Xilinx 在2012 年发布的一套集成于Vivado开发环境的开发工具[12-13],主要目的是用于可编程逻辑器件(比如FPGA)的设计和开发。用户可以通过使用HLS 高层次设计工具来选择多种不同的高级语言(如C,C++,System C)来进行FPGA 的设计,通过仿真、优化及综合等步骤就可以以RTL 代码的形式输出,既可以是网表形式,也可以导出为Xilinx 的IP 核。引入HLS 设计工具,在代码生成时可以快速优化FPGA 硬件结构,提高执行效率,降低开发难度,在开发过程中可以快速验证和修改算法,及时查看算法的实际效果,缩短开发周期。采用HLS 设计的硬件电路具有良好的扩展性,并且开发过程简单,系统的设计使用C 语言就能实现,HLS的开发过程如图2 所示。
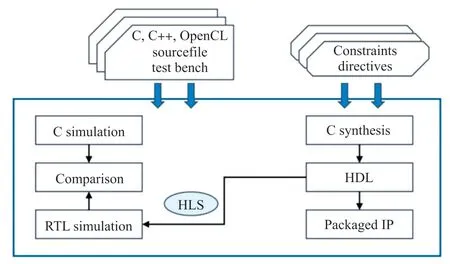
图2 HLS 的开发流程图
2.2 特征、权重参数的定点量化
神经网络的数据量主要集中在卷积层的输入输出以及卷积核的参数,巨大的数据量会占用大量的硬件资源,且FPGA 不擅长浮点运算,为了节约传输成本,依据HLS 工具特有的自定义定点数ap_fixed,只要确定小数点的位置,就可以对数据实现量化。将32 bit 的浮点数量化成16 bit 的定点数,只需要在利用tensorflow 框架训练完整个网络时,对训练完的weights 参数进行最大值量化,计算出小数点的位置。对于特征参数的量化是在测试集中计算出小数点的位置,输出结果如图3 所示。
图3 权重特征的小数点位置
3 加速电路的设计与优化
3.1 卷积运算模块的设计
采用HLS 进行加速器的设计与实现,与传统的硬件电路设计思想不同,HLS 支持以高层次语言进行算法功能的描述,因此设计加速电路的首要任务就是采用软件语言(C/C++)对卷积神经网络各层的计算模型进行实现。卷积层的计算过程已经在前文进行了深入分析,因此基于高层次综合工具设计了一种卷积运算模块,通过C 语言配置CNN 的超参数,如图4 所示:

图4 卷积运算模块的超参数配置
对于不同的CNN 网络只需要输入对应的超参数的值即可完成不同CNN 网络的卷积rule 运算,由此可见此卷积运算模块适用于各种网络结构大小的卷积神经网络运算。
卷积层的计算主要包含4 层循环结构,如图5所示,最内层循环是完成Kx×Ky大小的单层卷积核与输入特征图像相应区域的乘累加运算,第2 层循环是将卷积窗口在整个Hin×Win大小的输入特征图中滑动以提取单层输入图像中的所有特征,第3 层循环遍历所有CHin 个输入通道,第4 层循环遍历不同输入特征通道输出CHout 个输出特征图像。

图5 卷积层计算伪代码
由此设计出的卷积运算通路的过程如图6所示。
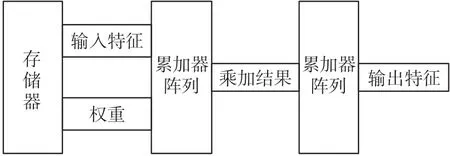
图6 卷积运算通路
3.2 卷积运算模块的优化
3.2.1 卷积运算的分解
由于特征、权重参数都是多维的空间变量,无法在计算机中读取,因此我们要将其展开为一维变量。如下图7 所示,对于特征参数,它在空间中的排布方式为三维变量,因此需要将其展开为一维变量,考虑到FPGA 优秀的并行运算能力,所以在空间中沿输入特征的通道C 将其切割为C/K 个通道,每一个通道可以实现K 路并行的计算且需要的特征存储空间减少,大大提高了加速电路的运算效率和节约了FPGA的存储资源。特征参数经过切割后,它在内存中的排布方式变为了一维变量:[C/K][H][W][K]。
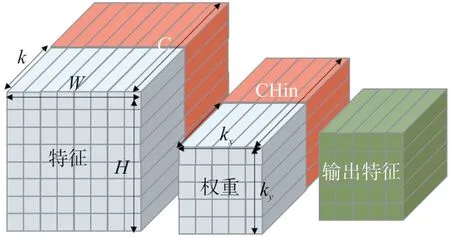
图7 卷积运算的分解
权重参数在空间中的排布方式为四维变量,要将它展开为一维变量,也是对其输入通道CHin 切割为CHin/K 个通道,实现每一个通道的K 路并行,它在内存中的排布方式变为一维变量:[CHout][Ky][Kx][CHin/K][K]。
4 卷积神经网络加速器系统测试与实验结果
4.1 实验测试平台
本设计采用Xilinx 公司推出的PYNQ-Z2 开发板作为测试平台。PYNQ-Z2 采用的是ZYNQ-7020的芯片并且继承了ZYNQ 开发平台的优秀性能。同时,用户可以通过Python 编写代码进行板上开发和测试。
4.2 手写数字识别网络测试
本设计采用图1 所示的手写数字识别网络对设计的通用加速器进行验证和测试,实验分别为CPU软件实现和调用FPGA 硬件加速器进行实现,通过两者对比,分析FPGA 加速器的加速效果和计算精度,同时对加速器的功耗性能进行分析。
4.2.1 手写数字识别网络与MNIST 数据集
本设计所使用的手写数字识别网络是在LeNet-5网络基础上优化改进而来的,其网络规模比LeNet-5略小,以28 pixel×28 pixel 单位大小的灰度图像为输入。本设计在主机端基于Tensorflow 框架采用MNIST 训练集对该网络进行训练,训练完的网络模型在MNIST 数据集上的测试准确率达到98.42%。
4.2.2 实验结果分析
本设计将从识别准确率,加速效果,资源消耗与功耗效率3 个方面对加速器运行手写数字识别网络的结果进行分析,在加速器中一律采用8 重并行运算,即K=8。
(1)识别准确率
为了测试加速器的计算精度,本实验分别记录了基于ARM 纯软件和基于FPGA 硬件加速器实现的手写识别网络在MNIST 测试集上的识别准确率,表2 给出了两者准确率的对比结果。

表2 不同平台的手写数字识别准确率
从表2 中可以发现FPGA 平台实现的手写数字识别准确率要略微低于ARM 软件平台的手写数字识别,这是由于本设计的加速器采用的定点量化的数据格式,因此在准确率方面有略微的下降,这一点点的损失可以忽略不计。
利用Jupyter-notebook 打印部分被正确或错误识别的图片来验证该网络的识别效果。图8 所示的是测试集中被正确识别的图片样例,可以看出这些图片字迹清晰,易于辨认。图9 所示的为被错误识别的样例,可以看出这些被错误识别的图片均字迹潦草,十分容易被混淆。

图8 正确识别的图片样例

图9 错误识别的图片样例
(1)加速效果
为了对比加速器的加速效果,本设计首先在ARM 处理器利用Tensorflow 框架运行手写数字识别网络,然后基于本文所设计的CNN 加速器运行该网络,并记录两种方式识别不同数量手写数字图片所用的时间,运行时间的记录通过调用time.time()函数实现。图10 所示为本设计采用的手写数字识别网络在两种实现方式下的耗时对比情况。
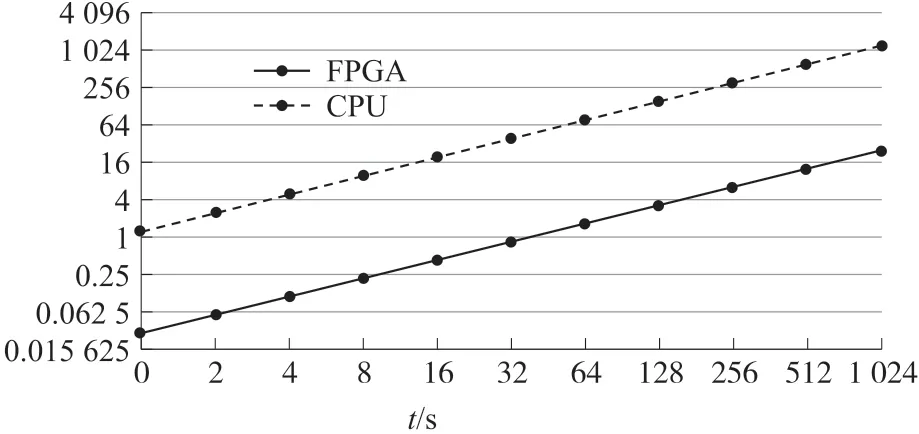
图10 手写数字识别网络耗时情况
从图10 中可以看出,基于FPGA 运行的MNIST网络单张图片耗时约为0.029 s,基于AMR 处理器运行的同一网络单张图片的识别耗时为1.22 s,在单帧图片的处理速度上,本设计实现的通用加速器相对于CPU 纯软件计算实现了42.1 倍的加速效果。加速器实际能够达到的计算速度可通过单位时间内处理的图片帧数(Frame Per Second,FPS)来衡量,其计算方式如式(1)所示。
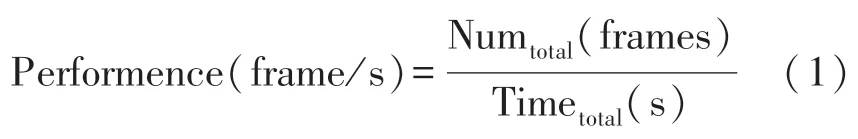
根据通用加速器处理1 024 张图片所用时间,计算可知该加速器计算速度约为37.63 FPS,该计算速度满足实时性要求。
(2)资源利用率与功耗效率
本设计根据Vivado 提供的综合报告对资源利用率与功耗效率进行分析。表3 所示为CNN 加速器在PYNQ-Z2 开发板上实现后占用的资源情况。本设计采用对权重值和特征图像值进行定点量化的方法,因此对BRAM 资源的消耗减少了很多,占用率只有9%。由于卷积网络运算的过程中涉及到了大量的乘法加法运算,因此对FPGA 片上的乘加器阵列计算资源使用率较高,达到了39%,总体看来,所有的资源消耗都是在理想范围之内的。
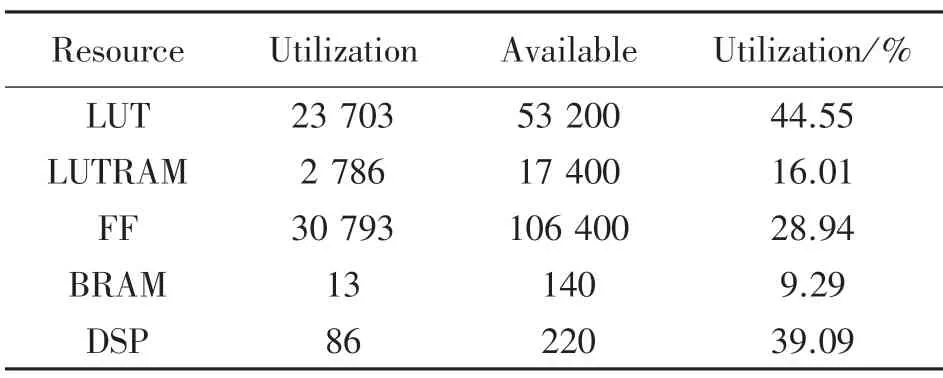
表3 PYNQ-Z2 资源利用情况
图11 为Vivado 提供的功耗分析报告。可以看出,加速器运行时的平均功率约为1.825 W,其中系统动态功耗为1.684 W,约占系统总功耗的92%,静态功耗为0.141 W,约占系统总功耗的8%。PYNQZ2 开发板中ARM 处理器的动态功耗相对更大,约占系统动态功耗的91%,而FPGA 端的加速电路的运行功率只有0.155 W,功耗相对较低。
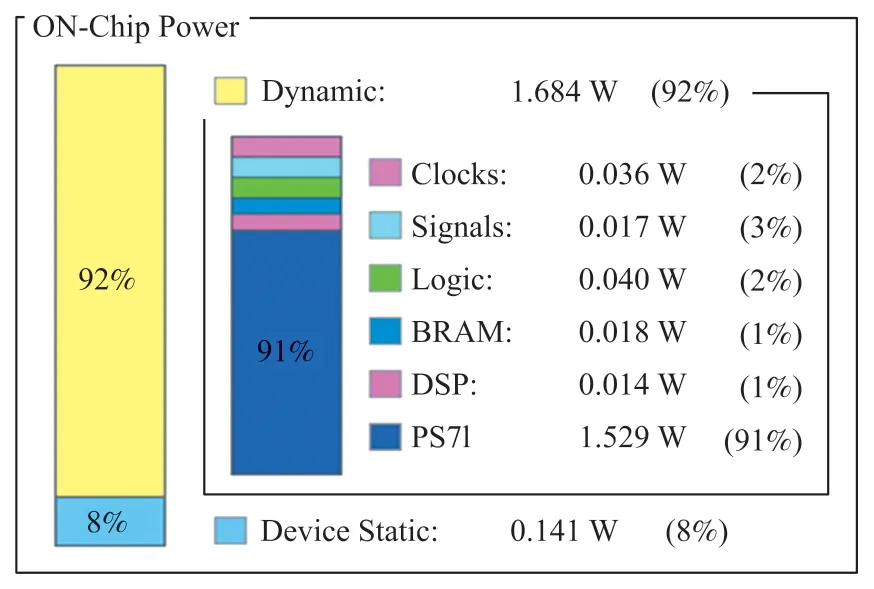
图11 加速器功耗分布
加速器运行的功耗效率可通过单位功耗处理的MNIST 图像帧数来衡量,其计算公式如式(2)所示。
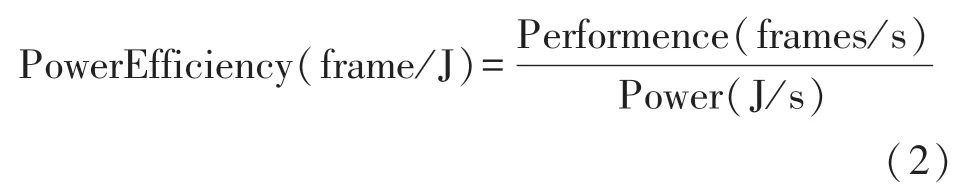
前文提到加速器的处理速度为37.63 FPS,结合加速器运行时的平均功率为1.825 W,换算可知加速器的功耗效率为20.6 frames/J,该功耗效率完全满足嵌入式应用场景下的低功耗设计要求。
5 结束语
提出了一种基于FPGA 的高效可配置的CNN加速器,其中所有层以流水线方式同时工作,以提高系统的吞吐量和性能。为了利用CNN 的并行性,在卷积层采用了多种硬件优化策略,在速度,资源使用和功耗之间取得了良好的平衡。用手写数字识别网络模型进行测试,实验结果表明,在PYNQ-Z2 FPGA 上实现了37.63 FPS 和20.6 frames/J的性能。该设计和验证实验表明,高效可配置的CNN 加速器是CNN 应用在嵌入式设备或移动终端上的最佳选择。
