基于多粒度对抗训练的鲁棒跨语言对话系统
2021-09-28朱军楠宗成庆
向 露 朱军楠 周 玉 ,3 宗成庆
任务型对话系统旨在通过对话交互的方式在有限的回合内帮助用户完成特定的任务,比如导航、订机票等.近年来,对话系统成为学术界和工业界关注的焦点.尤其是端到端任务型对话系统[1-5]引起了研究者广泛的兴趣,此类系统能够接收用户的输入,并直接生成对应的回复.
随着全球化的快速发展和跨境电子商务的普及,跨语言交流变得愈发频繁.在此背景下,开发和部署跨语言的任务型对话系统已成为迫切需求.然而,目前的任务型对话系统主要使用特定的单语数据进行训练.对于一种新的语言,须重新对该语言的对话数据进行收集和标注,这将耗费巨大的成本,同时使得系统的开发周期变长.因此,能否利用已有的单语对话系统构建跨语言系统,成为本文关注的焦点.
近年来,随着深度学习技术的快速发展,机器翻译技术取得了长足的进展,包括谷歌、百度和微软在内的诸多互联网公司都已经部署了各自的开源机器翻译系统,这为跨语言对话系统的构建提供了便利.因此,本文借助已有的机器翻译系统作为不同语言之间的桥梁,提出了 “翻译-对话-回翻”的跨语言对话框架.如图1 所示,该框架包括三个系统:“用户语言(中)-源语言(英)”的机器翻译系统、“源语言(英)”的对话系统和 “源语言(英)-用户语言(中)”的机器翻译系统.其工作流程包括三个步骤:1) 翻译步骤,即采用 “用户语言-源语言”机器翻译系统将用户的输入翻译成对话系统所支持的语言;2) 对话步骤,即对话系统根据步骤 1) 转换得到的源语言句子生成回复;3) 回翻步骤,即采用 “源语言-用户语言”机器翻译系统将系统生成的源语言回复翻译至用户语言以反馈给用户.
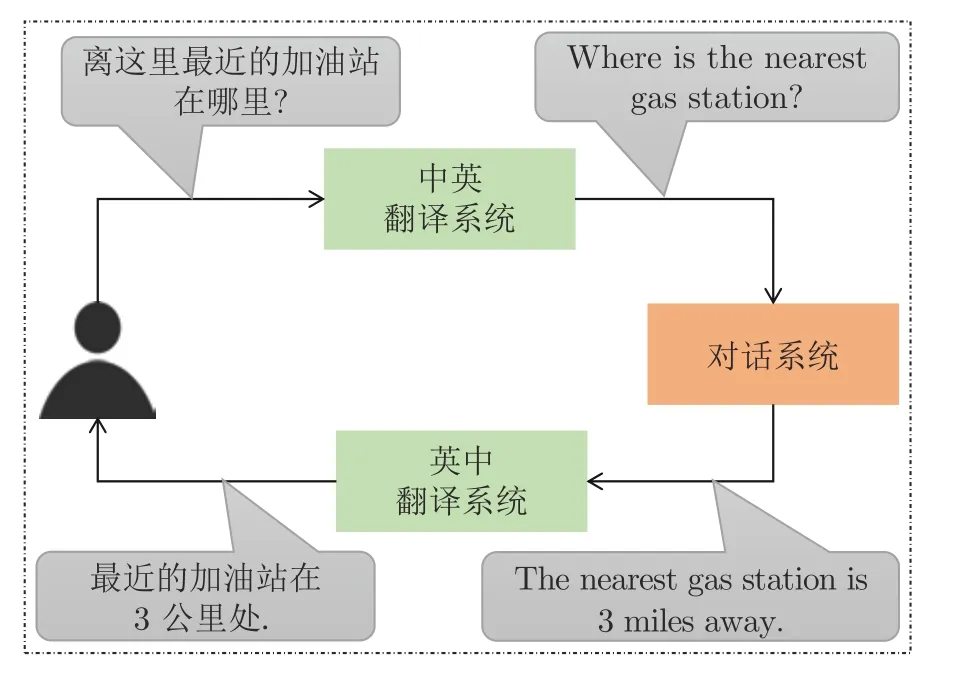
图1 基于机器翻译的跨语言对话系统Fig.1 Machine translation based cross-lingual dialogue system
本文所提出的跨语言对话框架可以充分利用现有的翻译系统和单语对话数据,无须重新标注数据即可将单语的对话系统扩展至多种语言,便于实际开发与部署.
然而,当 “用户语言-源语言”缺乏机器翻译平行数据或机器翻译平行数据的领域与任务型对话的领域存在显著差异时,机器翻译系统的结果不可避免地会引入各种干扰和错误.原始的对话系统通常是在干净数据上进行训练的,无法有效地处理机器翻译系统所引入的噪声,从而严重制约跨语言对话系统的质量.事实上,许多研究表明,大多数神经网络系统对输入的变化十分敏感,微小的输入扰动可能会引起较大的输出差异[6-9].因此,构建面向由机器翻译所引入噪声的鲁棒性跨语言对话系统,对于提升跨语言对话服务的性能至关重要.
针对上述问题,本文提出了一种基于多粒度对抗训练的鲁棒跨语言对话系统构建方法,以提升跨语言对话系统对于多粒度翻译噪声数据的鲁棒性.具体地,该方法首先利用 “翻译-回翻”的方式,构造了词汇、短语、句子三种粒度的噪声对抗样本.之后,该方法利用对抗训练的方式学习噪声无关的隐层向量表示,进而提升对话系统应对翻译系统所引入噪声的能力.本文提出的方法在 “中文到英语”和“德语到英语”两种语言对上开展了实验,实验结果表明本文所提方法能够在保持源语言性能的情况下,显著提升跨语言场景下对话系统的性能.
1 相关工作
1.1 任务型对话系统
任务型对话系统旨在通过对话交互帮助用户完成特定任务.根据实现方式的不同,现有的任务型对话系统可以分为两类:基于管道的系统和基于端到端的系统.基于管道的系统[10-11]由自然语言理解模块(Spoken language understanding,SLU)[12-13]、对话管理模块[14-16]和语言生成模块[17]组成,每个模块单独设计,成本较高且存在误差传递.为缓解管道式系统的缺点,研究人员提出了多种端到端对话系统[18-21].其中,Lei 等[21]提出了一种简化的序列到序列的对话模型(Two stage copynet,TSCP),其核心思想是对上下文编码后分为两步进行解码.该模型第一步根据上下文解码出每个语义槽的对话状态,第二步根据上下文以及前一步解码出的对话状态解码出系统回复.这种两阶段解码方式简化了对话状态追踪模块(Dialogue state tracking,DST),取得了较好的对话生成效果.本文将使用TSCP 作为图1 所示跨语言对话框架中的单语对话系统.
1.2 跨语言对话系统
目前的跨语言对话系统相关研究主要集中于管道式对话系统中某些模块的跨语言迁移.针对SLU 模块的迁移,García 等[22]和Calvo 等[23-24]提出通过不同的策略利用机器翻译系统将源语言的SLU数据转换成目标语言训练数据,从而训练相应的SLU 系统.Bai 等[25]使用强化学习进一步提升了SLU的语言迁移能力.除此之外,Chen 等[26]也对DST 的跨语言迁移问题展开了研究,并提出了一种用于DST跨语言迁移学习的 “教师-学生”框架.Schuster 等[27]则提出了一个多语言意图识别和语义槽填充数据集,并探索了从资源充足语言迁移到资源稀少语言的不同策略.上述工作只关注对话系统的个别模块,而本文着眼于整个跨语言对话系统的构建,直接使用机器翻译系统将用户话语翻译成目标语言,然后与对话系统进行交互.
1.3 对抗学习
基于对抗学习提升系统鲁棒性的方法已经被应用于多个自然语言处理任务,包括文本分类[28-29]、机器翻译[30-32]、对话生成[33]等.其基本思想是通过构造对抗样本对已训练完备的网络进行攻击,从而调整网络参数以提高鲁棒性,使网络能够抵抗这些攻击.Belinkov 等[30]通过在训练数据中引入对抗样本提升基于字符级别的翻译模型的鲁棒性.在对话领域,Tong 等[34]探讨了生成式任务型对话系统的敏感性和稳定性问题.他们通过不同的策略生成对抗样本,包括随机交换、去掉停用词、数据级改写、生成式改写、语法错误等,实验结果证明利用对抗样本进行训练不仅可以提高原始模型的鲁棒性,还可以提升在原始数据上的性能.不同于上述方法,本文所提方法能够构建面向特定翻译系统的噪声,并利用对抗学习提升对话系统的鲁棒性.
2 背景介绍
本文将TSCP[21]作为图1 中的单语对话系统来评估所提方法的有效性.该系统的框架如图2 所示.TSCP 提出了信念跨度(Belief span)以记录对话系统每一轮的对话状态.在此基础上,TSCP 将任务型对话系统拆分为信念跨度生成和回复生成两个任务,并通过一个序列到序列模型(Sequence to sequence,seq2seq)实现.具体而言,TSCP 将解码划分为两阶段.在第一个阶段,生成一个信念跨度,以便于同知识库进行交互,这一阶段对应着对话状态追踪,即根据上下文解码出每个语义槽的对话状态.之后在第二个阶段生成机器回复,即根据上下文及知识库检索结果解码出系统回复.
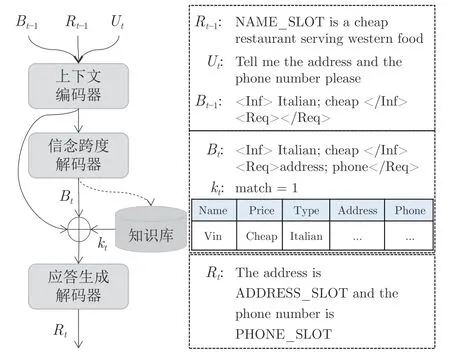
图2 TSCP 框架Fig.2 TSCP framework
一个多轮对话可以表示为{(B0R0U1;B1R1);(B1R1U2;B2R2);···;(Bt-1Rt-1Ut;Bt Rt)},其中Bt表示第t轮对话的状态追踪,即当前所涉及的所有语义槽信息,Bt仅由模型使用,对用户不可见;Ut表示第t轮用户的输入;Rt为第t轮系统的回复;B0和R0初始化为空序列.
TSCP 的两阶段解码可形式化表示如下:
第一阶段,使用信念跨度Bt-1、系统回复Rt-1和当前用户的输入Ut,解码生成当前的信念跨度Bt并对知识库进行搜索,如式(1)所示
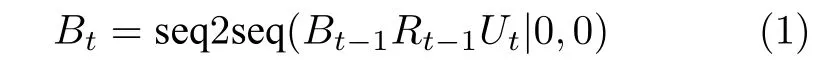
第二阶段,根据知识库搜索结果kt与解码所得的信念跨度Bt对机器回复进行解码,如式(2)所示
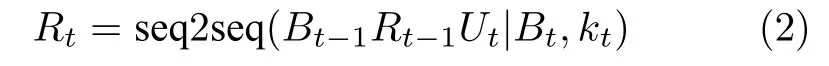
在具体实现的过程中,使用两阶段CopyNet[35]实现,以允许在生成信念跨度和机器回复时可以直接对输入端的关键信息进行复制.
3 本文方法
为提升跨语言场景下对话系统对机器翻译步骤所引入噪声的鲁棒性,本文提出了一种基于多粒度对抗训练的鲁棒跨语言对话系统构建方法.具体而言,该方法包括多粒度对抗样本的构造和对抗训练两步.
3.1 多粒度对抗样本构造
在跨语言场景下,对话系统所接收到的用户输入Ut是经过机器翻译系统处理后的结果.然而,翻译过程难免会引入一些噪声,使得对话系统的性能受到一定程度的制约.为缓解该问题,本文将干净的对话训练数据转换为包含机器翻译噪声的带噪数据,从而使得对话系统能够学习如何处理噪声.
本文使用 “翻译-回翻”技术生成包含翻译噪声的对话数据.假设对话系统所支持的语言定义为源语言S,用户所使用的语言定义为用户语言T,对话系统的训练数据记作XS.首先,我们使用一个S →T的机器翻译系统将训练数据XS从语言S翻译至语言T,之后使用一个T→S的机器翻译系统进行反向翻译,所获得的数据记作.通过这种方法,可以生成一组数据.由于是由翻译系统生成的,与原始数据XS相比,其中便引入了机器翻译系统的噪声和误差.该数据是直接通过对句子级进行翻译再回翻构造的,因此本文将这类数据记为句子级对抗样本.
仅生成句子级对抗样本在噪声类型和数据多样性上是不够的,在很多情况下,噪声的粒度是短语或词汇级别的.因此,本文构造了词汇级对抗样本和短语级对抗样本.具体的构造方法如图3 所示,其中MT 表示机器翻译系统,LS表示源语言句子,LT表示利用机器翻译系统将LS进行翻译得到的用户语言句子,表示利用机器翻译系统对LT进行回翻得到的句子.该框架分为两步:第一步,借助机器翻译系统和词对齐,构造词汇和短语两种粒度的噪声;第二步,利用构造的噪声及对话系统训练数据生成词汇级和短语级两种粒度的对抗样本.
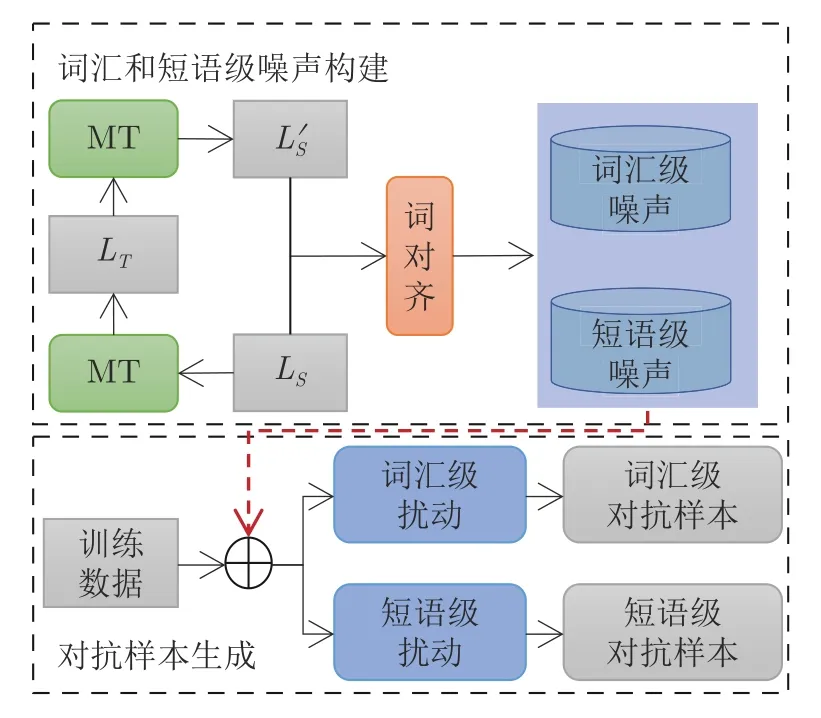
图3 词汇级和短语级对抗样本生成框架Fig.3 The framework of word-level and phrase-level adversarial examples generation
词汇和短语级噪声构建.给定LS中的一个句子x={w1,w2,···,wn},首先利用机器翻译将其翻译至用户语言,之后再利用机器翻译将该句子回翻至源语言,从而获取一批句对{ (x,x′)},其中x′包含了机器翻译过程可能对原始句子x产生的变化.
本文借助统计机器翻译的思想,利用{(x,x′)}构造词汇级、短语级两种粒度的噪声.
对抗样本生成.在得到词汇噪声和短语噪声后,本文利用上述噪声生成对应的对抗样本,具体生成方法如下.
1) 词汇级对抗样本.本文使用词汇级噪声对原始用户话语中的词汇进行替换,从而在词汇层面产生包含翻译噪声的用户话语.为了保证替换之后生成的用户话语语义不会发生改变,本文只允许对除了限定词(如the、a、an、some、most、any、every)、人称代词(如she、hers、herself、he、him、himself、it)和情态动词(如can、cannot、could、couldn't、must)之外的词进行替换.这主要是因为替换限定词、人称代词和情态动词很容易导致陈述不一致甚至语义发生变化.对于其他词汇,将从词汇级噪声中查找其对应的噪声词汇.对于每个用户话语,随机抽取一个满足替换规则的单词,并随机从噪声词汇中选择一个单词对该单词进行替换,例如将 “thenearestgrocery”替换成 “theclosestgrocery”.这样可以为训练数据中的每个原始语句随机生成多个包含翻译噪声的用户话语.
2) 短语级对抗样本.类似于词汇级对抗样本生成,本文使用短语级噪声对原始用户话语中的短语进行替换,从而在短语层面产生包含翻译噪声的用户话语.对于用户话语,我们在短语级噪声中查找用户话语中的N元组(N-gram)及其对应的噪声短语.对于用户话语中的每个N元组,随机抽取一个满足替换规则的片段,并从候选噪声短语中随机选择一个短语替换它,例如将 “where′s the nearestparking garage”替换成 “whereis the latest car park site”.
总体而言,本文所提多粒度对抗样本构造方法如算法1 所示.

图4 展示了一个多粒度对抗样本实例,包括词汇级对抗样本、短语级对抗样本和句子级对抗样本.由该实例可以看出,通过本文所提的多粒度对抗样本生成方法可以在词汇、短语、句子级别生成更加丰富多样的对抗样本,从而为后续增强模型鲁棒性奠定数据基础.

图4 多粒度对抗样本实例Fig.4 An example of multi-granularity adversarial examples
3.2 对抗训练
在得到对抗样本后,本文须利用上述对抗样本提升跨语言对话系统的鲁棒性.图5 给出了本文所提对抗训练的示意图.给定干净上下文x和包含扰动的上下文x′,对抗训练旨在使得上下文编码器输出的隐层向量Hx和Hx′能够尽量相似,同时要求解码器端能够输出相同的信念跨度和应答语句.

图5 对抗训练结构框图Fig.5 The structure of adversarial training
具体的对抗训练优化目标如下:

其中,Lclean是对话系统原始的训练目标,当输入干净上下文x时,解码器能够生成正确的信念跨度和应答语句;Lnoise则是包含扰动的上下文x′及其对应的信念跨度和应答语句之间的损失;Ladv则是鼓励上下文编码器能够生成尽量一致的隐层向量.
上下文编码器作为生成器G,引入一个判别器D来区分Hx和Hx′.上下文编码器的目标是针对x和x′生成尽量相似的隐层向量,以混淆判别器D,而判别器D则尽量去区分这两种隐层向量表示.G和D通过极小化极大算法进行训练,其优化目标为:

本文采用多层感知机作为判别器,判别器根据输入的隐层向量输出分类分数,并尝试将D(G(x))最大化,将D(G(x′)) 最小化.G和D的最终训练目标是使得编码器可以针对干净数据x和噪声数据x′进行相似编码表示,从而使得判别器D无法区分干净数据和噪声数据的隐层向量表示.
本文在两种测试场景下(如图6 所示)对所提方法的有效性进行验证:1) 跨语言测试 (Crosstest),在这种场景下,对话系统接收通过机器翻译系统翻译之后的语句作为输入,以评估对抗训练是否能够让对话模型更加鲁棒;2) 源语言干净测试(Mono-test),在这种场景下,对话系统接收原始干净测试数据作为输入,并评估对抗训练是否能使得模型在源语言干净测试数据上具备更好的性能表现.整体而言,本文的目标是提升跨语言对话系统的鲁棒性,而该目标是以不损害对话系统在干净数据上的性能为前提.本文认为不应该以降低在源语言上的系统性能为代价实现跨语言场景下的鲁棒性提升.因此,本文旨在构造一个能够满足包括源语言及机器翻译系统所支持的其他语言需求的对话系统.

图6 两种测试Fig.6 Two kinds of test
4 实验
4.1 实验设置
对话数据集.本文在CamRest676[3]和KVRET[18]两个公开的任务型对话数据集上对本文所提方法进行评估.其中,CamRest676 包含了餐馆预定单一领域的676 个对话;而KVRET 则是一个多领域的多轮对话数据集,包括日程规划、天气信息查询和导航三个领域.本文遵循原始论文中的数据划分方式,数据的详细信息见表1.

表1 数据集统计信息Table 1 Statistics of datasets
为进行跨语言实验,本文通过人工的方式将CamRest676 和KVRET 的测试集翻译成中文.此外,为验证在其他语言对上的有效性,本文还将KVRET 的测试集翻译至德语.为进一步开展实验,本文需要与上述两种语言对相对应的机器翻译系统,包括中英和德英双向翻译系统.
对话模型.本文使用Lei 等[21]提出的TSCP 作为单语基线对话系统.隐层向量和词向量的维度d均设置为50 维.CamRest676 和KVRET 的词表规模|V|分别为800 和1 400,min-batch 设置为32.本文使用Adam[38]优化器进行模型的参数更新,其学习率为0.003,衰减参数为0.5.在解码过程中,CamRest676 和KVRET 均采用贪婪搜索策略(Greedy search).在训练过程中采用提前终止法(Early stopping)提高训练效率,在每一轮迭代过程中对上下文编码器和判别器的参数进行同步更新.对抗性训练过程中,CamRest676 和KVRET使用的词表规模分别设置为1 800 和2 500.经过在验证集上调参,CamRest676 和KVRET 上对抗训练的超参数λ分别设置为0.2 和0.1.
机器翻译系统.本文需要机器翻译系统将用户输入从用户语言翻译至源语言,从而与对话系统进行交互.此外还需要利用机器翻译系统构造三种粒度的噪声对抗样本.本文使用大约包含210 万句对的LDC (Linguistic data consortium)双语训练数据对中英翻译系统(ZH→EN) 和英中翻译系统(EN→ZH)进行训练;使用大约包含200 万句对的德英双语训练数据对德英翻译系统(DE→EN)和英德翻译系统(EN→DE)进行训练.上述翻译系统均使用字节对编码 (Byte pair encoding,BPE) 技术对训练数据进行切分,学习30000 个融合操作,然后分别限制词表为频次最高的前30000 个亚词.所有系统均采用transformer_base 设置.
评价指标.本文使用实体匹配率(Entity match rate,mat.)、成功率F1(SuccessF1) 和BLEU作为对话系统的三种自动评价指标.同时,与Mehri 等[39]类似,本文使用一个组合分数(combined score) 作为总体评价指标.该指标计算公式为:
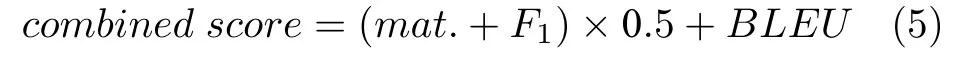
4.2 实验结果
中到英的跨语言实验.为生成对抗样本,首先需要构造对应粒度的噪声.本文使用大约包含80万句英语口语的数据集构造词汇级和短语级噪声.在词对齐之后,保留双向词汇翻译概率均大于0.01的词对作为词汇级噪声,保留满足条件的短语对及双向短语翻译概率均大于0.01 的短语对作为短语级噪声.对于句子级噪声,则直接将对话训练数据中的用户话语通过翻译系统翻译再回翻生成.本文使用以下几种方法进行实验对比.
1)随机交换:通过随机交换句子中两个相邻词的位置生成对抗样本,如 “Where is the nearest gas station?”和 “Where is the gas nearest station?”;
2)停用词:通过删除句子中的停用词生成对抗样本;
3)同义词:通过同义词典中的同义词替换句子中的词生成对抗样本,本文使用WordNet 查找同义词.
表2 和表3 分别给出了使用不同方法生成的对抗样本在CamRest676 和KVRET 上的Cross-test和Mono-test 的实验结果.通过该实验结果,可以得出以下结论.
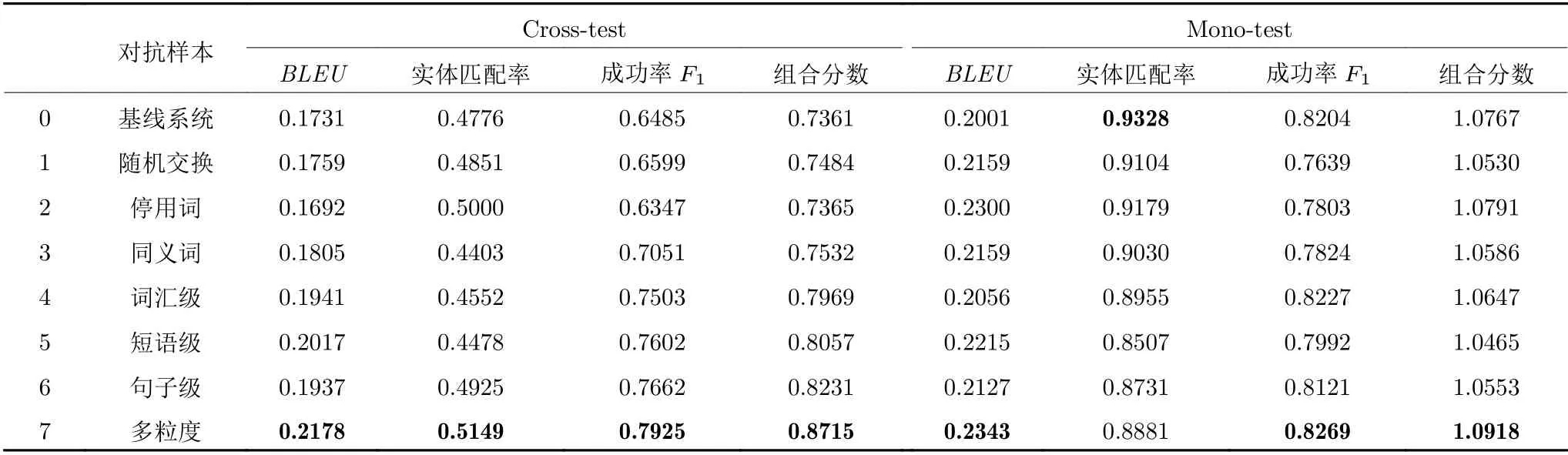
表2 CamRest676 数据集上的实验结果Table 2 Experimental results on CamRest676

表3 KVRET 数据集上的实验结果Table 3 Experimental results on KVRET
1) 机器翻译的噪声对于对话系统性能的影响很大.通过表2 和表3 中基线系统在跨语言测试集和源语言测试集上的性能表现(表2 第0 行和表3第0 行),可以发现当使用机器翻译作为桥梁翻译用户语句,再输入到对话系统后,对话系统的性能下降明显.在CamRest676 上,对话系统的性能从1.0767下降至0.7361;在KVRET 上,对话系统性能从1.0034下降至0.7382.
2) 本文方法能够生成与翻译噪声更相关的对抗样本,对于对话系统性能的提升更加明显.在CamRest676 上,相比于随机交换、停用词、同义词,本文方法在跨语言测试集上的效果提升更加显著(表2 第1~3 行和第4~6 行),最高可提升至0.8231.在KVRET 上也有相同的效果(表3 第1~3行和第4~6 行).当将词汇-短语-句子三种级别的对抗样本集成训练后,对话系统在跨语言测试集上取得了最佳效果(表2 第7 行和表3 第7 行).
3) 本文方法不仅可以提升对话系统处理跨语言输入的性能,在源语言上还能取得与原始系统相当的水平.在某些情况下,还能超过原始系统处理源语言的性能.在CamRest676 上,使用三种级别对抗样本集成训练后,对话系统的性能可从1.0767提升至1.0918 (表2 第0 行和第7 行).在KVRET上,使用三种级别对抗样本集成训练后,相较于原始系统,对话系统性能均有一定提升,最高可从1.0034 提升至1.0431.
德到英的跨语言实验.本文在KVRET 数据集上还进行了德语至英语的跨语言实验,实验结果如表4 所示.实验设置与中文到英语的设置相同.通过实验结果可以看出,德语到英语的跨语言性能与中文到英语的性能具有相同的趋势.使用本文提出的三种粒度的对抗样本,可以显著提升对话系统在跨语言场景下的性能,同时还能保证对话系统在源语言上的性能.
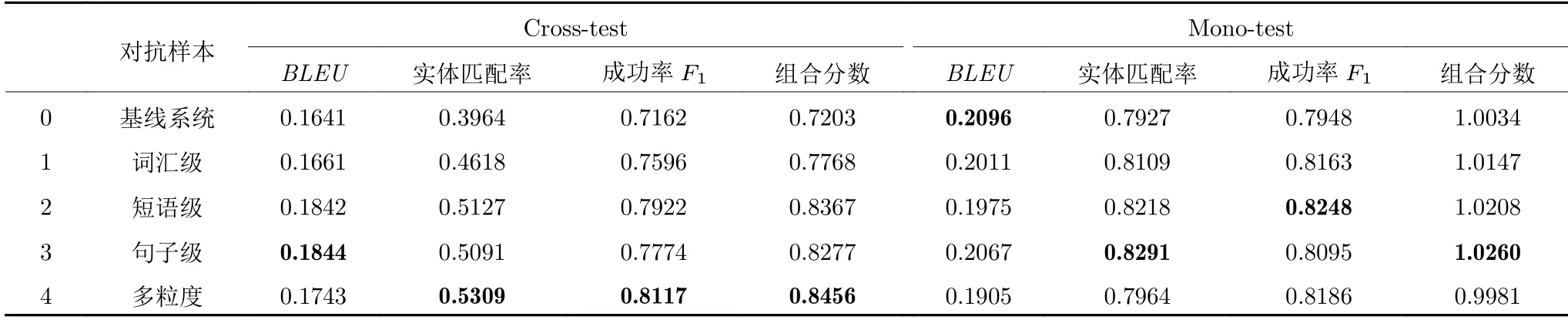
表4 KVRET 数据集上德到英的跨语言实验结果Table 4 Cross-lingual experimental results from German to English on KVRET
跨语言对话实验结果实例分析.表5 展示了三个中文到英语的跨语言对话实验结果实例,其中实例1 来自CamRest676 数据集,实例2 和实例3 来自KVRET 数据集.表5 分别展示了这三个实例在基线系统和本文所提多粒度方法上的跨语言实验结果(Cross-test)和源语言实验结果(Mono-test).在跨语言实验中,用户输入中文话语,经过翻译系统翻译成英语话语后,输入到英语单语对话系统中与对话系统进行交互,生成回复.从这三个实例可以看出,机器翻译的过程会引入一些噪声,使得对话系统无法正常工作.比如实例1 中,机器翻译系统将用户话语中的 “价位适中”翻译成 “appropriate price”,而基线对话系统能够处理的是 “moderately priced”,当输入翻译系统生成的用户话语后,对话系统不能正常回复.使用本文所提多粒度对抗训练方法更新对话系统后,由于从词汇-短语-句子三个粒度构造了面向机器翻译噪声的对抗样本,使得对话系统能够更好地处理由机器翻译引入的噪声.除此之外,我们可以发现,本文所提方法还能一定程度上提升对话系统生成回复的质量(实例1 和实例3).

表5 跨语言对话实验结果实例Table 5 Examples of cross-lingual experimental results
翻译系统累计错误分析.对话系统接受翻译系统的翻译结果作为输入并生成回复.为对比翻译噪声对于对话系统性能的影响,本文利用CamRest676测试集对翻译系统引入的噪声进行了详细分析.从CamRest676 测试集中随机选取60 个对话数据,人工分析了英语测试集和经过中英翻译系统翻译生成的英语测试集之间的区别,以及这些区别对于对话系统性能的影响.这60 个对话总共包含241 轮用户输入,去掉用户表示感谢的轮数之后,本文总共分析了177 轮.通过对数据集进行分析,将翻译现象归类为以下4 种类别.表6 分别给出了类别1、类别2 和类别3 的实例.
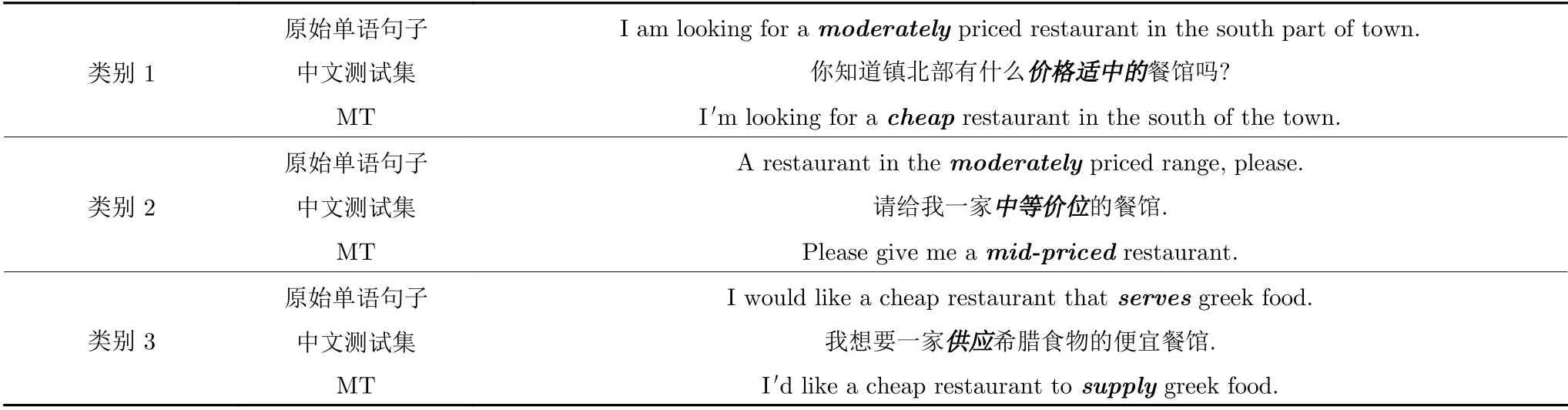
表6 翻译现象类别实例Table 6 Categories of translation phenomena
类别1:关键词语义错误.这里关键词指的是与对话系统信念跨度相关的词汇.
类别2:关键词表达不一致.
类别3:未登录非关键词.这里的未登录非关键词指的是当关键词翻译正确时,不在基线系统词表中的词.
类别4:其他.
本文对177 轮经过机器翻译系统翻译之后的用户话语进行分析,该数据在以上4 种类别上的分布情况如表7 所示.

表7 翻译系统噪声类型分析Table 7 Noise type analysis of machine translation
基线系统和本文所提多粒度方法在这4 个类别上的性能如表8 所示.从基线系统在跨语言测试和源语言测试上的表现可以发现,这4 个类别的翻译现象对于单语对话系统的性能都是有影响的.根据性能下降的程度可以发现,类别1 的影响 > 类别2的影响 > 类别3 的影响 > 类别4 的影响.这主要是由于关键词对于信念跨度和回复生成都非常重要,关键词翻译错误会导致对话系统难以正常工作.而类别3 性能下降的主要原因是这些非关键词是未登录词,也会对单语对话系统的性能造成一定的影响.
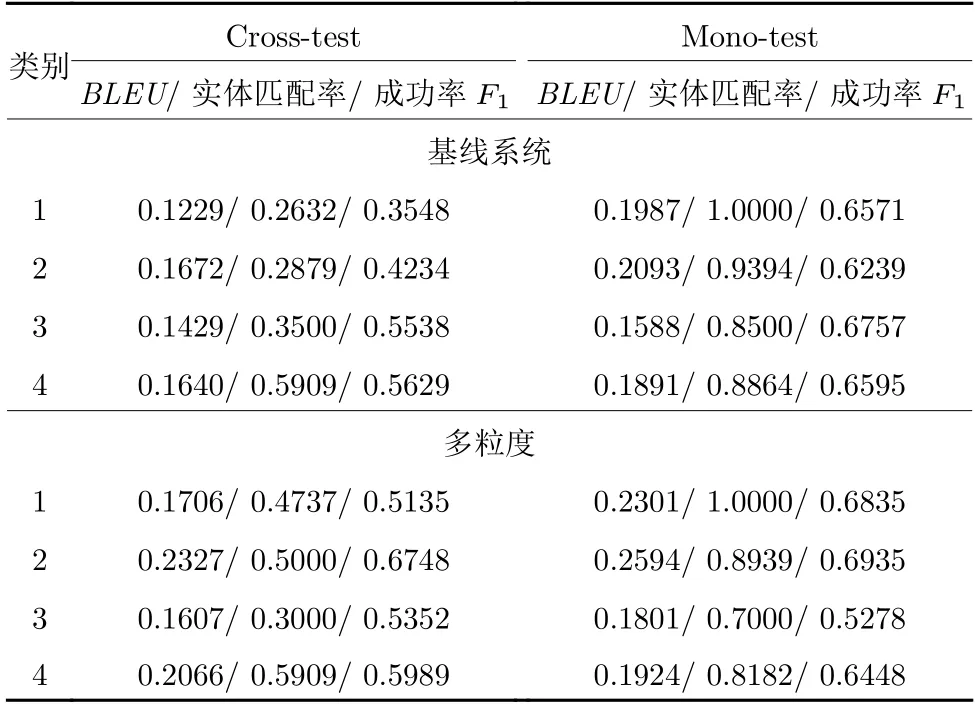
表8 4 种翻译现象上的实验结果Table 8 Experimental results on four translation phenomena
从本文所提方法的实验结果可以看出,本文所提方法主要提升了类别1 和类别2 的性能,而这两种类别也是对对话系统性能影响最大的.后续可以通过有针对性地生成更多的多粒度对抗样本来提升对话系统处理类别3 和类别4 的能力.因此,本文所提多粒度对抗训练方法主要通过在词、短语、句子三个粒度生成针对机器翻译噪声的对抗样本,并利用对抗样本更新对话系统,使得对话系统能够更好地处理由翻译系统翻译生成的话语.
4.3 扩展实验
在之前的实验中,本文利用TSCP 作为单语基线对话系统进行实验,验证了本文所提出的多粒度对抗样本及对抗训练的有效性.为进一步验证本文所提方法的有效性,本文还使用了以下两个端到端任务型对话系统作为单语基线对话系统进行实验.
1) SEDST[40]:该模型与TSCP 具有相同的模型结构.所不同的是,该模型对信念跨度的训练引入了后验正则化,使得状态追踪的训练更加稳定.
2) LABES-S2S[41]:该模型是一个概率对话模型,其中信念状态(Belief states)使用离散隐变量进行表示,并与系统响应进行联合建模.具体实现过程中,使用了两阶段序列到序列方法.
本文在CamRest676 数据集上进行了中文到英语的跨语言实验,实验结果如表9 所示.其中,第0行和第1 行显示的是使用SEDST 作为单语基线对话系统的实验结果,第2 行和第3 行显示的是使用LABES-S2S 作为单语基线对话系统的实验结果.实验结果表明,使用本文提出的三种粒度的对抗样本,可以显著提升对话系统在跨语言场景下的性能,同时还能保证对话系统在源语言上的性能.

表9 CamRest676 数据集上使用其他单语基线对话系统的跨语言实验结果Table 9 Cross-lingual experimental results using other monolingual baseline dialogue systems on CamRest676
5 结束语
本文提出了面向跨语言对话系统的多粒度对抗训练的方法,通过机器翻译系统和源语言对话数据构造词汇-短语-句子三种粒度的噪声数据,并利用对抗训练提升对话系统在跨语言场景下的鲁棒性.在CamRest676 和KVRET 数据集上的实验结果验证了本文所提方法的有效性,本文方法不仅可以提升对话系统在跨语言场景下的鲁棒性,还能提升对话系统在干净数据下的性能.
