汽油在线调合配方优化技术研究进展
2021-08-27张立博王雁君邱建章
张立博,张 蕾,王雁君,邱建章,房 韡
(中国石化 石油化工科学研究院,北京 100083)
随着环保要求日趋严格,我国汽油标准已升级到国Ⅵ,除辛烷值和硫含量外,对烯烃、芳烃等的含量均有更严格的要求。国内炼厂汽油池主要包括催化裂化精制汽油、重整汽油、烷基化汽油、甲基叔丁基醚(MТBE)、抽余油和石脑油等组分,如何利用现有组分降低成本,最大限度实现汽油质量指标卡边控制及提高一次调合成功率,是炼厂汽油调合技术的发展目标。
早期,多数炼厂采用罐调方式进行汽油调合,整个调合过程复杂耗时,且一次调合的成功率低。在线调合技术基于管道调合工艺,结合在线调合优化控制技术和在线分析技术,能减少调合罐数量,调合组分可以在线互补,精准控制调合比例,可同时调合多牌号产品,且一次调合的成功率高,弥补了罐调方式的不足。目前,罐调技术已逐步被在线调合技术所取代。国外多家公司的汽油在线调合技术已在国内炼厂成功实施,如美国Honeуwell公司、日本Yokogawa公司、英国AVEVA公司等[1-5]。Yokogawa公司开发的汽油在线调合系统可自动进行批量管道调合操作,实现配方优化功能和产品质量属性控制[3]。Honeуwell公司的 SуmphoniteТMBLEND汽油调合系统使用非线性求解算法,可进行多周期优化[4]。国内部分炼厂的仪表自动化基础较差,基础设施与国外软件功能设计不匹配,难以实现国外软件的全部功能。而且部分炼厂加工原油的种类和汽油组分生产工艺变化频繁,调合模型后期维护量大,维护费用高。因此,国外软件在国内市场面临移植性差、长周期运行维护成本高等难题[6]。中国石化石油化工科学研究院(简称石科院)、中国科学院自动化所、浙江中控技术股份有限公司等单位自主研发的在线调合技术基于国内炼厂的实际情况,可实现离线调合和在线调合功能,提供多产品、多牌号、多周期的调合计划和调度优化,已在国内多家炼厂应用[7-10]。虽然国内外汽油在线调合技术已实现工业应用,但均面临调合模型维护频繁等难题,调合系统难以实时获取最优调合配方。汽油在线调合技术的关键在于如何准确快速地获取最优调合配方,而配方优化过程主要受调合规则和调合过程模型的优化求解影响。
本文从经验回归到分子水平介绍了核心调合规则——辛烷值非线性调合规则的发展历程,从传统的梯度信息化求解到启发式求解,阐述了调合过程模型优化求解方法的研究进展。
1 汽油在线调合系统
汽油在线调合系统包括汽油在线质量分析、调合优化与控制、管道调合工艺设备与仪表控制等子系统,汽油在线调合系统的示意图见图1。
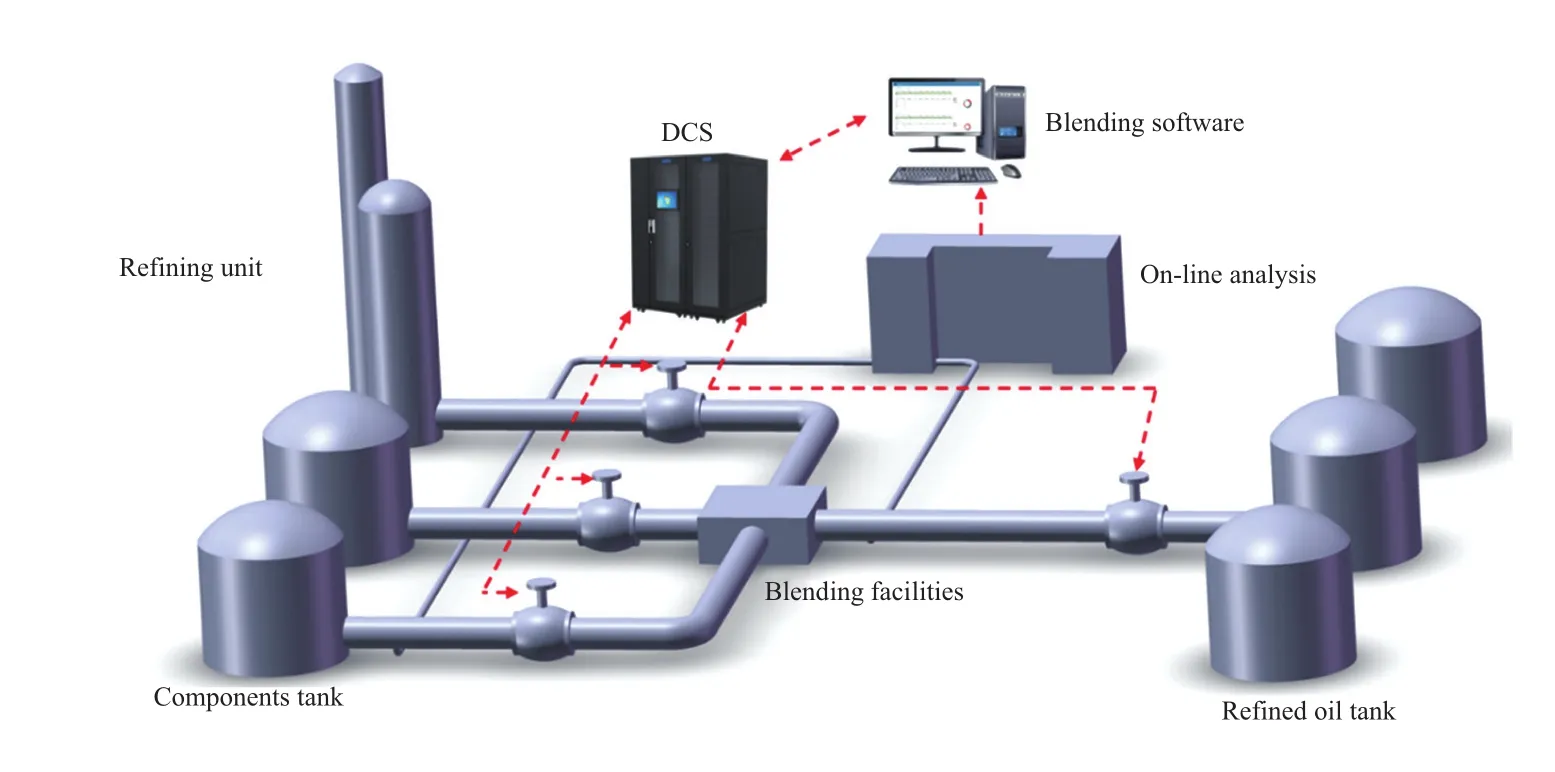
图1 汽油在线调合系统的示意图Fig.1 Тhe gasoline on-line blending sуstem.
调合组分油通过输油管道在调合头(静态混合器)有效混合,优化与控制系统依据在线分析数据实时计算并控制各组分比例进行配方优化,在保证产品质量合格的前提下实现质量过剩最小化或调合效益最大化。
在线调合技术框架可分为离线配方优化、在线优化和常规控制三个模块,汽油调合技术路线见图2。离线配方优化是指考虑市场需求和组分罐及产品罐库存情况,基于调合规则进行模型优化得出初始配方;在线优化是指采用非线性预测模型,以离线配方优化方式得到的初始配方为基础,根据在线分析的反馈信息,实时动态优化调合配方;常规控制是指通过集散控制系统执行在线优化指令。
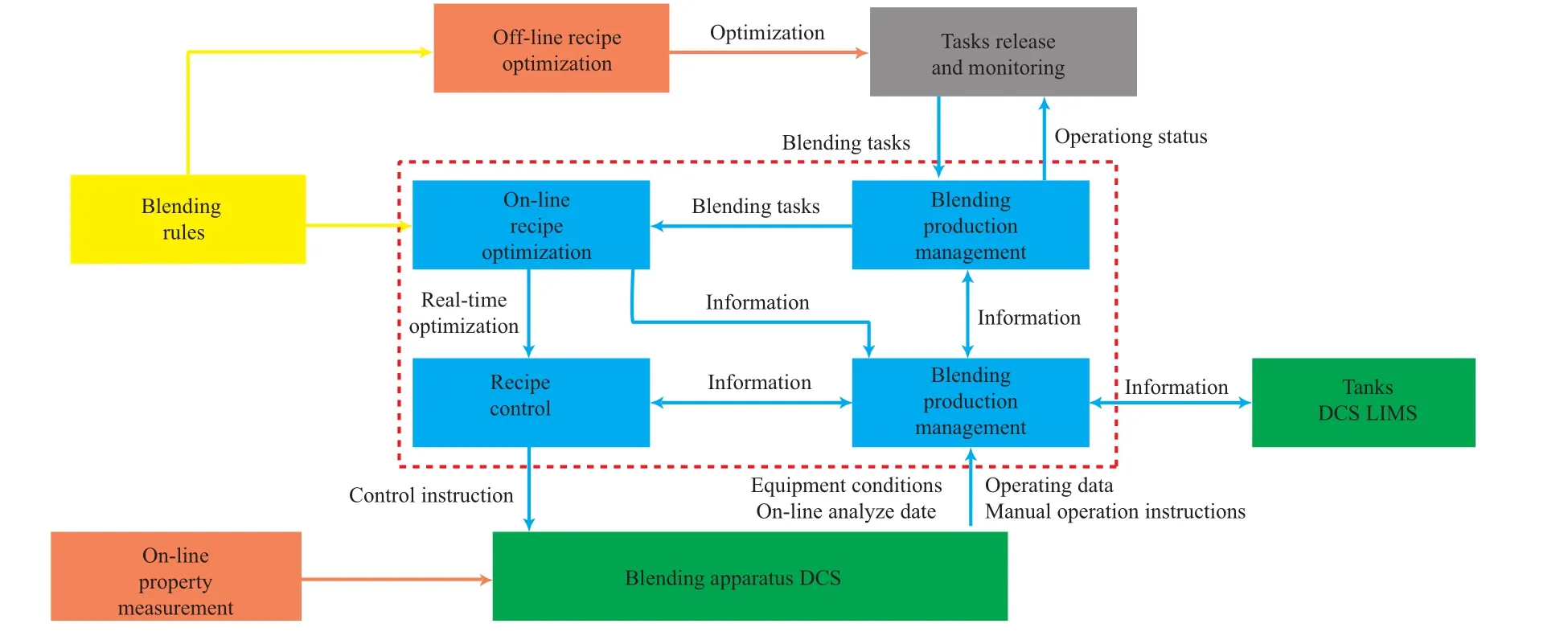
图2 汽油调合技术路线Fig.2 Тhe technical route of gasoline blending.
2 汽油在线调合配方优化技术
汽油调合过程中,考虑调合组分和产品质量指标、产品价格等因素,以生产能力最大化或者效益最大化为目标。由于一些非线性的调合规则(如辛烷值调合规则)以及调合过程的连续性,描述汽油调合过程的数学模型实质上是一个非线性规划问题,汽油调合配方优化求解问题可以归纳为非线性函数优化问题。
以生产效益(即调合利润)最大化为目标函数,式(1)为调合利润目标函数,式(2)为表示辛烷值等质量指标约束、组分用量和工艺条件等约束条件的系列不等式方程。
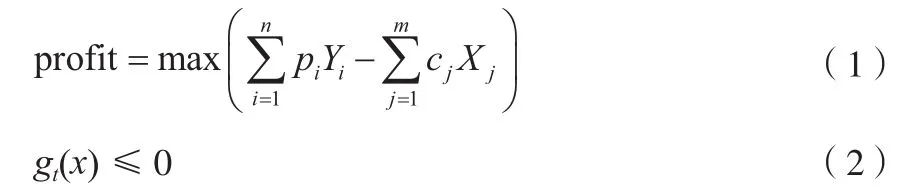
式中,profit为调合利润;pi为成品油i的市场价格;Yi为成品油i的产量;cj为组分油j的成本价格;Xj为组分油j的使用量;n,m分别指成品汽油和组分油的种类;gt(x)为约束条件。
实现汽油在线调合配方最优化,首先要建立精准的汽油调合规则,为调合产品性质预测提供准确指导,然后基于调合过程建立模型并求解,准确快速求取全局最优解,实现调合利润最大化。因此,精准的调合规则和模型求解优化是汽油在线调合技术发展的核心。
2.1 汽油调合规则进展
汽油调合规则描述各调合组分性质与调合产品性质的关系,分为线性关系或非线性关系。汽油质量的主要控制指标包括辛烷值、馏程、苯含量、硫含量、蒸气压、烯烃含量、芳烃含量、腐蚀性能等。其中,辛烷值、蒸气压和馏程等具有明显的非线性调合效应,其余均可视为线性关系。辛烷值作为重要的非线性指标直接影响产品质量和效益。因此,建立准确的辛烷值预测模型至关重要。
2.1.1 辛烷值调合规则
成品汽油的辛烷值并不是组分油辛烷值的简单叠加。组分油中的芳烃与烯烃的敏感度较高,因此,调合过程中组分油之间存在复杂的调合效应,简单的线性调合模型不足以准确描述。辛烷值模型的发展主要围绕解决调合辛烷值产生非线性的原因以及用数学形式描述这些非线性关系两个方向。早期研究主要采用数据回归分析建立辛烷值经验模型,至今仍在广泛使用。机器学习算法出现后,开辟了不考虑非线性因素产生的原因直接利用数据学习预测辛烷值的新思路。另外,也有研究基于分子水平探索调合过程中辛烷值非线性产生原因,以期建立分子水平调合规则。机器学习算法与分子水平调合规则尚不能进行工业应用,但已取得的研究成果为工业应用奠定了基础。
2.1.1.1 半经验半机理模型
从调合辛烷值非线性原因出发建立含可变参数的模型,利用已有实验数据(如调合组分组成、辛烷值等)回归分析得到具有一定适用范围的非线性回归方程。Zahed等[11]利用回归分析方法建立了5个变量的经验模型,与实验值平均偏差为0.54%。Stewart[12]以烯烃组分作为调合非线性因素,提出4参数多组分汽油调合模型,该模型需要各组分油的芳烃、烃、不饱和烃的体积分数,且该模型缺少实际应用实例,精度还有待考证。Healу等[13]以烯烃和芳烃组分作为调合非线性因素,提出6参数的多元汽油调合辛烷值估算方程——Ethуl RТ-70模型,该模型也常作为其他辛烷值新模型对比的标准。
除将调合非线性因素直接参数化建立辛烷值调合模型外,还有考虑两种汽油调合组分间的相互作用,在调合组分辛烷值体积平均值的基础上,增加各组分间的相互作用项来表示辛烷值非线性调合行为的交互法模型,该模型的应用较为广泛。Тwu等[14]基于烃类混合物的混合机理,利用回归关联的方法得到汽油馏分间的二元交互作用参数,用于预测汽油调合的辛烷值。陈新志[15]研究了溶液混合过程中热力学性质的变化,利用二元组分相互作用参数推算多元性质,提出了适用于组分油为MТBE、重整汽油、烷基化油、直馏汽油和催化裂化汽油体系的辛烷值模型。此外,还可利用调合组分的性质信息(需要各组分的研究法辛烷值,马达法辛烷值,组分油浓度,烯烃、芳烃和饱和烃组成等原料性质信息),将调合过程的非线性问题转化成线性问题进行处理,但所需信息较多,使其实际应用受限[16]。
半经验半机理模型基于大量的实验室调合数据,在某种范围内可以相对准确地预测辛烷值,但存在计算过程复杂、回归数据样本需求多、参数多且某些参数难确定等问题。当前商业汽油调合软件并未对外公布调合规则的详细信息,但调合规则主要应为半经验半机理模型,只是不同的商业软件有特有的模型修正方法或数据处理技术。
2.1.1.2 机器学习算法建模
汽油调合过程中,辛烷值调合非线性关系的详细机理并不完全清晰,机器学习算法模型不需要考虑机理,只需以调合实验数据为样本,通过算法不断学习,逐步完善,建立一个可预测的汽油辛烷值黑箱模型。
神经网络算法和支持向量机回归算法均被用于预测调合汽油的辛烷值[17-24]。神经网络算法应用较多(见图3)。基于机器学习算法预测调合辛烷值,预测的准确性与样本数量存在一定关系。孙忠超等[18]利用BP神经网络算法和支持向量机回归算法对催化裂化汽油的辛烷值建立了37个变量的非线性数学模型,他们发现随样本量的增多,两种算法的准确性增加、模型泛化能力增强、辛烷值预测误差减小。此外,3层结构的BP神经网络模型可在预测辛烷值的同时预测调合汽油的密度、初馏点等性质,但建模过程复杂,需要大量历史数据且应用性差[22-23]。
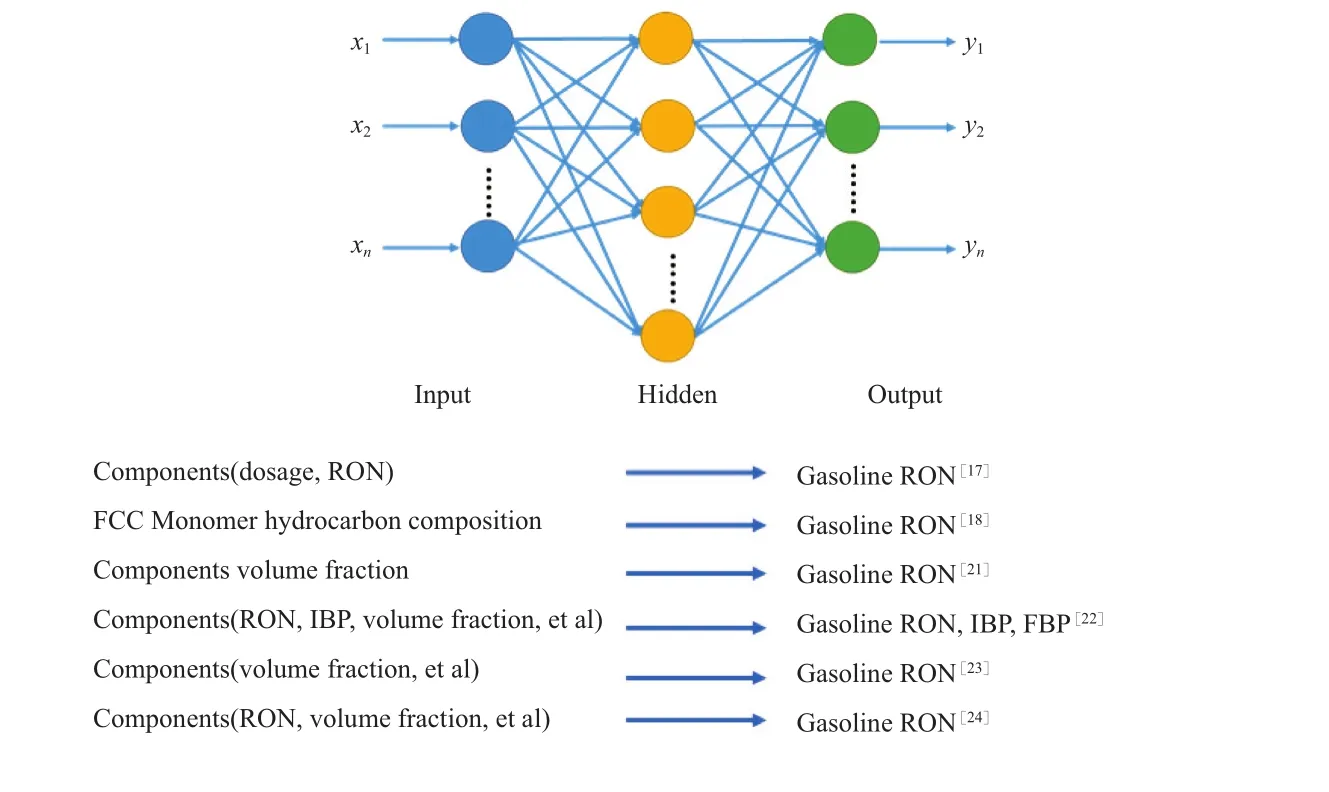
图3 神经网络预测辛烷值模型Fig.3 Тhe prediction model of octane number bу neutral network.
机器学习算法建模无需给出固定的模型数学表达式,且在数据样本范围内精度较高,但对于数据样本量小的情况,模型参数准确性不高。机器学习算法自身也存在一定的不足,如BP神经网络算法的权值和阈值优化采用的是基于梯度的算法,因而易陷入局部最优点。此外,不同炼厂加工的油品种类和性质差异较大,机器学习算法建立的调合规则面临移植性差、建模样本数据需求量大、维护困难等问题。
2.1.1.3 分子水平调合模型
建立分子水平调合规则,将汽油看作烃类化合物的理想混合体系,可直接通过分析汽油试样分子组成预测辛烷值等性质[8],从源头上解决辛烷值模型参数修正等问题。分子水平预测汽油辛烷值路线见图4。已有研究从分析调合组分油单体烃组成出发,调合出高辛烷值汽油[25]。Liu[26]提出了改进的分子类型同源序列方法,发现分子组成对关键性质(如辛烷值、蒸气压等)影响显著,并在配方优化过程中验证了调合模型的准确性。桂晓娇等[27]以汽油馏分的488种烃分子及含氧化合物为基础,建立了一种基于Ghosh RON模型的改进分子组成辛烷值预测模型,该模型预测较为准确且不受调合组分性质等限制。适用性广、准确性高的分子水平调合规则的建立,需要采集大批量、多类型的汽油调合组分和成品汽油,对汽油进行详细组成分析并建 立分子水平数据库。

图4 分子水平预测汽油辛烷值路线Fig.4 Тhe predicting route of octane number on molecular level.
汽油辛烷值调合规则为典型的非线性模型,并未有详细的机理模型。单一的数据回归算法和机器学习算法所建立的辛烷值调合规则并未考虑非线性机理,主要依赖实验数据,调合规则适用范围受限。半经验半机理模型可以兼顾一定的非线性机理,机理模型难以描述的部分使用经验参数代替,常用的半经验半机理模型参数一般由定量的实验数据回归得到。随企业汽油调合数据的积累和挖掘,深度融合机理建模和数据驱动建模的混合建模方法是未来汽油辛烷值调合规则发展的重点方向。目前,采用深度融合机理建模和数据驱动建模的混合建模方法在石化生产过程中应用较多[28-29],而汽油辛烷值调合规则混合建模的报道很少。殳越[30]借鉴了乙基模型,考虑了烯烃含量、芳烃含量以及敏感度对调合辛烷值的影响,提出了用可变调合效应对辛烷值进行补偿,可变调合效应值可基于调合数据回归预测得到。
2.1.2 调合规则参数优化
为保持调合规则的精度,在线调合过程中需使用偏差更新方法,对调合规则的参数进行实时校正,以消除测量误差、组分质量波动等因素的影响。常规的偏差更新方法是通过实时修改调合模型预测值与实测值之间的偏差对优化过程予以校正,以维持调合模型的精度。如基于辛烷值调合效应模型,通过递推最小二乘算法实现辛烷值性质的实时更新,即根据实际调合配方,自动计算组分油辛烷值的偏差补偿,保证模型的适用范围[8]。但在组分油性质波动的情况下,偏差补偿的方法无论采用线性规划算法还是非线性规划算法求解,均难以准确获得最优配方,适用范围受限[31]。
调合规则模型参数可通过机器学习算法实现在线优化。沈阳自动化研究所[32]基于陈新志提出的辛烷值模型,通过比较实际辛烷值与计算辛烷值的误差,用机器学习算法对模型参数进行智能化调整,以取得调合生产最大利润率,但调合规则模型参数在线优化的准确性和实用性还有待验证。
2.2 调合过程模型求解优化
汽油调合优化是一个涉及物料平衡约束、非线性指标约束(如辛烷值调合规则)的复杂非线性规划问题,快速求取调合过程模型全局最优解对实现在线调合过程效益最大化至关重要。调合过程模型求解实质上为约束非线性规划求解问题,目前主要基于迭代法求解,逐步逼近最优解。常用方法是将有约束优化问题无约束化,如Lagrange-Newton法、逐步二次规划法(SQP算法)、惩罚函数法等;但将有约束优化问题转化成一系列无约束优化问题,计算量大且收敛速度慢,难以得到精确解。SQP算法存在相容性问题,即原问题有解,转化为二次规划子问题却无解;惩罚函数法的惩罚因子值在非常大的情况下才能够很好地逼近原问题的最优解,但由于存在误差,这样的计算在理论上无法达到收敛值。
汽油调合过程模型优化求解流程见图5。可利用传统算法和启发式算法求解调合过程模型,但汽油调合过程模型优化求解算法的选择与模型形式有关。若调合规则均为线性模型,则可采用线性规划方法进行求解;若调合过程模型涉及神经网络模型,如辛烷值调合规则采用神经网络方法建模,整个调合过程模型优化求解就不能考虑梯度信息化的优化算法,但可采用启发式算法进行求解。单一批次在线调合过程中,求解在物料平衡约束和性质指标约束下的最优调合配方,计算量相对较小,传统的求解算法基本上可以满足求解精度和计算时间的要求。若汽油调合过程中考虑多周期调合、调合调度优化等问题,将汽油调合过程由非线性规划问题发展到混合整数非线性规划问题,则启发式算法相对传统算法优势明显,无需初始值,收敛速度快,可求解复杂优化问题。启发式算法[33-37]已被用于处理汽油调合过程中复杂非线性函数的优化问题,如遗传算法、模拟退火算法及群体智能算法(如分化微粒群算法、蚁群算法)等。遗传算法是模拟自然选择和自然遗传过程,迭代搜索最优解,但遗传算法属于一个概率性弱搜索算法,不能处理汽油调合过程中有约束的问题,还需要特殊处理,如采用惩罚函数法处理非线性约束,将汽油调合过程约束问题转化为无约束问题进行计算。群体智能算法是一类仿生物行为的优化算法(如粒子群优化算法、蚁群算法、人工鱼群算法、差分进化算法等)。粒子群优化算法基于迭代原理,全局搜索能力强[33];蚁群算法适合处理离散优化问题,但无法有效求解连续优化问题[34];差分进化算法借鉴“优胜劣汰,适者生存”的自然进化法则,收敛性强,一定程度上能解决粒子群算法早熟收敛现象[37]。总体而言,这些新兴算法为工业应用中快速获取非线性规划问题全局最优解提供了可能,但也存在待改进之处。

图5 汽油调合过程模型优化求解流程Fig.5 Optimizing solution process of gasoline blending process model.
3 结语
汽油在线调合技术能实现比例调合、过程自动控制、在线配方优化等功能,但仍面临调合组分和工艺状况变化频繁等问题。精准的调合规则和准确快速求取最优解仍是有待解决的难题。基于经验回归建模的辛烷值调合规则面临调合组分变化频繁引起模型维护量大等难题。机器学习算法模型过于依赖样本数量,难以应对训练样本以外的情况。分子水平调合规则虽然可从机理上详细描述辛烷值非线性原因,但因为当前分子数据库规模相对较小,不能满足工业应用需求。半经验半机理模型兼顾机理描述,模型关键变量可通过数据挖掘获取。随着炼厂的数字化转型,更多汽油调合数据可被挖掘利用,因此,基于机理和数据驱动的混合建模方法是非线性调合规则的重点发展方向。汽油调合优化过程实质上是求解非线性规划最优解问题,遗传算法、粒子群算法等启发式算法可有效处理约束非线性规划问题,为调合过程提供全局最优解。
