基于深度学习的烟草垄行分割模型
2021-08-20王博陈颉颢蒋红海
王博,陈颉颢,蒋红海
(650031 云南省 昆明市 昆明理工大学 机电工程学院)
0 引言
图像语义分割是计算机视觉中最具挑战性的问题之一,语义分割是为图像中每个像素识别并分配一个类别标签,它有着广泛的应用,如汽车自动驾驶中的环境感知[1]。近年来,卷积神经网络被发现能够从图像中自动提取出比手工制作的图像更紧凑、更有意义的特征,这类模型的代表研究工作有DeepLab[2-4]系列以及PsPNet[5]。
图像语义分割有2 种方法,一种为传统图像语义分割,另一种为基于卷积神经网络的语义分割。在这方面,Zhu[6]等人综述了全监督方法、弱监督方法和无监督方法等传统的语义分割方法;Guo[7]等人总结了各种语义分割模型的优势、劣势和主要挑战;Tian[8]等人从全监督语义分割方法和非全监督语义分割方法两方面对图像语义分割方法进行了详细综述。
烟草垄行图像分割为包含各种背景的垄行图像分割问题,即为图像多分类语义分割问题。垄行图像的变异性和丰富性使得通过先验知识来手工构建特征提取器变得困难,而神经网络算法更依赖于自动学习来提取垄行各分类的特征。本文的语义分割算法是基于卷积神经网络搭建的,两组成部分为编码器和解码器,解码器的作用是将图像中各种类别的特征进行提取,编码器的作用是根据解码器所提取出来的特征对图像的各像素点进行分类预测。
1 提出的卷积神经网络垄行语义分割模型
本文中为基于卷积神经网络搭建的垄行语义分割算法。首先,当神经网络模型的层数深度相同时,卷积神经网络远小于全连接神经网络可训练的权重参数数量,因硬件设备算力及内存的限制,硬件设备可训练权重参数的数量是有限制的。在可训练参数的数量相同时,卷积神经网络模型的网络层数远大于全连接神经网络。虽然全连接神经网络能在数字图片识别任务中取得90%的准确率,但由于烟草垄行图像环境复杂,背景较多,垄行的语义分割任务中涉及的图像特征更为复杂,因此,使用层数较多卷积神经网络是更好的选择;其次,卷积神经网络搭建的语义分割模型的输入层可接受任意大小的图片作为输入,使用卷积神经网络搭建的模型泛化性较全,连接神经网络更强。
垄行语义分割模型主要的层有以下几种:
(1)卷积层:卷积层由卷积单元组成,参数是通过反向传播算法最佳化得到的。此模型中各每个卷积层使用常规卷积核、深度可分离卷积核,及用于空间维度卷积操作的卷积核来搭建。将常规卷积核中空间相关性与通道间的相关性进行解耦,能有效提取图像中目标特征[9]。本文在隐藏层中使用结构为3×3×1 和1×1×c 的卷积核。
(2)激活层:本文的分割算法需要部署在车载电脑上,且可随车移动,由于车载电脑的硬件和内存有限,所以需选择适中的神经网络模型参数量。本文算法中选择使用PReLU[10]函数作为激活层的激活函数。
(3)子采样层:子采样层主要作用是压缩数据和参数的量,减小过拟合。使用Maxpooling不能总是提升CNN 网络的性能,特别当使用特别大的网络时,该网络通过卷积层即可学得相应数据集的必要不变特征[11],本文使用最大池化操作来实现子采样层。
本文模型将垄行图像分割为4 个类:田埂,土壤,背景,烟草,所以,Softmax 层的输出就是一个4 通道且每个通道的长宽和原图像相同的张量。每个通道和原图像索引相同的值代表着原图像该像素点属于某一类的概率。
2 垄行语义分割模型的架构
本文的卷积神经网络模型一共包含着114个卷积层。将模型中相邻的几个神经网络层定义为一个卷积块,本文模型中共包含4 个功能不同的的卷积块:基于常规卷积核的卷积块(ConvBlock),基于深度可分离卷积核的卷积块(ConvdwBlock),基于深度可分离卷积核下采样卷积块(DownConvdwBlock),基于深度可分离卷积核上采样卷积块(UpConvdwBlock)。将模型各层按输入输出顺序排列可得表1。其中:Nb——使用模块数量;Fs——卷积核空间维度尺寸;NF——输出特征组的通道数;Dm——通道扩张率;inputsize——输入特征组的具体尺寸。
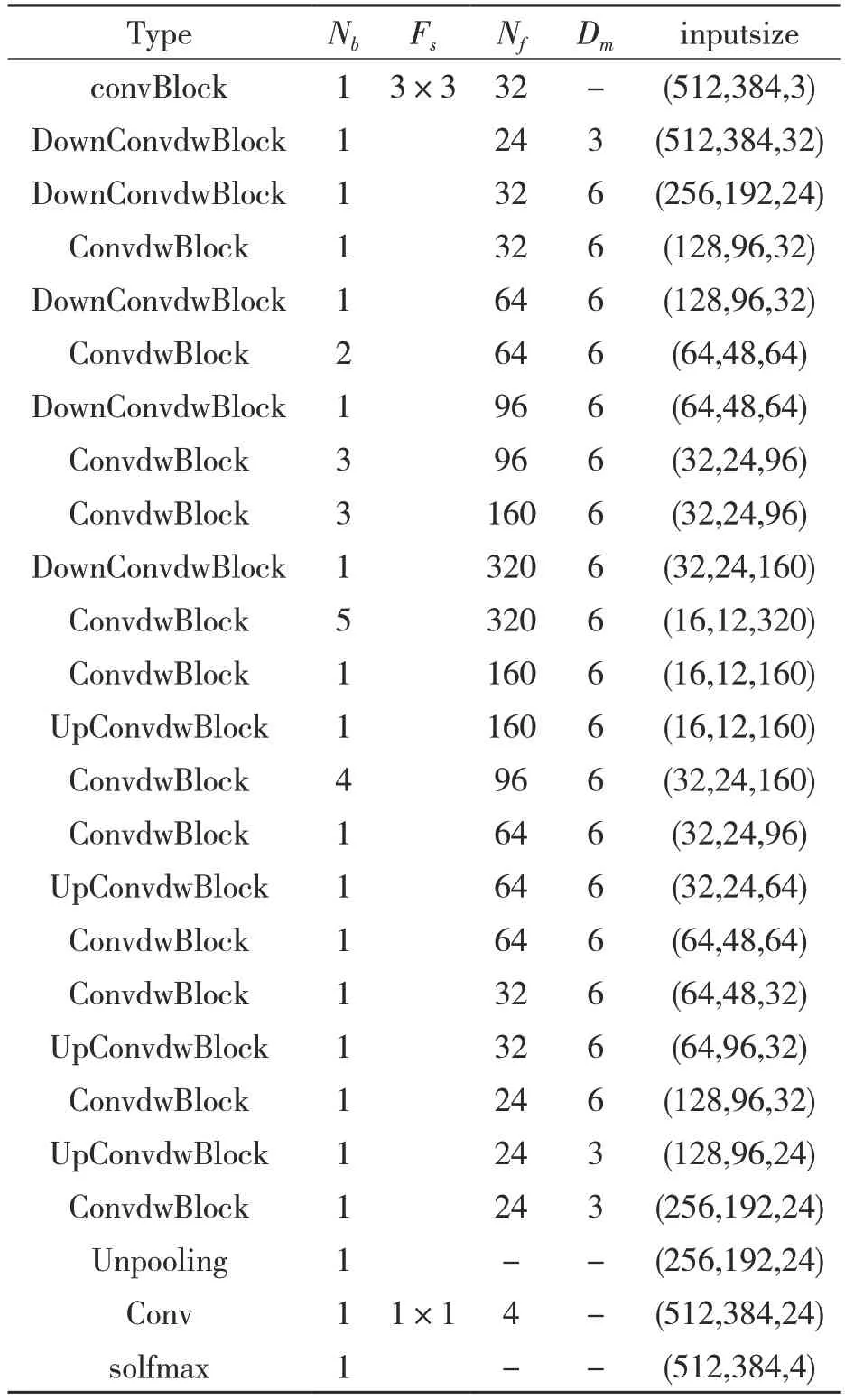
表1 Lhsegnet 结构Tab.1 Lhsegnet structure
(1)基于常规卷积核的卷积块(ConvBlock):该卷积块的作用是特征提取及分类,在模型的首层使用该卷积块,提取出图像中色彩、边缘等初级的特征,如图1 所示。
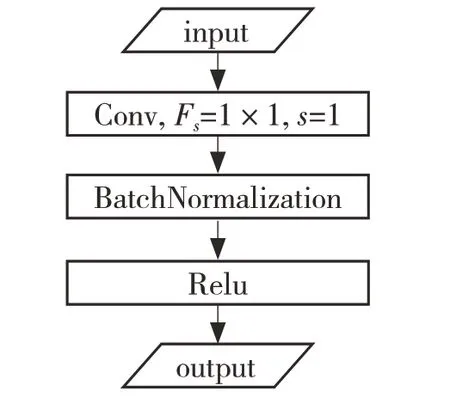
图1 ConvBlock 结构Fig.1 ConvBlock structure
(2)基于深度可分离卷积核的卷积块(ConvdwBlock):本文使用的卷积神经网络模型卷积层较多,有可能出现退化问题。该卷积块使用shortcut[12]避免模型的退化问题,即通过shortcut,将该卷积块的输出特征组和输入特征组进行对位置元数的相加[8]。此种方法不会添加多余的参数,但是却可以提高模型的收敛速度,很好地解决退化问题。如图2 所示。
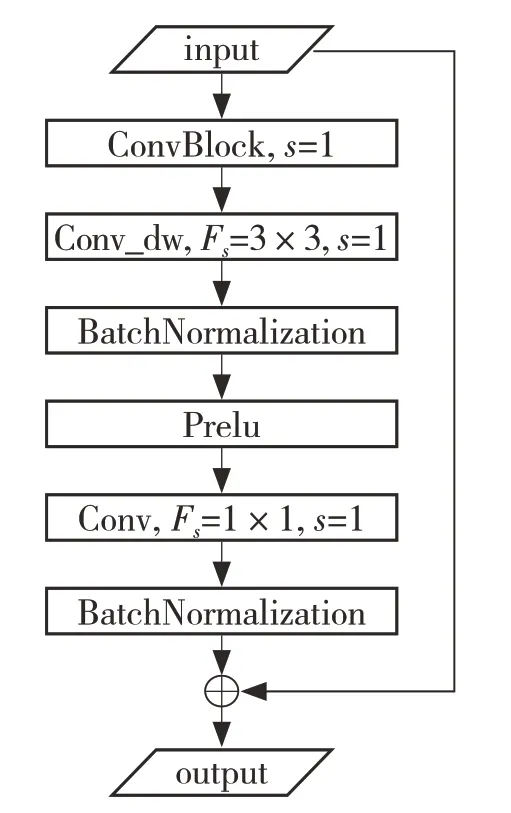
图2 ConvdwBlock 结构Fig.2 ConvdwBlock structure
(3)基于深度可分离卷积核的下采样卷积块(DownConvdwBlock):该卷积块有通道扩张率Dm和输出特征组的通道数Nf两个参数,该卷积块加入了最大池化索引提取层(MaxpoolIndex),且深度可分离卷积层(Conv_dw)的步长为 2,如图3 所示。
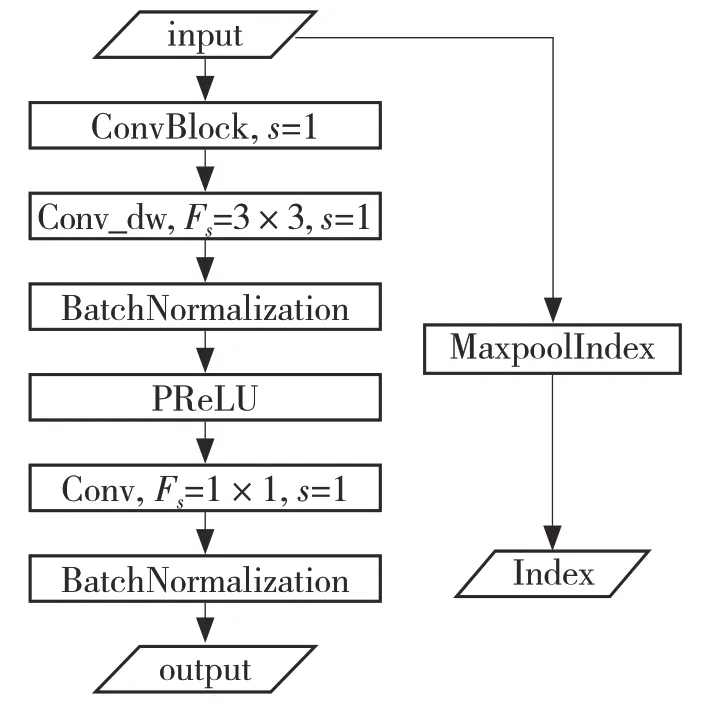
图3 DownConvdwBlock 结构Fig.3 DownConvdwBlock structure
(4)基于深度可分离卷积核的上采样卷积块(UpConvdwBlock):该卷积块的输入为前一层卷积块输出的特征组,由DownConvdwBlock 提供与之维度相对应的位置索引。在上采样层中,将特征值插入到该索引的对应位置,得到较准确的分割边界。如图4 所示。
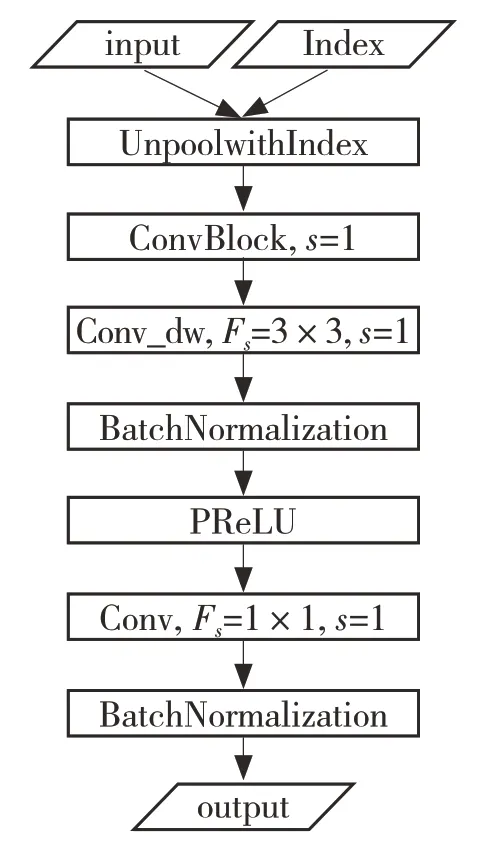
图4 UpConvdwBlock 结构Fig.4 UpConvdwBlock structure
3 实验
3.1 实验平台及数据集制作
本次实验采用深度学习框架tensorflow2.0,在Python3.7 开发环境下搭建模型。硬件上,台式电脑的CPU 型号为 i7-8850h,内存16 G,GPU 型号为GXT2080,该型号显卡的显存为8 G。本次实验样本拍摄于烤烟种植区,为保证样本多样性,采样时做了以下几点:
(1)在不同时间、不同光照下进行样本采集;
(2)采集样本时既要保证其共性,也要保留其存在的个体差异;
(3)需要在不同的拍摄角度下采集,需有细节的纹理特征;
(4)各个烟田中烟苗生长速度不同,需采集形态各异的样本。
使用labelme 制作样本,主要分为4 类,土地、背景、田埂、烟草,样本尺寸为[720×621],所有样本分辨率均调整为[512×384]。将样本分为训练集、验证集和测试集,训练集中有600 个样本,验证集150 个样本,测试集100 个样本。部分训练集样本如图5 所示。

图5 部分训练集样本Fig.5 Part of the training set
3.2 不同优化算法的训练实验
本文使用2 种优化算法对模型进行训练,分别为AdaDelta[13]和Adam[14]。AdaDelta 是一种基于梯度下降的自适应率学习方法,具有较强的鲁棒性[15];ADAM 使用动量和自适应学习率来加快收敛速度,具有计算效率高、很少的内存需求等优点。AdaDelta 和Adam 自适应算法可以为每个参数设置学习速率,并且在学习过程中自动调节。分别使用AdaDelta 优化器和Adam 优化器对模型进行训练,得到的损失函数曲线如图6 所示。
由图6 可知,Adam 优化器相对于AdaDelta优化器收敛速度明显加快,前20 轮损失函数下降较快,第20 轮到第55 轮损失函数值下降较慢,第55 轮至第80 轮为过拟合阶段。而在使用AdaDelta 优化器时,训练集与验证集损失函数值均缓慢下降,但在250 轮后,验证集出现震荡,模型有过拟合趋势。对AdaDelta 优化器和Adam 优化器的像素准确率进行比较,由图7 可知Adam优化器的像素准确率远远高于AdaDelta 优化器。
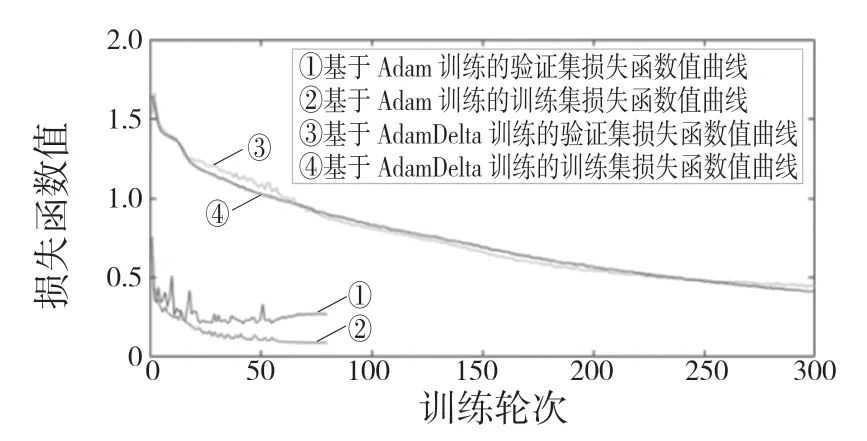
图6 AdaDelta优化器和Adam优化器训练损失函数曲线图Fig.6 AdaDelta optimizer and Adam optimizer train loss function graph

图7 AdaDelta 优化器和Adam 优化器像素准确率曲线图Fig.7 The AdaDelta optimizer and Adam optimizer pixel accuracy curves
像素准确率和损失函数未达到理想状态,因为样本是通过手工描点的方式来进行标注的,存在一定的标注误差;其次,由于模型使用了宽度可卷积搭建,容量较小,模型对图像中比较复杂的边界不能进行很好的拟合;最后,优化器性能对模型有一定的限制。
3.3 基于类间平衡技术训练实验
类间平衡技术是通过为出现频率低的类设置较小的权重,出现频率高的类设置较大的权重,提高样本类的准确率,训练集中各类别像素点比例如表2,各类别损失函数如表3。

表2 训练集中各类别像素点比例Tab.2 Pixel ratio of each category in training set
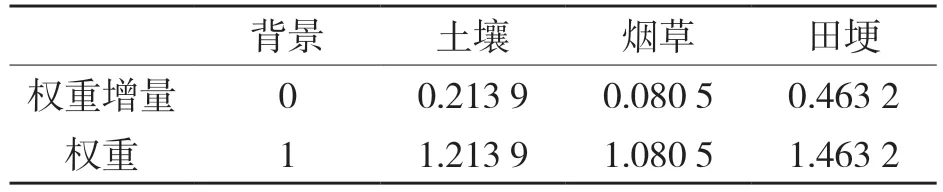
表3 训练集中各类别损失函数权重Tab.3 Weight of each loss function in training set
若以Loss 表示使用类间平衡技术的损失值,则损失函数
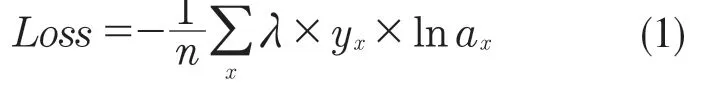
式中:n——标签类别数量;x——样本;y——标签值;a——模型预测值;λ——各分类的权重。
本次实验选用Adam 优化器,使用小批量随机训练法,设置批大小为3。本次实验共80 轮,每轮进行1 000 次迭代。分别对使用类间平衡技术训练后的损失函数值和像素准确率进行统计,结果分别如图8、图9 所示。
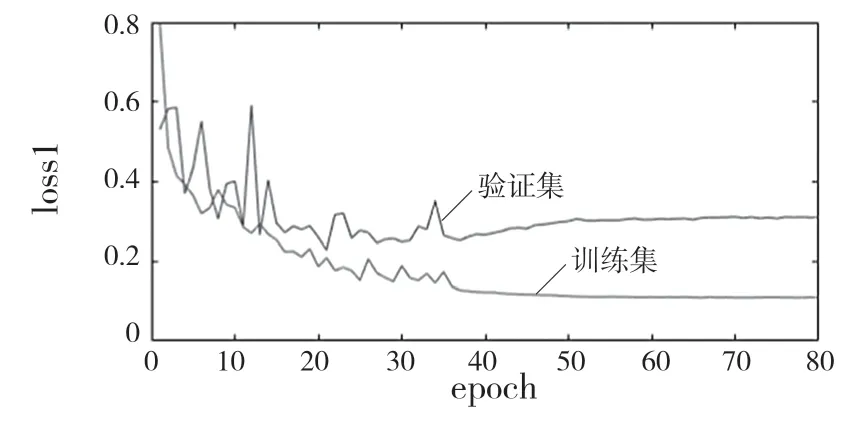
图8 类间平衡训练后的损失函数值曲线Fig.8 Loss function value curve after inter-class balance training
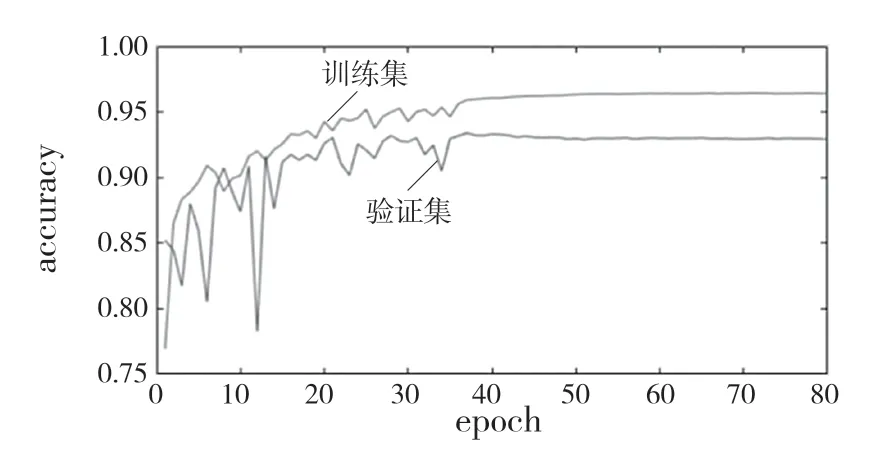
图9 类间平衡训练后的像素准确率曲线Fig.9 Pixel accuracy curve after inter-class balance training
将不使用类间平衡技术的训练称为常规训练,将两种训练平均像素准确率进行对比,如图10 所示,类间平衡技术训练比常规训练田埂平均像素准确率收敛得更快,因此类间平衡技术有助于小样本类别的识别。部分使用类间平衡技术后样本分割图如图11 所示。
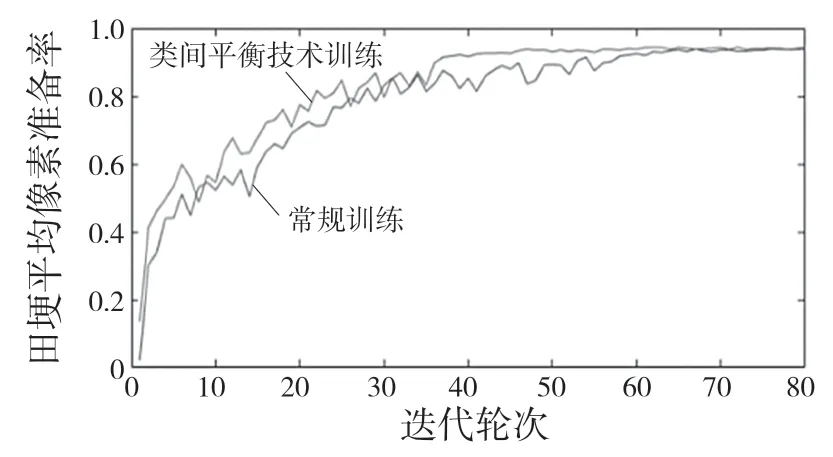
图10 田埂平均像素准确率曲线Fig.10 Average pixel accuracy curve of field ridge

图11 部分使用类间平衡技术后样本分割图Fig.11 Sample segmentation diagram after using technique of class balance
3.4 与Segnet 卷积神经网络模型的对比实验
在对2 个模型的训练中,为防止过拟合,对各层卷积核正则化,正则化超参数使用tensorflow中默认值0.001,类间平衡技术使用参数如表3所示,同时使用Adam 优化器采用随机梯度下降的方式训练,设置批大小为4,LHsegnet 模型共迭代60 轮,Segnet[16]模型共迭代了100 轮,每轮皆进行了1 000 次随机梯度下降。将训练好的模型在验证集上进行验证对比,其中LHsegnet 模型参数量为1 336 万,处理测试集图像平均每幅耗时0.113 6 s,像素准确率为0.921 3;Segnet 模型参数量为2 946 万,处理测试集图像平均每幅耗时0.214 2 s,像素准确率为0.716 1。比较可知,本文提出的LHsegnet 模型对比Segnet 模型,效果更好。
从表4 可知,LHsegnet 模型相对于Segnet 模型对小样本类别有较好的表现。LHsegnet 模型与Segnet 模型分割效果图如图12 所示。从图12 可以看出,LHsegnet 模型分割效果图中田埂,背景类别的边界较为准确。
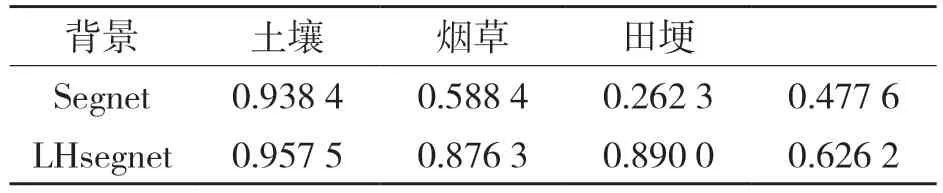
表4 测试集中各类别的平均像素准确率Tab.4 Average pixel accuracy for each category in test set

图12 两种模型测试集分割效果图Fig.12 Split renderings of two model test sets
4 结语
本文基于卷积神经网络搭建了语义分割模型LHsegnet,针对烟草垄行图像的场景识别问题,此模型中使用了宽度卷积来压缩各个卷积层的可训练参数,提高运行速度。使用PreLU 激活函数为宽度卷积提供非线性输出,并使深度可分离卷积层输出的负值信息不会全部丢失,从而增加了模型的表达能力,使用类间平衡技术来增加模型识别率。实验结果表明,LHsegnet 模型对垄行图像分割效果较好。
