基于FA-SVR的小麦蚜虫发生程度预测模型研究
2021-06-17高风昕
高风昕
(黄淮学院数学与统计学院,河南 驻马店 463000)
引言
豫南地区是我国小麦的主产区,其产量高低对我国粮食安全有着重要的影响,而小麦蚜虫是危害小麦产量和品质的重要害虫。在豫南地区危害小麦的蚜虫主要是麦长管蚜、麦二叉蚜等属于同翅目蚜科,有翅可迁飞,具有迁移性,繁殖能力强,1a可以繁殖20余代。麦长管蚜、麦二叉蚜主要以成蚜、若蚜吸食小麦叶面、茎秆、嫩穗的汁液使小麦缺失营养导致叶面逐渐变黄直到枯死,从而使小麦减产,据统计,我国每年因为麦蚜虫的危害使小麦减产2~3亿t。因此,预防预测麦蚜虫的危害是科技工作者的一项重要任务。
目前国内外对小麦蚜虫的预测模型主要有经验法、实验法和统计预测法等。如,李文峰等[1]利用逐步回归的方法构建蚜虫预报预测模型;丁世飞等[2]用逐步判别方法构建麦蚜虫发生期的模型;王纯枝等利用相关分析法和主成分法构建蚜虫适宜度的预测预报模型;luo等[3]利用spss中的逻辑回归方法给出蚜虫预报预测模型;孙淑梅、丁世飞、李鸿怡等利用模糊数学的方法构建小麦蚜虫预报预测模型。以上专家给出的预测模型对小麦蚜虫的防治都起到了积极的作用,但这些模型大多以天气条件作为主要因素,预测的准确率和时效性不够高。支持向量机在小样本训练方面比其它方法更胜一筹,而且该方法的泛化能力非常强,支持向量机大多运用在证券、金融、电子商务、大气污染物浓度的预测中[7-10],小麦蚜虫发生程度的预测模型研究国内外文献资料涉及很少,基于此,本文运用支持向量机回归对豫南地区小麦蚜虫发生程度进行预测,构建了支持向量机回归的小麦蚜虫发生程度的短期预测模型,填补了支持向量机回归在小麦蚜虫短时预测的不足,通过测试样本验证该方法时效性和泛化能力强、预测精度高,具有良好的研究和应用前景。
1 支持向量机基本原理
支持向量机(SVM)将每个样本数据表示为空间中的点,使不同类别的样本点尽可能明显地区分开,通过将非线性低维空间上的样本数据映射到高维空间中,使样本数据在高维空间中转化线性样本数据,然后寻找最优化区分两类数据的超平面,使各类到超平面的距离最大化,距离越大表示SVM的分类误差越小,即使数据集的边缘点到分界超平面的距离最大,称边缘点为支持向量。
设低维空间上的训练样本为(x1,y1),(x1,y1),…,(xn,yn),xi∈Rn,yi∈R,其中xi为i个n维输入向量,yi为对应的输出值,通过一个非线性映射Φ(x)将训练样本由低维空间映射到高维空间中,在高维空间中再对样本进行线性回归分析,根据风险最小化准则构建高维空间中拟合最优的线性回归函数f(x)=ω·φ(x)+b(ω为权重向量,b为偏置常数),然后使用该函数对另外的样本进行预测,把线性回归问题转化为求如下的最优化问题。
(1)
(2)
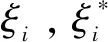
模型(1)、(2)的对偶问题:
(3)
(4)
(5)
式中,k(xi,x)为核函数。常用的核函数有线性核函数、多项核函数、径向基核函数和sigmod核函数。根据专家经验,径向基核函数(KBF)能使支持向量机取得最好的效果,所以选择KBF作为核函数。
对支持向量机回归参数估计有多种,比较各种参数估计方法从预测精度上考虑常选择网格搜索法来确定惩罚因子C,核参数σ,损失函数中的参数ε。
2 FA-SVR小麦蚜虫发生程度预测模型
2.1 小麦蚜虫发生程度的影响因子
本文选取豫南地区驻马店市、信阳市、南阳市2009—2020年小麦种植区的气象和小麦蚜虫发生程度的数据资料,气象各因子资料来源于豫南地区逐日气象观测资料,小麦蚜虫的发生程度和天敌的数据资料来源于当地植保部门,气象资料采取每月每旬作为时间周期,小麦蚜虫的发生程度和天敌数据资料是指每个地市至少选择5个样本采集区,每5d采集1次样本。影响小麦发生程度的因子有日最高气温、日最低气温、平均气温、日照时数;平均相对湿度、最小相对湿度、平均降水量、平均水气压;平均风速、最大风速、最大风速风向、极大风速、极大风速风向;日最高本站气压、日最低本站气压、平均气压;七星瓢虫、异色瓢虫、食蚜蝇幼虫、草蛉幼虫、寄生性天敌。本文以2009—2020年,每年2月1日—5月20日,以每旬作为时间周期,为了减少因子个数把天敌作为一个因子,共17个指标187个解释变量。根据中华人民共和国农业行业标准(NY/T612-2002)《小麦蚜虫测报调查规范》,麦蚜发生程度根据百株蚜量(y,头)分为5级,分级标准为一级(y≤500)、二级(500
2.2 数据的归一化处理
利用影响小麦蚜虫发生程度的指标因子和小麦蚜虫发生程度数据组成的样本集,(xi,yi),i=1,2,…n,xi∈Rn,yi∈R,构建小麦蚜虫发生程度的SVR预测模型。由于各影响因子的量纲不尽相同,为了克服各因子由于量纲的不同对预测结果的影响,同时为了提高各个数据间的可比性和数据的收敛速度,减少模型的训练时间,先对原始数据进行归一化处理,利用公式(6)可将原始数据压缩到[0,1]。
(6)
2.3 FA-SVR组合模型预测流程图
本文通过构建因子分析和支持向量机回归组合预测模型(FA-SVR预测模型),提高模型的预测精度和时效性,根据指标构建原则(全面性、简明性、可操作性、经济性、代表性、规范性等)选取17个指标的评价体系,对样本数据标准化处理,克服量纲和大数据对结果的影响,利用因子分析法提取5个公共因子(光热因子、水分因子、风因子、气压因子、天敌因子),从而减少支持向量机指标的输入个数,分别以所得公共因子为自变量,以麦蚜发生程度为因变量分别进行多元线性回归分析和支持向量机回归分析,根据以上分析可以确定FA-SVR预测模型的流程图,如图1。
3 实证研究
3.1 主成分SVR参数寻优
以旬为单位收集了2009—2020年12a的210个样本数据,其中选取2009—2017年的样本数据作为训练样本,2018—2020年样本数据作为测试样本。对于训练样本选取径向基核函数(KBF)构建式(5)的ε-SVR预测模型。同时利用170个训练样本使用LIBSVM 3.22软件包,采用网络遍历法和K(K=10)折交叉验证法选择最优参数,结果C=2257672.96512,g=0.000038896503529,P=0.0338。
3.2 预测值和实际值的比较分析
以因子分析得到的5个公共因子为解释变量,利用FA-SVR模型和多元线性回归模型(MLR)得到麦蚜发生程度的预测值与观测值之间的数据如表1,并且利用FA-SVR模型得到麦蚜发生程度的预测值与实际值之间的相关系数接近于1,利用多元线性回归模型得到麦蚜发生程度的预测值与观测值之间的相关系数为0.97,这表明麦蚜发生程度实际观测值与预测值之间具有高度的相关性,并且通过FA-SVR模型得到的训练样本的预测值与实际观测值相符合,如表1,测试集样本数据的预测值与实际观测值相符合,如表2。
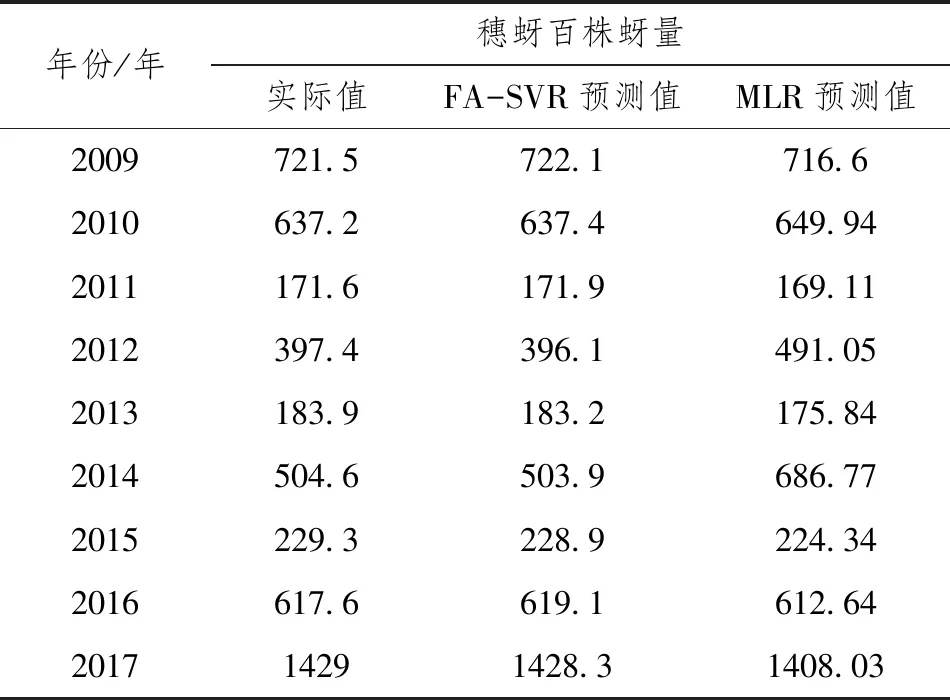
表1 训练样本实际观测值与预测值对比
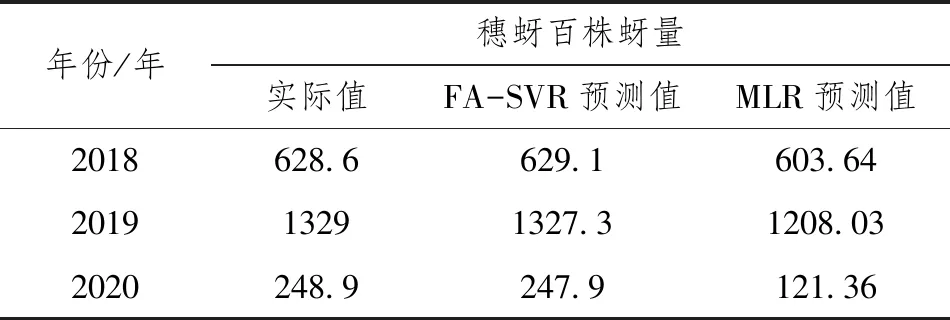
表2 测试样本实际观测值与预测值对比
3.3 模型评价
为评价模型的质量,常用FA-SVR模型的预测值与观测值的进行比较,通常采用以下统计量对FA-SVR模型进行评价,比较结果如表3。
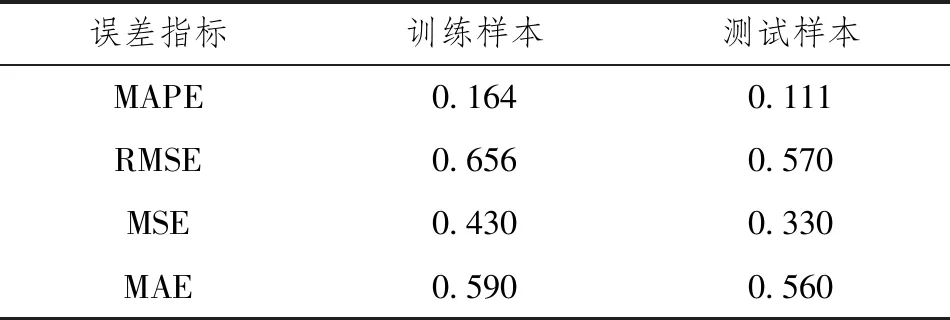
表3 训练和测试样本误差因子比较
平均绝对误差:
均方误差:
均方根误差:
平均绝对百分比误差:
4 结论
本文首次将FA-SVR模型应用于豫南地区小麦蚜虫发生程度的预测模型中,通过实证分析可以看出,预测值和实际值呈现高度的相关性并且基本一致。由表4中3个模型比较可以得出,FA-SVR组合模型具有较高的预测精度,所以FA-SVR组合模型的应用能够准确及时地发布豫南地区小麦蚜虫监测预警信息,能够有效地进行小麦蚜虫的科学防控,并且本模型的预测精度和泛化能力都较高,所以,FA-SVR组合模型用于豫南地区小麦发生程度的预测是可行的。
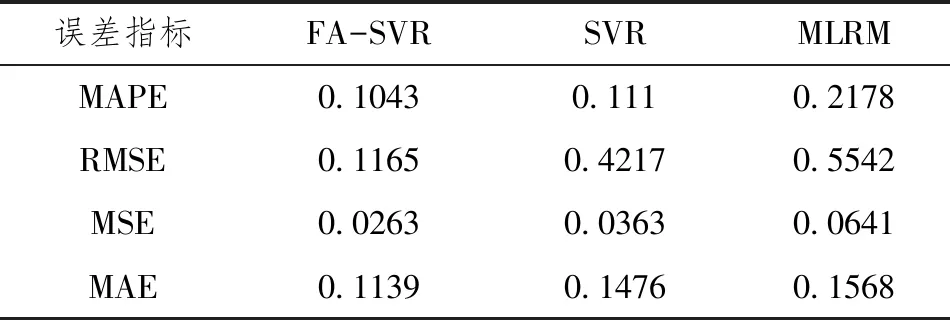
表4 训练样本误差比较
