一种RNN-T与BERT相结合的端到端语音识别模型
2021-05-11郭家兴韩纪庆
郭家兴 韩纪庆

摘要:端到端语音识别模型由于结构简单且容易训练,已成为目前最流行的语音识别模型。然而端到端语音识别模型通常需要大量的语音-文本对进行训练,才能取得较好的识别性能。而在实际应用中收集大量配对数据既费力又昂贵,因此其无法在实际应用中被广泛使用。本文提出一种将RNN-T(RecurrentNeuralNetworkTransducer,RNN-T)模型与BERT(BidirectionalEncoderRepresentationsfromTransformers,BERT)模型进行结合的方法来解决上述问题,其通过用BERT模型替换RNN-T中的预测网络部分,并对整个网络进行微调,从而使RNN-T模型能有效利用BERT模型中的语言学知识,进而提高模型的识别性能。在中文普通话数据集AISHELL-1上的实验结果表明,采用所提出的方法训练后的模型与基线模型相比能获得更好的识别结果。
关键词:语音识别;端到端模型;BERT模型
【Abstract】Theend-to-endspeechrecognitionmodelhasbecomeoneofthemostpopularspeechrecognitionmodelsduetoitssimplestructureandeasytraining.However,itusuallyneedsalargenumberofspeech-textpairsforthetrainingofanend-to-endspeechrecognitionmodeltoachieveabetterperformance.Inpracticalapplications,itisverylaboriousandexpensivetocollectalargenumberofthepaireddata,resultinginthemodelcannotbewidelyused.ThispaperproposesamethodofcombiningtheRecurrentNeuralNetworkTransducer(RNN-T)modelwiththeBidirectionalEncoderRepresentationsfromTransformers(BERT)modeltosolvetheaboveproblems.ItreplacesthepredictionnetworkpartintheRNN-TwiththeBERTmodelandfine-tunestheentirenetwork,thustheRNN-Tmodeleffectivelyuseslinguisticinformationtoimprovemodelrecognitionperformance.TheexperimentalresultsontheChinesemandarindatasetAISHELL-1showthat,comparedwiththebaselinesystem,thesystemusingtheproposedexpansionmethodachievesbetterrecognitionresults.
【Keywords】speechrecognition;end-to-endmodel;BERTmodel
作者簡介:郭家兴(1995-),男,硕士研究生,主要研究方向:语音识别;韩纪庆(1964-),男,博士,教授,博士生导师,主要研究方向:语音信号处理、音频信息处理。
0引言
近年来,各种基于深度神经网络的端到端模型在语音识别(AutomaticSpeechRecognition,ASR)领域正逐渐成为研究热点。不同于传统的语音识别模型,端到端模型不再需要将输入语音帧和给定文本标签进行一一对齐,其仅包含一个单独的序列模型,可以直接将输入的语音特征序列映射为识别的文本序列,简化了识别的过程。同时模型不依赖语言模型和发音词典,降低了对专家知识的要求[1-3]。目前,端到端语音识别模型主要包括基于注意力机制的编解码模型[4-5]、连接时序分类(ConnectionistTemporalClassification,CTC)模型[6-7]、基于循环神经网络转换器(RecurrentNeuralNetworkTransducer,RNN-T)的模型[8-9]三种。其中,RNN-T模型是由Graves等人针对CTC的不足所提出的改进方法。相比于CTC,RNN-T可以同时对输入和输出序列的条件相关性进行建模,而且对输入和输出序列的长度没有限制。这使得RNN-T模型更加适合语音任务,因此本文拟围绕RNN-T模型来展开研究工作。
时下的大量研究表明[10-14],端到端语音识别模型仍然存在着语料资源有限所导致训练不充分等一系列问题。而收集大量语音-文本对非常困难,这导致端到端语音识别模型在实际应用中的表现欠佳。最近的工作表明,可以使用纯文本数据来改善其性能。文献[5]用词级语言模型组成RNN输出网格,文献[8]用外部语言模型对搜索算法进行重新打分。文献[15-16]在波束搜索期间合并了字符级语言模型,而文献[17]采用知识迁移的方法,先对大规模外部文本训练语言模型,再将该语言模型中的知识迁移到端到端语音识别系统中。这些方法在解码阶段将端到端模型与其它语言模型结合在一起,可以有效改善语音识别模型的性能,但是都需要额外的步骤来集成和微调单独的语言模块,因此都不是真正意义上的端到端模型。
为了解决上述问题,同时考虑到BERT(BidirectionalEncoderRepresentationsfromTransformers)模型[18]是目前对语言学信息建模最好的模型,本文提出一种将RNN-T模型与BERT模型进行联合优化的方法,就可以高效利用BERT模型所提供的语言学信息,也是一种真正的端到端模型。
1提出方法
1.1RNN-T模型及其局限性分析
1.1.1基于RNN-T的端到端语音识别模型
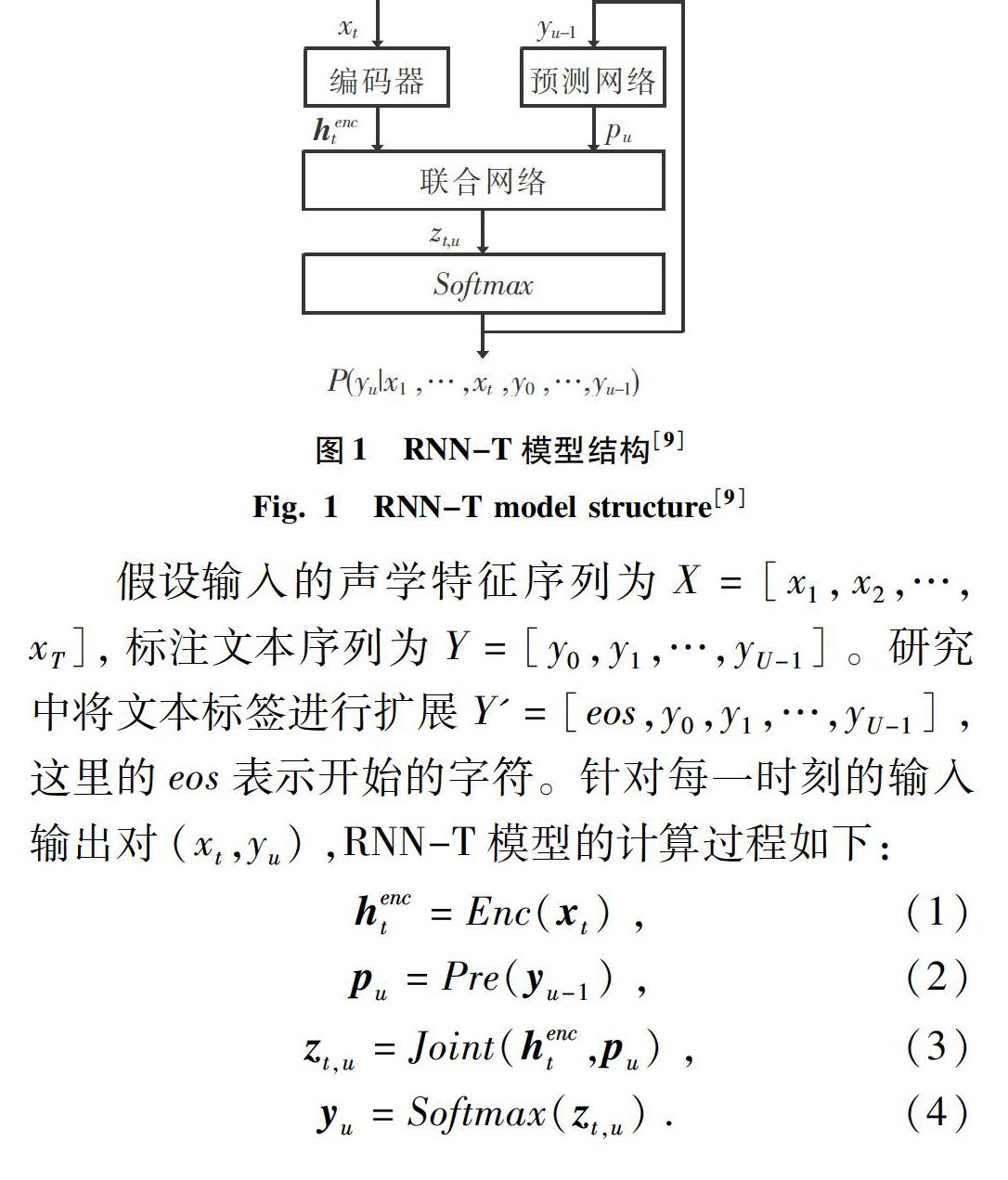
基于RNN-T的端到端语音识别模型能够很好地将声学信息和语言学信息进行联合优化,在端到端语音识别任务中取得了目前最好的性能,通常由3部分构成:编码器(Encoder)、预测网络(PredictNetwork)和联合网络(JointNetwork)。其中,编码器的功能就类似于传统语音识别系统的声学模型,通过将输入的声学特征序列转化为发音基元序列,预测网络给出对应的语言学信息,联合网络的作用是结合语言学信息和发音基元序列产生对应的转录文本,整个模型结构如图1所示。
RNN-T模型不仅解决了CTC中输出之间的条件独立性假设,以及缺少语言建模能力的不足,还使用了共同建模的思路来对语言模型和声学模型进行联合优化;同时,模型具有在线解码等诸多优点,是一种比较有前景的模型。因此,本文首先搭建基于RNN-T结构的端到端语音识别基线模型。
1.1.2RNN-T模型的局限性分析
RNN-T模型也存在不足。一方面,由于在RNN-T模型中,声学建模与语言学建模已被整合在一个网络中,其仅用一个目标函数进行优化,这就要求训练数据必须同时包含输入和输出序列。然而在实际应用中配对数据的获取十分困难。另一方面,RNN-T模型并不能像CTC一样与传统的WFST结合,在第一遍解码中,未能利用大型语言模型的好处,而RNN-T的预测网络所提供的上下文信息,只能在一定程度上缓解这种劣势。
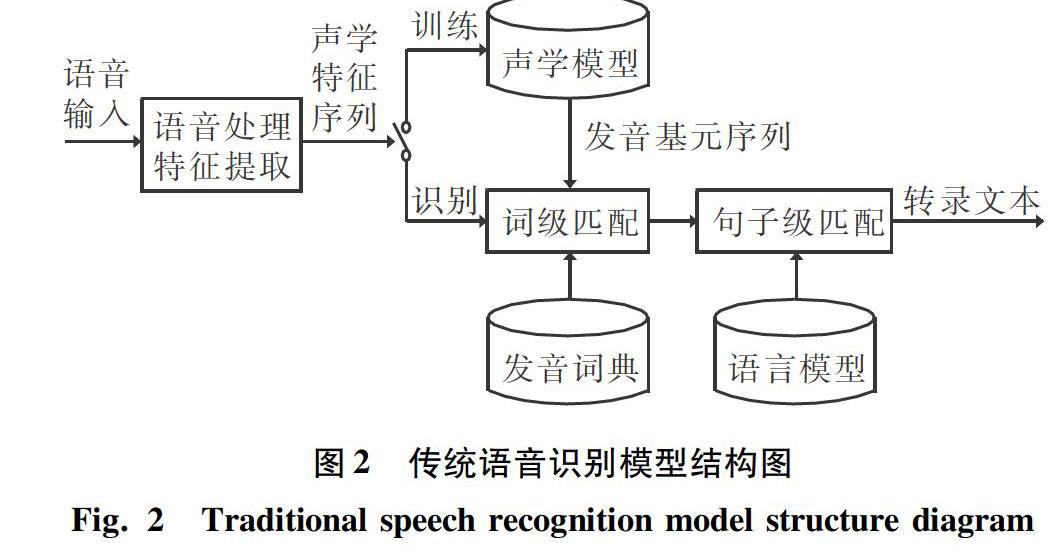
实际上传统的语音识别模型也会出现上述问题。传统语音识别模型结构如图2所示。由图2可知,在传统语音识别模型中,通常采用独立的声学模型和语言模型分别建模声学信息和语言学信息。首先,使用声学模型去识别每一个发音基元,将输入的声学特征序列转化为发音基元序列;然后,在发音词典和语言模型的帮助下,通过搜索算法在发音基元序列中得到一条最佳路径,这条最佳路径就对应了识别的转录文本序列。对于容易出错的词,语言模型没有见过或者很少见过这种搭配,导致搜索算法计算出的概率得分很低。所以要提高语音识别模型的识别准确率,就必须重新扩充语言模型部分,旨在使模型对容易出错的词也能计算出一个比较高的概率得分。因此传统的语音识别模型可以利用比训练集的转录文本多几个数量级的纯文本数据,来单独训练语言模型部分,以更新语言学的知识,从而保持声学模型部分不动。然而,通过扩充语言模型的方式并不适用于RNN-T模型,因為在RNN-T模型中训练数据和扩充数据都必须是平行的文本和语音对。
1.2用BERT模型替换预测网络
根据1.1节中的分析,RNN-T模型在实际应用中表现不好是因为缺乏训练数据,进而导致模型的语言学信息建模不充分。而RNN-T的预测网络所提供的上下文信息,只能在一定程度上缓解这种劣势。鉴于传统语音识别方法可以直接用大量文本数据单独训练语言模型部分,从而扩充模型的语言学信息,在RNN-T模型中,编码器部分相当于声学模型,预测网络相当于语言模型。参考传统语音识别方法的经验,直观有效的方法就是对预测网络进行扩充。因此,本文提出使用更强大的语言模型来替换RNN-T模型的预测网络部分,以在推理时提供更具表示性的语言学信息。
BERT模型是目前对语言学信息建模最好的语言模型[20],与其它语言模型不同,BERT采用双向语言模型的方式,能够更好地融合上下文的信息。同时,预训练的BERT模型在实际使用时,只需要根据具体任务额外加入一个输出层进行微调即可,而不用为特定任务来修改模型结构。本文使用BERT模型来替换RNN-T模型的预测网络部分,使联合网络在进行解码的过程中,通过BERT模型引入外部的语言学信息来进行辅助解码。网络结构如图3所示。替换后的模型在进行解码时,由预测网络提供当前时刻的上下文向量变为由BERT模型提供对应信息。
1.3微调RNN-T模型
1.2节中介绍的将BERT模型与RNN-T模型进行结合的方法,通过使用BERT模型替换RNN-T模型的预测网络部分,实现了在推理时利用BERT模型提供的语言学信息。
然而实验结果表明,直接替换的方法会导致模型的识别性能下降,这是因为BERT没有参与训练,只是在RNN-T模型进行解码时提供相应信息,从而导致了BERT模型和RNN-T的编码器部分不匹配。例如,t-1时刻联合网络预测的字符为“新”,而BERT模型预测下一个字符是“冠”,但语料库中并没有这个词,这就导致联合网络没有见过BERT模型提供的信息,从而出现错误。
解决方法是微调RNN-T模型。具体来说,就是在用BERT模型替换掉RNN-T的预测网络部分后,再用训练语料库重新训练一遍整个模型。在这个过程中BERT模型参与了训练,使联合网络逐渐适应BERT模型提供的信息,进而使编码器和BERT模型相互匹配。
2实验与结果分析
2.1实验数据
实验基于2种普通话语料库:AISHELL-1[21]和AISHELL-2[22]。其中,AISHELL-1包含180h语音数据,AISHELL-2包含1000h语音数据。使用Kaldi提取40维的FBank特征,每个特征都被重新调整为在训练集上具有零均值和单位方差。
在实验中,本文使用AISHELL-1训练RNNT模型,将AISHELL-2的转录文本作为文本数据集,训练BERT模型。
2.2模型结构和实验设置
在基线RNN-T模型中,编码器由5层双向长短时记忆(BidirectionalLongShort-TermMemory,BLSTM)网络组成,每层有700个单元,正向和反向各有350个单元。预测网络由700个门控循环单元(GatedRecurrentUnit,GRU)的单层组成,联合网络结合了声学和语言学信息,由700个单元的单向前馈网络组成,使用tanh作为激活函数。
在實验设置方面,模型采用声学特征作为输入,标注文本作为输出序列,实现端到端的语音识别模型;模型直接进行解码,以提取输出字符序列,而无需使用单独的发音模型或外部语言模型;采用字错误率(CharacterErrorRate,CER)作为语音识别效果的评价指标。
2.3实验结果与分析
本文的实验结果见表1。RNNTransducer是使用AISHELL-1数据集训练的基线模型。RNNTransducer*模型是用BERT模型替换RNN-T模型中的预测网络部分,并在推理时提供语言学信息的结果,可以发现字错误率大幅度上升。这是因为BERT模型并没有参与训练,只是在RNN-T模型解码时提供相应信息,导致BERT模型和RNN-T的编码器部分不匹配。RNNTransducer+Bert是用AISHELL-1数据集对整个模型进行重训练的结果,相当于对联合网络进行微调,使编码器部分与BERT模型之间相互匹配。与基线模型比较后可知,本文提出的方法相对降低了5.2%的字错误率,提高了模型的识别性能。
3结束语
本文针对基于RNN-T的端到端语音识别模型,提出了一种与BERT模型进行结合的方法。该方法通过用BERT模型替换RNN-T中的预测网络部分,对整个网络进行微调,从而使RNN-T模型在训练和解码过程中能够有效利用BERT提供的语言学信息,进而提高模型的识别性能。最后,在AISHELL中文普通话数据集上对所提出的方法进行了评估,实验结果表明,该方法能够获得更好的ASR性能。
参考文献
[1]韩纪庆,张磊,郑铁然.语音信号处理[M].2版.北京:清华大学出版社,2013.
[2]ALTER.语音识别进化简史:从造技术到建系统[J].大数据时代,2019(9):50-59.
[3]PRABHAVALKARR,RAOK,SAINATHTN,etal.Acomparisonofsequence-to-sequencemodelsforspeechrecognition[C]//Interspeech.Stockholm,Sweden:dblp,2017:939-943.
[4]GRAVESA,GOMEZF.Connectionisttemporalclassification:Labellingunsegmentedsequencedatawithrecurrentneuralnetworks[C]//Proceedingsofthe23rdInternationalConferenceonMachineLearning.NewYork,USA:ACM,2006:369-376.
[5]MIAOY,GOWAYYEDM,METZEF.EESEN:End-to-endspeechrecognitionusingdeepRNNmodelsandWFST-baseddecoding[C]//2015IEEEWorkshoponAutomaticSpeechRecognitionandUnderstanding(ASRU).Dammam:IEEE,2015:167-174.
[6]GRAVESA.Sequencetransductionwithrecurrentneuralnetworks[J].arXivpreprintarXiv:1211.3711,2012.
[7]RAOK,SAKH,PRABHAVALKARR.Exploringarchitectures,dataandunitsforstreamingend-to-endspeechrecognitionwithRNN-transducer[C]//2017IEEEAutomaticSpeechRecognitionandUnderstandingWorkshop(ASRU).Okinawa,Japan:dblp,2017:193-199.
[8]CHANW,JAITLYN,LEQ,etal.Listen,attendandspell:Aneuralnetworkforlargevocabularyconversationalspeechrecognition[C]//2016IEEEInternationalConferenceonAcoustics,SpeechandSignalProcessing(ICASSP).Shanghai:IEEE,2016:4960-4964.
[9]BAHDANAUD,CHOROWSKIJ,SERDYUKD,etal.End-to-endattention-basedlargevocabularyspeechrecognition[C]//2016IEEEInternationalConferenceonAcoustics,SpeechandSignalProcessing(ICASSP).Shanghai:IEEE,2016:4945-4949.
[10]KARITAS,WATANABES,IWATAT,etal.Semi-supervisedend-to-endspeechrecognition[C]//Interspeech.Hyderabad,India:dblp,2018:2-6.
[11]BASKARMK,WATANABES,ASTUDILLORF,etal.Self-supervisedSequence-to-sequenceASRusingunpairedspeechandtext[C]//Interspeech.Graz,Austria:dblp,2019:3790-3794.
[12]RENDUCHINTALAA,DINGS,WIESNERM,etal.Multi-modaldataaugmentationforend-to-endASR[C]//Interspeech.Hyderabad,India:dblp,2018:2394-2398.
[13]HORIT,ASTUDILLOR,HAYASHIT,etal.Cycle-consistencytrainingforend-to-endspeechrecognition[C]//ICASSP2019-2019IEEEInternationalConferenceonAcoustics,SpeechandSignalProcessing(ICASSP).Brighton,UK:IEEE,2019:6271-6275.
[14]HAYASHIT,WATANABES,ZHANGYu,etal.Back-translation-styledataaugmentationforend-to-endASR[C]//2018IEEESpokenLanguageTechnologyWorkshop(SLT).Athens:IEEE,2018:426-433.
[15]MAASA,XIEZ,JURAFSKYD,etal.Lexicon-FreeconversationalspeechrecognitionwithNeuralNetworks[C]//ConferenceoftheNorthAmericanChapteroftheAssociationforComputationalLinguistics:HumanLanguageTechnologies.Colorado,USA:ACL,2015:345-354.
[16]HORIT,WATANABES,ZHANGYu,etal.AdvancesinjointCTC-attentionbasedend-to-endspeechrecognitionwithadeepCNNencoderandRNN-LM[C]//Interspeech.Stockholm,Sweden:dblp,2017:949-953.
[17]BAIYe,YIJiangyan,TAOJianhua,etal.Learnspellingfromteachers:Transferringknowledgefromlanguagemodelstosequence-to-sequencespeechrecognition[C]//Interspeech.Graz,Austria:dblp,2019:3795-3799.
[18]DEVLINJ,CHANGMingwei,LEEK,etal.Bert:Pre-trainingofdeepbidirectionaltransformersforlanguageunderstanding[J].arXivpreprintarXiv:1810.04805,2018.
[19]HOCHREITERS,SCHMIDHUBERJ.Longshort-termmemory[J].Neuralcomputation,1997,9(8):1735-1780.
[20]JIANGD,LEIX,LIW,etal.Improvingtransformer-basedspeechrecognitionusingunsupervisedpre-training[J].arXivpreprintarXiv:1910.09932,2019.
[21]BUHui,DUJiayu,NAXingyu,etal.Aishell-1:Anopen-sourcemandarinspeechcorpusandaspeechrecognitionbaseline[C]//201720thConferenceoftheOrientalChapteroftheInternationalCoordinatingCommitteeonSpeechDatabasesandSpeechI/OSystemsandAssessment(O-COCOSDA).Seoul,SouthKorea:IEEE,2017:1-5.
[22]DUJiayu,NAXingyu,LIUXuechen,etal.AISHELL-2:TransformingmandarinASRresearchintoindustrialscale[J].arXivpreprintarXiv:1808.10583,2018.
