高铁车厢内RTM语言清晰度预测及优化
2021-04-17张学飞王瑞乾储丽霞
季 杰,张学飞,王瑞乾,储丽霞
(1.常州大学 城市轨道交通学院,江苏 常州213100;2.常州西南交通大学 轨道交通研究院,江苏 常州213164)
随着目前高速列车运行速度的持续提升,列车车内的声环境恶化[1-2],车内噪声环境首先对乘客的乘车体验感造成极大的影响,其次还会降低车内乘客间交流的言语清晰程度[3],并且还会对乘客接收车内语音广播系统播报信息的准确程度造成干扰,因此有必要对车内语言清晰度进行研究并优化。在如今计算机技术高速发展的年代,基于几何声学开发的一些室内声场预测方法已经达到应用水平,其中声线跟踪法由于其高精度及高效率已经在声场预测领域得到了较为广泛的应用,能够较高效地对声粒子在声场环境中的传播情况进行较好预测,故本文使用声线跟踪法对高铁车厢内的语言清晰度进行预测。
1 理论背景
1.1 声线跟踪法
声线跟踪法(Ray Tracing Method,以下简称RTM)是室内声场计算的常用方法之一,假设声音以声粒子形式沿直线传播,且不考虑其在空间内传播的波动性,另外在可以反射或者衍射的声场空间内,将声源发出的声粒子与声场空间内壁面的碰撞点相连便是声线。目前为止已经有很多在混响声场和长封闭空间声场中使用声线跟踪法进行声场预测的例子:Jang 等在长空间的SEA模型中采用GESEA与RTM 相结合的方法成功预测声音传输情况[4];蒋忠进等使用RTM 根据声音传播的机理计算接收球半径及声线密度,对封闭声场空间进行预测[5];蔡铭等通过对室内声场进行剖分并且结合RTM 显著提高计算效率[6]。
在整节列车车厢的模型中,先在各个扬声器位置上放置合适的声源,然后从声源发出一根声线,求出与车厢内反射面的碰撞点,基于Snell 或Lambert定律形成反射折射之后判断声线是否经过车厢内接收能量的传感器,若未经过则接着求反射声线,若经过传感器便记录声线能量及传播时间等数据,并判断声线能量是否低于事先设定的阈值,若高于则返回继续计算该声线,反之则停止运算并同时发出下一条声线,随之开始计算该点的平均脉冲响应,整个流程图如图1所示。
本文通过RTM确定合适的声线密度、接收点半径及体积,并叠加声线传播能量,得出传感器最终接收到的声压级。初始声线密度的影响因素包括声源发出的初始声线数目、声场空间体积、反射面吸声系数;另外传感器的接收点半径及体积大小会对声线传播能量误差及声线丢失数量有影响,导致预测精度降低[7]。声线跟踪法优点为计算效率高、计算速度快、且较容易被计算机实现,但是计算精度略差并且对低频段的预测有一定误差。
1.2 声线跟踪法计算车内声压级
在RTM 中通过前处理设置声源发出的总声线数目得出声源的初始声功率,通过声源发出的初始声功率L和初始声线数量n来计算初始声线Ln,公式如下:
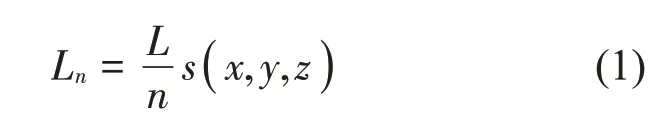
式中:声源发出的声线初始传播路径为s(x,y,z),传感器的接收半径关系式如下:
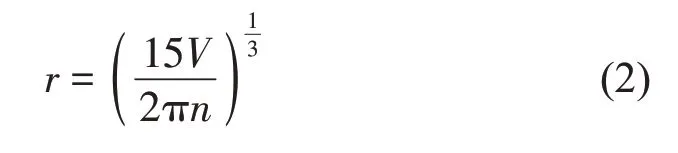
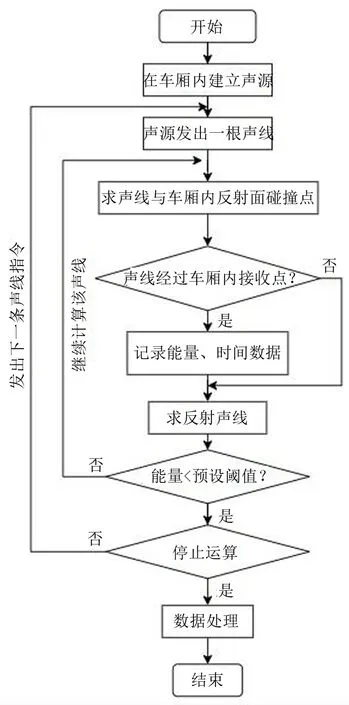
图1 车厢内部声线跟踪法预测流程图
式中:V为室内声场环境的总体积,通过传感器测得各个测点的脉冲响应。
在车内声场空间使用RTM预测时,根据传播时间及声能量计算出车内的声压级,公式如下[8]:

式中:根据各个声线的传播时间对声强进行排序、叠加,得出传感器的脉冲响应In(x,y,z),根据脉冲响应计算出车内声场的声压级,其中ρ0c0表示高铁车厢内空气阻抗,一般取为400 kg/(m2s),将ρ0c0值代入式(3)得出:
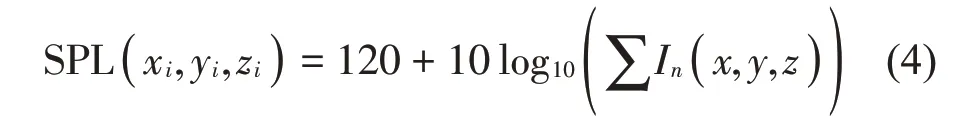
1.3 语言清晰度计算
本文基于RTM 对列车车内声场空间进行仿真预测分析,研究高铁车厢内广播系统扬声器位置和数目对车内语言清晰度的影响。依据国际标准“IEC60268-16(4.0 版,2011-06)”[9]预测车内语言清晰度,该标准在经历4次修订后更完整成熟。Houtgast 等将声音传输系统中的调制转移函数(Modulation Transfer Function,MTF)概念引入到计算语言传输指数(STI)中[10],其计算示意图如图2[11]所示。目前推荐的STI 测量方法有两种,分别是基于采集调制信号的直接法和基于收集脉冲响应信号的间接法,本文使用间接法测量。

图2 调制转移函数示意图
在STI 计算过程中信噪比也较为重要,根据接收到的脉冲响应信号计算出调制转移函数m(F)=m0/mi,其中m取值为0~1,随后将MTF 转化为信噪比,公式如下:

根据信噪比再将数据转化成中间传递指数TI:

传递指数TIy,z由一个频率调制某个频带得出,将这个频带在0.63 kHz~12.5 kHz 内用14个以1/3倍频程为间隔的频率调制成TIy,欲得到语言传递指数,需要对125 Hz~8 000 Hz 之间7个频带的TIy求平均,最后根据不同频带下的清晰度指数计权,计算出车内语言传递指数,公式如下:
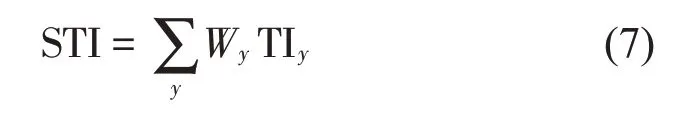
STI间接测量法流程图如图3所示。
2 模型验证与预测结果优化
2.1 RTM仿真模型验证
统计能量法(SEA)与声线跟踪法(RTM)均适用于中高频噪声,为验证本文RTM的正确性,将SEA与RTM及实验室试验结合进行方法验证。
先在VA One中建立预测模型声腔,其中发声室尺寸为5.4 m×4.1 m×3.3 m,接收室尺寸为4.5 m×4.2 m×3.3 m,将尺寸为985 mm×970 mm×8 mm的钢板放置于两声腔之间,声源位于左侧声腔,计算频率为100 Hz~8 000 Hz,声波速为343 m/s,阻尼损耗因子为0.1%,声腔内流体为空气,声源布置及测点布置与实际试验一致,进行RTM 仿真验证及SEA 验证,模型及试验布置如图4所示。由于模型是爆炸视图,所以部分传感器及声源显示在声腔外部。
VA One中可以设置自动声线数目,故在验证模型中采用自动声线数来进行模型验证,分析完成后自动生成34 677条声线。
验证结果如图5所示。基于3种方法的声压级变化趋于一致,随着频率升高声压级缓慢降低,并在2 000 Hz左右出现吸收峰值,由于统计能量法不适用于低频,并且在较小模型中声波长度接近或大于声腔尺寸,故声线跟踪法低频误差略大,因此这两种仿真方法不能精确计算低频声压级,1 250 Hz~6 000 Hz 之间的声压级误差均小于8 dB,在中高频段验证误差较小,结果可信,故本文中基于RTM模型的计算方法是有效的。

图3 STI间接测量法流程示意图
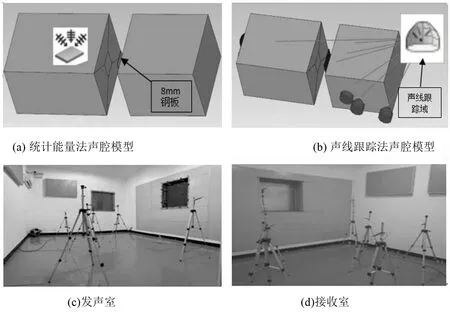
图4 模型图及试验图
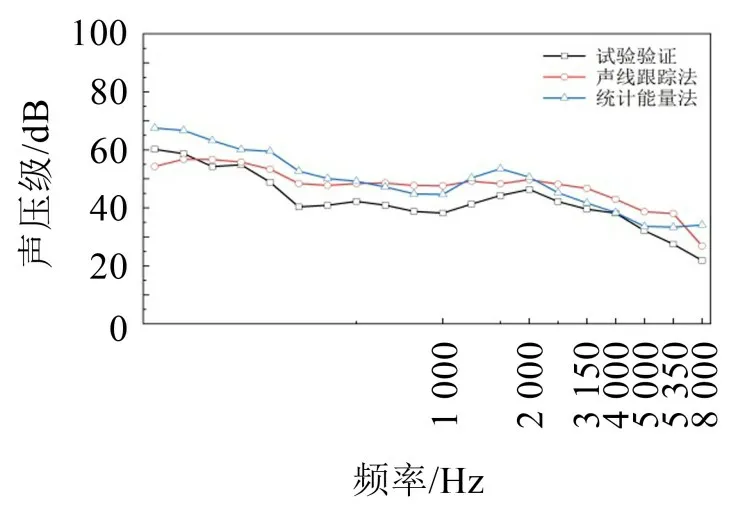
图5 验证结果图
2.2 高速列车模型
验证完成后在VA One中建立高铁车厢模型,模型分为车顶、侧墙、地板、端墙、座椅、车窗等区域,模型由15 849个节点、644个板单元及231个声腔构成,使用几何声学中的RTM并结合列车车内语言清晰度进行研究。为能够正确地模拟真实环境,在列车模型内扬声器位置通过布置球状声源来模拟列车广播系统播报的情况,并将传感器设置到乘客所处位置,用来模拟乘客接收到的声信号,以此来对高铁车厢内语言清晰度进行预测研究并优化。用每个声线跟踪计算声源传播到RTD传感器(Ray tracing domain 声线跟踪域传感器,以下简称RTD 传感器)的声场,计算得出的STI 数值能够较为准确地预测及评价车内语言清晰度,并且在提高语言清晰度的同时STI 呈现出单调递增的趋势[12-13]。在整个模型空间内建立合适的声线跟踪域,借助RTM建模形成声场内部或外部的声学流体子系统,并将声线跟踪域连接到模型内所有的声源、反射面及各个指定坐标点的RTD传感器,所建立的模型连接声线跟踪域后如图6所示。将车厢内部声腔的流体设置为空气,由于车内空气流体的内部损耗因子较低,故将声衰减系数设置为0.1,车厢内地板铺设地毯,座椅及车厢内部侧墙顶板的扩散系数设置为1 %。由于VA One 软件支持声线识别模型空间,故分析前声线数目设置为自动设置,模型内子系统能够进行的反射数与衍射数分别设为5,分析语言清晰度过程中声线通过模型内部连接面进行反射、折射并且反射面各元素之间的最大角度设为15°,连接面类型设置为Reflecting,根据模型内部空间大小及传感器的位置、数目等多方面因素,设置传感器的接收半径为0.03 m,以便传感器更精确地接收声信号,模型的爆炸视图如图7所示。

图6 车厢声线跟踪域连接模型

图7 车厢模型爆炸视图
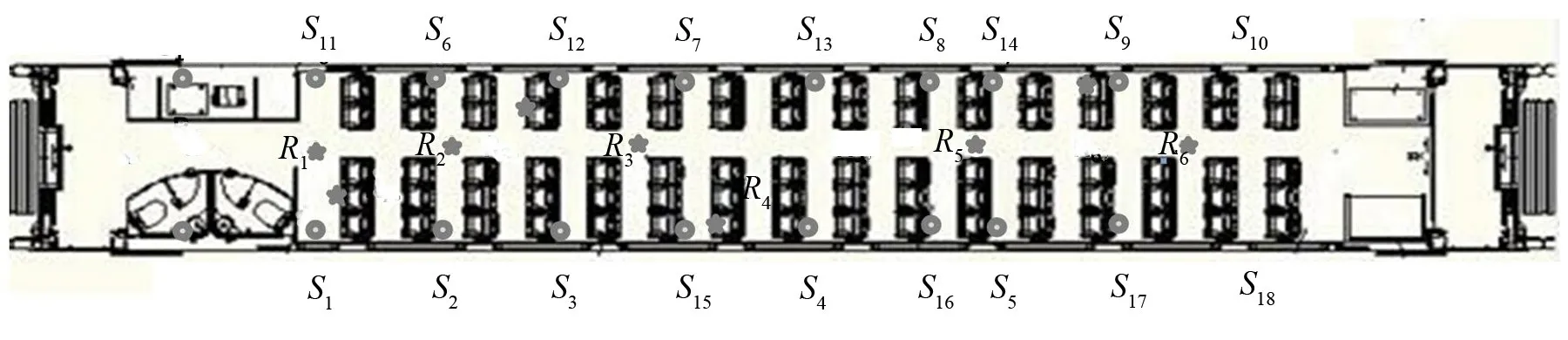
图8 基于车厢内部声线跟踪法预测的声源、传感器测点分布图
2.3 声源及传感器的布置
本文使用声线跟踪法预测的对象是某型高速列车的单节车厢,使用VA One软件进行建模该型高速列车内部尺寸为:长17.6 m,宽2.9 m,高2.2 m。车内声源S1~S18位于车厢内部18个广播系统扬声器处,使用声线跟踪法来模拟车内语言广播系统的声传递,模型内设置的球状声源是用于公共广播的扬声器声源(Compact acoustic sources 紧凑球型声源,以下简称CAS声源),距离车内地板高度均为1.6 m,用来模拟车厢内部公共广播扬声器的发声效果;传感器设置在距离地板高度为1.2 m的所有座椅处及1.5 m高的过道中,模拟乘客在坐姿及站姿情况下人耳所处位置。声源、6个特殊位置传感器布置图(左侧为车头部位)如图8所示。
2.4 预测结果
在使用RTM进行仿真预测的过程中,调用10个声源S1~S10对模型先进行稳态分析,仿真完成后自动生成114 137条声线,并得到RTD 传感器处125 Hz~12 500 Hz频率范围内的声压级,各个频率下车内声压级云图,如图9所示。
由图可见,中低频情况下车厢内声压级较高,且随着频率升高声压级减小,另外从总值来看车厢中部及左侧3 排座位处声压级较高,可以初步说明位于左侧的乘客接收声信号效果比右侧好,且车厢后部区域存在盲区,声压级接收不全面,有待改进。
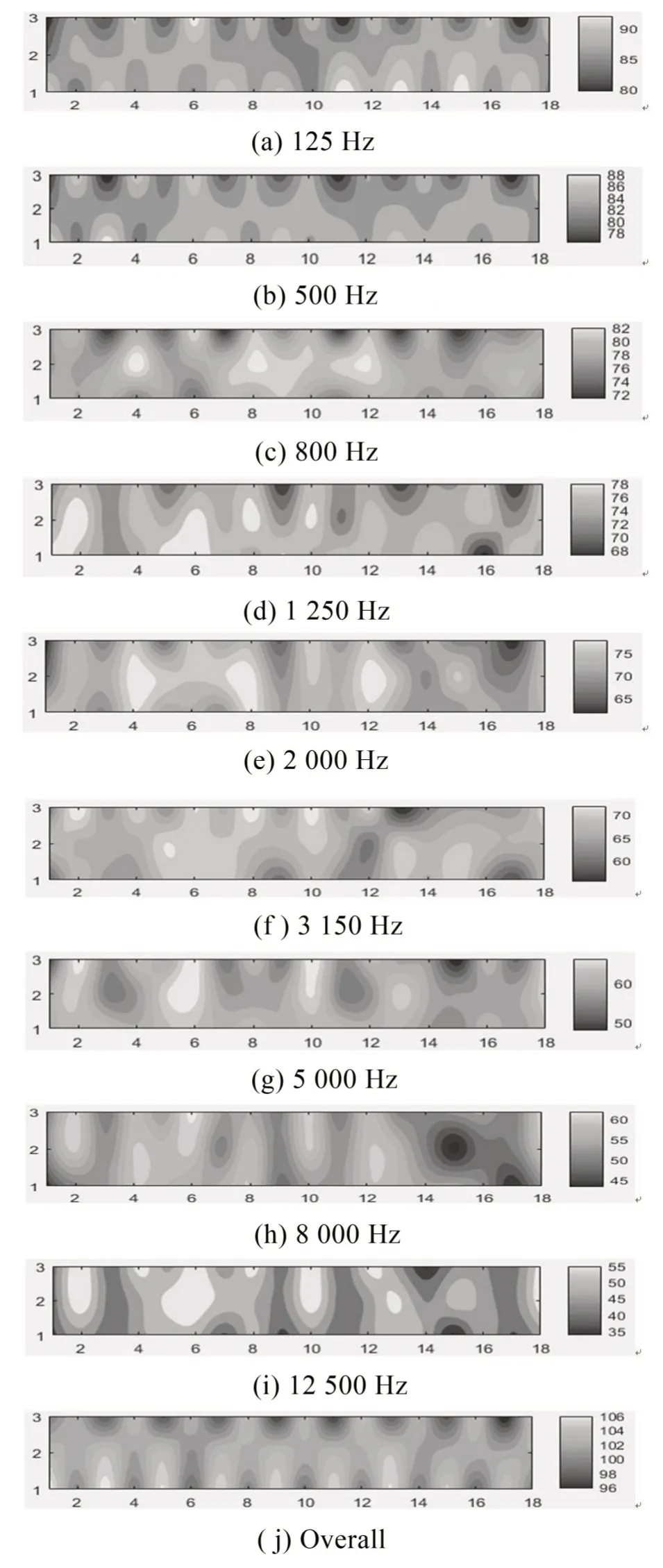
图9 车内声压级分布云图
随后,通过测出的声压级值得出脉冲响应信号,进行语言清晰度分析计算,分别模拟从声源发出男女声的声线,自动生成的声线数为645 896,对传感器测得的数据加权求出平均值,根据距离依次画出STI值的折线图,如图10所示。
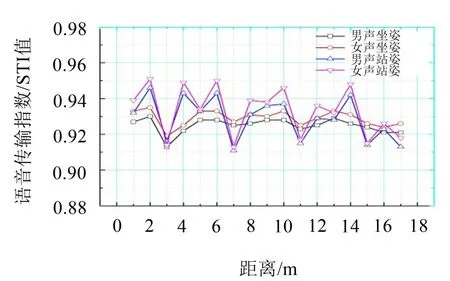
图10 男女声站、坐姿STI值对比图
从图中得出距离车头3米处STI值略差,车厢头部及中部的STI值趋于稳定并较为良好,列车尾部STI值具有随距离增加而下降的趋势,总体来看女声在同样的情况下比男声预测效果更好,并且在同样情况下站姿较坐姿语言清晰度更好,且女声依旧比男声效果好,建议使用女声进行语音播报。
在预测车内语言清晰度过程中,还采用T30 指标作为参考系数,其数值越低语言清晰程度越好。仿真过程中车内测点数目较多,故采用6个特殊位置的测点R1~R6进行125 Hz~8 000 Hz的信号采集,如图8所示。从表1可得,车厢中后部语言清晰度效果略差,并且各个测点处低频率的T30值较高,语言清晰度有待提高。
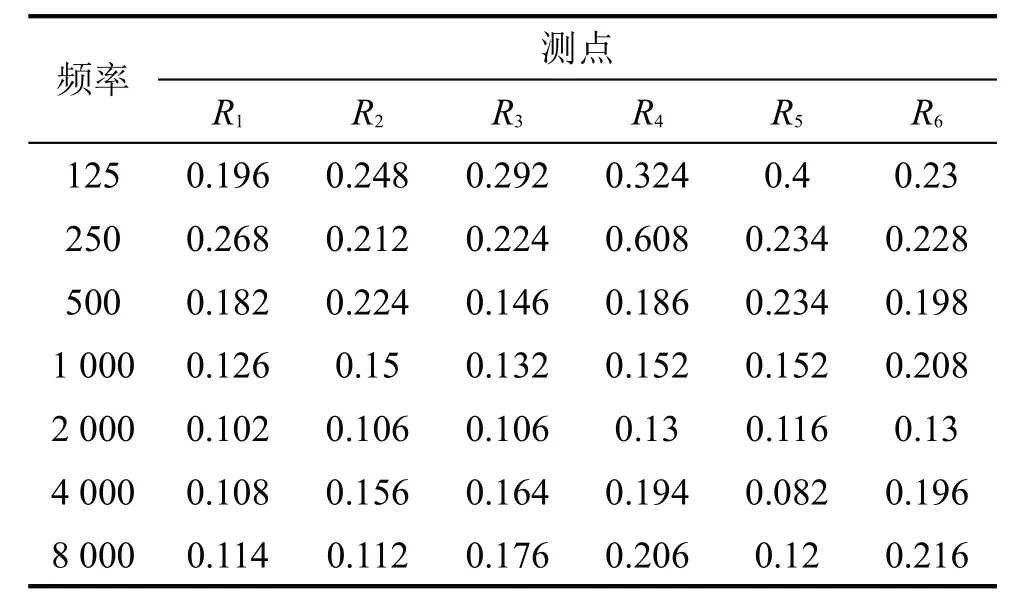
表1 T30仿真结果/S
2.5 优化结果
在进行仿真预测后,文中还进行了一定的优化改进,将车厢内CAS 声源数目提升至12、14、16、18个(S1~S18),分别进行男女声仿真预测,如图8所示。发现并不是声源数目越多STI值越高,语言清晰度的好坏程度与声源数目没有线性关系。其中在使用女声进行预测时,在将声源数目提升至14个的情况下,车内各个位置的STI值都较为稳定,并且不存在清晰度较差的盲区,效果较好,如图11所示。而对男声进行预测时,声源数目增长后清晰度反而不会提高,如图12所示。综合最初预测结果得出使用女声进行语言播报的效果较好。
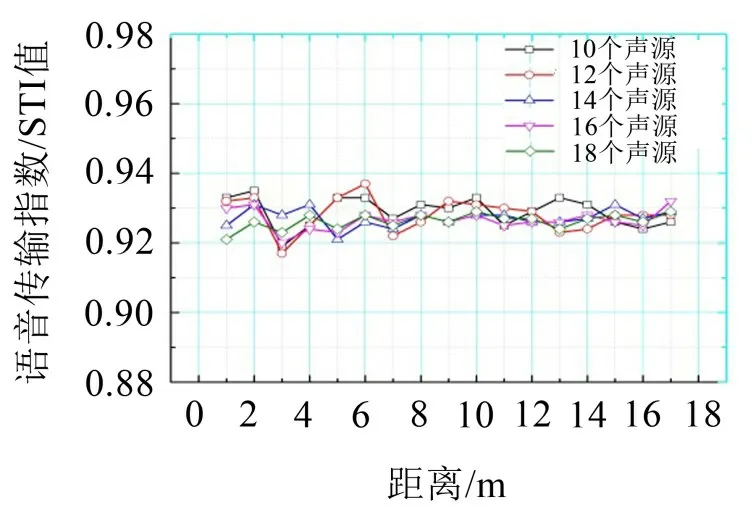
图11 女声声源STI值优化对比图
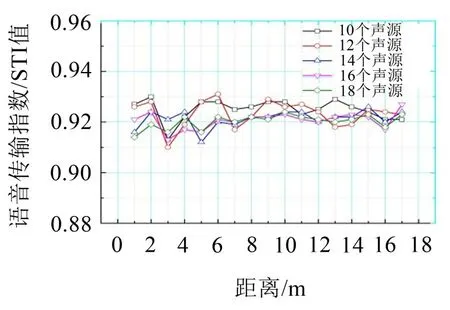
图12 男声声源STI值优化对比图
3 结语
本文先采用声线跟踪法(RTM)与统计能量法(SEA)及试验进行对比验证,证明声线跟踪法的正确性与准确性,并基于RTM 利用最新的STI 国际测量标准对车内语言清晰度进行预测及简单优化,能够得出以下结论:
(1)建立一种通过使用声线跟踪法预测高铁车厢内语言清晰度的模型,对车内声压级、语言传输指数STI、混响时间T30 指标进行预测研究,发现车厢内部靠近转向架区域语言清晰度效果略差,车厢头部及中部的语言清晰度良好;
(2)对于车内广播系统,使用女声效果好于男声,且较男声而言,女声更不容易被干扰,建议使用女声进行广播系统播报;
(3)基于预测得出的结果,改变声源数目及部分声源位置对高铁车厢内语言清晰度有改进效果,但声源数目与语言清晰度并不呈线性关系,而需采用合适的声源数目及位置。在声源数目为14个并采用女声进行播报时车内各处的STI值都较为稳定并且不存在清晰度较差的盲区。本文对改善乘客乘车体验及舒适度有一定的参考价值。
