一种优化的Logistic模型的流行病分类方法
2021-03-17安传波刘宇航周子欣朱家明
安传波,刘宇航,周子欣,朱家明
一种优化的Logistic模型的流行病分类方法
安传波,刘宇航,周子欣,朱家明
(安徽财经大学 统计与应用数学学院,安徽 蚌埠 233030)
对流行病的分类进行定量约束,为了确定某感染病是否为大流行病,分别搜集了以H1N1为代表的“大流行病”重灾区样本和以SARS为代表的“流行病”重灾区样本,并定义每次流行病的“重灾区”。其次分别选取感染率、病死率、医疗条件、人口密度等指标作为解释变量建立二分类Logistic模型,通过得到的被解释变量的预测值(即该病是否为大流行病的概率)来判断该病是否为大流行病。最后,由于疾病流行性问题的复杂性,在模型中依次引入平方项重新回归,通过定义不同的训练集和测试集,得到最优的回归方程,最终得到将病死率的平方项引入回归模型中,模型分类的准确率更高。
分类Logistic模型;重灾区;训练组;测试组;病死率
定义某个传染病是否为大流行病,对国家的宏观调动、疾病的防控、减少疫情带来的损失具有重大意义。在冠状病毒引发的病毒性肺炎(COVID-19)爆发之前,世卫组织只在2009年的H1N1流感爆发期间,宣布该传染病为大流行病。WHO表示:“大流行病(Pandemic)”是指某疾病的发病蔓延迅速,涉及地域广,人口比例大,在短时间内可以越过省界国界甚至洲界形成世界性流行。本文分别对H1N1(大流行病)和MERS、SARS(流行病)爆发期间“重灾区”的相关指标数据进行采样,构造出模型的数据源,以该病是否为大流行病为因变量(二分类)进行逻辑回归,通过求出的回归系数构造判断表达式,再对模型引入非线性解释变量进行优化,对每一个回归方程的数据分为训练组和测试组,用训练组的数据来估计出模型,再用测试组的数据来进行测试,得到最优的回归方程,用解释变量依概率收敛的数值判断传染病是否为大流行病。
国内学者对传染病的分类问题展开了大量的研究工作,但大多都只局限于定性的研究。如袁鸿昌[1]指出流行病学研究方法可以分为实验和观察两大类别进行定性分类。同时,也有少量学者进行了定量分析的研究。如李晓毅等[2]将贝叶斯判别和逐步判别相结合,对突发传染病的实际监控数据进行分析, 与历史数据库中的被人们所认知的各类传染病进行对比研究,对突发传染病进行分类判别。林寰等[3]结合实例论述了累积比数模型、不约束的部分比例模型、连续比模型及相邻比模型等4种模型的构成、特点、适用条件及可以对流行病有序分类得到的结果。胡龙飞等[4]将传染病的医学本质、流行病学原则、检疫等处理检验的有效性等影响因素进行等级评估,通过赋值加权法、危险因素聚类分析,对传染病进行分类。李傅冬[5]通过对近些年浙江省传染病暴发疫情和突发公共卫生事件进行全面整理分析,得出浙江省常见的传染病病种作为本研究的疾病范围。应用贝叶斯分类算法建立分类模型,采用SAS软件完成程序编写,进行流行病的定性分类。
综上所述,学者们从定性定量两个角度确定了流行病分类的主要标准。在定性方面,主要通过感官分析和实验观察,在定量方面则主要采用贝叶斯判别分类和聚类等分类模型进行流行病的判别,都取得了丰硕的成果。
1 指标选取和解释
本文对流行病深入分析,查阅相关文献,最终从流行病的客观反映、传播途径、感染环境等影响因素中选取6类指标,分成定量和定性两类,并对两类指标进行以下几点说明:
(1)感染人数和死亡人数为绝对量,其大小受该国的面积、气温、相关政策等多方面的影响,因此,本文只将感染率和病死率这两个相对量作为回归自变量引入回归方程。
(2)为了增加模型的精确度,用某地区人均GDP(美元)定量衡量该地区的经济状况[6]
(3)对于医疗条件变量,根据相关文献,发达地区的医疗设备、医疗条件都处在领先地位,因此,以某地区否为发达地区将全世界各个地区的的医疗条件分为“优”和“良”两类。
(4)世界人口密度主要分为两个梯度。中国、印度、美国三国人口总量占到全球人口总量的44%左右,远高于其他国家。因此,以中国、印度、美国为代表的第一梯度为人口大国,其余国家均并入第二梯度。具体指标分类如图1所示。
2 数据来源和分析
2.1 定义重灾区
重灾区是指在流行病爆发期间,按照确诊人数的数量,确诊人数总量在总确诊人数中占比超过1%的区域。从百度百科搜索引擎和快易数据网得到H1N1和SRAS两类流行病的样本数据。根据上述定义,分别从H1N1流感样本中选择8个地区,从SARS流感样本中选择4个地区。
2.2 数据的说明
(1)目前,由于新冠疫情在全球仍处在爆炸式增长阶段,且流行病的传播机理和影响因素错综复杂,用某个确定的模型来预测流行病相关问题的准确性有待商榷。
(2)由于大规模流行病爆发的次数不多,一些尚有记载的流行病的具体信息较少,该类数据的获取十分复杂和模糊。因此,如果以疾病种类为采样点,样本数据较少,以各类疾病下疫情较为严重的“重灾区”作为采样点,提高结果的准确度和普适性。
(3)是否为“大流行”病是病毒本身的属性,其具体反应在某个地区或者某个国家在某个时间段内的流行程度。因此,应该用该病在传播期间在某个地区的流行程度来定义,最终选择将不同流行病的“重灾区”相关指标代入的分类模型,以判断其是否为“大流行”。
2.3 数据的处理和可视化
2.3.1 定量数据的处理
为了减弱数据的异方差性,反映被解释变量和解释变量的弹性,将人均GDP取对数,作为独立的解释变量进行回归。
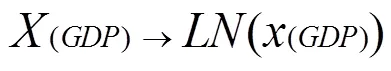
2.3.2 定性数据的分类
根据上述指标解释,本文将医疗条件、人口密度创建为哑变量。

2.3.3 数据的可视化
在定义“重灾区”后,以不同流行病爆发期间的“重灾区”为采样点,由于不同疾病的爆发和流行地区不同,通过对相关样本点的数据进行采集,作为逻辑回归的回归数据。最终确定H1N1选择美国、中国、墨西哥、法国、英国、意大利、印度、挪威8个地区为采样点,SARS选择中国香港、中国台湾、中国、加拿大、新加坡、越南6个地区为采样点,具体数据如图2所示。
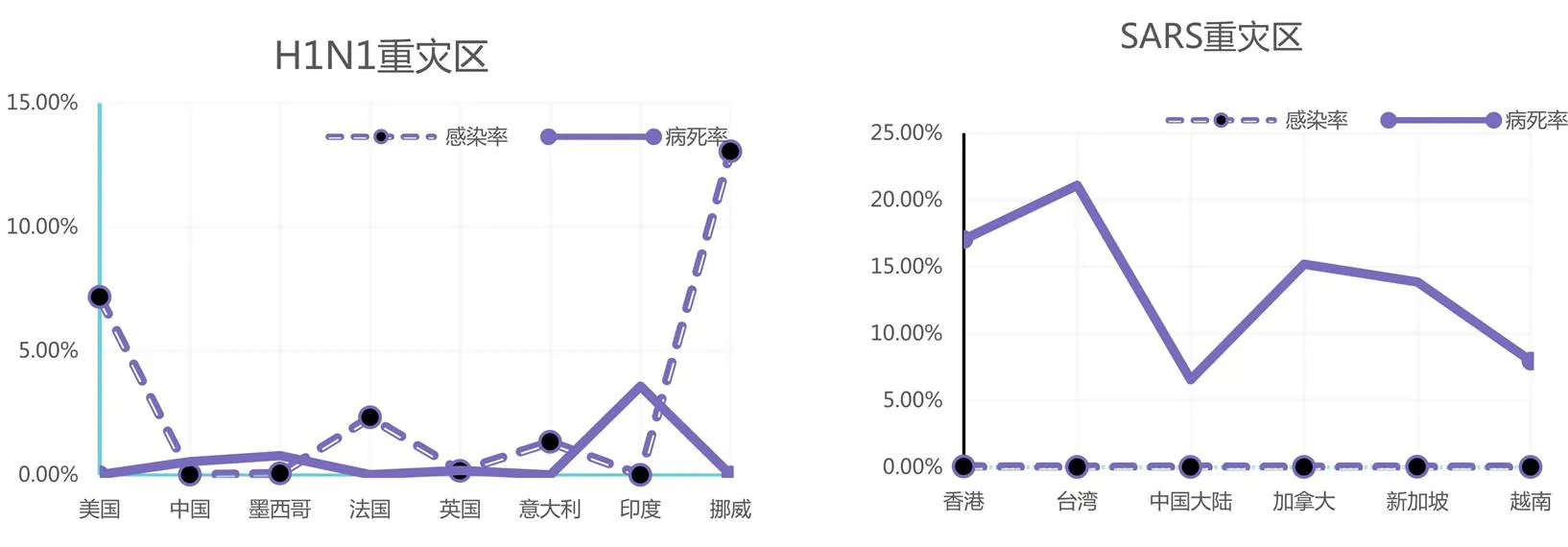
图2 H1N1和SARS重灾区折线图
3 二分类Logistic传染病分类模型
3.1 模型的建立
在社会科学诸如社会学、心理学、人口学以及经济学当中,Logistic回归模型是对二分类因变量进行回归分析时应用最为普遍的多元量化分析方法,既可以有连续的自变量,也可以有分类的自变量,通过Logistic回归分析,可以得到自变量的权重,进而预测事件发生的可能性,其公式如下:
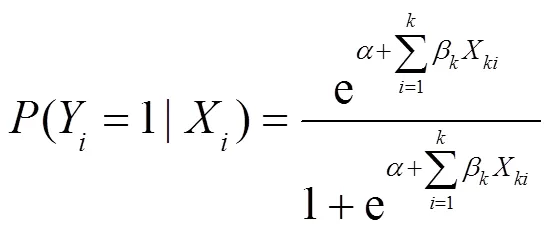
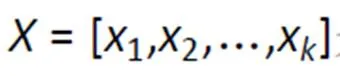
(1)创建因变量。以是否为大流行病的0-1变量为因变量,“0”表示该病不是大流行病,“1”表示该病为大流行病;以之前筛选后的因素为自变量,分别为感染率、病死率、人口密度、经济状况、医疗条件的Logistic模型。

(2)建立连接函数。为了把看成事件发生的概率,选择Sigmoid函数作为连接函数:
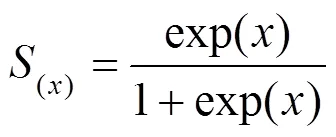
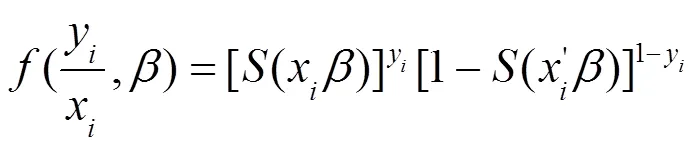
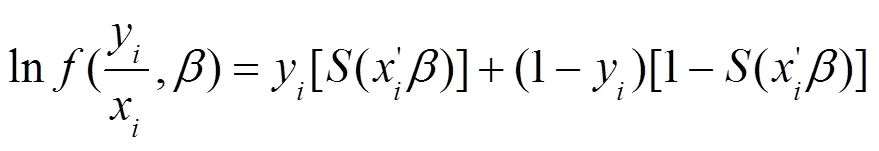
求出样品的对数似然函数,带入数据求出事件发生概率:
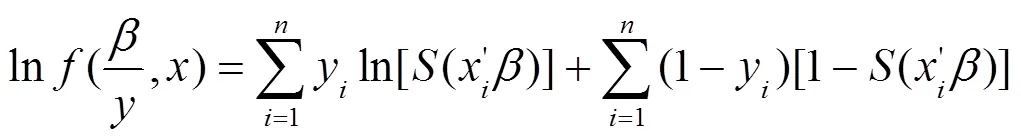
3.2 模型求解
由于引入的变量中存在虚拟变量,为了防止多重共线性的影响,只抽取两个设定哑变量的其中一个进行回归分析。代入提取的数据集,通过SPSS进行逻辑回归,迭代5次得到的回归方程以及回归系数显著性结果为
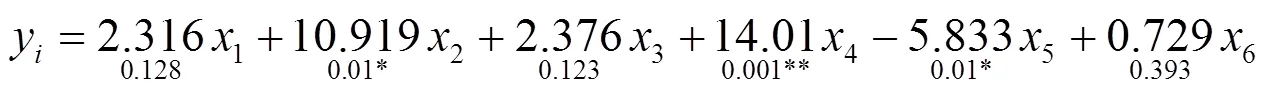
根据回归结果可以看出,该疾病是否为大流行与该病的病死率(0.01*)、持续时间(0.001**)和医疗条件(0.01*)有很大关系,与该地区经济状况关系不大,由于此次虚拟变量中选取人口密度小和经济状况差这两类情况作为参照,可以得到以下结论[7]:
(1)病死率以及疫情持续时间是判断该病是否为大流行的主要依据,某类流行病的持续时间越长,病死率越高,该流行病更有可能为大流行病。这也与现实情况相同,某些病虽然存在很大的传播性和感染率,但是病死率较低,生命是任何防疫工作的中心,只要病死率维持在很低的水平,该病就不会造成太大的恐慌和损失。
(2)可以看到,疫情在医疗条件好的地区爆发的可能性比医疗条件差的地区爆发的可能性小,疫情在人口密度大的地区比人口密度小的地区爆发的可能性大,这也与现实情况相符合。
3.3 模型可行性分析
根据SPSS生成的结果对该回归模型的已知参数进行再预测,结果如表1。
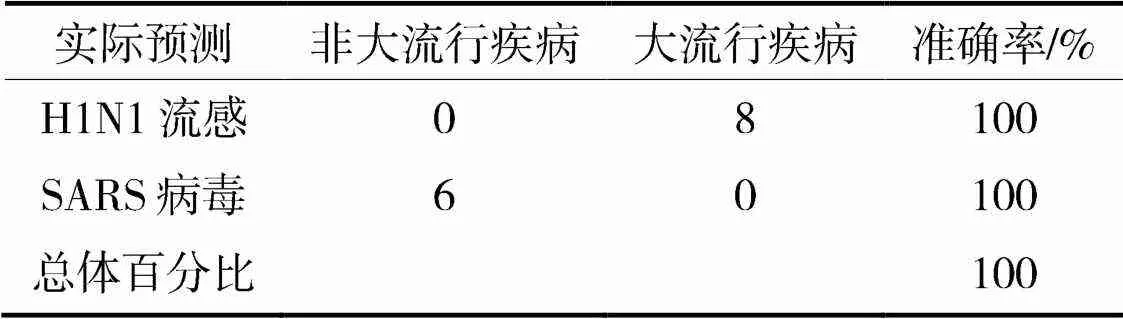
表1 再预测结果表
根据表1,该回归模型对已知样本再预测的准确率为100%,说明该预测模型较为准确。此外,由于目前中国的新冠疫情处于收尾阶段,根据附录提取出此次中国新冠疫情的相关指标进行模型的验证,相关指标具体值如表2所示。

表2 相关指标值表
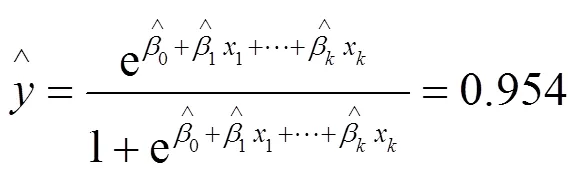
4 模型优化
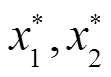
4.1 非线性回归
将感染率和病死率分别平方,依次加入到模型中进行回归,得到3个回归方程的表达式如下:
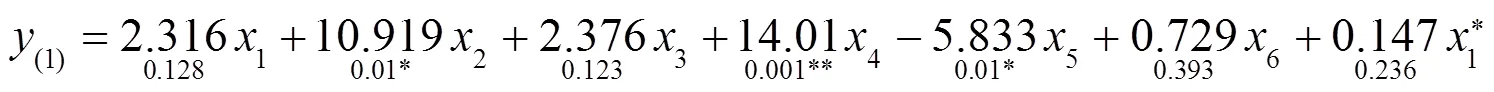
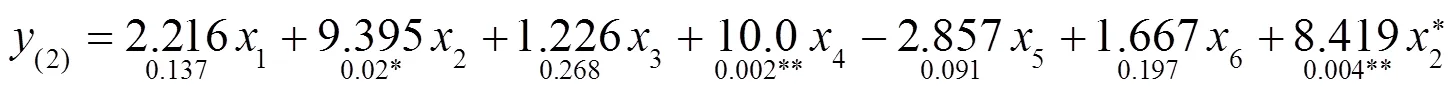
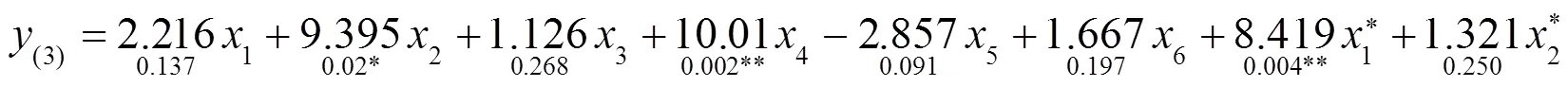
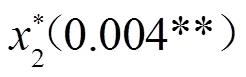
4.2 交叉验证
利用Matlab自带的Randperm()函数在所取样本中随机抽出3个样本,作为测试组,其余样本作为预测组,对以上4组回归函数进行多次预测,平均成功率如表3所示。
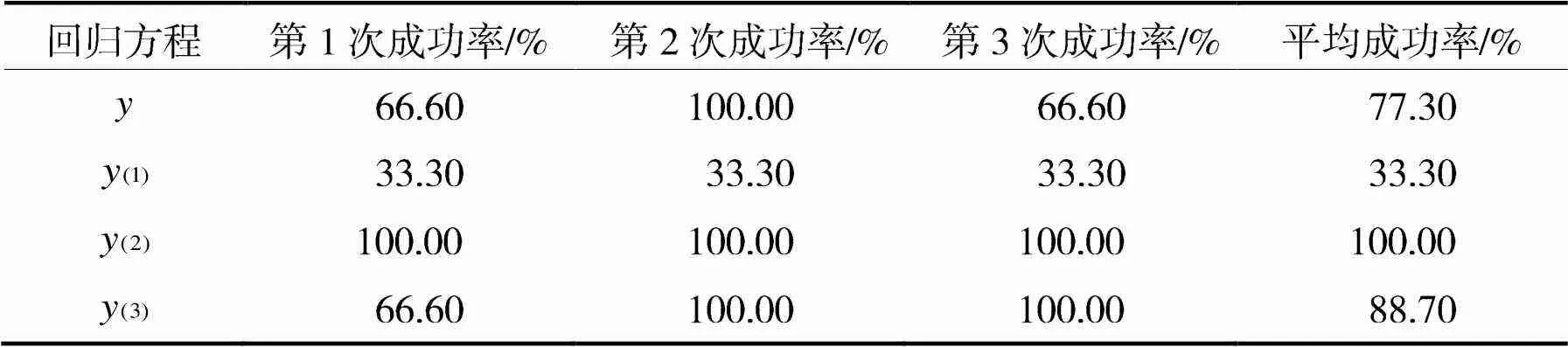
表3 多次预测结果表

5 结束语
通过上述研究,本文利用选取感染率、病死率、医疗条件、人口密度等指标作为解释变量建立二分类Logistic模型,通过得到的被解释变量的预测值(即该病是否为大流行病的概率)来判断该病是否为大流行病。最后利用交叉验证的思想对模型进行了修正,定义不同的训练集和测试集,得到最优的回归方程,最终得到将病死率的平方项引入回归模型中,模型分类的准确率更高。为此可以为有关部门防范“大流行病”提供一下建议[8]:
(1)严格控制病死率是防范该流行病成为“大流行病”的首要考虑因素,相关医疗和生物部门需要及时了解各类疾病的病理结构,加紧药物研发和临床诊断,将病死率控制到最低。
(2)进行紧急隔离,防止疫情持续扩散。人口密度和疫情持续时间对该病是否为“大流行病”都有着决定性作用,要及时疏散人群,坚决落实感染者的隔离工作,及时反馈感染者信息,同时加大社交媒体的宣讲普及,提醒未感染市民做好自我防护,避免疫情大规模扩散。
(3)加强医疗卫生体系的建设,目前全球一体化的进程愈发明朗,国家与国家之间的连接更加紧密,任何地区受到流行病的影响都会波及其他国家,各国之间应该精诚合作,积极建设全球化的医疗卫生系统,为全球人民的生命安全保驾护航。
[1] 袁鸿昌. 流行病学研究方法的类型及其分类原则[J]. 哈尔滨医药,1988(01): 61-64
[2] 李晓毅,徐兆棣. 突发传染病的贝叶斯逐步分类判别[J]. 中国卫生统计,2009, 26(03): 323-324, 327
[3] 林寰,潘晓平,李苑. 流行病学中有序分类结果变量的回归模型介绍及应用[J]. 现代预防医学,2006(05): 704-706
[4] 胡龙飞,吕志平,林爱华. 中国国境口岸监测传染病分类研究(一)——应用赋值加权和聚类分析法对传染病进行分类[J].中国国境卫生检疫杂志,2006(02): 65-72
[5] 李傅冬. 基于贝叶斯分类算法的浙江省常见传染病辅助分类模型研究[D]. 杭州:浙江大学,2013
[6] 原华荣. 世界人口分布的趋势及特征[J]. 西北人口,1991(04): 25-30
[7] Weiss R A, Mcmichael A J. Social and environmental risk factors in the emergence of infectious diseases[J]. Nature Medicine, 2004, 10(12): S70-76
[8] 熊成龙,蒋露芳,姜庆五.-冠状病毒引起人类疾病的流行与控制[J]. 上海预防医学,2020(1): 20-20
Epidemiological classification method based on optimized logistic model
AN Chuan-bo,LIU Yu-hang,ZHOU Zi-xin,ZHU Jia-ming
(School of Statistics and Applied Mathematics, Anhui University of Finance and Economics, Anhui Bengbu 233030, China)
In this paper, we quantitatively restrict the classification of epidemics. In order to determine whether an infectious disease is a pandemic, we collected samples of "pandemic" severely affected areas represented by H1N1 and "epidemic" severely affected areas represented by SARS. Define the "heavy disaster area" for each epidemic sample. Secondly, select the infection rate, mortality, medical condition, population density and other indicators as explanatory variables to establish a binary classification logistic model, and judge the disease by the predicted value of the explained variable (that is, the probability of whether the disease is a pandemic) whether it is a pandemic. Finally, due to the complexity of the disease epidemic problem, we re-regressed by introducing square terms in the model in turn, by defining different training sets and test sets, we got the optimal regression equation, and finally got the square term of the mortality rate into the regression model in the model classification accuracy is higher.
classification logistic model;heavy disaster area;training group;test group;mortality
2020-09-21
国家自然科学基金项目“自然资源资产与经济增长、经济安全的协调机制与策略研究”(71934001);安徽省教研项目“大数据背景下学科竞赛对新经管人才创新能力培养研究”(2018jyxm1305);大数据背景下数学类专业课程“数学建模”教学内容的研究(acjyyb2018006)
安传波(2000-),男,安徽六安人,本科,主要从事经济统计学应用研究,839072347@qq.com。
朱家明(1973-),男,安徽宿州人,副教授,硕士,主要从事应用数学研究,zhujm1973@163.com。
R181.3;O212.1
A
1007-984X(2021)01-0083-06
