基于逻辑回归的四川青川县区域滑坡灾害预警模型
2021-01-21方然可刘艳辉苏永超黄志全
方然可,刘艳辉,苏永超,黄志全
(1.华北水利水电大学,河南 郑州 450045;2.中国地质环境监测院(自然资源部地质灾害技术指导中心),北京 100081;3.洛阳理工学院,河南 洛阳 471023)
四川省青川县位于四川盆地的北部边缘,龙门山断裂带的地震多发带,辖区内山高坡陡,地形切割强烈,地质构造复杂,是滑坡等地质灾害高发区。近年来,特别是“5.12”汶川地震后,多次区域强降水作用下,滑坡灾害频发,点多面广的防灾形势日益严峻,居民正常生产生活受到严重威胁。在区域尺度上,开展降水诱发的区域滑坡灾害预警十分关键。自2003年以来,中国广泛开展各级地质灾害气象预警,在提高社会公众的防灾减灾意识和有效减轻地质灾害造成人员伤亡和财产损失等方面起到了积极作用[1-3]。
预警模型是成功开展地质灾害气象预警的关键,为此,大量学者开展了不懈的努力和探索。区域地质灾害预警模型主要分为统计预警模型和动力预警模型两大类,能在区域尺度得到实际应用的主要是统计预警模型,特别是基于统计原理的临界降水阈值模型[4-6],在美国、中国香港、日本等滑坡早期预警系统中都得到了广泛应用。2009年以来,刘传正等[2-3]提出了显式统计预警原理,多位学者针对不同地区的特点,构建了相应的统计预警模型[7-13],有效支撑了中国大陆各级地质灾害气象预警工作。但预警模型研究受制于研究区滑坡诱发机理复杂、调查监测数据不足等限制,仍存在区域预警精度有限、精细化不足等问题。
2015年,原国土资源部和中国气象局在四川省青川县建立了第一个国家级地质灾害气象预警试验区,针对地质灾害预警的地质环境专项调查监测、降雨加密站点布设与监测等工作逐步展开并取得了丰硕成果[14-15]。多年的数据积累和系统的预警专项调查,为区域滑坡灾害预警模型研究奠定了雄厚的数据基础;人工智能和大数据的蓬勃发展,为预警模型发展提供了新的方法。
本文以四川省青川县为研究区,开展了基于逻辑回归算法的区域滑坡灾害预警模型研究并校验,推动了人工智能在滑坡灾害预警领域中的应用,有效支撑了我国正在开展的区域地质灾害气象预警业务,具有重要理论意义和应用价值。
1 数据获取与清洗
本研究区为四川省青川县,位于川、甘、陕交界处,辖36个乡镇,总人口约22万。研究数据主要来源于四川省青川县1:5万地质灾害与地质环境调查成果、青竹江流域地质灾害调查成果、地质灾害灾情直报系统、青川县加密雨量监测数据以及青川预警试验区补充调查监测成果等[14-16]。
1.1 滑坡和非滑坡(正负样本)数据
据调查成果[16],截至2015年底,青川县共发生崩塌、滑坡、泥石流和不稳定斜坡灾害1 672处,其中崩塌262处、滑坡643处、泥石流45处和不稳定斜坡722处。灾害类型以不稳定斜坡最多,其次为滑坡、崩塌,泥石流数量相对少。本文研究对象为广义滑坡,包含了崩塌、滑坡和不稳定斜坡。青川县广义滑坡占总数的97.3%,是青川县地质灾害的最主要灾种。
正样本是指已经发生滑坡的点,正样本的采样一般以历史滑坡编目数据为依据进行筛选。筛选标准为具有确定的空间地理坐标和时间坐标(一般精确到日)。负样本是指没有发生滑坡的点,无法直接获取。本研究以正样本为基础,通过时空采样确定负样本[17]。空间上,在正样本120 m(3倍的预警网格单元大小)缓冲区外空间随机采样(正负样本采样比例1∶2),确定负样本的空间位置;然后在汛期范围内随机时间,确定负样本的时间属性。最终确定2010—2018年滑坡灾害正负样本1 826个:613个滑坡点(正样本)和1 213个非滑坡点(负样本)。
1.2 地质环境数据
孕育滑坡灾害的地质环境数据主要包括地形地貌、地层岩性、地质构造、沟谷水系,以及人类工程活动等。据相关分析结果[16],地形地貌是滑坡发育的重要条件,地层岩性是滑坡发育的物质基础条件,控制了青川县滑坡灾害的空间分布;地质构造特别是断裂带的分布对滑坡灾害发育影响明显;沟谷水系广泛分布,直接影响着斜坡稳定性;人类工程活动,特别是道路切坡、房屋建筑等,对自然斜坡进行改造,诱发或加剧了滑坡灾害的发生发展。因此,在前期研究成果基础上,本文选取了坡度、地貌、地层岩性、断裂、房屋分布等11个地质环境因子参与模型构建。
1.3 降雨诱发数据
降雨是研究区滑坡灾害发生的主要诱发因素。本研究降雨数据主要来源于气象部门,收集整理了青川县域43个加密雨量站点逐日雨量数据,通过空间插值,以公里网格为单元构建雨量数据库,保证了降雨数据的站点密度和监测精度。选取当日雨量,前1~15日逐日雨量等16个降雨因子参与模型构建。
1.4 训练样本集
以200 m×200 m为单元对研究区进行网格剖分(约82 000个网格单元),分别匹配27个影响因子(包括坡度等11个地质环境因子,当日雨量等16个降雨因子)作为输入特征参数,滑坡是否发生(滑坡正样本为1,非滑坡负样本为0)作为输出特征参数。构建了青川县区域滑坡灾害预警训练样本集,样本个数1 826个(图1),样本集输入特征及参数见表1。

图1 青川县区域滑坡灾害预警训练样本集Fig.1 Training sample set of regional landslide disasters in Qingchuan County

表1 训练样本输入特征及参数Table1 Input characteristics and parameters of the training samples
1.5 数据清洗
数据清洗是指对数据进行缺失值插补和异常值(噪音值)识别处理[18]。在机器学习模型构建过程中,训练样本集的好坏直接决定了模型准确性和泛化能力。原始数据集中常存在人工错误、数据传输误差、设备故障和地质信息模糊等问题,严重影响着训练样本集的质量。因此,对原始数据集进行数据清洗,是有效提升模型精度的必要基础。
数据清洗方法要根据数据实际情况进行选择。例如,若空值较少可直接删除,若空值所占比例较大,则不可直接删除,一般可用均值代替补全。对于离群值问题,因离群值不一定是错值,一般通过降低权重或是增加此类样本方式进行清洗[19-20]。
2 模型构建与检验
2.1 算法与工具
逻辑回归算法是一种常用的非线性二分类因变量回归统计模型,在机器学习领域也得到了广泛使用。该算法通过极大似然估计法估计参数,具有一致的渐进正态性[21-22]。与一般线性回归算法的区别在于逻辑回归算法通过Sigmoid 函数可以把输出结果约束在[0,1]之内:由图2所示,逻辑回归算法输出Y值介于0~1 之间,因此可以引入阈值的概念,从而对输出Y进行二分类。例如设置阈值为0.5,算法输出大于0.5 则判定为1,反之则判定为0。


图2 Sigmoid 函数Fig.2 Sigmoid function
滑坡灾害预警时,影响滑坡是否发生的地质环境、降雨等因素可以作为自变量,滑坡发生或不发生可以作为分类因变量。设P为滑坡发生的概率,取值范围为[0,1],1-P即为滑坡不发生的概率。P/(1-P)为滑坡发生与不发生的概率比值,对其取自然对数ln[P/(1-P)]:
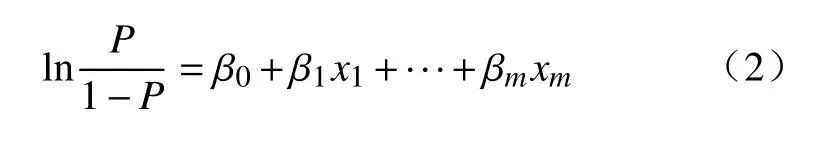

式中:P-滑坡发生概率;
x1,x2,···,xm-影响因子;
β0,β1,···,βm-逻辑回归算法的回归系数。
国内外学者在该领域也开展了相应探索,Lee S 等[23]和Ohlmacher G C 等[24]分别在韩国龙仁地区和美国堪萨斯州东北地区,选择诱发滑坡的致灾影响因子,采用了逻辑回归算法开展滑坡预测。李铁锋等[25]以长江三峡为研究区,把有效雨量与Logistic 回归模型结合,建立了预警模型。孙德亮[26]应用逻辑回归算法,设置了不同阈值开展对比分析,建立了滑坡灾害易发性分区模型等。
本文选取逻辑回归算法开展滑坡灾害预警模型训练。模型训练过程通过Python 语言实现,调用了sklearn 库里的LogisticRegression模型。
2.2 模型构建与优化
按照4∶1的比例,将青川县训练样本集(图1,表1)划分为训练集和测试集,进行训练和校验。采用贝叶斯优化算法、五折交叉验证开展模型参数优化。目前最常用的模型参数优化方法包括传统方法和超参数优化算法。传统方法,也称为网格搜索法,方法优化精度和速度成反比。为了参数优化更高效,出现了超参数优化算法—贝叶斯优化算法[27]。贝叶斯优化算法采用了高斯过程,通过增加样本数量来拟合目标函数分布,目标函数通过交叉验证精度来进行优化,每次迭代都会输出一次超参数,在寻找最优值的过程中优化超参数。通过贝叶斯优化算法,对逻辑回归模型的正则化指数C值进行参数优化,最终得到模型最优参数,C=2。
基于优化后的Logistic模型,分别设置0.25,0.5,0.75 三种不同的阈值对模型结果进行二分类,得到混淆矩阵,见表2。
根据表2,对比分析三种阈值分类结果的精度,可见,当阈值取0.5时,模型总精度最高。
2.3 模型检验
模型检验从3个方面来进行:
(1)准确率(Accuracy,ACC),表达的是模型的精度。模型准确率,是判断模型预测分类正确的样本数和总样本数的比值。另外,还有精确率(Precision)、召回率(Recall)和F1值等指标。
(2)ROC曲线和AUC值,表达的是模型泛化能力。ROC(Receiver Operating Characteristic)曲线是一个画在二维平面上的曲线;AUC(Area Under Curve),即ROC曲线下的面积。通常,AUC的值介于0.5 到1.0之间,AUC值越大,说明模型表现越好。

表2 不同阈值下的Logistic 回归分类结果混淆矩阵Table2 Confuse matrix of the result of the logistic regression classification under different thresholds
(3)学习曲线(Learning Curve),描述模型拟合程度,判断模型是否存在过拟合或欠拟合。
使用测试集对Logistic 回归模型的准确率和模型泛化能力指标进行评估。评估结果见表3和图3。可见,模型准确率为0.943,AUC值为0.980,模型准确率和泛化能力均较好。

表3 Logistic 回归模型分类Table3 Logistic regression model classification report

图3 逻辑回归模型学习曲线和ROC曲线Fig.3 Learning curve and ROC curve of the logistic regression model
开展区域滑坡实际预警时,按训练样本特征属性格式,输入研究区各预警网格单元27个特征属性,调用基于逻辑回归算法训练保存好的模型开展概率预测,依据模型输出概率P划分滑坡灾害预警等级。输出概率的预警等级,可参考地质灾害气象风险预警标准[28]中的预警等级划分,也可根据研究区具体情况微调确定。考虑到青川县基于逻辑回归算法的预警模型训练中阈值设定为0.5,结合研究区具体情况,将地质灾害气象预警概率等级划分标准调整如下,当输出概率P≥40%且P<60%时,发布黄色预警;当输出概率P≥60%且P<80%时,发布橙色预警;当输出概率P≥80%时,发布红色预警,见表4。

表4 预警等级划分Table4 Early warning level division
3 结论
(1)以清洗后的2010—2018年滑坡灾害为正样本,以1∶2的比例采样负样本,以200 m×200 m为网格单元,构建了青川县区域滑坡灾害训练样本集。训练样本数量为1 826个,其中正样本为613个,负样本为1 213个。各训练样本包含了27个输入特征参数(地质环境因子、降雨因子等),1个输出特征参数(滑坡正样本为1,非滑坡负样本为0)。
(2)基于1 826个训练样本,采用逻辑回归算法开展滑坡灾害预警模型学习训练。以训练样本集的80%作为训练集,20%作为测试集,进行5 折交叉验证,采用精确度(Accuracy)、ROC曲线和AUC值校验模型准确度和模型泛化能力。采用贝叶斯优化算法对模型参数进行优化。结果显示,设置阈值为0.5时,混淆矩阵的总精度最高,模型准确率为0.943,AUC值为0.980,模型准确率和模型泛化能力均较好。
(3)开展区域滑坡灾害实际预警时,可调用基于逻辑回归算法训练好的模型输出概率,根据概率分段确定预警等级,输出概率P≥40%且P<60%时,发布黄色预警;输出概率P≥60%且P<80%时,发布橙色预警;当输出概率P≥80%时,发布红色预警。
今后,将在青川县区域滑坡灾害预警中进一步校验模型的准确性。
