2007–2013 年华北平原典型灌溉农田生态系统日通量数据集
——以栾城站为例
2020-10-26张玉翠姜寒冰张传伟沈彦俊
张玉翠,姜寒冰,3,张传伟,3,沈彦俊*
1. 中国科学院遗传与发育生物学研究所农业资源研究中心/中国科学院农业水资源重点实验室/河北省节水农业重点实验室,石家庄 050022
2. 中国科学院栾城农业生态系统试验站,石家庄 051430
3. 中国科学院大学,北京 100049
数据库(集)基本信息简介

数据库(集)组成 本数据集由栾城试验站通量观测数据组成,含1个Excel文件,包括5个表单,分别为农田蒸散量、降水量、净辐射量、感热通量、二氧化碳净交换量数据记录。每个表单分别包括2192条日尺度数据和6条生育季尺度数据。
引 言
陆地生态系统碳水循环是地球化学循环的核心过程。研究陆地生态系统碳水循环过程对于人类调节生物圈–水圈–大气圈相互作用,对维持全球生态系统的物质运输与能量循环具有重要的指导意义,也是人为适应和干预全球变暖,缓解水资源供需矛盾的战略需求[1-2]。经过长期的理论发展和技术改革,基于微气象学原理的涡度相关技术已成为陆地生态系统与大气间的CO2和水热通量交换的标准观测手段之一[2]。涡度相关系统的观测原理就是将空气流动视为无数个涡流,通过物理量的脉动与垂直风速脉动的协方差计算湍流通量[3]。目前,涡度相关系统已被广泛应用于陆地生态系统碳水循环过程研究,长期连续的高频率联网观测积累的通量数据可为碳水循环机理、碳源碳汇的时空分布特征以及生物地球化学循环模型的优化等相关研究提供有力的数据支撑[4-5]。
2001 年,中国陆地生态系统通量观测研究网络(ChinaFLUX)依托中国生态系统研究网络(CERN)成立,经过十几年的发展,ChinaFLUX 目前已建设完成100 余个通量观测站,覆盖森林、草地、农田等多种类型的陆地生态系统,形成了全国尺度的碳水通量观测研究体系,实现了我国通量观测事业从起步到国际前沿水平的跨越式发展[6-8]。作为ChinaFLUX 重要成员之一的中国科学院栾城农业生态系统试验站(以下简称“栾城试验站”)始建于1981 年,隶属于中国科学院遗传与发育生物学研究所农业资源研究中心(简称“中科院农业资源研究中心”)。1989 年加入CERN,成为第一批基本站。2005 年成为国家生态系统观测研究网络(CNERN)台站,同年成为ChinaFLUX 农田生态系统的重要观测站点之一。
栾城试验站涡度相关系统长期连续的碳水通量联网观测开始于2007 年,本数据集包含了栾城试验站2007–2013 年的碳水通量观测数据,选取了其中较为重要的组成部分,包括农田蒸散量、降雨量、净辐射量、感热通量和二氧化碳净交换量,整理形成了日尺度和生育季节尺度数据产品,并以此数据论文形式对数据集进行系统性描述,以便于读者溯源定位,理解数据集内涵,推动数据开放共享和规范化使用。
1 数据采集和处理方法
1.1 数据来源及采集方法
基于ChinaFLUX 的顶层设计,经过观测塔选址、观测仪器选型和野外观测系统安装与调试等技术工作,中科院栾城农业生态系统试验站于2007 年11 月6 日正式开始长期连续的碳水通量联网观测。本数据集为2007 年10 月1 日至2013 年9 月30 日的农田碳水通量数据,其中2007 年10 月1日至11 月5 日的数据由历年相应通量项平均值并结合栾城试验站气象数据、土壤含水量和参考蒸散等插补得到。
栾城试验站全称为中国科学院栾城农业生态系统试验站(台站代码:LCA),该站地处太行山山前平原中部(37°53′N、114°41′E,海拔50.1 m),暖温带半湿润季风气候,年平均气温12.9℃,多年平均降雨量490 mm(2007–2013 年),无霜期200 天,全年平均日照时数2608 小时,≥0℃的积温为4710℃,雨热同期,适宜农业发展。土壤以潮褐土为主,质地为壤土,随土层由浅到深依次为粉砂壤、壤土和粘壤。农业生产以华北地区种植面积最为广泛的冬小麦–夏玉米一年两熟轮作制农田为主。冬小麦10 月初播种,次年6 月中旬收获;夏玉米6 月中旬播种,9 月底收获。其中冬小麦冠层高度约为1.0 m,夏玉米冠层高度在2.0 m 左右。
结合上述植被类型、冠层高度以及通量观测下垫面要求,栾城站架设了通量观测塔,并将碳水分析仪安装高度设置为3.5 m。涡度相关系统主要由开路式CO2/H2O 红外分析仪和三维超声风速计组成,同时辅有辐射分量和常规气象要素(降雨和空气温湿度等)的同步观测,观测设备型号及制造商等信息见表1。数据观测和存储除人工观测降水量外由系统自动完成,通常情况下每0.5–1 个月定期维护一次,每两年校准一次。

表1 各观测系统主要测定要素、关键传感器型号、制造商信息及安装高度
通量观测塔下垫面为充分灌溉管理下的典型冬小麦–夏玉米一年两熟轮作制农田生态系统,下垫面均匀且地势平坦,风浪区(>350 m)足够大。观测系统利用CR5000 型数据采集器以10 Hz 的频率进行原始数据采样和存储,连续自动监测生态系统的碳水通量,每30 min 输出一组平均值。常规气象要素的观测记录输出频度同样为30 min,由相应的数据采集系统自动完成数据获取和存储。通过U 盘下载原始数据并存储备份,然后根据ChinaFLUX 数据管理要求进行后续的质量控制和标准化处理。
1.2 数据处理方法
通量数据的原始观测数据统一遵循ChinaFLUX 技术体系进行标准化的质量控制和处理,处理流程如图1。为规范和便于读者对数据的使用,本数据集将10 Hz 的原始数据处理计算形成了日尺度和生育季节尺度数据产品[9]。
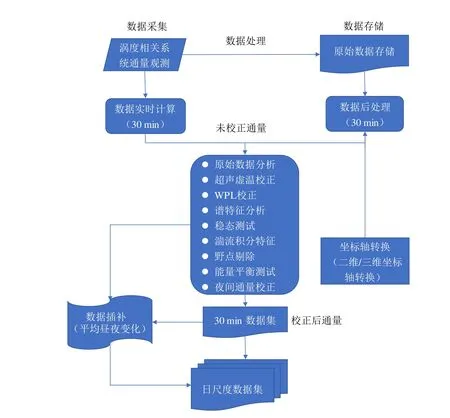
图1 通量数据质量控制与处理流程
数据质量控制过程主要包括原始数据分析、超声虚温校正、坐标轴旋转、WPL 校正、稳态测试、湍流积分特性、野点剔除、能量闭合度评价以及夜间摩擦风速阈值筛选[10-15]。野点剔除指原始数据中的异常值剔除,剔除方法包括绝对值法和相对值法[16]。绝对值法即依据观测指标理论上可能出现的数值范围设置上下限,将明显超出正常范围的数值直接剔除;相对值法即计算数据的平均值和方差,以4 倍方差作为检验标准,剔除偏离过大的数据。坐标轴旋转也称为倾斜校正,其目的是保证超声风速仪与地表平行,减少由于仪器倾斜导致观测的垂直风速中包含水平风速分量而造成的通量数据误差。本研究采用中倾斜校正,主要包括三次坐标轴旋转(Tiple Coordinate Rotation,TR)、WPL(Webb-Pearman-Leuning)校正、频率响应校正。其中三次坐标轴旋转可使x 轴平行于平均风速方向,侧向平均风速与垂直平均风速及两者的协方差为零;WPL 校正针对由于水热通量输送引起气体密度变化而导致的潜热通量和感热通量观测误差;频率响应校正针对仪器的系统误差,即由于仪器对高频和低频信号响应存在的缺陷。根据平均值检验法(Average Values Test,AVT)对夜间CO2通量数据进行校正[17]。本数据集前期主要利用编写的程序代码(2007–2011 年)以及软件EddyPro(LICOR 公司提供,2011–2013 年)对通量数据进行了以上质量控制和处理。2017 年后期利用ChinaFLUX统一程序代码对原始数据又进行了一次处理,由于所选计算方法基本一致,数据一致性达99.5%。针对缺失数据的插补,短时段(小于2 h)的缺失数据采用线性内插法,较长时段(大于2 h)的缺失数据利用平均昼夜变化法(Mean Diurnal Variation,MDV)进行插补[18]。对于蒸散量(ET)连续多日(7 日以上)的数据缺失时段或MDV 插值后仍存在的异常值,我们根据蒸散发生的机制对数据处理方法进行了改进,利用土壤含水量与ET/ET0的定量关系进行重新插补,这也是我们对数据插补方法的一点创新。具体方法如下:
①利用联合国粮农组织(Food and Agricultural Organization,FAO)推荐的Penman-Montieth 公式计算参考作物蒸散量ET0[19]:
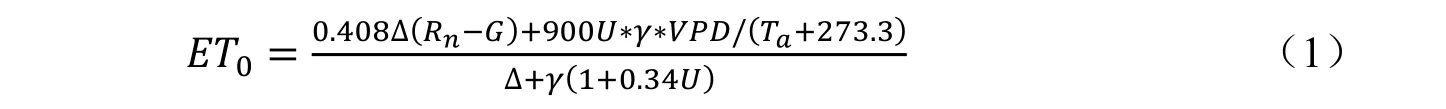
式中:ET0为潜在蒸散发(mm),Rn为表层净辐射(MJ/(m2·day)),G 为土壤热通量(MJ/(m2·day)),Ta为日平均气温(oC),U 为2 m 高度处风速(m/s),VPD 为饱和水汽压差(kPa),Δ 为饱和水汽压曲线斜率(kPa/oC),γ 为干湿表常数(kPa/oC),ET0计算用到的所有气象数据均来自栾城试验站标准气象场。
②筛选出连续7 日以上的数据缺失时段或异常值时段。
③筛选出存在缺值的日期及其前后2–3 天的数据。
④从筛选结果中选择与缺值处土壤含水量相近的日期(日期相同,年份不同),假设每个生育期的作物系数在同时期不变,将各ET/ET0取平均值作为缺值日的ET/ET0。其中土壤含水量数据由IHII 型中子仪(英国Didcot 公司生产)和自动传感器(Stevens 公司生产的Hydra Probe II)共同测定,观测深度为0–2 m。
⑤将平均所得的ET/ET0乘以当天对应的ET0,得到插补后的ET。
2 数据样本描述
2.1 数据集命名规则及数据量
本数据集为栾城站2007 年10 月1 日至2013 年9 月30 日的农田生态系统日尺度碳水通量观测数据,共计1 个EXCEL 数据文件,大小为295 KB。文件命名为“栾城典型灌溉农田生态系统2007–2013 年日通量数据集”,其中包括5 个表单,分别命名为“蒸散量”“降水量”“净辐射量”“感热通量”和“二氧化碳净交换量”。每个表单分别包括2192 条日尺度数据和6 条生育季尺度数据,其中降雨量数据包括了同时期的人工观测和自动观测数据。
2.2 数据文件示例
表2 为数据表头示例,详细介绍了数据项含义、数据类型、计量单位等信息。
表2 通量观测数据表头说明
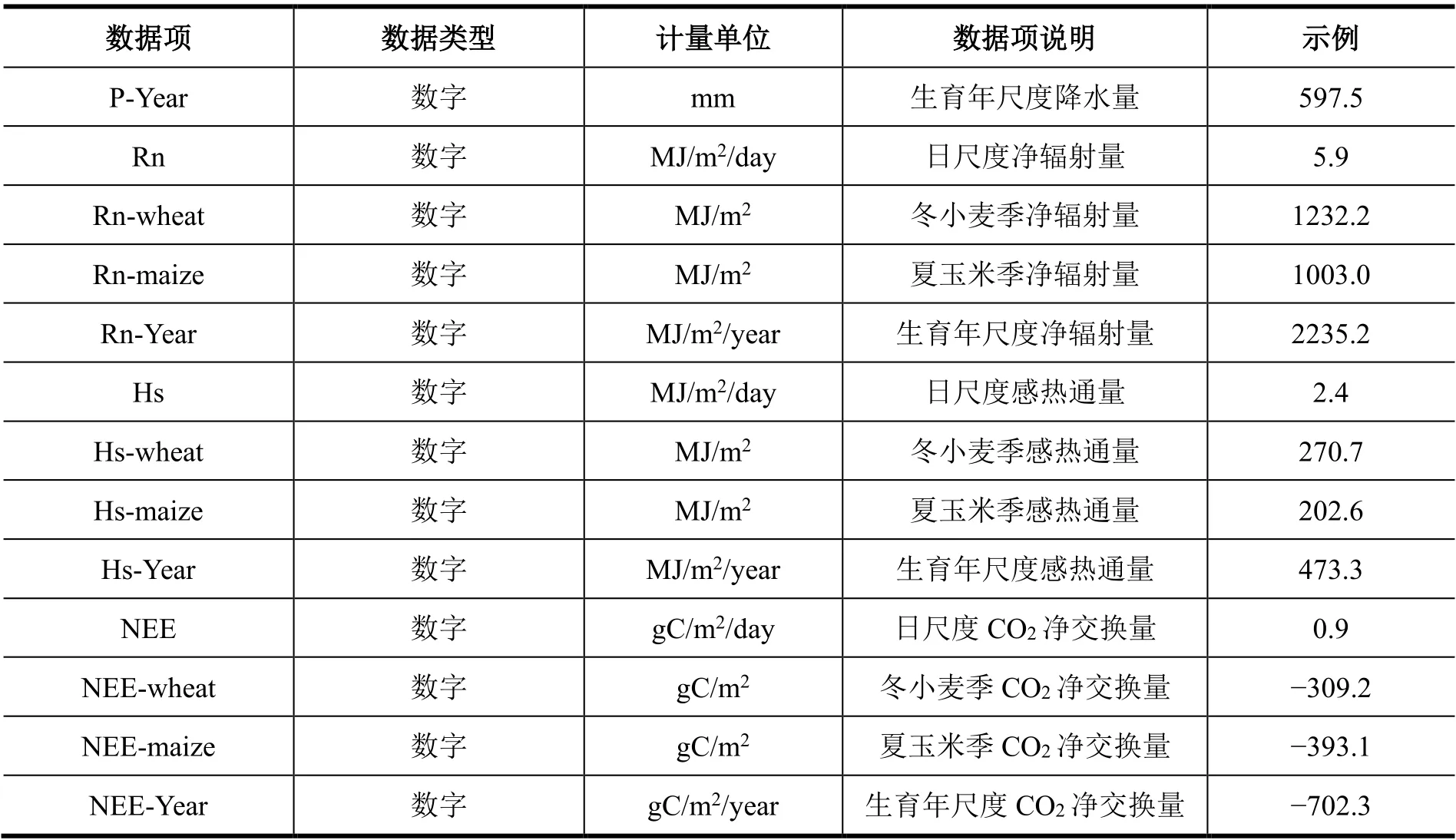
数据项 数据类型 计量单位 数据项说明 示例 P-Year 数字 mm 生育年尺度降水量 597.5 Rn 数字 MJ/m2/day 日尺度净辐射量 5.9 Rn-wheat 数字 MJ/m2 冬小麦季净辐射量 1232.2 Rn-maize 数字 MJ/m2 夏玉米季净辐射量 1003.0 Rn-Year 数字 MJ/m2/year 生育年尺度净辐射量 2235.2 Hs 数字 MJ/m2/day 日尺度感热通量 2.4 Hs-wheat 数字 MJ/m2 冬小麦季感热通量 270.7 Hs-maize 数字 MJ/m2 夏玉米季感热通量 202.6 Hs-Year 数字 MJ/m2/year 生育年尺度感热通量 473.3 NEE 数字 gC/m2/day 日尺度CO2 净交换量 0.9 NEE-wheat 数字 gC/m2 冬小麦季CO2 净交换量 −309.2 NEE-maize 数字 gC/m2 夏玉米季CO2 净交换量 −393.1 NEE-Year 数字 gC/m2/year 生育年尺度CO2 净交换量 −702.3
数据表头说明:
(1)Year 表示生育年,10 月1 日至次年9 月30 日,即从小麦播种到玉米收获的一个轮作周期。
(2)P(Precipitation)表示降水量(mm),表示从天空降落到地面上的液态或固态(经融化后)水,未经蒸发、渗透、流失,而在水平面上积聚的深度。
(3)ET(Evapotranspiration)表示农田蒸散量(mm),指单位时间单位面积农田土壤蒸发量和植物蒸腾量的总和。
(3)Rn(Net Radiation)表示净辐射量(MJ/m2),是射入到地表的辐射能与地表射出的辐射能的差。
(4)Hs(Sensible Heat Flux):表示感热通量(MJ/m2),指由于温度变化引起的大气与下垫面之间发生的湍流形式的热交换。
(5)NEE(Net ecosystem exchange of CO2)表示生态系统CO2净交换量(gC/m2)。NEE 为正值表示农田生态系统向大气释放CO2;NEE 为负值表示农田生态系统从大气吸收CO2。
3 数据质量控制和评估
目前全球通量观测研究领域普遍使用的数据质量评价体系主要包括一贯性检验和完全湍流假设的检验。本数据集基于此对数据质量进行了系统评价。功率谱和协方差谱检验结果表明,三维风速、CO2浓度和H2O 浓度的功率谱变化模态符合惯性副区−2/3 斜率理论值,表明涡度相关系统设备响应正常,不存在系统性的相移或失真[20]。结合湍流稳定性检验和积分统计特性检验对数据进行总体质量评价和等级划分,结果显示观测样本符合湍流的方差相似性规律,数据质量较高[21]。能量闭合度是通量数据质量评价的重要参考标准之一,Wilson 等通过统计分析了全球通量观测网络(FLUXNET)22 个站点50 年通量数据,发现所有植被类型和气候条件下的观测均存在不同程度的能量不闭合现象,平均不闭合度达20%[22]。为反映生态系统通量实际变化情况,本数据集中通量观测数据未进行强制能量闭合处理。但是借助于改进的ET(LE)插补方法,能量闭合度可达91%。其中小麦季观测结果的能量闭合度可达95%,玉米季可达88%,远高于全球通量观测网络台站汇交数据能量闭合程度的平均水平,数据质量较好。此外,为保证降水数据质量,本数据集不仅包含了人工观测降水数据,也收录了同时期的自动观测降水数据。
本数据集中,日尺度蒸散量和二氧化碳净交换量有效观测数据为90%和93%;人工降水量有效观测数据为100%,自动观测为96%;净辐射量和感热通量有效观测数据约为95%。数据缺失的原因主要分为两类:一是观测仪器运行故障导致的数据缺失,包括供电故障、设备维护等;二是数据处理过程导致的数据缺失,比如夜间和降水天气数据的筛选等。
4 数据使用方法和建议
本数据集为栾城试验站自通量观测系统布设完成至2013 年积累的通量数据,其观测、处理和质量控制与评估均采用国际通用方法,并根据自身条件和观测情况进行了改进,可靠性高。数据跨度从2007 年10 月至2013 年9 月,覆盖6 个连续作物年,观测样地属于华北地区典型的潮褐土高产农业生态类型,具有较强的代表性。本数据集可为农业节水理论与水文水资源研究等相关领域的发展提供坚实的数据支撑,包括农田耗水特征与蒸散结构分离[23-24],土壤水利用层次与地下水补给途径解析[23,25-26],农田生态系统碳氮水循环过程[27-28],农田水平衡和适水种植制度调整[16-17,29-30],农业生产力与水资源可持续利用程度评价[31],作物模型的验证与改进[29-30,32]等。此外,本数据集可与其他观测台站的数据进行综合集成,服务于陆地生态系统对全球变化的响应、区域尺度陆地生态系统物质循环与能量流动过程以及生态系统管理政策制定等相关领域。
目前通量观测数据仍普遍存在不同程度的能量不闭合现象,数据处理和质量控制也存在一定的不确定性。因此,本数据集在使用过程中需注意以下几个方面:
(1)随着ChinaFLUX 数据管理技术体系的更新和完善,不同年份汇交的通量数据处理方法不完全相同,因此本数据集可能与早期发表的数据存在一定差异(误差允许范围内)。
(2)本数据集的数据管理和质量控制方法详细信息可参考Zhang 等[16,26]、Shen 等[17]、于贵瑞等[33]、Wen 等[20]和Yu 等[6]已发表的文献。
(3)本数据集各项观测数据受仪器运行状态或数据处理过程影响,存在不同程度的数据缺失。数据文件中对插补数据进行了标注,建议优先采用未插补数据,以减少不确定性。
(4)针对降水数据,人工观测可能会在降水量较大的连续降水日无法及时观测导致数据偏小,而自动观测可能对小雨0.2 mm 的降水难以捕捉,有时也会由于仪器问题出现缺测,这是目前降水观测普遍存在的问题,所以建议根据研究实际情况选择所需降雨数据。
致 谢
衷心感谢CERN 综合中心和ChinaFLUX 数据资源管理人员以及栾城站观测人员的支持!感谢中国科学院地理所张雷明、陈智老师在数据质量控制和处理程序方面给予的指导!感谢中科院农业资源研究中心王玉英、程一松、闵雷雷、齐永青和郭英博士在数据收集、处理与监管方面给予的帮助!
数据作者分工职责
张玉翠(1984—),女,山东省滨州市人,博士,副研究员,研究方向为生态水文学与同位素水文学。主要承担工作:观测系统的长期连续运行、数据质量控制与整合。
姜寒冰(1993—),女,河北省泊头市人,博士研究生,研究方向为农田耗水机理。主要承担工作:数据处理与分析。
张传伟(1991—),男,山东省枣庄市人,硕士研究生,研究方向为多尺度农田耗水特征及其模拟。主要承担工作:数据处理与质量控制。
沈彦俊(1971—),男,河北省康保县人,博士,研究员,研究方向为水文学与水资源。主要承担工作:观测系统的总体运行和数据集的整体架构。
