基于图像混合核的列生成PM2.5预测
2020-08-05李晓理
李晓理,张 博,杨 旭
1) 北京工业大学信息学部,北京 100124 2) 计算智能与智能系统北京市重点实验室,北京 100124 3) 数字社区教育部工程研究中心,北京 100124 4) 北京未来网络科技高精尖创新中心,北京 100124 5) 北京科技大学自动化学院,北京 100083
伴随着雾霾在全国各地出现的频率越来越高,环境问题越来越引起人们的关注,尤其以京津冀地区最为明显.PM2.5是造成雾霾的主要因素,其在空气中滞留时间长,通过对太阳光的吸收、散射或反射,降低环境可见度;PM2.5颗粒被吸入人体后,会渗透到肺部组织,引发支气管炎等疾病,对人体健康造成危害.加强大气环境污染控制已成为亟待解决的问题,通过对PM2.5预测,可以为环境治理和人们健康出行提供准确的环境质量信息,有助于减轻环境污染对群众造成的危害.
近年来,国内外学者都对PM2.5预测方法进行了卓有成效的研究.文献[1]基于单时间序列模型,将动态指数平滑法和动态马尔科夫模型相结合,通过PM2.5历史数据预先确定算法的最优参数,对PM2.5进行动态预测,并验证了模型的有效性.文献[2]通过构建空间平滑核,对梯度增强算法进行改进,有效解决了PM2.5浓度与气溶胶光学深度、气象条件等预测变量之间的空间非平稳性,对日PM2.5进行预测.文献[3]提出了一种基于主成分分析和最小二乘支持向量机的杜鹃搜索混合模型,并将模型的预测效果与广义回归神经网络模型作对比,效果更优.文献[4]提取大气温度、湿度和风速3个特征,训练长短期记忆模型对1 h后的PM2.5污染等级进行预测,证明了PM2.5污染与周边地区的气象条件有密切联系.文献[5]利用随机数据分析方法,在多变量系统中选择与PM2.5相关的随机变量,作为神经网络的输入,实现了空气质量预测.文献[6]建立基于互补集合经验模态分解和支持向量回归的混合预测模型.对PM2.5质量浓度的原始时间序列进行分解,得到若干具有不同时间尺度的相对平稳分量,采用SVR算法对各个分量分别进行预测,求出各个分量的预测值之和,作为原始PM2.5质量浓度的预测结果.
也有学者利用图像对PM2.5进行预测.文献[7]利用大量室外图像,结合太阳位置、日期、时间、地理信息、天气条件等相关数据对PM2.5进行预测,该方法避免了大气测量装置的限制,为预测PM2.5提供了一种更为便捷的方式.文献[8]以手机照片为数据源,对良好天气下空间域和变换域的图像熵值建立自然度统计模型,通过计算污染图像的熵值的偏差度对PM2.5进行预测.文献[9]对不同天气条件下的照片质量进行分析建模,通过提取PM2.5浓度相关的特征建立粒子群优化的支持向量回归模型,实现了良好的预测效果.
鉴于大气环境复杂多变,PM2.5预测中需要考虑的因素较多,本文在上述研究的基础上,提出了一种基于图像混合核的列生成PM2.5预测方法.该方法通过分析图像变化与PM2.5浓度的关系,提取图像特征,并利用相关性分析完成特征选择.将图像特征经混合核映射到高维线性空间,有效避免了单核函数选取不当造成的影响.最后使用列生成方法来求解模型参数,保证了解的稀疏性和精确性,实现了对PM2.5的有效预测.
1 问题描述与数学基础知识
1.1 问题描述
PM2.5指空气动力学当量直径小于等于2.5 μm的悬浮物颗粒,会对可见光产生明显的散射作用.大气中PM2.5浓度的变化会使图像呈现不同的对比度、暗通道强度、可见度等特征信息,这使得利用图像实现PM2.5预测成为可能.
1.2 数学基础知识
本文采用了基于图像混合核的列生成方法研究了PM2.5预测问题,为了更好地介绍理论的原理,下面对方法中需要用到的一些数学基础知识进行简单地说明.
1.2.1 混合核
核方法被证明了是解决许多应用中推理问题的有效方法.通过引入正半定核K,可以使用线性学习算法创建非线性模型.给定观测样本{(x1,y1),(x2,y2),···,(xl,yl)}∈X×Y.其中输入空间X∈Rn,输出空间Y∈R(回归问题),通过非线性映射:

把输入数据映射到一个新的特征空间F={Φ(x)|x∈X},其中F∈Rn,原问题转化为:

在满足Mercer条件情况下,一定存在一个特征空间F和一个映射 Φ :X→F,使得
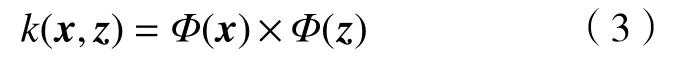
k(x,z)即为核函数.
核函数有两种主要的类型:全局核函数和局部核函数,局部性核函数学习能力强、泛化性能较弱,而全局性核函数泛化性能强、学习能力较弱,因此考虑把这两类核函数混合起来构成混合核函数.对文献[10]中混合核函数的形式进行扩展得到多核混合核函数的形式为其中kp(x,z)为单核函数,p是对应的核函数编号,µp为组合系数.由SVM决策函数可知,混合核函数的决策函数为:
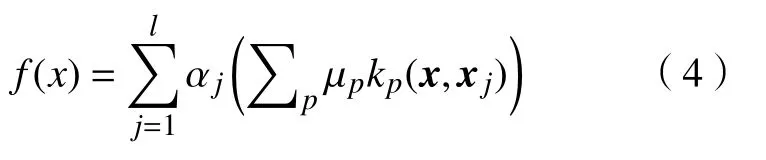
式中,α是模型参数,xj是第j个输入向量.本文中,不单独计算每个核矩阵(核对样本的Gram矩阵),而是采用混合模型,其决策函数为:

1.2.2 列生成
列生成算法是用于求解大型线性规划问题的一种重要方法.在原始问题中,列生成算法并不是一次性求解出所有参数 α,而是选取混合核矩阵K(构造方法在第4章介绍)的列子集并求解对应的 α 的最优解[11].根据拉格朗日对偶性[12],通过求解对偶问题可得到原始问题的最优解.原始问题的每一列对应于对偶问题的一个约束,当约束问题的解违反对偶问题中不存在的约束时,则需将该约束(原始问题中的一列)添加到约束问题中,以获得最优解.
基于决策函数(5),重写文献[13]中的线性列生成增强算法,使用2范数正则化构建如下凸二次规划问题:
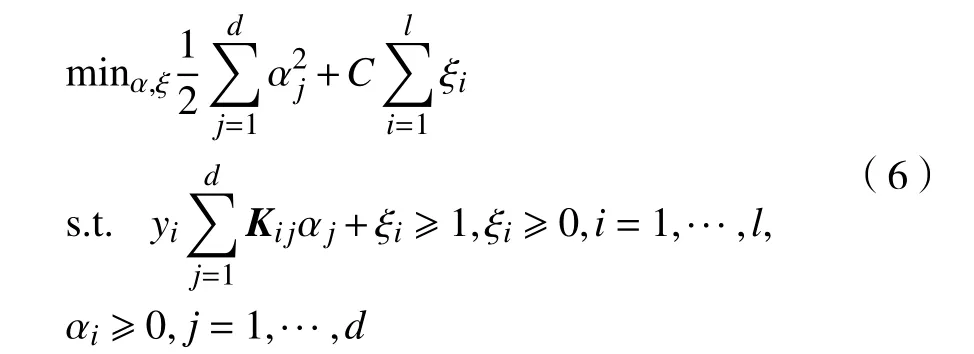
求得其对偶问题为:
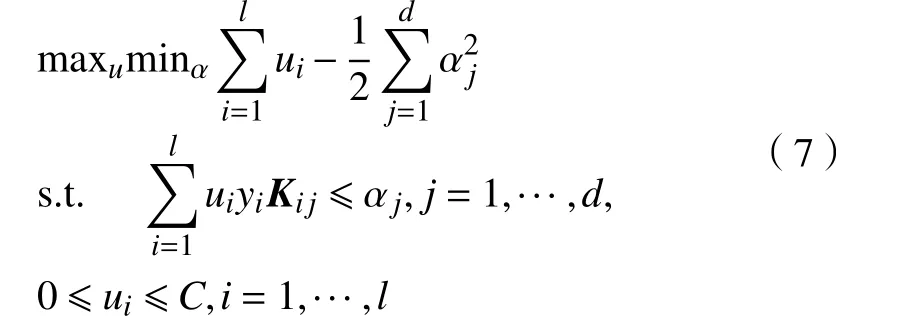

式中,j遍历核矩阵K中的所有列.列生成算法将列系数 α分为两部分,使用启发式算法选出的一部分W用于训练模型,未选中的部分N作为备选,假设未选中的部分αN=0,通过求解式(6)和(7)得当前最优解得αW,则=(αW,αN=0).经文献[14]证明,是原始–对偶问题的当前最优解,如果对于所有的,则即为满足KKT条件的全局最优解.对于线性列生成增强模型,每次选择N中使最大的列K·j加入到约束问题中.
将列生成增强算法推广到解决具有不敏感参数ε的损失函数max{|y−f(x)|−ε,0}的回归问题[15],模型的下限约束 α >0为非必需条件,所以在原模型中去除下限约束.为了构建回归模型,本文将偏离真实值至少 ε的点作为误差点.使用2范数正则化,对应的凸二次规划问题为:

设ui,vi为拉格朗日乘子,则原始问题(9)的对偶问题为:

同理,求解如下问题:

2 图像特征提取与相关性分析
空气中的雾霾会对图像造成严重的影响,会导致图像的一些特征值变低,尤其会影响图像的对比度、视见度、暗通道强度等[16].本文提取多个与雾霾相关的图像特征,并将图像特征与PM2.5值做相关性分析完成特征选择.
2.1 特征提取
本节提取与PM2.5浓度相关的空间对比度、非天空区域的暗通道强度、HSI空间颜色差异等特征.
2.1.1 空间对比度(Fig)
蓝宝石矿床的成因主要有:玄武岩型、伟晶岩型、矽卡岩型、碱性煌斑岩型、片麻岩型和砂矿型。中国蓝宝石矿床属于玄武岩型,其所生成的蓝宝石呈巨大的斑晶状,以深蓝色为主,不透明,澳大利亚也有此类蓝宝石,但是东南亚玄武岩型的蓝宝石颜色绚丽、透明度高;伟晶岩的蓝宝石如克什米尔蓝宝石其颜色纯正且饱和度高,但矿产资源较少;矽卡岩型矿床是世界蓝宝石的主要矿床类型,如斯里兰卡的蓝宝石,透明度高,颜色总类丰富;煌斑岩的蓝宝石产地是美国蒙大拿州,其蓝宝石颜色均匀但不鲜艳;片麻岩的蓝宝石颗粒较小、品质差,在美国、斯里兰卡和中国等地都有;次生矿的蓝宝石以砂矿形式存在的较多,且是蓝宝石原石的重要来源。
大气透射是指光线从场景辐射到观察者时,减去空气中颗粒物等的折射剩余的部分,是一个0到1之间的标量.根据大气透射模型,大气光的消光与透射率呈反比关系,两者满足如下公式[17]:

式中,bext是 消光系数,r(x)是光的传输距离.根据文献[18]:

定义空间对比度Fig为:Fig=|∇xI(x)|.
2.1.2 暗通道强度(Fid)
图像的暗通道强度定义为[19]:
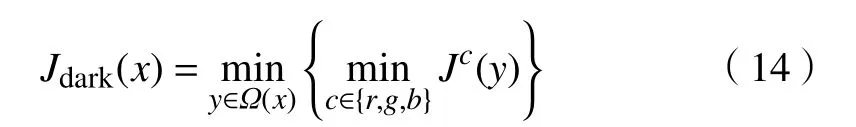
式中,Ω (x)是以像素x为中心的分块,J为场景辐射光,Jc表示其中一个颜色通道.从式中可以看出,给定像素的暗通道强度值为该分块三颜色同道中的最小值.大量无雾霾图像的先验知识表明,无雾霾图像的暗通道强度值为0,即:

将式(14)和(15)代入大气透射模型中,得:

式中,Ac为大气光,因此将t(x)选为特征Fid.
2.1.3 HSI 颜色差异(Fih,Fis,Fii)
根据Kim等的研究[20],天空在HSI颜色空间中颜色差异与大气消光bext存在指数关系,可表示为:bext=aeb∆D,式中a和b为 模型参数,∆D用来描述HSI空间中的差异.由于很难获取bext中在HSI三部分的影响参数,因此使用三部分在HSI颜色空间的差异值作为特征,定义如下:

式中,I是输入图像,其像素为m∗n,Ih(x,y)是像素点 (x,y)的h值 .同样,Fis和Fii定义如下:

2.2 相关性分析
采用皮尔逊相关系数对图像特征进行相关性计算.皮尔逊相关系数广泛用于度量两个变量之间的相关程度,其值介于–1与1之间,其中1表示完全正相关.其形式如下:
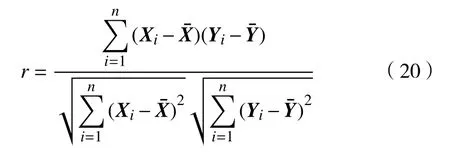
特征与PM2.5浓度值相关性越强,该特征越能表示图像的信息.当两组数据相关性系数大于0.6时,可认为两组数据相关性较强,当相关性系数小于0.6时认为两组数据相关性较弱.因此,本文选择与PM2.5相关性系数绝对值大于0.6的特征作为最终模型训练特征.
3 基于图像混合核的列生成 PM2.5 预测
PM2.5浓度变化主要影响图像对比度、非天空区域的暗通道强度、HSI空间颜色差异.由于图像特征与PM2.5浓度呈非线性关系[21],考虑到普通核函数各有利弊,为了得到学习能力和泛化能力都很强的核函数,采用混合核的方法建立图像特征值与PM2.5浓度之间的关系方程,并利用列生成算法求解方程参数.
3.1 特征选择
从图像中提取Fih,Fis,Fii,Fig,Fid共5个特征,对各特征和1 h后的PM2.5值进行相关性分析,结果如表1所示.5个特征与PM2.5浓度均呈负相关,可知PM2.5浓度升高,会导致图像对比度、暗通道强度下降,HSI颜色差异变小.其中Fig,Fid与PM2.5值的相关性强,Fih,Fis,Fii与PM2.5的相关性较强.因此,本文选择Fih,Fis,Fii,Fig,Fid共5个特征进行模型训练.

表1 特征与 PM2.5 相关性值Table 1 Correlation between characteristics and PM2.5
3.2 预测步骤
为方便预测,首先构造混合核矩阵.将给定的多个核函数组成核函数集S={K1,K2,···,Kp},计算每个核基于训练样本Kp(·,xj)的Gram矩阵Kp(Kp(·,xj)对应第j个训练样本).然后,将所有Gram矩阵并列构成一个混合核矩阵K=[K1,K2,···,Kp],则K为l×d的矩阵,其中d=l×p,Ki·表示混合核矩阵的第i行,K·j表示混合核矩阵的第j列.
在没有任何先验知识的前提下,优先选择简单的、计算成本低的核函数.本实验中,当简单核函数对应的列没有可添加的列用于求解时,则需要从更加复杂的核函数列中选取列用于求解.因此实验从简单到复杂采用三种核函数:线性核函数(L)、多项式核函数(P)、RBF核函数(R)构建混合核.将给定的3个核函数组成核函数集S={KL,KP,···,KR},分别计算每个核基于训练样本的Gram矩阵KL,KP,KR.将所有Gram矩阵并列构成一个混合核矩阵K=[KL,KP,KR],然后基于混合核矩阵利用列生成算法求解模型参数.实验中,L,P,R表示单核预测模型,L+P+R表示本文提出的混合核模型,核函数中的标准差 σ 用的均值代替(i,j遍历所有的训练样本).基于图像混合核的列生成预测步骤如下.
步骤1:采集图像数据和PM2.5浓度数据,经数据预处理后,配成样本对;
步骤2:提取图像特征,与1 h后的PM2.5浓度数据做相关性分析,剔除弱相关特征;
步骤3:选取多个核函数,计算核函数基于图像特征值的Gram矩阵;
步骤4:将多个Gram矩阵合并为混合核矩阵;
步骤5:抽取混合核矩阵的部分列构成列子集,利用列生成算法基于列子集求取模型当前解;
步骤6:验证当前解是否为最优解.若是,输出最优解,模型构建完成;若否,抽取未选列中的最佳列添加到列子集中,返回步骤5;
步骤7:利用验证集验证预测模型的精度与稳定性.
3.3 性能指标
为了衡量单核预测模型和本文混合核模型的性能优劣,采用均方根误差(emse),平均绝对百分比误差(emape)和相关系数(R2)3个指标对模型进行评估:

式中:yi表示第i个样本对应的PM2.5浓度的真实值,表示第i个样本对应的PM2.5浓度的预测值,表示模型预测输出平均值.emse反映模型预测输出值稳定性,emape反映模型预测输出值偏离实际值的程度,两者均是越小说明模型性能越好;R2反映模型预测输出值与真实值之间的关联程度,其值越接近1说明模型性能越好.

图1 数据采集设备(a)及数据样本(b)Fig.1 Data acquisition equipment (a) and data samples (b)
4 结果分析
本实验使用大气图像数据和对应的空气质量PM2.5数据进行实验.图像数据来源于安装在北京工业大学内的360智能摄像头,采集2019年1月1日至2019年5月31日每日9:00~16:00的600×320图像(每小时采样)共1000幅.PM2.5数据来自安装在北京工业大学校园内的808微型气象站.数据采集设备及数据样本如图1所示.

图2 混合核模型预测值Fig.2 Prediction results of mixture kernel model
4.1 预测结果分析
从采集的图像数据中随机抽取600张图像,将经过标准化处理的特征数据随机取400组作为训练样本,剩余200组作为测试样本.为了证明基于图像混合核与列生成模型的有效性,将该模型与单核预测模型实验结果进行对比.
针对基于图像混合核的列生成PM2.5预测模型,利用预留的验证集数据进行仿真实验,仿真结果如图2和3所示.从图2和3中可以看出,采用基于图像混合核的列生成模型对1 h后的PM2.5值进行预测,预测值与期望输出值基本相吻合,能达到相对较高的预测精度.预测值的相对误差绝大部分维持在较低范围内.
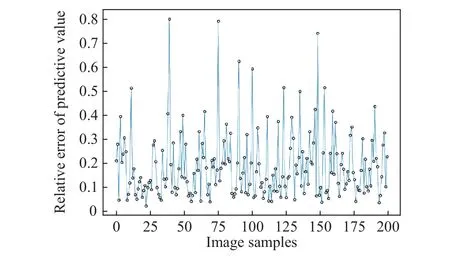
图3 混合核模型预测相对误差Fig.3 Relative error in mixture kernel model prediction
除了个别因环境因素、人为因素等造成的较大偏差外,基本可以认为该模型满足了预测精度要求.同时,将基于图像混合核的列生成PM2.5预测模型与单核预测模型进行对比实验,结果如图4所示.

图4 4 种模型预测相对误差Fig.4 Relative error in prediction for the four models
从图4中可以看出,对于同一测试样本,基于图像混合核的列生成模型的预测相对误差要普遍小于其他单模型,且混合核模型的预测相对误差稳定维持在一定范围内,未出现较大误差,可认为基于图像混合核的列生成模型在预测性能和模型稳定性方面优于其他三个单核预测模型.
结合3个性能指标对4种预测模型进行对比,结果如表2所示.相比于3种单核预测模型,基于图像混合核的列生成模型预测结果的均方根误差(emse)和平均绝对百分比误差(emape)最小,相关系数(R2)最大,说明基于图像混合核的列生成模型表现出了更高的预测精度和预测稳定性.

表2 4 种模型性能对比Table 2 Performance comparison of the four models
4.2 计算复杂度分析
基于图像混合核的列生成预测模型的计算复杂度取决于基于图像特征值的模型建立过程,因此其计算复杂度与列生成算法相等.列生成算法的计算复杂度计算如下:设样本总数为n,则混合核矩阵总列数为np,最终要抽取m列.抽取每列都要与其余所有列进行计算对比,则计算次数依次为总计算次数为因为m≪n,所以混合核模型的计算复杂度可表示为O(nmp),同理的单核预测模型计算复杂度为O(nk)(k为单核矩阵中抽取的列数).本文中p=3,m≪n,k≪n,可得O(nmp)=O(nk)=O(n),所以混合核预测模型与单核预测模型相比,计算复杂度没有明显增加.
综上,本文提出的基于图像混合核的列生成预测模型,在满足预测精度的前提下,获取数据的成本更低,获取数据的途径更便捷,计算复杂度与单核预测模型相比无明显增加,对进行PM2.5预测有一定的借鉴意义.
5 结论
列生成算法是解决多变量线性规划问题的典型方法,核函数可以将非线性数据映射到高维线性空间,本文将核技巧与列生成算法相结合,提出了一种基于图像混合核的列生成预测模型.通过实验得出以下结论:
(1)针对大气PM2.5预测影响因素复杂、大气污染物浓度数据难以获取等问题,基于图像数据建立模型进行预测是可行的,当选取的图像特征与PM2.5密切相关时,能够取得不错的预测效果.
(2)基于图像混合核的列生成预测模型无需考虑组合参数问题,且能从核矩阵中选择最佳的列,使模型的解具备稀疏性且预测精度可观.
(3)混合核模型比普通单核预测模型的预测误差小、精度高,模型稳定性好,该模型具备良好的预测性能.
(4)本文提出的模型对多雾、降雨和夜间等天气无法适用,会影响模型预测效果,需要在今后的工作中将此类特殊天气条件考虑到模型训练中,期望得到泛化能力更强、预测精度更高的预测模型.
