基于数据挖掘技术的外汇管理内部审计方法探索
2020-07-26褚伟金岳成林志永何浔丽汪东平
褚伟 金岳成 林志永 何浔丽 汪东平
[摘要]本文以企业货物贸易分类管理有效性审计为例,运用SAS软件中的分类相关模型,通过对以往的企业分类情况进行训练形成分类规则,实现模拟业务人员进行企业分类筛选,将模拟筛选的企业与现实分类企业作比,对不一致的企业进行现场审计分析,以发现分类管理中存在的风险。
[关键词]数据挖掘 聚类分析 分类管理 内部审计
近年来,外汇局不断推进“数字外管”建设,已开发20多个业务系统、采集海量业务与管理数据,同时,外汇局内审人员短缺,现有分支局少有内审专设机构,支局内审人员多为兼职,内部审计项目主要依靠总局、分局开展。为缓解审计人员少、审计任务多之间的矛盾,外汇局尝试利用数据挖掘技术,在审计项目实施过程中,通过对现有外汇管理信息系统进行数据挖掘、分析,快速发现审计重点,合理配置审计资源,提升内部审计效率,更好发挥内部审计增加组织价值的作用。
一、数据挖掘的概念及相关方法
1995年,数据挖掘概念在美国计算机年会上被提出,这一概念的主要内容是从大量的、模糊的、有噪声的现实数据中,提取人们不知道但又包含其中并可以被人们利用的知识和信息的过程,内含数据准备、数据处理、结果分析和评估等步骤。通过数据挖掘,可以让模糊无关联的数据,经过整理、加工、改造成清晰识别的状态,从而发现背后隐藏的逻辑关系。其中,聚类以及分类预测是数据挖掘过程中使用的关键方法。
聚类分析最本质的思想是实现“物以类聚”。聚类分析要解决的问题是事先不知道所研究的对象应分为几类,更不知道观测个体的具体分类情况,其目的是通过对观测数据进行分析,选择一种能够度量个体间接近程度的统计量,从而确定分类数目,建立一种有效的分类方法,并按接近程度对观测个体给出合理的分类。分类和预测可以用于提取描述重要数据类的模型以及预测数据未来的趋势。SAS软件中实现聚类以及分类预测常用的模型有以下几种:一是决策树(Decision Tree),主要用于数据分类,通常包括特征选择、决策树生成以及决策树的剪枝等过程,最后通过决策树形成规则,再把规则运用到新事物的分类中去;二是人工神经网络(Neural Networks),即从结构上模仿生物中的神经网络,通过训练来学习的非线性预测模型,运用在数据挖掘中进行分类、聚类特征采掘等;三是随机森林(Random Forest),作为决策树的一种拓展,但不同于决策树,具有双重随机性,即达到数据样本采样的随机性以及数据特征的随机性;四是支持向量机(Support Vector Machine),即一类按监督学习方式对数据进行二元分类的广义线性分类器,具有稳健性和稀疏性等特点,广泛运用在人像识别、文本分类等模式识别中。
二、数据挖掘在外汇局内部审计中的可行性分析
(一)外汇局信息化建设为内部审计数据挖掘提供可能
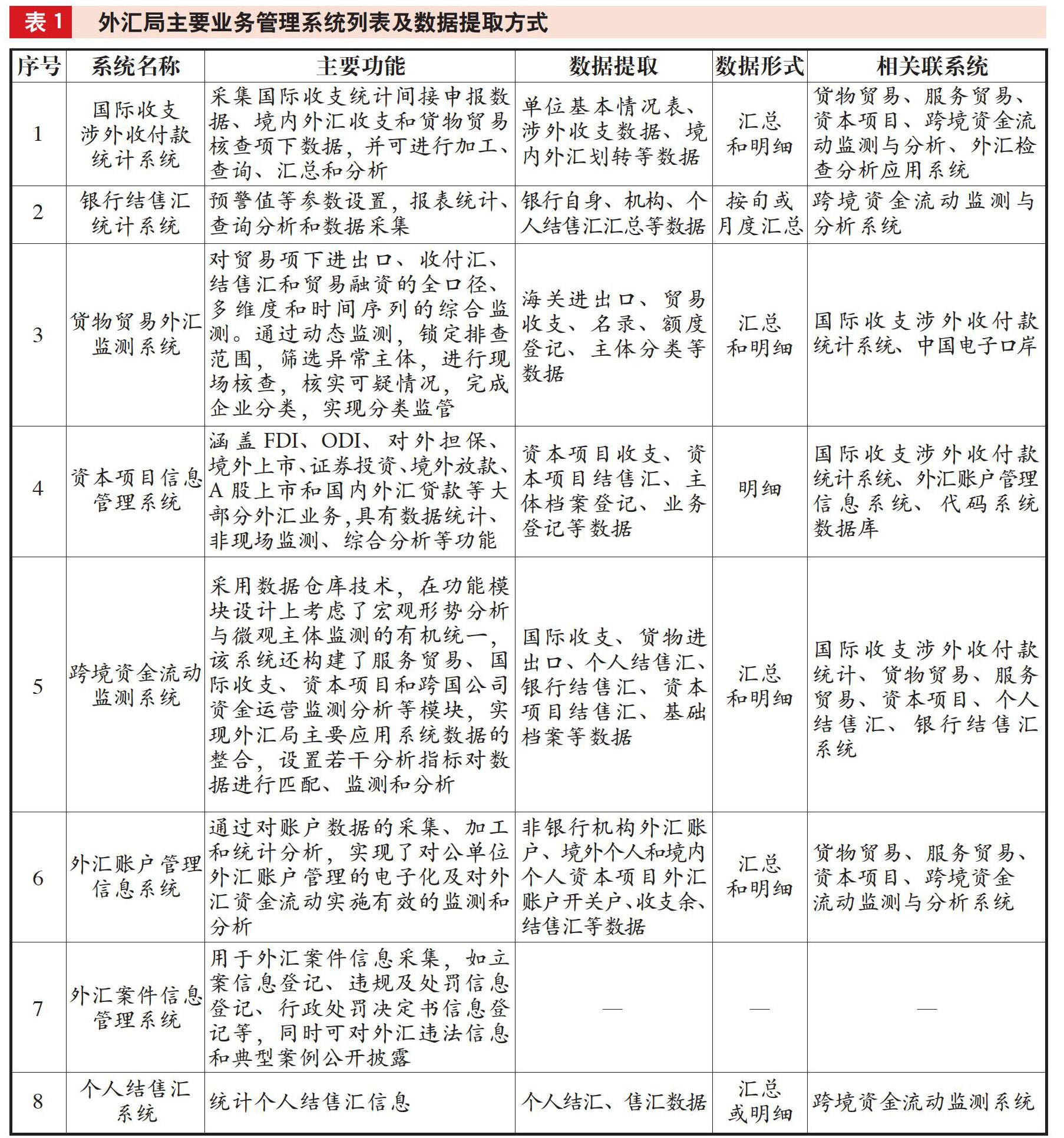
外汇局不断加强信息化建设顶层制度设计,完善适应外汇管理信息系统的软硬件环境和技术路线,并从“技术支持业务改革”向“技术引导业务改革”方向发展,逐步加强技术推动和引导业务改革。根据宏观调控决策、微观分析预测和外汇业务管理的需要,外汇局一方面加强外汇监管和统计手段的信息化建设,提升监管业务水平;另一方面探索逐步实现内审内控电子化与系统化,强化内部管控能力。目前,已开发使用银行结售汇统计、货物贸易、服务贸易、资本项目信息管理等20多个业务管理系统(见表1)以及适用于内审内控项目的实施、测评分析与整改的内控风险测评系统。至此,建立起覆盖外汇统计、信息管理、内部管控等全方位、多方面的系统平台,基本形成以数据采集、业务监管、网上服务为基础支撑的信息系统架构。
(二)外汇管理理念转变为内部审计数据挖掘提供支持
2009年以来,外汇局大力实践外汇管理理念和方式“五个转变”,从传统的依赖审批和核准的管理方式转变为重点加强跨境资金流动的监测分析和预警,从重事前监管、行为管理转变为强调事后核查、主体监管;从“有罪假设”转变为“无罪假设”,从“正面清单”转变为“负面清单”等,新一阶段的外汇管理工作开展着力于改善服务,侧重于科学监测和风险防控。为更好地满足“五个转变”的履职需要,外汇管理人员快速转变理念、改进方式、提高素质,尤其在监测分析方面实现了质的飞跃,在数据资源的监测、分析、利用取得了较好成效。因此,把数据挖掘技术运用到外汇管理内审工作中,通过大数据挖掘和分析提升内审工作效率,既十分必要也颇为可行。
三、货物贸易分类管理有效性审计思路
(一)外汇局货物贸易分类管理现状
2012年,外汇局取消原先的核销制度,推行以分类管理为核心的货物贸易外汇管理改革。为保证企业贸易外汇收支,购汇结汇具有真实、合法的交易背景,与真实货物进出口情况一致,外汇局采集企业收支数据及货物流数据,建立了进出口货物流与收付汇资金流匹配的核查机制,对企业贸易外汇收支进行非现场总量核查和监测。
实务操作中,所有发生货物贸易外汇收支的企业都需提前到外汇局进行名录登记,不在名录的企业不能办理贸易外汇收支业务。对于所有进入名录企业库的企业,外汇局将其分成A、B、C三类。其中A类企业是按照无罪假设推定的,所有进入名录企业库的企业经过3个月辅导期后,都归类为A类企业。B/C类企业是外汇局分类监管的重点,外汇局监管部门需要根据采集到的企业收支信息和海关货物流信息,通过非现场核查和现场核查的方式来分析判断可能存在的异常或违规行为,据此对企业进行降级处理,并对落入到B/C类的企业采取不同的监管措施。
对于B/C类企业的确定,外汇局采用“系统指标+人工核查”的方式。外汇局对于货物贸易企业日常监管依靠“货物贸易外汇监测系统”,系统通过指标对异常企业进行预警。现有货物贸易监测指标包括总量差额、总量差额率、资金货物比等。各地监测人员按照地区实际设置指标阈值,并将阈值报备外汇管理总局,监测人员不能随意更改阈值设置。对于超过系统阈值的企业,系统会将上述企业落入“重点监测库”,由监测人员对其进行二次筛选。二次筛选过程中,需要结合各个指标,依靠监测人员经验,通过非现场核查和现场核查,進行B/C类企业的最终确定。
(二)企业分类监管中的审计要点
分类监管是货物贸易外汇管理改革的核心,分类准确性在货物贸易日常管理中起至关重要的作用。可以说,分类的准确与否关系到日常监管是否有效乃至货物贸易改革成败。但在实际监管中,分类监管也存在风险,一是由于企业众多,落入重点监测库的企业也很多,对企业的分类筛选工作量极大,以A分局为例,该分局辖内共有名录企业6万多家,一般指标筛选后落入重点监测库的企业在6000家左右,监管人员要对这些企业进行二次筛选,工作量很大,可能存在工作疏忽,致使应纳入B/C类的企业没有纳入;二是可能存在廉政风险,监管人员在日常监管中,出于人情等原因,把应纳入B/C类的企业没有纳入。
传统内部审计方式难以有效发现上述问题。一般而言,监管人员只能发现不应纳入B/C类而被纳入的企业,因为对此类企业,操作规程要求监测人员留有分类资料,而对应纳入B/C类未纳入的企业,往往不留存任何监测资料。同时,二次筛选过程是监测人员根据多个指标依靠经验综合把握的,审计人员无法提供有利证据证明应纳入B/C类而没有纳入的企业。
(三)基于分类和聚类数据挖掘的审计思路
对于企业分类监管的审计,关键是寻找那些应纳入B/C类而没有纳入的企业。最好的方法是模拟审计对象日常监测人员自己的行为模式,运用计算机数据挖掘功能学习该模式,并将该模式运用到实际数据中,从而找到要找的企业。因此可以使用SAS中的分类相关模型,通过对以往的企业分类情况进行训练,从而构筑有效的分析模型,实现模拟业务人员对企业进行分类筛选。将计算机通过模拟筛选出来的企业与现实分类得到的企业作比,对不一致的企业进行现场审计分析,找到审计重点,发现被审计单位的风险。
四、案例分析:在B分局监管数据与分类模型基础上建立审计模型
(一)分类模型的建立
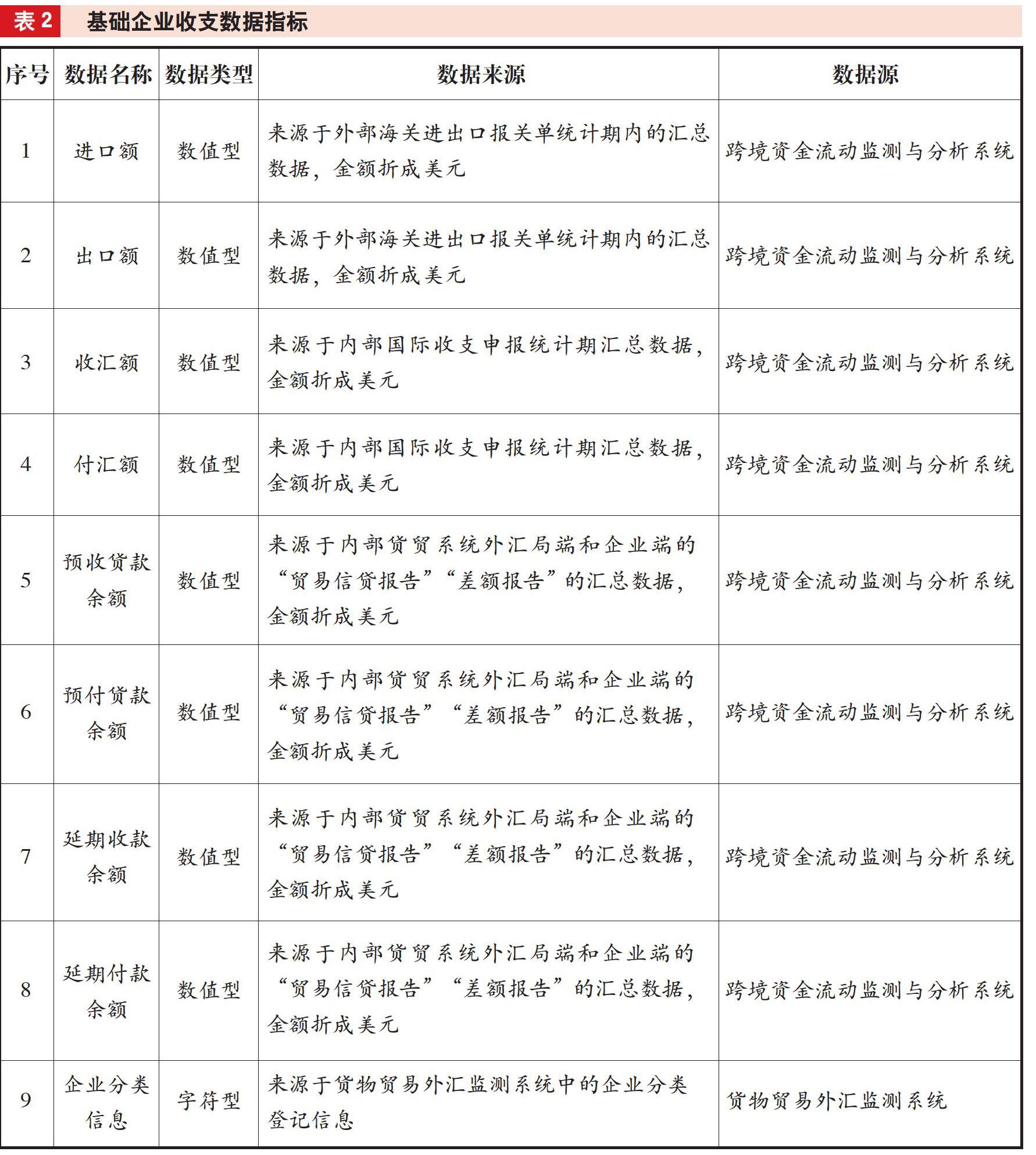
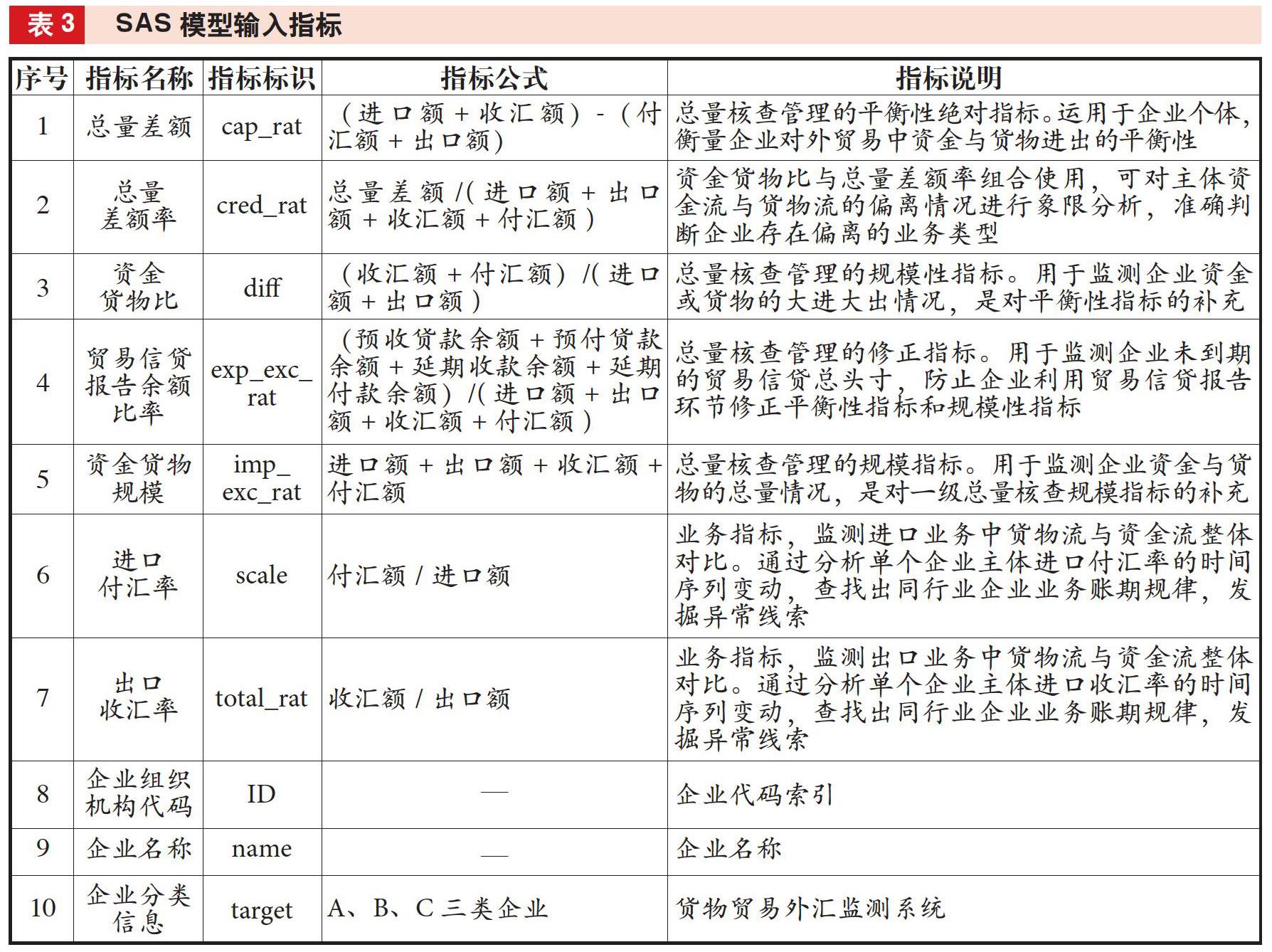
对审计对象B分局分类模型运用SAS软件中的决策树、人工神经网络、随机森林、支持向量机等模型来实现对企业群组的分析和异常企业筛查,并通过对比不同分类算法来选取准确率最好的分类模型。监管指标及特征值选取过程中,对于货物贸易企业收支行为的判断与分析需要以货物流与资金流数据为依托。为此,通过被审计单位监测业务人员评估,确定9类基础数据指标(见表2),并在这9类基础指标基础上加工形成10个输入指标作为SAS模型构建的特征值(见表3)。其中,总量差额、资金货物规模2个指标为总量数值型指标,反映对象企业的整体收支规模和业务体量;总量差额率、资金货物比、贸易信贷报告余额比率、进口付汇率、出口收匯率5个指标为比例型数值指标,反映对象企业的外汇收支特征及货物资金流动特征,是进行企业聚类分析的重要判断基础;企业分类信息为枚举型指标,以货物贸易监测系统中登记分类信息作为初始依据。
(二)数据采集及加工
审计对象B分局辖内共有4830家已名录登记的货物贸易企业,为有效过滤短期数据中的噪音和无意义波动,在此所有企业相关基础数据均以2017年1月至2018年6月之间的累计加总数据作为基础变量。剔除在此期间未发生任何收支行为的企业1041家,共构建3789条企业基础信息集合。为有效验证分类预测效果,根据数据挖掘的目标,采用分类抽样的方式,从3789条中随机选取1895条信息作为训练集,并将3789条全部数据作为评分测试集合。
在数据挖掘过程中,缺失值及异常值会导致最终挖掘结果的偏差,甚至造成混乱的挖掘结果,在建立基础数据集合后需要对缺失元素的数据对象进行缺失值填充,并修正会对挖掘结果产生较大影响的异常值。在实际对数据预处理的过程中发现,因为现有业务数据已经进行了标准统一,无需数据清洗,仅将缺失数据进行补0处理。同时针对货物贸易企业分类规则,将A类企业标识为0,B/C类企业标识为1,作为建模的目标变量。
(三)基于SAS的模型实现过程
在模型实现过程中,主要应用了SASEG和SASEM两个主要功能模块,其中通过SASEG实现对原始基础数据集的整理,并变换为标识的SAS数据文件,在SASEM中实现分类模型的构建,选取50%的数据记录作为样本训练,新建EM流程,选取决策树、人工神经网络、随机森林、支持向量机等备选算法构筑模型,并对算法的效果进行匹配比较。通过运行流程,得出不同算法间的效果比较,最终结果显示随机森林算法要优于其他算法类型,并将其作为模型构建的基础。构建的SAS模型会通过训练集生成相应的分类规则,根据训练的规则对完整评分数据集进行评分,并输出分析结果。
(四)模型运行结果及效果评价
在B分局评分集合的3789条企业数据中,已登记确认为B/C类企业的数量为149个。在分类模型预测中,评分前60的企业中确认B/C类企业57家,占比95%;在评分前100的企业中确认B/C类企业81家,占比81%;评分前200的企业中确认B/C类企业100家,占比50%,占现有已登记B/C类企业总数149个的67.6%;评分前500的企业中确认B/C类企业113家,占比22.6%,占已登记B/C类企业总数的67.6%。
可见,一是模型生产的分类规则能够有效覆盖大多数潜在异常企业特征,并生成有效的评分规则(见表4);二是审计人员可以重点关注未纳入B/C类企业的原因,特别是可将前100名中没有纳入B/C类企业的19家企业作为审计重点,审查是否存在疏忽或廉政风险。
五、数据挖掘在外汇局内部审计中的运用展望
数据挖掘作为一种当今流行的技术手段,在外汇局内部审计中具有广阔的运用前景。一是不仅在货物贸易管理审计中可以运用,在外汇检查、资本项目管理等业务管理领域同样适用。如在外汇检查领域,外汇检查业务是外汇局相对风险较高的业务领域,外汇局具有检查权的分支机构众多,但外汇局内审人员有限,因此需要寻找高风险分支机构优先开展审计,通过数据挖掘筛选重点分支机构不失为一条可行的路径。相对于随机抽取分支机构开展审计,可依托于外汇案件信息管理系统的海量数据,先对全国有检查权的外汇局进行一次聚类分析。按照行政代码提取全国已完成行政处罚的外汇案件数据,通过效果性指标(处罚笔数、处罚金额)、效率指标(立案时间与完结时间差、立案时间与处罚时间差)、规模指标(结售汇、收支额、违规金额)等按照行政代码进行聚类,寻找规模大但效果差、效率低的分支机构优先开展内部审计。二是数据挖掘手段不仅有聚类、分类预测,还可以运用关联分析、时间序列分析、孤立点分析等工具。外汇局收集的数据大多按时间采集,具有时间序列特征,且汇率、国际收支、进出口、外汇管理履职等方面具有明显的关联,因此通过时间序列分析、关联分析等可以有效考查审计对象履职绩效水平。如外汇检查案件同案不同罚的情况,可通过案件编号提取罚没款金额、违规金额等数据,以孤立点分析技术寻找罚款比例明显高于同类的案件,确定审计重点。三是数据挖掘不仅可以提升外汇局内审工作效率,还可以增强内审工作的科学性、针对性、有效性,切实服务外汇管理中心大局。如国际收支平衡管理是外汇局的中心任务,内审部门可通过数据挖掘手段检验国际收支平衡管理成效,提出决策建议,切实发挥内审咨询服务和价值增值作用。
(作者单位:国家外汇管理局上海市分局,邮政编码:200120,电子邮箱:jin_yue_cheng@126.com)
