基于提升方法的多度量行人再识别
2020-07-23陆萍董虎胜钟珊
陆萍 董虎胜 钟珊
摘 要: 受到光照、视角、姿态等因素的影响,跨摄像机的行人再识别是一项相当具有挑战性的研究工作。为了进一步提升行人再识别的匹配精度,设计了更具判别性的特征表达,即增强局部最大出现频次(eLOMO)描述子,并提出基于提升方法融合多个距离度量的匹配模型。在提取eLOMO特征时采用从水平条与密集网格两种不同的尺度中提取颜色与纹理特征,从而获得更具判别性的行人外观描述子。在匹配模型上,采用自适应提升(AdaBoost)方法来融合多种距离度量学习模型的优势,从而实现对行人外观的匹配。在行人再识别公共数据集VIPeR和PRID450S上的实验结果表明,该方法能够有效地提升行人再识别的性能。
关键词: 行人再识别; 特征表达; 度量学习; 提升方法; 距离融合; 公共数据集
中图分类号: TN911.73?34; TP391.4 文献标识码: A 文章编号: 1004?373X(2020)05?0036?06
Multi?metric person re?identification based on boost method
LU Ping1, 2, DONG Husheng2, ZHONG Shan3
(1. College of Computer Science and Technology, Zhejiang University, Hangzhou 310058, China;
2. Suzhou Institute of Trade and Commerce, Suzhou 215009, China; 3. Changshu Institute of Technology, Suzhou 215500, China)
Abstract: For the influence factors such as illumination, viewing angle and posture, the multi?camera person re?identification is a challenging research. In order to further improve the matching precision of person re?identification, a more discriminating characteristic representation named enhanced local maximal occurrence (eLOMO) descriptor is designed, and a boost method based matching model that fuses multiple distance metrics is proposed. Color and texture characteristics are extracted from two different dimensions of horizontal bars and dense grids for eLOMO characteristics, thus obtaining more discriminating person appearance descriptors. In terms of the matching model, the adaptive boost (AdaBoost) method is used to integrate the advantages of learning model for multiple distance metric, thus achieving the matching of person appearance. Experimental results on the public data sets VIPeR and PRID450S show that the method can effectively improve the performance of person re?identification.
Keywords: person re?identification; characteristic representation; metric learning; boost method; distance fusion; public data set
0 引 言
在摄像机监控网络的应用中,经常需要判断不同摄像机的画面中是否包含了同一个行人。这种跨摄像机的行人身份关联工作即为行人再识别[1]。受光照、视角、行人姿态与遮挡等因素的影响,同一行人在不同摄像机画面中的外观可能会存在相当大的差异,这使得跨摄像机的行人再识别面临着相当大的挑战。尽管在近些年的研究中已经取得了较大的进展[2?4],但距离实际应用仍存在很大的差距。
目前,行人再识别的研究工作主要围绕行人外观特征获取与距离度量学习两方面来开展。在特征描述子的获取上,主要从颜色与纹理等方面来刻画行人的外观信息,较为常用的基本特征描述子有颜色直方图、局部二值信息(Local Binary Pattern,LBP)、梯度直方图(Histogram of Gradient,HOG)等。为了能够获得更强外观刻画能力与判别性,目前使用的行人外观描述子大多由多种基本特征组合而成。文献[5]设计的局部最大出现(Local Maximal Occurrence,LOMO)描述子中,从密集网格中提取了联合HSV特征与尺度不变局部三值模式(Scale Invariant Local Ternary Pattern,SILTP)。受LOMO的启发,文献[6]设计了层次化高斯(Gaussian of Gaussian,GOG)描述子,使用一系列高斯分布的均值与方差来刻画颜色分布。文献[7?8]采用了将图像切分为多个水平条的空间划分方案,分别提出了显著颜色名称(Salient Color Names,SCN)与加权颜色直方图(Weighted Histograms of Overlapping Stripes,WHOS)描述子。但这些描述子或是从密集网络中提取,或是从水平条划分中计算获得,行人图像中的细节与整体外观未能有效的整合。
行人再识别中的距离度量学习模型旨在从行人图像数据中学习获得最优的马氏距离(Mahalanobis Distance),使得同一行人特征描述子之间的距离收缩,同时增大不同行人特征描述子间的距离。文献[9]从三元距离约束出发,设计了大间隔近邻(Large Margin Nearest Neighbor,LMNN)模型,在正样本对与负样本对间建立间隔从而使正确匹配图像得以被正确识别。文献[10]从概率角度出发提出了简单直接的度量(Keep It Simple and Straightforward Metric,KISSME)学习算法,从对数似然比判别函数出发推导出具有解析表达式的度量模型。文献[5]进一步改进了KISSME,联合学习一个投影子空间与度量矩阵的跨视角二次判别分析(Cross?view Quadratic Discriminant Analysis,XQDA)模型。文献[11]还设计了不均衡加权的度量学习模型(Metric Learning by Accelerated Proximal Gradient,MLAPG)来抑制训练样本对不均衡带来的度量偏差问题。由于不同的度量学习模型利用的是数据中不同方面的判别信息,单一的模型难以同时把它们有效地利用起来。
针对上述问题,本文设计了一种新的增强局部最大出现(enhanced Local Maximal Occurrence,eLOMO)描述子,eLOMO同时从具有覆盖的水平条区块与密集网格中计算颜色与纹理特征,从而能够从不同尺度上获得图像的细节与整个外观信息,因此也具有更强的判别力。在匹配模型上,采用AdaBoost方法对多种度量学习方法进行提升融合。在该方法中,每个度量学习模型被用作弱分类器,通过加权融合获得了更具匹配力的强分类器。在训练中不断地调整训练样本与各个度量的权重,使初始的匹配性能得以提升。为了验证本文方法的性能,在VIPeR和PRID450S数据集上进行了评估测试,均获得了优秀的行人再识别性能。
1 增强局部最大出现(eLOMO)特征
在行人再识别研究中,LOMO描述子表现出了优秀的行人外观刻画能力,在多个度量学习模型中取得了比较高的行人再识别准确率。LOMO描述子在计算HSV直方图與SILTP特征时,采用了10×10像素的滑动窗口来覆盖整幅行人图像。这样的密集网格处理保证了图像细节能够被细致地刻画,从而提取出图像的精细信息进行匹配。为了增强对视角变化的鲁棒性,LOMO还对同一高度上各滑动窗口中提取的HSV直方图与SILTP特征进行了最大池化处理。另外,LOMO中也考虑了不同尺度空间上信息的提取,采用对整幅图像作1/4缩放后再提取特征的策略。
虽然LOMO具有优异的细节刻画能力,但是刻画较大区域整体外观的能力却存在不足,主要原因是LOMO需要从密集网格中进行计算。为了增强它的判别力,本文进一步对图像作具有覆盖的水平条空间划分来提取特征,并将它与LOMO融合来赋予描述子整体外观刻画能力。
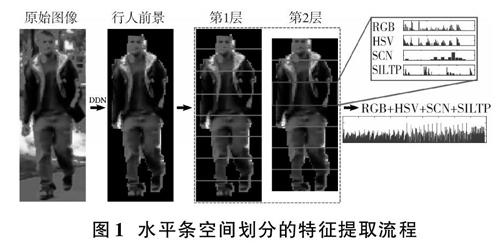
如图1所示,本文采用了具有覆盖的2层水平条金字塔空间划分。为了降低杂乱背景带来的干扰,在采用深度分解网络(Deep Decomposition Network,DDN)估计了行人图像的前景后,首先将图像划分为了8个等高的水平条区块,然后去除最顶端与最底端水平条各一半高度,接着再将剩余部分按7等份切分。这样的空间划分既保证了各个水平区块中的信息能够被连续覆盖提取,又可以使获得的特征能够比较好地表达出整体外观信息。在计算颜色与纹理特征时,除了联合HSV直方图与SILTP,还加入了联合RGB直方图与SCN[7]特征。其中,RGB直方图的计算采用了与联合HSV直方图相同的参数设置,即每个颜色通道均量化为8位;在提取SCN时采用了与文献[7]相同的16维显著颜色设置。由于新增的RGB直方图与SCN都具有比较好的颜色表达能力,因此,它们的引入能够显著增强对行人衣着颜色的捕捉。由于在提取水平条特征时,整个区块作为整体进行运算,因此不再需要进行局部最大池化处理。
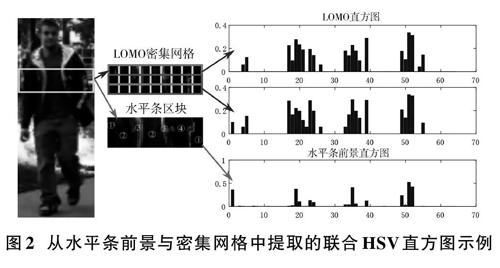
从行人图像的一个水平条中提取的联合HSV直方图示例如图2所示,其中,既有从密集网格中提取的LOMO特征,也有从整个水平条上提取的结果。为了更好地展示,图中给出的是4×4×4=64维的联合HSV直方图。
从图2中可以看出,LOMO特征具有2个直方图,因此维度上更高;而且直方图中的bin数量也更多,这说明LOMO具有很好的细节刻画能力。相比之下,从水平条中计算获得的特征bin数量比较稀少,其中的4个bin簇正好对应于图中行人衣服的4种颜色,说明它能够更好地捕捉图像的整体外观。因此,把LOMO与水平区块中提取的特征融合起来后,赋予了特征描述子“由粗到细”的表达能力。而这与人眼在识别对象时类似,因此,这样的特征描述子会具有更强的判别性。本文将融合后的特征描述子称为(eLOMO),其维度为40 960维。
2 AdaBoost多度量融合
在获得行人图像的外观描述子后,需要使用有效的度量模型来判别检索(Probe)图像与所有匹配(Gallery)图像间的距离或相似性,进而生成排序列表(Ranking List)。由于每种度量学习方法在模型设计上仅使用数据某一方面的信息,将不同的度量模型融合后将会获得更加鲁棒的距离。为了实现此目标,本文将各度量学习方法作为弱匹配模型,并采用AdaBoost方法将它们生成的距离结果融合提升。
设从训练集的检索图像与匹配图像中提取的特征描述矩阵与匹配标签矩阵分别为[X∈Rd×m],[Z∈Rd×n]([d]为特征表达维度)与[Y∈Rm×n];[xi∈Rd]([i=1,2,…,m])与[zj∈Rd]([j=1,2,…,n])分别为[X]与[Z]的第[i]和第[j]个样本,若[xi]与[zj]为一正样本对(即属于同一行人),则[Yi,j=1],否则,[Yi,j=-1]。为便于表述,这里作以下定义:
1) [p(xi)={(xi,zj),j=1,2,…,n}]为[xi]与所有匹配集中图像[{zj}nj=1]形成的图像对;
2) [h(xi)]为一个弱匹配,计算[xi]与所有匹配集中图像排序列表的度量模型;
3) [rank(zj,h(xi))]为排序位置运算,获得匹配集图像[zj]在[h(xi)]中的位置;
4) [Dt(p(xi))]为检索集中所有样本[{xi}mi=1]的权重分布;
5) [Dt={Dt(p(xi)),i=1,2,…,m}]为第[t]轮迭代中检索集样本的权重分布。
在弱匹配模型的选择上,本文使用了具有代表性的四种度量学习方法:MLAPG[11],XQDA[5],零空间Foley?Sammon变换(Null Foley?Sammon Transform,NFST)[4]和核化边界Fisher判别分析(Kernel Marginal Fisher Analysis,KMFA)[12]。它们的性能在各公开数据集上已经得到验证,下面对它们作简要介绍。
2.1 MLAPG
MLAPG中引入了不对称加权的策略来解决由正负样本对不均衡引起的度量矩阵存在偏差的问题,它的目标函数如下:
[L(M)= i=1m j=1nwijfM(xi,xj)] (1)
式中:[wij]根据[Yi,j]置为正负样本对数量的倒数;[fM(xi,zj)=log(1+exp(yij(d2M(xi,zj)-μ)))]为log?logistic损失函数,该函数能够提供一个柔性的决策边界来区分正确匹配样本对与错误匹配样本对,[μ]为一个正常数,用作决策阈值,[d2M(xi,zj)=(xi-zj)TM(xi-zj)]为马氏距离函数的平方。
MLAPG目标函数为凸函数,在优化求解时采用了高效的加速邻近点梯度(Accelerated Proximal Gradient)优化方法进行求解,该方法能够以[O(1t2)]的速度收敛到全局最优解[11]。
2.2 XQDA
如前所述,XQDA是通过对KISSME方法改进所获得的度量学习模型。令[Δij=xi-zj]为跨视角样本对的差向量,KISSME通過Bayes准则与对数似然比来决策[Δij]是否属于同一行人,通过对似然比函数化简可获得马氏距离决策函数:
[d(xi,zj)=ΔTijΣ-1I-Σ-1EΔij] (2)
式中:[ΣI]和[ΣE]分别为[Yi,j=1]与[Yi,j=-1]时[Δij]的协方差矩阵。
KISSME需要先对样本应用主成份分析(Principle Component Analysis,PCA)降维后再应用式(2)计算,且对维度过于敏感。为此,在XQDA中引入了需要联合学习的投影子空间[W],把[Δij]替换为[WTΔij]代入式(2)进行运算,可得:
[d(xi,zj)=ΔTijWΣ′I-1-Σ′E-1WTΔij] (3)
式中:[Σ′I=WTΣIW];[Σ′E=WTΣEW];[W]可通过对[Σ-1IΣE]作特征值分解获得[5]。
2.3 NFST与KMFA
NFST可以认为是小样本情况下的Fisher判别分析,其目标是在当样本数远小于样本维度时寻找到满足如下目标的一组投影方向[w]:
[maxwwTSbws.t. wTSww=0, wTSbw>0] (4)
式中[Sb]与[Sw]分别为训练样本的类间与类内散布矩阵。在求解NFST投影方向[w]时,可以通过Gram?Schmidt分解与特征值分解获得[w]的闭合形式解[4]。
MFA同样是Fisher判别分析的变体,但其仅从各样本的最近邻域中学习满足如下目标的投影方向:
[w*=argminwwTSwwwTSbw] (5)
与式(4)不同,这里[Sw=XLwXT],[Sb=XLbXT],[X]为所有训练样本特征矩阵,[Lw]与[Lb]分别为标记样本最近邻关系的标记矩阵[Aw]与[Ab]的Laplacian矩阵,即[Ls=Ds-As],[Ds=diagj≠iAs(i,j),?i],[s∈{w,b}]。MFA可通过对[S-1wSb]作特征值分解获得各投影方向[12]。
NFST与MFA都可以通过应用核函数进一步扩展到核空间实现对样本的非线性映射,核化后的NFST与KMFA通常能够获得更高的判别性能[4,12]。
2.4 基于AdaBoost提升方法的多度量融合
为了对多个弱度量匹配模型获得的距离进行融合提升,可以采用对这些匹配模型进行加权融合,但是权值的分配是一项相当棘手的难题。本文选择根据各弱匹配模型对检索图像匹配结果的判别性能进行自适应权值调节的AdaBoost提升方法。为此,首先定义如下的判别函数:
[f(h(p(xi)))=1, rank(zj,h(xi))≤β-1, otherwise] (6)
式中[β]用于指定匹配图像[zj]在检索图像[xi]的距离结果[h(xi)]中排序位置的阈值,实验时取值为1。为了增强模型的泛化性能,可根据数据集进行适当松弛。
在训练模型时,可以根据各检索图像[xi]的正确匹配是否与[f(h(p(xi)))=1]时的匹配结果一致来判断模型的分类准确率。根据各模型的分类准确率与各样本的权重分布,即可根据最小误差原则应用AdaBoost提升方法迭代确定各模型的权重,使得分类性能优异的弱匹配模型被赋予较高的权重,而性能较弱的模型权重相应减少;同时,在迭代中还会对困难样本赋予较高的权重。迭代结束后,最终的匹配结果将根据下式确定:
[H(p(xi))=tαtht(p(xi))] (7)
式中[αt]为在第[t]次迭代中弱匹配模型[ht]的权重。
算法1给出本文基于AdaBoost提升方法的多度量融合算法流程。
算法1: AdaBoost多度量融合算法
输入:样本特征矩阵[X],[Z],标签矩阵[Y]
初始化:[β=1], 置[D1(p(xi))]为[1m]
for [t=1,2,…,T] do
[εk←iDt(p(xi))f(hk(p(xi)))k*←arg minkεkht←h*kαt←12ln((1-ε)ε)]
[Dt+1(p(xi))←1ztDt(p(xi))exp(-αtf(ht(p(xi))))]
//[Zt]为归一化因子
end for
输出:[H(p(xi))=tαtht(p(xi))]
3 实 验
实验中选择了两个常用的行人再识别数据集(VIPeR和PRID450S)对本文方法进行了算法性能测试。其中,VIPeR与PRID450S均为在室外场景拍摄的数据集,它们都包含有2个摄像机视角,每个行人在各摄像机下均只有1张图像。VIPeR中有632个行人,他们的图像在光照与视角上存在很大的差异。PRID450S中行人数为450,行人外观差异主要来自于视角变化与杂乱的背景。
算法性能评估标准为行人再识别中最为广泛使用的累积匹配特征匹配(Cumulative Matching Characteristic,CMC)曲线,它反映了在前[r]个排序位置中找到正确匹配图像的概率。在算法评估时,VIPeR与PRID450S中的行人图像被随机地等量划分为两组,一组用于训练,另一组用于测试。为了获得稳定的实验结果,在每个数据集上都进行了10次随机实验,取它们的平均CMC值作为最终实验结果。
3.1 与文献中公开的结果进行比较
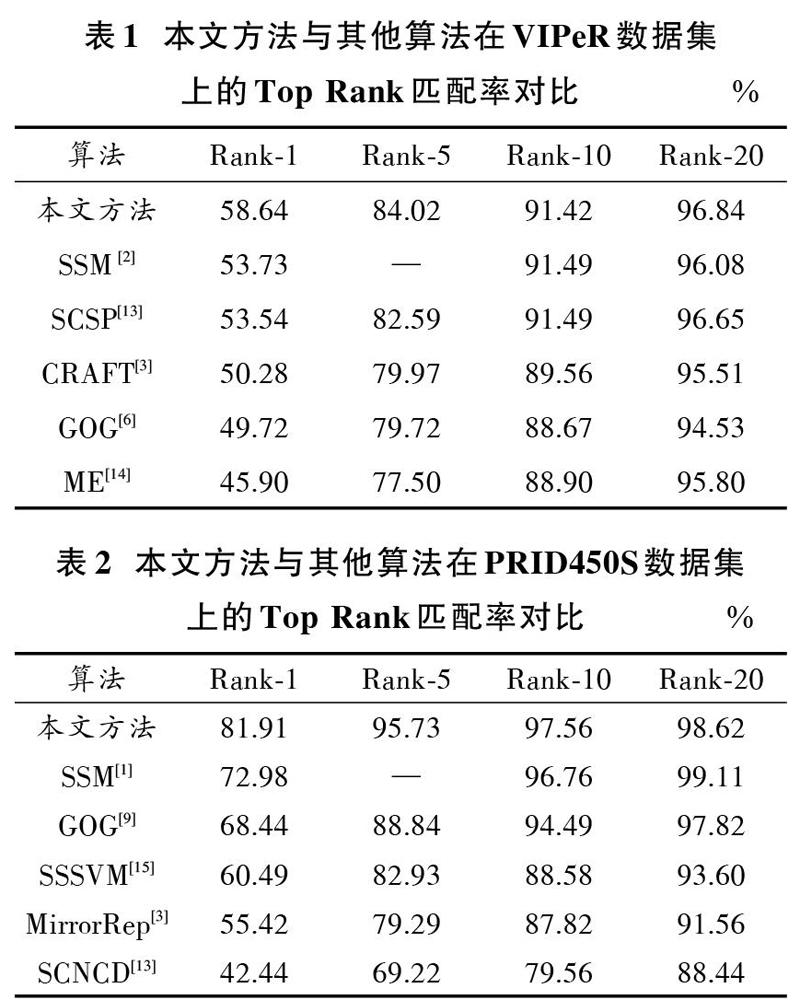
表1与表2给出了在VIPeR与PRID450S数据集上本文方法与其他文献中公开的行人再识别准确率的对比,表中仅列出了CMC中Rank?1,Rank?5,Rank?10,Rank?20上的数值。由表1,表2可以看出,本文方法取得的匹配准确率明显优于近几年公开的行人再识别方法,本文方法在两个数据集上取的Rank?1正确匹配率分别达到了58.64%与81.91%。在VIPeR上比此前最优的SSM[2]方法获得的结果53.73%高出4.91%,在PRID450S上比SSM报告的72.98%高出8.93%,与其他的方法相比要高出更多,这充分说明了本文方法在行人再识别中所具有的性能优势。
3.2 特征描述子判别性分析
本文方法取得较高匹配率的一个重要因素是具有优秀判别力的eLOMO特征表达。为了检验eLOMO特征的判别性,实验中使用本文AdaBoost多度量融合模型,对eLOMO、LOMO、本文设计的水平条区块提取的特征(标记为SF)、GOG与WHOS特征在VIPeR与PRID450S上分别进行了测试。图3给出了获得的CMC曲线。从图3中可以看出,eLOMO在两个数据集上都获得了最优的性能,证明eLOMO在刻画行人外观上具有更强的判别能力。
3.3 与各基本度量学习方法的对比
本文设计的融合方法中组合了四种度量学习方法,图4给出了它们独自取得的结果与采用AdaBoost融合后取得的结果对比(标记为AdaFusion),图4中还给出了对各个算法独立获得的距离直接使用平均加权时的结果(标记为AvgFusion)。从图4中可以看出,融合后的方法明显优于各个算法独立使用时的结果。需要注意的是采用平均加权时,AvgFusion并未比其他方法表现出明显优势,这也从侧面反映出AdaBoost提升融合时自适应赋予权值所带来的优势。
4 结 语
本文设计了一种更具判别性的eLOMO特征描述子,并提出了一种基于AdaBoost提升方法的多度量融合算法。在eLOMO特征中组合了对行人图像细节具有优秀刻画能力的LOMO特征和对整体外观具有良好表达能力的水平区块特征,取得了更加优秀的判别能力。本文提出的多度量融合方法能够自适应地赋予各基本模型最优权重,充分挖掘各度量的判别优势。在VIPeR与PRID450S数据集上的实验表明,本文方法能够有效提高行人再識别的准确率。
参考文献
[1] ZHENG Liang, ZHANG Hengheng, SUN Shaoyan, et al. Person re?identification in the wild [C]// 2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, US: IEEE, 2017: 3346?3355.
[2] SONG Bai, XIANG Bai, QI Tian. Scalable person re?identification on supervised smoothed manifold [C]// 2017 IEEE Confe?rence on Computer Vision and Pattern Recognition. Honolulu, US: IEEE, 2017: 2530?2539.
[3] CHEN Yingcong, ZHU Xiatian, ZHENG Weishi, et al. Person re?identification by camera correlation aware feature augmentation [J]. IEEE transactions on pattern analysis & machine intelligence, 2018, 40(2): 392?408.
[4] ZHANG Li, XIANG Tao, GONG Shaogang. Learning a discri?minative null space for person re?identification [C]// 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, US: IEEE, 2016: 1239?1248.
[5] LIAO Shengcai, HU Yang, ZHU Xiangyu, et al. Person re?identification by local maximal occurrence representation and metric learning [C]// 2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston: IEEE, 2015: 2197?2206.
[6] MATSUKAWA Tetsu, OKABE Takahiro, SUZUKI Einoshin, et al. Hierarchical Gaussian descriptor for person re?identification [C]// 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, US: IEEE, 2016: 1363?1372.
[7] YANG Yang, YANG Jimei, YAN Junjie, et al. Salient color names for person re?identification [C]// 2014 European Confe?rence on Computer Vision. Zurich, Switzerland: IEEE, 2014: 536?551.
[8] LISANTI Giuseppe, MASI Iacopo, BAGDANOV Andrew D, et al. Person re?identification by iterative re?weighted sparse ranking [J]. IEEE transactions on pattern analysis & machine intelligence, 2015, 37(8): 1629?1642.
[9] WEINBERGER Kilian Q, BLITZER John, SAUL Lawrence K. Distance metric learning for large margin nearest neighbor classification [J]. Journal of machine learning research, 2009, 10(1): 207?244.
[10] K?ESTINGER Martin, HIRZER Martin, WOHLHART Paul, et al. Large scale metric learning from equivalence constraints [C]// 2012 IEEE Conference on Computer Vision and Pattern Recognition. Providence, Rhode Island: IEEE, 2012: 2288?2295.
[11] LIAO Shengcai, LI Stan Z. Efficient PSD constrained asymmetric metric learning for person re?identification [C]// 2015 IEEE International Conference on Computer Vision. Santiago: IEEE, 2015: 3685?3693.
[12] XIONG Fei, GOU Mengran, CAMPS Octavia, et al. Person re?identification using kernel?based metric learning methods [C]// 2014 European Conference on Computer Vision. Zurich, Switzerland: IEEE, 2014: 1?16.
[13] CHEN Dapeng, YUAN Zejian, CHEN Badong, et al. Similarity learning with spatial constraints for person re?identification [C]// 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, US: IEEE, 2016: 1268?1277.
[14] PAISITKRIANGKRAI Sakrapee, WU Lin, SHEN Chunhua, et al. Structured learning of metric ensembles with application to person re?identification [J]. Computer vision and image understanding, 2017, 156(3): 51?65.
[15] CHEN Yingcong, ZHENG Weishi, LAI Jianhuang. Mirror representation for modeling view?specific transform in person re?identification [C]// 24th International Conference on Artificial Intelligence. Buenos Aires, Argentina: AAAI, 2015: 3402?3408.
[16] ZHANG Ying, LI Baohua, LU Huchuan, et al. Sample?specific SVM learning for person re?identification [C]// 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, US: IEEE, 2016: 1278?1287.
