数据不完备下基于特征识别的公交客流短时预测
2020-06-17方晓平林美陈维亚潘鑫
方晓平 林美 陈维亚 潘鑫
(中南大学 交通运输工程学院∥轨道交通大数据湖南省重点实验室,湖南 长沙 410075)
客流预测的时间跨度将影响公交调度效果,通常,以5~30 min为单位的客流预测为短时预测[1]。以30 min以下时间跨度为单位的短时预测多用于合理分配运输能力[2],而时间跨度不超过15 min的短时预测是主动、有效地根据乘客乘车的时间特征实施实时调度的先决条件[3]。
公交客流特征的分析可按客流数据分解和聚类展开[4]。客流数据分解是基于时序数据提取特征,将数据结构分解成高频和低频、线性和非线性等模式[5- 8],但整合各模式时所需的加权因子是其中的难点[9]。根据预定义度量和最大化组内的同质性及组间的异质性的聚类分析是常用方法[10],其中k-means聚类算法快速且容易实现,在大数据集的处理方面有较高的可伸缩性和高效性。相对于传统经验划分,k-means聚类可以划分出更详尽的数据类型,利于特征识别[11]。然而,聚类方法对“噪声”和离群点数据敏感,k的取值较为复杂[12]。在实际中可如文献[11]所述通过给出多个k值,由检验系数判断最佳聚类数。但短时客流的观测单位越接近实时,数据越容易出现异常点,k值的选定也随之变得繁琐。本质上,公交客流是不同属性的乘客对乘车时刻、日期、地点等属性进行选择以实现出行目的的乘客群,其属性数据间存在一定关联。结构化查询语言(SQL)是一种功能强大的数据分析工具和编程语言[13],它可快速识别数据间的关联性以提取所需数据[14],已有学者[15]提出将SQL用于数据特征分析。
现实中,受公交信息系统或其他应用条件限制,很难获得地点、乘客等属性数据,加之公交要实时预测,就需快速处理小规模数据,这种情况下就只能用不完备的、有限的数据进行预测。特征的识别要根据数据对象属性来选择。理想情况下,公交卡客流数据有详尽的数据属性类型,比如卡类型、实名卡数据等,可依据这些数据直接识别乘客的出行特征。但是公交卡多为非实名制,乘客个人信息、乘车环境等资料难以获得[16],一般仅有出行时间信息,有时包含与乘客间接相关的信息,比如卡号等,根据已有属性数据结构或属性间关联性对其进行拆分,是识别乘客出行特征的一种可行方法。如果拆分后的数据对象属性特征明确、结构稳定,达到重要比例,就有可能识别出未知的乘客属性特征,这就有利于分析乘客的出行特征。
客流预测一般采用两种途径:一种是直接通过分析数据的时序特征进行预测,如文献[11];另一种是通过一定方法从已有数据的关联特征去识别出新的特征,再进行预测。由于本研究以长沙市104路公交卡数据为样本,缺少乘客属性数据,因此采用后一种途径,先利用SQL分析卡号属性与乘客时间属性间的关联性,识别客流统计特征,再建立模型预测客流。
1 数据与特征分析
客流数据是预测的基础,只有掌握了数据特征才能选择适用的预测模型[17- 18]。文中数据采自长沙市公交104路2017年6月3日至30日的公交卡数据,共216 749人次。受公交系统所限,样本数据只有乘客出行日期、时刻、卡号以及客流统计量,无乘车地点和卡类型信息。每个卡号对应一名乘客,卡号与乘客刷卡时刻、日期存在关联性。
短时客流数据的特征可从序数、数值和分类属性来进行分析。分析客流数据的序数属性特征时,乘客出行日期、时刻是重要指标。以15 min为观测单位,将每日刷卡时间段6:00—22:15划分为66个片段。统计每个片段内的客流量绘于图1,可以发现:①整体上,非工作日客流量小于工作日客流量,两者具有不同波形,但均呈非平稳、非线性变化;②非工作日的高峰时段没有工作日的明显,每日早高峰的客流量明显高于晚高峰的;③客流变化具有按周和按日循环的双周期特征。与文献[11]中以30 min为单位的短时客流相比,文中短时客流波动更强。

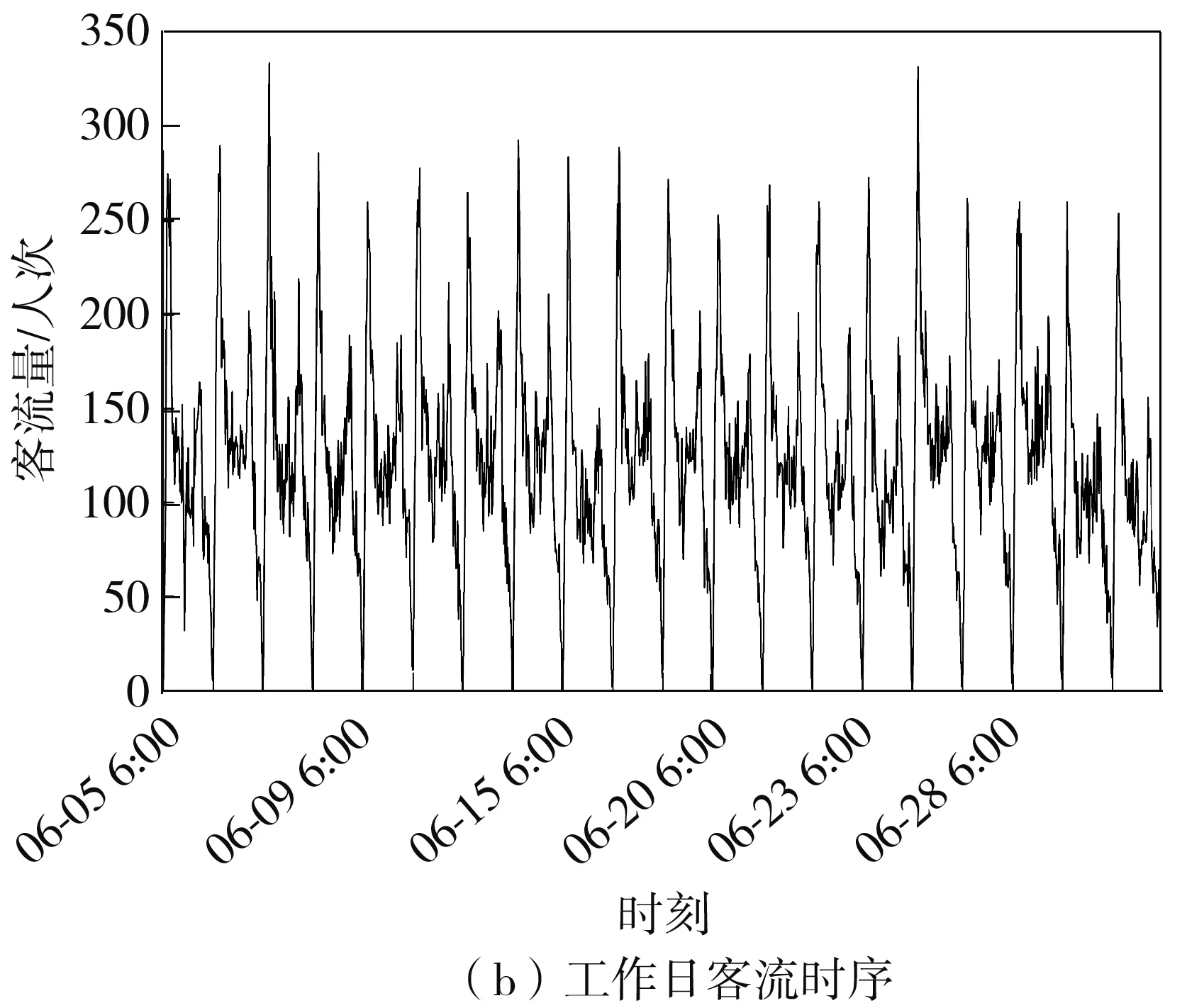
图1 2017年6月3日至30日的客流时序图
Fig.1 Passenger flow sequence diagrams from June 3 to June 30,2017
通过分析客流数据的数值属性特征,可对客流统计量进行描述。将2017年6月3日至30日分成4周,按工作日、非工作日与每周进行客流量统计,结果如图2所示。由图可知,每周客流量占总客流量的25%左右,其中每周非工作日客流量占比在6%左右,每周工作日客流量占比在18%左右,可见每周客流量基本稳定。

图2 客流量统计Fig.2 Statistics of passenger flow
进一步描述日客流统计量的特征,利用每周内周一至周日的日客流平均量与总客流量的占比分析日客流量的变动情况,结果见表1。由表可见,周一至周五的变动系数基本为1,而周六和周日的变动系数基本为0.9,说明客流在工作日和非工作日有不同的变化规律。
表1 周一至周日的平均客流量变动系数
Table 1 Variation coefficient of average passenger flow from Monday to Friday

时间周一周二周三周四周五周六周日变动系数1.0751.0781.0870.9550.9870.9360.883
分析客流数据的分类属性特征,考虑卡号与乘客刷卡时间的关联性来推断未知的乘客属性特征。以卡号为主索引,用SQL提取同一卡号的刷卡日期、时刻数据,发现有些乘客在多个工作日几乎相同时刻刷卡,也有些乘客的刷卡时刻不一定相同,但是平均每周有刷卡记录的天数很高,而其余乘客表现为偶尔出行,如图3所示。同样,也有乘客在6月内多个非工作日刷卡,其乘车的时间特征可能具有规律性。这是由于104路公交途经5个学校、21个居民生活区、12家医院和4个地铁站,通勤乘客可能占较大比例,其出行频次规律性比较强。
上述分析表明,工作日客流呈现较规律的非平稳、非线性和周期性特征,非工作日客流呈现随机性较大、周期性的变化特征,这些均符合常规的变化情况,学者们[11,19]也早已利用一定的预测模型取得了较好的预测效果。然而,客流呈现不同的变化是由于客流中混合了各种特性类型的乘客,如果具有相同或类似特征的乘客达到一定规模,那么将这部分乘客的乘车数据分离出来单独处理,有可能提升预测效果。因此,文中拟根据乘客每周的出行频次来区分乘客出行特征。
2 客流拆分
客流数据的拆分是以乘客每周刷卡的频次作为区分乘客出行特征的变量,客流总集被划分为不同特征的客流子集,分析每个子集的规模、方差来确定变量的最佳取值,从而推断客流出行特征。
对工作日客流数据进行统计,分析同一卡号在每周5个工作日出现的次数。设提取乘客数据的变量为TS,表示将每周工作日刷卡天数≥TS的乘客分离出来。以较大TS分离出来的乘客是高频出行者,定义为规律乘客(如图3(a)和3(b)所示),其余的则定义为非规律乘客(如图3(c)所示)。客流总集与不同特征客流子集的关系可表示为



图3 3种不同类型乘客的消费记录分布图
Fig.3 Distribution diagrams of consumption records of three different types of passengers
(1)

当客流子集规模达到一定大小时,数据特征明确、结构稳定,则以此拆分客流数据,推断未知的乘客属性特征。一般而言,数据集的方差平均值越小,数据变化越稳定。变量不同取值情况下的客流子集方差平均值如表2所示。
表2 变量不同取值下客流子集的方差平均值
Table 2 Average variance of passenger flow subsets with diffe-rent values of variable

变量取值方差平均值规律客流子集非规律客流子集规律-非规律客流TS=1——18.59TS=210.9711.4911.23TS=38.5115.0611.79TS=45.4416.5911.02TS=53.7117.8410.78
比较表2所示方差平均值可知:
(1)当TS=1时,客流数据未拆分,即客流总集方差平均值为18.59,变量其他取值下的规律-非规律客流方差平均值明显小于18.59,说明以乘客出行频次为变量拆分数据是可行的;
(2)与TS=2、TS=4和TS=5时相比,在TS=3的情况下,规律-非规律客流方差平均值最大,说明TS=3的情况下无法较好地分离不同出行特征的乘客;
(3)与TS=4和TS=5时相比,在TS=2的情况下,规律客流子集方差平均值明显最大,这可能是TS=2的标准太低,无法判断乘客的出行特征(因为公交卡是非实名制的);
(4)与TS=4时相比,在TS=5的情况下,非规律客流子集方差平均值几乎接近客流总集方差平均值,这是因为此时拆分出的规律客流仅占总客流的8.34%,比例太小,拆分的意义不大。
因此,变量最佳取值为4。在TS=4的情况下,拆分出的子集分别呈现明显的规律和随机变化,由此推断:呈现规律变化的客流主要是以上班、上学为主的通勤属性乘客群,具有规律的出行特征;呈现随机变化的客流主要是休闲、娱乐等非通勤属性乘客群,具有非规律的出行特征。
对非工作日客流进行统计,没有发现形成具明显统计性特征的子集,因此,文中不拆分非工作日的客流数据,直接预测其客流量。
3 客流预测
短时客流预测模型的建立主要取决于已识别的数据特征[20]。如文献[21- 22]所述,客流数据在不完备的情况下较适用的预测方法是时间序列方法,该方法适合对具有不确定性的系统进行建模。由文献[11]可以知道,自回归滑动平均模型(ARMA)的预测时间明显短于神经网络、支持向量机等模型,能更好地满足观测单位为15 min的短时客流预测的时效性要求。其中,SARIMA模型是ARMA模型的变形形式,对具有周期性、非线性和非平稳性特征的时间序列数据能建立更合理的模型[23]。因此,文中为每类数据集分别建立最优SARIMA预测模型。
考虑到样本数据具有以周为单位的周期性,将第1至第3周数据用于建模,第4周数据用于预测对比。建立SARIMA模型需要利用一定的检验标准来判定数据的平稳性,如果不符合检验标准则需平稳化处理,直到数据具有平稳性,之后由检验准则判定模型最佳参数,建立最优模型。SARIMA模型对每类数据子集的建模步骤都是一致的,而模型参数的最佳值需由具体数据来确定。用绩效衡量指标决定系数(R2)、平均绝对误差(MAE)和均方根误差(RMSE)来进行样本内(第1至第3周)和样本外(第4周)的绩效检验,评价模型预测效果。
3.1 各特征子集预测
设变量TS=4,将客流总集拆分为规律客流子集和非规律客流子集,对每类子集分别进行预测。
由单位根、时序图和自相关图检验标准判断规律客流子集的平稳性。采用Fisher Chi-square统计量进行单位根检验,检验结果中P值为0.53,大于0.05,说明序列存在非平稳性。图4所示的时序图中,序列呈现周期性的“高低峰”变化,说明序列具有非平稳性和周期性。图5所示的自相关图未快速截尾,呈三角对称形式,在周期s=66的整倍数上出现峰值,序列表现为非平稳、周期性的变化。

图4 规律客流子集原始序列图
Fig.4 Original sequence diagram of regular passenger flow subsets

自相关偏相关自相关系数偏相关系数Q统计量P值10.8840.884776.260.00020.763-0.0841355.400.00030.589-0.3161700.400.00040.399-0.1931858.600.00050.210-0.0871902.400.00060.028-0.0931903.200.0007-0.1160.0201916.600.0008-0.228-0.0031968.500.0009-0.2980.0012057.500.00010-0.336-0.0272170.600.000660.8850.1587400.100.0001320.8150.06314296.000.0001980.7460.03520565.000.000
图5 规律客流子集原始序列自相关图
Fig.5 Auto-correlation diagram of original sequence of regular passenger flow subsets
综上,规律客流子集原始序列表现为非平稳、周期性的变化,需进行平稳化处理。
通过周期性和非周期性差分处理获得平稳化差分序列,由上述3个检验标准判断差分序列的平稳性。当对某一时刻的客流数据与下一周期相应时刻的客流数据做差(即周期性差分次数D=1),对一个周期内的数据依次做差(即非周期性差分次数d=1)时,表3 所示的差分序列单位根检验在1%的显著性水平下拒绝H0(H0:序列存在非平稳性),图6所示的差分序列图围绕零值上下波动,图7所示的差分序列自相关图一步截尾。由此可知,差分处理后的序列可满足SARIMA模型的平稳性要求。
表3 规律客流子集差分序列的单位根检验结果
Table 3 Unit root test results of differential sequence of regular passenger flow subsets
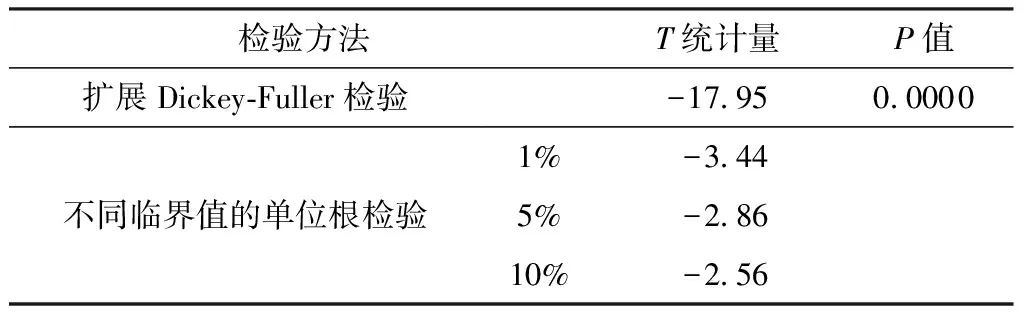
检验方法T统计量P值扩展Dickey-Fuller检验不同临界值的单位根检验 -17.950.00001%-3.445%-2.8610%-2.56

图6 规律客流子集差分序列时序图
Fig.6 Differential sequence diagram of regular passenger flow subsets

自相关偏相关自相关系数偏相关系数Q统计量P值1-0.541-0.541271.330.00020.067-0.320275.500.0003-0.021-0.231275.920.0004-0.021-0.216276.330.00050.023-0.171276.800.0006-0.013-0.154276.960.00070.003-0.142276.970.0008-0.013-0.157277.130.00090.022-0.131277.570.00010-0.005-0.116277.600.00066-0.461-0.054663.620.0001320.0350.030861.560.000198-0.072-0.036988.340.000
图7 规律客流子集差分序列自相关图
Fig.7 Auto-correlation diagram of differential sequence of regular passenger flow subsets
建立模型SARIMA(p,d,q)(P,D,Q)s所需AR、SAR、MA、SMA项的滞后阶数p、P、q、Q通过识别平稳序列的自相关图获得,由R2、赤池信息准则(Akaika Information Criterion,AIC)和施瓦茨信息准则(Schwarz Criterion,SC)判断最佳值。由图7可初步判断p和q取值分别为1、2、3和1、2,P和Q取值分别为2和2,p、P、q、Q在不同组合下获得的准则取值如表4所示。R2值越大、AIC和SC值越小,SARIMA模型越理想。当p=1、q=1、P=2和Q=2时,SARIMA(1,1,1)(2,1,2)66模型拟合效果最佳,检验结果如表5所示,表达式为
(1+0.016B)(1+0.802B66+0.071B132)·
(1-B)(1-B66)yt=(1+0.990B)·
(1+0.003B66+0.875B132)εt+0.000 7
(2)
式中:yt为预测值;B为滞后算子,即Bnyt=yt-n;εt为残差序列,需呈不相关性。
表4 滞后阶数值不同组合下的判断准则值
Table 4 Judgment criteria values under different combinations of lag order values

模型R2AICSCSARIMA(1,1,1)(2,1,2)660.786.226.26SARIMA(1,1,2)(2,1,2)660.786.226.27SARIMA(2,1,1)(2,1,2)660.786.226.27SARIMA(2,1,2)(2,1,2)660.786.226.28SARIMA(3,1,1)(2,1,2)660.786.236.28SARIMA(3,1,2)(2,1,2)660.786.236.29
用Q统计量检验模型残差序列的相关性,结果如图8所示。自相关系数和偏自相关系数都处于可接受的范围内,SARIMA(1,1,1)(2,1,2)66模型为最优模型。利用最优模型进行样本内和样本外预测,获得规律客流子集预测值。

表5 最优模型检验结果Table 5 Test results of the optimal model

自相关偏相关自相关系数偏相关系数Q统计量P值10.0010.0010.0003—20.0500.0501.9659—3-0.035-0.0352.9277—4-0.013-0.0153.0557—5-0.041-0.0374.3769—6-0.002-0.0024.3812—70.0030.0064.38720.0368-0.003-0.0064.39510.11190.0230.0224.82810.18510-0.002-0.0034.83140.305110.0280.0265.46980.36112-0.051-0.0507.60030.269130.0430.0419.10750.24514-0.029-0.0219.76850.28215-0.033-0.04010.65100.300
图8 残差序列相关性检验结果
Fig.8 Correlation test results of residual sequence
按照上述步骤对非规律客流子集建立SARIMA模型,得SARIMA(2,1,2)(2,1,3)66为最优模型,其表达式见式(3)。预测样本内和样本外的非规律客流数据,获得非规律客流子集预测值。
(1-1.004B+0.046B2)(1+0.356B66+
0.625B132)(1-B)(1-B66)yt=
(1+1.818B-0.819B2)(1+0.527B66-
0.521B132+0.878B198)εt+0.004
(3)
3.2 客流总集预测
客流总集预测是直接对整体客流建立SARIMA模型进行预测。
按照前述步骤得出预测客流总集的最优模型为SARIMA(3,1,2)(2,1,1)66,其表达式为
(1+0.615B+0.049B2+0.131B3)·
(1+0.125B66+0.151B132)(1-B)·
(1-B66)yt=(1+0.241B+0.55B2)·
(1+0.906B66)εt+0.000 7
(4)
4 结果分析
将规律客流子集预测值和非规律客流子集预测值按照对应时刻整合,获得预测总值。将该预测总值及直接预测客流总集获得的预测总值分别与观测值进行对比,分样本内和样本外绘于图9和10。


图9 观测值与各特征子集整合预测值的对比
Fig.9 Comparison of observed values and integrated predicted values of each feature subset
由图9和10可知,无论是预测各特征子集的方法还是直接预测客流总集的方法,样本内预测值与观测值的差距都明显小于样本外的,这是因为客流数据随时间随机波动。当以15 min为观测单位时,数据波动更强烈,且样本内与样本外的数据波动不一致,对样本内的客流数据预测可获得更好的预测效果。
对比图9(a)和10(a)可知,两种预测方法获得的预测值均非常接近观测值,但第2、第3周部分观测点的观测值与客流总集直接预测值相差略大。这是因为第2、第3周的工作日客流占比明显不同于第1周(由图2可知),可能不同特征的客流规模发生了变化,影响了预测效果。
对比图9(b)和10(b)可知,两种预测方法获得的预测值均与观测值存在一定差距,但各特征子集整合获得的预测总值与观测值的差距更小,这是因为预测时区分了不同特征的客流。此外,周四到周五的预测值和观测值差距比周一到周三的更小,这是因为周四和周五的变动系数小于周一至周三的(由表1可知)。


图10 观测值与客流总集预测值的对比
Fig.10 Comparison of observed values and predicted values of total passenger flow sets
将客流预测总值代入绩效衡量指标R2、MAE和RMSE,分样本内和样本外检验,获得的绩效值如表6所示。

表6 客流预测绩效值Table 6 Performance values of passenger flow prediction
分析表6所示客流预测绩效值可知:
(1)与文献[11]中ARMA模型获得的RMSE相比,文中SARIMA模型的RMSE最低为5.43,说明文中模型可对客流数据有效预测;对比文献[11]中为每个聚类建立ARMA模型获得的R2值,文中SARIMA模型获得的R2值普遍更高,最高达0.95,说明考虑客流属性数据间的关联性可很好地分析客流特征。因此,数据特征识别对预测效果还是有改善的。
(2)与对客流总集直接预测得出的绩效值相比,各特征子集预测整合得出的平均绝对误差MAE和均方根误差RMSE都优于样本内和样本外的值,MAE分别改善21.13%和36.11%,RMSE分别改善18.94%和35.48%。可见预测客流数据的方法不同,预测结果也有所变化,故区分不同特征客流进行预测是可行的。
(3)对比预测非规律客流子集获得的绩效值,预测规律客流子集获得的样本内和样本外MAE和RMSE均明显更小。这是因为样本数据属性不完备,导致非规律客流子集中可能还存在其他未知的特征未能被有效识别出来,影响了预测质量,但整体上各特征子集的预测绩效都有所提升。
5 结语
(1)客流预测的质量很大程度上受乘客出行特征的影响。预测规律客流子集、非规律客流子集和客流总集得出的样本内平均绝对误差分别为4.01、9.05和13.06,样本外平均绝对误差分别为5.19、16.82和29.24,说明文中方法对具规律性特征客流的预测效果更好。
(2)客流数据的不完备会影响数据特征识别的方式。文中受公交系统条件所限,未获得乘客属性数据。通过考虑公交卡号与乘客出行时间的关联性来识别乘客出行特征,得出的规律客流子集预测模型拟合度高达0.95,可见考虑客流属性数据间的关联有利于数据特征识别,所识别的特征是有效的。
(3)各特征子集预测整合得出的绩效相对于直接预测客流总集时的有改善。影响客流总集预测效果的因素一是时变的不确定性特征,二是构成集体的个体差异造成的混沌效应。对于前者,很多学者利用小波分析或者其他分解方法来探索其中的时变规律;对于后者,可通过聚类分析,将样本总体按照不同特征拆分成子集后再分别预测、汇总。由于各子集内部的一致性比总体的要高,因此该方法可提升预测绩效。文中研究结果也表明了该方法的有效性。
文中运用SARIMA方法得到工作日样本内的预测模型的拟合度高达0.94,样本外的为0.83,而非工作日样本外的为0.61,因此,如何提高非工作日客流的预测效果可做为下一步的研究内容。后续研究中,可考虑采用神经网络算法来预测非工作日客流,利用神经网络算法的深度学习能力来提高预测精度。此外,由于数据属性的缺失和数据收集量的限制,文中方法存在一定的局限性。后续研究中,可从时变特征识别和进一步完善不完备数据识别技术两个方面来开展工作。
