基于空洞U-Net神经网络的PET图像重建算法
2020-03-13杜倩倩杨晓棠
杜倩倩,强 彦,李 硕,杨晓棠
(1.太原理工大学 信息与计算机学院,山西 晋中 030600;2.加拿大西安大略大学,医学影像和医学生物物理学系, 加拿大安大略 伦敦 N6A 3K7;3.山西省肿瘤医院 放射科,太原 030000)
正电子发射断层成像技术(positron emission tomography,PET)技术是核医学领域比较先进的临床检查影像技术,是目前唯一可在活体上显示生物分子代谢、受体及神经介质活动的新型影像技术。它在肿瘤学、心血管疾病学、神经系统疾病研究以及新药开发研究等领域中显示出卓越的性能。PET成像的过程是通过注射或服用放射性药物,采集正电子湮灭产生的光子数目得到投影数据[1]。但数据采集持续时间长,探测器环记录的海量数据也为后续数据存储和图像重建带来困难,且对人体有一定损害,并且受探测器效率影响,检测到的投影数据受噪声干扰大,导致最终PET图像成像质量较低。
迄今为止,多种PET重建方法相继被提出。常见的重建策略有滤波反投影FBP(Filter Back Projection)方法、最大似然期望最大化MLEM(Maximum Likelihood Expectation Maximization)方法。FBP算法在断层成像中有着广泛的应用,具有形式简单、计算效率高和成像速度快等优点[2],但是却无法有效地抑制噪声,重建图像的分辨率和噪声特性非常差。MLEM算法由于能够在图像重建的过程中引入各种物理成像条件以及统计模型,具有全局收敛性、非负性和计数保持的特点[3],图像重建质量变好,空间分辨率得到提高,得到了广泛的研究与应用,成为PET图像重建的经典算法之一。然而该算法收敛速度慢,通常需要更多的计算时间,另外由于PET重建逆问题的本质, 往往会产生不稳定现象,即随着迭代次数的增加,图像反而逐步退化[4-5]。
近年来,随着深度学习技术的不断成熟,在语音、文本、视频等方面深度学习方法得到广泛的应用[6-7],基于卷积神经网络(convolutional neural network,CNN)的方法也在医学/生物成像问题中[8]提供了令人兴奋的解决方案。CNN由于通用逼近规则的灵活性能够在任务中学习复杂的非线性关系。GONG et al[9]提出了一种基于CNN的优化转移迭代PET图像重建方法,将CNN嵌入到图像表示的迭代重建框架中。由于基于MSE损失的网络框架经常会导致模糊的输出结果,QI et al[10]提出了一种由CNN搭建而成的网络框架(Dnns),使用感知损失作为目标函数以代替MSE损失。然而,基于卷积神经网络的方法在PET图像重建中存在两个问题:一是为了有效去除图像中的伪影信息,通常需要大尺度的视觉感受野来获得充分的上下文语义信息,这通常需要扩大卷积核的尺寸,而卷积核大小的增加不可避免地增加参数量,降低内存利用率;另一个是基于MSE的损失函数经常导致输出的结果模糊,影响医生的诊断[10]。
通过不需要参数的逆拉登变换进行反投影,将测量的不确定性转移到图像空间中,造成PET图像中含有径向条纹伪影和高噪声,在保持原始分辨率的同时很难去除。本文在这项工作中,首先使用逆拉登变换将光子计数数据向后投影到图像空间,在此基础上重建PET图像;并且基于上述卷积神经网络存在的缺点,提出了一种嵌套空洞卷积[11]残差块的Unet网络与感知损失相结合运用于PET图像重建中,记作D-Unet,网络框架如图1所示,以改善重建图像质量。实验结果表明,相对于其他重建算法,本文的算法在改善重建图像质量方面获得了满意的效果。

图1 D-Unet网络框架结构图Fig.1 Architecture of the proposed dilated U-Net (D-Unet) for 2D
1 相关工作
1.1 PET数据模型


(1)
其中,Nv代表重建图像中的像素数目,Nm代表响应线的数目(Lines of response,LOR),r代表光子采集过程中的散射效应和随机符合事件,在本文的方法中,设为0.A∈RNmNv表示检测概率矩阵,图像重建的过程可以看作成像过程的‘逆’过程,就是基于投影数据y,求解生物组织内放射性浓度分布x的过程。如公式(1)所示,由于病态算子A,散射和随机符合事件的存在,求解x的问题通常是不适定的。
1.2 U-Net网络
2015年,Olaf R提出了基于CNN的U-Net网络[13],最初主要应用于医学图像分割,其后在其它的领域得到了广泛的应用(例如,图像去雾、去噪、去模糊、超分辨率等方向)。U-Net网络的主体结构是编码器-解码器结构。在编码阶段,使用卷积层逐步提取特征并通过池化层逐步降低特征图分辨率,逐渐还原展现环境信息,到达瓶颈层后,再通过解码过程结合编码阶段各层信息逐步恢复特征细节和空间位置信息,还原图像精度。值得注意的是,U-Net处理从两个主要来源引入了某种程度的模糊。第一个是卷积的数学性质。其次,当特征图通过网络时,通常是池化,然后是反卷积。研究学者发现,空洞卷积通过扩大的感受野,从而处理多尺度的上下文信息,是一种消除模糊效果的有效方法[14]。对于PET图像重建,输入的含有条纹伪影的PET图像和输出的去除条纹伪影后的图像之间存在一些共同特征,图像的边缘是相似的,U-Net网络相较于普通的编码-解码网络有所不同,其具有跳跃连接结构,编码阶段提取的特征可绕过瓶颈层到达解码阶段,因此能帮助解码器更好地修复目标地细节。
2 方法描述
2.1 RnD块
RnD块是D-Unet网络的主要部分。空洞卷积被看作是在卷积核中每个像素之间插入“孔”(数值为0),对于一个扩张率为k×k的空洞卷积核,相应的空洞卷积核的感受野为kr×kr,其中kr=k+(k-1)×(k-1).PET图像去噪重建的过程中使用空洞卷积,在保持相同分辨率的情况下保持更广泛的局部信息,图2描述了RnD块的详细结构,图的左侧为RnD块的主要组成部分,右侧代表空洞卷积的处理过程,RnD 模块分别以扩张率为1,2,4将三个卷积层依次叠加,最终得到的感受野的大小为15×15,是普通情况下叠加三个标准卷积层的两倍。为了避免稀疏空洞卷积带来的细节损失,在RnD块中加入了一个短距离的跳跃连接[15],同时有助于恢复图像细节。RnD模块的公式表示如下:
xi+1=F(r3,F(r2,F(r1,xi)))+xi.
(2)
式中:F表卷积函数,ri代表空洞卷积的扩张率,这里分别对应1,2,4.

图2 RnD的模式(左)和不同的空洞卷积对应的接受域(右)Fig.2 Schema of the RnD blocks (left) and corresponding receptive field (right) for each dilated convolution
2.2 网络架构
本文所提出的空洞U-Net(Dilated U-Net,D-Unet)重建网络模型的体系结构如图1所示,粉红色阴影所表示部分代表RnD块,网络输入的带有噪声和条纹伪影的FBP PET图像,主要是实现像素到像素之间的输出。它由47层组成,包括9个RnD块(图2中红色阴影所表示部分),4个反卷积层,30个卷积层,4个池化层,和其他的批量归一化(Batch Normalization,BN),修正线性单元(Rectified linear unit,ReLU).对于PET重建,输入的是反投影光子数据得到的含有径向条纹伪影和高噪声的图像,输出的是重建的PET图像,n指的是特征图的数量,d指的是空洞卷积的扩张率,k指的是卷积核的大小。在编码阶段,一开始的卷积层用来提取PET图像的抽象特征,其次特征图进入所设计的RnD块,通过引入空洞卷积,有效的感受野增加,同时在不增加参数量的情况下,用和普通卷积相同数量的参数聚合多尺度上下文信息。在解码阶段,为了实现像素到像素之间的输出,在编码阶段对输入的图像进行池化操作后,需要对提取到的特征映射再进行反卷积,以便恢复到原始图像的尺寸。为了更好地保存原始图像的信息,本文还采用了跨层连接的策略,将输入到网络中的图像与反卷积后相同维度的图像进行融合。
在以往的工作中,多采用真值图像和输出结果之间的MSE作为损失函数,通常定义为:
(3)
其中,xsim代表含有径向条纹伪影和高噪声的PET图像。然而,该损失函数是定义单个图像像素之间的差异,完全基于该损失函数的优化可能导致模糊的网络输出,具体表现为PET图像上缺乏连贯的网络细节[16],进而对医生的诊断产生负面的影响。因此,为了提高PET图像重建的结果质量,在MSE损失函数的基础上额外增加了感知损失,该损失函数是由预训练的深度卷积神经网络(visual geometry group at oxford university,VGG16 networks)所定义,感知损失函数定义如下
(4)
其中,φ表示特征提取操作符,是基于预训练的网络的输出,通过比较特征图而不是像素强度,可以使网络在保持图像细节的同时更有效地去除噪声。由此,总损失函数可以表示为,
ltotal=αlmse+βlperceptual.
(5)
基于ltotal损失函数的D-Unet 一旦训练好,我们可以应用它到任何新的输入(即含有径向条纹伪影和高噪声的PET图像),并且可以得到良好的去伪影重建效果。采用VGG16网络的第一个池化层之前的输出作为提取的特征,以相同的空间大小作为输入,共提取64幅特征图。这个过程如图3所示。利用通用图像训练出来的VGG16网络由于网络层的增加通常能够得到更低水平的特征,从而获取较好的表现结果。假设医学PET图像也有如此表现,我们尝试从更深的网络层中提取特征,但性能不如只选取第一个池化层提取的特征结果,其原因值得进一步研究。

图3 基于VGG网络的特征图生成过程示意图Fig.3 Schematic of the feature map generation process based on the VGG network
总的来说,如图4所示,所提出的用于PET图像重建的 D-Unet模型包括3个步骤:1) 根据PET成像原理,由目标域(GT图像)生成仿真数据集,并将其分为训练集和测试集,并保证来自同一目标域的测试集性能达到最新水平;2) D-Unet中分别输入含有噪声和径向条纹伪影的PET图像xsim,并与真值/标签PET图像xgt计算MSE损失和VGG感知损失。根据公式(5),使用Adam方法优化并更新D-Unet中的权重参数,不断迭代;3) 当D-Unet模型得到充分的训练时,将来自源域的xsim用D-Unet进行重构,得到与真实PET图像xgt极度相似的PET图像,该网络详细训练过程详见图5.

图4 本文方法缩略图Fig.4 Proposed overall architecture

图5 D-Unet网络训练过程Fig.5 Training process of D-Unet
3 实验
3.1 质量评价参数
为了定量、客观地评价重建图像质量,需对重建结果进行定量描述。采用一些常见的质量评价参数定量分析图像的重建质量,分别是偏差、方差、峰值信噪比,定义如下:
1) 偏差(Bias).
(6)

2) 方差(Variance,Var).
(7)
式中:Ns代表同一噪声水平情况下随机泊松噪声的实现次数,这里Ns=10,方差给出了重建图像之间的对应像素的离散程度,方差越小表示重建图像质量越好。
3) 峰值信噪比(Peak Signal To Noise Ratio,PSNR).
(8)
峰值信噪比是基于图像对应像素点间的误差,即基于误差敏感的图像质量评价,峰值信噪比越高表示图像失真越小,重建图像质量越好。
3.2 数据集
许多深度学习实验的主要瓶颈是可用数据集的有限大小和标记数据的缺乏。通过综合生成标记数据来绕过这个问题。真值数据是从阿尔茨海默病神经成像计划(ADNI)数据库中大脑扫描的轴向切片中提取出来的。关于ADNI PET数据获取协议的详细信息可以在UCLA神经成像实验室(LONI)的网站上找到(http://www.loni.ucla.edu/ADNI/Data/ADNI Data.shtml).具体来说,一个真值图像通过拉登变换产生没有噪声干扰的正弦图数据(投影数据),对真值图像的投影数据加入泊松噪声。利用斜坡滤波和线性插值的逆拉登变换,将正弦图反投影到图像空间中,生成含有噪声和条纹伪影的输入图像。泊松噪声(示踪剂剂量)水平可以通过设置从探测器收集的光子总数来调整。在本研究中,训练数据光子总数计数值为3×106.模拟10次随机泊松噪声实现,并分别进行了重构比较。每0.718°在平行光束几何图形中收集投影,每张PET图像切片共使用252个视图角度。训练数据为8 000张128×128的切片,测试数据为100张128×128的切片。其次,为了验证D-Unet的鲁棒性,本研究准备了四个不同噪声水平的测试数据,分别为1×105,1×106,3×106和1×107,代表不同的光子总数控制噪声水平的PET数据。
3.3 训练细节
本工作中的VGG网络[17]是在ImageNet[18]上预训练的。所有卷积核权重初始化均采用何凯明初始化方式[19]。D-Unet使用Adam优化器[20]进行训练并且相应超参数设置为β1=0.9,ε1=108,β2=0.999,该超参数的设置是参考论文的推荐值[20],并且实验证明该超参数设置能够加快训练速度, 同时在训练过程中更容易跳出极值解,避免陷入局部最优解。批量大小设为20,网络在迭代2 000次左右时验证集上感知损失不再明显下降,因此选择第2 000次保存的权值作为最终的模型参数。其固定学习率为0.000 1,并逐渐降低为0.另外,我们设置α=0.1,β=1,根据之前的研究[21]和实践,发现设置这些权重是足够的,这样不同损失项的大小就可以平衡到相似的比例中。本文的实验环境是基于内存为16 GB的Intel Xeon E5-2680服务器,显卡为Nvidia Tesla K80c,应用的深度学习框架为tensorflow 1.14,采用的编程语言为python3.6.
3.4 不同噪声水平的重建效果
图6(a)-(c)显示了所提出的方法在不同的噪声水平下的重建结果,可以清楚地看到,D-Unet去除了大部分的条纹伪影,并且保留了底层PET图像详细的细节结构。当光子计数量为1×107时,重建出的PET图像与GT图像非常相似。然而,对于光子计数量为1×105时,大部分径向条纹伪影和高噪声被有效抑制,但是边缘细节有明显的损失。这是因为探测到的光子数较低,并且在投影空间中有明显的信息丢失。
3.5 几种重建算法的比较
为了验证本文所提方法的有效性,将D-Unet方法与传统的FBP,MLEM,基于深度学习的PET重建方法(Dnns),以及仅含有MSE-loss的D-Unet方法5种算法进行比较分析。其中,MLEM选取第38次迭代的重建结果,对于Dnns,对训练过程执行了500个epoch,以使得重建结果达到最优效果。不同噪声水平下的重建结果如图6所示。
图7给出了总光子数量为3×106,不同对比试验方法得到的重建结果,可以看出,D-Unet的重建效果要优于其他图像重建算法。传统的MLEM重建效果差,重建的图像具有很明显的噪声;使用基于深度学习的Dnns方法,噪声已经得到一定程度的抑制,但图像仍有伪影的存在;使用损失函数为MSE的D-Unet方法,去噪性能得到进一步的改善,但可以看出本文算法重建图像所含的噪声最少,重建图像和真实图像最接近;边缘保持方面,传统的MLEM方法破坏了物体的边缘结构,边缘线出现锯齿形状,但是本文方法能较好地保持图像的边缘。
为了更好地了解重建图像的质量,画出上面5种算法重建图像沿不同方向的轮廓线,以及他们和真实轮廓线上像素值的的绝对差,这些轮廓线穿过了边界以及不同区域,因此图像重建算法可以用轮廓线的比较来衡量,结果见图8,从图8(a)和(b),可以发现,D-Unet方法能够有效地恢复图像像素值,MLEM和Dnns在0 °和45 °方向的轮廓线有明显的漂移,和没有应用感知损失的方法相比,运用感知损失的方法能够使重建的图像的轮廓线更接近于真实图像的轮廓线。这一结论同样也可以从(c)和(d)中得出,D-Unet重建图像和真实图像轮廓线上像素值的绝对差普遍比其它算法的要低,而且它的轮廓线上的像素值变化趋势和GT图像像素值变化趋势非常接近,这也说明了D-Unet算法在边界保持和像素值恢复上具有优势。

图7 真值图像及各算法重建结果图像(光子计数量为3×106) Fig.7 GT PET image and reconstructed PET image using different methods (photon counts is 3×106)
图9给出了D-Unet在结合不同损失函数的情况下对应的网络训练过程曲线图,从图中可以看出引入了感知损失的模型在训练步数为750次附近时损失值就已经达到比较低的水平,并且保持较小幅度的浮动,相似的实验结果在图7(e)和(f)也有体现,这也证明了感知损失在优化训练网络,提高重建像素精度方面发挥了重要作用。
表1列出了针对100张测试PET图像数据,5种算法的PSNR,Bias,Variance质量参数的均值标准差(Mean±SDs)的对比情况,对于PSNR,可以发现传统方法MLEM表现出较差的性能(28.75±3.39 VS 33.46±4.08),原因是MLEM在图像重建的过程中直接采用投影数据进行建模,而投影数据中含有大量的噪声,重构过程中无法对噪声进行有效地抑制。对于基于深度学习的方法,Dnns的PSNR数值明显低于D-Unet(mse)方法(28.51±3.12 VS 29.13±3.22),这也表明了嵌套结合空洞卷积的Rnd块的U-Net网络通过最大程度的获得感受野,从而有效地进行PET图像去躁。当U-Net网络结合感知损失作用于FBP PET图像时,Bias数值明显小于仅使用mse损失函数的U-Net网络(0.03±0.01 VS 0.07±0.01),Variance 数值也表现出一样的趋势(0.12±0.04 VS 0.11±0.02),可见本算法的性能优于其他的图像重建算法。这得益于该方法使用U-Net在对PET图像进行编码与解码降噪的过程中,结合空洞卷积扩大感受野与感知损失函数良好的细节和边缘保持能力,实现了优势互补。表2统计了不同对比方法分别训练和重建一张PET图像所需时间,从表中可以看出,本文所提出的方法在网络离线训练完成后,由于方法耗时较少,该方法在PET扫描仪上的实时重建效果明显优于其它方法。
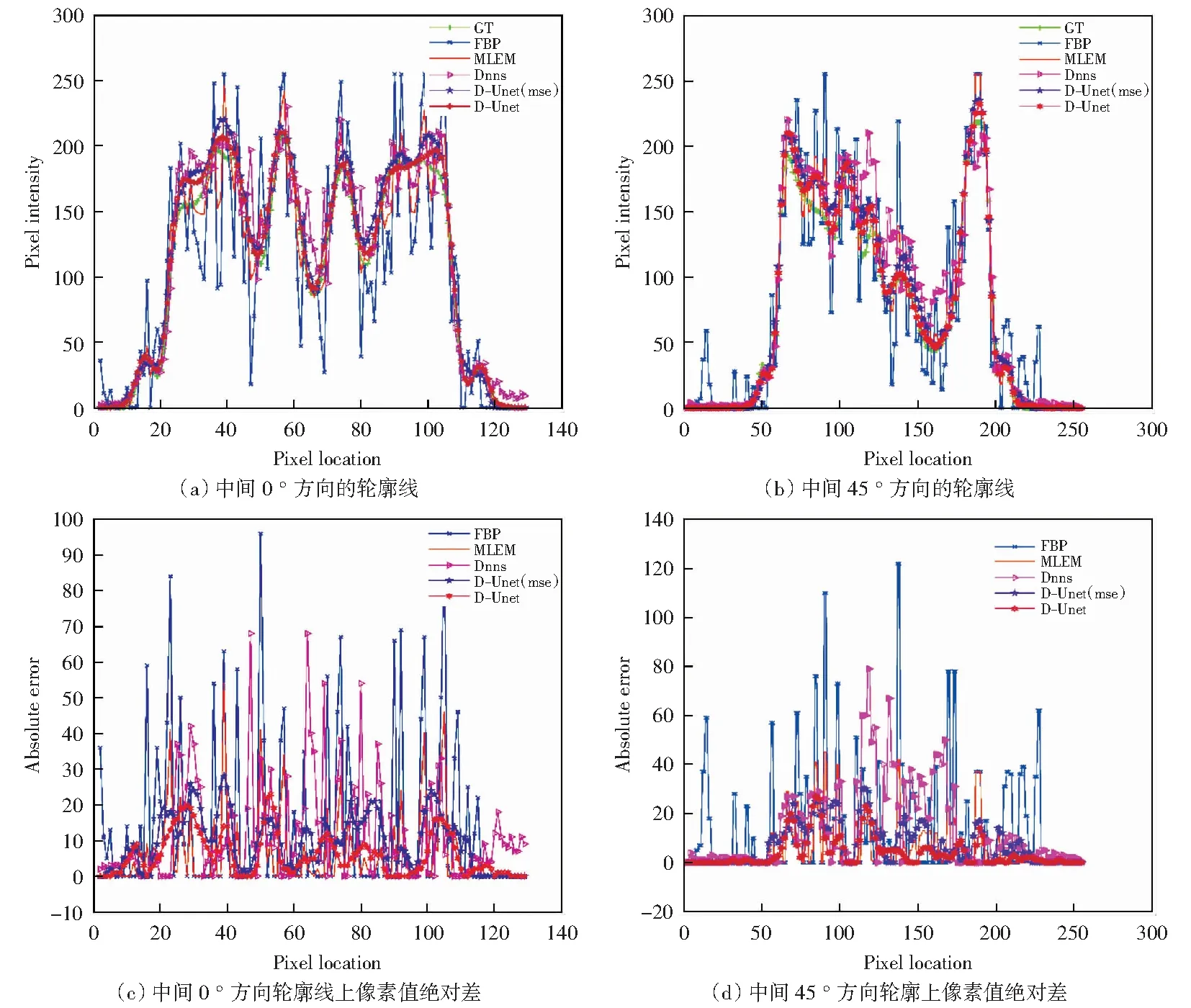
图8 重建图像在不同方向的轮廓线以及轮廓线上像素值的绝对差Fig.8 Contour lines of the reconstructed image in different directions and the absolute difference of pixel values on the contour lines

图9 训练过程曲线图Fig.9 Curve of training process

表1 各重建算法的质量评价参数(Mean±SDs)Table 1 Quality evaluation parameters of each recons- truction algorithm (Mean±SDs)

表2 算法的运行时间Table 2 Running time of the algorithm
4 结束语
本文提出了一种新的基于空洞卷积的U-Net网络,与感知损失函数相结合,并将其应用于PET图像重建中,通过与其它重建算法进行比较的实验表明,无论从主观的视觉效果还是从客观的质量评价参数看,本文提出的方法能很好地抑制噪声,提高成像质量,有利于实际的应用。算法的有效性与可行性得到了验证。该算法除了可以应用于PET、医学CT等医学成像领域之外,在工业CT、无损检测方面也有良好的应用前景。
