基于k-means聚类的居民阶梯电量制定方法
2019-12-11邓雅心
李 昂,叶 欣,邓雅心
(1.陕西理工大学 电气工程学院, 陕西 汉中 723000;2.国网青海省电力公司 经济技术研究院, 青海 西宁 810000)
近年来,国家持续深化电力体制改革,推进销售电价改革工作。阶梯式电价改革方案能够改善交叉补贴现象、促进节能减排、引导用户合理用电,在我国经过试点探索,随后实现全面推广。长期以来,分段电量的制定一直是研究的重点。
居民阶梯电价是一种先进的非线性电价定价机制,它按照用户消费的电量分段定价,单位电价随用电量累计增加呈阶梯状逐级改变。付飞翔等[1-3]介绍了阶梯电价的产生背景以及在多国的发展与差异。张粒子[4]指出,居民阶梯电价分为递增式和递减式两类,我国适宜采用居民阶梯式递增电价(下文统一简称阶梯电价)。分档次数是整个阶梯电价方案的基石,只有确定好合适的分档次数才能确定分档电量与分档电价[5]。张粒子等[6]应用家庭电器设备估算法和概率统计方法确定各段阶梯电量及其覆盖率的范围。黄海涛等[7]基于改进的密度聚类的分析方法来确定各阶梯电量。朱柯丁等[8]采用秩和比法以及计算机循环算法确定合理的分段阶梯数和各阶梯电量。刘自敏等[9]基于中国家庭动态跟踪调查数据,通过反事实场景构建和截面门槛模型来分析各阶梯电量。
上述文献所探讨的阶梯分段电量制定方法,大多是运用经济学原理和数理统计分析的数学建模过程,其模拟结果具有一定的理论性与科学性,在实际应用中也起到了不错的效果。但是,建模函数往往不能将所有的影响因素考虑周全,导致其拟合结果存在一定程度的偏差。另一方面,我国各地现行的阶梯电价政策,大多都是几年前制定的,已不能完全适应与贴合快速发展变化的市场环境。因此,有必要建立一种新的阶梯电价制定策略。智能电网的推广和大数据理念的应用,为解决类似问题提供了新思路。智能电网是大数据最重要的应用领域之一[10]。在智能电网深入推进的形势下,电力系统的数字化、信息化、智能化不断发展,带来了更多的数据源[11]。何文韬等[12-13]对未来大数据的发展与应用进行了探讨与展望。杨德昌等[14]结合聚类与预测方法进行短期负荷预测。王帅等[15]使用密度峰值聚类算法分析多种用户类型的负荷曲线。杨卫红等[16]通过对用户的用电行为聚类以分析用户参与电网调节的潜力。王保义等[17]关注用电数据的隐私保护并提出两阶段聚类方法。
智能电表、在线状态监测设备、数据传输和存储设备的推广使用,方便电网企业从亿万居民家庭终端采集、传递和存储海量的居民用户历史用电信息。本文正是基于这些电力大数据,运用聚类的大数据分析方法,探讨阶梯电价的分段阶梯数和各阶梯电量的制定方法。与前文中提到的传统策略相比,本方法直接从居民用电实际情况出发,原理简单,避免了建模误差,具有良好的真实性、时效性。
1 阶梯分段的k-means聚类方法原理
聚类起源于分类学,是数据挖掘与统计分析中的一个重要的研究领域。从机器学习的角度看,它是一种无监督的机器学习方法[18]。在事先对数据集的分布没有任何了解的情况下,通过聚类,可以将数据集划分为由若干相似对象组成的多个组或簇,使得同一组中对象间的相似度最大化,不同组中对象间的相似度最小化。k-means算法是一种基于划分的聚类算法,是MacQueen在1967年首次提出。通常使用误差平方和(Sum of Squared Error, SSE)作为度量聚类完成度的阈值目标,即对每个簇中的每个对象,求对象到其所属簇的聚类中心的距离的平方和。这个准则试图使生成的k个结果簇尽可能地紧凑和独立。SSE定义如下:
(1)
式中x表示数据对象,vi表示聚类ci的聚类中心,k表示聚类个数,d(vi,x)表示距离函数,i=1,2,…,k。
聚类分析中所用到的距离函数有多种定义形式,其中最常用的是欧几里得距离,表示如下:
(2)
图1展示了k-means聚类的具体步骤。

图1 k-means聚类的原理
由智能电网系统获得的居民历史用电量数据,是对居民用电行为特性的最真实、最直观、最可靠的反映。而居民用电行为特性的形成,是多种因素综合作用的结果,如各地区的经济发展水平、电力资源的稀缺程度、居民用户的电力需求弹性、家庭的人员组成与电器存量、居民的收入差距与消费特性、地区的季节规律和气候环境等。
应用k-means算法,根据历史用电量数据对居民用户进行聚类,将具有相似用电量级的用户划分为一个簇,最终形成多个簇。在一个周期内,相似的用电量级很大程度上能反映出相似的用电行为特性,进而间接反映出其背后的多种影响因素。可以认为,借助k-means算法能够避免对影响因素考虑不周的风险,由此跳过传统建模的缺陷,直接从实际现象出发处理问题。
聚类的结果是形成多个簇,可将这些簇作为天然的阶梯电量划分依据,其中,簇的数量对应分段阶梯数,簇与簇之间的边界量对应各阶梯段的分界电量限值。
2 聚类有效性评价
2.1 进行有效性评价的必要性
由上文可知,阶梯分段数量等同于k-means算法的初始k值,要将居民历史用电量信息的数据集划分为多少个簇群,成为问题的关键。
通过文献研究可知,在目前采用阶梯电价制度的国家中,国际上阶梯分段数量从2阶到9阶不等,并在不时调整变化;就我国而言,阶梯电价被划分为三档。目前世界范围内并没有一个完全明确的分段依据。
因此,在使用k-means算法进行聚类时,应该选取多个不同的k值,得到不同的阶梯分段方案,再选择合适的评判方法,通过对比来评价各个方案的效果,选出相对最优方案作为阶梯分段方案的参考。
2.2 有效性评价的原理
评价聚类结果主要采用内部质量评价准则和外部质量评价准则,其中内部质量评价准则仅依赖数据集的固有特征和量值来进行评价,适合用来评价聚类效果的优劣和判断簇的最优个数。
Yanchi Liu等[19]列举了CH指标、DB指标、S_Dbw指标等11种广泛使用的内部质量评价方法,并结合实例,从识别单调性、噪声、密度不均、亚群和偏态分布等五类不同干扰的能力上对这些方法进行了对比验证,最后认为S_Dbw指标表现最为良好。Halkidi等[20]详细介绍了S_Dbw指标的定义方式。本文采用S_Dbw指标来评价聚类有效性。
对于包含n个样本的数据集S的一个划分D={vi|i=1,2,…,k},对聚类的平均标准差stdev、方差σ2、密度函数density(uij) 、功能函数f(x,u)做预定义。如下:
(3)
(4)
(5)
(6)
(7)

由于聚类的目标是使同一簇内的对象尽可能相似且不同簇中的对象尽可能不同,因此内部质量评价准则通常基于以下两个标准:簇间分离度和簇内紧凑度。在S_Dbw指标中,这两个标准由簇间密度Dens_bw(k)和簇内方差Scat(k)反映。
簇间密度定义
(8)
式中分子表示两个簇的分界点附近的样本密度,分母表示这两个簇的聚类中心附近的样本密度。如果两个聚类中心分得很开则分子就较小,每个簇各自密度很高很紧凑则分母就较大。因此,簇间密度指标越小,表示聚类效果越好。
簇内方差定义
(9)
式中分子反映了每个簇内部的各自的离散程度,分母反映了整个数据样本集的离散程度。方差越大,表示特定数据集的离散程度越大。如果簇内分布越紧密则分子就越小,簇间分布越离散则分母就越大。因此,簇内方差指标越小,表示聚类效果越好。
综上,可将S_Dbw指标定义为簇间密度指标与簇内方差指标之和:
S_Dbw(k)=Dens_bw(k)+Scat(k)。
(10)
对于同一个数据集S,能使S_Dbw指标最小化的值,则为能使聚类效果达到最优的聚类簇数。
3 实例分析

图2 阶梯分段方案实现流程图
本文讨论的基于k-means聚类的居民阶梯电量制定方法,其具体实现流程如图2所示。现结合实例进行分析。
3.1 数据采集
本文以西北地区某三线城市H市的居民家庭用电量数据进行实例分析。该数据来源于2017年H市21 645户居民家庭的实际年用电量数据,样本数据来自本地高中低档小区的城市居民家庭以及辖区内的农村居民家庭。
图3展示了H市居民家庭的年用电量与家庭数目的比例关系。由帕累托曲线可知,用电量最大的20%的家庭消耗了约40%的电能,而用电量较少的40%的家庭只消耗了约15%的电能。该地区的电能消费分布不均。
图4展示了H市居民家庭年用电量的概率分布情况,由图可知,约90%的居民家庭用户其年用电量在3300 kW·h以内,且总体上呈线性趋势分布。
H市居民阶梯电价现行标准于2012年颁布,执行三段阶梯分段,分段电量限值每月为180 kW·h和350 kW·h,折合每年为2160 kW·h和4200 kW·h。结合图3可知,三段家庭用户数量占比分别约为60%、38%、2%。前两段覆盖用户比例明显偏大,使得三段式阶梯不能完全发挥理想的调节分档作用,还可能导致电力公司的营业损失。
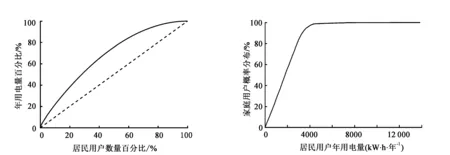
图3 用电量帕累托曲线 图4 用电量概率分布曲线
3.2 数据处理
将样本数据按照年用电量大小进行排序,设定每户保障电量为每月60 kW·h,极大电量为每月600 kW·h,折合为每年720 kW·h和每年7200 kW·h。按照此标准筛选出17 422户数据样本进行聚类。通过数据筛选,可以人为提高初始阶梯段的用户覆盖范围,并且排除极大离群值对聚类准确性的影响。
使用k-means算法将筛选后的数据进行聚类,初始k值依次选择为2到9,得到8组k值不同的聚类结果。表1展示了几组聚类结果的S_Dbw指标,图5展示了这些指标的变化趋势。

表1 聚类有效性评价指标
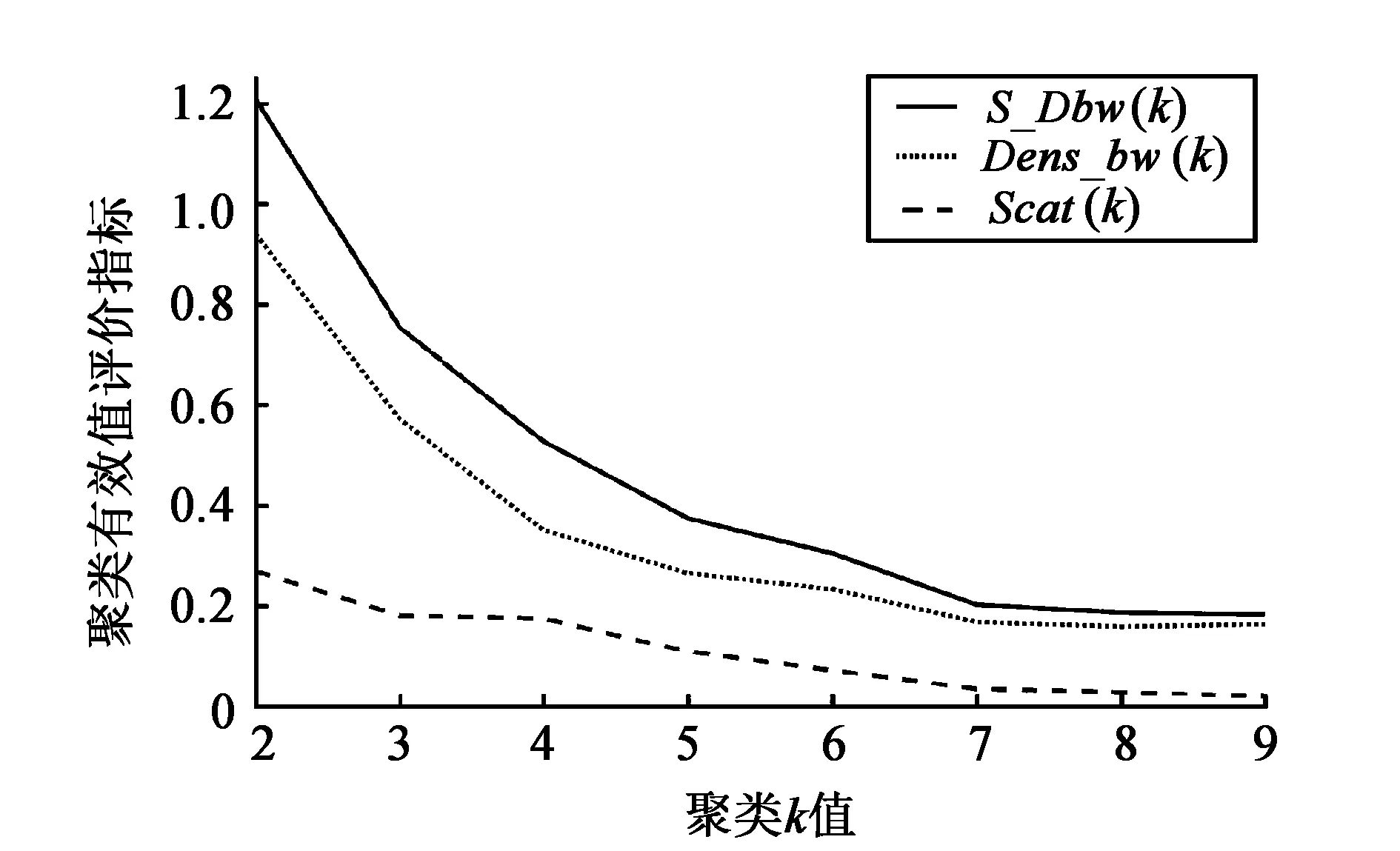
图5 聚类有效性评价指标变化趋势
3.3 分段阶数的选取
由表1和图5信息,结合S_Dbw指标属性可知,随着k值的增加,聚类有效性递增,但有效性的正向加速效率逐渐降低。
同时分析聚类结果,观察到k值取6到9时,聚类差异主要表现在对电量极大值的分配上。另外还应考虑到,阶梯分段数量过多,会对电力用户的认知、接纳和电网企业的推广、结算带来诸多不便。综合上述因素,可考虑选取k值为5。对各簇分界点数值适当取整,结合整个数据样本,得到各段电量界限以及用户分布,如表2所示。

表2 阶梯分段和用户分布
表2中分段方案与H市现行方案相比,具有明显的特点,具体表现在:
(1)将原本的3段阶梯细分为5段阶梯,第1、2阶属于低电量段,第3、4阶属于中电量段,第5阶属于高电量段;低、中、高三阶用户覆盖率大体上维持在原水平,但各段电量上限适当降低,更适应当地的经济发展水平。
(2)第1阶用户数超过40%,但用电量却不到20%,将这部分用户细分出来,能够更有针对性地制定相应的电价补贴政策,保障低收入群体的民生需求。
(3)中电量段的两阶共30%用户消耗了超过50%的电量,这部分用户属于社会的中产阶级,是电力消费的主力军。
(4)在后续制定电价费率时,考虑保证电网在第3阶的合理盈利,对于第4、5阶用户,应该制定相对较高的费率,引导用户节能减排,同时达到对第1阶的补贴作用。
4 结 论
本文结合电力大数据的发展背景,应用k-means算法对地区家庭用户的历史用电量数据进行聚类分析,并且选用S_Dbw指标对聚类结果的有效性进行验证,选择最优聚类方案,从而得到一种贴合当地实际情况的阶梯电价分段电量的制定方案。
在本文的基础上,选择合适的阶梯费率制定方案,以及将阶梯电价与峰谷分时电价、居民电采暖电价等政策相结合,以更深入地进行下一阶段的研究。
