当代小说句式特征的计量研究
——《繁花》与其他10部茅盾文学奖作品对比
2019-11-20刘海涛王雅琴
刘海涛,王雅琴
(浙江大学 外语学院,浙江 杭州 310058)
一 引言
20世纪末,随着新技术手段不断发展,早期注重传统印象直觉式分析方法的文体学家逐渐突出科学和跨学科研究的重要性,由此以计算机为基础的定量方法在文体学中开始盛行。与单纯的定性研究相比,量化研究结果为文体风格研究提供了全新的思路,使其更具科学性和客观性。[1]使用科学统计方法对文学作品评析进行验证,促进了文体研究的发展,为传统的思辨方法提供了客观的证据,有助于进一步探讨文学作品的艺术和审美效应。
上海本土作家金宇澄所著的《繁花》[2]一书(以下简称《繁》)自问世以来,反响巨大,并获得了第九届茅盾文学奖。书中对句法形式的突破尤为显眼,也吸引了语言学家的目光,被称为重现的民间“话本腔”[3-4],在当代小说中可谓独树一帜。书中对话铺陈,短句丰富,标点简单,律动鲜明。小说汲取传统的力量[5],形式繁复[6],铺张的叙事方式尤为惹眼[7]。张定浩指出,作者通过对现代汉语结构的“分解、破坏与创造”[8],形成了自己的一种语言。沈家煊以《繁〉为出发点,讨论汉语句法结构的本质特点。[4]这些研究表明,对该小说中具有传统“汉语腔”特点的语言进行调查,有利于从汉语实际出发,回归汉语自身的特点。因此,对于此种具有典型汉语特征的文本进行深入研究是非常必要的。
已有研究发现,句法特征在计量文体学(stylometrics,也称计量风格学)研究中发挥着重要作用[9-10],句法特征的效能可与词汇特征相媲美(效果甚至超过词汇特征),是一个高效率和高准确率的特征向量。目前已有不少有关当代小说的计量文体学研究成果[11-13],但由于种种条件限制,这些研究大多停留在词的水平上,主要关注词汇信息(如词频)和句子、短语的统计特征(如句长和词长等),句法特征的潜力还未充分发挥。因此,对中国当代文学作品句式特点进行计量研究有其必要性,有利于描述不同作家风格,挖掘文体特点,促进文体研究的现代化与科学化。
在计量语言学领域,关于句法结构的语言定律早已备受关注,注重使用数理统计方法的计量语言学以真实文本为对象,探究人类语言背后的规律,提高了研究成果的科学性和客观性。[14-15]学者们已发现很多具有普适性的定律,这些定律对不同语体中的语言现象、语言结构、结构属性以及它们之间的相互关系进行动态分析和描写,以揭示语言背后的规律。对当代小说句式特征的研究有利于从系统科学的角度全面理解其文体语言现象,也有助于发现当代汉语的句式特点和语言规律。
鉴于上述背景,本文拟采用计量方法,以《繁》为例,对当代小说的句式特点进行计量研究,此外选取了10部字数、时间与《繁》相近的茅盾文学奖获奖小说,作为对照语料。研究问题主要集中在以下三个方面:汉语腔的特点、整齐并置的短句以及韵致序列特征。通过将《繁》与这些作品进行对比,探究当代小说的句式特征,不仅有助于加深对汉语句法结构的认识,也对后续的汉语句法和文体研究有一定的启示作用。
二 语料构成
本文的语料包括《暗算》《秦腔》《繁花》《额尔古纳河右岸》《湖光山色》《天行者》《蛙》《推拿》《一句顶一万句》《生命册》《黄雀记》共11部小说(语料相关信息见表1)。由于汉语的词语之间没有空格等间隔符,为小句长和句长的统计带来困难,因此本文采用中科院分词软件——ICTCLAS汉语分词软件对文本进行分词(1)http:∥ictclas.nlpir.org/,对原始语料进行分词,并对分词后的语料进行了人工校对等后续处理。。
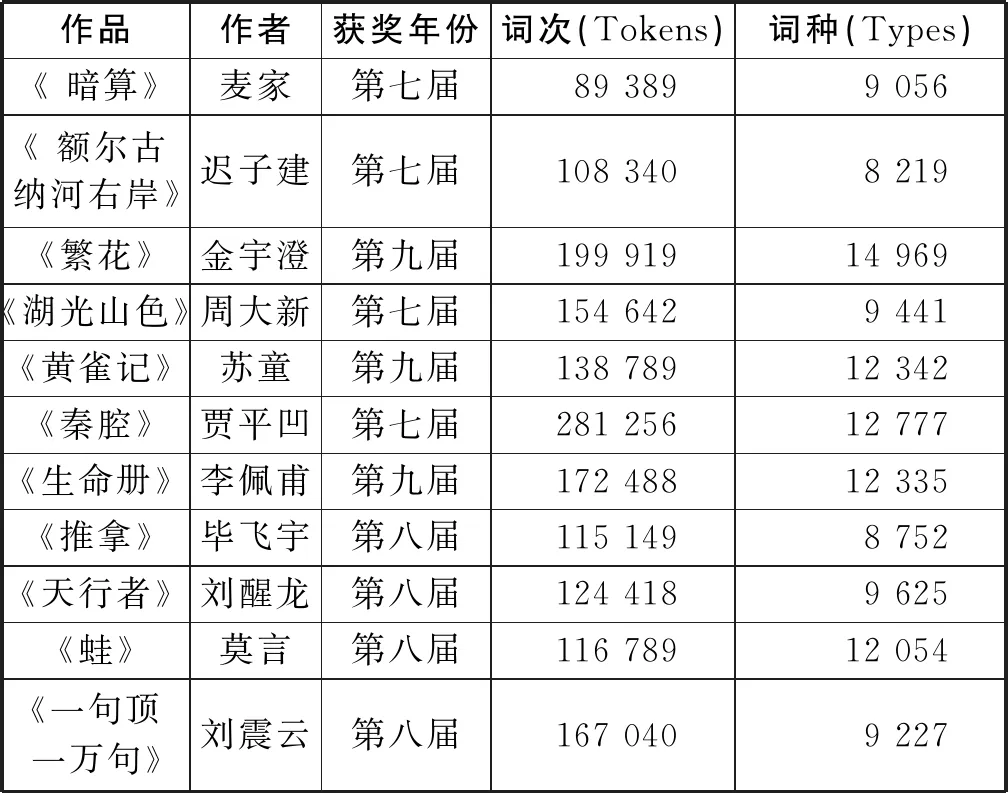
表1 语料相关信息(分词后)
三 汉语腔特点
赵元任[16]提出,汉语主要靠停顿和语调界定句子,他认为主谓形式齐全的句子为整句,主谓形式不齐全的小句为“零句”。在有意经营的话语中,整句是主要句型,而日常口语中,零句是根本。[16-17]汉语中零句可独立成句,也可与其他零句共同组成整句,直接导致了汉语中的“流水句”现象。[18]语言学家评价《繁》是“中国人血液里的东西”[4]9,也是名副其实的“汉语腔”。小说文从句顺,行文流畅,有大量的流水句和零句,读来一气呵成。以下3个例子充分显示了零句和流水句的特点:
1.零句
(1)陶陶说,我呀,成天琢磨安全通道,消防梯,已经神经了。[2]129
(2)沪生原来呢,还算正派,现在也学坏了。[2]272
2.流水句
此刻,阿宝于琴间流连徘徊,钢琴自由摆放,罗列散漫,形成各种行走路线,跻身于此,打开任何一块琴盖,内里简单而复杂,眼下的键盘,一丝不动,周围听不到一个音阶,有时,键盘上有几根头发,一屑碎纸,半枝断头铅笔,琴盖内散发出陌生气味,阿宝难以亲近,感觉到痛,怅然闭阖。[2]168
汉语中大多数零句是名词性词语(短语)和动词性词语(短语)。[16]比如说,没有谓语的主语也可成句,如例1(1)句中“我呀”仅是一个名词短语表示的主语。沈家煊进一步提出,“零句”不止于此,其多样性超出了语法学家的想象。如例1(2)中的“原来”不能和印欧语中的副词完全画等号,它也是“广义的话题”[4]36。
吕叔湘说:“汉语口语里特多流水句,一个小句接着一个小句,很多地方可断可连。”[19]7《繁》中存在很多如例2中一逗到底的流水句。大量的流水句对整体的句子分布有何影响?丰富的零句又对小句分布有何影响?笔者用计量的方法一探究竟。(2)《繁》中标点简单,逗号使用居多,其他小说中会存在其他情况,如分号等。为保持统一,本文根据《标点符号用法》(GB/T 15834—2011)所列出的标准,对句子和小句进行划分。判断句子的标准包括句号、问号、叹号,判断小句的点号为句号、问号、叹号、逗号、分号、冒号。此外,破折号、括号和省略号需要分情况考虑。就破折号而言,当其标示内容包含完整的主谓结构时,可以作为小句的界限;当括号中的内容、省略号前后的内容是小句和整句时,可以作为判断小句或句子的标准。
就小句长的分布情况而言,如下页图1所示,《繁》的小句长集中分布在2—4(词)之间,而其他小说的小句长大多处在[4,6]区间。另外,《繁》的小句长比例从4开始急剧下降,6以上的小句所占比重非常小。其平均小句长为3.60,和其他10部小说相比是最低的。沈家煊随机抽取《繁》的小句,发现平均每句5字,超过10字的句子极少。[4]笔者也用该单位进行了计算,发现《繁》的平均小句长为5.16字,从数据统计的角度证实了沈家煊的有关说法。
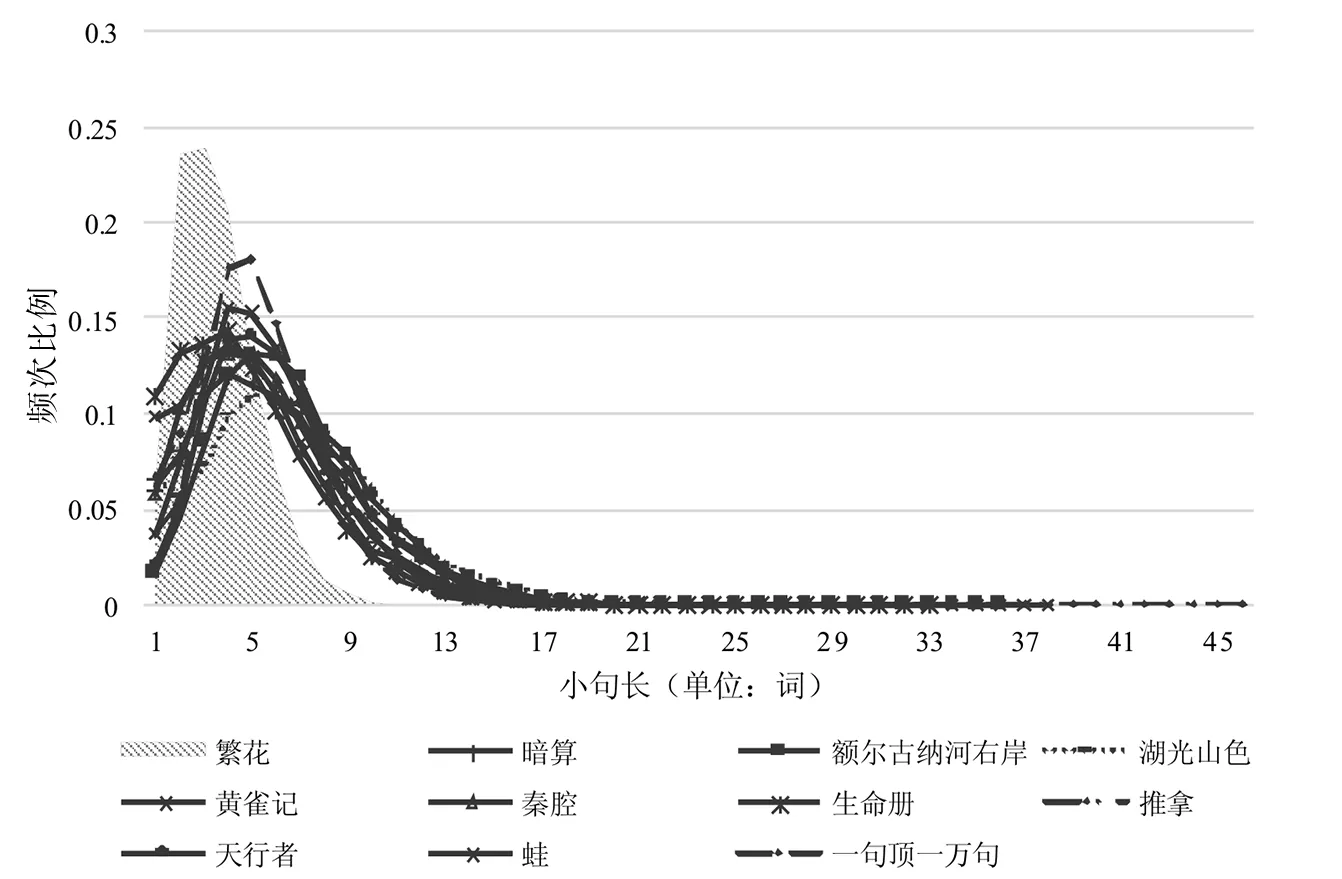
图1 所有小说的小句长分布曲线
如图2的句长分布曲线显示,就整体趋势来说,《繁》似乎与其他小说并无明显不同。具体来看,其短句长(如长度为2、3的句子)比例较低,而长句长比例较高。其平均句长达到了4.43个小句,是所有小说中的最大值,表明就平均值而言,句子中包含的小句数量最多,反映了整句中包含很多“可断可连”的小句,这恰好呼应了上文中大量的流水句现象。金宇澄曾提出,抱着向传统靠近一点的想法,从“很低的位置”出发,完成了《繁》。[2]从这个角度看,金宇澄或多或少实现了自己的承诺,运用了“密排文字”的形式讲述故事。从另一角度看,小说若以口语对话为主要特征,则会呈现零句、流水句多的特征,这也反映了和其他小说相比,《繁》的口语特征很明显。
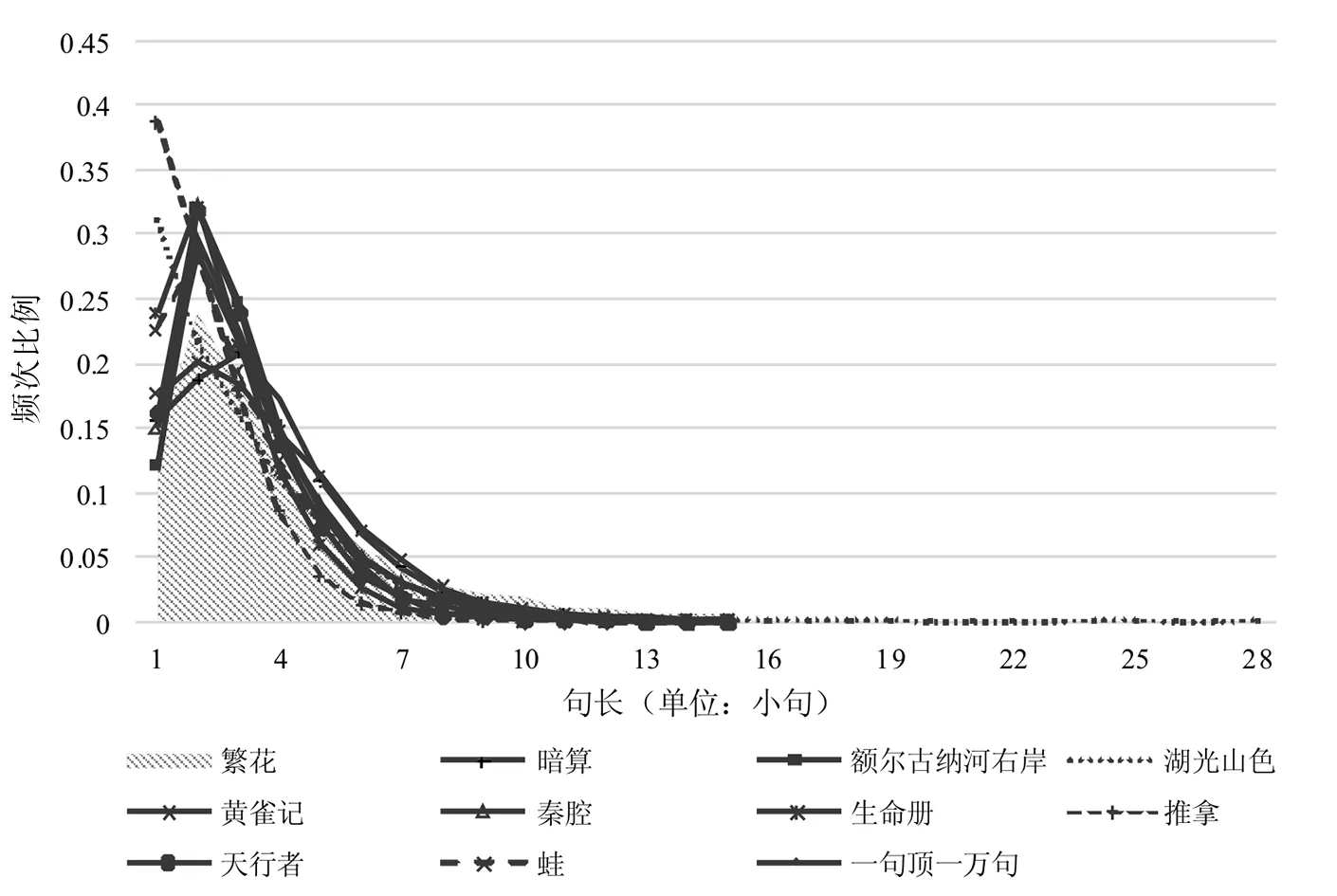
图2 所有小说的句长分布曲线
从20世纪上半叶开始,就有统计学家对语言的句长分布进行了研究[20],之后有研究认为句长分布符合一定规律[21],其分布类型或可用来区分不同作者的作品。本研究将从概率分布或普遍性的角度进一步讨论这些小说的小句长和句长分布。
学者们使用了不同的概率分布模型拟合句长分布。[21-22]其中,Pande和Dhami[22]采用了扩正负二项式(Extended Positive Negative Binominal)和超帕斯卡(Hyperpascal)模型。结合前人研究和本文的语料,本文采用扩正负二项式分布模型拟合相关数据。
结果显示,11部小说的句长拟合效果都很好(C<0.02,R2>0.9)(3)C和R2是判定模型拟合效果的两个标准。C为差异系数,C< 0.02, 结果为好;C< 0.01,结果为非常好。R2为拟合的决定系数,R2>0.8,结果为可接受;R2>0.9,结果为非常好。见:刘海涛.计量语言学导论[M].北京:商务印书馆,2017。,表明所选小说的句长分布都遵循一定规律,均具有相似的分布趋势,即较短的句子占较大的比重,当句长增大时,数量也随之降低,较长的句子所占比重很小。这说明虽然是不同作家的小说,但句长分布均具有人类语言的普遍特征。
在这种相同变化趋势的基础上,不同小说的分布特征可能存在差异。Pande和Dhami[22]指出,扩正负二项式模型的参数和指标可以用来比较不同作者的作品。该模型包含三个参数k、p和α,而《繁》的参数k值和p值是所有小说中的最小值。同样,本文亦使用该分布拟合小句长的分布,效果也都很好(C< 0.02,R2> 0.9),反映了和句长分布类似的情况,即不同小说的小句长分布也存在一定规律,具有普遍特征。此外,《繁》的k值较大(处于第二位),p值最大。
为了进一步验证模型是否能够区分《繁》和其他小说,本研究沿用Pande和Dhami的方法,加入了模型的其他特征指标(均来源于Altmann-Fitter软件拟合结果(4)http:∥www.ram-verlag.eu/wp-content/uploads/2013/10/Fitter-User-Guide.pdf (2014-11-29),分类前对所有指标都进行了标准化处理。),采用层级聚类方法(5)该方法的原理是根据文本向量之间的欧式距离,逐次合并相近的对象,继而再组成更大的簇,直到形成一个簇为止。最终通过树状图来展示结果,可以清晰地显示对象的分类结果。对文本进行分类。聚类分析显示,在以小句长模型的指标为文本向量的结果中,11部小说分成两类,其中《繁》和《黄雀记》《一句顶一万句》聚成一大类,在这一类别下,《繁》自成一类,其他2部小说为一类,而其他8部小说为另一大类,说明就小句长的参数分布而言,《繁》展现了与大部分小说不同的特点。此外,以句长模型的参数和指标为变量的聚类分析结果显示,所有小说分成两类,其他10部小说为同一类,而《繁》则为单独的一类,说明《繁》的句长分布比小句长分布更具独特性,与其他小说皆不同。两个聚类分析结果均有效,数学模型分类的共性相关系数小句长为0.76,句长为0.84。(6)该系数为验证聚类分析结果的效度,数值越接近1,说明效果越好。通过小句长和句长分布的参数比较,本文从数学模型的角度再次印证了《繁》的独特性,同时也说明不同文学作品的句长分布参数也是描述作者风格的一个重要参数,值得进一步研究。
四 整齐并置的短句
《繁》中大多是字数不多的短句并置,大致等长,节奏感很强,这些可断可连的零句构成了流水句。那么这些大量的零句和流水句之间的关系是否有特别之处?事实上,大多数人类语言中,句子和小句的关系均遵循某种规律(门策拉-阿尔特曼定律Menzerath-Altmann law),即:一种语言结构越长,则构成它的部分越短。[15]门策拉-阿尔特曼定律由门策拉提出,阿尔特曼进一步完善,其通用形式为:
y=axbe-cx(b<0)
(1)
该公式中,y为平均成分长度,x为结构长度。大多数情况下,一般简写为:
y=axb(b<0)
(2)
这一定律已被验证存在于不同语言结构单位之间,表2显示了符合该定律的结构单位和成分。[15]55以第一行为例,句子为结构,小句为成分,小句长度为因变量。因此,句子和小句的结构成分关系可以表达为:句子越长,小句的平均长度越短。
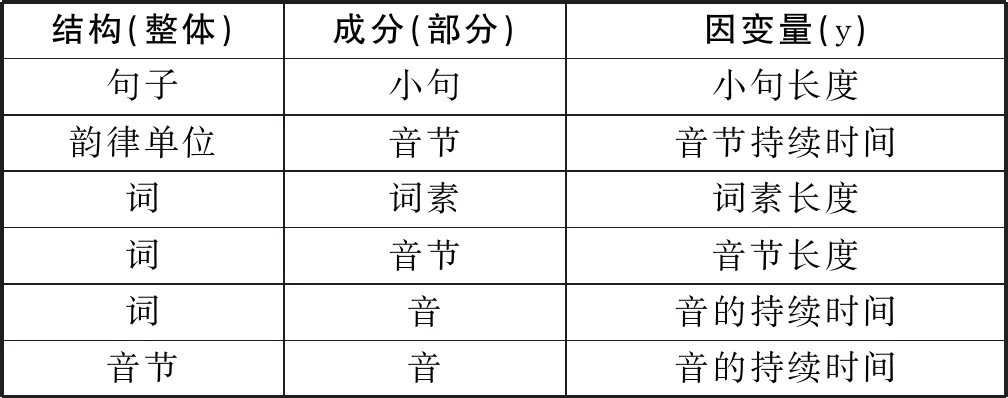
表2 符合门策拉-阿尔特曼定律的语言单位
本文拟采用门策拉-阿尔特曼定律对句子-小句和小句-词两个层面进行分析。在句子层面,句子和小句的结构成分关系可以表达为:句子越长,小句的平均长度越短。将该定律应用在本文的语境中,若《繁》的句子越长,则构成句子的小句应当越短。但这似乎和上文所陈述的特征有所相悖。如果用这种定律关系来比较《繁》和其他小说,会有什么发现?用更具普遍意义的语言定律去研究这种关系,或可从实证研究的角度阐释其独具一格的句式结构特点。Hou et al.[23]曾发现在不同语体中,句子和小句的关系不尽相同,因此,本研究亦可以检验Hou et al.结论的正确性。在小句层面,本文拟调查小句和词的结构成分关系。尚无学者对汉语的小句层面进行研究[24-25](7)所注参考文献,前者研究日语的句子、小句和论元层面,后者对捷克语的小句层面进行了考察。,因而本文是该结构层面的初步尝试(8)为了减小异常值对结果的影响,笔者选择了长度为1-15的小句(单位:词)和句子(单位:小句)。长度为1-15的小句和句子占了整体的大部分比重,比例和都达到了98%及以上,基本能代表整体文本的特点。。
(一)句子和小句的层级关系
本研究结果显示,大部分小说的拟合效果并不好(根据前人研究[26],R2值大于0.8,即模型拟合效果为可接受,而8部小说的R2值小于0.8),《繁》的拟合效果也较差(R2=0.370)。当《繁》的句长增长时,小句长并没有随之呈现下降的趋势,而是集中在某个值(3.5)附近。表明不论《繁》的句子有多长,其构成部分都保持相似的长度。
从具体的例子(分词后的句子)来看:
3) 天麻种子的培育。优质天麻为培育优质的天麻种子提供保障,在天麻开花期基质的温度控制在19~20摄氏度,湿度控制在50%,空气相对湿度控制在70%,空气温度控制为20~23摄氏度,通风换气,人为补光。因天麻花自身不能授粉,采用人工异株授粉方法,使天麻花结实,产生前果,授粉完成18~20天,果实成熟,适时采收。通过伴萌发菌种植。如暂时不种植,可保存在4摄氏度的冰箱中7天左右,保证种籽有足够的萌发率。
(1)沪生 说,等于 跳伞,我 父母 是 空军,这 要 训练。[5]49
(2)蓓蒂 说,马头 想 带 我 去 高郎 桥 去 看 看,马头 住 的 地方,全部 是 工厂,就是 杨树浦 的 茭白 园,昆明 路 附近,经常 唱 “马路 戏”,就是 露天 唱戏,唱 江淮 剧,不 买 票,就 可以 看 了,我 不 懂 啥 是 江淮 剧,想 去 看,结果 让 淑婉 姐姐 骂 了 一 顿,马头 一 声 不 响。[5]69
第一句句长是4个小句,平均小句长是(2+2+4+3)/4=2.75,第二句句长是15个小句,平均小句长是(2+10+4+3+5+3+4+3+3+3+4+7+3+8+5)/15=4.47。可以发现,句长为4的平均小句长比句长为15的值反而要小。随着句子的增长,其构成成分——小句的长度并没有随之降低。
这个结论与Hou et al.[23]的研究结论基本保持一致:汉语新闻中定律拟合效果较好,但在口语和小说中,定律的拟合效果较差。他们认为,这可能和小说和口语中大量的流水句现象有关。笔者认为这也可能和测量的单位有关,这对文体学研究有一定的借鉴和思考意义。大多数小说中口语化的表达较多,因此有很多流水句。流水句中包含了很多意义完整、独立且“并置”的零句。[18, 27]零句不包括完整的主谓组合,但它们也表达了一个完整的句子意义。正是汉语中零句的多样性和并置性造成了结构与成分关系的不稳定性,导致了整体较差的拟合效果。可以发现,赵元任的零句理论立足于汉语本身,能够解释汉语句式结构的特征,从而揭示汉语的本质特点。综合这一小节的数据和Hou et al.[23]的结论,可以得出,语体和文体的差异对汉语句式特点有一定影响,这对进一步研究汉语的句式特征有一定的启示意义。由于拟合效果差异过大,这里不再比较《繁》和其他小说的参数值异同。
(二)小句和词的层级关系
小句和词的层级关系结果显示,小句越长,词的平均长度有下降的趋势。接近一半的小说的拟合效果都为可接受(5部小说的R2值大于0.8),表明在5部小说中,小句层面的结构成分关系符合幂律分布。同时也可以发现,小句层面的定律拟合结果都优于句子层面的拟合结果。
大多数学者认为定律的参数值异同可能和不同语言层级相关,也有研究发现,不同语体的参数值存在差异。[28]接近一半的小说拟合效果较好,因此可以进一步观察模型的参数值。《繁》的a值最大,b值最小,和其他小说有所不同。说明从数学公式的描述来看,其小句和词的结构成分关系亦是独具一格。(9)由于定律并不包含其他特征指标,因此这里仅对两个参数的差异进行简单比较,其统计学意义需要未来进一步调查。可以发现,从相邻层级单位之间关系的角度出发,对当代小说进行语言定律的描述,用数学模型概括总结客观规律,有利于了解文学作品的特殊性和普遍性,以及汉语的句式特点,从而促进文体对比研究的科学化。
五 韵致序列特征
沈家煊指出,《繁》韵致调性强,有长短句的配合,效果才明显,如“口里一面讲,身体一面靠紧,滚烫。”[2]59“滚烫”这由一词构成的小句,紧跟在前面较长的小句之后,读起来有朗朗上口的感觉。
Köhler提出,动链可以分为长度动链、频次动链、多义度动链等类型。本文主要研究句法结构的长度序列特征,因此采用长度动链指标,其定义为:一系列持续保持相等或者增长趋势的长度值(如词素长度、词长或句法结构长度)。[29]90以《繁》中的某个流水句为例(分词后的句子):
徐总 说,我 喜欢 小 地方,北方 做官,包括 大 老板,喜欢 大 办公室,旁边 往往 摆 一 张 床,甚至 双人床,摆 一 对 绣花 枕头,甚至 密码 锁 的 套房,里面 有 私人 卫生。[5]290
以词为单位的小句长序列为:2423362554
根据动链的定义,该句话的小句长动链为:
(2-4)(2-3-3-6)(2-5-5)(4)
从这个例子可以看出,动链对文本的区分方式较为明确,并不基于主观臆断,减少了争议性,可以更加客观地反映文本的线性特征。此外,该方式能穷尽文本中的相关数值,描述文本的整体特征。[29]
在此基础上,本文拟从动链方面调查《繁》的小句长排列特征。已有不少研究分析了动链秩-频分布的拟合模型[30-31],其中,齐普夫-曼德布洛特分布模型(Zipf-Mandelbrot,以下简称齐曼模型)可以很好地拟合动链的分布情况,并且从某种程度上来说,模型的参数可以用来比较不同语体[30, 33],因此接下来本文尝试用该模型拟合动链的秩-频分布并比较参数。
按照动链的划分方法,本文对小句长动链的秩-频分布进行统计。由于篇幅有限,我们列出频次排名前十位的小句长动链,如表3所示,其他10部小说的前5个动链多是5、6、7、8,而《繁》不同,前5位分别是3、4、2-4、2-5、2-3。单从分布情况来看,它们的语言序列就有所不同。用概率分布去拟合这些小说的秩-频分布的结果会如何?
所选小说的小句长动链的秩-频分布均符合齐曼模型,虽然C值大于 0.02,但R2值大于0.9,拟合效果尚可接受,表明《繁》的小句长序列遵循参数分布,存在一定规律。其a值最大,b值较小(处于第二位)。
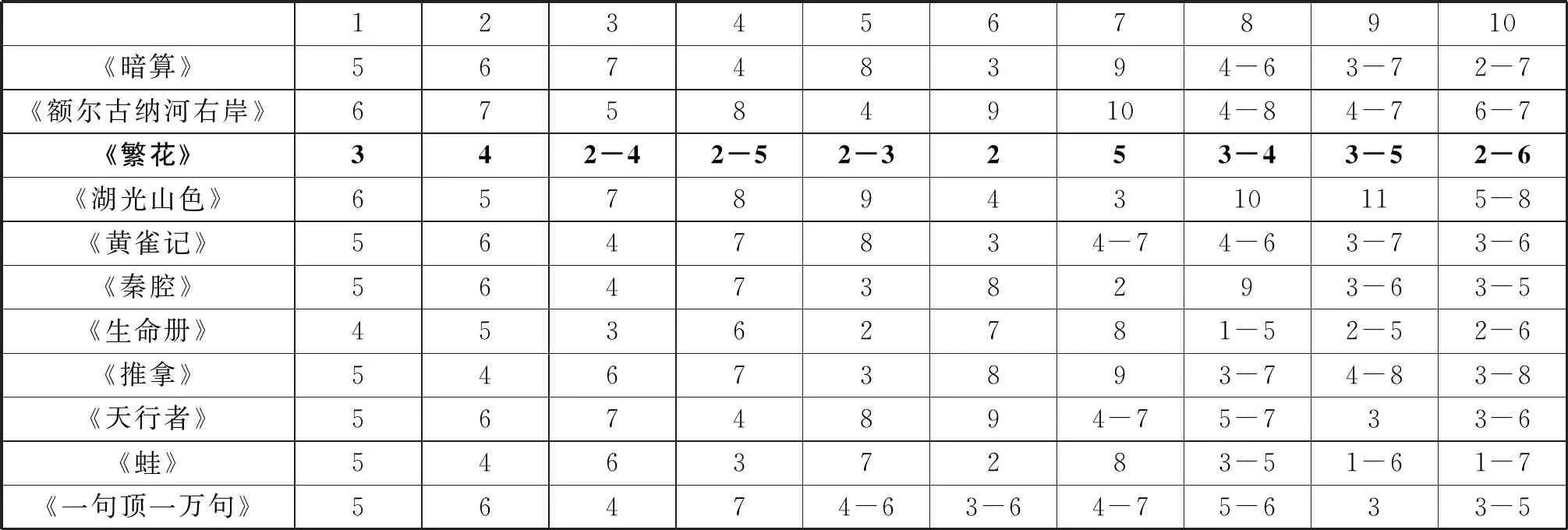
表3 小句长动链的秩-频分布
以句长动链模型的参数和指标为基础的聚类分析显示,包括参数在内一共13个指标,其共性相关系数为0.91,分类效果很好。结果表明,《繁》和其他9部小说被分为一类,《秦腔》单独成一类,说明《秦腔》和包括《繁》在内的10部小说都不同。而在前者的类别下,齐曼模型将《繁》和9部小说区分开来,说明从某种程度来说,《繁》的句长动链分布和大部分小说都不同。
众所周知,文体研究较少关注语段特征(语言单位的组合特征)[30],动链则提供了一个新视角,利用客观明确的区分方式描绘了文本的线性组合特征。由此看来,这和“长短句配合”的韵致一说有异曲同工之妙,同样都用小句长度为基准,描绘了文本线性特征。不同的是,动链采用了数学统计方法来测量韵致特征,将主观感受具象化,相关数据结果从某种程度上印证了:《繁》的韵致调性强,与当代小说有所不同。这也体现了金宇澄所说的:“当代书面语的波长,缺少‘调性’,如到传统里寻找力量,瞬息间,就有‘闪耀的韵致’。”[2]443如果不同风格的小说可以用参数值来衡量和比较,将其扩展到其他文体的比较研究是一个值得努力的方向。
六 结语
华语文学传媒大奖年度小说家颁奖词如此评价《繁》:“他的写作,有着话本式的传统面影,骨子里亦贯通、流淌着先锋文学的精神血脉。他将传统资源、方言叙事、现代精神汇聚为一炉,为小说如何讲述中国生活创造了新的典范。”[4]103。本研究运用计量的方法,发现《繁》与其他小说一样,在句法结构及语言序列特征方面均遵循人类语言的相关定律,同时也具有与其他小说所不同的特征,其独特的句式结构在当代小说中脱颖而出。在大多数现代小说都受到翻译腔影响的背景下,《繁》采取了独具匠心的语言表达,其“盛开的闪耀韵致”让人感到耳目一新,不禁回首拾掇传统“汉语腔”的神髓。
现代文体研究离不开现代研究方法[34],通过科学统计方法对文本特征进行测量,不仅可以为以直觉为基础的相关研究提供客观的验证,同时也反映了科学统计方法在研究不同作家风格中的重要作用。对不同小说的句式特点采用数学模型方法进行考察亦是一种新的尝试,为作家风格研究提供了一种新的路向。
