融合主题模型的在线可比度计算研究
2019-09-10赵永标张其林谷琼
赵永标 张其林 谷琼



摘 要:在线挖掘可比语料是构建大规模可比语料库的可行途径之一,在线可比度计算是语料挖掘过程中的关键环节。本文提出一种融合词汇重合度和主题模型的在线可比度计算方式,主题模型选择能够进行在线学习的Online LDA,利用词对齐工具GIZA++进行主题映射,融合方式为加权求和。在下载的中英新闻语料上的测试结果表明,两种计算方式融合后的准确性比两种都要高。
关键词:可比语料库;可比度;主题模型;主题映射
中图分类号:TP391.1 文献标识码:A 文章编号:2096-4706(2019)14-0001-04
Online Comparability Measurement Integrating Topic Model
ZHAO Yongbiao,ZHANG Qilin,GU Qiong
(Computer School of Hubei University of Arts and Science,Xiangyang 441053,China)
Abstract:Online mining bilingual comparable text pairs is among practical approaches for building large scale comparable corpora,Online comparability calculation is a key part of the mining process. We propose an online comparability measurement integrating the online comparability measurements based on word overlap and topic model. For topic model,we choose Online LDA which can be trained online. For topic mapping,we use the word aligning package GIZA++. For integration,we adopt the weighted summation. The test results based on downloaded Chinese-English news collection shows that the accuracy of the combination of the two measurements is better than either of them.
Keywords:comparable corpora;comparability;topic model;topic mapping
0 引 言
可比语料库是双语语料库的一种,在机器翻译、跨语言信息检索、双语词典编撰等领域有着广泛的应用。如何构建高质量、大规模的可比语料库一直是研究的热点问题。Web拥有海量的文本信息,而且在持续更新。从Web挖掘可比语料是目前构建可比语料库的重要途径。文献[1]从新闻网站下载不同语言的新闻文本,进而生成可比语料;文獻[2]从维基百科抽取可比语料;文献[3]尝试从社交网站Twitter中挖掘可比语料。这些文献构建可比语料库时将所需语料全部下载完成后,离线进行语料对齐,得到可比语料。这种构建方式难以构建大规模的语料库。解决这个问题的有效途径就是在线持续挖掘可比语料,语料下载与语料对齐同时进行。
构建可比语料库非常关键的问题就是在语料对齐阶段如何衡量两种语言文本之间的相似性(即可比度)。常用的方法有:(1)基于跨语言信息检索,即从源语言文档抽取关键词,翻译为目标语言,然后在目标语言文档中进行检索,根据检索的结果确定源语言文档与目标语言文档之间的相似性;(2)基于词汇重合度,即把文档当作词袋,将源语言文档词汇在目标语言文档中能找到对应翻译的比例,视为源语言文档与目标语言文档之间的相似性。
以LDA为典型代表的主题模型能够发现文档的隐含主题,对文本进行语义挖掘。不少研究者将主题模型应用于可比度的计算,取得了不错的效果。
文献[4]先利用源语言文档集训练得到源语言主题模型,然后通过翻译引擎将模型翻译为目标语言主题模型,将源语言文档和目标语言文档分别输入这两个模型中得到两篇文档的文档主题分布,通过计算这两个分布的余弦相似度来判断对应文档的相似性。文献[5]引入Bi-LDA,利用主题相同的可比语料进行训练,从而建立主题模型,然后通过KL散度、余弦相似度和条件概率相似度来计算待匹配文档的主题相似性。文献[6]利用主题相同的阿拉伯语和英语新闻语料分别训练两个LDA,通过主题映射,建立两个LDA主题集之间的关系,在此基础上抽取主题相关的特征,同时配合语义特征(标题、关键词、首句及次句相似度)训练SVM分类器判断待匹配新闻文档是否主题相关。
如前所述,在线挖掘可比语料是构建大规模语料库的有效途径。对于语料类型,从更新的速度,以及获取的难易程度来看,新闻是最适合的。同样,在线可比度计算也是关键步骤。本文针对中英新闻,借鉴文献[6]中主题映射的思想,将主题模型应用于在线可比度计算,提出融合主题模型的在线可比度计算方法,该方法由基本的计算方式和基于主题模型的计算方式两种方法融合而成。在线可比度计算方式需要满足计算速度快、所需资源少的要求,前面提到的基于跨语言信息检索和基于词汇重合度的可比度计算方式均满足该要求。从计算复杂性的角度来说,本文选择后者作为基本计算方式。对于基于主题模型的在线可比度计算方式,鉴于传统的基于吉布斯抽样算法的LDA训练速度慢的特性,本文选择速度更快的基于变分推断的Online LDA。Online LDA采用增量学习的方式,不仅学习速度快,而且当模型运行一段时间后需要补充新的训练材料时,能够仅针对补充材料进行训练,而不是全部重新训练,特别适合在线应用。融合方式采取按比例相加的方式,具体比例通过实验选取。
1 融合主题模型的在线可比度计算方法
融合主题模型的在线可比度计算过程主要分为两个阶段:(1)准备阶段;(2)在线可比度计算及融合阶段。这两个阶段又分为若干个步骤,其中Online LDA的训练、主题映射表的生成以及可比度的融合是关键步骤。融合主题模型的在线可比度计算过程如图1所示。
1.1 Online LDA训练及主题映射表的生成
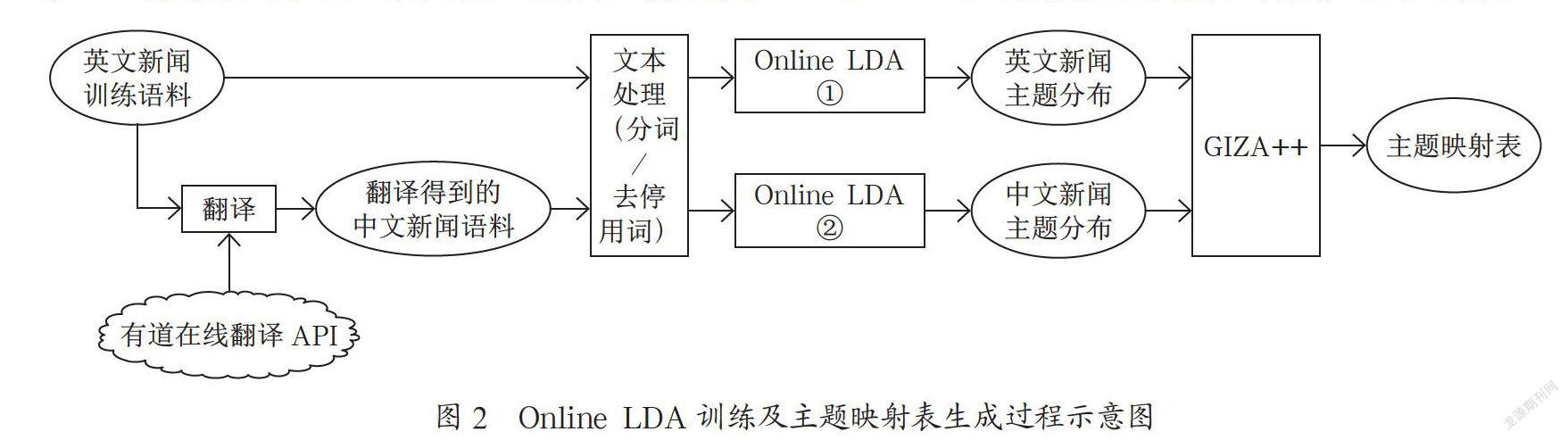
根据文献[6],能够进行主题映射的前提条件是训练用的双语语料必须是平行语料或者篇章对齐的具有相同话题的语料。这样的语料一般难以获得。本文尝试借助在线翻译引擎构造“近似”平行语料。构造方式有两种,即将英文新闻翻译为中文,或者将中文翻译为英文。经过分析,本文选择将英文新闻翻译为中文,因为所获取的英文语料主要来自国家权威媒体《环球时报(英文版)》,行文简洁,语法规范,有利于翻译引擎进行翻译。本文选择“有道在线翻译”作为翻译引擎。Online LDA训练及主题映射表生成过程如图2所示。
Online LDA通过在小批量数据上迭代采樣实现在线变分推断,即无须一次性提供全部训练集,可以分批渐进训练,适合在线学习和大数据集应用场景。其变分推断算法如下:
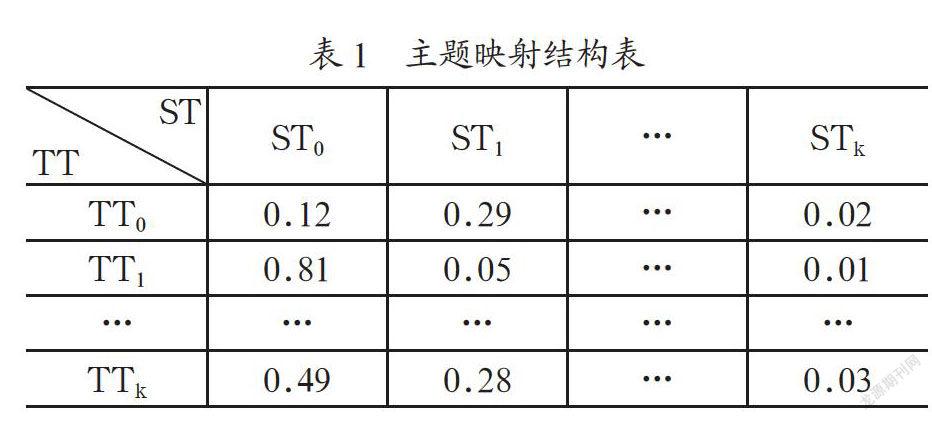
本文采用两个独立的Online LDA,分别针对近似平行语料库中的英文新闻语料和翻译得到的中文新闻语料进行训练。训练结束后,参考文献[6]中的方法,用词对齐软件GIZA++进行主题映射。该方法的基本思想是如果训练语料主题相同,LDA训练结束后可以确定各个文档的主题分布,如果把主题看作词,则可以认为训练语料是以主题为词的平行语料,通过GIZA++就可以得到主题之间的翻译关系,即主题之间的映射表,其结构如表1所示。
1.2 在线可比度计算及融合
1.2.1 候选新闻对的生成和常规文本处理
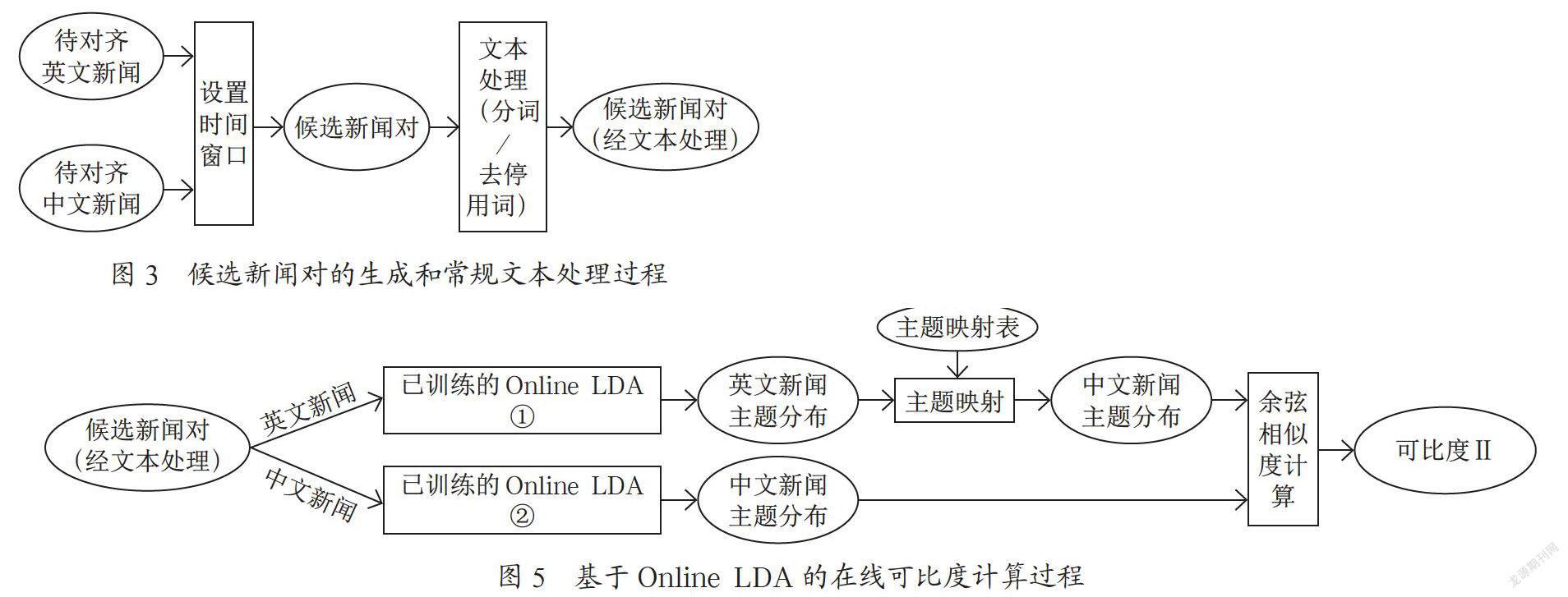
新闻具有很强的时效性,不同语言关于同一事件的报道一般会集中在一个时间段内,这就意味着可以把可比新闻对的搜索限定在有限的时间范围内,这样可以大大缩小候选新闻对的规模,更重要的是有利于在线构建可比新闻语料,即待一定时间范围(即时间窗口)内的语料下载完毕后即可开始文本处理、可比度计算和对齐工作。候选新闻对的生成和常规文本处理的过程如图3所示。
1.2.2 基于词汇重合度的在线可比度计算
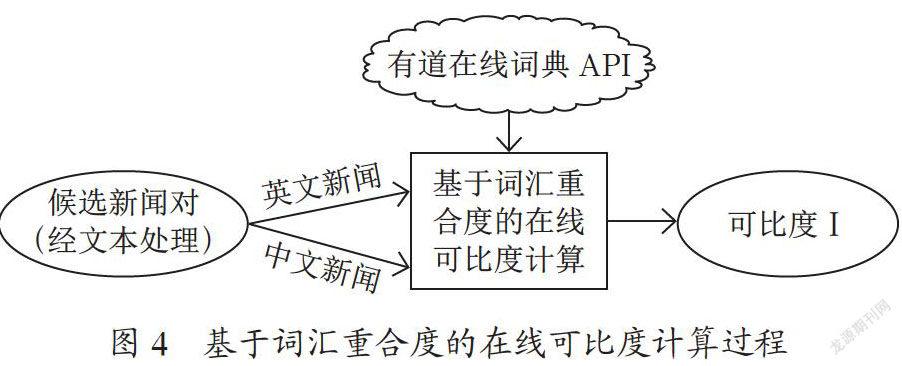
基于词汇重合度的在线可比度计算过程如图4所示。
计算过程需要双语词典的支持。相比本地词典,在线词典具有规模大、更新及时的特点。本文选择有道在线词典,根据文献[2]和文献[3],得出基于词汇重合度的可比度计算公式如下:
1.2.3 基于Online LDA的在线可比度计算
基于Online LDA的在线可比度计算过程如图5所示。
将候选新闻对中的英文新闻和中文新闻分别送入准备阶段已训练好的两个Online LDA中,推断得出各自的主题分布,然后利用主题映射表将英文新闻主题分布映射为中文新闻主题分布,然后求两个中文主题分布的余弦相似度,得到候选新闻度的相似度,即可比度。
1.2.4 两种在线可比度的融合
将两种在线可比度进行融合得到最终的在线可比度。可比度的融合采取赋权相加的方式。各自的权值通过试验选取。
2 实验设置
2.1 数据集
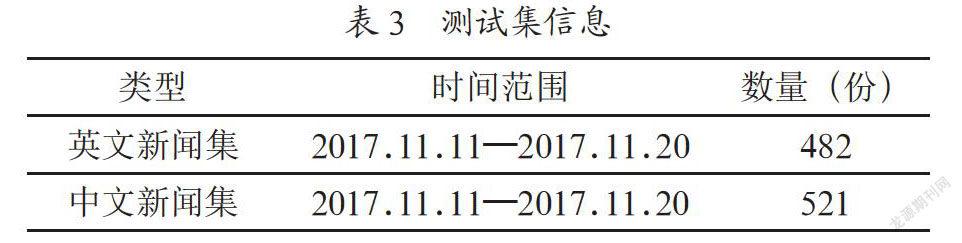
本文所使用的数据集采用爬虫下载,其中英文新闻来自《环球时报(英文版)》,中文新闻来自凤凰网,数据集分为训练集和测试集,具体信息如表2和表3所示。
对新闻的文本处理包括分词和去停用词。对于中文新闻和英文新闻分别采用中科院分词软件NLPIR和斯坦福大学的自然语言处理工具包CoreNLP进行分词,然后去停用词。
2.2 参数设置
在Online LDA训练阶段,需要设置的主要参数有主题个数K,小批量样本数量S,辅助参数κ、τ0的选取。S、κ、τ0选取Python机器学习包sklearn中给定的默认值,分别为128、0.7和10。参考文献[6]并经过测试可知,主题个数K=40比较合适。
在候选文本对生成阶段,需要设置的参数是时间窗口K,参考文献[7]将其设置为1,即对于源语言新闻文本,将前一天,同一天及后一天的目标语言新闻文本作为候选的可比新闻。
2.3 实验结果及分析
Python机器学习包sklearn实现了Online LDA的学习算法,但必须一次性提供所有训练文本,不能实现真正意义上的在线学习,另外也不能在已训练的模型上追加训练样本进行补充训练。
本文采用文献[8]所提供的程序,该程序能够从维基百科上下载页面文本,边下载边训练,也能够中止训练,保存训练模型,再重启继续训练,实现真正意义上的在线学习。将该程序中维基页面文本换成新闻训练集就能实现本文需要的在线训练。训练完成后,使用GIZA++得到主题映射表。
在测试集上,分别用基于词汇重合度的在线可比度计算方式和基于Online LDA的在线可比度计算方式计算可比度。对于测试集中每篇英文新闻,选取可比度最高的中文新闻组成可比新闻对,然后随机抽取200对进行人工判断,判断其是否主题相同或者相关,以估算两种在线可比度计算方式的准确性,结果如表4所示。
从表4可以看出,基于词汇重合度计算方式的准确度要高于基于Online LDA的计算方式,相比文献[6]的结果,高出的幅度要大一些,这可能与Online LDA训练集规模不够有关。
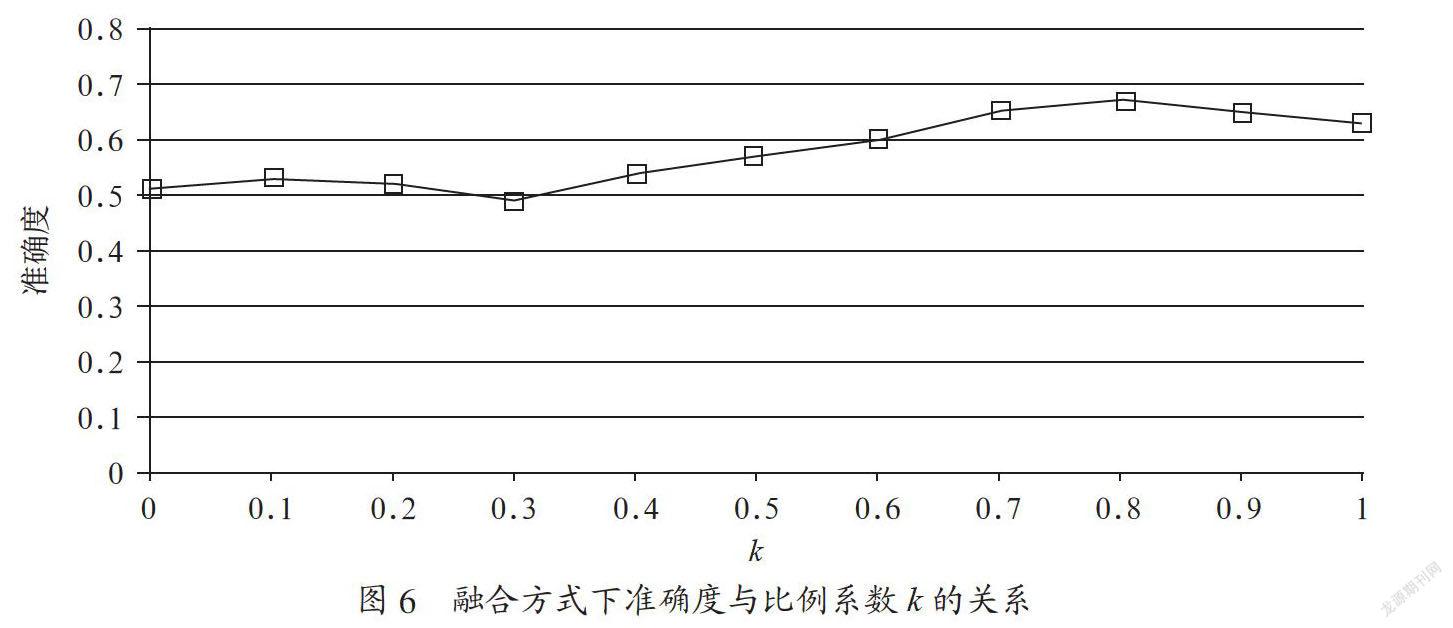
将两种计算方式按比例进行融合:comparabilitytotal=k×comparabilityoverlap+(1-k)×comparabilityonlineLDA
从图6可以看出,当k=0.8时,融合方式的准确度最高,为0.67,比基于词汇重合度计算方式的准确性高约6.3%。这表明融合两种计算方式有利于提高可比度计算的准确性。
3 结 论
在线挖掘可比语料是构建大规模可比语料库的可行方式之一。在线可比度计算是在线挖掘过程中十分关键的一环。在在线词典API的支持下,基于词汇重合度的在线可比度计算方式是常用的计算方法。鉴于主题模型在文本语义挖掘方面具有独特优势,本文在前人工作的基础上以新闻语料为对象,利用主题映射将Online LDA引入在线可比度计算,提出了融合主题模型的在线可比度计算方式,实验结果表明该方式的性能比单一方式有一定程度的提高。本研究还有需要完善的地方,例如,测试在更大规模的训练集下,基于Online LDA的在线可比度计算方式的性能是否会得到提升;当系统运行一段时间后,如何判定Online LDA需要补充数据进行训练。
参考文献:
[1] Talvensaari T,Laurikkala J,Järvelin K,et al. Creating and exploiting a comparable corpus in cross-language information retrieval [J].ACM Transactions on Information Systems,2007,25(1):4.
[2] Saad M,Langlois D,Smaïli K. Extracting Comparable Articles from Wikipedia and Measuring their Comparabilities [J].Procedia-Social and Behavioral Sciences,2013(95):40-47.
[3] Malek H,Maroua T,Chiraz L. Building comparable corpora from social networks [C].Workshop on Building & Using Comparable Corpora. International Conference on Language Resources and Evaluation,2014.
[4] Preiss J. Identifying Comparable Corpora Using LDA [C].Conference of the North American Chapter of the Association for Computational Linguistics:Human Language Technologies. Association for Computational Linguistics,2012.
[5] Zhu Z,Li M,Chen L,et al. Building Comparable Corpora Based on Bilingual LDA Model [C].Meeting of the Association for Computational Linguistics,2013.
[6] Firas Sabbah,Ahmet Aker. Creating Comparable Corpora through Topic Mappings [C]//Workshop on Building & Using Comparable Corpora. International Conference on Language Resources and Evaluation,2018.
[7] 房璐.英漢可比较语料库的构建与应用研究 [D].苏州:苏州大学,2011.
[8] Hoffman M D,Blei D M,Bach F R. Online Learning for Latent Dirichlet Allocation [C]//Advances in Neural Information Processing Systems 23:24th Annual Conference on Neural Information Processing Systems 2010. Proceedings of a meeting held 6-9 December 2010,Vancouver,British Columbia,Canada. Curran Associates Inc,2010.
作者简介:赵永标(1980-),男,汉族,湖北洪湖人,讲师,硕士,研究方向:自然语言处理方面的教学与研究。
