基于水沙组合分类的黄河中下游水沙变化特点研究
2019-07-24蔡蓉蓉张红武卜海磊
蔡蓉蓉,张红武,卜海磊,张 宇
(1. 清华大学水沙科学与水利水电工程国家重点实验室,北京 100084;2. 郑州清大水利工程技术咨询有限公司,河南郑州 450003)
1 研究背景
黄河流域的径流主要来自内蒙古自治区托克托县河口镇以上,泥沙主要来源于河口镇以下至陕西潼关之间,水沙异源[1],且黄河历来“水少沙多,水沙关系不协调”,加上下游洪灾频发[2-3],下游河段淤积严重,成为举世闻名的“地上悬河”。1960 年代以来,黄河下游洪水漫滩机遇减少,泥沙主要淤积在主槽及嫩滩,形成“二级悬河”[4]。下游水沙条件大为改变后,一些河段“二级悬河”发展迅速[5],“二级悬河”形势依然严峻[6],河道治理仍面临挑战。河床的冲淤变形与水沙组合(径流量与输沙量组合)类型密切相关,研究黄河的水沙组合类型有助于深入了解黄河水沙特点、进一步揭示河床冲淤变形规律,对判断未来的水沙情势及制定黄河未来治理方略大有裨益。
黄河水沙变化研究,一直是制定黄河治理开发方案的基础和难点,也是技术界关注与争论的焦点,尤其自1980 年代以来,有关部门先后围绕该问题开展相关项目的科学研究,取得了一系列成果[7]。特别地,有学者利用经验或理论方法,利用实测水沙资料对黄河的水沙关系展开了有关研究。尹学良认为大水期黄河河槽发生冲刷、小水期发生淤积,提出山东段黄河河槽的冲淤分界流量在1800 m3/s左右[8]。邰淑彩借鉴并改进了刘善均研究水文站典型水沙年的方法,与刘善均[9]认为河流的水量和沙量一般呈正相关关系不同,邰淑彩[10]认为黄河的水量和沙量可呈现出非正相关关系,她仍将水(沙)丰隶属度及其均值作为分类依据,利用阈值β(水沙大年下限)、a(水沙中年界限)、α(水沙小年上限),对渭河华县站的水文泥沙年资料进行分类并选取了包括小水大沙年在内的典型水沙年。目前,黄河水沙情势已发生改变[7],沙量锐减。实测资料表明,黄河中游潼关站年输沙量已由年均16亿t(1919—1959年)锐减至不足3亿t(2000—2018年)。信忠保等学者[11]认为退耕还林还草工程使植被恢复可能是导致相应区域产沙量显著下降的重要原因。马丽梅、赵跃中、蒋观滔等学者[12-14]的研究也给出了类似结论,都表明植被覆盖面积不断恢复是黄河沙量锐减的重要原因。由于黄河问题的复杂性与研究的重要性,“十三五”期间,国家重点研发计划首批设立“黄河流域水沙变化机理与趋势预测”项目(2016YFC0402400),对黄河水沙关系及水沙变化机理继续展开深入研究。
近年来,以人工神经网络为代表的机器学习方法在水科学研究中得到了广泛应用[15],有学者已将神经网络技术应用于降雨、径流预报及模拟等研究中[16],这为研究黄河水沙关系提供了新的方法。自组织映射(Self-Organizing Map,SOM)模型作为一种典型的神经网络模型,具有聚类、模式识别等众多功能,如伊璇等[17]利用该模型进行了滇池流域的分类和无资料区的径流模拟。鉴于黄河中游潼关站来沙量基本能反映黄土高原的侵蚀量及产沙强度[18],同时考虑到由于黄河支流伊洛、沁河的汇入及三门峡水库与小浪底水库的拦截作用,潼关站与花园口站相比,年径流量一般偏小,年输沙量一般偏大,可以说潼关站水沙条件更为不利。本文选取潼关站为代表站,利用该站的实测水沙资料,基于自组织映射-K均值聚类耦合方法(以下简称SOM-K法),对该站的水沙组合进行分类,揭示出不同阶段各水沙组合类型的变化规律,为深入了解黄河中下游潼关以下河段水沙变化特点提供参考。
2 研究方法
2.1 SOM模型Kohonen参考人脑神经元的特性,于1982年提出SOM模型[19]。SOM是一种无监督学习模型,可将复杂的高维输入数据通过非线性映射反映到低维(一般是二维)网格,并保留数据的拓扑关系,从而对输入数据进行有效聚类[19]。SOM 模型由输入层和可代表网格拓扑结构的输出层组成,输入(出)层由存放输入(出)向量的神经元组成,通常情况下,输出神经元以二维网格的形式排列,每一个输入神经元与每一个输出神经元间通过权值向量连接(图1)[20]。
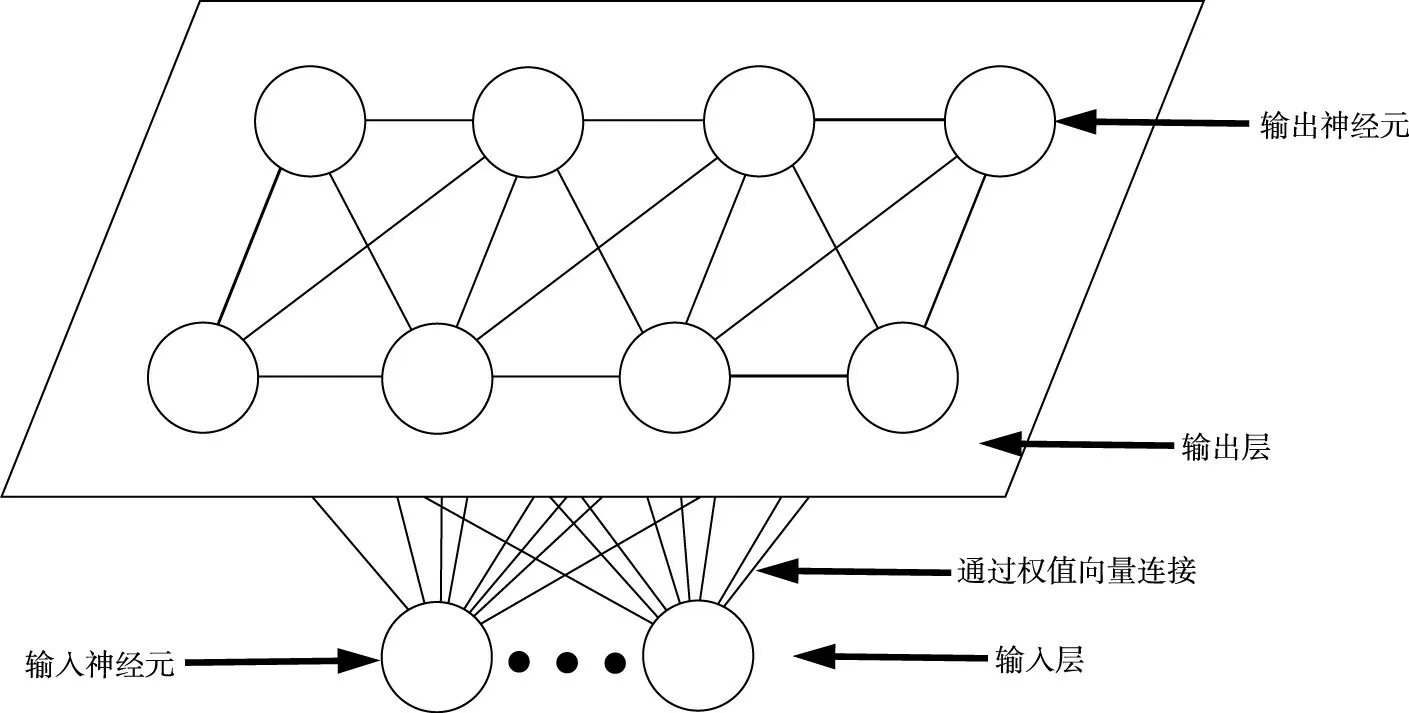
图1 SOM模型结构
在利用SOM 模型进行聚类分析前,需明确距离度量方法,数据初始化、数据训练所采用的算法类型,确定SOM 模型的网络尺寸、网格及映射类型、邻域类型、训练次数等参数。实践中一般使用欧氏距离作为距离度量方法,采用随机初始化方法(random initialization)进行数据初始化[21]。批量训练(batch training)算法中每次将所有数据向量输入模型,顺序训练(sequential training)算法中每次仅输入一个数据向量[22],前者可节省计算时间,更适用于实际[21]。输出层神经元数量确定方法没有统一的标准:Melssen 等[23]认为,输出层神经元数量应大于所期望聚类组数的2 倍并远小于输入数据的样本数;Lin等[24]认为输出层神经元数量应尽可能大以确保得到最大的分类;Abrahart等[25]及Parasuraman 等[26]采用反复试验(trial and error)的方法选取输出层神经元数量;亦可根据样本数量n采用公式m=5 n 确定输出层神经元数量m[22],并根据输入数据协方差矩阵最大两个特征值的比例确定网格的边长比[27]。为便于可视化,网格类型(grid shape)一般采用六边形(hexagonal),映射类型(map shape)一般定为片状(sheet)[27]。在水资源领域使用SOM 模型时,一般选择高斯(Gaussian)邻域函数[15]。使用顺序训练算法时,为使结果收敛,训练次数应至少是输出层神经元数量的500倍[27]。本文利用mean quantization error(QE)与topographic error(TE)度量SOM模型的聚类效果,QE代表输入向量与获胜神经元的平均距离,TE代表数据中第一获胜神经元与第二获胜神经元不相邻的比例。QE和TE越小,说明SOM模型的运算结果越好,但对于小尺寸网格TE并非决定性因素[28]。
2.2 K均值聚类法K均值聚类法是一种寻找输入数据集中未知子类的无监督学习方法,旨在将输入数据划分到指定数量的类中,使类内差异尽可能小而类间差异尽可能大[29-30]。
K均值聚类法的算法步骤如下:(1)确定想要得到的输入数据集的子类数K;(2)为每个输入向量随机分配一个1至K的编号作为该输入向量的初始子类;(3)将各子类中输入向量的均值向量作为相应子类的类中心;(4)计算每个输入向量与各子类类中心的距离,将每个输入向量分配到距离其最近的类中心所在的子类中;(5)计算调整后新类的类中心,重复步骤(4),直至迭代结束或者子类类中心没有任何变化[30]。K均值聚类法得到的可能是局部最优解,所得结果依赖于步骤(2)中输入向量的类别初始化情况,因此,必须多次运行步骤(2)—(5),选择一个最优的情况[30]。
2.3 SOM-K法SOM模型具有自组织性,算法简单,但SOM模型网络收敛时间过长[31]。K均值聚类法效率较高,但聚类结果依赖于所选取的初始聚类中心,容易陷入局部最优情况造成聚类效果不佳[31-32]。K均值聚类法处理噪声数据的能力逊于SOM模型[33]。黄河径流量与输沙量数据变幅较大,变化规律十分复杂,为了取得较好的聚类效果,本文使用自组织映射-K均值聚类耦合方法,即SOM-K法进行分析:将原始数据(矩阵尺寸n×b,n代表样本数量,b代表特征个数,考虑年径流量及年输沙量时b=2)输入SOM模型得到输出结果,该输出结果(矩阵尺寸a×b,a为SOM模型输出层神经元数量)表示SOM模型对于原始数据矩阵的学习结果,将其作为K均值聚类法的输入数据进行训练,最终得到聚类结果。本文利用MATLAB SOM Toolbox 工具箱[34]实现SOM 模型,使用MATLAB R2017a 中的kmeans函数实现K均值聚类。
3 研究区域与数据
黄河发源于青藏高原巴颜喀拉山北麓,在山东省东营市垦利区流入渤海,全长约5464 km,流域面积约75万km2[2](图2)。以内蒙古自治区托克托县河口镇与河南省荥阳市广武镇桃花峪为分界点将黄河分为上中下游三段。黄河上游长约3472 km,流域面积约占总流域面积的51.3%;中游长约1224 km,流域面积约占总流域面积的45.7%;下游长约768 km,流域面积约占总流域面积的3.0%[2]。
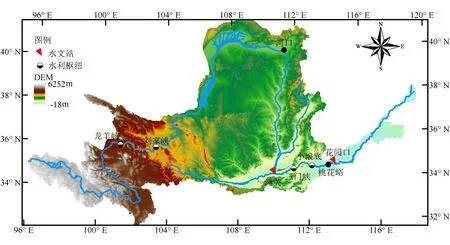
图2 黄河流域示意图
本文利用1919—2018 年及1987—2018 年黄河中游潼关站的年径流量及年输沙量数据(均为日历年数据,其中潼关2018年输沙量包括1亿多吨万家寨等水库排沙量,取为3.7亿t),分别构造水沙数据矩阵,矩阵维度分别为100行(即100年)2列(年径流量,年输沙量)及32行2列,基于SOM-K法进行年尺度水沙组合类型分类。由于潼关站早期实测数据匮乏,1919—1951年采用陕县站数据。年径流量及年输沙量数据单位不同,数量级上存在较大差异,故本文使用标准化数据进行分析,数据标准化公式为:
式中:Xst为标准化后的数据;为数据的平均值;σ为数据的标准差。

4 研究结果
4.1 1919—2018年潼关站水沙组合分类将欧氏距离作为距离度量方法,选取随机初始化方法、批量训练算法、六边形网格形状、片状映射结构、高斯邻域函数配置SOM模型,训练次数选为输出层神经元数量的500倍。综合多方面考虑,结合Melssen等提出的方法与反复试验法确定输出层神经元数量。根据前人经验,黄河的水沙组合可分为沙多水多、沙多水中、沙多水少、沙中水多、沙中水中、沙中水少、沙少水多、沙少水中及沙少水少9类,故输出层神经元数量宜大于18;由于输入数据样本数较少,且“远小于”的概念较为模糊,本文认为输出层神经元数量上限取为样本数的1/2 即可。将输出层最大边长定为10,结合上述两条原则,训练1919—2018年百年数据时共选取39组输出层神经元网格尺寸(表1)。每一种尺寸的SOM模型均进行500次训练,选择QE最小的一次结果作为各尺寸的最终结果。通过比较不同尺寸SOM模型的结果,将输出层神经元网格尺寸选为3×10,输出层神经元数量为30,该尺寸下500次训练的部分QE结果如表2所示(QE的最小值加粗表示)。
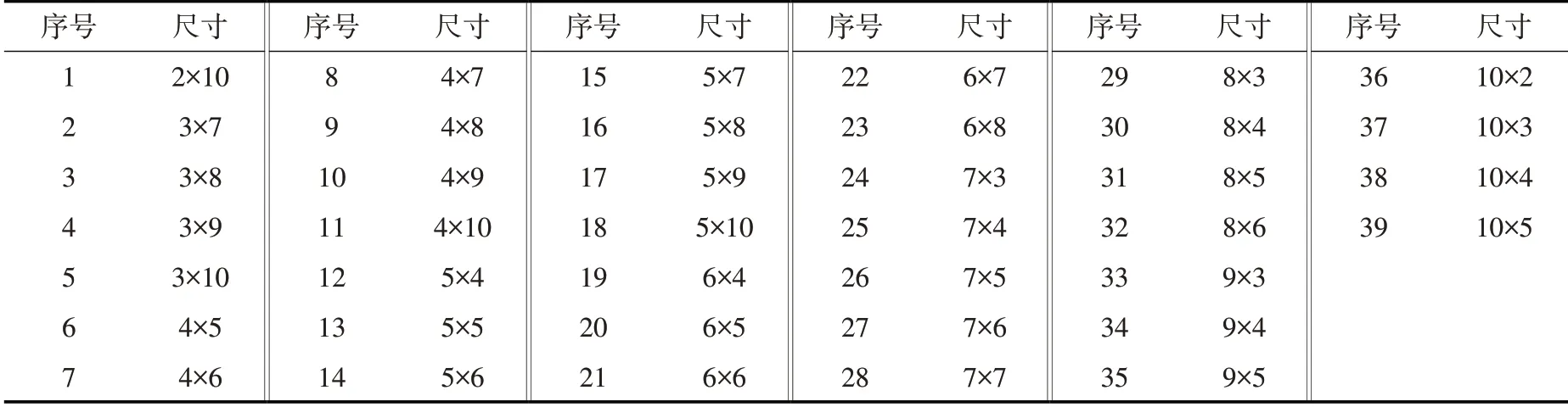
表1 输出层神经元网格尺寸(39组)
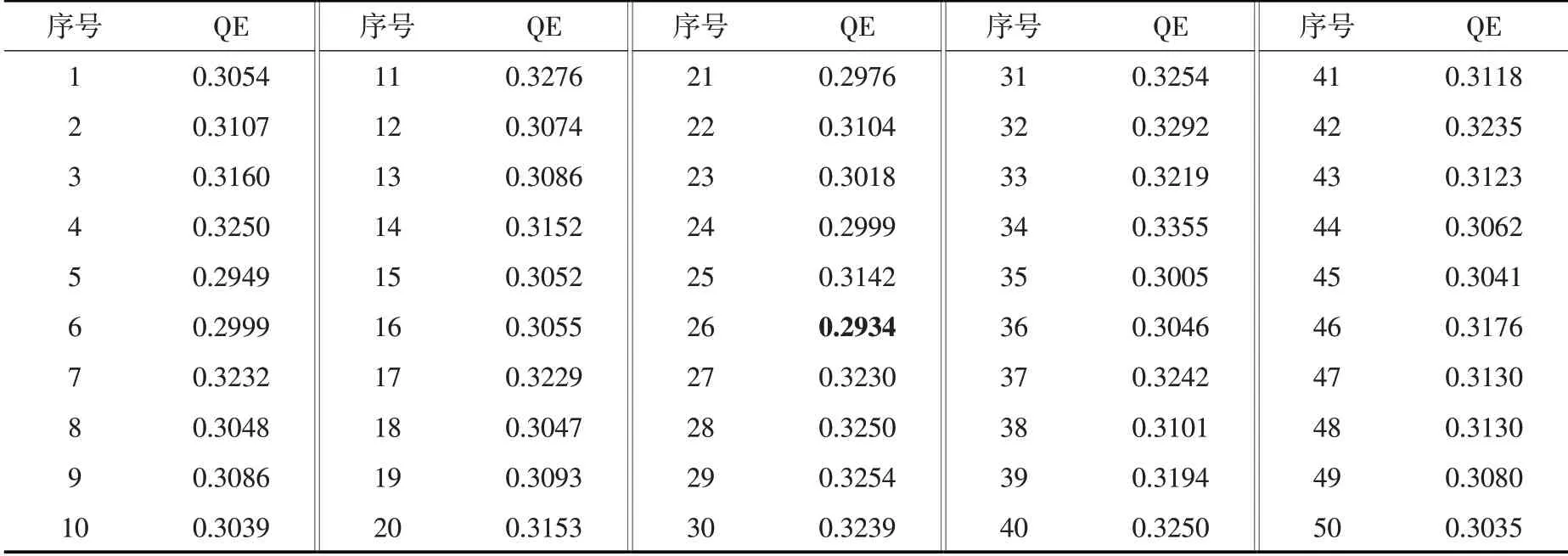
表2 部分试验QE结果(输出层神经元网格尺寸:3×10)
SOM模型的可视化聚类结果如图3所示,W代表径流量,Ws代表输沙量,TG代表潼关站,两个3×10六边形拓扑结构代表两个变量的标准化值分布,标准化值越大,六边形颜色越深。采用K均值聚类法将SOM模型的结果分为4大类,使用轮廓值(silhouette value)[35]评价聚类效果。轮廓值在-1到1之间,如果大多数输入向量拥有较大的轮廓值,可以认为聚类结果是合理的,如果大多数输入向量拥有较小或者为负数的轮廓值,表明聚类不合理,分得的子类数目可能过多或过少[35]。本次聚类效果如图4所示,大多数输入向量拥有较大的轮廓值,将输入数据集分为4个子类是合理的。

图3 SOM模型可视化聚类结果(1919—2018年数据)
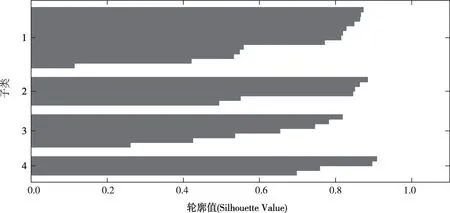
图4 聚类效果图(1919—2018年数据)
潼关站4个子类的年径流量及年输沙量分布如图5所示,依据各子类的年径流量均值及年输沙量均值将4个子类依次命名为沙少水中类型、沙多水多类型、沙多水中类型及沙中水中类型,各水沙组合的年径流量均值及年输沙量均值如表3 所示。值得注意的是,水沙组合类型中的“多”、“中”,“少”并非绝对的概念,而是与研究时期有关的相对值。
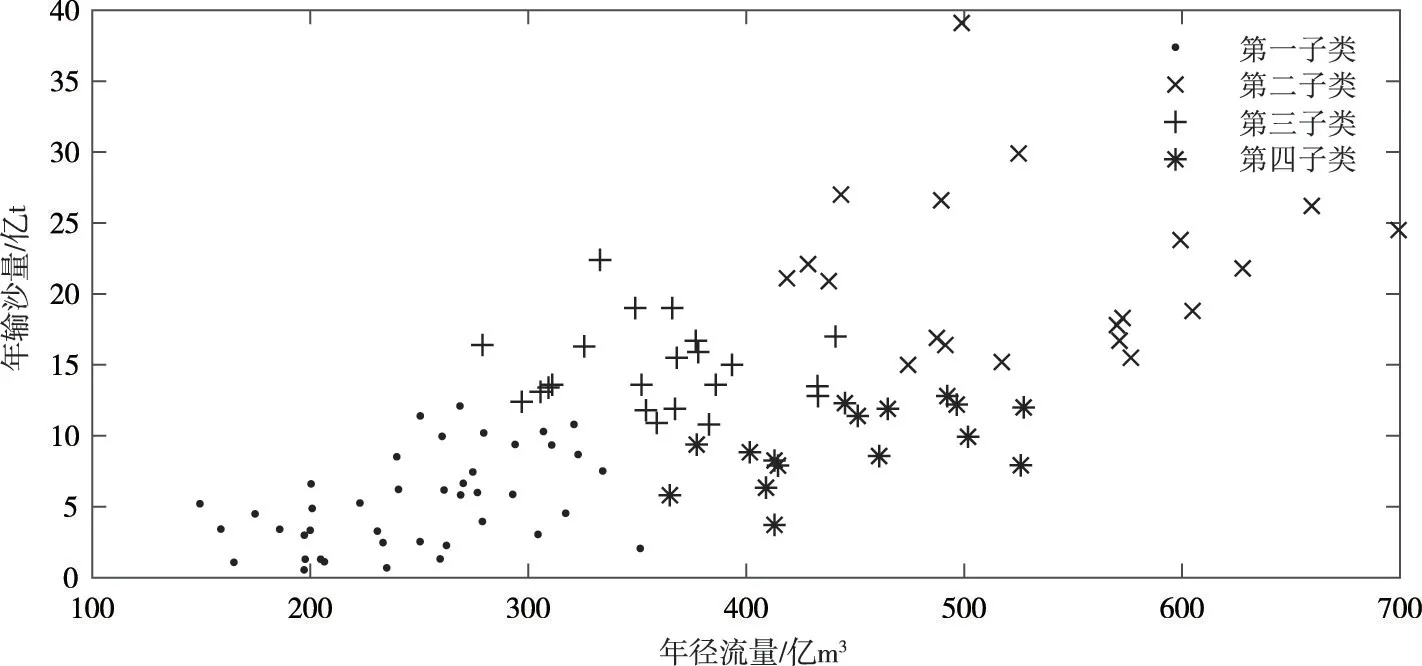
图5 潼关站4个子类的年径流量及年输沙量分布(1919—2018年数据)

表3 潼关站4种类型的水沙均值及出现频率(1919—2018年数据)
4种类型的出现频率如表3所示,沙少水中类型出现频率最大,为42%,沙多水多类型出现频率仍有20%。周恩来总理曾指出“水土保持是根治开发黄河的基础”[36],据《黄河水土保持志》记载,黄河流域的水土保持群众运动在1958—1960年进入高潮[37],张含英[38]认为1960年是水土保持工作中具有决定意义的一年,刘瑞龙[39]在这一年提出必须大抓黄河中上游的水土保持工作,可以说1960年是水土保持工作达到高潮并具有重要意义的一年。刘家峡及龙羊峡水库分别建成于1968年10月及1986年10月[40],龙刘水库的修建使黄河干流的水沙条件发生不小的改变[41]。1998 年特大洪水后朱镕基总理提出要“封山植树、退耕还林”[42],国务院发出紧急通知,2000 年前要对毁林开垦的林地实现全部还林[43]。刘家峡水库为不完全年调节水库,龙羊峡水库虽为多年调节水库改变了黄河上游的年际水量[44],但龙刘水库联合运用主要影响径流年内分配,且黄河沙量主要来源于中游,潼关站年水沙量受龙刘水库影响较小,故仅将1960 年及2000 年作为时间节点将1919—2018 年分为3 个阶段:第1 阶段为水土保持运动达到高潮前(1919—1960 年);第2 阶段为水土保持运动达到高潮后至实施退耕还林前(1961—1999年);第3阶段为实施退耕还林后(2000—2018年)。如表4所示,沙少水中类型主要在实施退耕还林后的时期出现,在3 个阶段中的出现频率相对增加,这与现有认识相符,说明本文方法可将水沙类型正确分类;沙多水多及沙多水中类型出现在实施退耕还林前的时期,在3 个阶段中的出现频率相对减少;沙中水中类型在3 个阶段中的出现频率先增后减。1986 年以来黄河年径流量及年输沙量大幅度减少[45],这一点亦可通过水沙组合分类结果看出:1986 年后潼关站有利于下游河道输沙的大水类型的出现几率明显减少(表5)。考虑到黄河水沙条件在1986年后的显著变化,需将1986 年后潼关站的年径流量及输沙量数据进行单独分类,以明确黄河水沙条件发生显著变化后潼关站水沙组合类型的变化。

表4 4种类型在3个阶段中的出现频数(频率)(1919—2018年数据)

表5 1986年后4种类型分别出现的频率
4.2 1987—2018年潼关站水沙组合分类将输出层最大边长定为10,训练1987—2018年的数据时共选取14组输出层神经元网格尺寸(表6)。每一种尺寸的SOM模型均进行500次训练,选择QE最小的一次结果作为各尺寸的最终结果。通过比较不同尺寸SOM模型的结果,将输出层神经元网格尺寸选为5×2,输出层神经元数量为10,该尺寸下500次训练的部分QE 结果如表7所示(QE 的最小值加粗表示)。
SOM模型的可视化聚类结果如图6所示。采用K均值聚类法将SOM模型的结果分为2大类,本次聚类效果如图7所示,大多数输入向量拥有较大的轮廓值,将输入数据集分为2个子类是合理的。

表6 输出层神经元网格尺寸(14组)
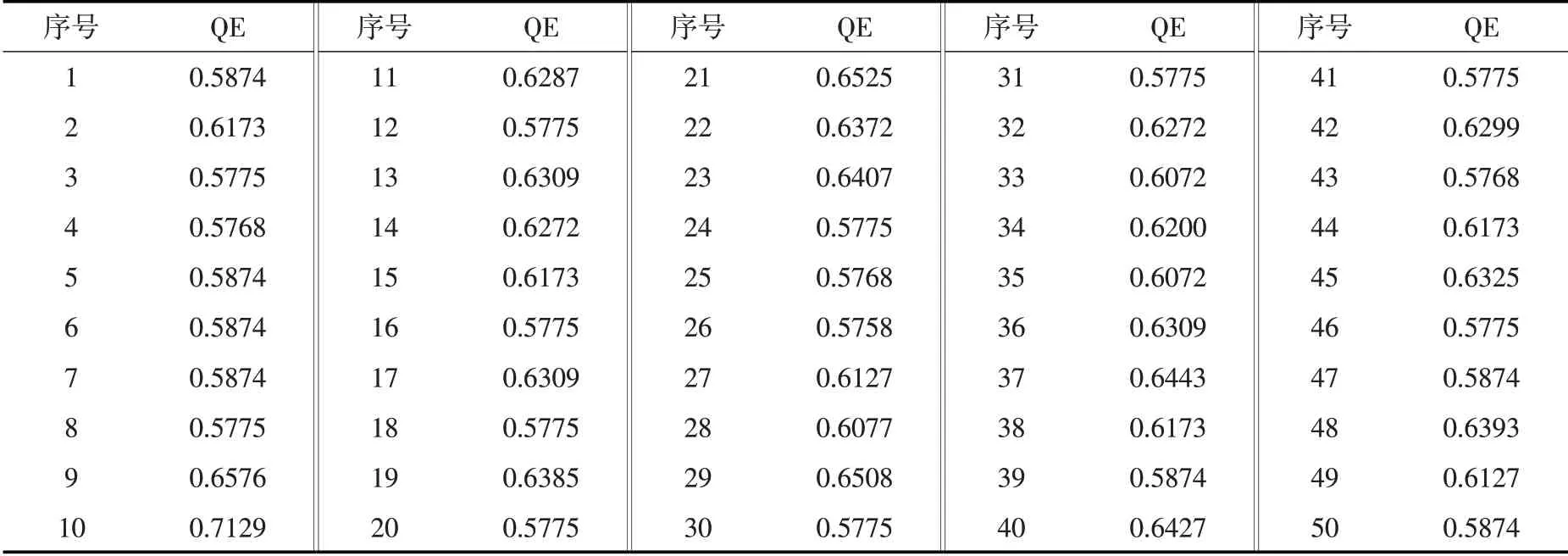
表7 部分试验QE结果(输出层神经元网格尺寸:5×2)

图6 SOM模型可视化聚类结果(1987—2018年数据)
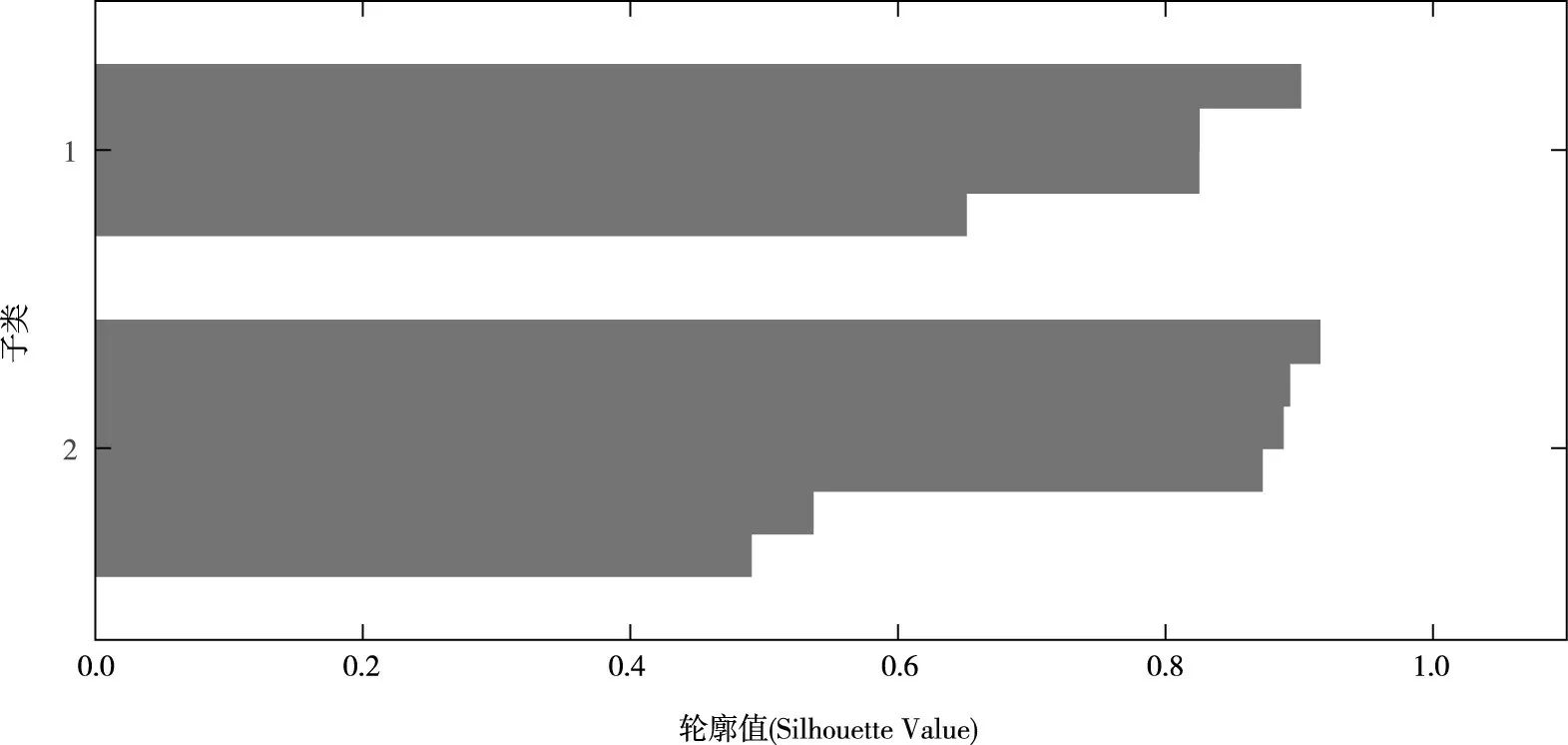
图7 聚类效果图(1987—2018年数据)
潼关站2个子类的年径流量及年输沙量分布如图8所示。同样地,依据各子类的年径流量均值及年输沙量均值将2个子类分别命名为沙中水中类型及沙少水中类型,各类型的年径流量均值及年输沙量均值的出现频率如表8所示。
采用4.1 节中的处理方法,将1987—2018 年根据时间节点2000 年分为1987—1999 年及2000—2018年2个阶段,2种类型在2个阶段中的出现频数(频率)如表9所示。可以看出,沙中水中类型的出现频率相对减少,沙少水中类型的出现频率相对增加。
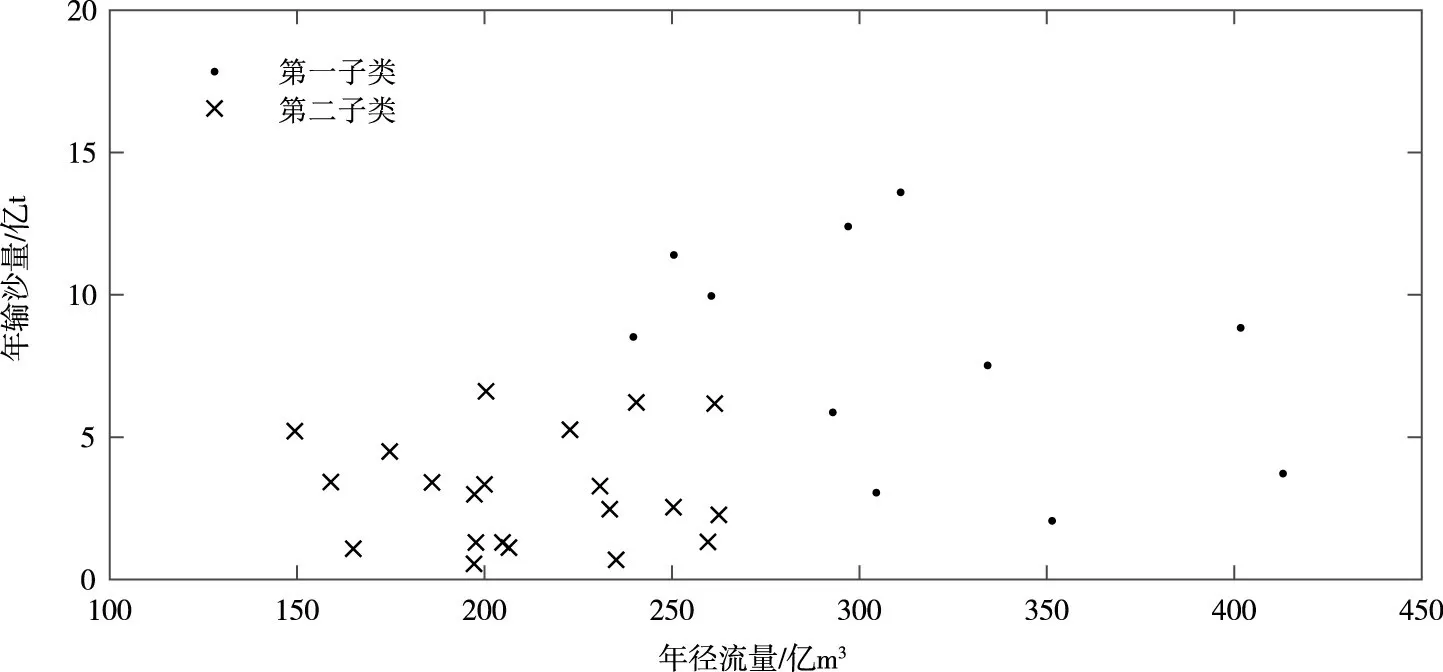
图8 潼关站2个子类的年径流量及年输沙量分布(1987—2018年数据)

表8 潼关站2种类型的水沙均值及出现频率(1987—2018年数据)

表9 2种类型在2个阶段中的出现频数(频率)(1987—2018年数据)
4.3 结果讨论比较表4及表9的结果,发现使用1919—2018年百年数据分析时,沙中水中类型的出现频率先增后减,而使用1987—2018年数据分析时,该类型的出现频率相对减少。给出百年数据分析结果中4种类型在1919—1960年、1961—1986年、1987—1999年及2000—2018年中的出现频数(频率),如表10所示,沙中水中类型在1987—1999年及2000—2018年出现频率相对减少,与表9结果相符,而在1919—1960年及1961—1986年出现频率明显增加,使得从百年尺度上看沙中水中类型的出现频率先增后减。

表10 4种类型在各时期中的出现频数(频率)(1919—2018年数据)
确定水利工程的设计及校核洪水时往往采用洪水频率分析成果,目前我国选用皮尔逊Ⅲ型曲线作为未知的洪水总体频率曲线线型[46],从而根据拟合曲线确定出设计洪水成果,例如将曲线上P=0.1%时的洪峰流量视为尚未发生过的千年一遇洪水洪峰流量。将水沙组合类型中出现频率最大的一组水沙组合(最高频水沙组合)下的径流量及输沙量视为水沙组合类型特征值,参考洪水频率分析方法中使用频率分析成果确定未发生过洪水的思路,认为此特征值可能较接近未来实际情况。4.1节与4.2 节的分析表明,两种时间尺度(1919—2018 年与1987—2018 年)下出现频率最大的水沙组合类型(均为沙少水中类型)对应的年径流量均值及年输沙量均值分别为249 亿m3及5.3 亿t 与211.2 亿m3及3.1亿t,此种差异产生的原因主要是时间尺度不同造成潜在分类阈值不同,即不同的时间尺度上对于黄河水沙丰度的衡量标准也是动态变化的。由王远见等学者的研究成果[47],黄河源区1959—2017年的年降雨量有显著的增加趋势,由靳少波等学者的研究成果[44],2007—2016年唐乃亥以上14站平均降雨量较1967—2016年多年均值增加6.2%,鉴于近些年降雨量有所增加的趋势,综合4.1节与4.2节结果,为留有一定安全余地,黄河中下游潼关以下河段年径流量特征值宜选用1919—2018年分析成果,即249亿m3。刘晓燕等学者的研究成果[48]表明,1980年代后,龙门、咸阳、张家山、河津及状头等水文断面以上地区单位降雨产沙量(产沙强度)明显降低,考虑到黄河流域通过水土保持措施使得沙量明显减少且基本不会大幅度增加的事实,表明未来潼关以下自然状况下,实际年输沙量一般不会超过表9 与表10 中2000—2018 年阶段沙少水中类型的年输沙量均值2.4 亿t。综合两节结果,黄河中下游潼关以下河段年输沙量特征值选用1987—2018年分析成果即可,即3.1亿t。此外,值得注意的是,1987年后沙中水中类型的出现频率超过30%,为留有一定安全余地,如为在黄河中下游修建水库时留出充足的淤积库容,应将沙中水中类型年输沙量均值7.9 亿t(约为8 亿t)亦考虑在内,作为黄河干流修建大型工程及下游治理方案论证的沙量特征值。鉴于问题的复杂性,黄河中下游潼关以下河段水量和沙量特征值的确定有待进一步深入研究。
5 结论
本文利用自组织映射-K均值聚类耦合方法对黄河中游潼关水文站1919—2018年的年径流量及年输沙量数据进行分析,将潼关站的水沙组合分为沙多水多、沙多水中、沙中水中及沙少水中4 种类型。沙少水中类型的出现频率最大,为42%,沙多水多类型的出现频率仍有20%。将研究时段分为水土保持运动达到高潮前(1919—1960年)、水土保持运动达到高潮后至实施退耕还林前(1961—1999年)及实施退耕还林后(2000—2018年)3个阶段,发现沙少水中类型主要在实施退耕还林后的时期出现,在3个阶段中的出现频率相对增加;沙多水多及沙多水中类型出现在实施退耕还林前的时期,在3个阶段中的出现频率相对减少;沙中水中类型在3个阶段均有出现,出现频率先增后减。
考虑到近期黄河水沙条件的显著变化,利用自组织映射-K 均值聚类耦合方法对1986 年后(1987—2018年)潼关站的年径流量及年输沙量数据进行分析,将潼关站的水沙组合分为沙中水中及沙少水中2 种类型,沙少水中类型的出现频率为65.625%。将研究时段分为1987—1999 年及2000—2018年2个阶段,发现沙少水中类型出现频率相对增加,沙中水中类型出现频率相对减少,与百年分类结果的差异体现出黄河水沙变化的复杂性。
基于自组织映射-K均值聚类耦合方法的潼关站水沙组合分类可较好地反映出实测水沙特性,有助于深入了解黄河中下游水沙变化特点,潼关站水沙组合特征值亦可为黄河中下游水沙变化研究提供参考。
