参数字典稀疏表示的完全无监督域适应*
2019-07-18余欢欢陈松灿
余欢欢,陈松灿
南京航空航天大学 计算机科学与技术学院,南京 211106
1 引言
域适应学习(domain adaptation learning,DAL)[1]作为迁移学习[2]的子问题,近几年在机器学习和数据挖掘领域受到了越来越多的关注,并被应用于自然语言[3-6]、计算机视觉[7-8]、医疗健康和生物信息学[9-10]等领域。DAL不同于传统的机器学习方法,其无需假设训练/源域(记为S)样本和测试/目标域(记为T)样本服从相同的概率分布,即PS(X)≠PT(X),因此能有效解决因概率分布不同而产生的学习性能退化问题。
无监督域适应(unsupervised DA,UDA)作为域适应学习的一个研究分支,通常用于解决标记稀缺、无标记小样本、个性化设计等问题。其中,无标记小样本问题备受关注,一般采用聚类方法进行建模,但因样本量少易导致聚类性能较差。因此,尝试借助相关域(与目标域分布不同)中的“知识”来提高目标域的学习性能。而在现实场景中,获得大量有标记源域样本成本较高,并且源域样本的标记有时可能难以获取。例如,校园网页文本分类中,不同学校的网页文本数据的分布可能存在差异(如已建立的校A网和新建立的校B网可分别作为源域和目标域),A网和B网的文本数据可能因标记成本的原因导致难以获得样本标记,同时B网建立时间较短,则可能仅有少量训练样本能获取。然而,针对此类问题,现有的基于参数[11-13]和非参数[4,14-22]域适应的方法可能难以直接对其建模。因此,在这种缺少监督信息(即完全无监督)的情况下,寻找源域和目标域间的共性并实现“知识”迁移更成为了无监督域适应研究的极大挑战。
为了应对上述问题,受先前软大间隔聚类[23](soft large margin clustering,SLMC)启发,提出了一种灵活的参数迁移新方法——参数字典稀疏表示的完全无监督域适应(whole UDA,WUDA)。该方法不仅扩充了文献[2]中的参数迁移方法,还扩展了参数迁移在域适应学习中的应用范围。本文中,WUDA的核心思想是源域和目标域的参数(决策函数的权重矩阵)借助一个参数公共字典上的稀疏表示实现选择性的互适应学习。此种基于参数字典稀疏表示的选择性域适应方法还未见发表。本文所提出的WUDA避免了现有参数迁移方法[11-13]的典型缺陷,如:(1)现有方法直接在域间作参数传递[11],或者通过线性变换[12]和参数微调[13]进行,而WUDA利用学得的参数公共字典作为桥梁实现了两个域的关联。(2)现有方法无法或难以进行参数的适应性选择学习,而WUDA则利用参数公共字典的稀疏表示加以实现,使得各域参数可被适应性选择。
总之,本文的主要贡献如下:
(1)借助源域的知识,从参数公共字典的角度,对两个域的权重经参数字典进行互适应学习,并通过系数的稀疏约束进行各域权重的适应性选择,从而实现域适应并提高目标域的聚类性能。
(2)为现有参数迁移方法提供了一个更大的灵活框架,能克服现有参数迁移方法无法适应性选择参数的缺陷,并扩展了参数迁移在完全无监督域适应上的应用。
(3)采用网格搜索法寻找最佳参数,有效克服了无标记样本无法使用交叉验证选择超参数的问题,同时合适的参数也避免了负迁移的产生。
(4)通过在多个模拟和真实数据集上与相关算法的比较,验证了本文方法在聚类性能上的显著有效性。
2 相关工作
域适应学习是机器学习领域的重要研究方向之一。在源域有标记的条件下,根据目标域是否包含样本标记,域适应学习可分为监督型[3,24]、半监督型[25-27]和无监督型[14-16,28]。例如,Daumé[3]提出了特征增广的监督型方法。那么,对于给定特征向量x,定义源域和目标域中样本的增广特征分别为和,然后根据训练分类器。但该方法需目标样本有标记,不适用于现实场景。针对这种问题,Daumé等人[25]对EDA(easy domain adaptation)算法做出改进,使其可用于半监督域适应学习。此外,考虑到无标记样本更易获得,且标记样本通常需要较高的代价,则为了提升机器学习算法在这种无标签目标域中的学习性能,无监督域适应和无监督迁移学习(unsupervised transfer learning,UTL)分别被提出。前者针对的是源域有标记而目标域无标记的学习问题,而后者解决的是源域和目标域均无标记的学习问题,其与本文提出的WUDA的主要区别[2]是:DAL针对的是不同域(D={X,P(X)})但任务(T={Y,P(Y|X)})相同的问题(DS≠DT但TS=TT)。例如,源域样本为来自Webcam的电脑图片,目标域样本为来自Amazon的电脑图片。显然,两个域的样本分布不同,但任务均为电脑识别。但UTL解决的是学习任务不同但相似的问题(TS≠TT)。因此,建立在聚类基础上的STC(self-taught clustering)[29]、TSC(transfer spectral clustering)[30]和TFCM(transfer fuzzy C-means)[31]算法先后被提出。其中,STC建立在双聚类的基础上,利用互信息学习两个域间的共有特征空间,从而提高目标域的聚类性能;TSC是一种谱聚类方法,它不仅与聚类任务的数据流形相关,还与聚类任务间共享的特征流形相关;TFCM则通过对齐源域和目标域的聚类中心来实现簇与簇的对齐,从而提高了FCM的聚类性能。
基于非参数迁移的域适应是解决UDA核心方法之一,主要包括特征迁移和实例迁移两种方法。第一种方法通常需将原始域中特征进行变换,使得变换后的域间差异减小。因此,文献[4]提出了结构对应学习算法(structural correspondence learning,SCL)来促进不同域的特征对应,其有效性取决于两个域中核心特征的启发式选择。虽然SCL算法在NLP(natural language processing)上获得了显著效果,但核心特征选择的启发式准则对不同应用极为敏感。鉴于此不足,基于对齐方式的UDA被提出。其中,Fernando等人[14]提出的子空间对齐(subspacealignment,SA)是一种实例对齐方法,该方法通过在子空间中学得变换矩阵来实现子空间基的对齐。但是,SA算法易在投影时产生代价。为了避免该问题,相关性对齐[15](correlation alignment,CORAL)和基于深度神经网络的深度CORAL[16](Deep CORAL)方法先后被Sun等人提出,CORAL通过对齐数据的二阶统计矩来学习一个线性变换矩阵,Deep CORAL建立在CORAL的基础上,解决了CORAL算法无法实现端对端计算的问题。虽然CORAL和Deep CORAL算法实现了较好的实验性能,但它们忽略了协方差矩阵是对称正定矩阵(symmetric positive definite,SPD)的属性——SPD矩阵不是欧氏空间的子空间。因此,Morerio等人[17]提出了基于黎曼度量的相关性对齐(log D-CORAL)方法,即采用似然欧氏度量[18]来衡量协方差矩阵的距离。尽管一阶矩[19](均值)、二阶矩[15-16](方差)对齐方法先后实现了较好的域适应性能,但Zellinger等人[20]提出了更强的对齐方法——中心距对齐(central moment discrepancy,CMD)。该方法实现了源域和目标域样本的各阶矩(包括一阶矩、二阶矩、三阶矩等)对齐,从而大大减小了分布间的差异。第二种方法基于重加权实现了模型建立。其中,核均值匹配(kernel-mean matching,KMM)[21]最具代表性,该方法通过匹配源域和目标域的核均值来直接学习权重,实现了域适应学习。但该方法仅关注了源域样本的重加权。因此,Li等人[22]从目标数据的角度实现了目标数据预测的重加权(prediction reweighting for domain adaptation,PRDA)。
不同于非参数方法,基于参数迁移的域适应则通过参数传递实现知识迁移。例如,Evgeniou等人[11]提出了一种参数直接迁移的方法,该方法借鉴了层次贝叶斯(hierarchical Bayesian,HB)框架[32]的思想,将SVM在源域和目标域学习的参数wS和wT分别表示为wS=w0+vS和wT=w0+vT,然后利用共享参数w0实现域间“连接”。除此之外,基于神经网络的参数迁移方法也逐渐受到关注。因此,通过参数微调[13]和变换[12](domain adaption with parameter transfer,DAPT)的方法先后被提出,参数微调法针对迁移权重实现微调,而DAPT的目标是学习一个变换矩阵W,将目标域上的分类器参数投影到源域参数空间中,使得域间参数分布相同。虽然RMTL(regularized multitask learning)和DAPT实现了部分参数的迁移,但它们不能灵活地选择各域参数和公共参数,更无法进行选择性适应。
综上所述,目前大部分域适应学习仅面向源域有标记的学习问题而设计,然而对于源域和目标域均无标记的域适应学习研究相对较少。为弥补现有参数迁移方法的不足并扩展域适应方法的应用范围,本文提出了一种基于参数字典稀疏表示的完全无监督域适应方法(WUDA)。
3 模型建立与优化
WUDA与在样本空间中直接学习字典的SIUDA[33]和S-LOW[34]不同,它通过样本学习参数(决策函数的权重矩阵),然后从学习参数公共字典的角度,在源域和目标域的权重间进行互适应参数字典学习。通过对系数的l2,1范数约束,不仅避免了文献[11-12]中的问题,而且实现了参数的选择性域适应。实际上,RMTL和DAPT能视为WUDA的特例,故而WUDA为基于参数迁移的域适应方法提供了一个更大的框架。
图1显示了WUDA的算法框架图。因此,针对给定的源域样本,通过SLMC实现聚类,学得源域权重矩阵WS。那么,当给定目标域样本时,WUDA不仅实现聚类,而且通过源域参数和目标域参数矩阵学习一个公共参数字典A=(a1,a2,…,ar),该参数字典实现了源域到目标域的知识迁移,同时对参数字典的系数矩阵做行稀疏约束,使得各域权重参数可从A中互适应选择。

Fig.1 System diagram of proposed WUDA图1WUDA系统图
3.1 软大间隔聚类(SLMC)
软大间隔聚类是一种结合了大间隔聚类[35](maximum margin clustering,MMC)和模糊聚类[36](fuzzy C-means,FCM)优点的方法,但其本身不同于FCM和MMC:第一,SLMC采用分类学习的原则在输出(标记)空间中实现聚类,该方法通过One-Of-C标记编码准则将输出空间中的聚类中心固定,并确定样本的决策函数和隶属度。第二,SLMC允许样本属于多个簇。因此,给定数据集X=[x1,x2,…,xn](xi∈Rd),令f(x)=WTx(W∈Rd×c表示权重矩阵)为决策函数,则在原始空间中SLMC的优化问题为:
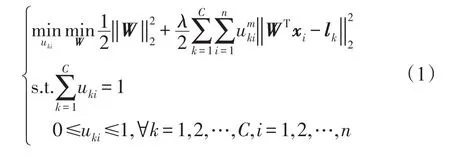
其中,U=[uki]C×n(uki表示第i个样本属于第k个簇的隶属度),{l1,l2,…,lC}表示C个簇的标记编码,且lk=[0,…,0,1,0,…,0]T∈RC(对应第k个类)表示第k个元素为1,其余元素均为0。
SLMC实际上是对样本标记的聚类,那么决策函数和隶属度可同时确定给定样本的预测值。而当给定实例的隶属度相等但簇标记不相等时,为了保证期望一致性,SLMC总是将样本分配给簇标记更小或更大的簇。
3.2 WUDA模型的建立
对于完全无监督域适应问题,给定无标记的源域样本XS=[x1,x2,…,xnS]∈ Rd×nS和目标域样本XT=[x1,x2,…,xnT]∈ Rd×nT,其中nT≪nS。假设源域DS和目标域DT不同:XS=XT但P(XS)≠P(XT),源任务TS和目标任务TT相同:YS=YT且P(YS|XS)=P(YT|XT)。因此,本文从学习参数公共字典的角度,实现了源域和目标域知识的关联,并通过对字典系数的稀疏约束实现各域参数的适应性选择。故WUDA的优化问题如下:

其中,WS和WT为d×C矩阵,分别表示源域和目标域的权重矩阵;A∈Rd×r表示源域和目标域公共字典;VS和VT为r×C矩阵,分别表示源域和目标域的系数矩阵,然后引入l2,1范数来约束系数,体现了权重矩阵可由字典稀疏表示的特性;λ、β1、β2和α为权衡参数。
对于式(2),第一项和第二项继承了原始的SLMC算法,主要用于目标域数据的聚类;第三项和第四项为参数的公共字典学习,实现了源域和目标域“知识”的连接;最后两项为字典系数的约束,并通过行稀疏约束实现了选择性域适应。
该模型基于SLMC在输出(标记)空间中进行聚类,通过学习参数公共字典实现域间知识连接,并由稀疏系数实现各域参数(权重)在公共字典中的适应性选择。此外,本文提出的参数迁移新方法,对于无监督模型(FCM及其衍生算法)、监督模型(SVM及其衍生算法)和神经网络模型,亦可分别对聚类中心和权重进行参数字典学习实现域适应。因此,本文提出的WUDA框架有着较广泛的扩展。
3.3 模型优化
WUDA是关于(WT,u,A,VS,VT)块凸的优化问题,则根据文献[37]可保证迭代优化的收敛性。故而,本文使用交替迭代法优化目标变量,即在优化过程中,固定其他变量,只优化一个变量。因此,式(2)的优化问题可重写为以下5个子优化问题:
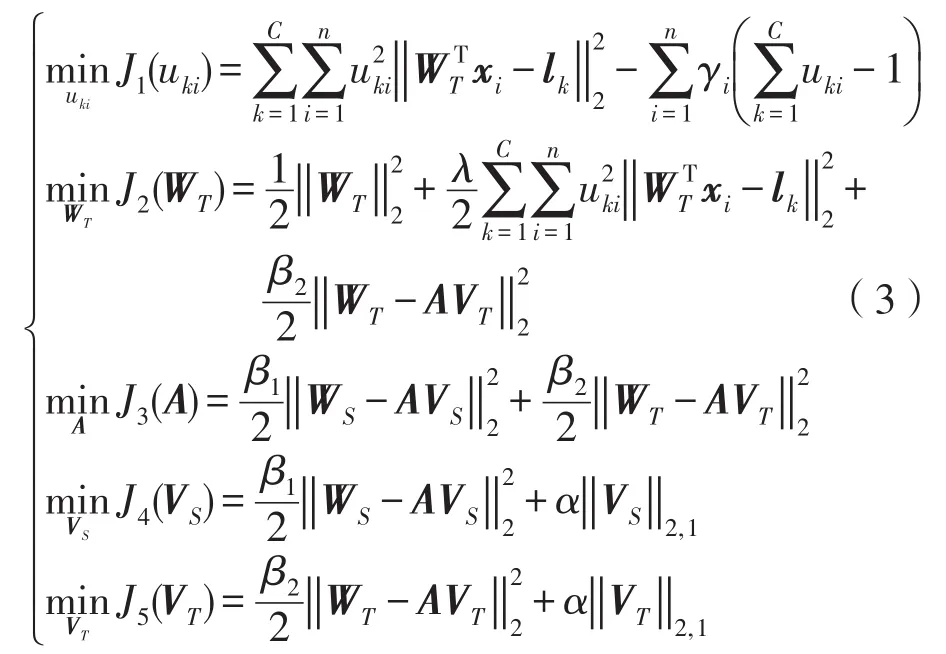
对于式(3)中的5个子优化问题,分别令关于uki、WT、A、VS、VT的偏导为0,即有:

因此,关于uki、WT、A、VS、VT的闭式解如下:

那么,具体算法如下:
输入:XS、XT,源域和目标域数据集;λ、β1、β2、α,权衡参数;r,字典的词汇量;ε,迭代停止参数;Max_iter,迭代最大次数。
输出:U,隶属度矩阵;,决策函数。


4 实验与结果
4.1 实验设置
实验中,采用RI(rand index)和NMI(normalized mutual information)指标评估WUDA算法的聚类性能。通常,RI和NMI的定义如下:
子美千古大侠,司马迁之后一人。 子长为救李陵而下腐刑,子美为救房琯几陷不测,赖张相镐申救获免。 坐是蹉跌,卒老剑外,可谓为侠所累。 然太史公遭李陵之祸而成《史记》,与天地相终始; 子美自《发秦州》以后诸作,泣鬼疑神,惊心动魄,直与《史记》并行。 造物所以酬先生者,正自不薄。
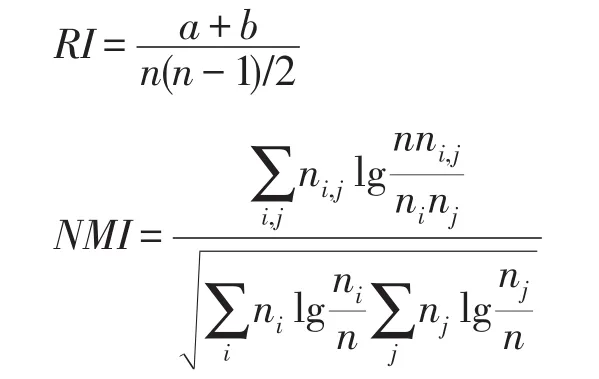
其中,n为样本数,a和b分别表示实际标记和预测标记属于相同类别的元素对数和不同类别的元素对数。ni,j表示簇i和簇j一致的样本量,ni和nj分别表示簇i和簇j的样本量。RI和NMI的取值范围均为[0,1],并且它们的值越大说明聚类效果越好。
在WUDA优化模型中,字典的词汇量r和多个权衡参数(λ、β1、β2、α)需要确定,β1和β2分别权衡源域和目标域所提供“知识”的程度。因此,这些参数值的确定对提高WUDA的聚类性能至关重要。同时,本文的研究问题是从完全无监督(源域和目标域中的数据均无标记)的角度考虑,而交叉验证法主要面向监督型方法确定参数。因此,在实验过程中采用网格搜索法来寻找最佳参数,避免了不佳参数产生的负迁移问题。
本文关注的是无标记小样本问题。因此,对目标域数据做以下处理:从给定的真实数据集中随机抽取各类的部分样本作为目标域的实验数据。
实验均在配置为Intel®CoreTMi5-3470 CPU,16 GB内存的计算机上运行,且实验代码均由python编写实现。
4.2 实验结果
为了验证WUDA算法的有效性,本文分别在模拟数据集和真实数据集上进行实验,对比算法包括聚类算法(FCM、SLMC)和无监督迁移学习算法(STC、TSC、TFCM),并且为了避免实验的偶然性,分别在各数据集上运行10次,以它们的均值作为最后的实验结果。
(1)模拟数据集
在模拟数据集中,分别模拟高斯分布和双月分布。在高斯分布的情况下,源域样本数为600(每个类为200),目标域样本数为90(每个类为30)且特征维度均为2。而在双月分布的情况下,源域样本数为400(每个类为200),目标域样本数为60(每个类为30),且特征维度也为2。由图2知,源域和目标域的边际概率P(X)不同,但条件概率P(Y|X)相同。

Fig.2 Simulated data sets图2 模拟数据集

Table 1 Performance comparison of simulated data sets表1 模拟数据集性能比较
(2)真实数据集
真实数据集包括Office+Caltech、Mnist+Usps和PIE数据集,分别为目标识别、手写数字和人脸识别数据集。如表2所示。

Table 2 Real data sets表2 真实数据集
(1)Office+Caltech数据集总共包括2 533个图片和4个域,分别为Webcam、Amazon、Caltech和Dslr,且这4个域的边际分布(P(X))不同但描述的均为相同的物体。在实验中,分别以Caltech和Webcam作为源域,以Amazon和Dslr作为目标域。
(2)Mnist+Usps数据集共有3 800个样本和2个域,这两个域中的手写数字的表现形式不同。实验中,以Mnist为源域,Usps为目标域实现完全无监督域适应。
(3)PIE数据集是人脸识别数据集,该数据集根据不同的拍摄角度划分域。实验中,选取PIE05作为源域,PIE07作为目标域实现完全无监督自适应。综上,数据如图3所示。
在实验中,为了验证WUDA的可行性仅仅是因为域适应而不是样本是否线性可分,以线性决策函数f(x)=WTx为代表进行算法验证和比较。因此,本文通过减少类别数来降低非线性情况的概率。那么,在 Caltech→Amazon、Webcam→Dslr、Mnist→Usps、PIE05→PIE07数据集中,分别从它们的10、10、10和68个类中随机选择3、4、3和8个类作为实验类别,故实验结果的好坏完全验证了域适应的程度。
对于非线性问题,本文的WUDA也可解决。但WUDA的优化函数需做以下修改:将核化后样本的决策函数表示成f(x)=WTφ(x)=αK,然而,直接对参数W进行字典学习会因φ(x)未知而导致问题无法优化。故而,需对参数α进行互适应公共字典学习,从而可以解决样本线性不可分的问题。因本文的主旨是验证WUDA在概念上的可行性,所以仅对线性情况做了实验,免去了非线性的实验,原因是两者实现方式上完全一致。因此,给出了非线性情况的理论说明,同时线性情况的实验已充分验证了WUDA不仅可行,而且聚类效果显著。
由于本文针对的是无标记小样本问题,且原始样本数过多,故从对应类中随机删除部分数据,得到了满足要求的数据。
在真实的域适应数据集上,分别与5种算法进行比较,得到表3,并据此得出以下结论:

Fig.3 Real data sets图3 真实数据集
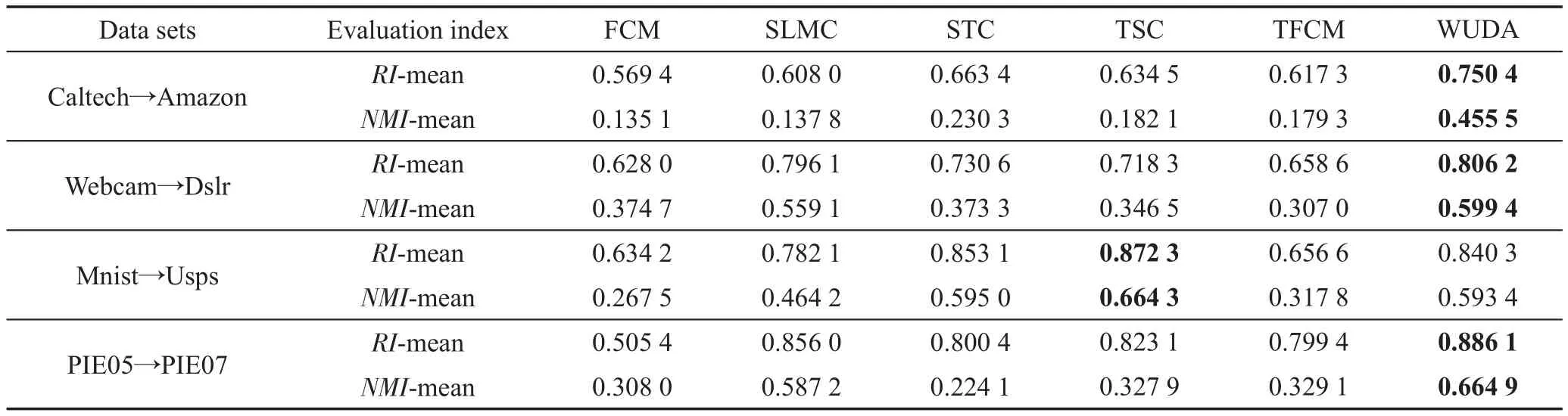
Table 3 Performance comparison of real data sets表3 真实数据集性能比较
(1)在Office+Caltech数据集和PIE人脸识别数据集上,提出的WUDA明显优于其他算法,主要得益于源域和目标域间公共字典的连接及其选择性适应。STC和TSC均从实例和特征两个角度实现知识迁移,由于其无选择能力,导致不利元素也被迁移致使性能变弱;而TFCM受源域和目标域间的类中心和隶属度的影响,若源域对目标域的类中心和隶属度指导性差,则同样因其无选择能力而导致迁移能力变弱。此外,对比2016年提出的TFCM,在Office+Caltech数据集上,WUDA的RI指标高出约15%;在PIE数据集上,NMI指标高出约35%。
(2)在Mnist+Usps数据集上,TSC的聚类性能最佳,但WUDA明显优于TFCM,且与STC的聚类性能相当。究其原因:Mnist和Usps数据集间参数的相关性较弱,导致Usps和Mnist互适应学得的公共“知识”较少,致使各域参数的选择能力变弱,故而WUDA的聚类性能达不到最佳。TSC在原始样本空间中实现谱聚类迁移学习,由于受参数相关性影响相对较小,因此域适应效果优于WUDA。
(3)在所有数据集上,提出的WUDA均优于原始聚类算法SLMC,说明通过调节域适应参数β1、β2和α,可有效地抑制负迁移的产生。
4.3 参数和收敛性
(1)参数选择
本文所提的WUDA的目标函数有多个参数需要确定,在完全无监督的情况下,采用网格搜索法寻找最佳参数。在参数选择的过程中,以PIE数据集为例进行参数确定。
首先是参数α,它用于权衡字典稀疏系数的重要性,搜索范围为[0.01,0.10,1.00,2.00,5.00,8.00,10.00,20.00,50.00]。观察图4(a)发现:当α=1.00时,NMI的值最大;同时,α在[2.00,5.00,8.00,10.00]上并未对结果产生显著性影响。
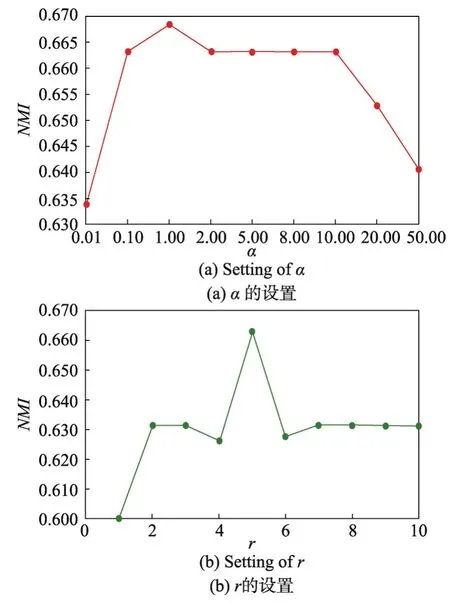
Fig.4 Parameter setting ofαandr图4 α和r的参数设置
然后是参数r,它表示字典的词汇量。从图4(b)易知,词汇量的大小显著地影响聚类性能,搜索范围为1~10,当r为5时,NMI取最大值0.665;当r超过5时,NMI趋于稳定。说明r超过一定值时,超出的字典对域适应学习影响较小。然而总体的NMI变化较大,则说明字典词汇量过小,会影响WUDA的聚类性能。
最后,对于参数β1和β2,分别用于权衡源域和目标域中参数W的重要性,搜索范围均为[0.000 1,0.001 0,0.010 0,0.100 0,1.000 0,5.000 0,10.000 0]。观察图5发现:当β1=5.000 0,β2=0.010 0时,NMI取最大值,说明目标域从源域中适应性学得了可迁移“知识”,提高了目标域的聚类性能。
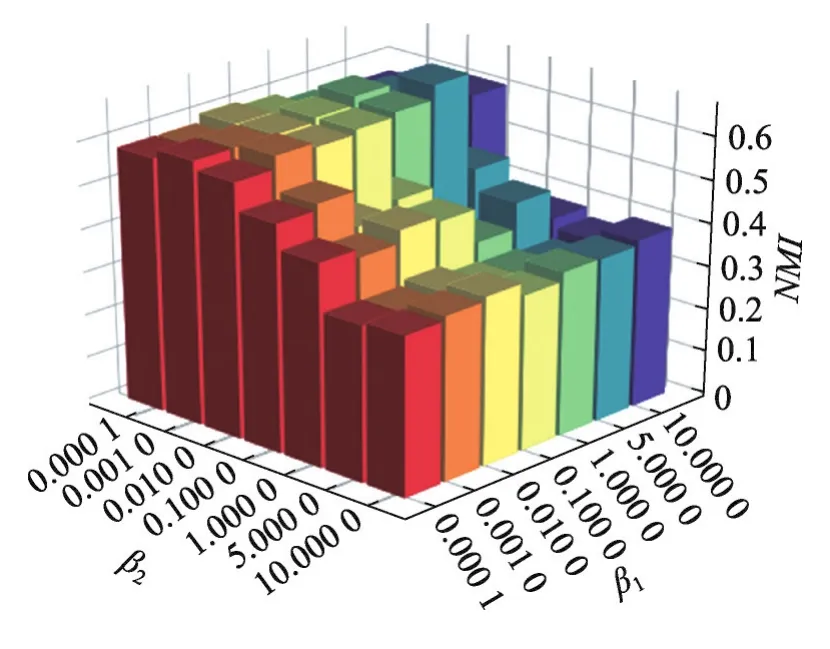
Fig.5 Parameter setting ofβ1andβ2图5 β1和β2的参数设置
(2)收敛性
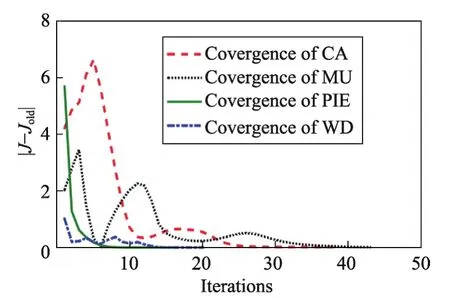
Fig.6 Convergence of data sets图6 数据集的收敛性
5 总结与展望
本文受软大间隔聚类的启发,结合字典学习的理论,在源域和目标域的权重间进行互适应参数公共字典学习,并引入l2,1范数来约束字典系数,使各域参数可从公共字典中适应性选择,从而实现域适应学习。最后通过相关实验验证了WUDA的可行性和显著有效性。除此之外,本文的算法思想不仅适用于SLMC,对于传统的无监督算法(如FCM及其衍生算法)、监督型算法(如SVM及衍生算法)和神经网络,可对聚类中心v和参数W分别进行互适应公共字典学习,亦可实现域适应学习。故下一步工作中,将对此算法做以下扩展:(1)目标域类别是源域类别的子类问题;(2)多个源域和多个目标域的互适应学习问题(既有虚漂移也有实漂移),同时包括源域和源域、目标域和目标域的互学习。
