一种基于主题判定的网页元素XPath定位器生成方法
2019-05-05高建华
张 弛,高建华
(上海师范大学 计算机科学与技术系,上海 200234)
1 引 言
在Web开发过程中,为了保证Web应用的质量,Web应用必须进行相应的测试.G.J.Myers[1]有一条著名的经验总结,在软件项目中,软件测试大约占用项目时间的50%和总成本的50%以上.即便已经出现了大量的自动化测试工具与框架,这个结论依然成立.
目前,Web自动化测试工具和框架已经很大程度上实现了自动化,代替了人工测试.在Web测试脚本的生成中,最耗时的和最脆弱的,就是Web网页元素定位[2].虽然目前已经存在一些提供自动化生成测试脚本的工具,如Watir、Selenium IDE的录制与回放[3],但是生成的测试脚本中不少还存在着网页元素定位器失效的问题.另外,在回归测试中,由于细微的Web结构改变或者网页元素属性值的变化,网页元素定位器可能会失效,从而导致Web测试脚本的失效,这时Web测试脚本需要修复或重新生成.
在Web测试脚本修复方面,多种针对网页元素定位器失效的方法[4-6]被提出,具有不错的效果,但是若能有效地提高Web测试脚本的鲁棒性,Web测试效率将进一步提升.
目前已实际应用的字符串匹配方法,通过输入框的id属性值来确定输入框的主题,提高了网页元素定位的鲁棒性,但是仅依靠id属性进行定位,定位能力较差.Lin等人[7]提出了应用于基于网页爬取Web应用测试的语义相关性方法,可以在一定程度上实现网页元素的主题确定,能够很好地帮助网页元素进行定位,但是标签中属性值复杂,直接获取到的属性值不一定具备相应的语义.M.Leotta等人[8-10]提出了多种方法来提高XPath定位鲁棒性,使得XPath定位器在回归测试时细微的Web结构变化情况下能保持较好的鲁棒性,但是在网页元素属性值和网页结构同时发生变化时,却难以继续保持良好的鲁棒性.
网页元素定位方法中,XPath 定位方法一般优于其它方法.因为网页元素不一定具备id,name,class等属性,使得基于这些属性的定位方法无法定位网页元素,故而有时XPath定位方法成为唯一的选择.此外,网页爬取技术的发展使得网页元素定位器的自动生成变成可能[11].
本文主要针对静态网页表单中的网页元素,采用网页爬取技术来获取网页DOM,通过“网页元素”-“特征词”-“主题”的转换,确定待测网页元素的主题,筛选得到所需主题的网页元素,并根据网页元素自动生成对应的XPath绝对路径,实现对网页元素的准确定位.经测试,该方法能够有效地确定网页元素的主题,自动生成的XPath定位器在回归测试中有较好的鲁棒性.
本文第2节定义了与网页元素相关的术语;第3节介绍了网页元素的主题关键词集合和主题特征词词频;第4节详细地阐述了基于主题判定的网页元素XPath定位器生成方法;第5节对本文提出的方法进行了实验和数据分析;第6节对本文内容进行了总结.
2 相关术语
定义1.网页元素主题:在Web测试中往往是对网页元素进行操作,而一个网页元素往往对应一个逻辑名称,如:用户名输入框、注册按钮等,在本文中将此定义为网页元素的主题.引入网页元素主题可以到达识别网页元素的目的,帮助网页元素定位.
定义2.主题集合:在一个Web页面中通常含有多个网页元素,因此对应的主题也有多个,将这些主题构成一个网页元素主题的集合,称为主题集合,记为T.
T={主题t1,主题t2,…}
定义3.主题关键词:从网页元素与主题相关的属性值中获取与某个网页元素主题相关的关键词,主题与其对应的关键词构成主题关键词对应关系.
主题t1:{关键词k11,关键词k12,…}
定义4.主题关键词集合:由于一个Web页面中对应一个主题集合,因而与该主题集合相关的关键词应该为主题集合中所有主题对应的关键词集合,这被称为主题关键词集合.
{主题t1,主题t2,…,主题tn}:{关键词k11,关键词k12,…,
关键词k21,关键词k22,…,关键词kn1,关键词kn2,…}
由于集合内元素的互异性,主题关键词集合中的元素互不相同.
定义5.网页元素特征词:首先提取网页元素的重要属性值,而后从网页元素与主题相关的属性值中提取主题关键词集合中的词,这两部分提取到的词作为网页元素特征词,其全体记为F.
F=(重要属性值s1,重要属性值s2,…,
关键词k1,关键词k2,…)
网页元素的重要属性值,一般是指能帮助区分网页元素的类型和确定网页元素的主题的网页元素属性值.网页元素的标签名一般是网页元素的其中一个重要属性值,并基于标签名来确定网页元素的重要属性值,如网页元素标签名为input时,则type属性值应为该网页元素的重要属性值.静态网页表单中网页元素的类型一般有文本、输入框、按钮、图片、超链接等等.
3 主题词库
主题词库是主题集合中所有主题特征词的集合,主题词库主要是为了实现网页元素主题的确定.其中,主题特征词是属于该主题下的所有网页元素样本特征词的集合.在Web开发过程中,一般都有相应的前端开发代码规范,使得开发者在开发过程中须遵循相应的命名和赋值规范.因此,网页元素的属性值中一般也会有相应的关键词来代表对应的主题,这使得网页元素的主题确定能够实现.
3.1 主题关键词集合
选取Web测试中将要进行测试的主题,如:用户名输入框,密码输入框等主题,收集足够的网页元素样本.根据命名与赋值规范,从这些网页元素样本中,找出与对应主题相关的关键词,并组成相应的主题关键词.主题关键词可以不断扩充和重复使用,也可以专门为特定的网页制定合适的主题和相应的关键词用于Web回归测试.主题关键词基于特定的主题集合将组成主题关键词集合,主题关键词集合的作用是在特定的主题集合场景下建立了网页元素主题与关键词之间的联系.
3.2 提取特征词
提取网页元素特征词主要是从网页元素与主题相关的属性值中提取主题关键词集合中的词以及网页元素的重要属性值.
算法1.特征词提取算法
输入:网页元素e
主题关键词集合F
网页元素的重要属性列表IL
与主题相关的属性列表AL
输出:网页元素e的特征词W
1.W←[],S←[]
2.ForeachimpAttr∈ILDo
3.W←W∪Format(e.impAttr.value)
4.Endfor
5.Foreachattr∈ALDo
6.Ife.attr.value≠NULLThen
7.S←S∪Format(e.attr.value)
8.Endif
9.Endfor
10.FSorted←SortByLength(F)
11.Foreachs∈SDo
12.Foreachf∈FSortedDo
13.Ifs.substring=fandSatisfyCons(s)Then
14.W←W∪f
15.Endif
16.Endfor
17.Endfor
算法1中,Format函数是将字符串中字母转化为小写、特殊字符转化为空格以便于关键词提取.SatisfyCons函数是避免出现重复提取和错误提取,防止干扰主题确定.其中,第2行至第4行是提取网页元素的重要属性值;第5行至第9行是提取与主题相关属性的值;第10行至第17行是从与主题相关的属性值中提取主题关键词集合中的词.
主题特征词是由该主题下的所有网页元素样本特征词构成的集合,形成了主题与特征词的对应关系.因此仅针对单个主题下提取网页元素样本特征词时,主题集合中仅有一个主题且主题关键词集合与该主题关键词相同.
3.3 主题特征词频次
主题特征词频次是指主题特征词在该主题下平均每个网页元素样本特征词中的出现频次.
(1)
其中,topic代表主题,feature代表特征词,nfeature代表特征词在该主题下出现的次数,Ntopic代表该主题下的网页元素样本数.
4 基于主题判定的网页元素XPath定位器生成方法
基于主题判定的网页元素XPath定位器生成方法是通过确定待测网页元素的主题并自动生成网页元素的XPath定位器.方法如图1所示,步骤如下:
1)确定Web网页中的待测网页元素属于哪些主题,即确定主题集合,而后确定主题关键词集合,并计算主题特征词频次.
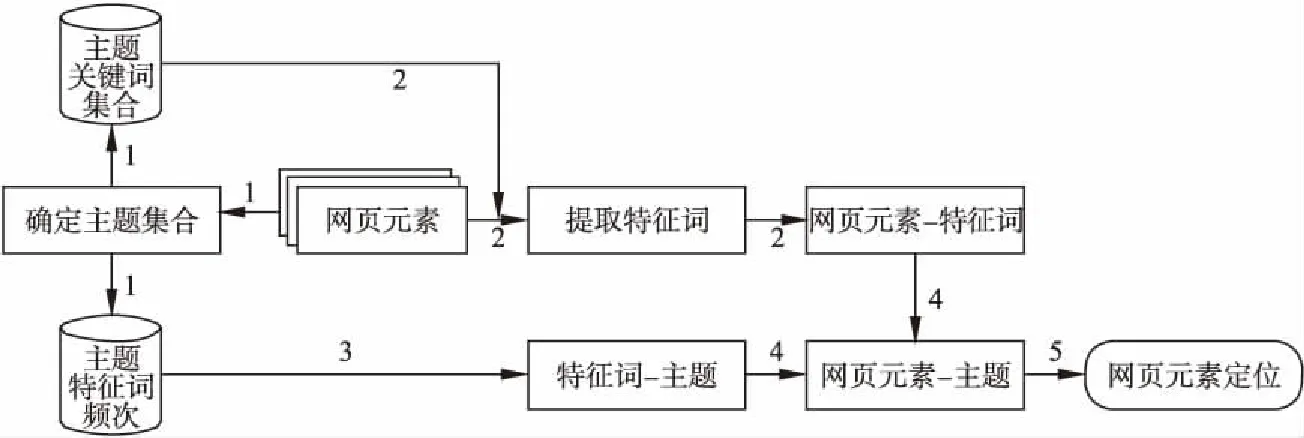
图1 方法的概图Fig.1 Overview of the proposed approach
2)结合主题关键词集合,从待测网页中提取网页元素特征词,而后计算待测网页元素中对应特征词的频率.
3)依据主题特征词频次,计算提取到的网页元素特征词属于各主题的概率.
4)结合待测网页元素中对应特征词的频率和网页元素中对应特征词的频率,得到待测网页元素属于各主题的概率,依此确定待测网页元素的主题.
5)基于待测网页元素的主题生成XPath定位器.
4.1 确定网页元素主题
待测网页元素是进行Web测试时能够被操作的网页元素.对于Web页面而言,测试人员可以确定待测页面有哪些主题的待测网页元素,从而确定主题集合.主题集合确定后,可以进一步确定主题关键词集合.本方法通过爬取待测网页,筛选得到待测网页元素,并通过算法1从待测网页元素中提取待测网页元素特征词.
网页元素e中特征词w出现的频率pe(w|e).
(2)
其中,nw代表网页元素e中特征词w的出现次数,ne代表网页元素e中所有特征词出现的总次数.
而后通过第3节所获得的主题与特征词关系,计算待测网页元素e中特征词w属于主题t的概率pw(t|w).
(3)
其中,T是指主题集合.
由于网页元素各属性值之间不属于上下文关系,将网页元素的主题约束于主题集合后,可以通过网页元素中特征词的频率与特征词属于某主题的概率,计算得到该网页元素属于主题集合中某主题的概率,从而实现“网页元素”-“特征词”-“主题”的转换,达到确定网页元素主题的目的.
网页元素e属于主题t的概率pt(t|e).
pt(t|e)=∑w∈Wpw(t|w)·pe(w|e)
(4)
其中,W代表所有待测网页元素的特征词.本方法中将网页元素对应概率最高的主题作为该网页元素的主题.
一般情况下,待测网页元素的主题是该网页元素对应概率最高的主题,但是存在少数网页元素的主题并不是网页元素对应概率最高的主题,存在这种情况一般是因为部分主题的网页元素样本数少、待测网页元素属性值命名不规范或者待测网页元素属性值中存在较多干扰主题确定的词.同时由于一些非待测网页元素在该方法下也会有一个对应的主题,这些非待测网页元素存在对应主题后可能将影响Web测试,因而需要设定阈值来减少非待测网页元素的干扰.本文通过实验发现如果将阈值设置在合理区间,即网页元素对应认定主题的概率要大于阈值才认为该网页元素属于该主题,能消除大多数非待测网页元素的影响,也尽可能地不影响待测网页元素的主题确定.
4.2 网页元素XPath路径生成
本文采用深度优先搜索(DFS)与DOM树结合的网页元素XPath路径生成算法,来实现网页元素XPath路径的自动生成.
算法2.网页元素XPath路径生成算法
输入:网页DOM
给定的网页元素e
输出:网页元素e的XPath路径eXpath
1. root←DOM.body
2. startXpath←“/html/body”
3. call WebElementDFS(root,startXpath) //深度优先搜索
4.
5.FunctionWebElementDFS(DOMnode,XPathxpath)
6. tagnameList←[]
7.Foreachchild∈node.childrenDo
8.tag_name←child.tag_name
9.position←0
10.tagnameList←tagnameList∪tag_name
11.Foreachn∈tagnameListDo
12.Ifn =tag_nameThen
13.position←position+1
14.Endif
15.Endfor
16.Ifchild = eThen
17.eXpath←xpath+″/″+tag_name+″[″+position+″]″
18. StopDFS()
19.Else
20. WebElementDFS(child,xpath+″/″+tag_name+″[″+position+″]″)
21.Endif
22.Endfor
23.Endfunction
在算法2中,从Body节点开始遍历所有子节点,第7行记录了子节点的标签名;第8行至第14行计算了XPath路径的位置值.如果该子节点为输入的目标网页元素e,则生成XPath路径并停止DFS搜索,如第17行至第18行所示;否则继续进行DFS搜索,如第20行所示.
5 实验分析
为了验证基于主题判定的网页元素XPath定位器生成方法的有效性,本文在实际网站中应用本文所提方法.实验主要寻求以下几个问题的解答:
Q1:相对于广泛使用的字符串匹配方法,使用本文所提方法是否可以提升网页元素定位的能力?
Q2:使用本文所提方法是否可以在回归测试中提高网页元素定位器的鲁棒性?
Q3:在Web测试时,本文所提方法是否可以提升测试效率?
5.1 实验设置
实验1.待测网页集合有82个页面,由注册页面和登陆页面组成,针对“用户名”、“密码”、“邮箱”、“名”和“姓”等5个主题的输入框进行相应实验,共260个待测网页元素,分别采用本文提出的方法和字符串匹配方法进行待测网页元素的主题确定与定位.
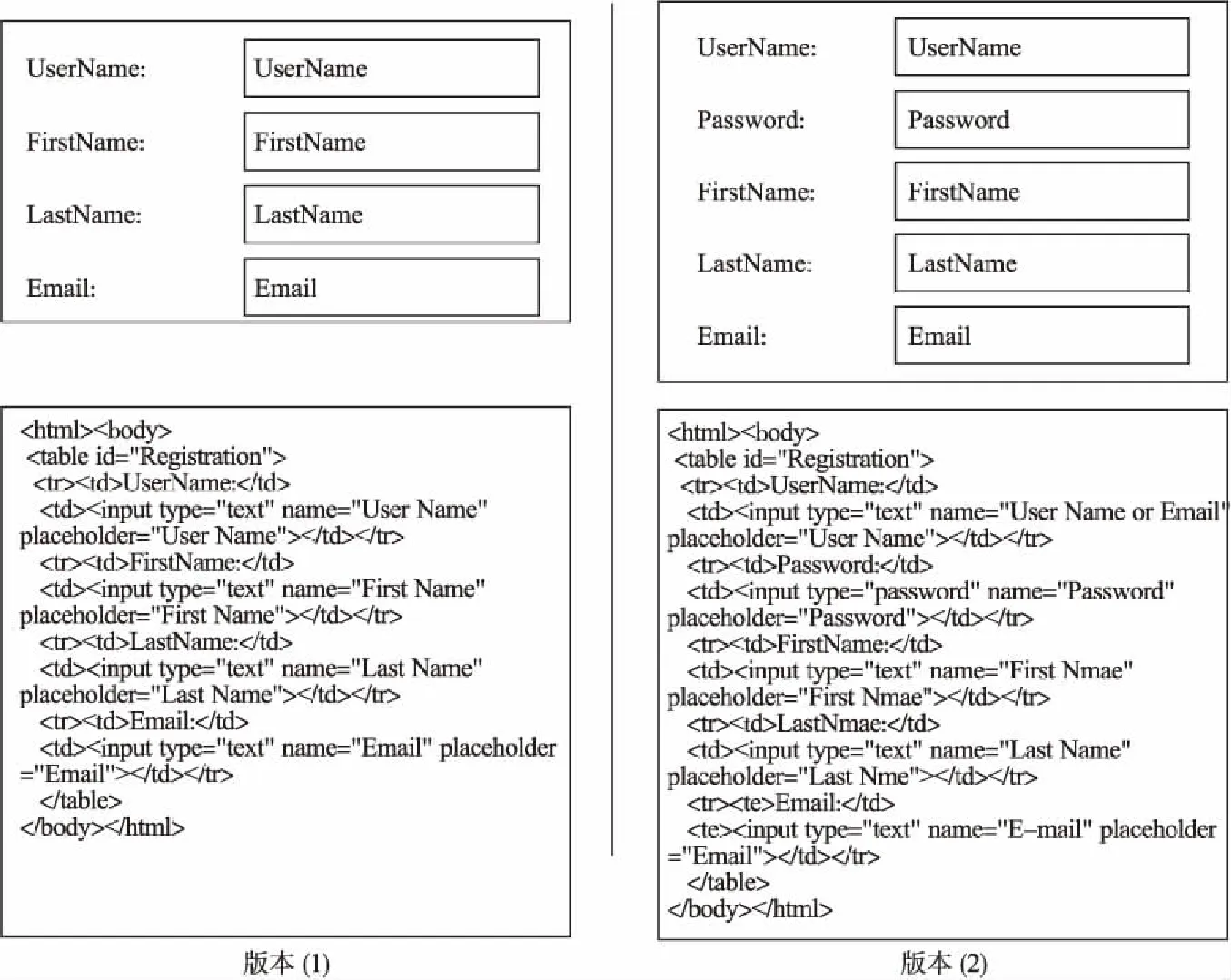
图2 Web应用的两个版本Fig.2 Two versions of a Web application
实验2.将本文提出的方法应用于一个简单Web应用的两个版本中,Web应用如图2所示,与文献[8]所提及的5种方法作比较,验证使用本文所提方法是否可以在回归测试中提高网页元素定位器的鲁棒性和提高测试效率.
5.2 网页元素定位能力
目前广泛采用的字符串匹配方法,是基于特征词字符串匹配规则来确定网页元素的主题.例如,若要对一个主题为“密码”的输入框中赋值“Pwd123”.
第1步,基于特征词字符串匹配规则来确定网页元素的主题:
DOM.tag=input∩DOM.id.substrings
∈{″password″}
⟹password(DOM)istrue
其中,{″password″}代表的是“密码”主题下特征词的集合.
第2步,对相应主题的网页元素赋值:
password(DOM)istrue⟹DOM.value=″Pwd123″
若从{″password″}集合中选出一个元素″password″,则这种网页元素定位方式等同于XPath定位器:
“//input[contains(@id,′password′)]”
除了字符串匹配方法还可以通过id直接定位来实现对输入框的赋值,如对id属性值为″userpassword″的网页元素实现相应操作:
DOM.tag=input∩DOM.id=″userpassword″
⟹DOM.value=″Pwd123″
这种网页元素定位方式等同于XPath定位器:
“//input[@id=′userpassword′]”
提取字符串匹配方法相对于直接通过id定位,增强了网页元素定位的鲁棒性,减少了对网页元素id属性具体属性值的关注,提高了生成和修改测试用例的效率.
本文提出的基于主题判定的网页元素XPath定位器生成方法实现该操作的步骤如下:
首先,确定待测网页元素中有哪些主题,并通过本文所述方法确定这些待测网页元素的主题.
其次,对相应主题的网页元素赋值:
DOM.topic=password⟹DOM.value=″Pwd123″
字符串匹配方法中主要依靠网页元素的单一属性值来判断网页元素的主题,往往会出现一个待测网页元素对应多个主题或不属于任何主题的现象.例如,网页元素id属性值为“usernamereg-lastName”,按照字符串匹配方法,该网页元素至少将对应两个主题,分别是“用户名”和“姓”.在实验1中,我们约定当id属性值对应多个主题时,将该网页元素按照“用户名”、“密码”、“邮箱”、“名”、“姓”的顺序,对应的最后一个主题作为它的主题.同样,为了避免非待测网页元素的影响,实验1中,本文所提方法中待测网页元素的主题确定时,仅当网页元素属于对应概率最高的主题的概率大于0.31时,才认为该网页元素属于这一主题.实验1结果如表1所示.
表1 实验1结果
Table 1 Result of Exp.1

方法是否可定位是否确定主题主题正确性数量比例基于主题的网页元素定位方法 可定位的 确定主题 主题正确97.3%主题错误1.1%未确定主题-1.6%字符串匹配方法可定位的 确定主题 主题正确74.2%主题错误1.5%未确定主题-3.1%不可定位的--21.2%
本文通过对不同规模(120、260、390、580个网页元素)的测试样本进行实验得到的结果均如图3所示.其中,非待测网
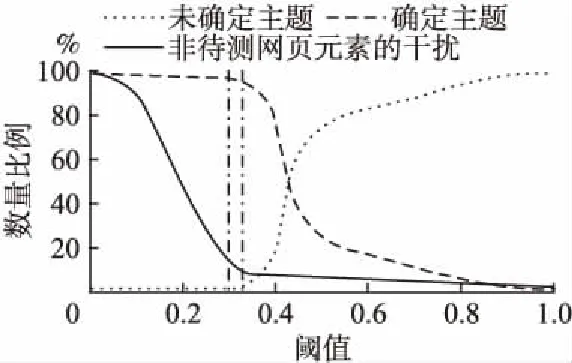
图3 阈值选择的影响Fig.3 Influence of threshold selection
页元素的干扰是指非待测网页元素有对应主题的占非待测网页元素总体数量的比重.当阈值较小时,非待测网页元素影响较为明显.但是当阈值超过某一特定值时,非待测网页元素影响较小但是将影响网页元素主题的确定.本文发现所提方法的阈值一般设置在区间[0.30-0.33]中时表现良好,故本文实验部分选取阈值为0.31.
5.3 网页元素定位器的鲁棒性
常用的网页元素定位主要是通过网页元素属性值定位,XPath定位器实现的,通过id、name等属性值来定位网页元素准确高效,但是在实际中,让开发人员为每一个网页元素都添加id或者name属性并不现实.如果没有id或者name属性对应的定位方法就无法定位到相应的网页元素,更无法生成,而XPath定位器几乎可以定位到所有网页元素.因此,XPath定位器成为自动生成网页元素定位器方法的最好选择.
目前,广泛用于Web测试中的Selenium IDE可以通过模拟用户操作,录制并回放产生测试用例脚本,但是这样生成的脚本,其稳定性和可靠性有限,往往会导致失效,需要测试人员进行修正才能使得其可以正常运行,而其中73.62%的失效是由于网页元素定位器失效[2].另外,通过SeleniumIDE生成的脚本部分是通过XPath定位器进行网页元素定位的,在回归测试中,网页元素或者网页结构的细微变化就可能会导致测试失败,这时就需要测试人员对脚本进行修复或者重新生成.因此,提高网页元素定位器在回归测试中的鲁棒性成为了关键.
在图2中版本(2)较版本(1)而言,既存在网页结构变化也存在网页元素属性值变化.在回归测试中,网页元素XPath定位器往往在三种场景下失效:a)网页结构变化;b)网页元素属性值变化;c)网页结构与网页元素属性值同时变化.本文所设计的这一Web应用的两个版本中囊括了这三种场景,场景(a)对应姓输入框的变化;场景(b)对应用户名输入框的变化;场景(c)对应电子邮箱输入框的变化.实验2结果如表2所示.
5.4 实验数据分析
根据试验结果,可以逐一回答前文所提的Q1-Q3问题.
Q1:网页元素定位能力方面,从表1中可见,相对于字符串匹配方法,本文所提方法使得可定位的网页元素增加了21.2%,网页元素主题确定正确率提高了23.1%.使用字符串匹配方法,如果网页元素中不包含id属性,则无法进行字符串匹配,更无法采用网页元素的id属性来进行网页元素定位.这是导致字符串匹配方法无法定位部分网页元素的原因.
在实验1中,出现了对部分非待测网页元素主题确定的错误,这会使得Web测试出现错误.为减小由于非待测网页元素主题确定的错误而导致Web测试错误,实验1设置了主题确定概率阈值为0.31,但是在极小部分Web测试中由于非待测网页元素主题确定的错误而导致的Web测试错误依旧存在.
另外,对于待测网页元素的类型是按钮时,本文提出的网页元素定位存在一定难度,虽然能够较好地确定该网页元素的主题,但是许多网页存在多个同主题的按钮,无法辨别所要点击的按钮.这些困难也存在于字符串匹配方法中.因此,本文所提方法目前对按钮类的待测网页元素还有待改进.
在文献[7]中提出通过语义相关性来判断网页元素主题的方法,在一定程度上提高了对网页元素主题确定的正确率,也有助于网页元素的定位,但是从网页元素的type、id、name、maxlength等属性中直接提取到的属性值作为特征词,往往不具备相应的语义.
基于主题判定的网页元素XPath定位器生成方法改进了基于网页元素单一属性来判断主题的方法,综合考虑了网页元素中与主题相关的多个属性,来进行网页元素主题的确定,摈弃了基于单一属性进行网页元素定位的策略,提出了根据网页元素自动生成XPath定位器的方法.实验表明本文所提方法增强了网页元素的定位能力.
表2 实验2结果
Table 2 Result of Exp.2

场景方法类型版本(1)版本(2)有效性正确性aFirePath Abs绝对/html/body/table/tbody/tr[3]/td[2]/input/html/body/table/tbody/tr[3]/td[2]/input有效错误FirePath Rel相对//∗[@id=′Registration′]/tbody/tr[3]/td[2]/input//∗[@id=′Registration′]/tbody/tr[3]/td[2]/input有效错误Selenium IDE相对//input[@name=′Last Name′]//input[@name=′Last Name′]有效正确Montoto[12]相对//input[@name=′Last Name′]//input[@name=′Last Name′]有效正确Robula+[10]相对//∗[contains(@name,′Last Name′)]//∗[contains(@name,′Last Name′)]有效正确本文所提方法绝对/html/body/table[1]/tr[3]/td[2]/input[1]/html/body/table[1]/tr[4]/td[2]/input[1]有效正确bFirePath Abs绝对/html/body/table/tbody/tr[1]/td[2]/input/html/body/table/tbody/tr[1]/td[2]/input有效正确FirePath Rel相对//∗[@id=′Registration′]/tbody/tr[1]/td[2]/input//∗[@id=′Registration′]/tbody/tr[1]/td[2]/input有效正确Selenium IDE相对//input[@name=′User Name′]//input[@name=′User Name′]无效Montoto[12]相对//input[@name=′User Name′]//input[@name=′User Name′]无效Robula+[10]相对//∗[contains(@name,′User Name′)]//∗[contains(@name,′User Name′)]无效本文所提方法绝对/html/body/table[1]/tr[1]/td[2]/input[1]/html/body/table[1]/tr[1]/td[2]/input[1]有效正确cFirePath Abs绝对/html/body/table/tbody/tr[4]/td[2]/input/html/body/table/tbody/tr[4]/td[2]/input有效错误FirePath Rel相对//∗[@id=′Registration′]/tbody/tr[4]/td[2]/input//∗[@id=′Registration′]/tbody/tr[4]/td[2]/input有效错误Selenium IDE相对//input[@name=′Email′]//input[@name=′Email′]无效Montoto[12]相对//input[@name=′Email′]//input[@name=′Email′]无效Robula+[10]相对//∗[contains(@name,′Email′)]//∗[contains(@name,′Email′)]无效本文所提方法绝对/html/body/table[1]/tr[4]/td[2]/input[1]/html/body/table[1]/tr[5]/td[2]/input[1]有效正确
Q2:在表2中,有效性指XPath定位器指向的目标是否存在,而正确性是指XPath定位器指向的目标是否正确.
从表2中可见,就网页元素定位器的鲁棒性方面而言,在文献[8]中提到的5种生成XPath定位器的方法在实验2的场景(c)中都失效了,而本文提出的基于主题判定的网页元素XPath定位器生成方法所自动生成的XPath定位器,却能在回归测试中自动生成有效并且正确的XPath定位器.在场景(a)和场景(b)中,本文所提方法依然表现良好,而其他方法在场景(a)或场景(b)可能会出现失效或错误.实验表明,在回归测试中本文所提方法对网页元素定位的鲁棒性得到提高.
在文献[9]和文献[10]中提出的方法增强了XPath定位器在一些场景下的鲁棒性,但是XPath定位器在回归测试中始终是固定的,这使得XPath定位器依旧脆弱.
Q3:测试效率提高方面,在实验1中,在已有主题词库情况下,由于测试人员仅需提供主题集合即可生成网页元素定位器,测试变得更加简单,即使不是专业测试人员,也能对照测试用例,进行相应的Web自动化测试.而在实验2中,简单Web应用的回归测试时,由于待测网页元素的定位依靠自动生成的XPath定位器,所以仅需将“密码”主题添加到主题集合中即可,避免了人工重新生成定位器的工作.相较于修复网页元素定位器和重新修改测试脚本,本方法节省了较多时间.本方法在主题词库确定后可以较大程度的提高测试效率,但是方法在网页元素样本收集和主题关键词选择上比较耗时,这是需要改进的.另外,对部分主题难以收集到足够网页元素样本的Web测试,由于主题确定的准确率不高,难以直接使用本方法进行网页元素定位,这种情况下本方法需要结合手动生成的网页元素定位器进行Web测试.实验表明,基于主题判定的网页元素XPath定位器生成方法能在一定程度上提高Web测试的效率.
6 总 结
基于主题判定的网页元素XPath定位器生成方法通过确定待测网页元素的主题,并根据网页元素自动生成对应的XPath绝对路径,实现对网页元素的定位,能够在一定程度上提高测试效率.未来研究的方向是应用机器学习相关算法,通过语义分析来实现网页元素主题的确定;通过动态推导Web状态流程图,实现动态Web应用的网页元素XPath定位器自动生成,进一步提高Web测试效率.
