基于LSTM的PM2.5浓度预测模型
2019-03-19,,,,
,,,,
(北京工商大学 计算机与信息工程学院,北京 100048)
0 引言
随着近几年雾霾天气在全国范围内的频繁出现,细微颗粒物(Fine Particulate Matter, PM2.5)受到了公众的广泛关注。PM2.5通常指环境空气中空气动力学当量直径小于等于 2.5 微米的颗粒物。PM2.5能较长时间悬浮于空气中,其在空气中含量浓度越高,代表空气污染越严重。与较粗的环境空气颗粒物相比,PM2.5粒径小,活性强,极易附带有毒、有害物质(例如,重金属、微生物等),且在大气中的停留时间长、输送距离远,因而对人体健康和大气环境质量的影响更大。如何有效的对空气PM2.5浓度进行准确的预测和预报,对于保护公众身体健康,环境治理具有重要的意义。由于PM2.5浓度受到多方面因素的影响,呈现出明显的不规则和不确定性波动,很难对其进行有效的数学建模。
近年来深度学习技术[1]在人工智能领域取得显著成就。深度神经网络可以对数据抽象特征进行提取,并且拥有强大的对高维数据进拟合的能力,可以有效地根据PM2.5历史数据,构建预测模型。本文基于深度学习中LSTM[2](Long Short-Term Memory)循环神经网络,依据过去20小时采集的空气数据,预测未来5个小时PM2.5浓度指数。实验数据表明本文提出的算法模型达到了良好的效果,可以有效的预测出未来5小时内空气中PM2.5浓度值。
1 相关工作
最近几年,学术界对PM2.5浓度预测进行了也许多研究。文献[3]基于非线性回归模型建立预测模型,并设计出一个基于逆风PM2.5浓度的附加参数,用于增强预测模型的表现,取得了良好的效果。文献[4]首次提出了一种基于数据预处理和分析的混合EEMD-GRNN(集合经验模态分解 - 通用回归神经网络)模型,用于提前一天预测PM2.5浓度。文献[5]提出优化神经网络的大气PM2.5污染指数预测方法,利用主成分分析法对大气PM2.5污染指数的各种影响因素进行分析,保留影响因素的主要特征成分,并作为神经网络的训练样本,利用遗传算法进行BP神经网络结构参数的寻优,并利用最优参数构建BP神经网络的预测模型,获得准确地预测结果。文献[6]使用贝叶斯kriged卡尔曼滤波模型对PM2.5时空过程进行短期预测,利用Kriging方法建立模型的空间预测并使用马尔可夫链蒙特卡罗技术实现,在时间和空间上获得良好的预测效果。文献[7]提出了一种基于地理的模型,使用MLP提前三天预测SO2,CO和PM10的日平均浓度,其采用了3种地理模型:单站点邻域模型,双站点邻域模型和基于距离的模型。实验结果表明,基于地理的模型优于普通模型,特别是基于距离的模型。如果在地理模型中增加更多的气象变量,预计仍有很大的改进空间。文献[8]提出了一种新的混合ARIMA-ANN模型,以提高PM10预报精度,取得了较好的预测精度。
尽管之前许多学者在PM2.5和其他空气质量预测算法上取得了不少突破性进展,但是大部分现有算法模型都需要复杂的数据处理和设置外部参数条件,而这一过程需要很强的专业知识,增加了模型的实现复杂程度,同时也降低了其易用性。本文提出的基于LSTM循环神经网络PM2.5预测算法模型,能够有效地根据历史数据预测出未来时刻PM2.5浓度值,同时模型具较低的实现复杂度和开发成本。
2 基于LSTM的PM2.5预测算法
2.1 RNN神经网络
原始的神经网络一般都是全连接网络,而且非相邻的网络之间没有连接,没有办法有效处理不定长的时序数据。RNN(Recurrent Neural Network)是一类用于处理序列数据的神经网络,为了更有效的处理时序数据,RNN将网络的隐藏层相连接,可以理解为多个具有相同结构和参数的前向神经网络的循环堆积。循环的次数和输入序列的长度一致,且要求在序列中毗邻状态的对应网络的隐层之间互联。RNN网络结构示意图如图1所示。
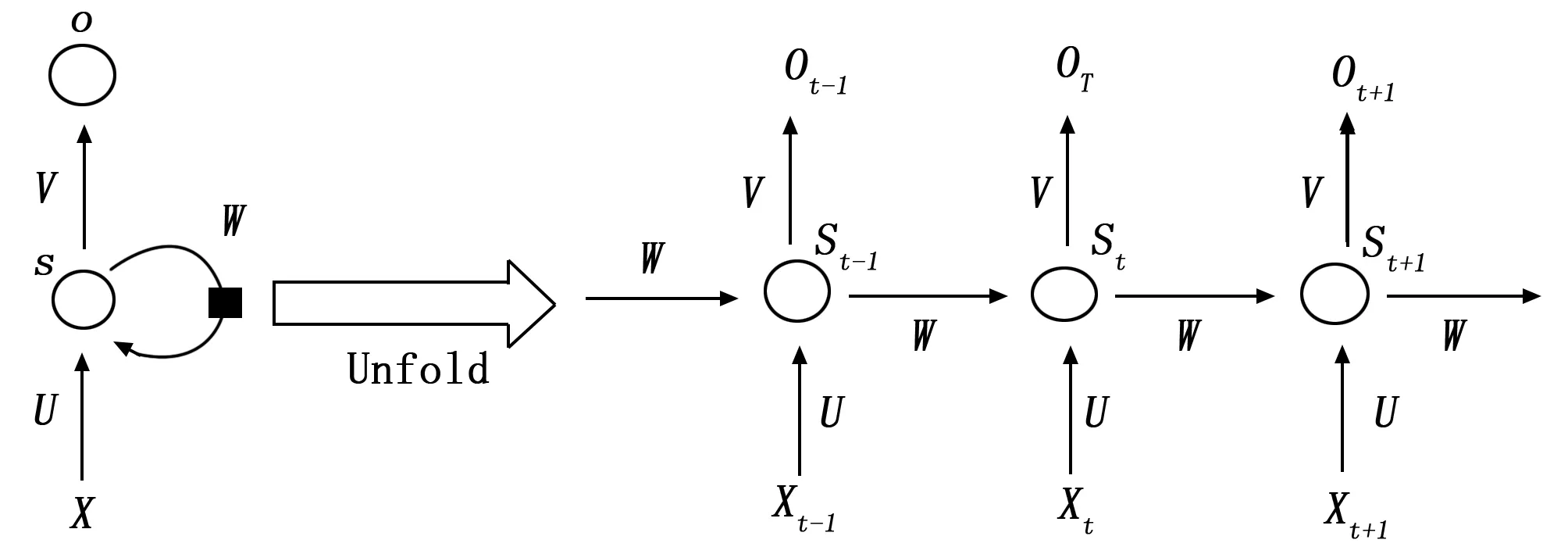
图1 RNN结构图
在RNN中网络每一个时刻除了要接受输入层的参数以外,还要接收自身网络上一时刻隐层输出。RNN的隐层控制着序列数据的信息传递。不同的时刻之前连接的权重代表着过去时刻信息对当前时刻的影响。
RNN网络的输入记为{x0,x1,…xt,x(t+1)…},输出集记为{y0,y1,…yt,y(t+1)…},隐藏层的输出记为{s0,s1,…st,s(t+1)…}。RNN能够处理时序信息隐层单元起了关键作用。数据信息的流向是从输入层到输出层,并跟随隐藏层的状态传递下去。具体计算过程如公式(1)(2)(3)所示。
st=σ(Uxt+Wst-1+bi)
(1)
ot=Vht+bo
(2)
yt=softmax(ot)
(3)
在上式中U,W,V分别是网络输入层,隐藏层,和输出层权重参数,bi和bo分别是输入层偏置和输出层偏置参数,σ是激活函数,一般会选择一般会选择tanh函数。
理论上RNN可以处理任何长度序列数据,但是当处理序列过长时会导致历史时时刻信息的影响削弱甚至消失,称之为梯度消失。对RNN的改进主要是集中在隐层神经网络的结构做优化。如LSTM和GRU[9](Gated Recurrent Unit)在隐层网络中增加了门控制单元,使得网络可以保留住历史时刻比较重要的信息。
2.2 LSTM神经网络
RNN的关键作用是可以依据隐藏层之前的转态传递处理序列问题,即做当前时刻的任务是可以考虑到过去时刻的影响。但是RNN处理较长时序数据时会很难训练,表现极差。LSTM是长短期记忆网络,通过相应的网络结构改变来避免长期依赖问题。在RNN中通过隐藏层连接重复同一个网络模块。LSTM同样延续了与RNN同样的重复连接结构,不同的是在LSTM网络中增加细胞状态ct。ct也会随着不同的时刻传递下去,细胞转态ct代表了长期记忆。LSTM的关键就是细胞状态,在整个序列的运算过程中只有少量的线性交互,所以可以有效保存过去较长时刻的信息。
LSTM的细胞结构如图2所示,当接收到前一个时刻隐藏层输出ht-1和当前时刻输入xt,首先会用遗忘门决定细胞状态丢弃不重要的信息。遗忘门运算如公式(4)所示:
ft=σ(Wxfxt+Whfh(t-1)+Wcfc(t-1)+bf)
(4)
在上式中Wxf,Whf,Wcf,bf代表遗忘门的网络参数。σ代表sigmoid激活函数,ft是遗忘门输出向量,其中向量中的每一个元素都在(0,1)范围内。代表着当前时刻细胞状态ct中每个元素的重要程度。
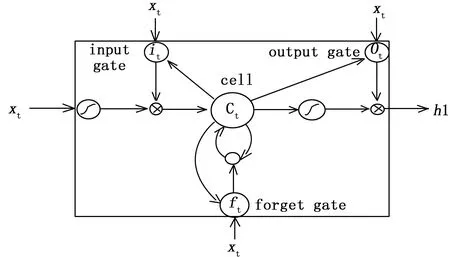
图2 LSTM神经元示意图
LSTM还要确定当前时刻,细胞状态哪些位置的信息需要更新和确定更新后的值。这个决定通过输入门来完成。输入门的运算过程如公式(5)(6)所示:
it=σ(Wxixt+Whiht-1+Wcict-1+bi)
(5)
(6)
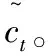
当遗忘门和输入门运算完成,LSTM会更新当前时刻的细胞状态,更新细胞状态的计算过程如公式(7)所示:
ct=ftc(t-1)+itct
(7)
式中,ft是遗忘门的输出,代表着哪些信息需要遗忘,哪些信息需要保留。
LSTM最后会计算当前需要确定什么样的信息需要输出,这个任务主要靠输出门根据当前的细胞状态ct来完成。公式(8)计算确定哪些部分的细胞状态需要输出,公式(9)把细胞状态通过tanh函数处理,得到一个(-1,1)范围的值,并将其和ot相乘得到当前时刻最终的隐藏层输出。
ot=σ(Wxoxt+Whoht-1+bo)
(8)
ht=ottanh(ct)
(9)
式中,Wxo,Who和bo是输出门的参数,ht是当前时刻的隐层输出。
LSTM在RNN的基础上增加了三个门控制,分别是遗忘门,输入门和输出门。遗忘门和输入门负责对细胞状态的ct的更新。在网络中ct会保留住序列数据的重要信息并可以传递较长的时刻,能够有效的缓解长期依赖。LSTM目前已被广泛的应用于序列标注,机器翻译和语音识别等自然语言处理等任务中。
2.3 PM2.5预测模型
本文采用LSTM神经网络实现,算法模型根据当前时刻最近20个小时的历史空气质量观测数据预测未来5个小时PM2.5浓度值。这是个典型的时序预测问题,LSTM能够有效的处理时序数据。算法网络模型的整体结构图如下图3所示。
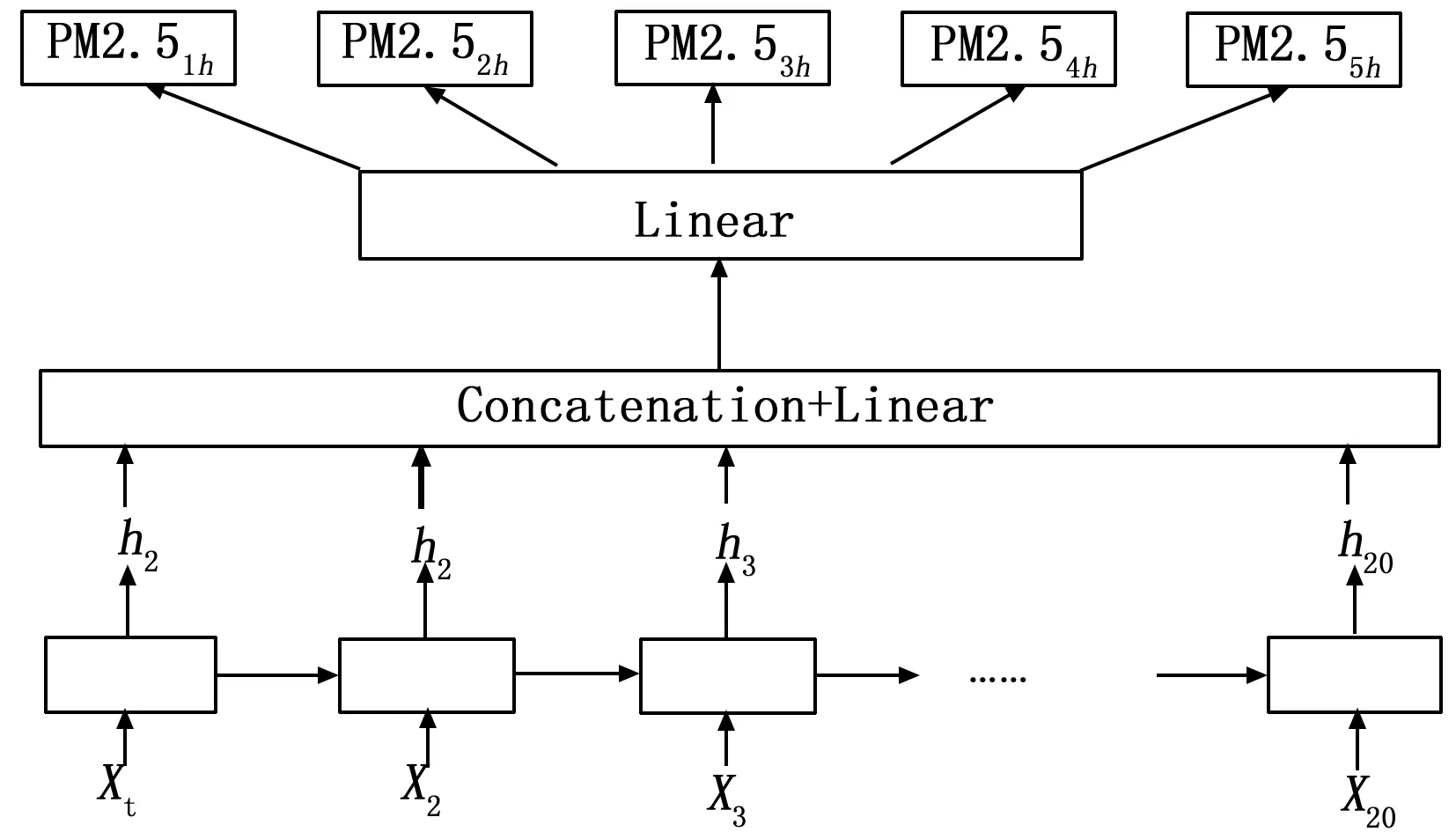
图3 算法模型结构图
在模型中x1,x2…x20代表某个观测地点采集的最近20个小时历史空气数据。h1,h2…h20代表每个时刻输出隐状态向量。对于第时刻输入数据xt={PM2.5, PM2.5_24h, PM10, PM10_24h, AQI}。xt为5维的向量数据,其中PM2.5是t时刻的PM2.5测量值,PM2.5_24h是t时刻PM2.5最近的24小时测量均值,PM10是时刻的PM10测量值,PM10_24h是时刻PM10最近的24小时测量均值。AQI(Air Quality Index)代表时刻的空气污染指数。模型会依据20个小时的历史数据,抽取特征,完成参数的学习,来预测未来5个小时的PM2.5浓度值。
模型输入为最近20个小时历史的测量数据x1,x2…x20,然后根据公式(4)(5)(6)(7)(8)(9)所述得到h1,h2…h20输出隐状态向量,经过公式(10)合并,得到编码向量。
h=Concat(h1,h(2)…h20)
(10)
m=σ(Whmh+bhm)
(11)
PM2.5o=Wmom+bmo
(12)
公式(10)中代表对向量首位相连拼接合并,完成对历史时刻数据的编码。根据公式(11)对向量h经过一次全连接层线性变化得到模型最终的特征向量m,此时向量m就是模型对历史数据抽取的抽象特征。在公式(11)中W_hm和b_hm代表全连接层的权重和偏置。在输出层中,如公式(12)所示,模型会会根据特征向量预测出未来时刻的PM2.5,用PM2.5o表示。PM2.5o是一个5维的实数向量,包含预测出的未来5个小时的输出值PM2.51h,PM2.52h,PM2.53h,PM2.54h,PM2.55h。
模型的训练阶段采用均方误差MSE作为的损失函数,具体计算过程如公式(13)所示:
(13)
式中,N代表样本的总数,j代表未来第小时,PM2.5j代表第j小时的预测值,yj代表第j小时的真实值。梯度优化过程中使用Adagrad[10]策略进行参数更新,初始的学习率设置为0.01。
算法模型的完整训练过程如算法1所述。
算法1:基于LSTM的PM2.5预测算法
1: 初始化LSTM神经网络参数,(公式(4)(5)(6)(7)(8)(9)中的W和b)
2: 初始化全连接层网络参数,Whm和bhm
3: 初始化输出层网络参数Wmo和bmo
1: 定义M为训练集总共batch数
2: for each iteration i=1,2,…,Mdo
3: 采样一个batch的训练样本序列x,y
4: 根据公式(4)-(9)得到历史序列隐状态序列h1,h2,… ,h20
5: 根据公式(10)串联合并h1,h2,… ,h20
6: 根据公式(11)(12)得到预测结果PM2.51h,PM2.52h...PM2.55h
7: 根据公式(13)计算模型损失
8: 计算网络所有参数值的梯度
9: 更新参数值
10: end for
3 实验结果与分析
3.1 数据集
本文选择网络公开的北京空气质量数据作为实验评测数据,数据包含2014年1月1日到2014年12月31日北京市内35个数据收集地点每小时的采集数据。实验按照25个小时大小的滑动窗口切分数据,取前20个小时数据作为模型输入数据,后5个小时的数据作为预测数据,生成样本对数据集。在样本对数据集中,本文随机选择20%作为测试数据,剩下的80%作为训练数据。舍弃含有空值和异常数据样本,共搜集得到517 476条训练样本,129 370条测试样本。
3.2 实验结果
本实验环境主要参数CPU:Intel(R) Core(TM) i7-6800K CPU @ 3.40GHz,GPU显卡:1 080 ti4,内存为32 GB,操作系统为Ubuntu 16.04 64 bit。实验设置训练迭代epochs为100,LSTM隐状态维度为128维,损失函数选择回归预测常用的MSE均方误差,batch size设置为64。迭代完成100次训练,模型训练学习曲线如图4所示。
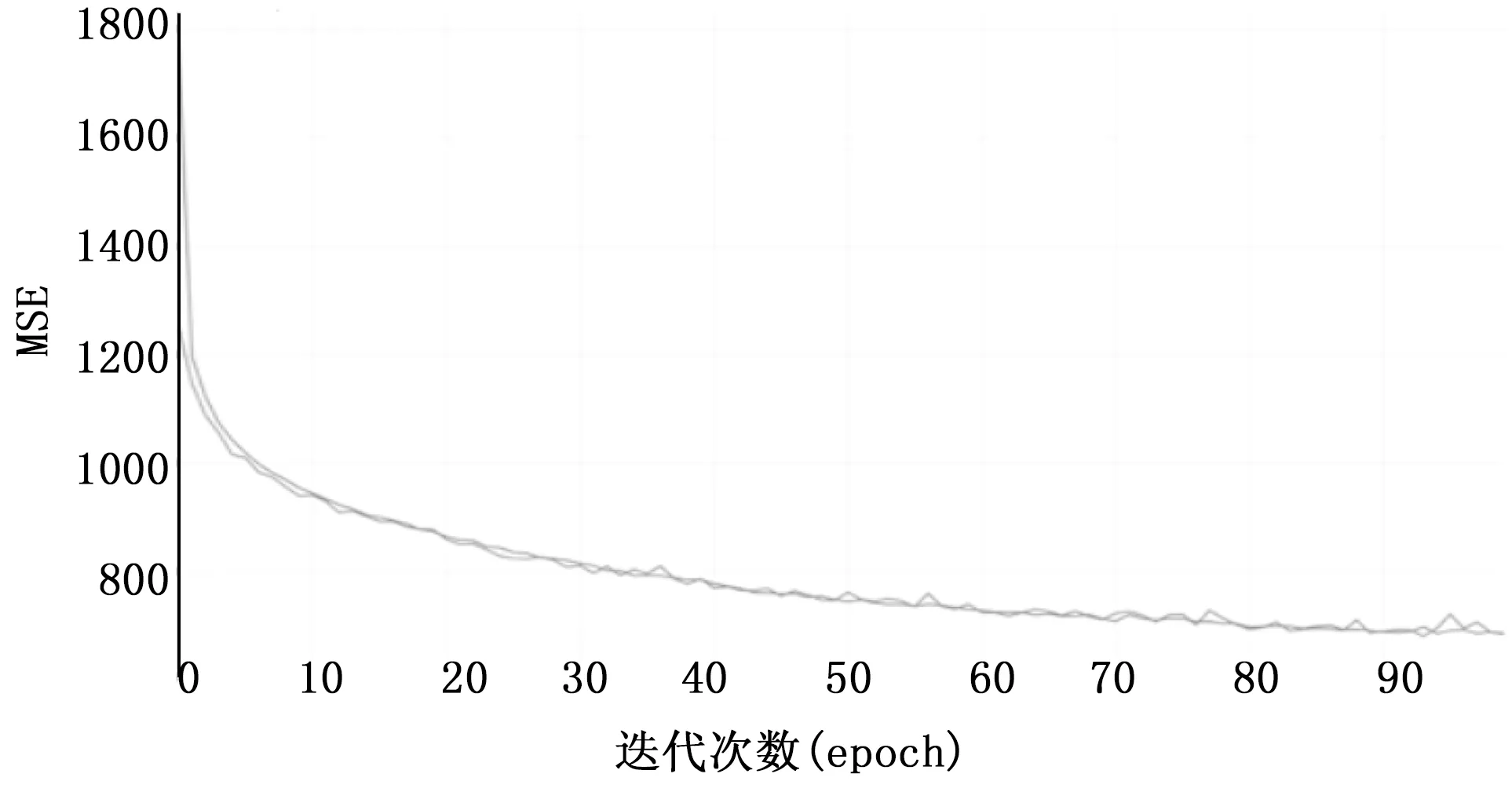
图4 模型训练学习曲线
由图可知,随着迭代次数的增加,训练误差和测试误差都下降很快。当到迭代次数(epoch)达到100时,测试误差和训练误差明显有分叉的迹象,为避免模型发生过拟合,本文选择到迭代次数到100次停止继续训练。可以看出来,测试集误差不断下降,说明算法模型学到了数据的真实分布和潜在规律。
为验证所提出算法的有效性,文本选取了3种机器学习算法作为对比参考,分别是ARIMA[11],SVM[12]和GBDT[13]。对比实验各个算法根据给定大小的训练数据集训练模型,在同样的测试集上得到测试结果,以MSE和准确率做为评价标准。准确率以不同的相对误差作为条件,给定最近20个小时的历史观测数据预测未来5个小时的PM2.5浓度。误差实验结果如表1所示。
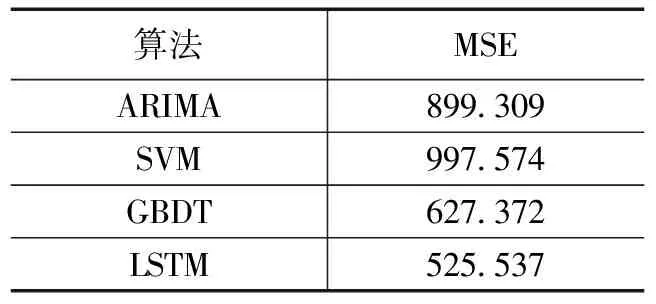
表1 MSE(均方误差)实验结果表
在实验结果中LSTM取得了最小的均方误差,在误差评价指标上表现出较好的预测能力。准确率实验结果如表2所示,在实验过程中分别考虑了相对误差在0.1,0.2和0.3的范围内,对比不同算法取得的准确率,LSTM同样取得了最好的预测效果,在准确率上表现出良好的时序列预测能力。
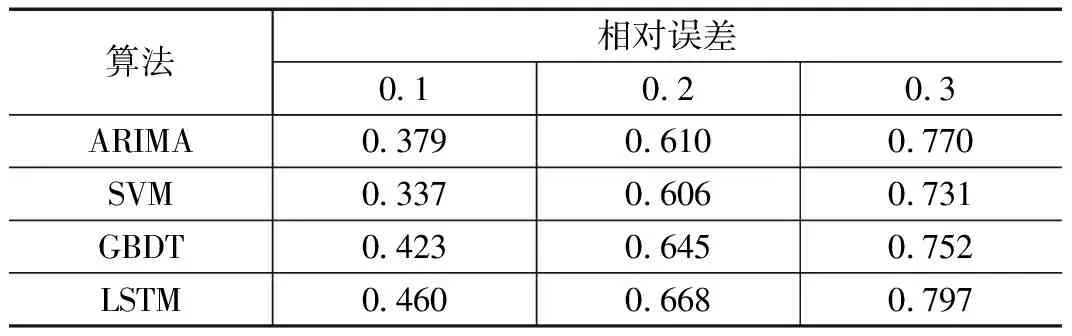
表2 准确率实验结果表
为验证本算法模型稳定性和实用性,本文选取测试数据中三个不同数据采样地点并随机采样20天数据作为时间轴对比不同的算法预测效果,实验结果如图5、图6和图7所示。从三个采样地点预测值与真实值对比来看,LSTM预测值与真实值的拟合更加好,没有出现较大的明显偏差。在图5、图6和图7中,ARIMA,SVM和GBDT三个对比预测算法均出现了在序列拐点处的滞后性,与真实值有较大的偏差,说明三个预测算法,直接用历史数据作为特征或者对历史数据的简单处理作为特征,并不能表现出其更深层次的序列规律。LSMT也表现出神经网络特有的优势,通过多种非线性运算能够对高维数据抽取抽象和深层的特征,展现出比较好的预测和拟合效果。通多对同一种算法在不相同采样地点的横向对比,发现本文提出的LSTM预测算法具有更好的稳定性。如对比SVM算法分别在图5、图6和图7中的表现,可以看到SVM在图7中的拟合效果要比图5和图6中的效果差很多,而LSTM算法在三个图中均表现出了不错的效果,没有根据不同采样地点数据的变化而受到很大的影响。
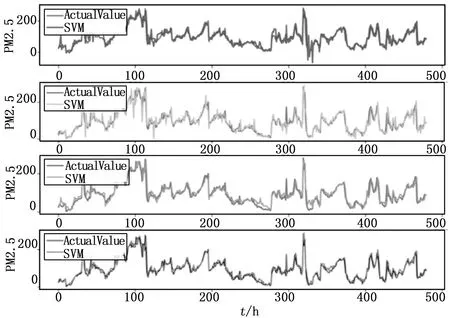
图5 算法预测对比图(前门观测点数据)
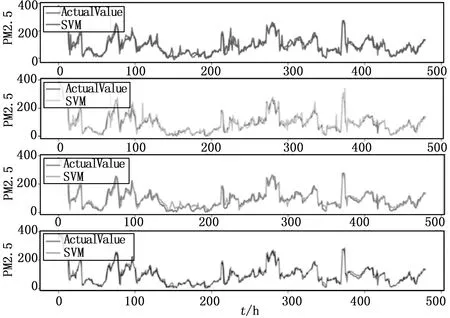
图6 算法预测对比图(天坛观测点数据)
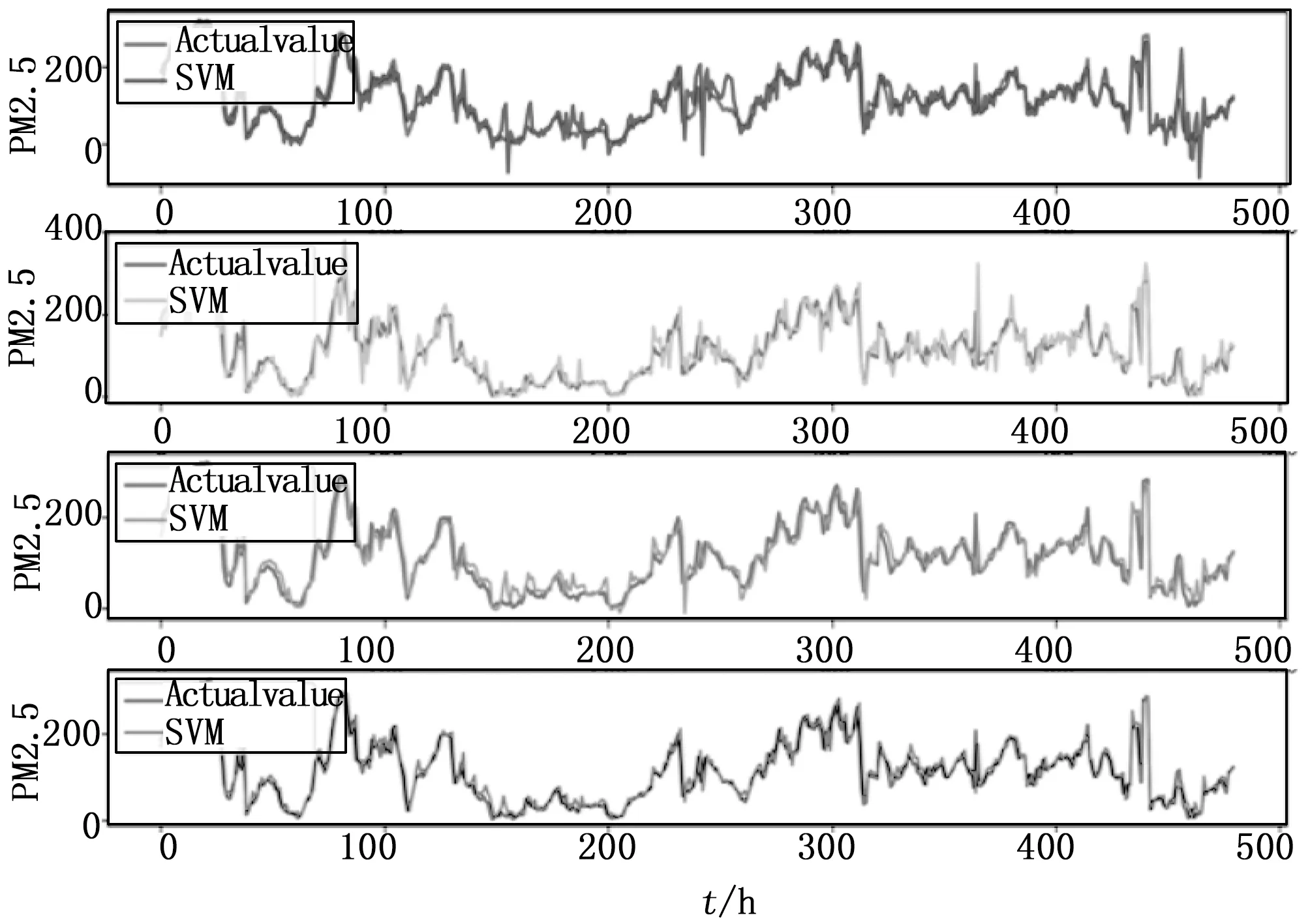
图7 算法预测对比图(通州观测点数据)
4 结束语
文本提出了基于深度学习LSTM循环神经网络的PM2.5预测算法,算法模型不需要对数据进行复杂的专业处理,LSTM可以抽取数据的时序特征,对未来时刻PM2.5进行有效的回归预测。实验结果也表明,本文提出的预测模型得到了良好的预测效果,可以依据某个为位置的最近20小时历史测量数据,对未来5个小时的PM2.5值进行有效的预测。未来研究工作中可以对PM2.5浓度变化规律和机理进行深入的分析研究,结合更多的理论基础对PM2.5进行更加精准的长时间段预测。
