基于偏序拓扑图的帕金森病语音障碍分析方法
2019-03-18蒋培培张晓娟
张 涛 蒋培培 李 林 张晓娟
1(燕山大学信息科学与工程学院,河北 秦皇岛 066004)2(开滦精神卫生中心, 河北 唐山 063001)
引言
帕金森病(Parkinson′s disease, PD)是人类常见的神经退行性疾病之一,目前该病的平均发病年龄是55岁,且发病率随着年龄的增长而升高[1]。在45岁和65岁以上人群中,帕金森病的发病率分别为0.4%和1.7%。预计到2030年,全球大约将有3 000万帕金森病人,其中中国大约有1 500万人。
帕金森病的病因尚未完全明确[2],目前所有针对帕金森病的治疗都是控制病情的发展,而无法从根本上治愈。因此,帕金森病的早期诊断无论对于家庭还是社会均具有重大意义。在帕金森病的各种早期表现中,语音障碍为典型症状之一,大约90%的帕金森病人会出现某种程度的语音障碍[3],且语音采集可通过电话等多种方式进行远距离传输,易于实现远程诊断。这使得基于语音障碍检测的帕金森病诊断方法得到了极大的关注。
2007年开始,牛津大学的Little等对此进行了一系列的研究[4-5],并利用模式识别方法对基于语音障碍的帕金森病诊断进行了分析,奠定了模式识别方法在语音障碍的帕金森病机器诊断中应用的理论基础。当前信息处理领域的帕金森病语音障碍研究主要集中在数据采集、特征选择和分类诊断等3个方面。
2007年,Little在信息采集上建立了第一个帕金森病语音障碍数据集OPDD(Oxford Parkinson′s Disease Dataset)[4];2010年,通过电话进行信号采集的远程帕金森病数据集PTDS(Parkinsons Telemonitoring Data Set)成型[5]。2013年,Betul提出集成元音、单词与句子的多类型测试方法[6];2016年,Orozcoarroyave在研究中发现英文发音进行检测的局限性,提出针对西班牙语、德语和捷克语的采集方法[7]等。张涛提出了元音分类度的帕金森病语音采集方法[8],确立了更符合中国人发音特点的语音采集方案。
在特征分析与特征提取上,目前主要有Das等使用粗糙集方法进行特征选择[9],以及Frid利用卷积网络的自学习特性进行特征选择[10]。他们通过对特征的分析和提取,降低数据集的维数并形成分类规则,从而降低分类的复杂度,提高分类结果的逻辑性,为帕金森病数据集从分类向知识发现过渡做了有益的尝试。
在分类诊断上,基于不同分类原理的分类器被设计出来用于帕金森病数据集的分类。比如:朴素贝叶斯[11]方法、随机森林方法[12]、支持向量机[5]、神经网络等均被用于语音障碍的帕金森病诊断。除此之外,Ali利用深度置信网络将帕金森病的特征选择与诊断结合起来[13],张涛则利用可视化分析将帕金森病特征选择、特征融合与诊断融为一体[14],为基于语音障碍的帕金森病的发现奠定了理论基础。
以上分类器虽然在分类精度上达到了较高水平,但由于其均以概率或测量模型为基础,难以做到数据的知识性表示。本研究从知识结构的概念分析出发,结合形式概念分析[15-16]中的概念分析方法,提出偏序拓扑图的可视化层次表示方法,并将其用于帕金森病的语音障碍分析,尝试从充要条件的角度,将帕金森病语音障碍分析与诊断进行结合,为在认知计算领域进行帕金森病分析奠定基础。
1 方法
1.1 形式概念分析基础
形式概念分析以形式背景为分析对象,对其进行定义。
定义1:形式背景可以用三元组K:=(G,M,I)表示,其中G表示所有对象的集合,M表示所有属性的集合,I⊆G×M表示对象与属性之间的关系,G×M表示的是集合G与集合M的笛卡尔积。
定义2:如果K:=(G,M,I)是一个形式背景,A⊆G,B⊆M,有
f(A)={m∈M|∀g∈A,(g,m)∈I}
g(B)={g∈G|∀m∈B,(g,m)∈I}
如果A、B满足f(A)=B和g(B)=A,则称二元组(A,B)是形式背景K中的一个概念,并将A称为概念(A,B)的外延,B称为概念(A,B)的内涵。
在形式背景表示方法中,属性拓扑作为一种基于图论的表示方法,在概念可视化、高速概念计算、关联规则分析等方面表现出了独特的优势,其定义[17-19]为
定义3: 属性拓扑。对于二值形式背景K:=(G,M,I),其属性拓扑可以定义为AT=(V,E)。其中,V=M为拓扑的顶点集合,E为拓扑中边的集合,有
(1)
形式背景“急性炎症”[20](acute inflammations,不含temperature of patient与nephritis of renal pelvis origin项)如表1所示,经过净化后[21]对应的属性拓扑图如图1所示。在图1中,由于属性f为决策属性,暂不参与运算。
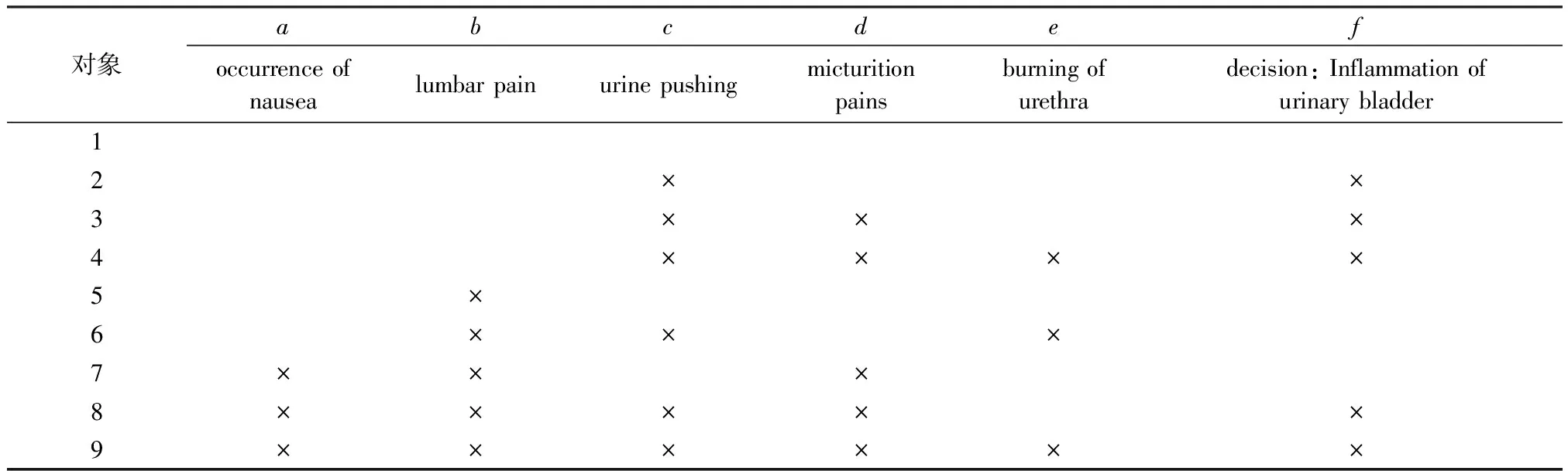
表1 “急性炎症”形式背景Tab.1 Formal context named “Acute Inflammations”
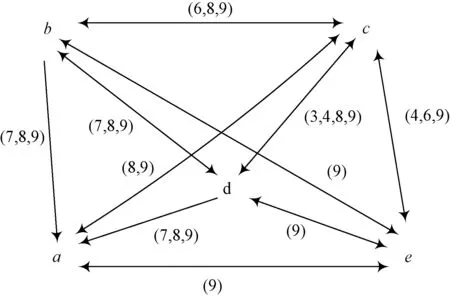
图1 表1形式背景的属性拓扑图Fig.1 Attribute topology of Tab. 1
1.2 偏序拓扑图表示
属性拓扑侧重于形式概念发现的本体论研究,但由于其连接关系中没有层次化概念,在知识结构的可视化表示中缺乏条理性。因此,本研究将属性偏序图与属性拓扑图结合,提出偏序拓扑图(partial order topological graph,POT graph)的形式背景表示方法,在属性拓扑本体分析的基础上突出层次性。
设偏序拓扑图为PT={Vp,Ep},其中Vp={Ψ,V,E},且Ψ′=A,E′=∅。
显然,在形式背景中,有
∀m∈M,Ψ→m
∀m∈M,m→E
式中,符号→表示伴生关系[21]。
由偏序理论可知,Ψ为属性拓扑的上确界,称为拓扑起点;E为属性拓扑的下确界,称为拓扑终点。根据属性拓扑定义,其与其他顶点集合的权值为
从构造角度,起点Ψ和终点E的引入是为了在属性拓扑中引入整体偏序特性,为后期的路径搜索等算法提供明确的开始和结束标记,对知识发现和分类而言不具有实际意义,其加入对于原有的属性拓扑的性质不构成影响。因此,可对起点Ψ和终点E涉及的连接做修正。
设与起点Ψ和终点E直接相连的顶点集合分别用起点集A和终点集B表示。A和B的选择有两种情况,描述如下:
1)不存在伴生属性,即属性拓扑中所有的属性均为顶层属性。令A=M且B=M,即∀mi∈M构造起点到mi的单向出边和mi到终点的单向出边,即属性拓扑的全部属性既可以作为路径的起点,又可以作为路径的终点。
2)存在伴生属性。令A为顶层属性集,B为伴生属性集,即构造起点到各个顶层属性的单向出边和各个伴生属性到终点的单向出边,可保证每一条路径均以某一个顶层属性为起点,以某一个伴生属性为终点。
除了顶点集合外,由偏序理论可知,偏序过程具有传递性,即若存在a→b→c,则有a→c。因此,对于伴生属性,只需保留伴生关系,其他连接均可不再考虑,即对式(1)修正如下:
(2)
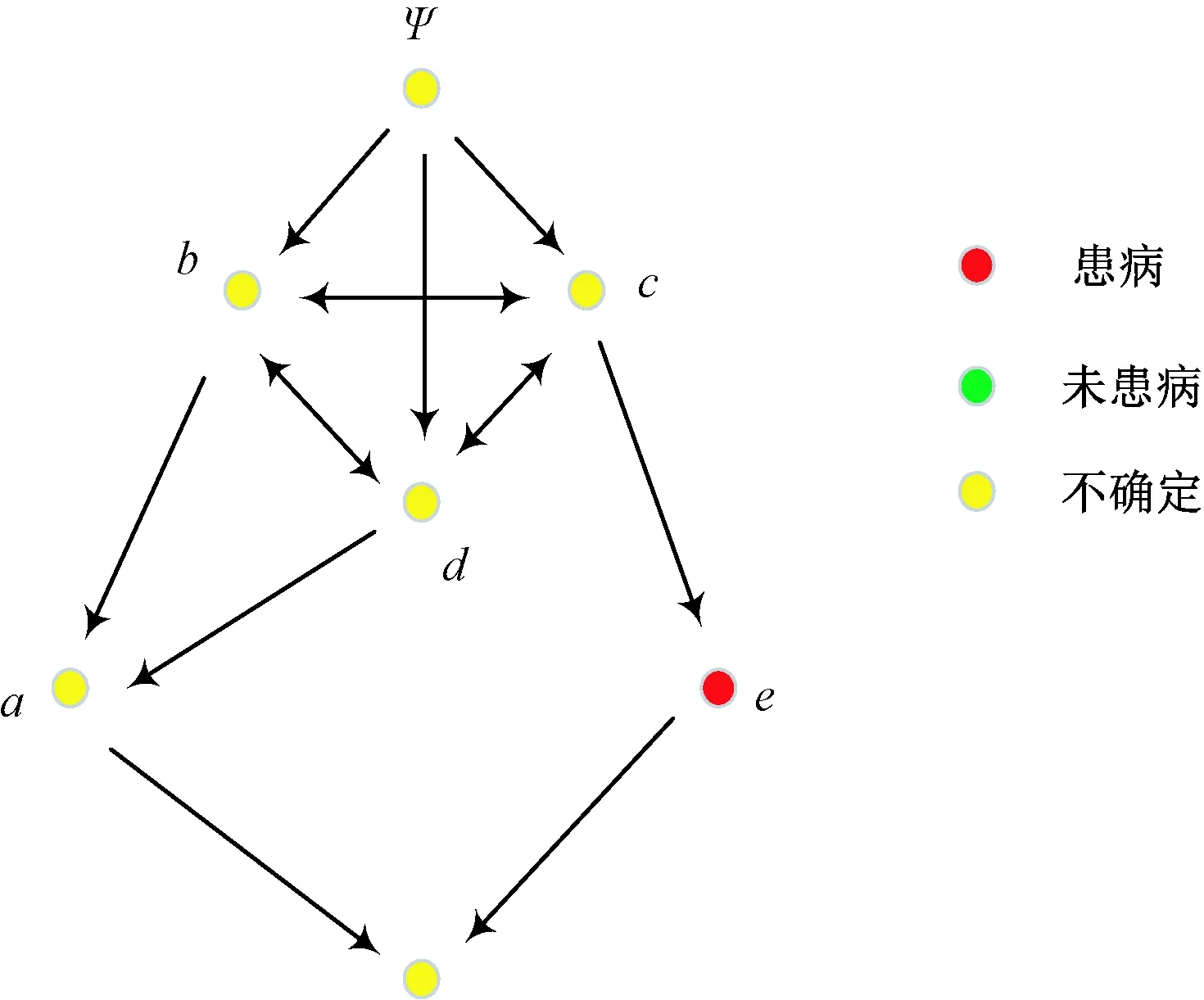
经过偏序化后的属性拓扑为偏序拓扑,其在保留属性拓扑基本结构的同时,强化了属性偏序结构,为将属性拓扑的本体表示和属性偏序的关联表示融合提供了条件。表1形式背景的偏序拓扑表示如图2所示。
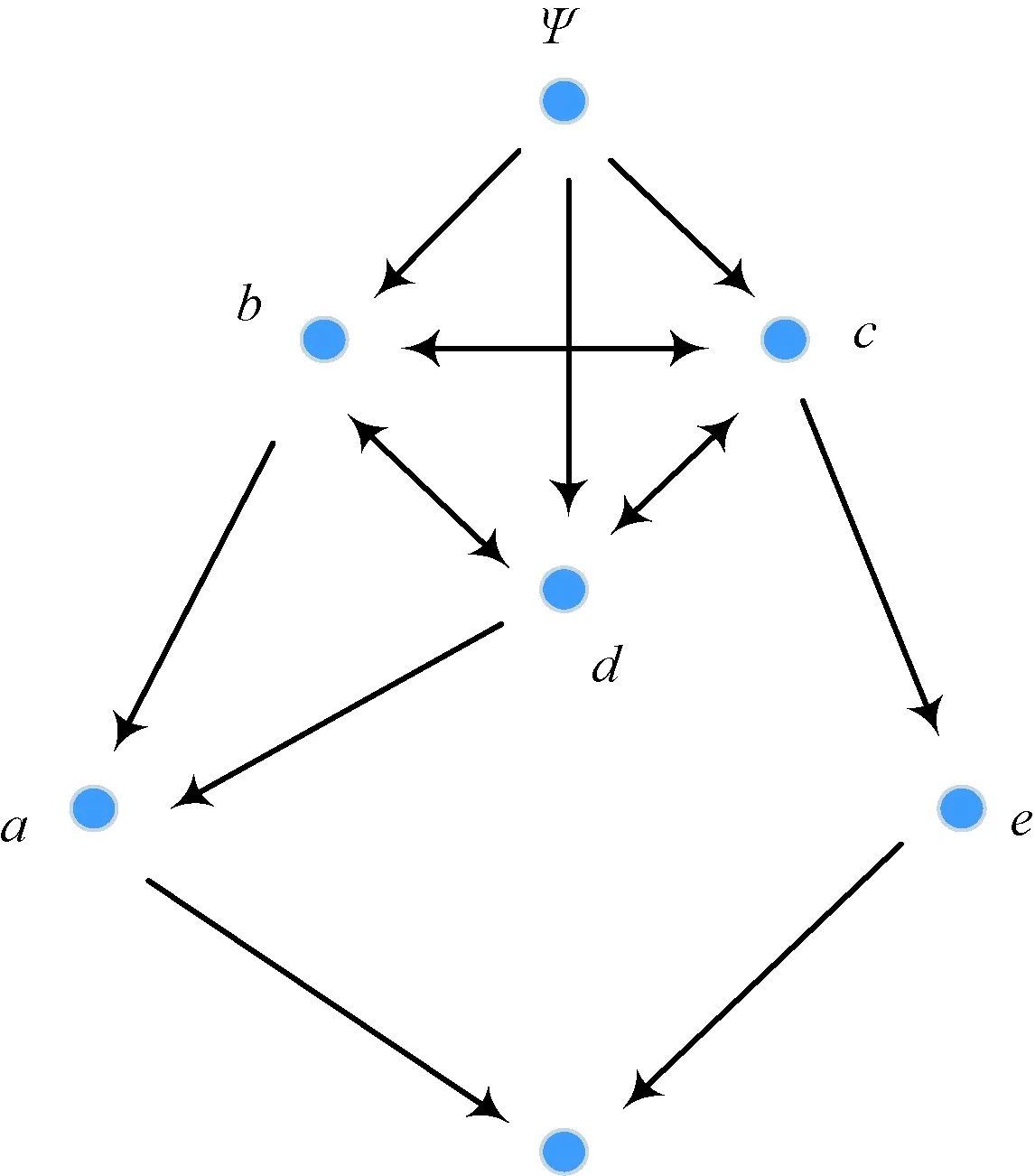
图2 表1形式背景的偏序拓扑表示Fig.2 POT graph of Tab. 1
1.3 偏序拓扑的关联规则与本体发现
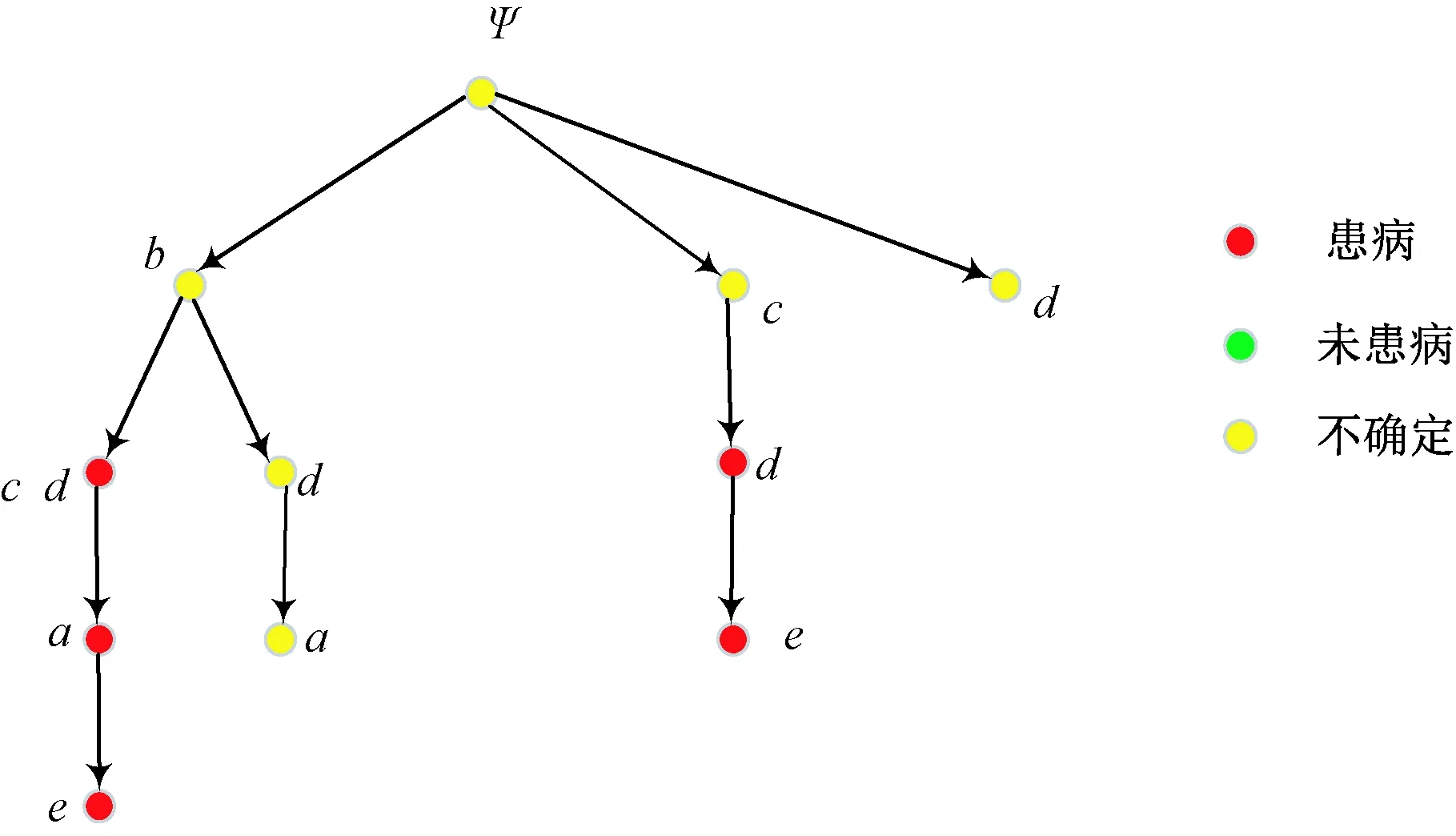
为了提取形式背景的本体,首先需要对偏序拓扑完成形式概念发现。根据属性拓扑理论,在知识发现过程中,偏序拓扑中的顶层属性具有独立成为内涵的能力[17]。对于伴生属性,根据伴生层次可将其分解为多级伴生关系。根据属性偏序理论可知,偏序拓扑中相同层的属性间存在着覆盖能力区分[22],根据覆盖能力可将相同层属性进行排序。在偏序拓扑中,结合其拓扑性与偏序性,设a,b∈M,则其排序规则如下:
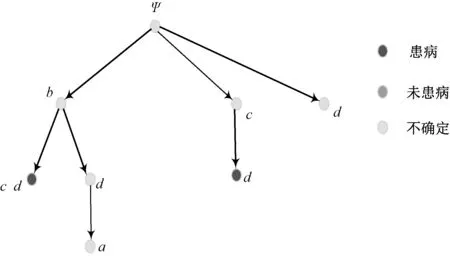
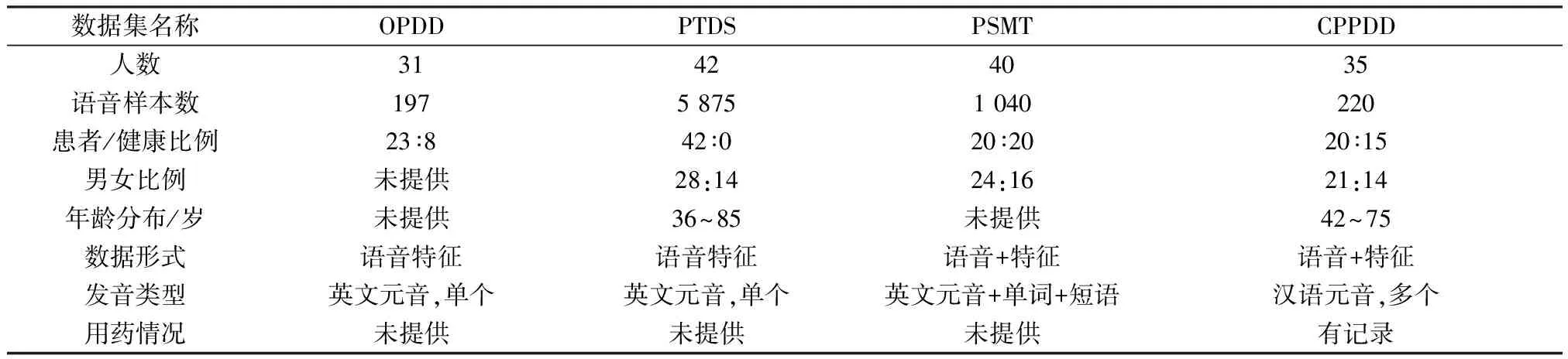
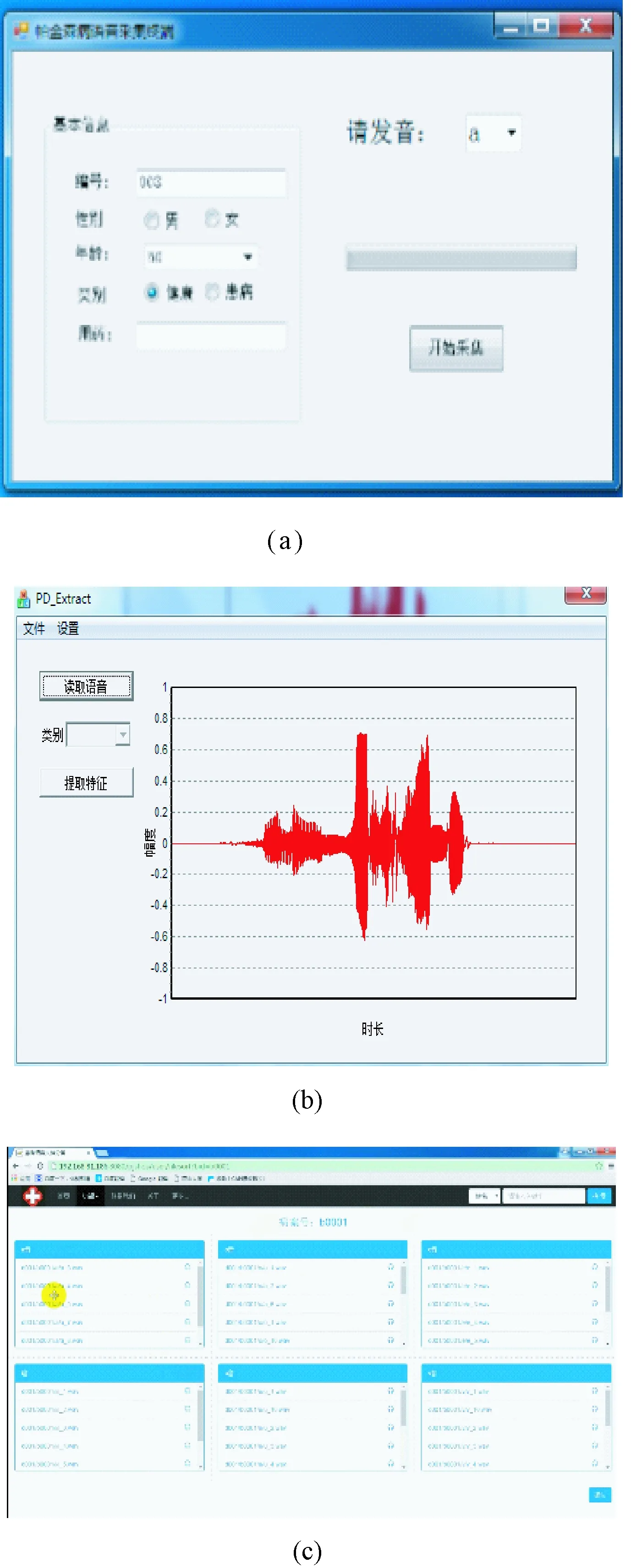
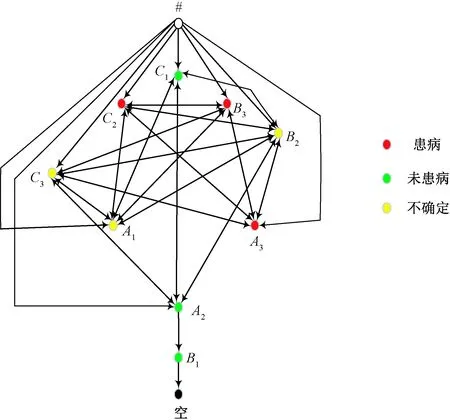
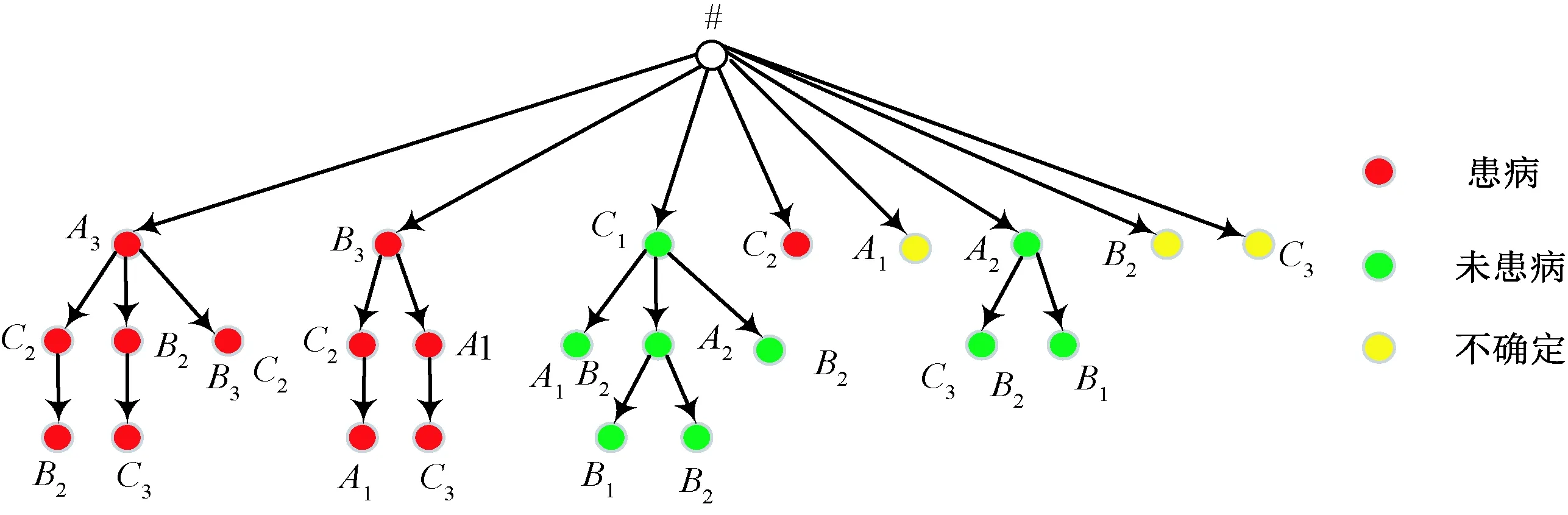
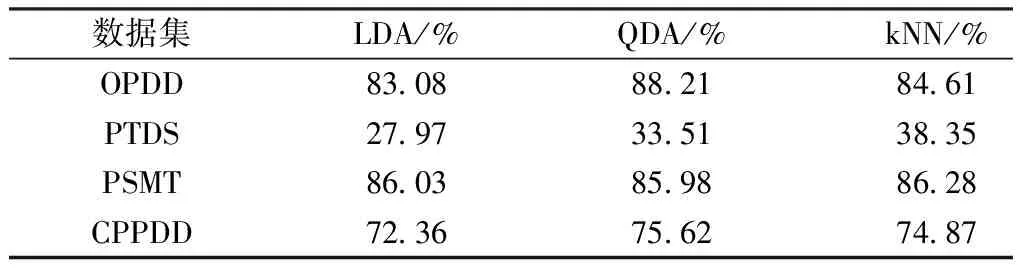
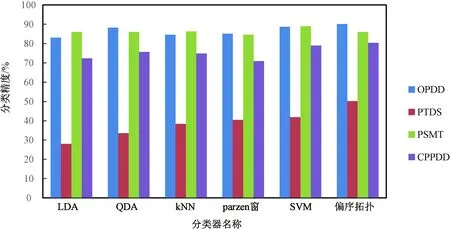
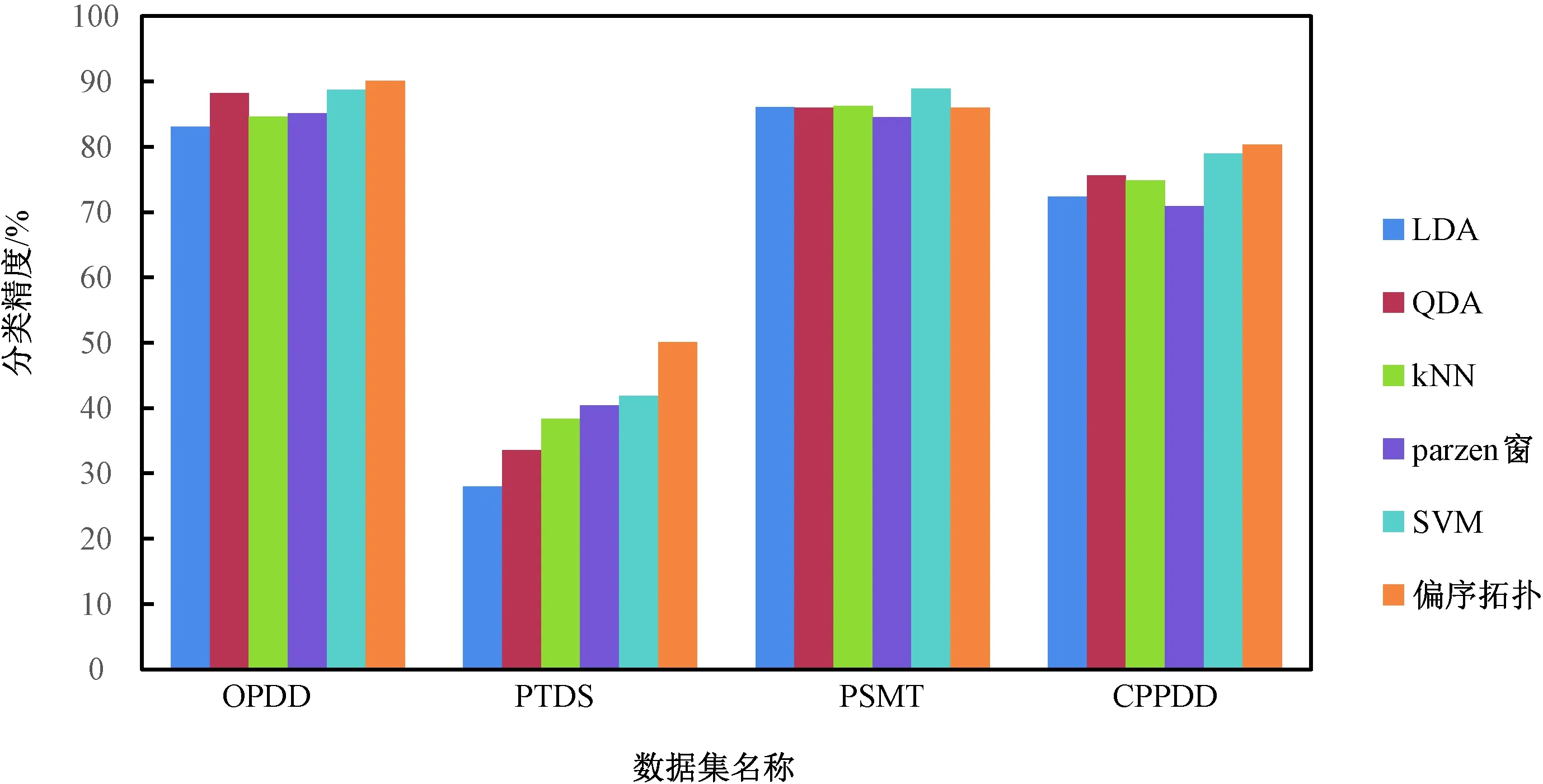
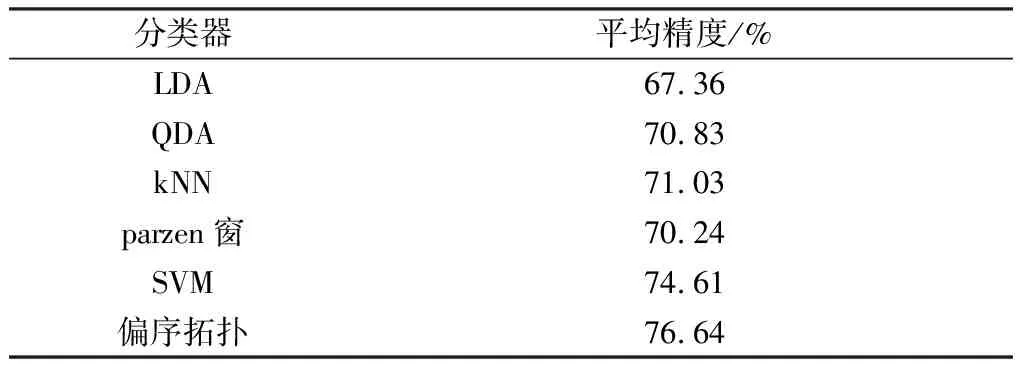
1)若a→b,则Sort(a) 2)若a、b同层且Degree(a)≥Degree(b),则Sort(a) 其中,Sort(*)表示排序后的序号位置。显然,根据此规则排序后,任意属性的所有父属性一定位于该属性之前。 设属性集M排序后的集合为M={m1,m2,…,mm}。对于确定顶点排序的偏序拓扑,可通过以下过程完成概念树的生成。 步骤1:访问初始顶点v,形成规则树的根root,并标记顶点v为已访问。 步骤2:顶点v入队列。 步骤3:当队列非空时则继续执行,否则算法结束。 步骤4:出队列取队头顶点u,形成当前树的节点Tnode。 步骤5:查找顶点u的第一个邻接顶点w。 步骤6:若顶点u的邻接顶点w存在且是非终点属性,则继续执行,否则转到步骤3。 步骤7:若顶点w的父属性已经存在于T中,则继续,否则转至步骤9。 步骤8:将w加入队列。判断其加入w后对象集合是否发生变化,若集合不变,则Tnode.data=Tnode.data*w。 步骤9:查找顶点u的w邻接顶点后的下一个邻接顶点w,转到步骤6。 根据以上过程,可生成概念树表示,图2的概念树如图3所示。在概念树中,根节点至树中每一个节点的路径均为一个形式概念。将概念树中具有相同意义的节点进行合并,即为经典的概念格表示。 图3 图2的概念树Fig.3 The concept tree of Fig.2 为了便于可视化分类,本研究将可视化模式识别中色度图理论[23]引入决策形式背景表示,形成类别偏序拓扑表示图。在该图中,通过基色与混合色,表示形式背景中类别的传递与变化情况,进而直观表示属性在分类意义下的可约关系。 以表1所示背景为例,当考虑决策属性f时形成决策形式背景。在对该决策形式背景进行着色时,设患病采用红色基色表示,未患病采用绿色基色表示,不确定类别采用黄色,则图2所示偏序拓扑的着色情况如图4所示。 图4 图2的类别偏序拓扑表示Fig.4 Category POT graph of Fig.2 在类别偏序拓扑中,节点对象集合的关注点由单个对象泛化至对象的类别,是对象集合中类别的分布表示,因此更适合以分类为目的的数据形式化表示。同时,由于类别偏序拓扑关注节点的类别可分性,因此可将属性分为可分属性与不可分属性。 定义1:可分属性。对于属性a,若∀o∈a′,有oId1,则条件属性a为决策属性d1的可分属性。 定义2:不可分属性。对于属性a,若∃o1,o2∈a′,有o1Id1且o2Id2,则条件属性a为不可分属性。 根据色度图理论可知,在类别偏序拓扑中,基色节点表示可分属性,混色节点表示不可分属性。因此,可通过类别偏序拓扑,直观观察形式背景中各属性的类别分布状况。在此基础上,可得如下性质: 性质1:独有属性一定是可分属性。 证明:由可分属性和独有属性的定义可知,独有属性必然为可分属性。 性质2:在偏序拓扑中,若有a,b∈M且a→b,则必有lab(b)⊆lab(a)。函数lab(·)表示对外延取类别标签。 证明:对于形式背景的偏序拓扑表示,由其偏序特性可知,若有a,b∈M且a→b,根据伴生属性定义,则有a′⊃b′。因此,lab(b)⊆lab(a)。 性质1和性质2是类别偏序拓扑中关于类别传递性的基本描述。由此可知,对于偏序拓扑,自底向上则为普偏性增强过程,自顶向下是特异性增强过程。若属性a为可分属性,则对于B={b|a→b,b∈M},均为可分属性。因此,在自顶向下的分析过程中,对于模式分类,在不考虑数据频繁模式且关注分类实时性的情况下,可采用自底向上的普遍性增强分类器设计方式。 对于强调数据可靠性的场合,属性的频繁度越高,意味着出现瑕疵数据的概率越小,因此可采用自顶向下的方法进行分类规则的提取,以增强分类结果的可靠性。同时,对普遍性高的属性进行优先处理,符合属性拓扑理论中的概念搜索思想,可以在分类过程中实现知识发现过程。 对于决策形式背景,可同样采用色度法对其进行着色。对图3进行着色后,其表示如图5所示。 图5 着色概念树Fig.5 Coloring concept tree 从认知角度看,概念树中路径的集合反映了对当前数据完整的知识学习过程,但从粒计算和分类角度看,则存在着信息的过学习现象。因此,本项目在前期概念追溯思想的基础上,针对决策形式背景,提出概念树的约简过程。 设概念集合C={(A1,B1),(A2,B2),… }是概念(A,B)的直接超概念集合,即对于任意i,有A⊆Ai等价于Bi⊆B。因此,集合C在层次序上位于概念(A,B)的上层,可表示为(A,B)≤(A2,B2)。概念(A,B)外延的信息类别为 lA={lab(a1),a1∈A} 因此,lA表示了概念(A,B)中的类别集合。则集合C中每一个概念(Ai,Bi)的外延信息类别可表示为 lAi=uion{lab(a1),a1∈Ai} 若有对于任意Ai,均满足lAi=lA。从知识意义上看,由(Ai,Bi)(A,B)的属性增加并未带来知识容量的增加。因此,可以节点的类别标签为基础,完成对概念树的约简。结合分类原理,若属性a→类别ai,则任何包含属性a的概念必属于ai类。因此,对于以分类为目的的数据分析过程,步骤7和8可修改如下: 步骤7:若顶点w的父属性已经存在于T中,则w加入树T中,其父节点为Tnode;否则转至步骤9。 步骤8: 判断加入w后对象集合是否类别唯一。若类别不唯一,顶点w入队列;若类别唯一,则将w及其伴生属性在M中删除。 根据修改后的算法,图5对应的约简概念树如图6所示。 图6 约简概念树Fig.6 Brief concept tree 由图6可知,对于急性验证中膀胱炎(inflammation of urinary bladder)的判断,可采用有b症状(lumbar pain)下c、d症状(urine pushing, micturition pains)同时出现或c症状(urine pushing)下d症状(micturition pains)出现作为诊断依据。 约简概念树的形成,在不影响分类和知识发现的前提下,不但节省了数据的存储空间,同时简化了计算过程,为基于偏序拓扑的模式分类与知识发现统一框架奠定了理论基础。在约简概念树中,对于可分概念,可以直接进行分类;而对于不可分概念,则可以经过属性叠加增强其分类性能,或利用主动生长方式[24]进行模糊分类。 表3 CPPDD与国际主流数据集对比Tab.3 Comparison between CPPDD and the classic international datasets 1.5.1帕金森语音概念分析实验 为了验证所提出方法对帕金森语音特征在概念提取上的有效性,采用牛津帕金森语音数据集OPDD(http://archive.ics.uci.edu/ml/datasets/Parkinsons)进行数据分析。 在OPDD的22个特征中,通过前期的分析可知,NHR、DFA和D2是最具有代表性的3个语音特征[25]。考虑到数据规模的可表示性,本实验仅选择这3个语音特征作为分析属性。在OPDD数据中,随机选择10位测试者,每个测试者选择一段语音进行NHR、DFA和D2特征分析,患病样本与健康样本比例为1∶1。分析集合如表2所示,其中name为受试者语音编号,NHR、DFA、D2分别为受试者语音所提取的特征,status为标签数据,表明受试者是否患病。 表2 OPDD数据子集Tab.2 Subset of OPDD data 1.5.2帕金森病诊断精度实验 为了全面测试本方法的有效性,采用多数据集、多分类器对比测试的方法进行。所采用的帕金森病数据集包括当前国际主流帕金森数据集OPDD、PTDS、PSMT(Parkinson Speech Dataset with Multiple Types of Sound Recordings Data Set)和本课题组采集的汉语发音的帕金森病语音数据集CPPDD(Chinese Pronunciation Parkinson detection dataset)。 CPPDD以元音分离度方法为基本方法[8]进行采集。为了满足采集要求,分别构建了易用性语音采集平台、语音信号处理工具箱和语音数据管理系统3个基础工具,其工作界面如图7所示。 图7 语音采集平台软件界面。(a)语音采集;(b)语音信号处理;(c)语音数据管理Fig.7 The platform software interface of voice acquisition. (a) Voice acquisition; (b) Voice signal processing; (c) Voice data management 数据采集工作主要在唐山工人医院和开滦精神卫生中心展开,共采集到语音样本35人,其中帕金森患者20人,健康人15人,男女比例21∶14,年龄分布42~75岁,受试均签署知情同意书。采集到的原始数据和所提取的特征均保存于数据集中。表3对比了本数据集与当前国际主流帕金森数据集OPDD、PTDS、PSMT。为了对比测试结果,实验中均采用数据集中的语音特征作为分类诊断依据。 表5 二值化后的帕金森数据集Tab.5 Binarized Parkinson datasets 表4帕金森数据集量化区间及特征简写 Tab.4QuantizationintervalandfeatureabbreviationofParkinsondatasets 原始特征量化后特征特征简写NHRNHR[∗,0.006)A1NHR[0.006,0.02)A2NHR[0.02, ∗)A3DFADFA[∗,0.70)B1DFA[0.70, 0.75)B2DFA[0.75∗)B3D2D2[∗, 2.1)C1D2[2.1, 2.4)C2D2[2.4, ∗)C3 为了客观地评价本研究所设计分类器的分类性能,利用LDA、QDA、kNN、parzen窗、SVM等经典分类器作为对比测试方法。不同的分类器在不同的数据集上进行应用,通过对比分类精度,评估本方法与经典方法的性能差异。为了保证测试结果的客观性,本实验中的参考分类器均采用PRTools中的软件包完成。 在表2所示的OPDD数据子集下,利用可视化离散方法[26]对该数据集进行离散化,形成标准的二值形式背景,各特征离散所用的区间及简写如表4所示。以表4为量化间隔对帕金森数据进行离散化,形成的二值形式背景如表5所示。 图8 帕金森数据类别偏序拓扑Fig.8 The category POT of Parkinson data 将离散化后的二值形式背景进行拓扑表示和概念计算,其类别偏序拓扑与类别着色概念树分别如图8、9所示。在该图中,红色点表示决策属性status=1(帕金森病患者)对应的属性,绿色点表示决策属性status=0(健康人)对应的属性,黄色点表示该属性为混合类别,无法判断结果。为了清晰起见,偏序拓扑并未标注属性间的具体连接内容,概念树仅标注了内涵增量组合,并未对外延进行标注。 图9 帕金森数据类别着色概念树Fig.9 The category coloring concept tree of Parkinson data 数据集LDA/%QDA/%kNN/%parzen窗/%SVM/%偏序拓扑/%OPDD83.0888.2184.6185.1388.7290.13PTDS27.9733.5138.3540.4141.8750.12PSMT86.0385.9886.2884.5688.9285.98CPPDD72.3675.6274.8770.8778.9280.34 着色概念树清晰地表明当前数据集下语音特征与帕金森病之间的关系。若受试者D2特征值较小(属性C1)或NHR中等(属性A2),可以认为该受试者没有帕金森病;如果受试者出现NHR较大(属性A3)、DFA较大(属性B3)或D2特征中等(属性C2)时,可认为其患有帕金森病;其他情况(A1,B2,C3)靠单独一个指标无法确定,需要多个特征联合判断。该结论与当前医学上关于帕金森病语音障碍研究具有一定的吻合度。 在测试本方法的有效性中,基于偏序拓扑图的帕金森病语音障碍分析和LDA、QDA、kNN、parzen窗、SVM等经典分类器,在不同的数据集上应用的分类结果如表6所示。结果表明,在数据集OPDD、PTDS、CPPDD中,所提出的方法与其他经典方法相比,其分类精度明显高于其他分类器。在同一分类器下,OPDD与PSMT数据集下的分类精度一般高于CPPDD的分类精度。 为了清晰地表示实验结果,从数据集和分类器两个角度进行对比,如图10、11所示。 基于以上数据结果,不同分类器在不同的帕金森病语音数据集下的平均分类精度如表7所示,其中本研究的基于偏序拓扑图的帕金森病语音障碍分析的平均分类精度达到76.64%,比其他分类方法中最佳的SVM分类器(74.61%)高出2.72%的诊断精度。 分别从相同分类器下不同数据集的分类精度和相同数据集下不同分类器分类精度,对本研究的实验结果进行讨论。 相同分类器下,不同数据集的分类精度不尽相同。在本研究中,共采用OPDD、PTDS、PSMT 3个英语发音的国际公开数据集和汉语发音的帕金森病语音数据集CPPDD进行分析。 图10 相同方法下不同数据集的实验精度对比Fig.10 Comparison of experimental accuracy of different datasets with the same method 图11 相同分类器下不同数据集的分类精度对比Fig.11 Comparison of classification accuracy of different datasets with the same classifier Tab.7Theaverageclassificationaccuracyofdifferentclassifiers 分类器平均精度/%LDA67.36QDA70.83kNN71.03parzen窗70.24SVM74.61偏序拓扑76.64 OPDD为经典的帕金森病语音数据集,是经过特征提取的帕金森病语音特征集合,也是目前大多数研究人员常用的帕金森病语音数据集。由表6可知,该数据集目前分类精度普遍高于80%,主流的SVM方法达到了88.72%,而本研究的偏序拓扑方法分类精度达到了90.13%。该数据集分类精度高的原因在于其为二分类数据(仅包括健康、患病两类),且在特征提取之前经过了预处理。 PTDS为远程采集数据集,语音信号经过电信线路的传输,损失了部分具有诊断意义的高频信息,且该数据集根据帕金森病的患病严重程度分为5级。信息损失与分类类别的增加造成了分类困难,故各分类器在该数据集下的表现均不尽人意。与此同时,该数据集的数据混叠为分类器的性能提供了更好的区分条件。在本实验中,偏序拓扑由于具备局部数据分析能力,使得其分类精度达到50.12%,远高于其他分类器的分类精度。 PSMT数据集的特点在于其提供的是原始语音与语音特征混合的数据集,因此该数据集可以测试在未经过预处理过程下的分类器对噪声的敏感程度。偏序拓扑方法对该数据集的分类精度仅达到了平均水平,这主要是由于在数据离散化过程中未能有效去除噪声干扰,从而降低了数据分类精度。 CPPDD是目前为数不多的汉语发音数据集,且该数据集目前所有语音未经过预处理。从整体上看,对于相同的分类器而言,CPPDD的分类精度要低于英语发音的OPDD与PSMT数据集。这说明,汉语发音的复杂性与帕金森病的诊断精度之间存在一定的相关性,下一步需要针对汉语发音进行专门的算法优化。 综上所述,对于不同的数据集而言,经过数据预处理的CPDD分类性能最优,能提供语音和特征双重数据的PSMT次之,汉语发音数据集CPPDD需要进一步地优化算法以提升其整体精度,而PTDS数据集本身的不可分性可用于测试分类器对局部数据的处理程度。结合中国目前帕金森病患病人数的实际情况,针对性地研究汉语为母语的帕金森病语音障碍诊断,无论对于理论研究还是临床研究均具有重要的意义。 对于同样的数据集而言,不同的分类方法得到的分类精度不同。由表7可知,本研究所提出的概念分析方法基本达到了主流分类器的分类精度。 横向分析各分类器的差别,其主要原因在于帕金森数据集为典型的非线性高维复杂数据,因此以LDA为代表的线性分类器无法完成高精度的分类界面描述;而QDA作为非线性分类器,虽然分类精度有所提高,但仍受二次方程的约束;kNN分类器基于样本的近邻测量,其分类精度依赖于邻近样本的混叠程度,由于帕金森数据集在局部混叠严重,因此分类性能一般;SVM作为核方法的代表,因其高维映射的非线性分类特性,使得其在经典分类器中分类性能达到了最优。概念分析分类器作为一种新型分类器,通过离散化过程完成对原有数据的局部化,再通过概念计算过程完成高维非线性映射,且其升维过程并不受核函数等函数形式限制,因此其性能高于经典的SVM分类器,可以获得更高的分类精度。 综合以上分析可知,针对帕金森病的语音数据集的非线性特性,需要一种基于非测量机制的非线性分类器进行分类处理。而偏序拓扑本身的局部离散化和概念计算,使得其在帕金森病的语音障碍分类中平均分类精度达到最优。同时,偏序拓扑特有的结构分析特性,为语音障碍与帕金森病间的因果分析与推理奠定了基础。 本研究针对帕金森病的语音障碍诊断,设计了一种基于偏序拓扑的概念计算分析与分类方法。该方法利用偏序拓扑的层次结构对帕金森病的数据特征进行表示,并利用形式概念分析中形式概念的思想进行特征的二次组合与升维,从而在概念分析的基础上获得分类诊断性能。实验表明,偏序拓扑可以对帕金森病特征进行层次化表示,并且其分类精度与经典分类器相当。 但对于大规模数据集,偏序拓扑在可视化方面仍需精简,且概念计算本身带来的时间消耗是本方法的缺点,也是下一步要重点研究的问题。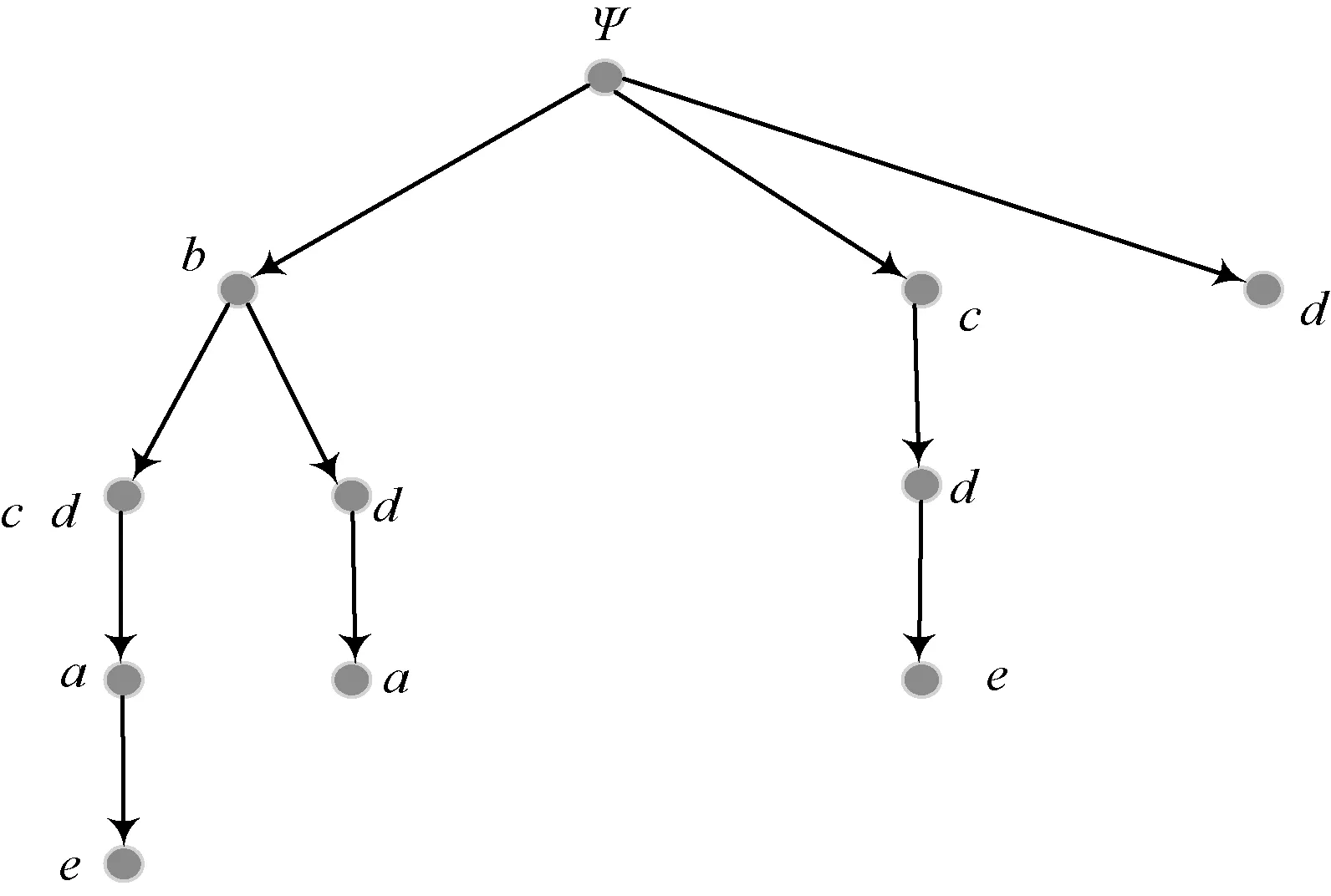
1.4 可视化分类与知识发现
1.5 数据与对比方法
2 结果
2.1 帕金森语音特征的概念分析
2.2 帕金森病诊断精度的实验
3 讨论
3.1 数据集分析
3.2 分类器分析
4 结论
