基于Hadoop的工程造价费用估算与信息管理系统设计
2018-12-03兰溯源
兰溯源
(延安大学建筑工程学院,陕西 延安 716000)
随着我国建筑业的不断发展,工程造价行业积累了大量的数据信息,这些信息的积累,为工程造价信息共享和挖掘奠定了基础。目前,工程造价行业还存在一些比较突出的问题,如信息互通困难,使得工程造价单位和管理部门数据共享不充分,存在“信息孤岛”的现象。同时部分工程造价信息数据更新慢,没有充分体现出其应有的价值。如何对这些海量数据进行存储和挖掘,提高这些数据在工程领域的应用效率,成为业内思考和研究的重点。朱渊[1]以输变电工程为背景,采用Web技术构建了一个可用于输变电工程造价管理的系统,运用该系统工作人员可对工程造价进行预算、及时查看工程进度等;周文琼等[2]采用BIM/BLM构建工程决算系统,通过该系统可实现工程决算的可视化。但目前工程造价信息共享不足,“信息孤岛”现象依然存在。针对数据共享以及考虑到当前海量的造价信息存储、分析问题,本文基于Hadoop架构体系构建一个可供工程造价行业查询工程造价预算与信息管理的系统,改变当前信息共享差、数据利用效率低下的状况,以此为工程造价行业提供更多有价值的信息,促进工程造价行业的整体发展。
1 系统角色与需求分析
构建工程造价费用估算与信息管理系统的目的是利用云计算技术对工程造价数据进行挖掘,提高工程造价行业的信息利用率。根据设计目的以及结合造价行业的具体业务,设计7种不同的角色,这些角色在该系统中拥有不同的业务需求,具体如图1所示。
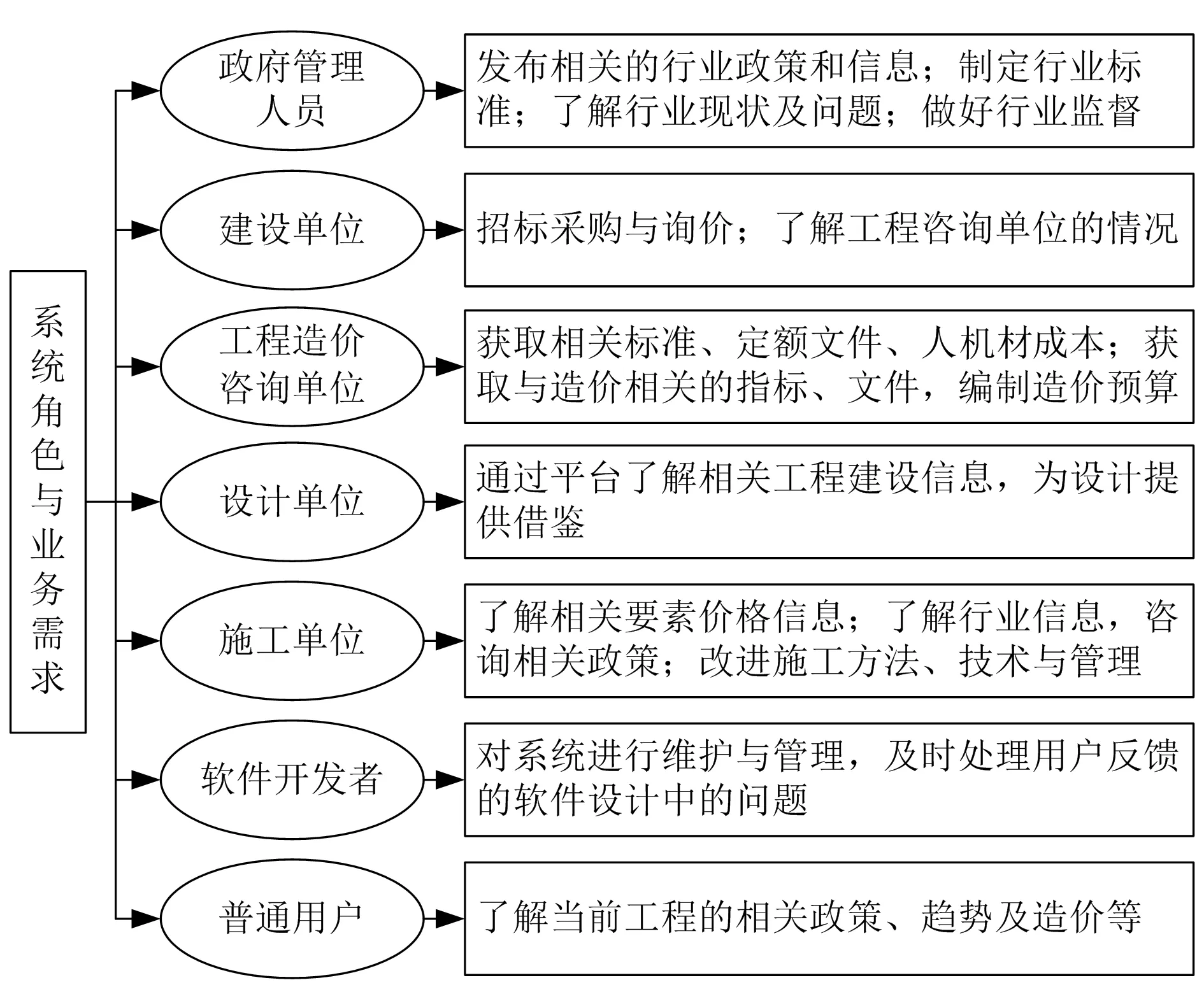
图1 不同角色的业务需求分析
从图1可以看出,工程造价信息管理平台是以信息的共享和利用为基础的。信息管理平台本身就促进了整个行业信息共享的效率,因此在该系统的设计中,另一个要关注的问题就是如何利用系统中海量的工程造价信息,提供工程造价估算与预测功能,为工程管理者提供借鉴与参考。
2 系统整体架构搭建
根据以上的设计目标和业务需求,在设计中首先应满足基本业务需求,其次再考虑系统的长远发展,以便扩展系统的功能。本系统构建目的是实现工程造价行业信息的共享,促进造价业务的协同,并通过投资预测等功能,为造价行业提供相关的决策依据。考虑到数据量庞大,采用Hadoop架构搭建系统,将系统分为数据集成层、数据存储层、数据处理分析层、数据输出展示层。系统整体架构如图2所示。
通过图2看出,不同层具有不同的功能。
数据集成层是整个系统数据的来源,这些数据可以来自MySql数据库,也可以来自Sql Servers数据库,还可来自其他的数据库。换句话说,这些数据可以是结构型数据,也可以是非结构型数据,数据的类型包括文字、图片、音频等。为方便对这些数据的存储和查询,在数据源与数据存储层之间使用Sqoop工具,通过该工具可实现关系型数据库与Hadoop间的交换。
数据存储层采用HDFS、Hbase等组件,通过分布式文件存储系统和统一的接口即可完成对不同节点下文件的访问。Hbase主要负责对非结构化的数据进行存储。
数据处理分析层采用MapReduce并行处理技术、Hive技术等,以完成对数据的计算和查询。通过MapReduce并行技术提高运算速率,采用Hive提高查询效率。
数据输出展示层则是将查询的结果展示给用户。
3 功能模块设计
系统设置了信息分析与发布、信息采集、信息检索、用户注册与登录、数据分析、系统维护与管理等模块,如图3所示。
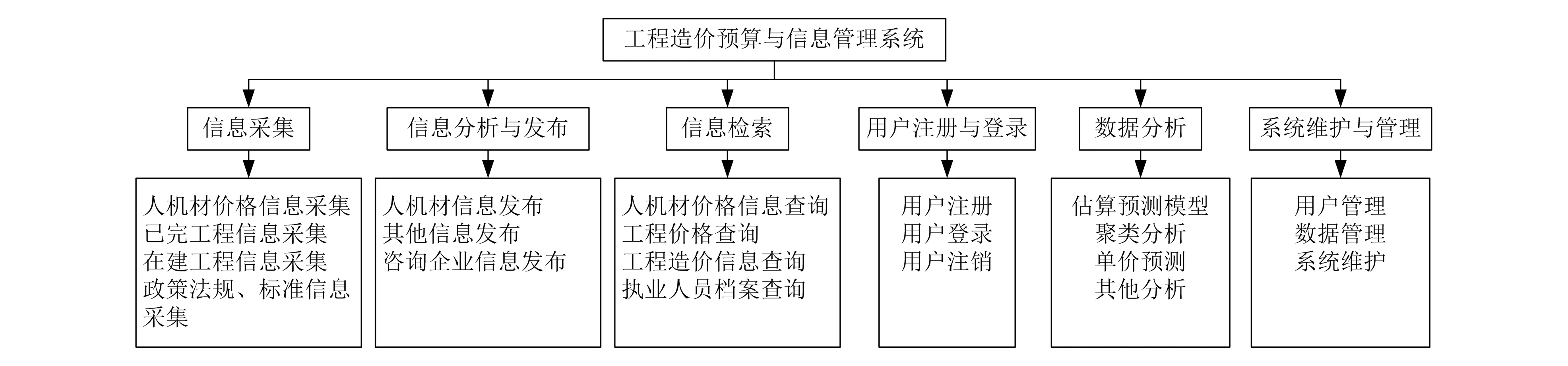
图3 系统功能模块
4 系统详细设计
4.1 用户登录设计
进入登录页面,用户输入登录名和密码,与后台服务器中存储的登录名和密码进行比对,如一致则进入到工程造价预算与信息管理系统主界面;如不一致,则返回重新登录。具体流程如图4所示。
4.2 工程造价估算模型构建
工程造价估算模型的构建是本系统的重点。目前,用于工程造价估算的模型很多,其建模方法包括神经网络算法、灰色关联分析算法等。本文在总结以往方法优缺点的基础上,选用灰色关联分析算法进行工程造价估算模型的建立。该方法的基本思路是根据序列曲线几何形状的相似度[3],来判断两工程的造价之间联系是否紧密。
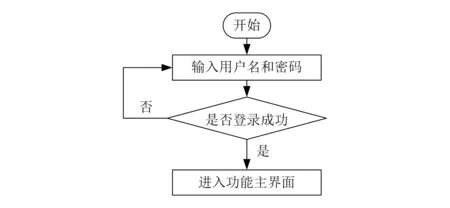
图4 系统登录流程设计
如项目造价变化趋势一致或者是相似,则认为两者之间的关联度较高;如变化趋势区别较大,则认为两者之间的关联度低。对于工程建设项目来讲,影响工程造价的因素很多,因此在进行项目投资估算时,通过工程项目特征相似度进行关联分析。具体的思路是:选取与待测项目特征比较接近的工程项目若干,然后采用灰色关联度分析法筛选出与待测工程最为接近的n个典型工程,对这些典型工程的平均投资额进行计算,最后得到预测工程的投资额度。
具体测算步骤为:
1)选取测算指标,包括工程结构、内装形式、给排水方式等。
2)根据上述关键指标,筛选出同类型的工程项目,然后将估算工程的单方造价与类似项目的特征信息进行系数赋值。本文将该系数值设定为0.5。
3)计算估算工程项目与典型工程的关联度。
假设有P个典型工程,其包含8个特征参数,分别为结构形式、内墙装饰、外墙装饰、给排水、暖通、强电、弱电、电梯等,可以得到工程的参数序列集合Xi:
(1)
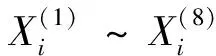
①求取t。
(2)
式中:X(1)~X(8)为同类型工程各特征参数的平均数;t为选定的特征参数与同类型工程特征参数平均数的差的绝对值。
②找出t中的最大差值tmax和最小差值tmin,并计算关联度系数:
(3)
式中:moi为关联度系数;q为第q个特征参数。
③计算关联度roi:
(4)
式中:n为被比较的特征参数个数。
4.3 综合单价预测模型构建
除整体的工程造价估算以外,还需对某个工程的单项造价进行预测。本文引入残差自回归预测模型对工程的综合单价进行预测,并采用并行计算技术,以提高综合单价预测的准确性和计算效率。具体的预测流程如图5所示。
4.4 信息聚类设计
为进一步提高Hadoop框架下海量数据信息挖掘的效率,引入k均值聚类算法对工程造价库中的数据进行聚类。
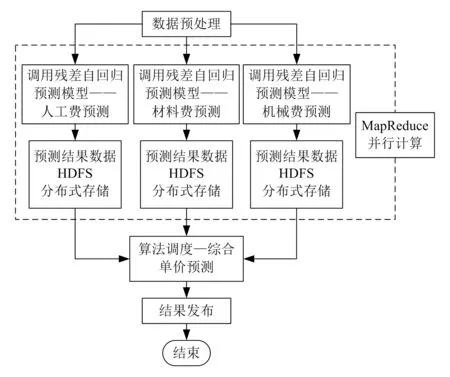
图5 综合单价预测流程
在聚类算法中,最关键的是确定初始k值和中心点[4-5]。本文使用k均值聚类法对系统中的信息进行挖掘分类时,对中心点的选择进行了改进,即改变以往只选择一个中心点作为聚类点的做法,在比较数据样本的距离后,选择距离尽可能远的两个样本作为初始的中心点,即对于给定的数据集A={x1,x2,…,xm},xm∈Rd,选择两个样本距离最长的点作为中心点,然后计算每个样本与这两个点之间的距离。具体过程设计为:
1)选取样本中距离最长的两点s,t作为中心点,即dst=dmax。
2)分别计算其他样本与s,t中心点之间的距离。若样本xi(i=1,2,…,P)与样本xs和xt的距离存在|xi-xs|<|xi-xt|,则将xi归入数据集As中,反之归入数据集At中。由此得到新的两类数据集As和At。
3)计算新数据集As和At中的样本到xs的距离,分别用d1max和d2max表示,取两者中的较大者,设为d3=max{d1max,d2max},对应的数据记为xu。若d3>0.5dst,那么将该数据标记为第三个聚类的中心点。
4)以此类推,直至找不到符合条件的样本,停止分类。
在运行上述算法的同时,运用MapReduce分布式处理技术对数据进行分布式聚类。
4.5 在线查询模块设计
为提高系统的实用性,在系统中加入在线查询功能。用户在输入关键词后,可及时查到工程价格信息、材料成本信息、造价指数等。具体流程如图6所示。
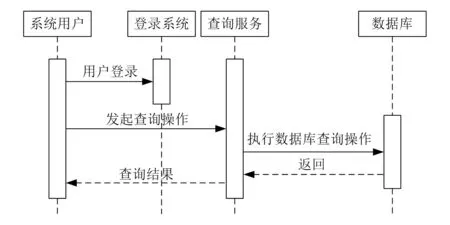
图6 在线查询实现流程
5 系统测试
5.1 测试环境搭建
为验证本系统的可行性,需对系统进行测试。硬件环境:部署5台计算机,1台为主节点,4台为子节点。计算机的CPU为四核 core i7,内存为8GHz,硬盘为500G。
软件环境:操作系统为Windows 2008 Server;开发工具为JDK 1.6.25;Hadoop 的版本为Hadoop 0.20.2。
5.2 性能测试
根据上述的节点部署,选择4个子节点计算机对数据进行测试,得到如图7所示的结果。
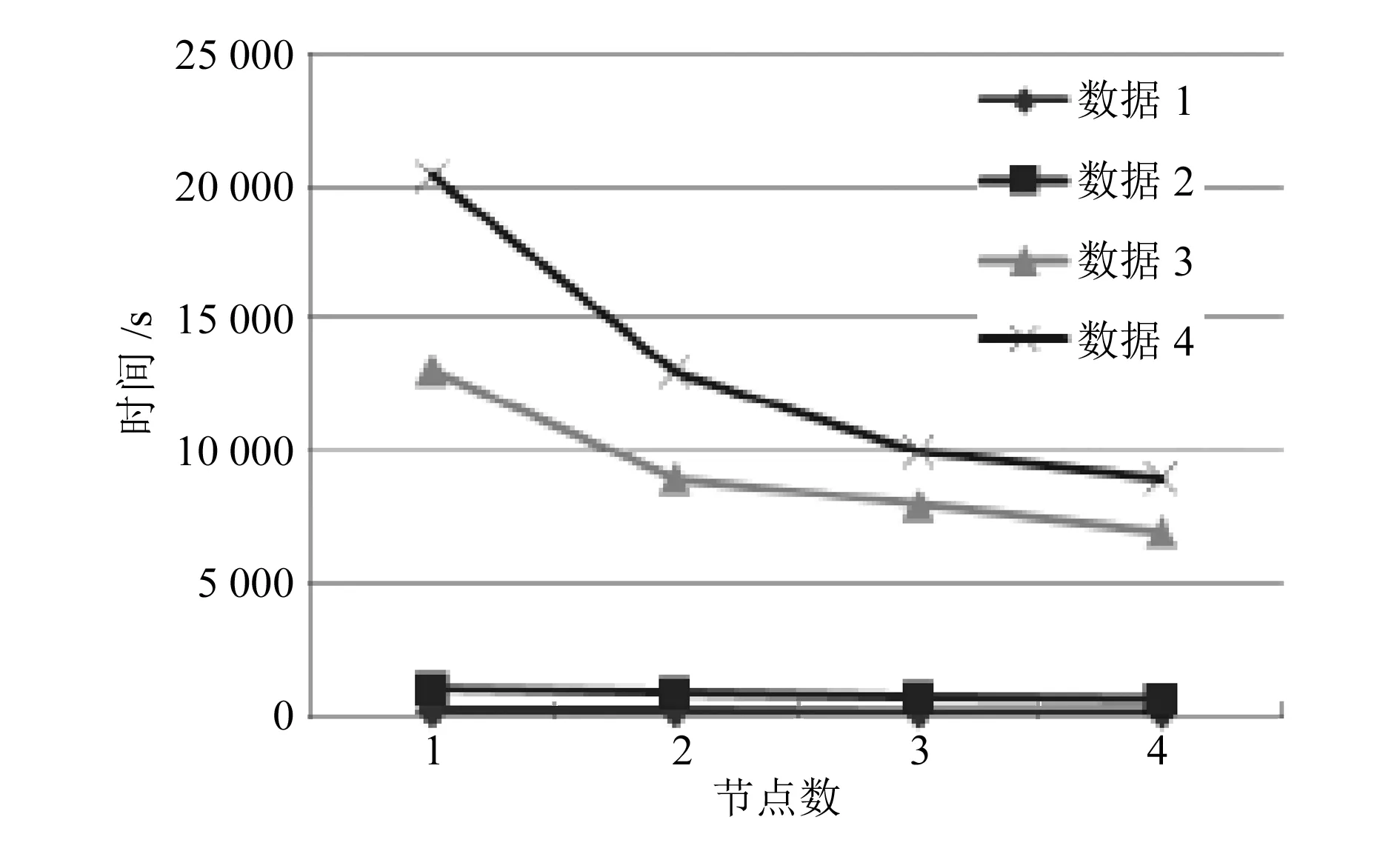
图7 数据处理时间
从图可以看出,在数据相同的情况下,当子节点超过3个时,数据处理的速度明显加快。说明通过分布式部署的方式,可提高大规模数据的处理效率。
5.3 功能测试
以用户登录、造价信息查询为例进行功能测试。当用户输入用户名和密码后,可直接进入到系统主界面。登录界面如图8所示。
图8 登录界面
对不同区域的造价信息进行查询,如点击“成都”→“建筑工程”,可以得到如图9所示的造价信息界面。
6 结束语
本文提出的关联度投资估算方法,在一定程度上可快速估算出工程的整体造价,进一步拓展了工程管理系统的功能,也促进了工程造价行业信息的共享。本文系统的构建借助了大数据框架体系,可提高系统运行的效率。

图9 行业造价信息界面
