聊天机器人中用户就医意图识别方法
2018-10-16冯旭鹏刘利军黄青松
余 慧,冯旭鹏,刘利军,黄青松,3
(1.昆明理工大学 信息工程与自动化学院,昆明 650500; 2.昆明理工大学 教育技术与网络中心,昆明 650500;3.云南省计算机技术应用重点实验室(昆明理工大学),昆明 650500)(*通信作者电子邮箱kmustailab@hotmail.com)
0 引言
近年来,人工智能发展迅猛,逐渐融入各个领域,其中在医疗领域的应用正引起学术界和工业界广泛关注。不少在线医疗平台开始使用聊天机器人来提供健康咨询服务,这时聊天机器人不仅充当客服角色,更多起到一个健康咨询师的作用。在和“健康咨询师”聊天过程中,用户会产生大量数据,不仅包含其健康信息,还包含其他相关信息。如果能够利用这些信息提前判断出用户就医倾向,则可以为下一步给用户提出合理治疗建议以及推荐相应科室作好准备[1]。
准确识别用户意图有助于了解用户潜在需求,辅助事件预测以及判断事件走向[2]。虽然目前聊天机器人中用户意图识别的研究工作还处于起步阶段,但由于互联网蓬勃发展,互联网用户意图识别的研究正如火如荼进行,因此可以借鉴这些相关领域的研究。比如基于搜索引擎的查询意图识别,研究者主要通过分类Query来确定用户的搜索内容[3]。在消费意图挖掘研究中有学者利用模板的思想来抽取和泛化用户的消费意图,Ramanand等[4]提出基于规则和图的方法来获取意图模板;Chen等[5]考虑到消费意图语料的匮乏,在消费意图表达具有相似性的假设下提出了跨领域迁移学习(transfer learning)的消费意图检测方法。这些传统的意图识别方法一般是基于模板匹配或人工特征集合,费时费力、扩展性不强。
针对上述问题,本文把聊天机器人中用户就医意图识别看作文本分类问题,即明确没有就医意图、极小可能就医、可能就医、极大可能就医和明确具有就医意图;同时考虑医疗领域聊天文本的特点,即长度短、包含多轮回话的上下文信息和领域专有词,比如医院、医生等,构建了基于短文本主题模型(Biterm Topic Model,BTM)和双向门控循环单元(Bidirectional Gated Recurrent Unit,BiGRU)的意图识别模型(BTM-BiGRU)来进行用户就医意图识别。针对领域文本特点,本文使用主题作为文本特征,首先通过BTM对用户聊天文本进行主题挖掘,相较于狄利克雷分布(Latent Dirichlet Allocation,LDA)主题模型,BTM对短文本的适应效果更好[6]。然后结合深度学习方法,将上述BTM得到表示连续语句的特征向量集送入BiGRU中进行完整上下文学习,最后通过Softmax[7]输出分类结果实现本文任务。与支持向量机(Support Vector Machine,SVM)[8]等传统机器学习方法相比,BiGRU能够更好地对用户多轮对话进行建模,充分利用上下文信息来提取用户聊天文本特征。实验结果证明该混合模型结合了BTM和BiGRU的优点,相比传统方法,能更有效进行用户就医意图识别。
1 相关研究
1.1 词向量
在使用机器学习进行自然语言处理时,第一步肯定是将实际的文本内容变成计算机能识别的表示形式,即将要处理的信息数学化[9]。向量空间模型是目前自然语言处理中的主流模型,其中词向量则是最基础和重要的。词向量常见的一种表达方式是one-hot representation,它的向量维度是整个语料库中词个数,每一维代表语料库中一个词,其中1代表出现,反之为0。很明显,one-hot representation不仅存在维度灾难,而且最大问题是它只表达词本身是否出现,而没有表达词与词之间的关联。为此,便有了通过目标词上下文来预测目标词从而得到词向量的方法,称为distributed representation。相应地,句向量、段向量等也就可以在此基础上得到。如今最常用的词向量训练方式是word2vec[10],本文也使用它来训练词向量。
1.2 主题模型
近几年,许多需要大规模文本分析的领域都成功应用了主题模型[11],包括自然语言处理、数据挖掘、商业智能、信息检索等。首先关于主题,它是一个概念、一个方面,表现为一系列相关的词语。例如一个文档如果涉及“医院”这个主题,那么“医院”“医生”等词语便会以较高的频率出现。用数学语言描述,主题就是词汇表上词语的条件概率分布,与主题关系越密切的词语,它的条件概率越大,反之则越小[12]。而主题模型作为语义挖掘的利器,则是一种对文字隐含主题进行建模的方法。主题模型中最具代表性的是Hofmann[13]提出的基于概率潜在语义分析(Probabilistic Latent Semantic Analysis,PLSA)模型和Blei等[14]提出的LDA模型。而本文所采用的BTM则是Cheng等[15]提出的针对短文本学习的主题模型,该模型通过词对共现模式加强主题学习。
2 基于BTM-BiGRU的用户就医意图识别
2.1 BTM
针对短文本,由于其数据稀疏,如果根据传统的词共现方式来进行主题挖掘,效果将很不理想。为此,Cheng等[15]利用词对共现来代替词共现,提出一种短文本主题模型(BTM)。BTM结构如图1所示,其中各参数的含义如表1所示。
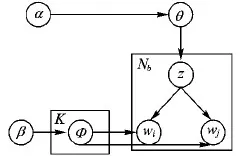
图1 BTM结构

参数含义K主题数目Nb语料中所有词对的数目α主题的狄利克雷先验参数概率分布β主题词的狄利克雷先验参数概率分布θ文档-主题概率分布Φ主题-词概率分布z主题
每篇文档的主题分布产生过程如下:
假设文档的主题概率等于此文档生成的词对的主题概率的期望值,如式(1)所示:
(1)
其中:z表示主题,d表示文档,b表示词对。
通过贝叶斯公式能够得到词对的主题概率P(z|b),如式(2)所示:
(2)
其中:P(z)=θz,P(wi|z)=φi|z,wi、wj表示某个词对b中的两个不同的词,θz表示从主题分布θ中抽取一个主题z,φi|z表示主题-词分布φz中词wi对应值。
用文档中词对的经验分布估计P(b|d),如式(3)所示:
(3)
其中,nd(b)为文档d中词对b的出现次数。
2.2 基于门控循环单元的双向循环神经网络
2.2.1 门控循环单元
针对普通循环神经网络(Recurrent Neural Network, RNN)[16]存在的两大问题,即长距离依赖和梯度消失或梯度爆炸,Hochreiter等[17]提出了长短期记忆(Long-Short Term Memory, LSTM)模型。相比传统RNN,LSTM的重复神经网络模块更复杂,增加了门结构,即遗忘门、输入门以及输出门。三个门的计算也造成了LSTM训练时间较长,而门控循环单元(Gated Recurrent Unit, GRU)[18]作为LSTM的一个变体,在保持其学习效果的同时又使结构更加简单,节省训练时间。GRU只有重置门rt和更新门zt,其中更新门由遗忘门和输入门合成,其工作流程具体如下:
和LSTM一样,GRU的关键是元胞状态。首先决定要从旧元胞状态和当前输入中丢掉哪些信息,由重置门来控制其程度,如式(4)所示:
rt=σ(Wrxt+Urht-1)
(4)
其中:σ代表Sigmod非线性函数,xt代表当前输入,ht-1代表上一时刻隐层的输出。
接下来是决定将哪些新信息保存到元胞状态,具体分为两部分:
1)更新门用来控制忘记之前信息和添加新信息的程度,如式(5)所示:
zt=σ(Wzxt+Uzht-1)
(5)
(6)
其中:tanh代表双曲线正切函数,⊙代表元素级相乘运算。
最后,把这两个值组合起来用于更新旧元胞状态ht-1到新元胞状态ht,如式(7)所示:
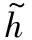
(7)
2.2.2 双向门控循环单元
双向GRU是GRU的改进。由于GRU是单方向推进,往往忽略了未来的上下文信息,而双向GRU的基本思想是使用同一个训练序列向前向后各训练一个GRU模型,再将两个模型的输出进行线性组合,使得序列中每一个节点都能完整地依赖所有上下文信息。对于本任务,在每一个时间步上充分利用过去和未来的上下文,将有助于更好理解用户的就医意图。双向GRU的结构如图2所示。
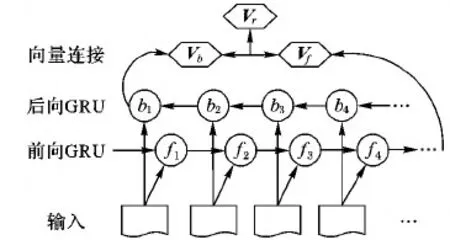
图2 双向GRU模型结构
2.3 BTM-BiGRU混合模型
2.3.1 混合模型结构
该混合模型的结构如图3所示,由BTM层、Sentence embedding层、BiGRU层和最终的Softmax层组成。
1)BTM层:按照聊天顺序将聊天语句逐句送入BTM层,利用BTM挖掘出每句的文档-主题概率分布P(z|d)的最大值p=(z|d)max对应主题下的主题-词分布前N个词。
2)语句嵌入层:将BTM层得到的主题词作为特征项并用词向量表示,特征词对应权重由整个实验语料的TF(Term Frequency)和IDF(Inverse Document Frequency)确定,如式(8)所示,从而得到句子的特征向量。假设长度为n句话的用户聊天文本,令Si∈Rk代表聊天中第i句话的句向量,则整个用户聊天文本表示为CR∈Rnk,如式(9)所示:
wik=TFik×IDFik
(8)
其中,wik代表第i句话的第k个主题特征词权重。
CR=S1⊕S2⊕…⊕Sn
(9)
其中,⊕代表将句向量依次进行拼接操作。
假设经过滤得到某用户的聊天对话:D=S1+S2,其中S1=“最近我这一直胸闷,想去医院看看”,S2=“请问我该挂什么号”。通过BTM层后分别得到S1的最大主题概率下的前2个主题词为“医院”“医生”,S2的为“挂号”“科室”。利用word2vec分别得到医院、医生、挂号、科室的词向量,假设为x1、x2、x3、x4,其对应TF-IDF权重为w11、w12、w21、w22, 则S1的句向量S1=w11·x1⊕w12·x2,S2的句向量S2=w21·x3⊕w22·x4。
3)BiGRU层:由前向GRU和后向GRU组成。分别将用户聊天文本向量CR顺序、逆序输入前向GRU和后向GRU,得到两个方向的连续语句表示F_CR′和B_CR′,将其拼接起来作为用户多轮会话的最终表示。
4)Softmax层:本任务一共有5个输出,即该用户明确没有就医意图、极小可能就医、可能就医、极大可能就医和明确具有就医意图,因此混合模型的Softmax层输出维度为5。Softmax层的输出是判别类别的概率,即根据条件概率的值来判断聊天文本到底属于哪类用户意图。
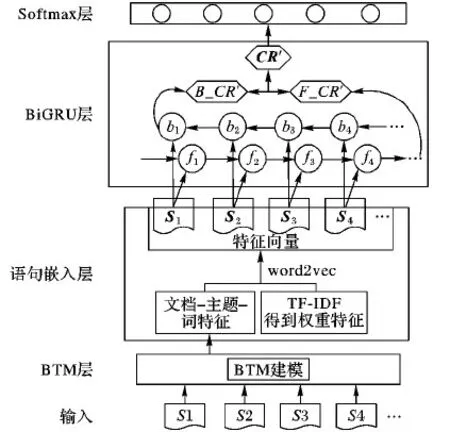
图3 BTM-BiGRU结构
2.3.2 混合模型优点
本文综合BTM和双向GRU的优点,构建了BTM-BiGRU混合模型。正如前文分析所得,由于BTM采用词对共现模式代替传统的词共现模式,因此可以更好地对短文本进行主题特征挖掘。GRU不仅保持LSTM可以对文本的上下文信息进行有效刻画,解决文本长期依赖问题的优势,而且只有两个门的计算,参数减少,节省了模型的训练时间。但不管是LSTM还是GRU,都有一个问题,它是从左往右推进的,后面的输入会比前面的更重要。很明显对于本任务来说这是不妥的,因为聊天中各语句应该是平权的,因此本文采用双向GRU来完整捕捉上下文信息。
3 实验分析
3.1 实验数据及评价指标
由于目前公开的医疗聊天语料较少,因此本文使用的实验数据是通过爬虫程序在浙江大学附属第一医院爬取下来的用户聊天语料,共计18 822条。通过关键字及模板规则过滤掉对意图没有贡献的语句,再人工将同一用户的一句或多句话归为一组,共分了5 660组数据。然后由两名标注人员各自对其标注意图类别,通过匹配两名标注人员的标注结果,去掉不一致,最终得到标注结果一致的5 425组数据,如表2所示。其中,明确没有就医意图有891组,极小可能就医有538组,可能就医有1 868组,极大可能就医有782组,明确具有就医意图有1 346组。另外,为避免实验结果的偶然性,在进行对比实验时,采用5折交叉验证,即将数据集分成5等份,其中1份作为测试集,其余4份作为训练集,进行循环实验,得到5次分类结果。
本文的用户就医意图识别本质是多分类问题,因此采用文本分类器中常用的评估指标来对每种类型进行评价,即准确率P、召回率R以及二者的综合评价F-measure值,如式(10)~ (12)所示:
P=TP/(TP+FP)
(10)
R=TP/(TP+FN)
(11)
F-measure=2RP/(R+P)
(12)
其中:属于类A的样本被正确分到类A中,记这一类样本数为TP(True Positive);属于类A却被错误分到类A以外的其他类,记这一类样本数为FN(False Negative);不属于类A被正确分到类A以外的其他类,记这一类样本数为TN(True Negative);不属于类A却被错误分到类A中,记这一类样本数为FP(False Positive)。
关于整体性能的评价,用准确率P、召回率R和F-measure的期望,其中每种类型的权重与其对应语料数量成比例。

表2 实验语料举例
3.2 参数设置
BTM-BiGRU混合模型的参数设置中,BTM部分,将主题数设为K=8,α=50/K=6.25,β=0.01,在不影响实验效果的情况下选取主题-词概率分布中前N=2个词作为文档特征。此基础上得到主题-词分布如表3所示。在word2vec时,设置词向量维度为100。在BiGRU这部分设置输出维度为128。另外,设置训练过程中batch_size=32,为防止数据过拟合,还应使用dropout[19]与L2正则化进行约束,其中dropout应用于BiGRU层与Softmax分类层之间,并且dropout=0.25,而L2正则化则应用于最终的Softmax层。

表3 主题-词分布
3.3 实验结果对比与分析
实验环境搭建在VMware Workstation+Ubuntu+Linux下。实验中,首先需要对上述实验数据进行清洗,去除数据中的杂质文本,然后采用jieba分词工具进行分词,之后使用 Google开源提供的word2vec进行词向量模型的训练以量化文本。
3.3.1 不同方法效果比较
本文为与现有方法作更好对比,除基于BTM和BiGRU单模型外,还比较传统模板匹配、SVM分类方法以及文献[20]中提到目前较好的基于卷积和长短期记忆网络(Convolution Neural Network and Long-Short Term Memory Network,CNN-LSTM)的方法。CNN-LSTM利用CNN能够获取深层特征的优点,先对用户聊天文本提取局部代表性特征,然后为保证文本时序性,按照卷积先后顺序重新组合,再依次输入LSTM中进行上下文学习,最后得到较为理想的分类结果。不同方法下,整体性能表现如表4所示。
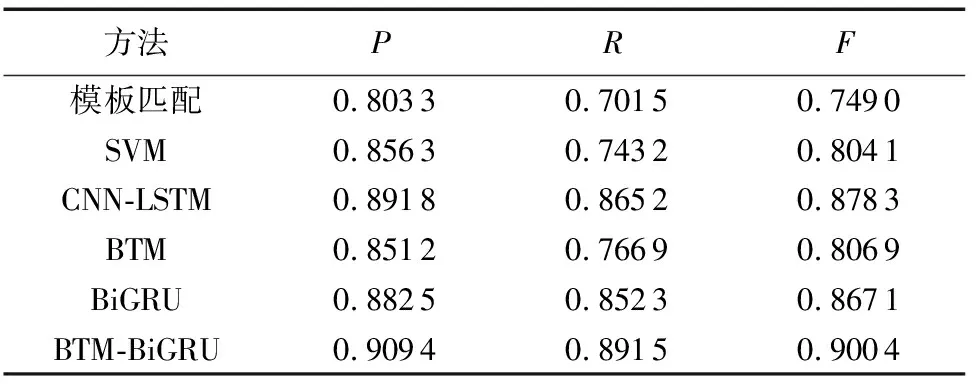
表4 意图识别实验结果
实验结果表明,在聊天机器人中用户就医意图识别任务上,本文的BTM-BiGRU方法效果最好。对比基于BTM、SVM方法与本文方法的实验结果,说明了BiGRU的优势,它能够充分地利用上下文建模。对比基于BiGRU、CNN-LSTM方法与本文方法的实验结果,则证明本任务上使用BTM挖掘的主题特征作为循环神经网络的输入效果更好。虽然基于模板匹配方法的效果不错,但其需要事先获取意图模板,比较费时费力,而且一旦模板不准确,效果将很差。
3.3.2 不同方法时间复杂度比较
实际应用中,不仅考虑方法效果,也需要关注其时间复杂度。考虑到传统基于模板匹配的意图识别方法,其模板获取所花费时间远远多于其余五种方法,因此这里主要比较基于SVM、CNN-LSTM、BTM、BiGRU以及BTM-BiGRU的方法执行时间,如表5所示。
这四种方法训练模型时均涉及迭代,迭代次数不同所用时间也就不同,这里均以最终实验效果最好为准得到各自执行时间。结果表明,时间最短的是基于SVM的方法,时间最长的是CNN-LSTM,这体现了GRU的优势,相比LSTM能够节省训练时间。因此无论从方法效果还是时间复杂度上考虑,本文提出的BTM-BiGRU方法都是行之有效的。
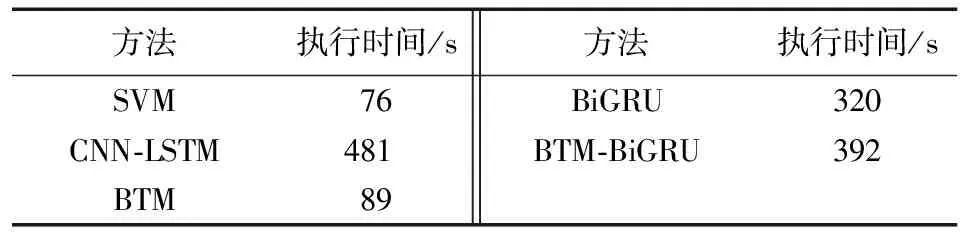
表5 各方法执行时间
4 结语
在线医疗聊天机器人中,如果能在聊天过程中识别出用户就医倾向,将便于进一步为用户提出合理治疗建议以及推荐相应科室。本文将任务当作文本分类问题,并针对医疗聊天文本的特点,提出了基于短文本主题模型和双向门控循环单元的意图识别模型BTM-BiGRU来进行用户就医意图识别。实验结果表明,该混合模型的整体分类准确率优于传统的用户意图识别方法以及目前较好的CNN-LSTM方法。
本文在不同阶段利用了BTM和BiGRU提取特征,后续工作将在特征工程上作进一步研究,寻找更好方法进行医疗聊天文本特征提取,从而继续提高聊天机器人中用户就医意图识别的效果。
