航空发动机试飞趋势监控模型数据样本容量优化
2018-07-23潘鹏飞马明明
高 扬,潘鹏飞,马明明
(中国飞行试验研究院,西安710089)
1 引言
基于试飞数据的模型辨识技术在航空发动机飞行试验中的作用越来越大,已成为“预测—飞行—比较”试飞模式的重要基础[1-3]。数据的质和量是决定航空发动机试飞数据模型好坏的关键因素,一方面需要高质量的试飞数据,即试飞数据中要包含尽可能多的发动机技术状态信息;另一方面需要尽可能提升每一个技术状态中所包含的数据量,使发动机试飞数据模型既能在预测包线内性能优异,又有可能在非样本点上具有更好的推广性能[4-10]。
航空发动机飞行试验是在真实条件下对发动机工作质量进行检验,通常参加试飞的发动机的技术状态仍处在不断完善和调整过程中,意味着不同技术状态下的试验数据样本库有限,试验数据具有很大的不均匀性,实际应用中会导致不必要的建模误差[1-5]。数据样本容量和特征分布是数据驱动模型精度的主要影响因素,已有学者针对数据驱动建模中的样本充分性、特征完备性进行了深入研究[3-7,9-12]。由于发动机飞行试验数据获取的成本和周期限制,为建立实用化的发动机趋势监控模型,有必要探索模型辨识中所必须的最小数据样本容量。
本文基于对某型涡扇发动机全部飞行试验数据的分析,建立了该发动机全状态趋势监控模型。以数据样本库中各个样本点之间的欧式距离为优化函数,以最大化样本点之间的欧式距离的同时最小化模型的预测误差为目标,基于遗传算法进行优化分析,确定出了该型涡扇发动机趋势监控模型的最小需求数据样本库,并在实际科研试飞中进行了推广应用。
2 航空发动机趋势监控模型
以数据为基础建立发动机趋势监控模型。模型以三层前向神经网络为基础,同时在神经网络输入层中考虑输入参数和输出参数的历史延迟数据。该模型结构属于NARX非线性模型,但与常规NARX非线性模型相比,文中采用人工神经网络替代了常规 NARX 模型中的非线性函数[1-5,11,12,14,15],其数学模型见公式(1),采用的神经网络模型拓扑图见图1,模型采用的输入输出参数列表见表1。
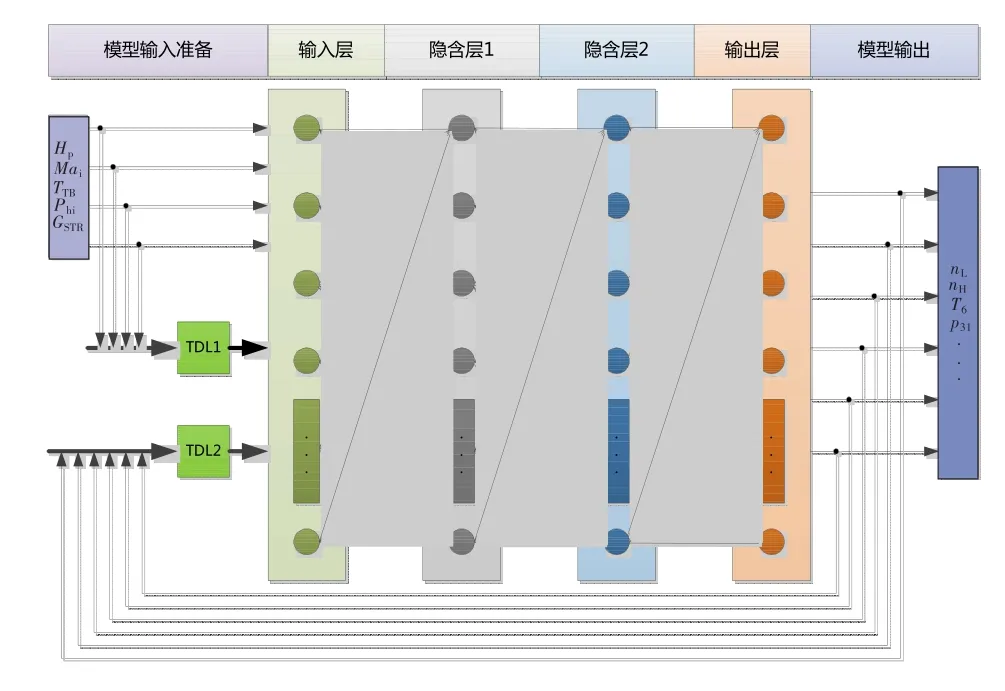
图1 基于神经网络的发动机趋势监控模型结构Fig.1 The topology structure of neural network based on aero-engine trending monitoring
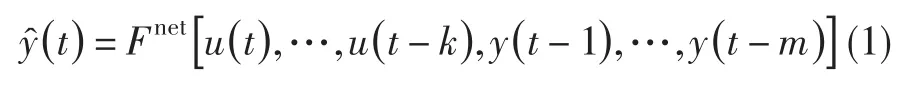
其中,Hp为气压高度,Mai为飞行马赫数,TTB为大气总温,Phi为油门杆角度,GSTR为发动机作战/训练状态指示信号,nH为高压转子转速,nL为低压转子转速,T6为低压涡轮出口总温,p6为低压涡轮出口总压,α1为低压导向叶片角度,α2为高压导向叶片角度,p31为高压压气机出口压力,pf为主燃油总管燃油压力,D8为尾喷口喉部直径。k、m为延迟时间,计算时按经验选取k=10、m=10,同时采用优化算法对神经网络有效延迟参数和隐含层数量进行优化。文中采用的高压转速、低压转速、涡轮后温度神经网络模型的输入输出延迟特征及隐含层神经元数目见表2,表中高压转速输入编码含义见表3。
3 样本容量数学描述
按照飞行试验数据点在飞行包线内分布及发动机工作状态对试验数据样本容量进行优化分析,选用表征工作包线区域的Hp和Mai,及表征发动机工作状态的Phi和nH定义试验样本中任意两点之间的距离。按照Enclidean距离定义,对数据样本库中任意两个数据样本点和,其欧式距离dij定义见图2和公式(2)。
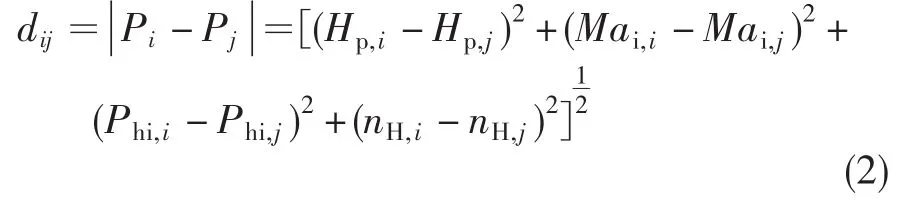
在试验数据样本库中,对于给定的任意两点之间的距离D,若以点Pi为圆心、以d(d≤D)为半径的超球体内邻域存在试验数据样本点,则该部分数据样本包含了和Pi一样的信息,建模过程中将该部分样本点忽略。记给定任意两样本点距离Dc下的发动机模型预测误差为εc,则发动机全状态趋势监控模型的最小数据样本库确定问题可转换成公式(3)描述的优化问题。

表1 航空发动机非线性模型输入输出参数信息Table 1 The input and output information of aero-engine NARX model
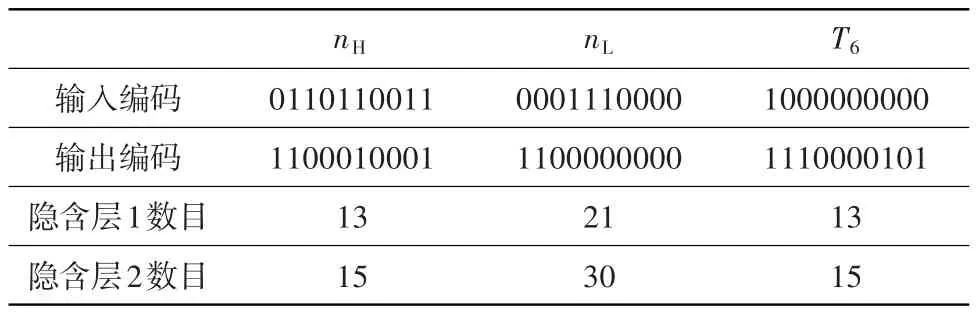
表2 航空发动机神经网络模型结构参数设置Table 2 The structure parameter settings of aero-engine neural network model
表3 高压转子转速输入编码含义Table 3 The input code meaning of high-pressure spool rotating speed
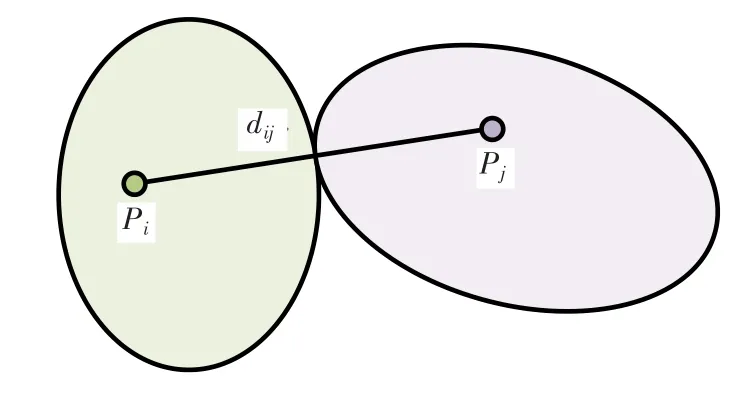
图2 任意两点之间的欧式距离Fig.2 The euclidean distance between any two points
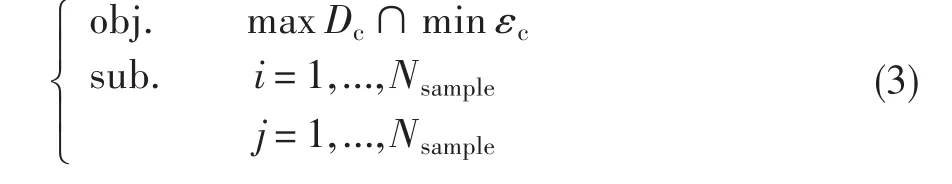
式中:Nsample为样本库中的试验点总数。公式(3)的含义为在所有试验数据样本点上,找到最大可能的距离D,同时确保在该距离确定出的试验数据样本上建立的发动机模型的参数预测误差最小。
4 基于遗传算法的距离优化
采用遗传算法对样本点距离进行优化之前,首先在全部试验数据样本上辨识得到发动机趋势监控模型。记该模型的参数预测误差为εb,并将其作为优化过程中的基准误差。最小数据样本库优化流程框图如图3所示。优化过程主要步骤为:
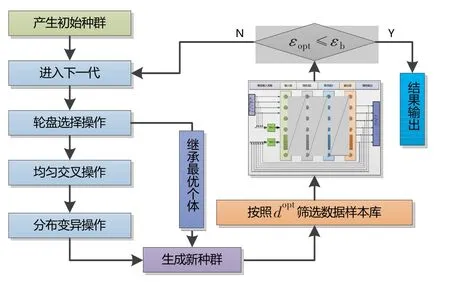
图3 基于遗传算法的最小数据样本库确定流程Fig.3 The optimizing procedure of minimal data sample capacity based on evolving algorithm
(1)选取原始数据样本库DS0中相距最近的两点之间的距离Dmax作为优化的起始距离d=Dmax。
(2)基于遗传算法对d进行均匀交叉、分布变异等操作,结合轮盘操作中继承得到的最优个体,获取优选后的距离dopt。
(3)以DS0为基准,剔除dij≤dopt内的重复样本点,获得筛选后的数据样本库DSopt。
(4)以筛选后的DSopt为基础,对发动机模型进行训练学习,并获取模型的参数预测误差εopt。
(5)若εopt≤εb,则优化过程停止,输出对应的dopt、DSopt及发动机模型;否则进入步骤(2)。
5 应用推广
以某型涡扇发动机科研试飞数据为基础,采用遗传算法对该发动机模型的最小数据样本需求进行优化分析。图4示出了该发动机全状态模型的最小数据样本在飞行包线内的分布。可见,优化后发动机模型的样本需求从原始12 721个样本点减少至369个样本点,通过合理安排试飞科目和内容,只需5~6个架次的试飞数据即可建立发动机模型。基于该模型,可以在图中工作包线的空白区域扩展试飞时监控发动机工作状态,提高飞行试验的安全性。同时,当航空发动机技术状态发生调整时,在优化后的样本点上有针对性地重新录取测试数据,可大幅度降低试飞架次需求,提高试飞效率。
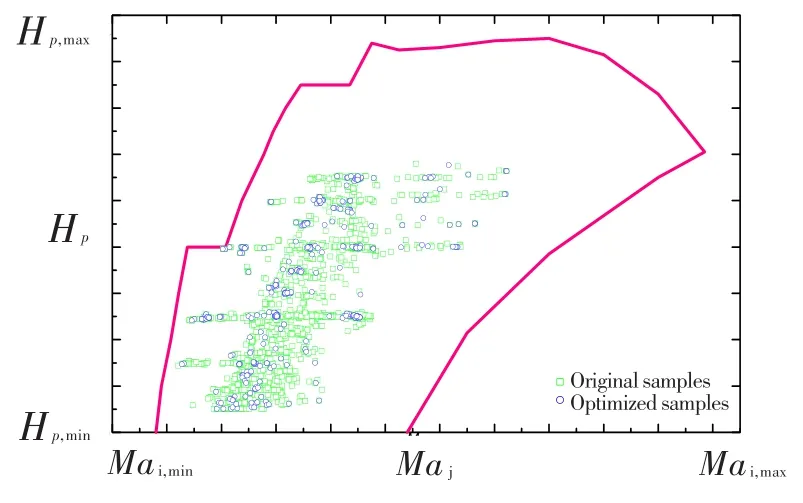
图4 优化后的涡扇发动机趋势监控模型最小数据样本分布Fig.4 The optimized data sample distribution in flight envelope of aero-engine trending monitoring model
6 结论
采用遗传算法对某型涡扇发动机全状态趋势监控模型所需的最小数据样本进行了优化,并在实际科研试飞中进行了推广应用。通过有针对性地安排试飞内容,只需要5~6个架次试飞数据即可确定发动机的实时趋势监控模型。主要研究结论如下:
(1)基于遗传算法对数据样本之间的欧式距离进行优化,可获得涡扇发动机模型所需的最小数据样本库,大幅度节省试飞数据模型辨识周期;
(2)所建立的发动机模型最小数据样本特征库具有通用性,可直接推广至其他类似发动机的仿真建模过程中,缩短仿真建模周期;
(3)实现了最小数据样本库中包含最多数据特征,降低了发动机神经网络模型复杂度,提升了发动机模型在非样本点上的表现性能。
