身份信息与位置信息的加工进程及语境预测性的影响*
2018-06-22徐迩嘉
徐迩嘉 隋 雪
(辽宁师范大学心理学院; 儿童青少年健康人格评定与培养协同创新中心, 大连 116029)
1 引言
人们在区分相同字母组成的单词时, 如 salt(盐)和slat (板), 依靠的是相同字母的位置信息, 也就是说, 字母在英文单词中的作用是通过两方面信息体现的, 即身份信息(identity information)和位置信息(location information)。在汉语词汇加工中, 读者也需要通过词素身份信息来确认组成词汇的字是什么, 而出现“人工”和“工人”这对身份信息相同的词时, 就需要依靠位置信息来区分两个词语。在拼音文字的研究中发现, 读者对字母的身份信息和位置信息编码的进度是不同的(Rayner & Fischer,1996)。与替换单词内个别字母(substitution-letter,SL)形成的非词(例如:由bridge替换字母 d变为 t形成的 britge)相比, 单词内字母换位(transpositionletter, TL)形成的非词(将bridge内部的字母dg进行换位变为 gd形成的非词 brigde), 更容易被识别成与它相对的真词(bridge) (Perea & Carreiras, 2006),这种现象称为字母换位效应(transposition-letter effect,TL effect), 中文也翻译成转置字母效应(滑慧敏,顾俊娟, 林楠, 李兴珊, 2017)。TL非词能够在一定条件下激活原词的词汇理解和表征(Pagán, Paterson,Blythe, & Liversedge, 2016; Sánchez-Gutiérrez &Rastle, 2013)。在阅读情况下, TL非词比SL非词能够产生更大的预视效应(Johnson, Perea, & Rayner,2007)。这说明, 在词汇识别和加工过程中, 字母的身份信息比位置信息更重要, 位置信息更加灵活。研究也发现, 字母身份信息和字母位置信息的编码过程是分离的。对词语内部不同位置的字母进行换位, 其效果也是不同的。换位发生在词首、词尾比发生在词内部对词汇识别的破坏性更大(White,Johnson, Liversedge, & Rayner, 2008; Yakup, Abliz,Sereno, & Perea, 2014)。关于识别的时间段, 两种信息的作用也不同, 在视觉词汇识别的早期阶段, 字母位置信息的作用很小(Luke & Christianson, 2012)。
依托拼音文字对字母身份信息和位置信息的研究, McClelland和Rumelhart (1981)提出交互激活模型(interactive activation model)并主张, 词汇识别过程中, 字母位置固定, 词汇识别依赖于词汇中包含的字母信息(what)和字母位置(where)。Norris(2006)提出的贝叶斯读者模型(the Bayesian reader model)主张, 词汇中的字母与他们的特定位置相联系。Whitney (2001)提出的顺序编码模型(sequential encoding regulated by inputs to oscillations within letter units, the SERIOL model)主张, 词汇加工有5个水平:节点、视网膜、特征、字母、双字母组合、词汇。在双字母组合水平中, 字母探测转为对双字母对的探测, 例如 card (卡片)一词中包含双字母对:ca、cr、cd、ar、ad、rd, 这与换位词crad包含的双字母对是一样的, 而替换词cald包含的双字母对为ca、cl、cd、al、ad、ld, 其中只有三个与原词card是一样的, 因而换位词比替换词更接近本词。Davis (2001)提出自我组织词汇习得与识别模型(self-organizing lexical acquisition and recognition,the SOLAR model)并主张, 每个字母的识别与自我激活水平有关, 第一个字母激活水平最高, 依次递减, 最后一个激活水平最低, 因而位置与激活水平有关, 相邻两个字母激活水平相似。这些理论不同程度地的解释了字母位置加工及换位后产生效应的原因。那么汉语词汇识别中的位置信息更接近哪一个理论解释的情况呢?将在本研究中得到关注。
句子语境下, 词汇信息的识别受语境特性的影响, 如语境预测性高低。读者可以通过上文内容对接下来的内容进行预测, 上下文关系越密切, 预测作用越大。拼音文字的研究发现, 对高预测性词的反应时比对低预测性词的反应时短(Smith & Levy,2013; Whitford & Titone, 2014)。高预测性词比低预测性词被略读的可能性更大, 被注视时间更短, 回视更少(Kretzschmar, Schlesewsky, & Staub, 2015)。在中文关于预测性的研究中, 控制关键词的首字频率、尾字频率和整词频率, 发现词频的影响在词素位置颠倒的情况下也会发挥作用(卞迁,崔磊, 闫国利, 2010)。而在篇章阅读中, 低预测性目标词比高、中预测性目标词的注视时间长, 高预测性目标词被跳读的概率高(Liu, Reichle, & Li, 2016)。
在拼音文字的研究中, 发现语境预测性和词频与换位效应有交互作用(Luke & Christianson, 2012),但这种交互作用在中文词汇加工和文本阅读中并没有得到一致性的验证。关于汉语词汇的构成, 首先由笔画组成部首, 再由部首组成词素, 又由词素组成词汇, 最后由词汇通过语法结构组成句子。在拼音文字研究中, 字母是组成单词的最小单位, 而在中文研究中, 词素通常被定义为形态和意义最小的语言单位(张玲燕, 金檀, 田朝霞, 2013)。笔画换位和部首换位与英文中字母换位的对应情况都是不理想的, 因为汉语中不仅有 8种基本笔画, 还有很多复杂笔画, 而且这些笔画并不是水平排列的,换位后会导致换位后的汉字无法识别; 而汉字部首之间有左右结构和上下结构, 部首换位在很多情况下是无法进行的。因此, 英文字母和中文汉字并不能完全类比(滑慧敏等, 2017), 无论怎样进行实验设计, 英文的换位效应研究都不可能在中文中复制,但是我们可以借鉴其研究方法, 研究汉字词素位置信息和身份信息加工的特点。研究者采用语义启动范式, 使用汉语逆序词(如“工人”−“人工”)作为实验材料, 考察不同SOA (57 ms, 157 ms, 314 ms) 下的启动效应, 发现在SOA为157 ms时, 正常的语义启动和逆序启动两种效应之间没有显著差异, 都能缩短联想词的判断时间; 而在加工的早期(SOA为57 ms)和晚期(SOA为314 ms), 逆序词的启动明显弱于正常的语义启动, 这一结果说明, 词素表征的激活经历了由弱到强再逐渐减弱的过程, 词素位置信息的加工晚于词素身份信息的加工, 词素位置信息的加工发生在词汇加工的晚期(彭聃龄, 丁国盛,王春茂, Taft, 朱晓平, 1999) 。这个研究与换位的研究略有不同, 汉语逆序词本身也有一定的含义, 换位后的词语也能提取汉语中对应的语义, 这也会对词素身份信息和位置信息的作用产生影响。新近研究(Gu, Li, & Liversedge, 2015)已经发现中文字序编码与位置信息编码不同。字序编码发生在阅读的早期阶段, 而位置信息编码没有这么严格。所以,为了避免字序加工的影响, 本研究避免了换位后产生逆序词的情况。在实验 1中, 使用原词(如“经济”)、换位非词(如:由原词“经济”通过首字和尾字换位形成的假词“济经”)、两种替换词(如:由原词“经济”通过使用无意义的符号对首字进行替换, 形成首字替换非词“吅济”和对尾字进行替换, 形成的尾字替换非词“经吅”)以及无意义符号非词(吅吅)作为启动词, 通过比较不同条件的启动效应, 探究词素位置信息和身份信息的加工进程, 并以无意义的符号启动(无关启动)为基线, 比较原词条件、换位条件、替换条件的启动效应之间的差异。首字替换和尾字替换两个条件的设置, 是为了比较身份信息在词语的不同位置发生改变后的差异。实验1采用启动范式, 研究词汇单独呈现时, 词素身份信息和位置信息的加工进程, 并通过改变启动词呈现时间来探究启动词换位效果的延续性。本文参考了彭聃龄等人的研究及相关英文研究(Vergara-Martínez,Perea, Gómez, & Swaab, 2013), 结合本实验特点选用了80 ms, 150 ms, 300 ms三个启动时间。
实验1的结果能够反映, 在词汇单独呈现情况下, 汉语词素的身份信息和位置信息加工过程, 以及启动时间的影响。但是身份信息与位置信息的作用以及延续性, 在句子语境下, 是否会因为语境预测性因素的加入有所改变呢?为了探究这个问题,设计了实验 2, 通过记录被试阅读句子过程中的眼动特征, 探究词素位置信息和身份信息在句子阅读中的作用, 同时操纵语境对目标词的预测性, 研究语境的预测性对词素位置信息和身份信息加工的影响。实验2能够考察句子呈现条件下, 词汇身份信息和位置信息加工的特点, 以及语境预测性的调节作用, 但是, 不能回答词汇身份信息和位置信息加工的时间进程。因此, 设计了实验3, 采用边界范式, 通过调节目标词预视时间来统一测量位置编码的时间进程及预测性对时间进程的影响。采用边界范式对词边界对汉字顺序编码的影响的研究(Gu &Li, 2015)有效地考察了四字词的情况。说明边界的设定可以考察 4个字的空间, 本研究是双字词, 边界的作用可以得到保证。
换位非词是位置信息错误, 身份信息是完全正确的; 而词素掩蔽词是位置信息正确, 而身份信息错误。两者比较可以考察身份信息和位置信息加工的分离。另外, 语境的预测性会影响目标词被加工的深度(Cona, Arcara, Tarantino, & Bisiacchi, 2015),自上而下的语义预测与自下而上的词汇通达能够相互作用, 高预测性的目标词可以不必完全加工,因此对词素位置信息和身份信息完整性的要求会降低; 而低预测性的目标词, 对位置信息和身份信息的完整性要求很高, 并且, 位置信息的改变对阅读的影响比身份信息的改变小, 并且如前文中提到的, 已有研究证明通常词首的字母或者词首的字更重要(Schotter, Angele, & Rayner, 2012), 且在句子阅读中, 存在副中央凹预视效应, 能够通过副中央凹的预视来加工目标词(臧传丽, 张慢慢, 岳音其,白学军, 闫国利, 2013)。本研究假设, 汉语双字词加工中位置信息的作用相比于身份信息更灵活, 在词汇单独呈现时, 随着加工时间的延长, 位置信息与身份信息的作用逐渐接近, 在句子阅读中, 语境预测性能够促进身份信息和位置信息的加工, 高预测性情况下, 二者的作用相似, 低预测性情况下,位置信息的作用较身份信息更为灵活。目标词的预视时间短, 位置信息的作用较身份信息的作用小,随着预视时间延长, 位置信息和身份信息的作用逐渐接近。与首字替换词对句子阅读的影响相比, 尾字替换词对句子阅读的负作用更小。
2 实验1:词汇加工早期位置信息的作用
2.1 方法
2.1.1 被试
被试为 20名在校大学生, 均为右利手, 年龄21~24岁。被试的裸视或矫正视力正常, 均不了解实验目的。母语均为汉语。每个被试都阅读了《知情同意书》, 并签字同意。所有被试均不知实验目的, 实验结束后获得学分和适当报酬。
2.1.2 设计和材料
选取了90个中频双字词作为实验材料(如:手机), 并对这些双字词进行如下处理:(1)换位:将原词的词素换位形成新的换位假词(如:机手, 材料处理时保证换位后的非词在语音和语义上均为无意义的假词); (2)首字替换:将原词的首字用无意义符号“吅”替换, 形成首字替换假词(如:吅机); (3)尾字替换:将原词的尾字用无意义符号“吅”替换, 形成尾字替换假词(如:手吅)。并将材料分为 3组, 每组的启动词呈现时间不同, 实验材料的基本情况见表1。
本实验为 3(启动时间)×5(启动类型)两因素被试内设计, 被试对单独呈现的词汇进行真假词判定。启动时间分别为80 ms、150 ms和300 ms, 5种启动条件分别为:(1)原词启动:用原词启动目标词, 如“经济”启动“经济”; (2)换位启动:启动词为目标词的换位词, 如“济经”启动“经济”; (3)首字替换启动:用首字替换非词启动目标词, 如以“吅济”启动“经济”; (4)尾字替换启动:用尾字替换非词启动目标词, 如以“经吅”启动“经济”; (5)无关启动(无意义符号):由无意义符号“吅吅”启动目标词, 如以“吅吅”启动“经济”。实验材料举例见表2。
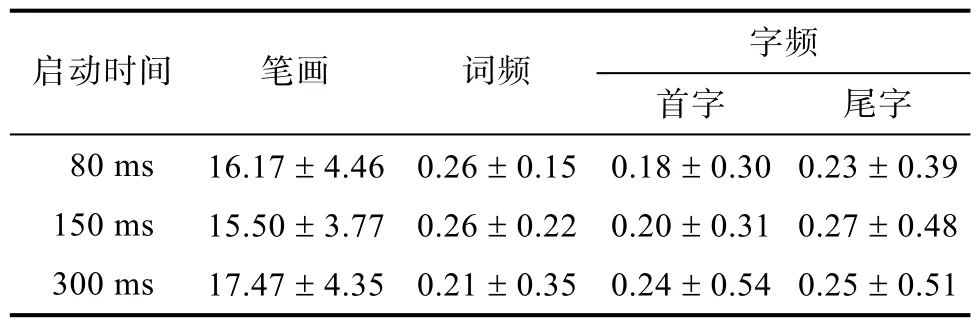
表1 实验材料的基本情况(M ± SD)

表2 不同启动条件真假词判断任务的材料示例
5种条件下, 用不同启动词来启动同一目标词,对材料分组并进行了拉丁方匹配, 在一个List中同一组启动词−目标词(如表1)只呈现一对词, 共5个List, 共形成 450个实验项目。另外每个 List加入45个填充项目, 填充项目的目标词均为假词。每个List总共呈现135个试次, 进行伪随机处理。
2.1.3 实验程序
实验使用台式联想计算机, 通过 E-prime软件呈现并收集数据。每个试次的程序为:“+”字注视点→被试按键→启动词→“####”掩蔽刺激呈现50 ms→目标词→被试按键判断。实验材料以白底黑字呈现。每个被试均为单独测验, 眼睛离屏幕为60 cm, 启动词和目标词均为40号宋体加粗, 每个目标刺激所占的视角约为1.9°。指导语如下:屏幕中央会出现注视点, 请您按键, 按键后, 注视点消失, 然后出现刺激“####”, 这个刺激消失后, 出现目标词, 请您判断是不是真词?如果是真词, 请按F键, 如果不是真词, 请按J键(被试间进行平衡)。被试阅读指导语后, 进行 15个试次的练习, 然后,进行正式实验。
2.2 结果
数据分析时, 填充材料不参与分析, 实验中被试的平均正确率为97.72%, 我们删除了低于300 ms或高于3000 ms的数据15个, 总删除率为0.8%。反应时结果见表3。

表3 三种启动时间和5种启动类型的反应时(M ± SD)
对反应时结果进行方差分析, 结果表明:启动时间的主效应显著,
F
(2, 236) = 67.82, 偏η= 0.37,p
< 0.01, 事后检验(Least Significant Difference,LSD
)发现, 随启动时间的增加, 目标词的反应时缩短, 三种启动条件下的反应时均差异显著(p
s <0.01)。为了分析位置信息和身份信息的改变对启动效应的影响, 将无意义符号启动条件做为基线, 其他条件与用无意义符号条件的反应时相减, 结果见图1。
图1 不同条件下的启动效应
以启动效应为因变量, 启动条件和启动时间为自变量, 进行方差分析, 结果表明:启动时间的主效应不显著,
F
(2, 236) = 2.07, 偏 η= 0.02,p
>0.05。启动词类型的主效应显著,F
(3, 354) = 52.30,偏η= 0.31,p
< 0.01。LSD
检验发现, 除了换位条件与尾字替换条件之间的启动效应差异不显著外(p
> 0.05), 其他条件的启动效应之间均差异显著(p
s < 0.01)。启动类型和启动时间交互作用显著,F
(6, 708) = 10.08, 偏 η= 0.08,
p
< 0.01。80 ms的启动效应, 换位条件与首字替换差异不显著(
p
> 0.05), 两者与原词(p
s < 0.01)、尾字替换(p
s< 0.01)差异均显著, 原词效应与尾字替换效应差异不显著(
p
> 0.05)。150 ms的启动效应, 换位效应与原词效应没有显著差异(p
> 0.05), 两者与两种替换效应均差异显著(p
s < 0.01), 两种替换条件之间差异不显著(p
> 0.05)。300 ms的启动效应, 只有换位效应与尾字替换效应差异不显著(p
> 0.05), 其它条件效应之间均差异显著(p
s < 0.01)。2.3 讨论
实验 1的结果表明, 在启动时间为 80 ms时,换位效应与首字替换效应差异不显著, 与尾字替换和原词启动效应差异显著, 这与拼音文字的实验结果不一致(Luke & Christianson, 2012; Kezilas,McKague, Kohnen, Badcock, & Castles, 2017)。在中文词语单独加工的早期阶段, 如果词素的位置错误,与身份错误一样对词汇加工造成影响, 此时, 词素的身份信息和位置信息都很重要。身份信息正确,位置信息错误, 启动效应也无法与原词相比。换位与首字替换差异不显著, 说明, 不同位置的词素激活程度不同, 与SOLAR模型观点一致(Davis, 2001),第一个字激活水平高于第二个字。而在启动时间为150 ms时, 换位启动与原词启动差异不显著, 与替换启动差异显著, 说明身份信息破坏比位置信息破坏影响更大。在这个阶段, 词素位置有了一定灵活性。而启动时间为300 ms时, 换位非词与尾字替换词出现了差异不显著的情况, 在此阶段启动词位置信息和身份信息的作用对于单独呈现的目标词而言都起到很大作用, 但从结果来看, 无法说谁起的作用更大。
比较三种启动时间下的首字替换词和尾字替换词启动条件可以发现, 尾字替换词对目标词的启动效果更大, 说明首字的替换对词语位置信息和身份信息的破坏更大, 这与拼音文字换位研究的结果是一致的(White et al., 2008; Yakup et al., 2014), 说明身份信息破坏的位置, 对词语识别的影响是不同的, 具有跨语言的一致性。词首字母具有内在的重要性, 更多的与高级认知功能有关, 而词尾字母与低水平的视知觉有关(滑慧敏等, 2017)。将三个阶段联系起来分析可以发现, 在识别单独呈现的汉语词汇时, 在识别的早期, 即使身份信息一致, 位置信息的改变也会影响目标词的识别。而随加工时间的延长, 位置信息的作用逐渐减小, 身份信息的作用逐渐增大。到了加工的晚期, 身份信息和位置信息的作用逐渐一致, 无法判断此时哪个作用更大, 而且此时身份信息在词语中的位置对启动效应的影响很大,这与中文词素位置作用的研究结果是一致的(梁菲菲, 王永胜, 白学军, 2016)。
实验1研究了词汇单独呈现时, 位置信息与身份信息作用的时间进程。而对于时间进程的研究,大多采用脑电(ERP)进行, 研究发现(Vergara-Martínez et al., 2013), 在刺激呈现260 ms之后, 真假词判断有显著差异, 而在刺激呈现360 ms之后, 词语的频率会影响真词与换位假词的判断。可见, 中文词汇单独呈现时, 在刺激呈现的早期阶段, 位置信息对词语的识别加工作用更大, 而随着时间的推进, 对词语进行更深度的加工时, 词汇的身份信息、词频等因素都会产生影响。
3 实验2:语境预测性对词汇位置信息加工的影响
3.1 方法
3.1.1 被试
在校大学生 50名, 均为右利手, 年龄 19~24岁。被试的裸视或矫正视力正常, 均不了解实验目的。母语均为汉语。每个被试都阅读了《知情同意书》, 并签字同意。所有被试均不知实验目的, 实验结束后获得学分和适当报酬。
3.1.2 设计和材料
采用 4(关键词类型)×2(预测性)两因素被试内设计。关键词类型为:
a
原词、b
换位词、c
首字替换、d
尾字替换。预测性为:H
对目标词预测性高、L
对目标词预测性低。实验使用了64个句子框架, 是基于32对双字词编出的, 选自现代汉语词频词典, 由50名不参加实验的被试完成填词任务, 形成句子框架(如:“这批产品降价是为了扰乱中国的____”), 要求被试填入双字词, 75%以上几率被填出则为高预测性词语(如“市场”), 25%以下被填出则为低预测性词语, (如“经济”), 相应将高低预测性词语颠倒的句子框架(如“出台这些政策是为了复苏国家的____”), 同样也在实验前进行填词任务。对于32对目标词, 在4种条件下控制它们的词素位置与词素信息:
a
原词,即以单词正确的顺序和正字法呈现(如“市场”);b
换位, 以错误的位置呈现词素, 即将双字词的两个字位置颠倒(如“场市”);c
首字替换, 处于词首位置的字由符号“吅”替换呈现(如“吅场”);d
尾字替换, 处于词尾位置的字由符号“吅”替换呈现(如“市吅”)。在实验前, 由 28名不参加实验的被试对句子通顺性进行5点评分, 1为不通顺, 5为通顺, 句子的通顺性平均分为4.32。本实验的材料对同一个目标词编制高−低预测性的句子框架, 因此目标词的词频、字频、笔画等本身属性已经进行了控制。实验材料举例见表4、表5。
表4 句子阅读任务的材料举例
表4这组材料是同一个句子框架, 含有“市场−经济”作为关键词的情况。这个句子框架对于“市场”是高预测性的, 对于“经济”是低预测性的。具体关键词有4种情况。

表5 句子阅读任务的材料举例
表5这组材料是同一个句子框架, 含有“市场−经济”作为关键词的情况。这个句子框架对于“经济”是高预测性的, 对于“市场”是低预测性的。具体关键词有4种情况。
3.1.3 实验仪器
采用EyeLink 1000眼动仪追踪眼动轨迹并记录被试右眼的眼动数据。眼动仪的采样率为1000次/ms。刺激在一个 21英寸的 DELL显示器上呈现, 分辨率为1024×768像素, 刷新率为75 Hz。被试眼睛与屏幕的距离为68 cm。刺激以19号宋体形式呈现,每个汉字在屏幕上占了 25×25像素(字间距为 3像素)。每个汉字成0.67°视角。
3.1.4 实验程序
实验中, 每个被试单独进行实验。首先向被试介绍实验仪器和实验环境, 之后, 被试开始阅读指导语, 以了解实验目的, 如果有问题先向主试提问,确认后进行实验。首先是8个试次的练习实验, 确保被试完全了解实验后, 进行正式实验。正式实验中, 有 54个句子后面跟随一个与之相关的判断题,以便被试真正理解了句子(其中36个问题的答案为“是”, 18个问题的答案为“否”), 实验过程中的句子随机呈现, 实验开始和每个试次前都会进行校准,整个实验过程大约需要15~20分钟。
3.2 结果
本研究使用Eyelink 1000眼动仪自带的数据处理软件 Data Viewr将数据导出后, 采用 Microsoft Office Excel 2007软件对数据进行管理和分析, 然后使用SPSS for windows 16.0对数据进行统计分析及处理。回答句子后出现的判断题, 被试的平均正确率为 86%, 由于实验任务为阅读并回答问题, 较为困难, 因此我们调整了标准正确率, 删除了正确率低于80%的2名被试的数据, 并排除了注视点持续时间小于80 ms或大于1200 ms的数据, 占总数的1.63%。运用SPSS 16.0统计软件包对其他数据的具体指标进行分析。
根据本研究的实验假设和目的, 参考实验设计,本研究选取目标词内的指标:首次注视持续时间(first fixation duration, FFD)、首次注视的注视次数(first run fixation count, FRFC)、凝视时间(gaze duration, GD)、总注视时间(total time, TT)、总注视次数(fixation count, FC)这样5个指标; 以及与目标词相关的整句指标:从目标词向前的回视(regression out, RO)、向目标词的回视(regression in, RI)、整句注视时间(sentence duration, SD)以及整句注视次数(sentence fixation, SF)。
3.2.1 兴趣区内指标
兴趣区内指标分析是指对不同条件下, 对目标词上的眼动指标进行分析。旨在了解不同预测性和不同的词语身份信息、位置信息条件下, 对兴趣区的加工情况。
具体指标的含义为:首次注视持续时间(first fixation duration, FFD), 是指落在兴趣区中第一个注视点的持续时间; 首次注视的注视次数(first run fixation count, FRFC), 是指在第一次注视兴趣区到进入下一个兴趣区之前, 所有注视次数的总和; 凝视时间(gaze duration, GD), 是指从第一次注视到离开兴趣区前的凝视时间; 总注视时间(total time,TT), 是指在当前兴趣区中所有注视时间的总和。总注视次数(fixation count, FC), 是指在当前兴趣区所有注视次数的总和。描述统计的结果见表6。
对兴趣区内4个眼动指标进行重复测量方差分析, 结果如下:
(1)首次注视持续时间, 预测性主效应不显著,
F
(1, 818) = 0.45,p >
0.05, 偏 η= 0.10; 但位置信息的主效应显著,F
(3, 2454) = 6.68,p <
0.01,偏η= 0.98, 多重比较(LSD
)结果显示:原词与换位非词(p =
0.023)、两种替换非词之间存在显著差异(p <
0.01), 几种非词之间均不存在显著差异(p
s >0.05)。两个变量的交互作用不显著(p
> 0.05)。(2)首次注视的注视次数, 各条件均没有显著差异(
p
> 0.05)。(3)凝视时间, 预测性主效应显著,
F
(1, 818)= 17.06,p
< 0.01, 偏η= 0.11; 高预测性条件下,对目标词的凝视时间短于低预测性条件下的凝视时间; 位置信息主效应显著,F
(3, 2454) = 88.27,p
< 0.01, 偏 η= 0.76。多重比较(LSD
)发现, 原词条件下的凝视时间为517 ms、换位非词条件下的凝视时间为574 ms和两种替换词的凝视时间分别为尾字替换586 ms, 首字替换615 ms, 几种条件之间均存在显著差异(p
s< 0.01)。两个变量的交互作用显著,
F
(3, 2454) = 10.89,p
< 0.01, 偏 η=0.10。在高预测性条件下, 原词条件与首字替换条件差异显著(p =
0.018), 与其余条件之间差异均不显著(p
s > 0.05), 换位非词条件与首字替换词条件差异也显著(p
= 0.041), 与其余条件之间差异不显著(p
s > 0.05), 两种替换条件之间差异不显著,p
>0.05。
而在低预测性条件下, 首字替换词条件与其他条件之间均差异显著(p
s < 0.01), 其他条件之间均没有显著差异(p
s > 0.05)。(4)总注视时间, 预测性主效应显著,
F
(1,818) = 5.57,p
= 0.025, 偏η= 0.66; 高预测性条件下, 对目标词的总注视时间短于低预测性条件下的总注视时间; 位置信息主效应显著,F
(3, 2454) =3.78,p
= 0.031, 偏η= 0.82。多重比较(LSD
)发现,原词条件与换位非词和首字替换词条件之间存在显著差异(p
< 0.01), 但与尾字替换词条件差异不显著(p
> 0.05), 而换位非词与首字替换词和尾字替换词之间不存在显著差异(p
> 0.05)。两个变量的交互作用显著,F
(3, 2454) = 3.28,p
< 0.01, 偏 η=0.75。在高预测性条件下, 原词条件与首字替换词条件的总注视时间差异显著(p
= 0.037), 其余条件差异均不显著(p
s > 0.05), 而在低预测性条件下,原词与尾字替换词条件的总注视时间差异显著(p
<0.01), 原词条件与换位非词条件的总注视时间差异不显著(p
> 0.05), 其余条件均没有显著差异(p
s >0.05)。(5)总注视次数, 预测性主效应显著,
F
(1,818) = 4.99,p
= 0.02, 偏η= 0.61, 高预测性条件下,对于目标词的总注视次数少于低预测性条件; 位置信息主效应不显著,
F
(3, 2454) = 1.43,p
> 0.05,偏 η= 0.38, 两个变量之间存在交互作用,F
(3, 2454) = 4.16,p
< 0.01, 偏 η= 0.86。在高预测性条件下, 各条件之间均没有显著差异(p
s > 0.05)。而在低预测性条件下, 原词条件与换位词(p
= 0.033)、首字替换词条件(p
< 0.01)的总注视次数差异显著,换位词与尾字替换词差异显著(p
= 0.013), 其余条件均没有显著差异(p
s > 0.05)。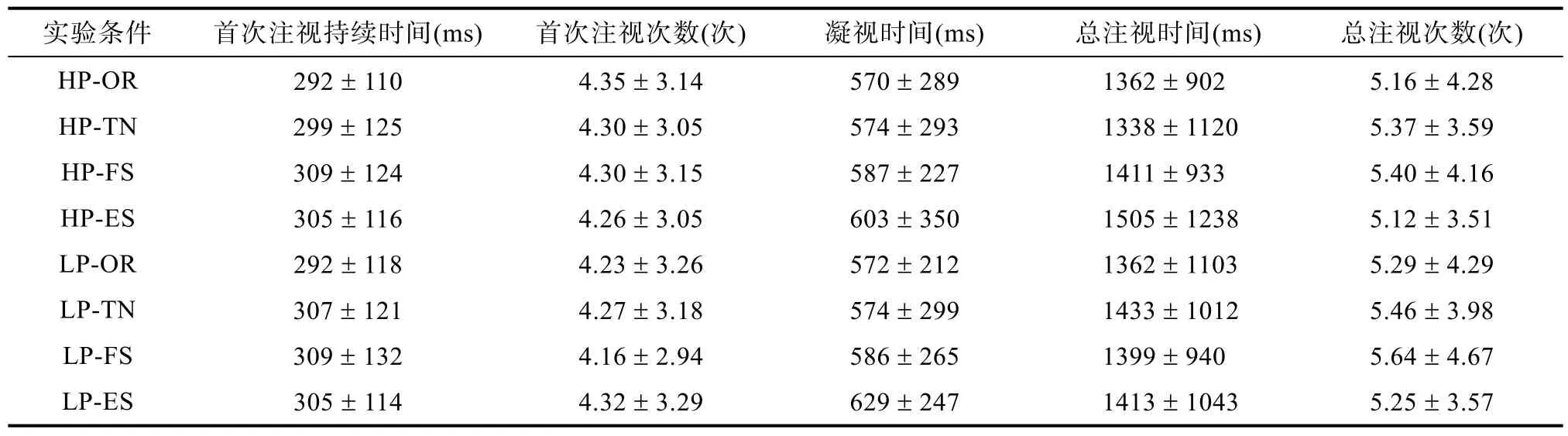
表6 每种实验条件下各兴趣区内眼动指标的平均值和标准差(M ± SD)
3.2.2 目标词相关指标
在阅读加工过程中, 加工到目标词后, 又对目标词之前的内容进行注视, 即从目标词向前的回视(regression out, RO), 这类回视是与目标词加工有关的回视。在加工目标词之后的内容时, 出现向目标词的回视, 这也是加工中需要提取目标词信息时出现的回视, 就是向目标词的回视(regression in,RI)。这两个指标是与目标词相关的指标。在本实验中, 兴趣区之前、之后的内容相同, 被试对兴趣区之前、之后内容的理解应该是一样的, 但由于兴趣区中的词语有不同条件, 所以从兴趣区向前回视和从兴趣区后向兴趣区的回视反应的就是目标词加工的差异。为了探讨目标词加工差异在兴趣区外的表现, 本文增加了这两个指标进行分析。描述统计的结果见表7。
对4个与目标词相关眼动指标进行重复测量方差分析发现:
(1)从目标词向前回视率, 预测性主效应显著
F
(1, 818) = 12.35,p
< 0.01, 偏 η= 0.93; 比较发现, 高预测性条件下, 从目标词向前回视率低于低预测性条件下的回视率; 位置信息主效应显著,
F
(3, 141) = 6.73,p
< 0.01, 偏 η= 0.98, 多重比较(
LSD
)结果表明, 原词条件与换位条件(p
= 0.012)、替换条件(p
s= 0.013)之间均差异显著, 换位条件与两种替换条件(首字条件
p
= 0.013, 尾字条件p
=0.012)之间也差异显著, 两种换位条件直接差异也显著(p
= 0.012)。其中原词条件下的从目标词向前回视率最低, 换位条件下最高。两个变量的交互作用不显著(p
> 0.05)。(2)向目标词的回视率, 预测性主效应显著,
F
(1, 818) = 7.73,p
< 0.01, 偏 η= 0.79; 其中高预测性条件下, 从目标词区域向前回视率低于低预测性条件向前回视率; 位置信息主效应显著,
F
(3,2454) = 3.46,p
< 0.01, 偏 η= 0.78, 多重比较(
LSD
)结果表明, 原词条件与几种非词条件均差异显著(p
s=
0.011), 但几种非词条件差异不显著(p
s>
0.05),两个变量之间的交互作用不显著(p
> 0.05)。(3)整句阅读时间, 预测性主效应显著,
F
(3,1149) = 5.95,p
< 0.01, 偏 η= 0.96, 高预测性条件下的整句阅读时间短; 位置信息主效应也显著,
F
(1, 383) = 11.73,p
< 0.01, 偏 η= 0.93, 多重比较(
LSD
)结果表明, 原词条件与换位条件、首字替换条件(p =
0.045), 尾字替换条件(p =
0.050)之间均差异显著, 尾字替换条件与换位条件(p =
0.046)和首字替换条件(p =
0.035)之间也差异显著, 而换位条件与首字替换条件之间差异不显著(p >
0.05)。预测性与位置信息之间没有交互作用(p >
0.05)。(4)整句注视次数, 预测性主效应显著,
F
(3,1149) = 3.91,p
< 0.01, 偏 η= 0.87, 高预测性条件下的整句注视次数少; 位置信息主效应也显著,F
(1, 383) = 11.04,p
< 0.01, 偏 η= 0.91, 多重比较(
LSD
)结果表明, 原词条件与换位条件差异不显著,与两种替换条件差异显著, 而首字替换与其他三种条件均差异显著, 且次数最多, 尾字替换与换位条件差异不显著, 与其他两种情况差异均显著。同时,预测性与位置信息之间存在交互作用,F
(3,1149) = 4.35,p
< 0.01, 偏 η= 0.76, 进一步分析发现, 在高预测性条件下, 原词条件与换位条件和尾字替换条件差异均不显著(
p
> 0.05), 与首字替换词之间差异显著(p
= 0.015), 其他条件之间差异均不显著(p
s > 0.05)。而低预测性条件下, 原词条件与换位条件差异不显著(p
> 0.05), 与尾字替换词之间差异显著(p
= 0.035), 其他条件之间均差异显著(p
>0.05)。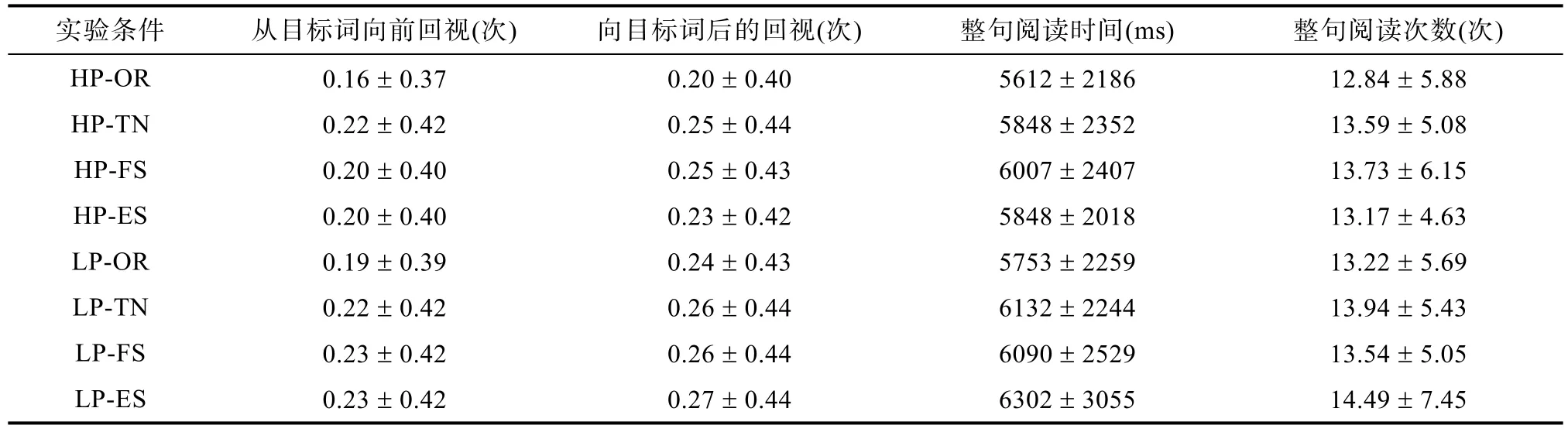
表7 每种实验条件下各与目标词相关眼动指标的平均值和标准差(M ± SD)
3.3 讨论
在实验2中, 使用原词、换位词、首字替换词、尾字替换词作为目标词, 通过编制高预测性及低预测性句子框架, 探究预测性对于位置信息加工的影响。结果发现, 除首次注视持续时间(FFD)和首次注视的注视次数(FRFC)外, 均有预测性主效应, 说明句子的预测性对阅读的影响可以通过眼动指标反映出来。结合目标词内指标与句子中其他与目标词相关的指标可以发现, 相比于首字替换假词, 换位假词对于阅读的影响较小。结合目标词内凝视时间、整句阅读时间和整句总注视次数指标, 可以看出预测性对于位置信息的影响。高预测性条件下,汉字位置信息与身份信息对于句子的影响均有所下降, 可以看到首字替换词的注视时间长、注视次数多, 说明在此情况下, 首字身份信息的破坏对于整句阅读的影响大, 这与本实验的假设是一致的。而低预测性条件下, 位置信息和身份信息的影响增大, 换位非词和替换非词没有显著差异, 但依然是换位非词更加靠近原词, 这说明预测性增大了身份信息和位置信息改变对阅读产生影响, 但无法彻底抵消身份信息的改变对阅读的破坏, 尤其是替换发生在词首位置。
对于目标词内首次注视时间和首次注视次数指标预测性不显著的情况, 我们认为可能是由于当首次注视到目标词时, 由于是刚刚接触到目标词,预测性并没有对这个阶段的词语加工产生影响, 这也对预测性研究提出一个新思路, 在进行预测性研究时, 应该关注整句的注视时间、向前眼跳比率和向后眼跳比率(Luke & Christianson, 2016)这些能更好反应预测性的指标。
由于对目标词的位置信息做了4种不同的处理,形成了原词、换位非词、首字替换词和尾字替换词。研究发现在从目标词向前眼动和从目标词向后眼动的指标中, 换位词与原词存在显著差异, 与首字替换词和尾字替换词均不存在显著差异, 出现身份信息和位置信息都重要的情况。回视率是衡量加工后期情况的指标, 在这个阶段, 换位词与原词存在显著差异的情况与以往的研究是一致的(Pagán et al., 2016)。位置信息和身份信息在目标词内指标中,换位词与原词之间均存在显著差异, 与尾字替换词均不存在显著差异, 但在首次注视时间、首次凝视时间、凝视时间上与首字替换词存在显著差异。
而在整句阅读次数指标上, 出现了预测性与位置信息的交互作用, 在高、低预测性条件下, 原词与换位非词差异均不显著, 但高预测性条件下, 原词与尾字替换词差异不显著, 在低预测性条件下, 原词与首字替换词的差异显著。根据以往研究(Yakup et al., 2014)并结合本实验中的其他指标, 可以发现,首字替换词对阅读的影响比尾字替换词要大, 尤其是在高预测性的条件下。因为首字替换词的第一个字的身份信息被完全破坏, 导致在预测性高的情况下, 看到已经破坏的非词时, 对阅读产生较大的影响, 而且也较难通过尾字来关联原词, 但看到的如果是尾字替换词的话, 那么看到的首字是确定的,通过之前句子的预测, 能够对词语进行关联, 因此对阅读产生的影响较小。而在预测性低的情况下,无法预测出即将出现的目标词, 因此无论出现的是首字替换词还是换位词, 都无法做出预测, 所以在这种情况下, 原词与换位词, 首字替换词之间差异并不显著。
目标词内的指标反映了被试在进行句子阅读中对于目标词加工的情况, 在这些指标中, 换位词与尾字替换词的加工是不存在显著差异的, 但这能说明在中文句子阅读的情况下就不存在换位效应吗?显然是不能的, 因为在首次注视时间、首次凝视时间和凝视时间的指标中, 我们发现换位词与首字替换词之间是存在显著差异的, 这说明在进行句子阅读时, 位置信息与身份信息相比是较灵活的,也就是说, 当换位词导致了位置信息 100%的变化,而首字替换词导致的50%身份信息变化时, 换位词依然能够较快的进行加工。而尾字替换词由于双字词的首字是能够看到的, 因此在句子通顺的情况下,被试能够猜测出掩蔽词语, 并且在本实验中还发现,在高预测性条件下, 尾字替换词比换位词加工更容易, 这种结果说明在预测性的帮助下, 能够通过预测来对整词进行提取加工。也就是说, 尾字替换词与换位词的类似不能解释为换位效应的消失, 而是由于在句子阅读中, 被试在进行副中央凹词加工时,能够通过预测性来对目标词进行猜测, 使目标词的加工变快。
在实验2中, 我们发现词汇的身份信息对阅读的作用更大, 语境预测性能够促进词语身份信息的加工。那么语境的预测性对于词汇身份信息和位置信息影响的时间进程是如何呢?为了探究这一问题, 我们设计了实验3。实验3采用边界范式, 参考副中央凹预视效应的研究方法(Inhoff & Radach,2014), 选用实验2中的实验材料, 通过改变掩蔽刺激的目标延迟时间, 来探究语境预测性对句子阅读中词汇身份信息和位置信息影响的时间进程。
4 实验3:语境预测性对词汇位置信息加工影响的时间进程
4.1 方法
4.1.1 被试
在校大学生 26名, 均为右利手, 年龄 21~23岁。被试的裸视或矫正视力正常,母语均为汉语。每个被试都阅读了《知情同意书》, 并签字同意。所有被试均不知实验目的, 实验结束后获得学分和适当报酬。
4.1.2 设计和材料
实验采用 4(关键词类型)×2(预测性)×3(目标延迟条件)三因素被试内设计。关键词类型及预测性与实验2相同, 预视时间分别为0 ms, 50 ms和100 ms。
实验材料的编制和评定同实验1。实验材料举例见表8。例子的词汇“手机”是实验的目标词n, 每个句子都包含一个无形的边界(McConkie & Rayner,1975), 这个边界位于目标词之前的空白区, 目标词在句子阅读的开始处于掩蔽状态, 掩蔽材料包括(1)原词(2)换位非词(3)首字替换非词和(4)尾字替换非词。当被试眼睛越过边界, 目标词位置的掩蔽刺激在0 ms (没有延迟条件)、50 ms或者100 ms后被替换成目标刺激。

表8 实验2实验材料举例(边界在“手”之前)
4.1.3 实验仪器与实验程序
被试机屏幕刷新率为 120 Hz, 其余与实验 2相同。
4.2 结果
结果分析使用的仪器和方法与实验2相同, 句子后出现的判断题的被试的平均正确率为93%, 删除了正确率低于90%的2名被试的数据, 并排除了注视点持续时间小于80 ms或大于1200 ms的数据,占总数的1.40%。
根据实验3的实验假设和目的, 参考实验设计,本次结果分析选取了目标词n的相关指标:首次注视持续时间(first fixation duration, FFD)、首次注视的注视次数(first run fixation count, FRFC)、凝视时间((gaze duration, GD)、总注视次数(fixation count,FC)。
4.2.1 首次注视持续时间
对目标词n的首次注视持续时间进行统计, 描述性统计结果见表9。预视时间为0 ms时, 预测性主效应显著,
F
(1, 168) = 29.70,p <
0.01, 偏η=0.50; 位置信息的主效应也显著,
F
(3, 504) = 20.36,p <
0.01, 偏η= 0.81, 多重比较(LSD
)结果显示:原词条件与两种替换条件之间差异不显著(p
s>
0.05), 尾字替换和首字替换条件差异不显著(p >
0.05), 其余条件之间均差异显著(p
s<
0.01)。预测性与位置信息的交互作用显著,F
(3, 504) = 16.02,p <
0.01, 偏η= 0.18。在高预测性条件下, 几种条件之间均差异不显著(p
s>
0.05), 而在低预测性条件下, 原词条件与换位条件差异不显著, 与替换条件差异显著(p <
0.01), 换位条件与两种替换条件差异也显著(尾字替换条件:p =
0.02; 首字替换条件:p <
0.01)。预视时间为50 ms条件下, 预测性主效应、位置信息主效应均不显著。预视时间为100 ms条件下, 预测性主效应显著,
F
(1, 172) = 36.26,p <
0.01,偏η= 0.64; 位置信息主效应不显著, 预测性与位置信息的交互作用也不显著。
表 9 每种实验条件下首次注视的持续时间(ms)的平均值和标准差(M ± SD)
4.2.2 首次注视的注视次数
对目标词首次注视的注视次数进行统计, 描述性统计结果见表10。预视时间为0 ms时, 预测性主效应显著,
F
(1, 168) = 84.44,p <
0.01, 偏η=0.84; 位置信息的主效应也显著,
F
(3, 504) = 17.47,p <
0.01, 偏η= 0.49, 多重比较(LSD
)结果显示:原词与其他条件均差异显著(p <
0.01), 换位条件与首字替换条件差异显著(p <
0.01), 两种替换词条件之间差异也显著(p =
0.035), 其余条件之间均差异不显著(p
s>
0.05)。预测性与位置信息的交互作用显著,F
(3, 504) = 3.20,p =
0.023, 偏η= 0.19。在高预测性条件下, 原词条件与其它几种条件之间均差异显著(换位条件p =
0.029, 尾字替换条件p =
0.020, 首字替换条件p <
0.01), 换位条件与尾字替换条件差异不显著(p >
0.05), 与首字替换条件差异显著(p <
0.01); 尾字替换条件与首字替换条件差异也显著(p <
0.01)。而在低预测性条件下, 原词条件与其它几种条件均差异显著(p
s<
0.01), 换位条件与两种替换条件差异也显著(尾字替换条件:p =
0.02; 首字替换条件:p <
0.01)。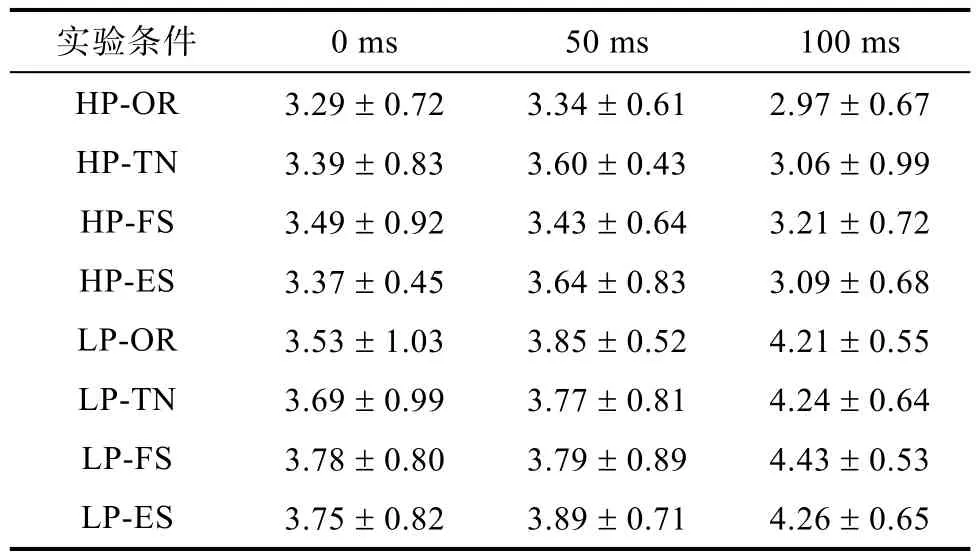
表 10 每种实验条件下首次注视的次数的平均值和标准差(M ± SD)
预视时间为50 ms条件下, 预测性主效应显著,
F
(1, 168) = 4.91,p =
0.028, 偏 η= 0.28; 位置信息主效应不显著, 预测性与位置信息的交互作用也不显著。预视时间为100 ms条件下, 预测性主效应显著,
F
(1, 172) = 56.73,p <
0.01, 偏 η= 0.84; 位置信息主效应不显著, 预测性与位置信息的交互作用也不显著。
4.2.3 凝视时间
对目标词的凝视时间进行统计, 描述性统计结果见表11。预视时间为0 ms时, 预测性主效应显著,
F
(1, 168) = 9.35,p <
0.01, 偏 η= 0.53; 位置信息的主效应也显著,
F
(3, 504) = 30.81,p <
0.01, 偏η= 0.51, 多重比较(LSD
)结果显示:除尾字替换和首字替换条件差异不显著外(p >
0.05), 其余条件之间均差异显著。原词条件的凝视时间最短, 换位词条件较原词条件较长, 两种替换时间则更长。预测性与位置信息的交互作用显著,F
(3, 504) = 5.80,p <
0.05, 偏η= 0.33。在高预测性条件下, 原词条件与其它条件差异显著(p <
0.01), 换位条件与替换条件差异也显著(p <
0.01), 而在低预测性条件下, 几种条件之间差异均不显著(p
s>
0.05)
表11 每种实验条件下凝视时间(ms)的平均值和标准差(M ± SD)
预视时间为 100 ms时, 预测性主效应显著,
F
(1, 172) =15.90,p <
0.01, 偏 η= 0.85; 位置信息的主效应也显著,F
(3, 516) = 3.28,p =
0.021, 偏η=0.19, 多重比较(LSD
)结果显示:原词条件只与首字替换条件差异显著(p <
0.01), 换位条件也仅与首字替换条件差异显著(p =
0.022), 其余条件之间差异均不显著(p
s>
0.05)。预测性与位置信息的交互作用不显著。4.2.4 总注视次数
对目标词总注视次数进行统计, 描述性统计结果见表12。预视时间为0 ms条件下, 预测性主效应显著,
F
(1, 168) = 32.78,p <
0.01, 偏 η= 0.63; 位置信息的主效应也显著,F
(3, 504) = 24.81,p <
0.01,偏η= 0.92, 多重比较(LSD
)结果显示:原词条件与其它条件之间均差异显著(ps <
0.01), 换位条件与尾字替换条件差异不显著(p >
0.05)与首字替换条件差异显著(p <
0.01), 首字替换条件与尾字替换条件差异也显著(p =
0.020)。预测性与位置信息的交互作用显著,F
(3, 504) = 13.58,p <
0.05, 偏η=0.75。在高预测性条件下, 原词条件与其它条件差异显著(p <
0.01), 其它条件之间均差异不显著 (p
s>
0.05), 而在低预测性条件下, 几种条件差异均不显著(p
s>
0.05)。
表 12 每种实验条件下总注视次数(次)的平均值和标准差(M ± SD)
预视时间为50 ms时, 预测性主效应显著,
F
(1,168) = 4.17,p =
0.043, 偏η= 0.24, 位置信息主效应不显著, 预测性与位置信息的交互作用也不显著。预视时间为100 ms时, 预测性主效应显著,
F
(1,172) = 46.47,p <
0.01, 偏η= 0.,72; 位置信息的主效应也显著,
F
(3,516) = 3.08,p =
0.027, 偏η=0.17, 多重比较(LSD
)结果显示:原词条件只与首字替换条件差异显著(p =
0.011), 换位条件也仅与首字替换条件差异显著(p =
0.015), 其余条件之间差异均不显著(p
s>
0.05)。预测性与位置信息的交互作用显著,F
(3, 504) = 2.73,p =
0.043, 偏η= 0.15。在高预测性条件下, 几种条件差异均不显著(p
s>
0.05), 而在低预测性条件下, 原词条件与首字替换条件差异显著(p <
0.01), 其余条件之间差异均显著(p
s>
0.05)。4.3 讨论
在实验 3中, 通过控制目标词的预视时间, 发现预测性结果与实验2结果一致, 但位置信息和身份信息的作用与实验2相比有更深层的发现, 当预视时间为0 ms时, 位置信息的作用较小, 在预视时间为50 ms和100 ms时位置信息的作用增大, 位置信息的破坏与身份信息破坏一样对目标词的识别和加工造成影响。也就是说, 在句子阅读中, 预视时间较短时, 对目标词的预视时间不足, 这时位置信息的破坏较身份信息的破坏对汉语识别造成的影响小。这与四字词边界范式中单独词条件凝视时间结果、两个双字词条件的注视时间结果, 比较一致(Gu & Li, 2015)。上述影响受预测性的调节, 随着预视时间增加, 副中央凹加工的时间延长, 汉语位置信息的破坏对目标词的识别影响变大, 且预测性的改变不会对位置信息的破坏起到作用。
在预视时间为 0 ms时, 分析首次注视的持续时间和首次注视的注视次数可以发现, 预测性可以调节位置信息和身份信息的作用, 高预测性时, 几种条件下的首次注视持续时间差异不显著, 也就是说, 高预测性能够降低身份信息和位置信息破坏对词汇识别造成的影响, 在高预测性条件下, 尾字替换条件的首次注视持续时间较首字替换条件更短,这也是预测性对于身份信息破坏作用的调节的证明。也就是说, 在本实验中, 预测性在首次注视的时候就已经开始起作用, 这与实验2的结果不同。在实验 2中, 改变的词语是通过副中央凹加工后,还通过中央凹进行加工, 也就是说, 相比实验 3中的首次注视指标, 实验2中反映的不仅仅是副中央凹加工的作用, 而是进一步加工的效果。结合凝视时间和总注视次数发现, 高预测性情况下, 原词条件的时间最短, 次数最小, 而低预测性条件下, 由于对目标词无法预测, 因此, 各个条件下的词汇的总注视时间和总注视次数是类似的, 这也是可以理解的。
将实验1与实验3的结果结合起来可以发现:在单独呈现条件下, 位置信息由启动时间为 80 ms时比身份信息更重要, 到100 ms时作用减小, 在加工中比较灵活, 到 300 ms时与身份信息共同作用的过程, 而在句子语境下, 预视时间为0 ms时, 位置信息作用小, 预视时间为50和100 ms时, 可以通过凝视时间和总注视次数两个指标看出, 位置信息的作用相比于预视时间较短时更重要。再比较高低预测性时的结果可以发现, 在预视时间较短时,高预测性时的结果与实验1中启动时间短时的结果是类似的, 而低预测性时, 与实验 1中几种启动时间下得到的启动效应都不同, 出现了都不显著的情况。而随着预视时间的延长, 高预测性时出现几种条件都不显著, 而低预测性时与实验1中启动时间较长时的结果是类似的。也就是说, 在单独呈现时,在早期加工阶段, 位置信息的作用更大, 随着加工时间的延长, 位置信息的作用逐渐降低, 身份信息的作用逐渐增加。而在句子语境下, 由于句子语境预测性及副中央凹加工的存在, 位置信息的作用在早期阶段较为灵活, 随加工的深入, 位置信息的作用增大。
在预视时间为50 ms时, 各指标均出现了预测性主效应显著, 而没有出现位置信息的主效应显著。也就是说, 在这个阶段, 位置信息和身份信息的作用是类似的, 无法确认哪个作用更大。这与实验 1的结果类似, 随着加工时间的延长, 位置信息的作用增大, 换位非词和替换非词都会对加工造成类似的影响。而在预视时间为100 ms时, 位置信息和身份信息的作用出现了差异, 此时, 目标词首字的身份信息的破坏对目标词的加工造成最大影响,而位置信息和目标词尾字的身份信息的破坏我们也无法判定哪个的作用更大, 但可以肯定的是, 在这个阶段, 目标词首字的身份信息作用是最大的。
5 总讨论
通过行为实验和眼动实验, 采用真假词判断任务和句子阅读任务, 考察了在阅读加工的早期阶段和晚期阶段, 词语的身份信息和位置信息加工的特点, 以及预测性对位置信息的影响。综合三个实验的结果, 发现位置信息的作用在早期阶段(句子中预视时间为0 ms时)作用较小, 即使发生改变也不会带来很大影响, 相比身份信息更加灵活。随着加工时间的延长(单独呈现启动词80 ms, 句子中预视时间为50 ms), 位置信息的作用逐渐增大, 与身份信息改变相比, 位置信息改变需要更长的注视时间,更多的注视次数。而到了加工的晚期阶段(单独呈现启动词300 ms, 句子预视时间为100 ms, 实验2),位置信息的作用与身份信息的作用类似, 但身份信息的作用与所处的位置(处在词汇中的首字或尾字)有关。可见, 词汇中的字母作用与特定位置关系密切, 贝叶斯读者模型主张词汇中的字母与他们的特定位置相联系(Norris, Kinoshita, & van Casteren,2010)。不同位置作用也是不一样的。而且首字替换比尾字替换破坏性更大, 也说明词汇识别中, 不同位置的刺激激活程度是不一样的。Davis (2001)提出的 SOLAR模型也主张, 每个字母与自我激活水平有关, 第一个字母激活水平最高, 依次递减,最后一个激活水平最低。所以尾字替换破坏性小很多。但是, 本研究结果并不支持 Whitney (2001)提出的SERIOL模型, 没有出现一致的换位比替换优势的数据模式。其原因也许是, 本研究的实验材料是双字词, 双字母组合的差异体现不出来。未来研究需要探讨三字词、四字词、六字词情况。
在本研究中, 对于句子阅读的预测性效应的研究发现, 语境预测性对不同目标词条件下的阅读产生影响。结合实验2和实验3的结果, 发现, 预测性从副中央凹加工时, 就会对目标词的加工产生影响, 预测性在副中央凹加工的早期阶段, 会对位置信息的加工有促进作用, 而到了中央凹加工阶段,对身份信息的加工有促进作用。参考实验1的结果,我们可以推测与拼音文字研究(Blythe, Johnson,Liversedge, & Rayner, 2014)会有不同的结果, 汉语词汇中汉字的位置信息比英文词汇中的字母位置信息更为重要。在单独呈现双字词时, 位置信息的重要性在早期阶段表现的很明显。但在句子语境条件下, 位置信息的重要性较单独呈现的情况会降低,但依然会产生很大的作用。结合眼动指标, 可以发现, 首字替换对阅读的阻碍作用最大, 证明了副中央凹更难加工换位词或者部分掩蔽词, 也再次证明SOLAR模型主张的不同位置字母激活不同的观点的正确性。而在目标词内的指标中发现, 换位词对于词语加工的阻碍作用小于掩蔽词, 这与在单独的词语阅读中发现的结果类似, 也就是说, 在有上下文语境的条件下, 语境的预测性对词语的加工促进作用。
位置信息和身份信息的作用, 汉语与拼音文字为什么不同呢?首先, 可能是因为实验使用的是双字词, 拼音文字的研究中, 使用的是多个字母的词汇, 例如“clerk” (Perea, Palti, & Gómez, 2012)。这种多字母的单词, 两个字母换位的情况下, 只会导致40%的字母位置的改变, 如果字母多的话, 位置信息改变所占比例更少。但是汉语双字词换位导致了位置信息 100%的改变, 换位词激活原词的难度增大。就像在前言中提到的, 在英文研究中发现, 换位位置对词语的加工也有不同影响, 换位发生在词首、词尾比发生在词内部对词汇识别的破坏性更大(White et al., 2008; Yakup et al., 2014), 而在中文阅读中, 双字词的换位相当于将整个的首尾进行了颠倒, 所以说对词汇识别的加工破坏性增大。尤其是在整句阅读中, 在英语研究中, 在阅读关键词前的内容时, 副中央凹加工可以根据换位单词的前几个字母对整个单词进行猜测, 而在汉语阅读中, 由于位置信息 100%的改变, 所以注视之前的词语时,副中央凹加工很难猜测换位词的原词。其次, 结合实验3的发现, 预测性在早期阶段的时候对位置信息的加工有促进作用, 那么在中文的词汇中, 首字对尾字是否也是有促进作用呢?在拼音文字中, 字母更多的是以单独的形式出现, 且一般情况下, 仅出现1~2个首字母无法对整个单词进行预测, 而汉字中, 双字词最多, 当出现首字时, 读者可能就会有意识的预测到下一个字, 并进行组词, 因此当位置信息破坏时, 加工会变得更困难。
那么词素位置信息和身份信息是如何作用于句子阅读下的词汇识别呢?根据汉语词汇识别的单向切分假设(Inhoff & Wu, 2005), 即汉语词切分严格遵循从左往右的序列, 例如读者注视到“...家的经济状况...” (本研究实验2材料)时, 在头脑中首先会确定“家的”是否是一个词, 然后再确定“家的经”是否是一个词, 如果不是的话, “家的”会被认为是一个双字词, 同时下一个字“经”就是下一个词的开始, 以此类推。那么研究者推断, 读者在文本阅读时, 通过前后相邻的词语构成一个汉字串, 又构成一个句子, 那么要识别整句及句子中词语的意思,就需要自下而上的通过对词语进行识别, 来分析整句的含义, 当句子中出现换位和替换时, 会对汉语词的切分和识别造成影响, 这也是汉语句子中身份信息和位置信息不同于拼音文字研究的原因之一。而结合预测性我们可以发现, 整句的意思能够对目标词的识别产生影响, 也就是说也存在自上而下的通过理解整句含义来分析词汇。以拼音文字的研究为基础, 有许多模型已经考虑到了字母位置信息编码的灵活性, 如空间编码模型(Davis, 2010), 重叠模型(overlap model) (Gome, Ratcliff, & Perea, 2008)和贝叶斯读者模型(Bayesian reader model)等。本实验结果较好地支持SOLAR模型和贝叶斯读者模型, 不支持SERIOL模型。另外, 双重途径加工模型(Whitney,Bertrand, & Grainger, 2012)也可以解释本研究的结果。双重途径加工模型(open-bigram account)认为, 词汇的激活是通过各字母身份信息和位置信息激活的数值通过加权的方式计算的, 比如单词“BIRD(鸟)”, BI、IR、RD 与整词“BIRD”的匹配程度是 1.0,BR, ID和整词的匹配程度是0.8, BD和整词的匹配程度是0.4, 所以单词“BIRD”的激活值为4.4 = 3 ×1 × 1 + 2 × 0.8 × 0.8+ 1 × 0.4 × 0.4, 当激活值不足时, 需要更深层次的加工, 而位置信息发生改变导致激活不足时, 如将“BIRD”变为了“BRID”, 激活值仍为4.4, 而如果身份信息发生了改变如I变为U激活值会下降。在汉语中, 身份信息和位置信息的加工可能同样遵循这种模式, 但中文中, 激活值的权重可能与身份信息的位置有关, 身份信息在副中央凹阶段最先加工, 然后位置信息开始加工, 随加工的深入, 身份信息继续加工, 直到达到词汇通达。
在本研究中, 句子预测性对关键词识别的促进作用与以往研究结果是一致的。句子阅读的研究表明在词汇通达的过程中存在预测性效应, 即对高预测性词汇的识别快于对低预测性词汇的识别(苏衡,刘志方, 曹立人, 2016)。实验2和实验3的研究结果也表明, 对词素位置信息颠倒的高预测性词语的识别仍比对词素位置信息颠倒的低预测性词语的识别速度快, 这证明了预测性效应的存在, 即使双字词中的词素位置信息发生了颠倒, 高预测性词语仍能促进读者对它的识别速度。
本研究通过对词素身份信息和位置信息加以改变探讨了词素信息的重要性, 结果表明词素信息的加工会对句子阅读中的词汇加工产生影响, 这充分证明了词素位置信息的加工是词汇加工的重要阶段。结合以往研究, 运用颠倒字母位置的方法探讨拼音文字字母编码问题, 而对于汉语这种特殊的文字系统, 本研究运用词素位置改变和首字尾字替换的方法对词汇识别中词素位置信息和身份信息的重要性进行了进一步的探讨。
5 结论
汉语双字词的身份信息和位置信息的加工是分离的。在单独呈现时, 位置信息在早期加工阶段作用更大, 随着加工时间的延长, 位置信息的作用逐渐降低, 身份信息的作用逐渐增加。在句子阅读中, 位置信息在副中央凹加工的早期阶段作用较为灵活, 随加工的深入, 位置信息的作用增大, 语境预测性在早期能够促进位置信息的加工, 在晚期能够促进身份信息的加工。
Bian, Q., Cui, L., & Yan, G. L. (2010). Effects of the transposed morpheme on the Chinese sentence reading:evidence from eye movement data.
Psychological Research,3
, 29−35.[卞迁, 崔磊, 闫国利. (2010). 词素位置颠倒对汉语句子阅读影响的眼动研究.
心理研究, 3
, 29−35.]Blythe, H. I., Johnson, R. L., Liversedge, S. P., & Rayner, K.(2014). Reading transposed text: Effects of transposed letter distance and consonant-vowel status on eye movements.
Attention, Perception, & Psychophysics,
76
(8), 2424−2440.Cona, G., Arcara, G., Tarantino, V., & Bisiacchi, P. S. (2015).Does predictability matter? Effects of cue predictability on neurocognitive mechanisms underlying prospective memory.
Frontiers in Human Neuroscience,
9
, 188.Davis, C. J. (2001). The self-organising lexical acquisition and recognition (SOLAR) model of visual word recognition.
Dissertation
s International: Section B: The Sciences and Engineering, 62
, 594.Davis, C. J. (2010). The spatial coding model of visual word identification.
Psychological Review,
117
(3), 713−758.Gomez, P., Ratcliff, R., & Perea, M. (2008). The overlap model: A model of letter position coding.
Psychological Review,
115
(3), 577−600.Gu, J. J., & Li, X. S. (2015). The effects of character transposition within and across words in Chinese reading.
Attention Perception & Psychophysics, 77
(1), 272−281.Gu, J. J., Li, X. S., & Liversedge, S. P. (2015). Character order processing in Chinese reading.
Journal of Experimental Psychology: Human Perception & Performance, 41
(1),127−137.Hua, H. M., Gu, J. J., Lin, N., & Li, X. S. (2017). Letter/character position encoding in visual word recognition.
Advances in Psychological Science, 25
(7), 1132−1138.[滑慧敏, 顾俊娟, 林楠, 李兴珊. (2017). 视觉词汇识别中的字符位置编码.
心理科学进展,
25
(7), 1132−1138.]Inhoff, A. W., & Radach, R. (2014). Parafoveal preview benefits during silent and oral reading: Testing the parafoveal information extraction hypothesis.
Visual Cognition,22
(3–4), 354–376.Inhoff, A. W., & Wu, C. L. (2005). Eye movements and the identification of spatially ambiguous words during Chinese sentence reading.
Memory & Cognition,
33
(8), 1345−1356.Johnson, R. L., Perea, M., & Rayner, K. (2007). Transposedletter effects in reading: Evidence from eye movements and parafoveal preview.
Journal of Experimental Psychology:Human Perception & Performance,
33
(1), 209−229.Kezilas, Y., McKague, M., Kohnen, S., Badcock, N. A., &Castles, A. (2017). Disentangling the developmental trajectories of letter position and letter identity coding using masked priming.
Journal of Experimental Psychology:Learning, Memory, & Cognition,
43
(2), 250−258.Kretzschmar, F., Schlesewsky, M., & Staub, A. (2015).Dissociating word frequency and predictability effects in reading: Evidence from coregistration of eye movements and EEG.
Journal of Experimental Psychology: Learning,Memory, & Cognition,
41
(6), 1648−1662.Liang, F. F., Wang, Y. S., & Bai, X. J. (2016). Word spacing facilitates novel word's acquisition during Chinese reading:The modulation of within- word position.
Psychological Exploration, 36
, 403−408.[梁菲菲, 王永胜, 白学军. (2016). 词间空格促进汉语阅读的新词学习: 词素位置的调节作用.
心理学探新,
36
,403−408.]Liu, Y. P., Reichle, E. D., & Li, X. S. (2016). The effect of word frequency and parafoveal preview on saccade length during the reading of Chinese.
Journal of Experimental Psychology: Human Perception and Performance, 42
(7),1008−1025.Luke, S. G., & Christianson, K. (2012). Semantic predictability eliminates the transposed-letter effect.
Memory & Cognition,40
(4), 628−641.Luke, S. G., & Christianson, K. (2016). Limits on lexical prediction during reading.
Cognitive Psychology,
88
,22−60.McClelland, J. L., & Rumelhart, D. E. (1981). An interactive activation model of context effects in letter perception: Ι.An account of basic findings.
Psychological Review,
88
(5),375−407.McConkie, G. W., & Rayner, K. (1975). The span of the effective stimulus during a fixation in reading.
Perception and Psychophysics,
17
(6), 578–586.Norris, D. (2006). The Bayesian reader: Explaining word recognition as an optimal Bayesian decision process.
Psychological Review,
113
(2), 327−357.Norris, D., Kinoshita, S., & van Casteren, M. (2010). A stimulus sampling theory of letter identity and order.
Journal of Memory & Language,
62
(3), 254−271.Perea, M., & Carreiras, M. (2006). Do transposed-letter similarity effects occur at a prelexical phonological level?
Quarterly Journal of Experimental Psychology,
59
, 1600−1613.Pagán, A., Paterson, K. B., Blythe, H. I., & Liversedge, S. P.(2016). An inhibitory influence of transposed-letter neighbors on eye movements during reading.
Psychonomic
Bulletin & Review, 23
(1), 278–284.Perea, M., Palti, D., & Gomez, P. (2012). Associative priming effects with visible, transposed-letter nonwords: Jugde facilitates court.
Attention, Perception, & Psychophysics,74
(3), 481−488.Peng, D. L., Ding, G. S., Wang, C. M., Taft, M., & Zhu, X. P.(1999). The processing of Chinese reversible words - the role of morphemes in lexical access.
Acta Psychologica Sinica, 31
, 236−270.[彭聃龄, 丁国盛, 王春茂, Taft, M., 朱晓平. (1999). 汉语逆序词的加工——词素在词加工中的作用.
心理学报, 31
,236−270.]Rayner, K., & Fischer, M. H. (1996). Mindless reading revisited: Eye movements during reading and scanning are different.
Attention Perception & Psychophysics, 58
, 734−747.Sánchez-Gutiérrez, C., & Rastle, K. (2013). Letter transpositions within and across morphemic boundaries: Is there a cross-language difference?
Psychonomic Bulletin &Review,
20
, 988−996.Schotter, E. R., Angele, B., & Rayner, K. (2012). Parafoveal processing in reading.
Attention, Perception, & Psychophysics,74
(1), 5−35.Smith, N. J., & Levy, R. (2013). The effect of word predictability on reading time is logarithmic.
Cognition,128
(3), 302−319.Su, H., Liu, Z. F., & Cao, L. R. (2016). The effects of word frequency and word predictability in preview and their implications for word segmentation in Chinese reading:Evidence from eye movements.
Acta Psychologica Sinica,48
, 625−636.[苏衡, 刘志方, 曹立人. (2016). 中文阅读预视加工中的词频和预测性效应及其对词切分的启示: 基于眼动的证据.
心理学报, 48
, 625−636.]Vergara-Martínez, M., Perea, M., Gómez, P., & Swaab, T. Y.(2013). ERP correlates of letter identity and letter position are modulated by lexical frequency.
Brain & Language,125
(1), 11−27.White, S. J., Johnson, R. L., Liversedge, S. P., & Rayner, K.(2008). Eye movements when reading transposed text: The importance of word-beginning letters.
Journal of Experimental Psychology: Human Perception & Performance,
34
(5),1261−1276.Whitford, V., & Titone, D. (2014). The effects of reading comprehension and launch site on frequency-predictability interactions during paragraph reading.
Quarterly Journal of Experimental Psychology,
67
(6), 1151−1165.Whitney, C. (2001). How the brain encodes the order of letters in a printed word: The SERIOL model and selective literature review.
Psychonomic Bulletin & Review,
8
(2),221−243.Whitney, C., Bertrand, D., & Grainger, J. (2012). On coding the position of letters in words: A test of two models.
Experimental Psychology, 59
(2), 109−114.Yakup, M., Abliz, W., Sereno, J., & Perea, M. (2014). How is letter position coding attained in scripts with positiondependent allography?
Psychonomic Bulletin & Review,21
(6), 1600−1606.Zang, C. L., Zhang, M. M., Yue, Y. Q., Bai, X. J., & Yan, G. L.(2013). The modulation of parafoveal processing on Chinese silent and oral reading.
Studies of Psychology &Behavior,
11
(4), 444−450.[臧传丽, 张慢慢, 岳音其, 白学军, 闫国利. (2013). 副中央凹信息量对中文朗读和默读的调节作用. 心理与行为研究,
11
(4), 444−450.]Zhang, L. Y., Jin, T., & Tian, Z. X. (2013). Morphological processing: Morpho-orthographic or morpho-semantic?
Psychological Science, 36
, 576−579.[张玲燕, 金檀, 田朝霞. (2013). 词素认知加工——基于形式还是基于语义?.
心理科学, 36
, 576−579.]