基于子字单元的神经机器翻译未登录词翻译分析
2018-05-29李军辉熊德意周国栋
韩 冬,李军辉,熊德意,周国栋
(苏州大学 计算机科学与技术学院,江苏 苏州 215006)
0 引言
神经机器翻译(NMT)采用一种新颖的解决机器翻译问题的方法,并且最近几年已经取得了极大的成功[1-3]。尤其是在翻译的流利度方面,NMT系统与传统的SMT系统相比,翻译结果更加顺畅。总的来说,NMT系统采用神经网络结构,不需要存储短语表,而是有着一个小规模的词汇表,这大大减小了计算的复杂度。
但是,NMT系统也有自身的缺点。因为NMT系统为了能够控制计算的复杂度,有着一个固定大小的词汇表,通常会将词汇表限制在30~80KB之间,这就导致了其在翻译未登录词时有着严重的不足。由于限定词汇表有大小限制,对于未出现在该词汇表中的词,NMT系统用UNK标记来替代。结果,NMT系统不仅无法将它们翻译准确,而且破坏了句子的结构特征。为了解决NMT系统中存在的这一问题, Sennrich和Haddow[4]提出了一种BPE编码[5]的解决方法。该方法将训练语料中的单词拆分成更为常见的小部分,这里把它叫做子字单元。通过这种方法,我们假设在同样将词汇表设置成30KB的情况下,由于很多单词拆解的子字部分是相同的,所以30KB的子字单元实际上可以表示出远远超出30KB的以单词为基础的词汇表。这样,对于绝大多数未登录词,就可以通过子字单元的组合表示出翻译的结果。
将单词拆解为子字单元的方法对于未登录词问题确实是一种简单的方法,但是对于其翻译的效果我们依然持疑问的态度。因此,本文对BPE方法的翻译结果进行了分析。分析BPE方法是如何翻译未登录词的,在多大程度上解决了NMT系统对未登录词的翻译问题。
通过对中英文翻译的实验结果分析,本文有如下发现:
(1) 验证了BPE方法对未登录词确实是一种行之有效的方法,在对中英文双向都拆解成子字单元的实验中,实验结果与不做处理的NMT系统相比,提高了1.02 BLEU值。
(2) 本文进行了四组实验,对各个实验中训练语料中未登录词进行了统计,发现通过BPE方法的实验在训练语料中基本涵盖了所有的训练单词。
(3) 统计了各测试语料中源端未登录词的个数,然后得出结论: 使用中英文端均做BPE的方法,测试源端语料基本不会出现未登录词。从翻译结果看,目标端翻译结果中不含有UNK标识符,从而可以说明通过BPE的方法确实极大程度上解决了未登录词的问题。
(4) 分析测试源端中未登录词的词性和各组对比实验的解决效果,发现NMT系统中未登录词的来源主要是名词、动词和数词。
(5) 与SMT方法比较,BPE方法对未登录词的翻译效果在精准度上基本上保持一致。对于测试源端语料中未登录词的翻译均达到了45%左右的正确率。
1 神经机器翻译系统
本节将简要介绍本文的神经机器翻译系统,该系统采用注意力机制,包含一个编码器和一个解码器[6],整体结构如图1所示。
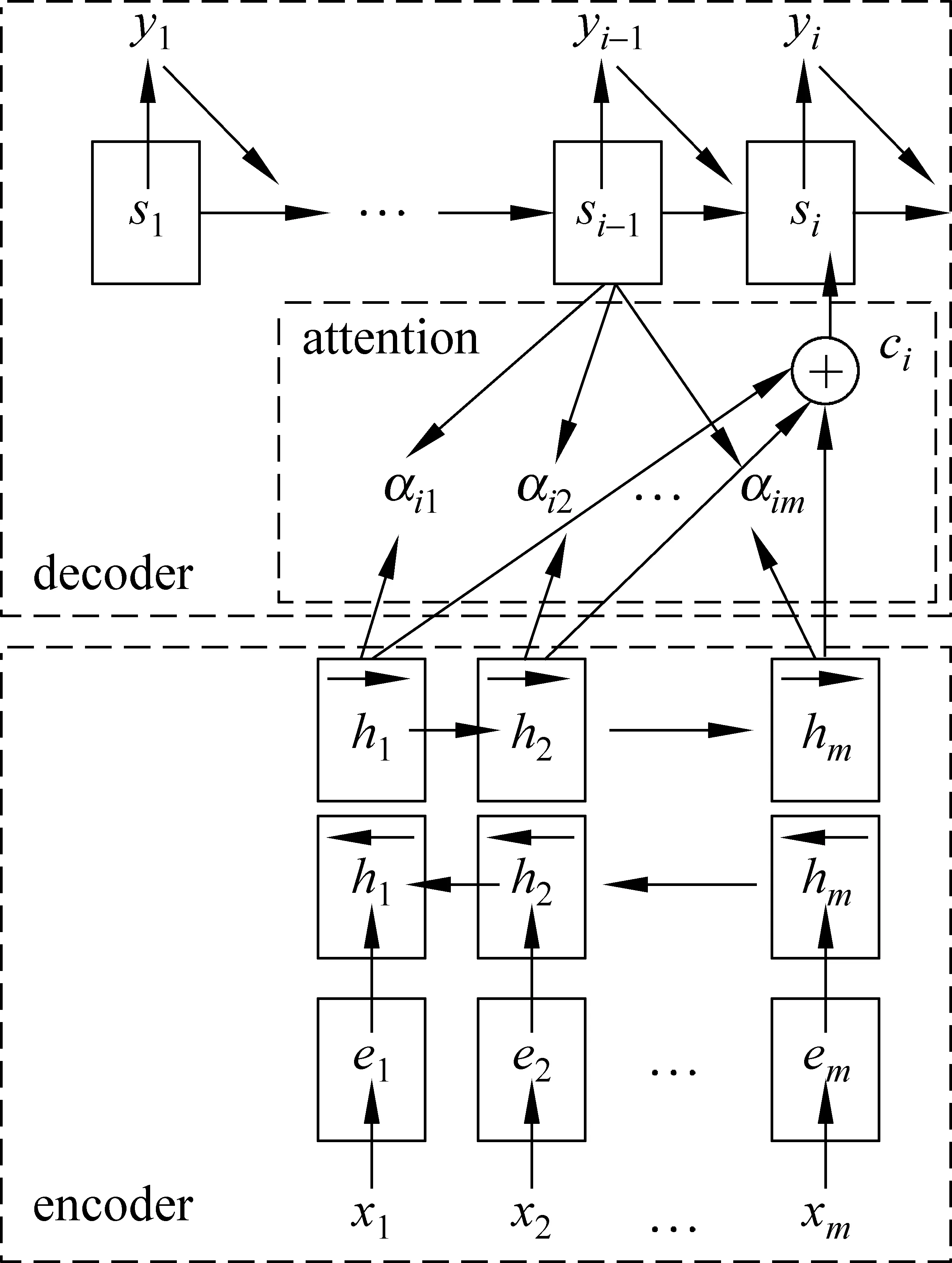
图1 基于注意力机制的神经机器翻译
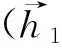
p(yi|y1,…,yi-1,x)=g(yi-1,si,ci)
(1)
si为循环神经网络第i时刻的隐藏状态,计算通过:
si=f(si-1,yi-1,ci)
(2)
ci也被叫作注意力向量,具体计算公式为式(3-5)。
其中,att(si-1,hj)是一个通过源端隐层状态hj和目标端前一隐层状态si-1计算出的匹配程度。
2 BPE*可以在http://aclweb.org/anthology/attachments/P/P16/P16-1162.Software.zip得到BPE方法使用的代码编码与子字单元
虽然有大量的工作用来不断地优化神经机器翻译系统,但是对于未登录词的解决仍然是当今神经机器翻译系统的一大难题。
BPE的思想是将单词拆解为更小、更常见的子字单元。对于原本不在词表中的单词,NMT系统一般会用UNK标示符替代。BPE方法将其拆解为常见的子字,通过翻译子字部分将原有的UNK单词进行了翻译,从而极大地保存了句子的结构特征和流畅性。
BPE方法拆解成子字单元的具体效果可以通过下面的例子来进行说明:
例(a) he is a good boy
例(b) h@@ e is a g@@ o@@ o@@ d b@@ oy
假设例(a)出现在训练语料中,传统的NMT系统在形成词汇表时,使用的是以单词为基础的划分方式,然后取词频出现较高的单词形成字典。但是BPE方法则是以一种介乎单词和字母之间的子字单元形成字典,如例(b)所示,其将一个句子中的单词拆分成了更小的部分 he→h@@ 和e。原本以he形成字典的方式转变为h@@ 和e 两个字典。更加详细的说明可参见文献[4]。
在中文语料中,假设“大学文凭”是一个中文未登录词,被标记为UNK,通过BPE的方法,将“大学文凭”拆解为“大学”和“文凭”两个部分,而“大学”和“文凭”这两部分恰恰是在词汇表中的,可以准确翻译,从而可以得到“大学文凭”的正确翻译结果如下:
Eg.大学文凭→大学 文凭 →university diploma
3 实验
本文针对中到英的翻译任务分析BPE方法对未登录词的翻译效果。为此,共准备了四组实验,每组实验的翻译性能采用评测标准BLEU值[8]。
训练集包含从LDC语料库中抽取的1.25MB句对的中文到英文平行语料*该语料包括LDC2002E18,LDC2003E07,LDC2003E14,LDC2004T07,LDC2004T08和LDC2005T06。。选择NIST MT 06数据集作为开发集,NIST MT 02, 03, 04, 05, 08作为测试集。
表1给出了本文进行的四组实验及其描述,其中Baseline系统将所有的中英文端未登录词都替代为UNK标记,BPE_cn、BPE_en、BPE_all指分别在源端(即中文端)、目标端(即英文端)和两端(即中英文端)进行BPE子字单元处理。
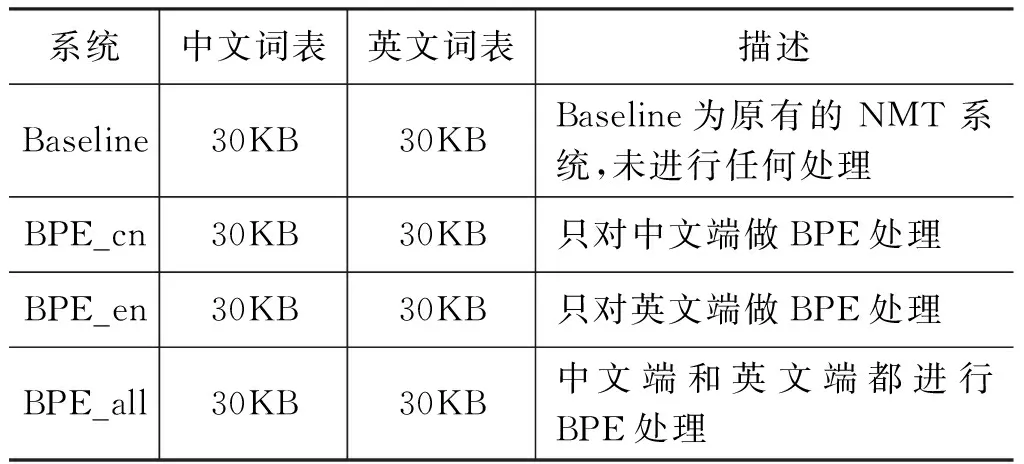
表1 四组实验及其描述
在实验中,设置隐层单元的个数为1 000,源端和目标端单词词向量(word_embedding)的维度为620维。神经网络用Adadelta[9]模型更新参数。设置batch_size为80。我们使用GPU去运行实验训练部分,提高实验运行的速度。
3.1 训练语料中未登录词的统计
本文统计了上述四个实验中未登录词的个数,如表2所示,从表中可以看出:
(1) 在相同的训练语料下,通过BPE方法可以极大地减少未登录词的个数,系统中中文未登录词的个数从174 291(Baseline系统)减少到549(BPE_all系统),英文未登录词的个数从75 910(Baseline系统)减少到0(BPE_all系统)。
(2) 在测试语料中,因为测试语料单词的个数要远远小于训练中出现的单词个数,所以我们有理由相信: 在中英文均做BPE处理的实验中,在测试时,源端将产生极少的未登录词,英文翻译结果中将会有极少的UNK标识符。这在我们之后的实验结果中也得到了验证。
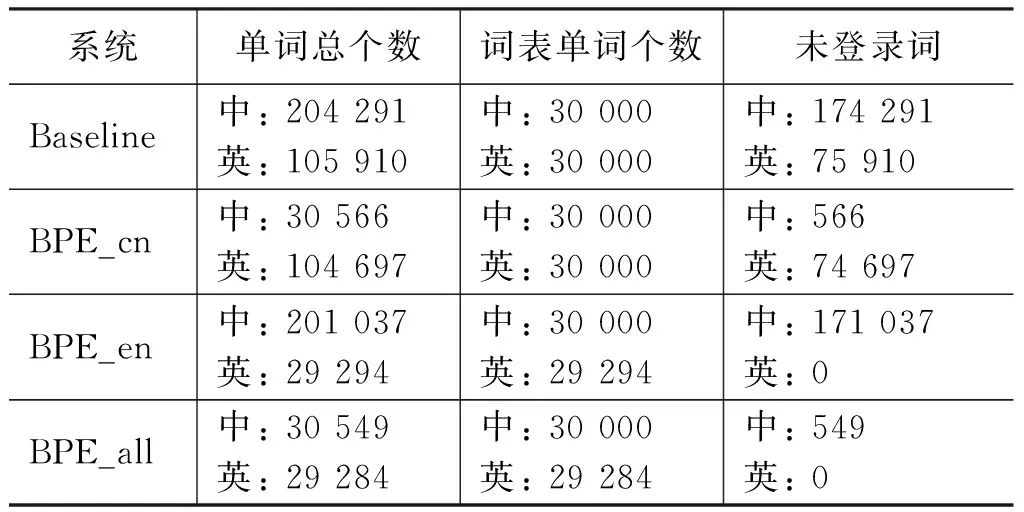
表2 四组实验中在相同训练语料下,单词总个数、词表单词个数和训练语料中未登录词的统计结果
其中,我们设置源/目标端句子最大长度为50,超过50个单词的句子舍弃,BPE在拆解成子字单元的过程中,会增加句子的长度*原Baseline在最大句子长度设置为50时,实际用于训练的语料行数为1 128 660。采用BPE_all方法也将最大句子长度设置为50的情况下,实际用于训练的语料行数为1 119 600,两种情况下训练规模近似相同,仅仅减少了0.8%。。
3.2 测试集未登录词的统计
表3统计了各个测试集源端包含的中文未登录词的个数。

表3 测试集源端统计结果
注: ① 在对源端做BPE处理时,源端单词个数会增多。
② S-W: 测试集中源端(中文端)单词总个数,S-U: 测试集中未登录词个数。
表3的统计结果表明,在Baseline系统中,测试集源端存在5%左右的未登录词。我们把这部分词称为VBaseline_chn_UNK。
通过上表的统计结果可以发现,经过BPE处理的实验与未经任何处理的Baseline实验相比,其测试集中含有很少的未登录词。特别地,对于BPE_all系统,由于源端和目标端同时分别采用了BPE编码,这样就使得在翻译时源端和目标端词汇表中的单词基本上完全覆盖了测试集中的单词,所以翻译结果中将基本不会含有未登录词*如表3所示,在测试集中,源端仍存在极少数的未登录词,该未登录词基本上是特殊符号。。在 测 试 的 时候,虽然BPE_all系统中源端含有很少的未登录词,但是BPE_all是否可以将VBaseline_chn_UNK翻译正确,翻译的质量如何,我们在下一节将进一步讨论。
3.3 Baseline系统测试集源端UNK分析
本节分析了BPE_all实验对VBaseline_chn_UNK集合中单词的翻译效果。图1给出了该集合中单词按词性的分布统计。不难看出,Baseline系统中源端未登录词主要是名词(约占76%),然后是动词(约占16%)和数词(约占6%)。
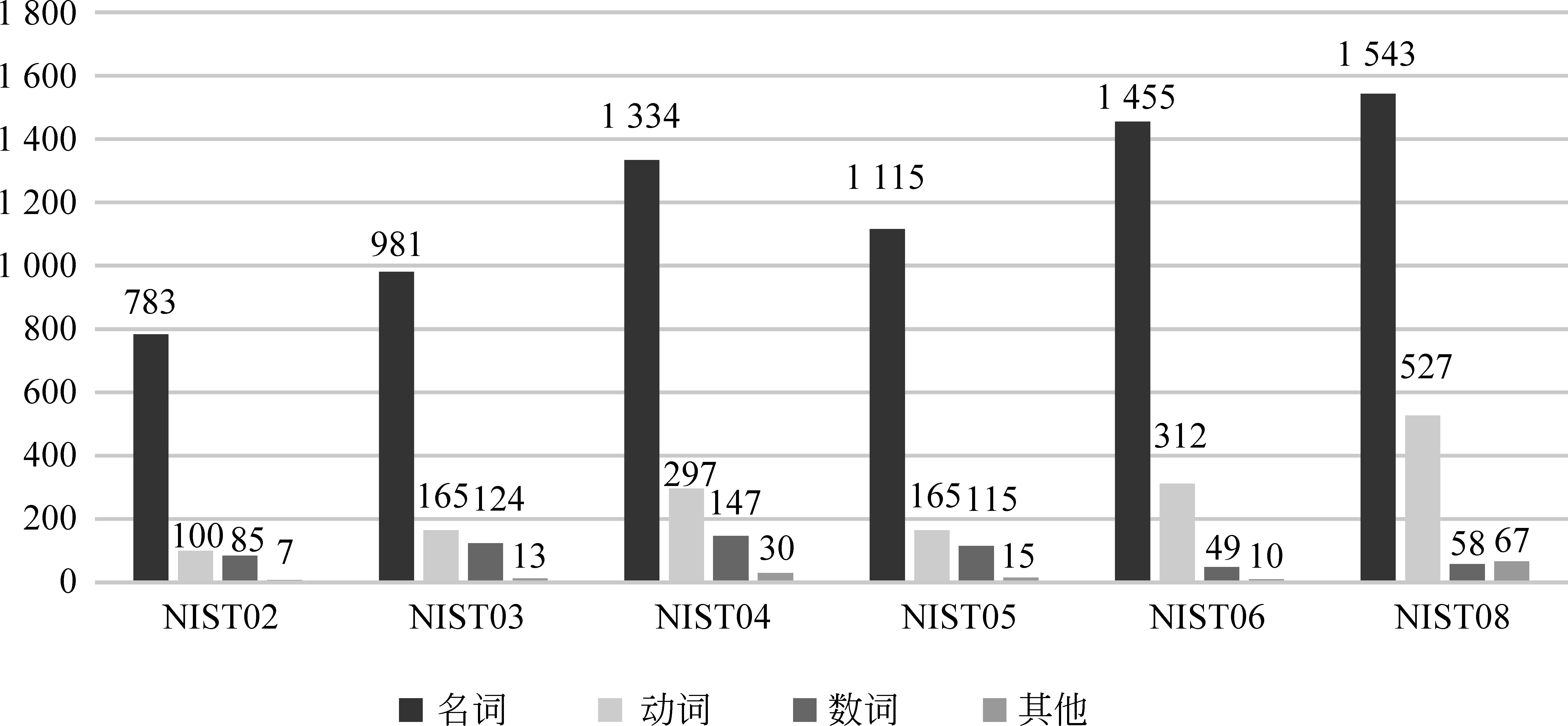
图2 测试集VBaseline_chn_UNK的词性分布
表4统计了在BPE_all实验中,将VBaseline_chn_UNK集合中单词正确翻译的比率。根据参考数据集,以NIST06为例,人工分析了NIST06中VBaseline_chn_UNK共1 826个词的翻译准确率。以名词为例,从表4可以看出,VBaseline_chn_UNK总共包含名词1 455个,其中669个翻译正确,占46%,说明BPE方法对源端未登录词具有一定的翻译效果。

表4 在BPE_all系统中,NIST06开发集VBaseline_chn_UNK的翻译正确统计
3.4 Baseline系统译文UNK分析
本节分析在Baseline系统中,哪些源端词翻译为译文的UNK。根据词对齐信息,找到译文中UNK所对应源端的单词,称源端的这些词为VBaseline_to_eng_UNK。图3统计了VBaseline_to_eng_UNK的词性分布情况,该图说明了导致译文中出现UNK最多的是名词(70%),紧接着是动词(17%)和数词(8%)。表5统计了VBaseline_to_eng_UNK中UNK是来自源端未登录词的个数(VBaseline_chn_UNK),以及源端在词表中但最终翻译为UNK的单词个数。以NIST02为例,Baseline的译文中共包含单词25 394个,其中UNK的数量为636个。针对这636个译文UNK,其中534个是由源端UNK翻译所致,另外102个是由源端非UNK翻译而来。这也说明了译文中产生UNK的单词大部分来自于源端的未登录词。
接着,由于目标端已消除UNK(BPE_all译文中没有UNK标示符),本节分析BPE_all系统又是如何翻译VBaseline_to_eng_UNK中的词,其翻译质量又如何。以NIST06为例,本文人工分析了NIST06中VBaseline_to_eng_UNK共1 204个词的翻译准确率,如表6所示。以名词为例,从表6可以看出,VBaseline_to_eng_UNK总共包含名词881个,其中396个翻译正确,占45%。

表5 测试集译文中UNK的统计
注意:表中,UNK行指译文中出现UNK的个数;Chn_UNK行表示多少数量的译文UNK翻译自源端UNK;Non_Chn_UNK行表示多少数量的译文UNK翻译自源端非UNK词。

图3 测试集VBaseline_to_eng_UNK的词性分布

名词动词数词其他词性所有词性总数正确数总数正确数总数正确数总数正确数总数正确数8813962079870464671204547(45%)
我们评测了各词性下的UNK单词在BPE翻译结果下的正确数,发现最终使用BPE方法的实验可以将45%的UNK单词翻译正确(其余单词翻译错误或漏翻),从而在一定程度上保障了句子的结构特征和流畅性。
3.5 BPE与SMT比较
从以上分析可以看出,BPE编码可以在一定程度上解决未登录词的翻译问题。但是,与SMT系统相比,BPE是否能够更好地解决未登录词的翻译仍未知。由于SMT并没有限定词汇表,对VBaseline_to_eng_UNK
中的词的翻译效果要比NMT Baseline系统好。本节主要比较SMT系统*本文的SMT系统采用cdec源码实现的层次短语翻译系统(https://github.com/redpony/cdec)。为公平起见,SMT系统与NMT系统使用相同的训练集、开发集和测试集。与BPE_all系统,分析两者对VBaseline_to_eng_UNK中的词的翻译效果。
以NIST06为例,本文人工分析了NIST06中VBaseline_to_eng_UNK共1 204个词在SMT系统下的翻译准确率,如表7所示。

表7 在SMT系统中,NIST 06测试集VBaseline_to_eng_UNK的翻译正确统计
比较表6和表7不难看出,BPE方法和SMT系统在翻译精准度上基本持平,最终对UNK单词翻译的精准度均达到了45%左右,从而可以说明BPE方法在一定程度上既具有传统NMT系统的流畅性,又具有接近SMT系统的未登录词翻译精准度。
3.6 主要结果
表8给出了Baseline系统和各BPE系统在测试集上的翻译性能BLEU值。从表8中可以看出,仅对源端或目标端采用BPE编码,能够在一定程度

表8 使用和未使用BPE的系统在测试集上的翻译性能BLEU值
注:表示在将显著水平设置为0.01时,BPE_all系统比Baseline系统相比有显著性提高[10]。
上提高翻译性,两端同时采用BPE编码,能进一步显著地提高翻译的性能,例如BPE_all系统在测试集上比Baseline系统平均提高了1.02 BLEU值。
4 总结
在本文中,我们分析发现BPE编码的方式确实在一定程度上解决了NMT系统中未登录词的翻译问题。通过将原有单词拆解为高频子字单元的方法,扩展了原有系统中的词汇表的大小,使在利用相同词汇表大小的情况下,我们可以表示出更多的单词,从而使系统中未登录词个数大大减少。
统计UNK单词被正确翻译的概率,我们又发现BPE方法在翻译精准度上基本和SMT系统持平,从而可以说明BPE方法在原有NMT系统流畅性的基础上又具有一定的翻译精准度。
但是使用BPE的方法仍然有其自身存在的问题,例如单词的漏译现象。对于NMT系统中低频词和未登录词的问题仍然是一大难题,我们在人工智能的道路上依然任重道远。
[1] Nal Kalchbrenner, Phil Blunsom.Recurrent continuoustranslationmodels[C]//Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing. Seattle, Washington, USA: 2013: 1700-1709.
[2] IlyaSutskever, Oriol Vinyals, Quoc V.Le. Sequence to sequence learning with neural networks[C]//Proceedings of the Neural Information Processing Systems (NIPS 2014). Montreal, Canada: 2014: 3104-3112.
[3] Dzmitry Bahdanau, Kyunghyun Cho, Yoshua Bengio. Neural machine translation by jointly learning to align and translate[J]. arXiv preprint arXiv, 1409.0473: 2014.
[4] Sennrich R, Haddow B, Birch A. Neural machine translation of rare words with subword units[J]. arXiv preprint arXiv: 1508.07909, 2015.
[5] Philip Gage. A new algorithm for data compression[J]. The C Users Journal, 1994, 12(2): 23-38.
[6] Minh-Thang Luong, Hieu Pham, Christopher D.Manning.Effective approaches to attention-based neural machine translation[C]//Proceedings of EMNLP 2015: 1412-1421.
[7] Kyunghyun Cho, Bart van Merrienboer, Caglar Gulcehre,et al. Learning phrase representations using RNN encoder-decoder for statistical machine translation[J]. arXiv preprint arXiv: 1406.1078, 2014.
[8] Papineni K, Roukos S, Ward T, et al. BLEU: a method for automatic evaluation of machine translation[C]//Proceedings of the 40th annual meeting on association for computational linguistics. Association for Computational Linguistics, 2002: 311-318.
[9] Mattew D Zeiler.ADADELTA: an adaptive learning rate method[J]. arXiv preprint arXiv: 1212.5701, 2012.
[10] Philipp Koehn.Statistical significance tests for machine translation evaluation[C]//Proceedings of the 2004 conference on empirical methods in natural language processing.


E-mail:dyxiong@suda.edu.cn
