异种语料融合方法: 基于统计的中文词法分析应用
2012-06-29孟凡东徐金安姜文斌
孟凡东,徐金安,姜文斌,刘 群
(1. 中国科学院 计算技术研究所 智能信息处理重点实验室,北京 100190;2. 北京交通大学 计算机与信息技术学院,北京 100044)
1 引言
词法分析是自然语言处理领域的基础性研究课题之一,词法分析的精度直接影响自然语言处理后续工作的效果。基于统计的词法分析很大程度上依赖于语料库,加大训练语料,可以直接提高词法分析的精度。但是,手工标注大规模语料代价昂贵。并且,不同领域的语料切分和标注的标准往往不同,难以直接混合使用。图1 以《人民日报》语料和宾州中文树库语料为例,具有不同的切分和词性标注标准,在《人民日报》语料中“高新技术”为一个词,标注为名词(n),在宾州树库中,“高新技术”被分为“高”“新”“技术”,并分别标注为形容词(JJ)、形容词(JJ)和名词(NN)。并且,这两种语料的词性标注集也不同,名词的标注分别是n和NN。

图1 《人民日报》语料(上面)和宾州中文树库语料(下面)的分词和词性标注标准举例
针对上述问题,Jiang et al.[1]提出了一种基于错误驱动的方法。利用源语料信息,将其分词和词性标注标准作为特征指导目标分析器,使其产生更好的效果。解码时,首先用源词法分析器对测试语料切分,再用目标词法分析器进行第二次切分,此时以第一次的切分结果为特征,即利用源语料指导目标词法分析器。该方法明显地提高了词法分析精度,是目前中文词法分析中效果最好的方法之一。但是该方法的解码过程略为复杂,不如一次解码的效率高。
本文在Jiang et al.[1]基础上提出了异种语料的自动融合策略,以此提高中文词法分析的精度。本方法的思想是先将源语料的分词和词性标注标准进行转化,使其与目标语料一致,再将转化后的语料与目标语料融合,训练一个新词法分析器。利用这个新的词法分析器可以直接进行解码,不需要二次解码。实验结果表明,本方法可以明显提高中文词法分析精度。与Jiang et al.[1]的方法相比,本方法与其具有相当的词法分析性能,甚至比其略高。并且具有更快的词法分析速度,只进行一次解码,简化了解码步骤,更具有实用性。而且,本方法可用于进一步融合其他领域的语料,更好地提高词法分析性能。因此,本方法更具有可扩展性。
本文在第二节简要介绍采用的词法分析方法,第三节详细阐述语料自动融合思想,第四节是实验及结果分析,第五节是总结与展望。
2 中文词法分析方法
本文采用判别式的词法分析方法。将分词和词性标注问题转化为字符(汉字)分类问题。根据Ng and Low[2]的方法,分词采用四种位置标记,b表示词首,m表示词中,e表示词尾,s表示单个汉字独立成词。即一个词只可以被标记成s(单字词)或bm*e(多字词)。联合分词与词性标注就是对于每个字,有位置标记和词性标记,例如“e_v”,表示一个动词的词尾。
2.1 分词特征模板
根据Ng and Low[2]的方法,用C0表示当前的汉字,C-i表示C0左边第i个汉字,Ci表示C0右边第i个汉字。Pu(Ci)用于判断当前汉字Ci是否为分隔符(是就返回1,否则返回0)。T(Ci)用于判断当前汉字Ci的类别: 数字、日期、英文字母和其他(分别返回 1,2,3 和 4)。

表1 特征模板
表1 描述了分词和词性标注的特征模板。假设当前分析的汉字是 “450 公里”中的“0”,特征模板生成的特征:C-2=4,C-1=5,C0=0,C1=公,C2=里;C-2C-1=45,C-1C0=50,C0C1=0公,C1C2=公里;C-1C1=5公;Pu(C0)=0;T(C-2)T(C-1)T(C0)T(C1)T(C2)=11 144。
2.2 训练算法

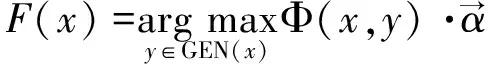
(1)

下面是感知机训练算法的伪代码。本文使用了“平均参数”技术(Collins, 2002)避免过拟合。
1:Input: Training examples (x,y)
3:fort←1…Tdo
4:fori←1…Ndo
3 语料自动融合
本文采用自动融合语料的方法提高词法分析的精度。基本流程如下(流程如图2所示):
1. 将源语料(语料1)转化为与目标语料切分和词性标注标准一致的语料(语料3);
2. 将目标语料(语料2)和转化后的语料(语料3)合并,成为更大的语料(语料4);
3. 用语料4训练新的分词和词性标注模型。本方法的关键是第一步。

图2 方法流程图
3.1 分词和词性标注标准的自动转化
为了方便说明,“源语料”表示其他领域的语料,“目标语料”表示当前训练词法分析器所需要的语料;“源标准”表示“源语料”的分词和词性标注标准,“目标标准”表示“目标语料”的分词和词性标注标准;“源分析器”表示用“源语料”训练的词法分析器,“目标分析器”表示用“目标语料”训练的词法分析器。
首先,为了获取源标准,用源语料训练一个源分析器,该分析器是用来处理目标语料使其带有源标准的。然后利用这个带有源标准的语料(作为源转化特征)和目标语料训练一个从源标准到目标标准的转换分析器。最后,用这个转换分析器处理源语料(并将源语料作为源转换特征),使其具有目标标准。经过以上步骤,便成功地将源语料转化为具有目标标准的语料。图3描述了语料标准转化的过程。该方法是合理的,因为目标语料经源分析器处理后,分词和词性标注的格式与源语料很相似,当然也存在一定的噪声,因为源分析器的精度不是百分之百。但是再通过转化训练,将源标准转化为目标标准的同时,起到了修正源分析器错误结果的作用,使得模型具有一定的容错能力。最后,再用该模型处理源语料,便可将源语料转化为具有目标标准的语料。
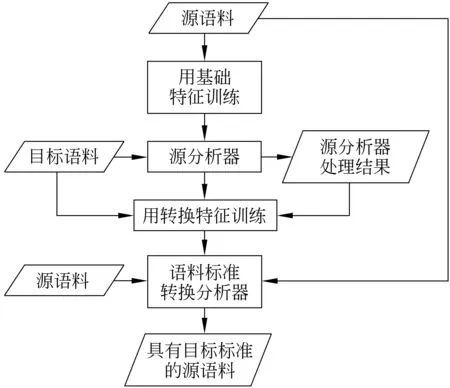
图3 将源语料转化为具有目标标准的语料
表2 描述了转换特征的一个例子。假设正在分析汉字串“美国副部长”中的“副”字,该汉字串经源分析器处理后被切分和标注为“美国/ns 副/b 部长/n”,而目标语料中切分和标注情况为“美国/NR 副部长/NN”。以联合分词与词性标注为例,语料标准转化过程如下: 经源分析器处理后,汉字串“美国副部长”中的“副”字被标记为“副/s_b”,表示“副”是单字副词,经过转换后“副”字被标记为“副/b_NN”,表示一个名词的词首。除了“@=s”和“@=s-b”以外,转换特征和基础特征基本一致,其中“@=s”表示源分析器标记当前汉字的位置信息为“s”,单字词;“@=s_b”表示源分析器标记当前汉字的位置和词性信息为“s_b”,单字副词。
3.2 训练与解码
将上面处理好的具有目标标准的源语料与目标语料合并,用这个合并后的大语料训练,便可得到一个新的词法分析器。训练新的词法分析器只用基础特征,不需要转化特征。
本方法与Jiang et al.[1]的方法有些类似,但也有很大的不同。图4和图5分别是Jiang et al.[1]方法的训练流程图和解码流程图。Jiang et al.[1]的方法旨在利用源语料信息,将其分词和词性标注标准作为特征指导目标分析器。该方法在解码时分为两步,首先用源词法分析器对测试语料进行切分,然后再用目标词法分析器切分一次,并以第一次的切分结果为特征指导第二次的切分。此方法取得了很好的效果,但是需要两次解码,增加了解码的复杂性。本论文方法旨在利用语料自动融合技术,训练出一个更好的词法分析器。其优点体现在词法分析精度高,只需一次解码,更具有实用性。并且,本方法还可以融合多领域语料,不限于两种,更具有扩展性。

表2 用于训练转化模型的转换特征
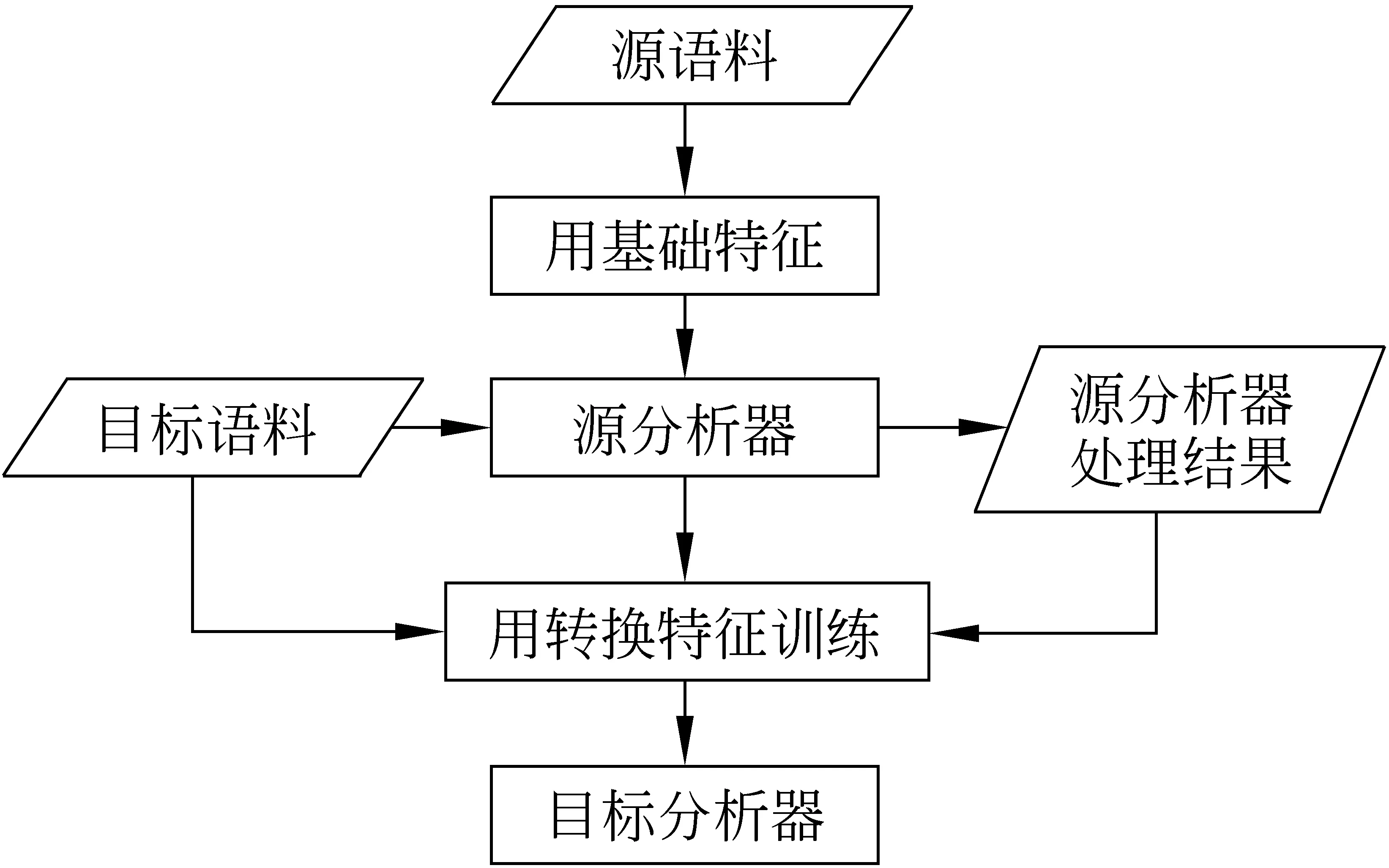
图4 Jiang et al.的训练流程

图5 Jiang et al.的解码流程
4 实验与结果分析
4.1 实验数据、环境和评测方法
本文实验采用《人民日报》语料和宾州中文树库语料5.0。这两种语料库具有不同的分词和词性标注标准,词性标注集也不同 (例如图1中的描述)。《人民日报》训练语料与测试语料的句子数分别为 100 344 和19 007,宾州树库训练语料与测试语料的句子数分别为18 074和348。
训练和解码的实验环境。操作系统: Red Hat Enterprise Linux AS,X64;处理器: Quad-Core AMD Opteron Processor 8347HE,1.9GHZ;内存: 64G;编译环境: GCC4.1。
本文采用F-measure 来评价词法分析精度,F1=2PR/(P+R),其中P是准确率,R是召回率。
4.2 结果与分析
表3的前三行是单独的在相应的语料上利用感知机算法训练的模型,即Baseline模型。表中PD表示《人民日报》语料,CTB表示宾州中文树库语料,PD→CTB 表示将《人民日报》语料融入到宾州树库语料中,CTB→PD 表示将宾州树库语料融入到《人民日报》语料中,PD+CTB表示将《人民日报》语料与宾州树库语料直接合并。“--”表示没有做该部分实验,因为PD与CTB词性标注集不同。
分别比较表3的第一行和第三行,可以看出联合分词与词性标注要比单独分词的精度高,因为词性标注信息相当于是额外的特征(Ng and Low, 2004)。同时可以看出,用PD训练模型,并且在CTB上进行测试,无论是分词还是联合分词与词性标注,精度都会下降很多(F1值只有不到92%),比单独在CTB上训练的模型精度(97%以上)低很多。虽然PD比CTB大很多,仍然不会提高精度,因为不同领域的语料的分词和词性标注标准不同。然而,利用本方法将PD融入CTB后,在CTB上做测试,无论单独分词还是联合分词与词性标注,F1值都有很明显的提高,较单独CTB训练的模型提高0.81个百分点,联合分词与词性标注的F1值分别提高了0.38个百分点(不考虑词性标注)和0.96个百分点(考虑词性标注)。将CTB融入PD后,在PD上测试,单独分词和联合分词与词性标注的F1值也都有提高。因为 CTB语料相对PD语料太少,只有不到其五分之一,因此F1值的提高不明显。直接将PD与CTB合并训练,无论在PD还是CTB上测试,F1值都下降很多。尤其是在PD上测试,F1值急剧下降,可见不同标准语料直接合并产生的负面影响也很大。

表3 单独分词、联合分词与词性标注的结果
表4中,源语料是PD,目标语料是CTB,测试集是CTB测试集。从表4可以看出,本方法与Jiang et al.[1]的方法相比,分词和联合分词与词性标注的性能基本与其相当,甚至略高一些,因为大语料具有更高的词语覆盖率,而如果遇到没有出现的词语,基于错误驱动的修正方法仍然无法很好的处理。而且本方法的解码速度快很多,其中分词速度提高了34.15%,联合分词与词性标注的速度提高了53.38%。并且,解码步骤只有一步,实用性更强。

表4 方法比较
表5中,“错误融合法”指的是首先利用目标分析器处理源语料,使其具有目标标准,再将处理后的源语料合并到目标语料中,再由这混合后的大语料训练出新的目标分析器。该方法看似更简单,但源语料经目标分析器处理后,虽然接近目标标准,却有很多错误的切分结果,直接使用会产生负面影响。表5的结果表明,利用该方法得到的分词结果比融合语料前只提高0.05个百分点,不排除是融入大语料提高了词语覆盖率所起的作用。而且联合分词与词性标注的F1值比融合语料前低很多,可见融合了含有错误信息的语料将导致词法分析精度的下降。

表5 错误融合法
综上所述,通过一系列实验,从正、反两面都说明了本方法的有效性和较强地实用性。
5 结语
本文提出了一种异种语料的自动融合方法,将该方法应用于中文词法分析,明显地提高了词法分析性能。我们用《人民日报》语料和宾州中文树库语料进行了实验,并且利用平均感知机算法,分别在《人民日报》语料、宾州中文树库语料以及融合后的语料上训练模型,对各个模型的分词以及联合分词与词性标注的效果进行了比较,实验结果表明,本方法确实可以提高词法分析精度。
本文还将本方法与Jiang et al.[1]的方法进行了比较,本方法在保证了与Jiang et al.[1]的方法具有相当性能的情况下,提高了分词以及联合分词与词性标注的解码效率。本方法具有更简单的解码步骤,实用性更强。而且本方法不局限于融合两个领域的语料,更具有扩展性。
接下来,我们将继续研究语料标准的转化方法,以及后续改进的语料合并方法,例如,语料加权合并。并且,进一步融合其他领域的语料以提高词法分析精度。
[1] Wenbin Jiang, Liang Huang, Qun Liu. Automatic Adaptation of Annotation Standards: Chinese Word Segmentation and POS Tagging—A Case Study. Association for Computational Linguistics[C]//Proceed-ings of the 47th Annual Meeting of the Association for
Computational Linguistics. Suntec, Singapore: ACL Publication Chairs, 2009:522-530.
[2] Hwee Tou Ng, Jin Kiat Low. Chinese part-of-speech tagging: One-at-a-time or all-at-once? word-based or character-based?[C]//Proceedings of Conference on Empirical Methods in Natural Language Processing. Barcelona, Spain: ENMLP Publication Chairs, 2004.
[3] Wenbin Jiang, Liang Huang, Yajuan Lv, et al. A cascaded linear model for joint Chinese word segmentation and part-of-speech tagging[C]//Proceedings of the 46th Annual Meeting of the Association for Computational Linguistics. Oho, USA: ACL Publication Chairs, 2008:897-904.
[4] Wenbin Jiang, Haitao Mi, Qun Liu. Word Lattice Reranking for Chinese Word Segmentation and Part-of-Speech Tagging[C]//Proceedings of the 22nd International Conference on Computational Linguistics. Manchester, England: COLING Publication Chairs, 2008:385-392.
[5] Kun Wang, Chengqing Zong, Keh-Yih Su. A Character-Based Joint Model for Chinese Word Segmentation[C]//Proceedings of the 24th International Conference on Computational Linguistics. Beijing, China: COLING Publication Chairs, 2010:1173-1181.
[6] Zhongguo Li, Maosong Sun. Punctuation as Implicit Annotations for Chinese Word Segmentation[J].Computational Linguistics. Proceedings of Computational Linguistics. 2009, 35(4):505-512.
[7] Yue Zhang, Stephen Clark. Chinese segmentation with a word-based perceptron algorithm[C]//Proceedings of the 45th Annual Meeting of the Association for Computational Linguistics. Prague, Czech Republic: ACL Publication Chairs, 2007:840-847.
