(2017年度“华苏杯”获奖论文三等奖)基于随机森林回归算法的电影评分预测模型
2018-05-21陆君之
陆君之
中国电子科技集团第二十八研究所
0 引言
随着人民生活水平的不断提高,观看电影已经成为了大家日常生活中不可或缺的娱乐方式之一。我国作为全球第二大电影市场,电影产业规模一直保持着每年30%左右的增长,焕发出旺盛的生命力和巨大的可持续发展潜力。然而整个市场的电影质量却是参差不齐,每年都会有大量大家俗称的“烂片”上映,并且各大电影评分网站存在制片公司雇佣“水军”刷评分的现象,导致观众在观看前没有信息渠道真正判断一部电影的好坏,电影评分预测模型可以对尚未上映的电影做出客观的评分,供观众进行参考。
本文主要结构如下:第1节介绍本实验所使用的相关技术和资源介绍;第2节介绍基于随机森林算法的电影评分预测模型的建模过程;第3节是实验内容与结果的分析,最后一节是总结与展望。
1 相关介绍
1.1 Spark MLlib
Spark是一个用来实现快速而通用的集群计算的开源簇运算框架。它扩展了广泛使用的MapReduce计算模型,适用于各种原先需要不同分布式平台的场景,大大减轻了原先需要对各种平台分别管理的负担。spark可以在内存中进行计算,因而它比MapReduce更加高效,即使在硬盘上进行运算,它也比MapReduce更快。
MLlib是Spark中提供机器学习函数的库,它是专为在集群上运行的情况而设计的。MLlib可使用许多常见的机器学习和统计算法,这些算法用来在集群上针对分类、回归、聚类、协同过滤等,简化大规模机器学习时间。其中一些算法也可以应用到流数据上,例如使用普通最小二乘法或者K均值聚类(还有更多)来计算线性回归。
1.2 豆瓣电影网
豆瓣电影网是国人最常用的对电影进行打分,写影评的数据网站,相比于IMDB更能体现国人对于电影文化的理解。虽然近年来豆瓣电影也开始出现“水军”刷分的现象,但是从“水军”现象的根源来看这并不影响豆瓣电影以往评分的真实性和有效性,并且虽然有延时性,豆瓣电影网也会将“非正常打分”的行为进行判断并不计入评分。
豆瓣电量评分的主旨和原则是“尽力还原普通观影大众对一部电影的平均看法”,是国内最公平公正的电影评分网站之一。国内相当多的电影评论节目,例如“暴走看啥片儿”,也将豆瓣电影评分作为衡量标准向观众推荐电影。它的电影数据也是符合本实验需要的,本实验用于数据分析实验的数据从豆瓣电影网上爬虫获取。
2 基于随机森林回归算法的电影评分预测模型
本文选用随机森林回归算法来做实验基于以下原因:
(1)电影中导演的评分、演员的评分、编剧的评分等输入特征之间可能存在潜在的相关性,但对于这些相关性很难正确的去进行衡量,因此对于特征之间多重共线性十分敏感的算法是不适用的。随机森林算法对于特征之间相关性并不敏感,也不需要对特征进行选择,非常适用于本次回归实验。
(2)随机森林算法鲁棒性很好,对于离散数据点相对而言不敏感,由于电影信息多样性,难免会有噪音数据,随机森林算法可以有效的避免这些数据对于最终模型的影响。
(3)随机森林算法可以评估所有输入特征的重要性,为下一步研究向大众推荐高质量电影打下基础。
2.1 特征工程
特征工程是大规模机器学习中非常重要的一步,特征选取的好坏直接影响到算法的效率。信息丰富的输入特征与将现有特征转换为合适的向量都能够极大的改进实验结果。本实验的特征选择结合中国内地电影市场实际情况,选取导演、编剧、主演、类型、国家地区作为特征,如公式(1)所示:
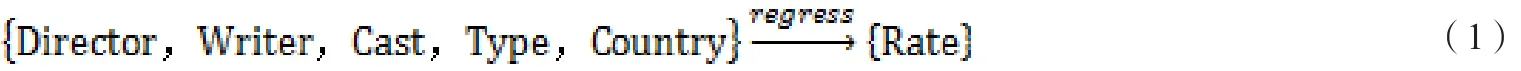
其中:Director表示导演执导水平特征,Writer表示编剧水平特征,Cast表示主演水平特征,Type表示影片类型特征,Country表示国家地区特征,Rate表示电影评分。
本节具体阐释影响电影评分的重要因素并给出相应定义,为随机森林回归模型的建立做好准备。
(1)导演执导水平特征
导演是电影创作团队的领导者和组织者,决定了电影艺术风格,对电影质量起到了非常重要的影响因素。本实验中以导演之前执导电影所获得的评分以及评分人数作为导演执导水平特征。考虑到虽然电影评分人数也是非常重要的维度,但是将电影评分人数单独作为一个输入特征引入的话,特征之间scale差距过大,会对收敛速度造成严重影响,所以我们将电影评分和电影评分人数作为一个特征组合来引入特征集中,作为对影人水平的综合评分,如公式(2)所示:

n表示导演参与拍摄的所有电影作品中,距离该部电影上映最近的n部电影,n取值小于等于5;
Rk表示导演拍摄的第k部电影的评分;
Pk表示导演拍摄的第k部电影的评分人数。
(2)编剧水平特征
编剧是电影剧本的创作者,剧本是电影拍摄的基础,决定了电影的上限。本实验取编剧主创的所有电影剧本中,距离该部电影上映最近的n部电影,n取值小于等于5,如公式(3)所示:

Rk表示编剧创作的第k部电影的评分;
Pk表示编剧创作的第k部电影的评分人数。
(3)主演水平特征:
演员具有独特的个人魅力,演员的发挥直接影响到一部电影口碑的好坏。考虑到大部分演员每年参演电影作品数量很多,对于演员的特征字段,本实验会参考演员参与拍摄的所有电影作品中,距离该部电影上映时间最近的n部相同类型且由他主演的电影,n取值小于等于5,主演水平特征计算公式(见公式(4))及说明如下:
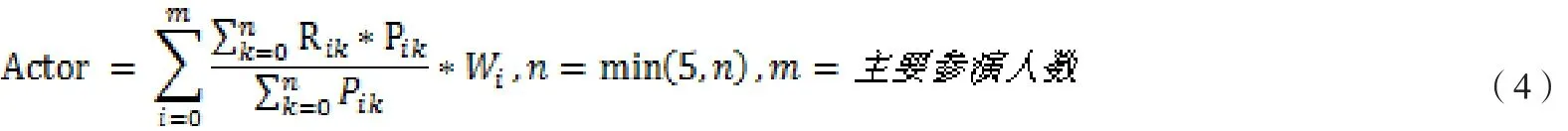
Rik表示第i位主演拍摄第k部电影的评分;
Pik表示第i位主演拍摄第k部电影的评分人数;
Wi表示第i位主演在此部电影的权重,这里本实验权重设置如表1所示,参演人数多于4位,则从第5位开始不考虑其对电影的影响。
(4)影片类型
电影有爱情片、动作片、喜剧片等多种类型组合,观众在不同时期可能对电影的类型有不同的喜好。因此电影类型对于其口碑是非常重要的特征,电影类型决定了它内容的表现形式,观众基础和影响力。因为一部电影经常会被贴上多种类型标签,所以对于该特征本实验需要综合考虑各个类型的权重计算得到它的评分。本实验取上一年此类型电影平均得分作为参考值,比如电影《寒战》于2012年11月08号上映,则分别选取类型为剧情、动作、犯罪且上映时间范围应该为
2011年11月08号到2012年11月08号的电影,计算得到此 类型电影的参考评分,见公式(5)与(6):

Rik表示第k部类型为i的电影的评分;
Pik表示第k部类型为i电影的评分人数;
Ri表示第i种类型电影综合评分;
Wi表示第i种类型在此部电影中的权重。
(5)国家地区
根据制片公司所在国家或地区的不同,观众受个人的文化背景和社会背景影响对于该地区的电影的看法也是不同的,因此国家地区也是电影口碑重要的特征之一。本实验取上一年此国家地区电影平均得分作为参考值,比如电影《寒战》于2012年11月08号上映,则选取同为香港制作且上映时间范围应该为2011年11月08号到2012年11月08号的电影,计算得到此电影的参考评分,见公式(7):

Rk表示第k部电影的评分;
Pk表示第k部电影的评分人数。
3 实验和结果分析
3.1 数据获取
本实验基于SCRAPY框架,采用“深度优先”算法,爬虫收集豆瓣电影网从2000年至2016年上映的所有电影数据作为本次实验的数据集,首先从豆瓣电影网的各个标签下的电影列表爬取获取电影信息,然后获取每一部电影相关推荐和影人代表作品中的电影加入到爬取队列中去,最终共收集到8万多条电影数据。经过整理,电影属性如表2所示:

表2 电影属性表
3.2 实验过程
(1)随机森林算法回归建模:
本实验利用spark mllib的randomforest包实现随机森林回归算法。首先将2015年以前出品的电影的评分数据作为训练数据,2016年出品的电影数据作为测试数据。我们将处理好的特征字段和电影评分处理成Labeledpoint,LabeledPoint是spark中用来表示带标签的数据点,包含一个特征向量和一个标签(由一个浮点数表示),本实验中标签为电影的评分,特征向量为上述特征工程所处理的,构造的LabeledPoint,见公式(8)
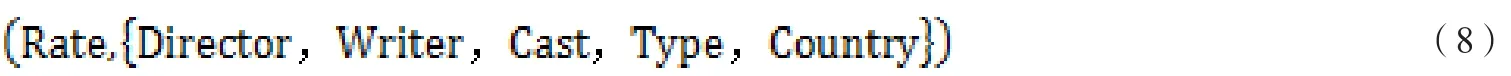
使用mllibtree.RandomForest的trainRegressor()方法来建立起随机森林回归模型。TrainRegressor()方法会返回一个weightedEnsembleModel对象,本实验使用此对象的predict()方法对测试集预测对应的值,即电影评分。接下来的实验中,将测试数据输入到建立好的随机森林中进行测试。
(2)误差对比
本实验除了给出使用随机森林回归算法模型的误差,还采用了DT算法、GBDT算法、Isontonic算法进行对比,误差比较如表3所示:
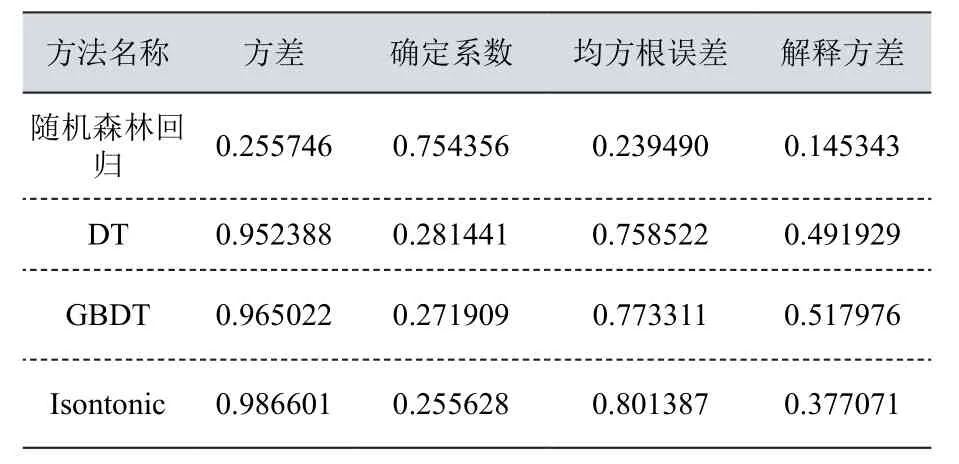
表3 算法误差对照表
从上述对预测的误差对比试验可以看出,本文所使用的随机森林回归算法建立的模型预测性能明显优于其他算法模型,在预测电影评分时相对误差远低于其他算法,同时它的确定系数也是最高的,说明这个模型在数据拟合上的表现是最好的。
本实验部分电影预测结果如下表4所示:
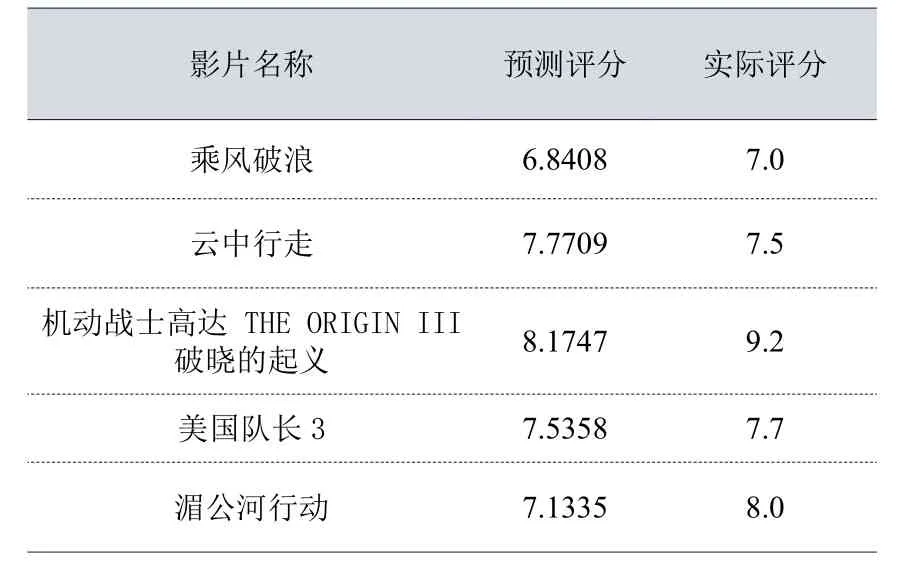
表4 部分电影评分预测结果表
4 总结和展望
本文从实际的中国电影产业市场出发,提出一种基于随机森林回归算法的电影评分预测模型,将机器学习应用于电影评分预测领域,通过将导演、编剧、主演、类型、发行国家地区作为影响电影评分的特征,对其进行特征工程处理。通过对比试验,随机森林回归算法模型确实比其他算法在预测电影评分的相对误差更低,同时预测的确定系数也更高。综上所述,本文提出的基于随机森林回归算法的评分预测模型解决了电影评分预测精度不高的问题,能够为大众推荐电影提供有价值的参考,具有实际的意义。
