基于改进K-means算法的微博舆情分析研究*
2018-01-26谢修娟李香菊莫凌飞
谢修娟 ,李香菊,莫凌飞
(1.东南大学成贤学院计算机工程系,江苏 南京 210000;2.东南大学仪器科学与工程学院,江苏 南京 210000)
1 引言
随着媒体技术的不断进步和信息传播渠道的日趋多元化,当今社会进入了“人人都是新闻传播者”的自媒体时代。广大网民参与言论的热情高涨,特别是微博的兴起,网民可以通过电脑、手机随时随地发表言论。新浪微博——Twitter[1]类的新兴网络应用,自2009年推出,截至目前,注册用户已超过5亿,月活跃用户数约为2亿,用户每日发博量突破1亿条[2]。可见,微博上的舆论已成为网络舆情中极具影响力的一种。如何从海量数据中快速有效地发现网民关注的热门话题?从而引导政府相关部门及时捕捉微博中敏感的舆论信息,合理地控制负面舆论的扩散。目前,很多政府机关采用全人工或是半自动的监测统计方法,效率低,准确度也低[3,4]。因此,迫切需要一种更为有效的微博热点话题发现方法。
K-means[5]是一种最为经典、使用最为广泛的划分聚类算法,经常被用于网络舆情的聚类中。但是,其使用有一定的局限性[6 - 8]:(1)需要事先确定聚类数;(2)初始聚类中心的选择方法不一,选取不当,往往导致最终聚类结果陷入局部最优。针对上述情况,研究者从不同角度提出一系列改进的K-means算法,文献[9]利用文档标题的稀疏相似度,确定K-means算法的初始聚类中心;文献[10]提出用凝聚的层次算法干预K-means算法的随机选取聚类中心的方式,保证最终的初始聚类中心更具有典型性;文献[11]提出使用二分思想递归分裂相似度大于给定阈值的簇,合并相似度小于阈值的簇,来获得聚类簇数。
本文提出一种基于密度的K-means聚类算法,对传统的K-means初始聚类中心选择方法进行改进,并将改进后的算法用于新浪微博的聚类中,以期能更快、更准确地对最近的微博数据进行聚类,以便发现微博热门话题。
2 相关的定义
定义1微博文档的表示:采用空间向量模型VSM(Vector Space Model),bi=(w1(bi),w2(bi),… ,wj(bi),… ,wn(bi)),wj(bi)表示第j个特征项在微博文档bi中的权重,本文权重计算采用TF-IDF方法,w=tf×idf,tf指特征项在某微博文档bi中出现的次数,idf是特征项在微博文档集bi中出现频率的量化。为了降低高频特征项对其它中低频特征项的抑制作用,需要对特征向量进行归一化处理,处理后的权重计算公式如下:
其中,tfj(bi)是指第j个特征项在bi中出现的次数,N是所有微博文档的个数,nj表示包含第j个特征项的微博文档的个数,n是bi中特征项的总个数,分母为归一化因子。
定义2两个微博文档bi和bj之间的相似度similarity(bi,bj) 定义为两个向量对象在状态空间方向上正交的可能性,用这两个向量的夹角余弦cosθij表示,若完全正交,表示两文档毫无相似性,点积为0。夹角余弦cosθij采用如下的计算公式:
其中,bik、bjk分别表示文档bi和bj第k个特征项的权值,1≤k≤N。
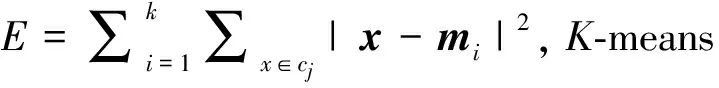
其中,E表示所有聚类文档的误差平方和,x是聚类簇cj中某个聚类文档,mi是每个聚类簇cj内所有聚类文档的均值。
定义4密度density:给定文档集合BL,b∈BL,文档b的密度定义为该文档与其它文档的平均相似度,采用如下的计算公式:
density(b)=∑x∈BLsimilarity(x,b)/NBL
其中,分子是文档b与其它文档两两间的相似度之和,分母是BL所包含的文档数。
定义5核心文档:若文档b的密度大于或等于给定参考值refSimilarity(大于0),则该文档是核心文档,refSimilarity称为密度阈值。
通过计算密度得到核心文档,能有效地规避噪声文档,避免初始聚类中心取到孤立点而导致聚类结果陷入局部最优。采用反证法:假设噪声点是核心文档,而其与各个文档间极不相似,根据定义2和定义3,噪声文档的密度约为0,这与核心文档的定义相冲突,因此,核心文档不可能是噪声文档。
3 改进的K-means聚类算法
3.1 基于密度思想的初始聚类簇中心选择算法
借鉴DBSCAN密度聚类思想,本文提出一种初始聚类簇中心选择算法InitialCenters,首先找出所有核心微博文档,选取K个相互间最不相似的核心文档作为初始聚类中心。
InitialCenters算法流程描述如下:
输入:微博文档集合blogList={b1,b2,…,bn};聚类簇数K;密度阈值refSimilarity。
输出:初始聚类簇中心centers={c1,c2,…,cK}。
Step1对于给定的微博文档集合blogList,求出任意两个文档间的相似度,保存至相似度矩阵docSimilarity中;
Step2根据相似度矩阵docSimilarity,计算每一个文档与其它文档两两之间的平均相似度,找出平均相似度高于密度阈值的文档,形成核心文档集合coreDocs;
Step3将coreDocs中的第一个核心文档作为第一个初始聚类中心点centers[1],并从coreDocs删除该文档,令计数变量nk=1,同时,将centers[1]置为当前聚类中心点;
Step4遍历coreDocs剩余核心文档,选择与当前聚类中心点最不相似的文档作为下一个初始聚类中心点,添加到centers中,并从coreDocs删除该文档;
Step5更新当前聚类中心点,并使nk=nk+1,转Step 4;
Step6重复Step 4和Step 5,直至nk与聚类簇数K值相等为止,输出centers,算法结束。
3.2 改进的K-means聚类算法
将InitialCenters算法所得到的初始聚类簇中心,再按照传统的K-means算法重复迭代,得到最终的微博数据聚类结果。
给定微博文档集合blogList={b1,b2,…,bn},初始聚类簇中心点集合centers={c1,c2,…,cK},初始化聚类簇clusters={clu1,clu2,…,cluK},K为聚类数。
其具体步骤如下:
Step1计算每个微博文档bi与每个初始聚类簇中心点的相似度,并将bi归入到与其最相似的簇clusters中;
Step3重复迭代Step 1和 Step 2,直到准则函数E收敛;
Step4输出最终聚类结果。
4 实验过程与结果分析
4.1 实验过程设计
本文将使用相同的数据源对传统的K-means算法以及改进后的K-means算法进行对比实验,以验证本文提出的改进算法在聚类效果上的优越性。
首先构建了一个抓取新浪微博的API,选取一些时下比较热门、关注度高的词条作为关键词抓取数据。本实验分别以“春晚”“逼婚”“芈月传”“环卫工”为关键词抓取了每个类别最近发表的1 000条微博数据,为保证数据的有效性,经人工过滤,从每个类中选取200条字符长度在15以上的微博,共计800条数据,作为此次实验的训练测试集。采用中国科学院ICTCLAS分词系统对微博数据进行分词、词性标注处理,并借助停用词表对分词结果中的词汇进行停用词过滤,而后使用定义1提及的TF-IDF方法构造微博数据的向量空间模型(VSM特征项矩阵),来实现微博文本聚类。
4.2 实验结果分析
本文采用F度量值[12]作为聚类结果的评价标准。该方法同时兼顾了查准率(P)和查全率(R)两个指标,P和R分别由下面的计算公式得到。
P=TP/(TP+FP)
R=TP/(TP+FN)
其中,TP为正类被划分为正类的文档数,即聚类的正确文档数,FP为负类被划分为正类的文档数,FN为正类被划分为负类的文档数,TP+FP表示实际分类的文档数,TP+FN表示应有的文档数。
为更客观地评价聚类性能,本研究对传统的算法进行多次随机选择初始聚类中心完成聚类,对本文提出的初始中心选择算法,也是选取了多个密度阈值进行聚类,分别取各自最佳的一次结果。参数的取值情况为:传统的K-means算法,初始聚类中心为(3,102,456,617),改进后的K-means算法密度参考值为0.036 25。表1是传统的K-means算法与改进后的K-means算法的F值的实验结果。

Table 1 F value comparison between the traditional K-meansalgorithm and the improved K-means algorithm
从表1中不难发现,改进后的聚类算法F值相对比较稳定,而不像传统算法F值上下波动比较大,此外,改进后的算法总体的聚类准确度有所提高,表1中,除了“逼婚”这一类别偏低,其它三类都比传统算法的F值高。可见,运用改进后的K-means算法对四个关键词近4 000条的微博数据进行聚类,所得到的聚类簇基本与事实数据一致,从每个簇中的特征项可以很快获得舆论关注的热点,以“春晚”为例,最近讨论比较多的是“六小龄童”“春晚主持人”“春晚吉祥物”“节目单”等,其中“六小龄童”热度最高。
再者是运行时间,虽然改进后的算法在计算初始聚类中心时有一定时间消耗,但是从几次实验来看,聚类过程中的迭代次数少了,因此最终的运行时间成本反而降低了。为验证改进算法的时间效率,在传统算法以及改进算法的多次实验中,分别选取具有代表性的四次聚类时间进行比较,图1直观地显示了改进后的算法在运行时间上所表现出的优越性。
可见,改进后的K-means算法不仅提高了微博聚类的正确性、稳定性,而且提高了运行效率,运用改进的K-means算法对一段时间内的微博数据进行聚类,能够快速、准确地发现舆情热点话题。
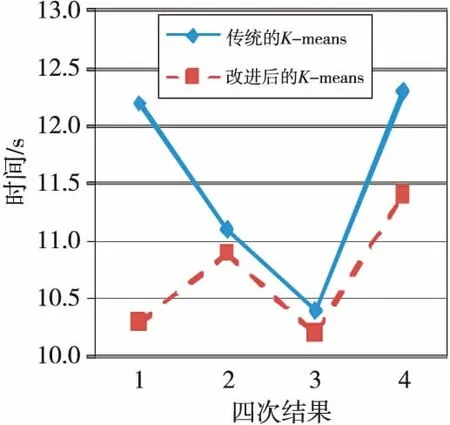
Figure 1 Comparation of time t图1 时间t值的比较
5 结束语
本文借鉴了密度聚类算法DBSCAN的思想,对K-means的初始聚类中心选择方法进行优化,提出在平均相似度较高的核心文档中找出相互间最不相似的文档作为初始聚类中心,以消除初始聚类中心选取到孤立点可能导致聚类结果陷入局部最优的不良影响,并将改进后的算法应用于微博数据的聚类中。实验结果表明,改进后的算法在聚类的准确性和时间效率方面都有一定的优势,可以用其对微博数据进行聚类分析,以发现一段时间内的微博舆情热点。
[1] Yu L L,Asur S,Huberman B A.Trend dynamics and attention in Chinese social media[J].American Behavioral Scientist,2015,59 (9):1142-1156.
[2] Wei Yang.Enterprise negative network public opinion propagation characteristic research based on the sina weibo[D].Hefei:Anhui University,2013.(in Chinese)
[3] Yi Chen-he.Emergency evolution law of network public opinion and government monitoring[D].Xiangtan:Xiangtan University,2014.(in Chinese)
[4] Zhang Li-juan.The countermeasure research of network public opinion guide of the local government[J].China Management Informationization,2015,18(18):203-204.(in Chinese)
[5] Takens F. Determing strange attractors in turbulence[M]∥Lecture Notes in Mathematics.Berlin:Springer Berlin Heideberg,1981:339-359.
[6] Yuan Fang,Zhou Zhi-yong,Song Xin.K-means clustering algorithm with meliorated initial center[J].Computer Engineering,2007,33(3):65-66.(in Chinese)
[7] Tang Xiao-qin,Dai Ru-yuan.Technique of cluster analysis in data mining[J].Microcomputer Information,2003,19(1):3-4.(in Chinese)
[8] Yang Zun-qi, Zhang Qian-nan.Research on attention of microblog users based onK-means cluster analysis[J].Journal of Intelligence,2013,32(8):142-144.(in Chinese)
[9] Tang Han-qing,Wang Han-jun.Application of improvedK-means algorithm to analysis of online public opinions[J].Computer Systems & Applications,2011,20(3):165-168.(in Chinese)
[10] Luo Hui-xia, Qu Xiao-ling.The improvement ofK-means clustering algorithm based on internet public opinion[J].Computer Development & Applications,2010,23(8):4-6.(in Chinese)
[11] Zhang Zhong-ping, Wang Ai-jie,Chai Xu-guang.Easy and efficient algorithm to determine number of clusters[J].Computer Engineering and Applications,2009,45(15):166-168.(in Chinese)
[12] Zhong Jiang,Liu Rong-hui.Improved KNN text categorization[J].Computer Engineering and Applications,2012,48(2):142-144.(in Chinese)
附中文参考文献:
[2] 魏杨.基于新浪微博的企业负面网络舆情传播特征研究[D].合肥:安徽大学,2013.
[3] 易臣何.突发事件网络舆情的演化规律与政府监控[D].湘潭:湘潭大学,2014.
[4] 张李娟.地方政府网络舆情引导的对策研究[J].中国管理信息化,2015,18(18):203-204.
[6] 袁方,周志勇,宋鑫.初始聚类中心优化的K-means算法[J].计算机工程,2007,33(3):65-66.
[7] 汤效琴,戴汝源.数据挖掘中聚类分析的技术方法[J].微计算机信息,2003,19(1):3-4.
[8] 杨尊琦,张倩楠.基于K-means算法的微博用户推荐功能研究[J].情报杂志,2013,32(8):142-144.
[9] 汤寒青,王汉军.改进的K-means算法在网络舆情分析中的应用[J].计算机系统应用,2011,20(3):165-168.
[10] 罗晖霞,曲晓玲.基于网络舆情的K-Means算法的改进研究[J].电脑开发与应用,2010,23(8):4-6.
[11] 张忠平,王爱杰,柴旭光.简单有效的确定聚类数目算法[J].计算机工程与应用,2009,45(15):166-168.
[12] 钟将,刘荣辉.一种改进的KNN文本分类[J].计算机工程与应用,2012,48(2):142-144.
