面向国产异构系统的HPL异构协同设计*
2018-01-26甘新标孙燎原雄成伟黄嘉昆
甘新标,孙燎原,刘 杰,雄成伟,黄嘉昆
(1.国防科技大学计算机学院,湖南 长沙 410073;2.计算机软件新技术国家重点实验室(南京大学),江苏 南京 210093;3.国防科技大学量子信息研究所兼高性能计算国家重点实验室,湖南 长沙 410073)
1 引言
高性能计算是衡量国家科技能力的重要标志,已广泛应用于大规模数值计算、武器装备模拟仿真等领域。为了制衡和封锁中国巨型机技术发展,美国商务部2015年2月18日发布芯片限售令,我国国家超级计算长沙中心、国家超级计算广州中心、国家超级计算天津中心和国防科技大学4家机构被列入美国芯片限售对象。幸运的是,中国高性能处理器发展技术早有预案,国产加速器(China Accelerator)就是国防科技大学计算机学院自主研发的高性能加速器[1]。China Accelerator的软件生态不同于GPU、MIC等比较成熟的加速器,其体系结构和编程模型更是有别于传统的CPU体系结构和编程模式,开发高效的应用程序将面临体系结构复杂、细节多,并行编程要求高、难度大,数据流动管理与分派繁琐复杂,优化困难等诸多挑战。因此,面向国产异构系统的HPL(High Performance Linpack)异构协同设计可以为China Accelerator广泛应用于核爆模拟、天气预报、地质资源勘查等领域提供技术参考,加速China Accelerator的推广应用。
线性系统软件包Linpack(Linear system package) 通过使用高斯消元法求解稠密一元N次线性代数方程组来评估高性能计算机的实际浮点性能,Linpack根据问题规模与优化选择的不同分为Linpack100、Linpack1000 以及HPL[2]。HPL采用高斯消元法求解N元一次稠密线性代数方程组来评估高性能计算机的浮点性能。高斯消元法首先将系数矩阵A通过分块递归的LU分解,将其分解为一个下三角阵L与一个上三角阵U的乘积,然后将线性代数方程组Ax=b演算成Ux=L-1b形式,最后,通过上三角方程回代求得线性方程组的解[3 - 5]。HPL由于规模可变,成为目前最流行的用于测试高性能计算机浮点性能的测试基准。当HPL求解问题规模为N时,浮点计算次数为(2/3)N3+(3/2)N2,计算时间为T,HPL测试浮点性能值为(2/3)N3+(3/2)N2)/T,浮点计算性能测试结果是高性能机Top500排名的重要依据。
由于支持China Accelerator的底层矩阵乘接口目前仅支持定制接口,为了提供一个通用的HPL测试环境,需要完成矩阵循环分布细致划分与封装dPEM(delicate Partition and Encapsulation on Matrix)。同时,为了充分发挥国产异构系统的效率,设计了异构协同矩阵乘调度算法OA4MM(Orchestrating Algorithm for Matrix Multiplication)。
2 面向CPU+China Accelerator的HPL设计
传统HPL算法中,求解N×N矩阵将以块为单位循环分布到所有CPU,由于矩阵采用了块循环分布,在N较大时,各个处理器的计算量基本相当,对于同构系统,传统的HPL一般可以获得较高的系统性能。由于计算速度的差异,如果给异构系统中每个处理器分配相同的计算量,那么计算速度快的加速器在完成计算后必须等待计算速度较慢的CPU进行通信,必然降低异构系统效率。因此,为了充分发挥异构系统的效率,必须基于异构系统结构设计高效协同的HPL算法。由于矩阵乘更新操作占据了HPL求解绝大部分计算时间,因此高效协同的HPL算法设计将满足CPU端矩阵乘更新计算时间TCPU与China Accelerator端矩阵乘更新计算时间TChina Accelerator在相同时间点完成各自的计算,避免不必要的通信等待。即:
其中,M、N、K分别为矩阵A(M,K)、B(K,N)、C(M,N)的纬度。
2.1 支持China Accelerator的矩阵乘定制接口封装
China Accelerator由6个DSP超节点、1个CPU节点、1个IO节点、全局Cache、核间同步、4个存储控制器MCU(Memory Control Unit)及IO设备构成。其中,每个DSP超节点包含两个飞腾―Matrix2000内核,每个飞腾―Matrix2000内核包含两个计算核心,每个计算核心包含16个向量计算功能单元;全局Cache GC(Global Cache)采用分布式Cache,由多个子体(SubGC)构成,每两个SubGC连接一个存储控制单元MCU;核间同步也采用分布式组织,由多个子体构成。上述节点、SubGC、MCU由环形互连连接。 因此,China Accelerator是一款面向计算密集型应用、能高效处理大量数据的高性能多向量体系结构加速器,如图1所示[1]。

Figure 1 China Accelerator体系结构图1 Architecture of China Accelerator
如图1所示,China Accelerator体系结构复杂、细节多,数据分派繁琐。为了最大化国产加速器计算资源利用率和提高处理器的性能,支持China Accelerator的底层矩阵乘接口目前仅支持定制接口,即,支持国产加速器China Accelerator的矩阵乘接口仅支持特定规模的矩阵乘A(FT_m,K)×B(K,N),FT_m是FT-Matrix支持的矩阵乘中第一矩阵的行数,K是FT-Matrix支持的矩阵乘中第一矩阵的列数,也是第二矩阵的行数,N是FT-Matrix支持的矩阵乘中第二矩阵的列数,A(FT_m,K)×B(K,N)中对N、K没有特殊限制,但是,FT_m只能是576的整数倍,并且必须大于或等于576×6。然而,支持通用CPU的基本线性代数库矩阵乘接口是能支持任意规模的矩阵乘A(L,K)×B(K,N),即A(L,K)×B(K,N)中的L、K、N为任意的正整数。
因此,传统的HPL矩阵乘调度方法不再适合于面向China Accelerator的HPL矩阵乘调度优化,国产China Accelerator迫切需要一种适用于定制接口的异构矩阵乘调度优化方法,将国产加速器仅支持定制接口的异构矩阵乘封装为类似CPU支持的通用矩阵乘,并且,最大化矩阵块循环分布计算效率,提升国产异构系统效率。CPU + China Accelerator异构系统的高效协同矩阵乘计算更新划分如图2所示。
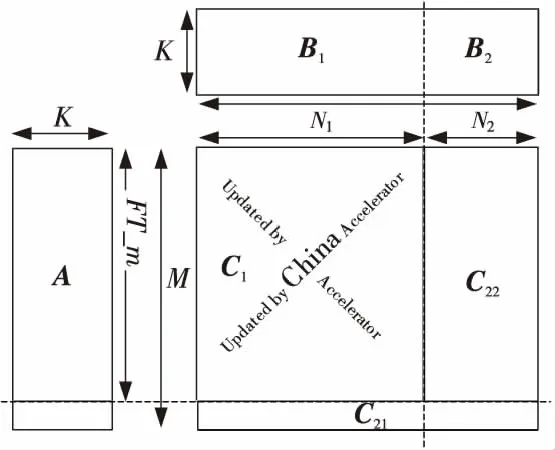
Figure 2 Matrix multiplication between CPU and China Accelerator with coordination图2 协同矩阵乘更新
如图2所示,由于China Accelerator目前支持的矩阵乘接口为定制接口,高效协同的矩阵乘更新算法中,CPU不仅要负责边缘非规则的矩阵乘计算,还必须与China Accelerator协同完成规则的矩阵乘更新操作。
2.2 异构协同矩阵乘调度算法
面向异构系统的矩阵乘调度可分为静态划分调度SdS(Static dispatch Strategy)和动态调度dSd(dynamic Schedule dispatch)。面向CPU+GPU的天河1A异构系统中,矩阵乘调度以静态调度为主,即,探索最优GPU端矩阵乘划分比例,如公式(2)所示。
其中,Gaccelerator为加速器GPU端矩阵乘更新时间,GCPU为CPU端矩阵乘更新时间。
在天河1A异构系统中,GPU端负责计算更新的矩阵子块大小预先已经确定[6,7],通过将CPU与GPU之间的数据传输时间隐藏于计算过程中来优化提升异构系统效率;与天河1A异构系统不同,面向CPU+MIC的天河二号异构系统中,矩阵乘调度算法以基于队列缓冲的动态调度为主[8,9],即,当前矩阵乘更新操作是分派至CPU还是MIC取决于任务计算队列的状态,以最大限度实现异构系统均衡,提高异构系统效率。
面向CPU+China Accelerator的HPL异构设计中,若采用类似天河1A的静态划分策略SdS,由于面向China Accelerator的底层数学库矩阵乘接口限制,只有满足接口规范要求的矩阵乘计算才能够调度到China Accelerator上加速,大部分的矩阵乘计算只能在CPU端完成更新操作;若采用基于队列缓冲的天河二号异构系统HPL矩阵乘更新动态调度方法dSd,将产生冗余的队列状态查询和计算任务请求等待。这是因为部分矩阵乘接口明显不符合China Accelerator内置的定制接口,但是,仍然需要监控队列状态并试图发送计算任务请求。
不同于天河1A异构系统中矩阵乘调度静态划分策略和天河二号异构系统中基于队列缓冲的矩阵乘更新动态调度方法,基于China Accelerator体系结构和软件生态,设计了一种异构协同矩阵乘调度算法OA4MM,以提高国产异构系统的效率。OA4MM调度方法属于一种基于天河1A和天河二号的动静融合协同矩阵乘均衡调度算法,OA4MM在矩阵乘静态划分的基础上引入动态调度策略,最小化动态调度中冗余的队列状态查询和计算任务请求等待,同时,最大限度划分矩阵乘更新调度至China Accelerator端加速,算法流程如图3所示。

Figure 3 OA4MM调度算法流程图3 Flow chart of OA4MM
3 实验结果与分析
3.1 CPU+China Accelerator验证系统
针对CPU+China Accelerator验证系统结构,系统设计的基于China Accelerator的计算刀片,灵活支持增添基于China Accelerator的加速子板,满足计算刀片能灵活可配、按需构建的用户需求。加速子板(包含4个China Accelerator)通过PCIE与计算刀片相连,并通过计算刀片上的高速网卡NIO(Network Input and Output)接入高速互连网络,实现计算结点间的互连。
CPU+China Accelerator验证系统由16个计算结点组成,如图4所示。单结点主要配置如表1所示。
3.2 矩阵分块对性能影响
由于China Accelerator目前仅支持特定规模的矩阵乘A(FT_m,K)×B(K,N),国产加速器底层支持的矩阵乘接口规范中对N、K没有特殊限制,但是,FT_m只能是576的整数倍,并且必须大于或等于576×6,为了充分利用China Accelerator强大的计算资源,调度至国产加速器上进行加速计算的矩阵块大小必然影响国产加速器的计算资源利用率和PCIE带宽的占有率,因此,矩阵分块大小将严重影响面向CPU+China Accelerator异构系统的HPL性能,其详细测试结果如图5所示。
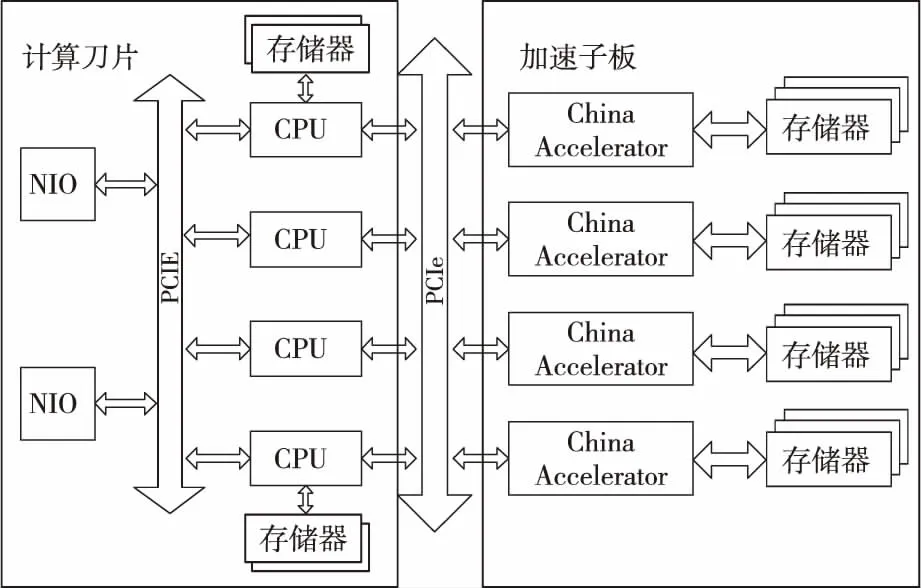
Figure 4 Architecture of node in experimental systems equipped with CPU and China Accelerator图4 CPU+China Accelerator单结点验证系统
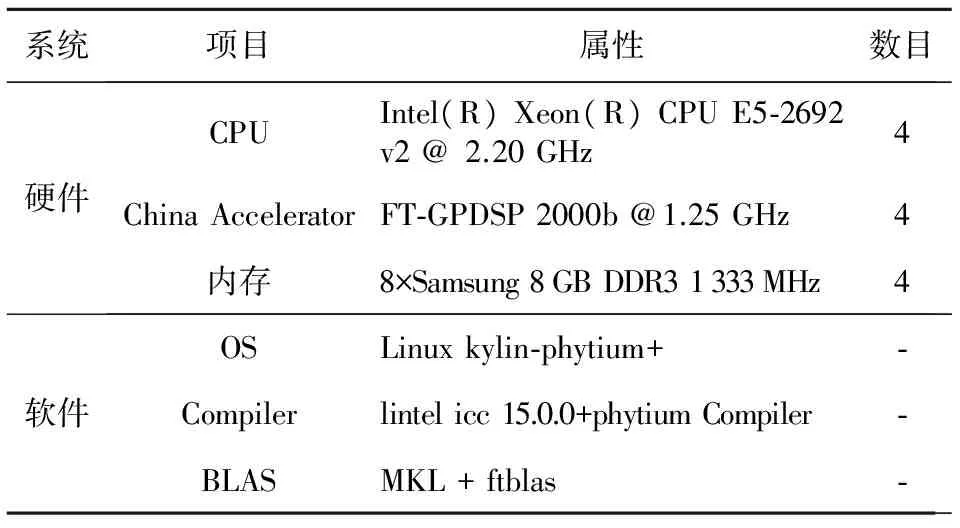
系统项目属性数目硬件CPUIntel(R)Xeon(R)CPUE5⁃2692v2@2.20GHz4ChinaAcceleratorFT⁃GPDSP2000b@1.25GHz4内存8×Samsung8GBDDR31333MHz4软件OSLinuxkylin⁃phytium+⁃Compilerlintelicc15.0.0+phytiumCompiler⁃BLASMKL+ftblas⁃

Figure 5 Performance evaluation on matrix block图5 矩阵分块的性能影响
以576×6的程序性能为基准,不同矩阵分块大小的加速比如图5所示。随着矩阵分块逐渐增大,程序性能显著上升至拐点后开始平稳回落,这是因为当矩阵分块较小时,频繁的数据传输严重影响程序性能,当程序性能达到局部最高点后,加速器端的存储资源就成为制约程序性能的关键。
3.3 OA4MM算法验证
为了充分验证OA4MM算法的高效性,面向CPU+China Accelerator的HPL设计配置了类似天河1A的静态划分策略SdS、基于队列缓冲的天河二号的动态调度方法dSd以及高效协同矩阵乘调度算法OA4MM,以探索CPU+China Accelerator异构系统的效率,上述三种异构调度方法的实测性能比较如图6所示,其中OA4MM的算法性能是在FT_m=576×30 时,即,最佳矩阵分块情况下的测试性能。

Figure 6 Performance evaluation with OA4MM and SdS/dSd图6 OA4MM与SdS/dSd的性能评估
由图6可知,高效协同矩阵乘调度算法OA4MM较天河1A异构系统中的静态划分策略SdS性能提升幅度随着计算结点数目和矩阵规模的增加逐渐明显;同时,在CPU+China Accelerator异构系统中,随着计算结点数目和矩阵规模的增加,OA4MM性能较天河1A的静态划分策略SdS和天河二号的动态调度方法dSd均有明显提升,全系统HPL性能提升近10%。
4 结束语
鉴于HPL参数配置优化实验在诸多文献中已有详细研究,面向国产异构系统的HPL异构协同设计将遵循China Accelerator矩阵乘接口规范,提出了dPEM方法对China Accelerator支持的底层数学库定制接口进行封装,屏蔽了定制接口限制,提供一个友好的HPL测试环境。为了最大限度发挥国产加速器的性能,提出了OA4MM调度算法。实验结果验证了dPEM的有效性和OA4MM算法的高效性,全系统HPL测试性能较传统的异构矩阵乘调度方法提升近10%,提高了基于国产加速器的异构系统效率,未来的工作将对OA4MM算法进行形式化描述和论证,并尝试将OA4MM调度算法应用至由GPU、MIC构建的异构实验系统中。
[1] Lu Yu-tong. Applications leveraging supercomputing systems[R].ISC’2015,2015.
[2] Dongarra J J, Luszczek P,Petitet A.The linpack benchmark: Past,present,and future[J].Concurrency and Computation: Practice and Experience,2003,15(9): 803-820.
[3] Zhang Wen-li, Chen Ming-yu,Fan Jian-ping.Emulation and forecast of HPL test performance [J]. Journal of Computer Research and Development,2006,43(3):557-562.(in Chinese)
[4] Liu Gang, Zhang Heng,Zhang Dian,et al.Optimization of Linpack for Loongson 3B processor [J]. Journal of Shenzhen University (Science & Engineering),2014,31(3):286-292.(in Chinese)
[5] Liu Jie,Hu Qing-feng,Chi Li-hua,et al.Parallel performance analysis of high performance Linpack[C]∥Proc of 2004 National Conference on High Performance Computing,2004:1.(in Chinese)
[6] Yang Xue-jun, Liao Xiang-ke,Lu Kai,et al.The TianHe-1A supercomputer: Its hardware and software[J].Journal of Computer Science and Technology,2011,26(3): 344-351.
[7] Wang Q, Ohmura J, Shan A, et al.Parallel matrix-matrix multiplication based on HPL with a GPU-accelerated PC cluster[C]∥Proc of the 1st International Conference on Networking and Computing, 2010:243-248.
[8] Du Yun-fei,Yang Can-qun,Wang Feng,et al.Analysis and evaluation method for Linpack benchmark [J].Dongbei Daxue Xuebao/Journal of Northeastern University,2014,35: 102-107.
[9] Liu Fang-fang,Yang Chao,Liu Yi-qun,et al.Reducing communication overhead in the high performance conjugate gradient benchmark on Tianhe-2[C]∥Proc of the 13th International Symposium on Distributed Computing and Applications to Business,Engineering and Science,2014:13-18.
附中文参考文献:
[3] 张文力,陈明宇,樊建平,等.HPL测试性能仿真与预测[J].计算机研究与发展,2006,43(3):557-562.
[4] 刘刚,张恒,张滇,等.基于龙芯3B 处理器的Linpack 优化实现[J].深圳大学学报(理工版),2014,31(3):286-292.
[5] 刘杰,胡庆丰,迟利华,等.高性能Linpack并行计算性能分析[C]∥全国高性能计算学术会议,2004:1.
