基于类别特征改进的KNN短文本分类算法*
2018-01-26黄贤英熊李媛刘英涛李沁东
黄贤英,熊李媛,刘英涛,李沁东
(重庆理工大学计算机科学与工程学院,重庆 400054)
1 引言
K-最近邻KNN(K-Nearest Neighbor)分类[1]作为一种经典的分类方法,由于其直接利用样本间的相似关系,有效地减少了类别特征选取不当对分类准确率的影响;同时,KNN分类的样本相似度拆分处理方式,使得KNN分类算法更利于大数据的并行化处理,而且其在不平衡数据集上也表现有良好的分类性能,更适用于现实的文本分类情况。但是,KNN分类在找K最近邻的过程中,要与整个训练空间的每个样本进行相似度的计算,KNN分类的效率会随着训练空间的增大而大幅度下降。同时,文本分类算法在进行分类时存在待分类文本中关键词稀疏、难以充分表征文本特性的问题[2],在短文本中关键词特征更加稀疏,同时存在样本高度不均衡等特点[3]。KNN文本分类算法通过各种辅助方式扩展测试文本来提高短文本分类的准确性,适用到短文本分类,增加了KNN分类算法相似度计算的时间复杂度,使得在短文本分类方面,KNN分类算法运行效率进一步下降。
目前针对KNN分类器效率提升主要是有两种方法。一种是通过降维来降低相似度计算复杂性,文献[4]依据概念进行特征选取,降低特征空间维数,提高KNN分类效率;文献[5]通过优化特征和分类器的结合,提升了KNN分类算法的性能;文献[6]通过自编码网络重构文本得到流形映射,提取短文本的流形特征,提升分类效果;文献[7]提出基于最大边缘相关的特征选择方法减少大量的冗余特征,提升分类效率;文献[8]运用熵特征变换指标设计相互类别差异量的相似度计算,来降低特征参数,提高KNN算法效率。另一种是通过样本间关联缩减训练空间,文献[9]利用扩展能力GC(Generalization Capability)算法使用案例维护学习减少训练空间,从而提高近邻检索效率;文献[10,11]利用粗糙集上下近似概念,对训练样本进行核心和边界区域划分,减少分类代价,以提高KNN分类效率;文献[12,13]利用聚类方法对训练集进行裁剪,解决传统KNN算法在训练集过大时速度慢的问题。但是,这些都是针对长文本分类的效率提升,针对短文本分类算法效率优化的文献较少。
结合不同算法的特点,本文采用卡方提取的方法在每个类别中提取各个类别的类别特征词项,利用类别特征词项结合hownet词典对训练空间进行二次拆分,将与类别特征词项相似的样本归到一个子集中,并以类别特征词项定义这个子集。这样,就将整个训练空间的每个类别拆分成为更小的训练子集。然后,根据测试数据的关键词项从拆分后的训练空间中,提取与测试数据相关的训练子集重构测试数据的训练集,依据KNN算法判定测试数据类别。通过这种方法来降低基于语义的KNN短文本分类算法在短文本相似度计算时的训练空间大小,提高KNN分类在短文本分类上的性能。
2 相关工作
2.1 卡方统计
依据卡方统计量的卡方提取是一种最常用的文本特征词项选择方法,通过计算类别ci和词项wj的相互独立性来表示类别ci与词项wj的相关程度。卡方值的计算公式如下:
(1)
其中,A表示在类别ci中包含词项wj的样本数,B表示不在类别ci中但包含词项wj的样本数,C表示在类别ci中不包含词项wj的样本数,D表示不在类别ci中且不包含词项wj的样本数。
卡方值越大,则类别ci和词项wj的相关程度越大,词项wj也就越能表示类别ci;反之,词项wj越无法表示类别ci。传统的卡方提取是在整个训练空间中提取卡方值最大的前K个特征,但这种方法提取不平衡训练空间时可能造成个别类别特征词项过少,影响分类准确性。本文采用申红等[14]的特征提取改进方法,在每个类别中分别提取在该类别中卡方值最大前K个作为该类别的类别特征,然后将所有类别的类别特征组合起来形成训练空间的特征词集。
在公式(1)中,(A+C)表示类别ci中的样本总数,(B+D)表示训练空间中除类别ci外的样本总数,(A+B+C+D)表示训练空间的样本总数。在一个类别中,上述3个值是恒定的,所以公式(1)可简化为:
(2)
2.2 基于hownet的语义相似度算法
基于hownet的短文本相似度算法主要是依赖hownet词典来计算两个短文本中关键词的相似度值来计算短文本的相似程度。基于hownet词典的词语相似度计算主要是刘群的相似度算法[15]及一些基于此改进的相似度算法,文本选取李峰的中文词语语义相似度算法[16]作为短文本语义相似度算法中基础的词语语义相似度算法,公式如下:
sim(w1,w2)=
(3)
其中,min(depthw1,depthw2)表示在知网中w1与w2的最小深度,distance(w1,w2)表示在知网中w1与w2的路径长度,α是一个调节参数,表示词语相似度为0.5时的路径长度。
假设两个短文本预处理后的结果为:
d1=(w11,w12,…,w1n)
d2=(w21,w22,…,w2m)
则d1和d2的语义相似度计算公式如下:
Sim(d1,d2) =
(4)
其中,mi= min(m,n),ma=max(m,n),delta是一个调节参数,定义一个非空值与空值的相似度。
本文中依据李峰的中文词语语义相似度算法定义文档与词语相似度值如下:
(5)
其中,wi文档d中的第i关键词。
3 基于特征语义的短文本分类算法
本文算法的重点在于利用类别特征词项对训练空间的拆分细化,根据测试数据构建近邻计算训练空间,以此来缩减训练空间,提升算法效率,其流程图如图1所示。
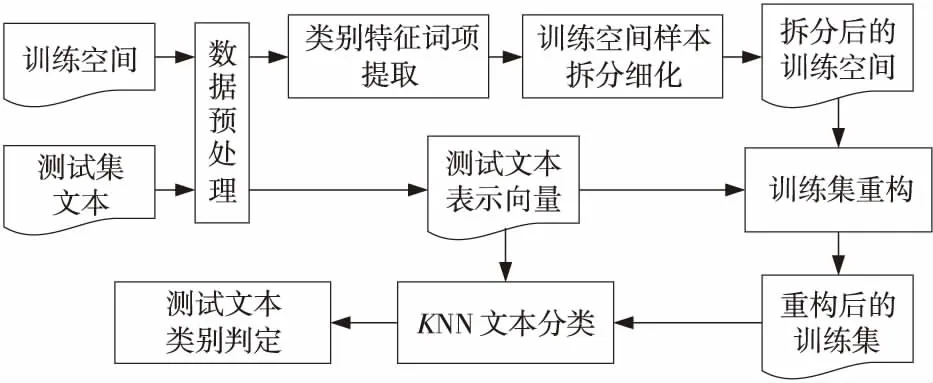
Figure 1 Flow chart of the KNN short text classificactionalgorithm based on category feature words图1 基于类别特征的KNN短文本分类算法流程图
Step1数据预处理。对训练数据和测试数据进行预处理,主要包括:无效字符剔除、文本分词(采用ICTCLAS[17])、停用词处理等,将文本数据用词项向量表示,得到处理后的训练空间和测试数据。
Step2类别特征词项提取。采用公式(2)在训练空间每个类别中提取相同数量的类别特征词项。为避免在Step 3的拆分过程中产生太多同名集,并保证特征的有效性,此处对取得的所有类别特征词项进行约减,去掉同时出现在3个及以上类别的类别特征词项。
Step3训练空间样本拆分细化。对于每个类别的每个样本,采用公式(5)的方法与该类别的类别特征词项做相似度计算。若相似度值大于相似度拆分阈值thresholdsplit,则将该样本加入对应的类别特征词项样本子集,若最后该样本未加入任何类别特征词集,则将其加入非类别特征集中。
为保证训练空间细化后的类别特征词项样本子集的样本数量的大小,防止大量样本被分入非类别特征词项样本子集,相似度拆分阈值不能太大;但如果相似度拆分阈值太小,细化后的类别特征词项样本子集的样本太多,训练集的重构过程会很耗时,且样本重复量太大,因此,本文定义相似度拆分阈值thresholdsplit为0.6,以类别Auto为例,类别Auto中包含“保养”“改装”“奔驰”等等多个类别特征词项样本子集,原训练空间类别Auto中有样本di:“成品油/n,价/n,涨/vi,部分/n,城市/n,汽车/n,排队/vn,加油/vi,”。按照式(5)计算文本“优惠/vn,元/m,部分/n,颜色/n,缺货/vi,手动挡/nz,奔腾/vi,详情/n,”与类别特征词项“保养”的相似度值为0.65,因此将样本di加入到类别特征词项“保养”所对应的样本子集中。
Step4训练集重构。根据测试数据提取对应的训练子集,将测试数据文本与所有类别的类别特征词项采用公式(5)进行相似度计算,将相似度值大于提取相似度阈值的类别特征词项所对应的类别特征词项样本子集中的数据提取到该测试数据的训练集。同时,对得到的训练集合进行去重处理,去掉重复的训练样本。具体流程如图2所示。
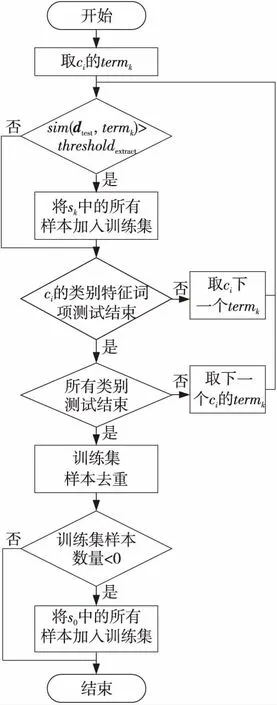
Figure 2 Flow chart of the training set recontruction图2 训练集重构流程图
Step5KNN文本分类。应用重构后的训练集使用KNN文本分类算法对测试文本进行分类处理,这里采用多数研究统计得到的传统KNN分类算法的K优值,取K值为10。文本相似度的计算采用基于知网的短文本相似度算法,利用公式(4)的方法计算测试文本dtest与重构得到的训练集中的每个样本的短文本语义相似度值,并取与测试文本dtest相似度最大的前10个样本作为K近邻集。
Step6判定类别。根据得到的相似度值最大的前10个样本的归属类别判断测试数据所属的类别。分类类别中对应前10个样本数目最大的即为测试数据的归属类别,若有多个最大,则取其中相似度和值最大的为测试数据的归属类别。
4 实验结果与分析
4.1 实验数据
实验选取从数据堂下载的搜狗新闻语料库[18],以其中的新闻标题作为实验语料数据源,从中提取出可确定类别的数据,剔除类别中数据条数小于10条的类别及数据。对于剩下的数据,对每条数据只提取其中的标题及所属类别。对提取得到的数据按照9∶1的比例提取训练集数据和测试集数据,并进行标题去重处理。
4.2 类别特征数量确定
类别特征数量的大小对本文算法的性能有较大影响,特征词项个数太少,训练集拆分程度过少,对效率的提升效果太弱;反之,若特征词项个数太多,则训练集合重构过程耗时太长,影响分类效率。
本文选取测试文本数量为100,对选取不同数目的类别特征词项时的KNN短文本分类算法进行实验。
图3是在不同特征词项数量下对100条测试文本进行KNN短文本分类的平均运行时间。从图3中可以看出,类别特征词项数量小于400时,改进的KNN短文本分类算法的测试文本的平均运行时间随类别特征词项数量的增加而减少。这是由于此时类别特征词项数量较小,训练空间样本重新拆分时根据类别特征词项数量拆分得到的样本数量少,拆分后每个类别内保留的样本数量过少,训练空间中的大部分样本被分入非类别特征集。一部分测试文本重构后的训练集中样本数量少于100,要加入非类别特征集中的样本,测试文本重构后的训练集较原训练空间样本数量减小有限,加上训练集重构过程的耗时,使得测试文本的平均运行时间较长。随着类别特征词项数量的增大,拆分后每个类别内保留的样本数量也在逐渐增加,非类别特征集的样本数量也会随之减少,重构后的训练集中样本数量小于100的测试文本数量也逐步减小,无需非类别特征集的样本的测试文本增多,测试文本的重构训练集的样本数量得到有效减少,测试文本的平均运行时间越来越短。

Figure 3 Running time of the algorithm under different numbers of feature words图3 不同特征词项数目下算法的运行时间
当类别特征词项数量大于400后,改进的KNN短文本分类算法的测试文本的平均运行时间随类别特征词项数量的增加而增加。根据类别特征词项数量拆分后的训练空间的样本子集数量已经足够,基本上所有测试文本在训练集重构时,无需非类别特征词项样本子集中的样本,此时测试文本的训练集重构过程随类别特征词项数量的增加,添加的类别特征词项所对应的类别特征词项样本子集就越多,重构后的训练集样本数量越来越多,测试文本的平均运行时间也越来越长。
但图3中,当类别特征词项数量为900时的测试文本的平均运行时间要低于类别特征词项数量为800时。这是由于实验的测试文本是随机提取的,当对测试文本进行训练集重构时,存在训练空间的15个类别抽取完样本去重后,训练集中样本数量都小于100的情况,此时测试文本的训练集需要加入非类别特征集中的样本,这样测试文本的运行时间就很长,当这种测试文本较多时,测试文本的平均运行时间就会较长。
表1是不同特征词项数目下优化后的KNN短文本分类算法的准确率。类别特征词项数目不大于700时,优化后算法的准确率随着类别特征词项数目的增加而提高,随着类别特征词项数目的增加,训练空间的拆分逐渐细化,测试文本重构的训练集合样本与测试文本的相关程度越来越高,优化后的算法的准确率也越来越高。类别特征词项数目大于700后,优化后的算法的准确率随着类别特征词项数目的增加反而有所降低。这是由于类别特征词项数目大于700后随着类别特征词项数目的增加,训练空间的拆分细化程度提高,类别特征词项集合中样本的数量减少,在测试文本训练集合重构时将一部分相关样本剔除,未加入到测试文本的训练集合中,使得算法的准确率下降。

Table 1 Algorithm accuracy underdifferent numbers of feature words
综合分析后,本文选取类别特征词项数目为400,此时优化算法的运行时间短,且准确率也相对较高。
4.3 实验过程与结果
实验从整个测试数据集中,按照不同的选取比率来随机抽取不同数量的测试数据,比较在不同测试数据下算法的性能。图4显示的是传统KNN算法与本文改进后的KNN算法的运行时间对比。

Figure 4 Comparison of running time图4 运行时间结果比较
从图4的对比结果中可以看出,在相同测试数据量下,改进后算法的运行时间约为传统KNN算法的一半,有的运行时间更少,这表明本文算法对测试数据提取出的训练集的样本数据有明显的减少,使得相似度计算的文本对数大量减少,运行效率有明显的提升。但是,由于不同测试数据提取训练样本所对应的样本数量不同,提取过程相似的类别特征词集合数不同,造成对于不同的测试数据,运行效率不同。特别是在测试数据量为91时,改进后的算法运行时间偏高,这是由于提取出的类别特征词项与随机选取的测试数据进行相似度计算时,相似度值大于提取相似度阈值的特征词项过多,使得提取到的训练集中的样本数量较多,比之原训练空间的样本数量减少量较少;同时,由于训练集合重构过程所需要的时间耗费,这样在对这些测试数据进行分类时,算法的运行时间就相对延长,效率提升就不会很大。但总体上,本文算法的运行时间还是要低于传统KNN算法。
改进后算法的准确率的宏平均与传统KNN算法的对比如表2所示,改进后算法的准确率的微平均与传统KNN算法的对比如表3所示。除去测试数据量为91时,准确率低于传统KNN,其他的情况下,本文算法的准确率较传统的KNN算法均有所提高。这是由于针对性的训练数据的提取,有效地将相关性较高的训练样本提取出来,减少由于知网语义相似度计算时,知网拓展引入冗余特征对相似度计算的影响,在一定程度上,提高了分类算法的准确率。但是,在随机提取的91条测试数据中,根据测试数据提取的训练集样本数量多,且非类别特征集样本未加入训练集,造成分类性能有小幅度下降。但总体而言,本文算法的准确率相对于传统KNN算法是有所提升的。

Table 2 Comparison of the accurary of macro average results

Table 3 Comparison of the accurary of micro average results
4.4 实验结果分析
从实验结果中可以看出,本文算法在效率上要明显好于传统KNN分类算法,主要是由于在本文算法中测试数据的训练集合是根据测试数据动态重构的。训练集合的选取是根据测试数据的特征来动态提取的,在整个训练空间中提取出与测试数据相关的样本重组训练集合。这样,就会对训练集合进行缩减,在相似度值的计算时,只需要跟缩减后训练集中的样本进行比较即可,大大提高了分类的效率。同时,结合了语义因素,避免由于短文本过短,信息量少而造成的分类准确率下降。
在准确率的比较上,本文算法的准确率要略高于结合知网的KNN分类算法,这是由于改进后的算法提取的测试数据训练集合都是与测试数据最相近的数据,一定程度上减少了因为特殊样本的偏差而造成的分类准确率下降。
5 结束语
本文在结合知网的KNN分类算法的基础上,通过类别特征词集,结合知网语义信息,对训练空间进行二次拆分,实现测试数据相似度计算时训练集合的动态重构,缩减训练集合样本数目。与传统KNN分类算法相比,该算法可以根据测试数据自适应地提取训练集合,实验表明,该算法可以在保证准确率的情况下,有效地提高KNN短文本分类效率。
但是,本文算法在分类的准确率上还有待改进,如何结合短文本的语义特征提高短文本相似度计算的准确性,还有待进一步研究。
[1] Cover T,Hart P.Nearest neighbor pattern classification[J].IEEE Transactions on Information Theory,1967,13(1):21-27.
[2] Li Bo, Shi Hui-xia,Wang Yi.A test extension algorithm based on synonymy discovery[J].Journal of Chongqing University of Technology(Natural Science),2014,28(2):76-81.(in Chinese)
[3] Yan Rui,Cao Xian-bin,Li Kai.Dynamic assembly classification algorithm for short text[J].Acta Electronica Sinica,2009,37(5):1019-1024.(in Chinese)
[4] Ding Ze-ya, Zhang Quan. Text categorization based on concept knowledge[J].Journal of Applied Sciences,2013,31(2):197-203.(in Chinese)
[5] Kacur J,Varga M,Rozinaj G.Speaker identification in a multimodal interface [C]∥Proc of the 2013 55th International Symposium on ELMAR,2013:191-194.
[6] Wei Chao,Luo Sen-lin,Zhang Jing,et al.Short text manifold representation based on AutoEncoder network[J].Journal of Zhejiang University (Engineering Science),2015,49(8):1591-1599.(in Chinese)
[7] Liu He,Zhang Xiang-hong,Liu Da-you,et al.A feature selection method based on maximal marginal relevance[J].Journal of Computer Research and Development,2012,49(2):354-360.(in Chinese)
[8] Liu Jin-sheng.On KNN algorithm based on optimizing similarity distance with entropy noise reduction[J].Computer Applications and Software,2015,32(9):254-256.(in Chinese)
[9] Zhan Yan, Chen Hao.Short text categorization based on theme ontology feature extended[J].Journal of Hebei University(Natural Science Edition),2014,34(3):307-311.(in Chinese)
[10] Wang Yuan,Liu Ye-zheng,Jiang Yuan-chun.Method of text classification based on roughk-nearest neighbor algorithm[J].Journal of Hefei University of Technology(Natural Science),2014,37(12):1513-1517.(in Chinese)
[11] Yu Ying, Miao Duo-qian, Liu Cai-hui,et al.An improved KNN algorithm based on variable precision rough sets[J].PR & AI,2012,25(4):617-623.(in Chinese)
[12] Ren Li-fang.Speeding K-NN classification method based on clustering [J].Computer Applications and Software,2015,32(10):298-301.(in Chinese)
[13] Luo Xian-feng, Zhu Sheng-lin,Chen Ze-jian,et al.Improved KNN text categorization algorithm based on K-Medoids algorithm[J].Computer Engineering and Design,2014,35(11):3864-3867.(in Chinese)
[14] Shen Hong,Lü Bao-liang,Utiyam a Masao,et al.Comparison and improvments of feature extraction methods for text categorization[J].Computer Simulation,2003,23(3):222-224.(in Chinese)
[15] Liu Qun, Li Su-jian.Word similarity computing based on How-net[J].Computational Linguistics & Chiese Language Processiong,2002,7(2):59-76.(in Chinese)
[16] Li Feng,Li Fang.An new approach measuring semantic similarity in Hownet 2000[J].Journal of Chinese Information Processing,2007,21(3):99-105.(in Chinese)
[17] Zhang H P, Yu H K, Xiong D Y, et al.HHMM-based Chinese lexical analyzer ICTCLAS[C]∥Proc of the 2nd SIGHAN Workshop on Chinese Language Processing:Association for Computational Linguistics,2003:758-759.
[18] http://www.datatang.com/data/43723.(in Chinese)
附中文参考文献:
[2] 李波,石慧霞,王毅.一种基于同义词发现的文本扩充算法[J].重庆理工大学学报(自然科学版),2014,28(2):76-81.
[3] 闫瑞,曹先彬,李凯.面向短文本的动态组合分类算法[J].电子学报,2009,37(5):1019-1024.
[4] 丁泽亚,张全.利用概念知识的文本分类[J].应用科学学报,2013,31(2):197-203.
[6] 魏超,罗森林,张竞,等.自编码网络短文本流形表示方法[J].浙江大学学报(工学版),2015,49(8):1591-1599.
[7] 刘赫,张相洪,刘大有,等.一种基于最大边缘相关的特征选择方法[J].计算机研究与发展,2012,49(2):354-360.
[8] 刘晋胜.基于熵降噪优化相似性距离的KNN算法研究[J].计算机应用与软件,2015,32(9):254-256.
[9] 湛燕,陈昊.基于主题本体扩展特征的短文本分类[J].河北大学学报(自然科学版),2014,34(3):307-311.
[10] 王渊,刘业政,姜元春.基于粗糙KNN算法的文本分类方法[J].合肥工业大学学报(自然科学版),2014,37(12):1513-1517.
[11] 余鹰,苗夺谦,刘财辉,等.基于变精度粗糙集的KNN分类改进算法[J].模式识别与人工智能,2012,25(4):617-623.
[12] 任丽芳.基于聚类的加速k-近邻分类方法[J].计算机应用与软件,2015,32(10):298-301.
[13] 罗贤峰,祝胜林,陈泽健,等.基于K-Medoids聚类的改进KNN文本分类算法[J].计算机工程与设计,2014,35(11):3864-3867.
[14] 申红,吕宝粮,内山将夫,等.文本分类的特征提取方法比较与改进[J].计算机仿真,2006,23(3):222-224.
[15] 刘群,李素建.基于《知网》的词汇语义相似度的计算[J].中文计算语言学,2002,7(2):59-76.
[16] 李峰,李芳.中文词语语义相似度计算——基于《知网》2000[J].中文信息学报,2007,21(3):99-105.
[18] http://www.datatang.com/data/43723.
