跨领域分布适配超限学习机及其在域自适应问题的应用
2018-01-23宋士吉
宋士吉,李 爽
(清华大学 自动化系,北京 100084)
在一般的数据分类问题中,训练集和测试集数据通常是同分布的,因而通过训练集数据训练的分类器可以在测试集上取得良好的效果.然而,在解决实际问题时,训练集和测试集往往服从不同的分布[1].在这种情况下,训练集(源域)数据的分类器不能直接用于测试集(目标域)数据的分类.域自适应问题的核心就是为了解决训练集与测试集分布不等的问题.例如,如果待分类的数据集T的标签难以获得,而可使用的有标签数据集S服从某个与T相关但不同的分布时,就需要运用域自适应的算法,以有效地利用数据集S的信息来低成本地对数据集T进行分析和分类.
近年来,研究者们提出了多种实现域自适应的模型和算法,比较常用的有3大类.第一类方法是寻找一个低维子空间,使得源域和目标域的数据样本在映射到该子空间后服从相同或相近的分布[2-4];第二类方法是对源域中的样本赋予某种权重,使其分布靠近目标域[5];第三类方法是利用低秩矩阵重构数据点,实现域之间的鲁棒自适应[6-8].
目前比较常用的一种数据集分布距离衡量方法是最大均值距离(Maximum Mean Discrepancy, MMD)[9].MMD的定义是两个分布在某个函数类映射下期望值的差的最大值.MMD具有非参数性、计算方便等优点,被广泛应用于上述的前两类域自适应方法中.通常对于有限样本集,采用经验MMD的形式来估计真实的MMD值.经验MMD表示为
由Huang et al.提出的超限学习机(Extreme Learning Machine,ELM)作为一种“广义的”单隐层前馈神经网络,已被大量的实验和应用证明其有效性[10-12].但是,大多数的ELM算法都基于一个通用的假设:训练集和测试集服从相同的分布.而现实生活中有很多应用其实都不满足该假设[13].于是如何利用有效的ELM框架来解决域自适应问题就显得十分重要.
本文基于超限学习机(Extreme Learning Machine,ELM)强大的函数拟合能力[14],提出了一种跨领域分布适配超限学习机模型(Domain Distribution Matching Extreme Learning Machine,DDM-ELM).该模型试图解决域自适应问题的几个关键问题:1)因为源域和目标域十分相关,故目标域分类器的构建应充分利用有标签的源域样本;2)由于源域和目标域的不同,设计模型时应能充分减小源域和目标域的差距,便于提高目标域样本的分类结果;3)模型设计应充分挖掘大量无标签目标域样本的本质信息和几何结构信息,使得目标域分类器能更加适合目标域样本而且能得到更准确的结果.所以,DDM-ELM旨在同时解决以上3个关键问题.DDM-ELM的基本思想示意图如图1.
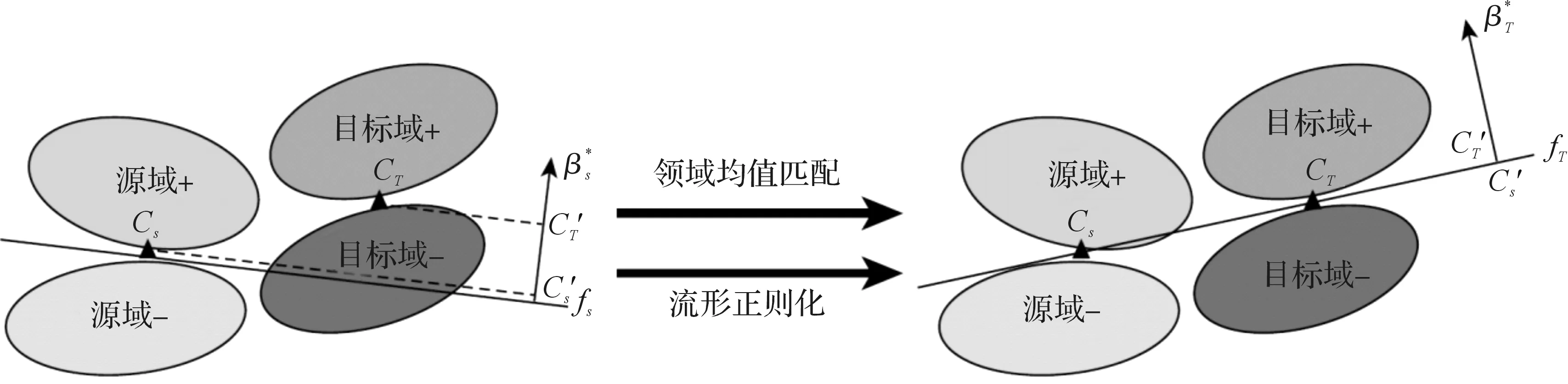
注:“+”代表正样本,“-”代表负样本;代表源/目标域的中心; fS/fT代表源/目标域的分类超平面;代表源/目标域分类超平面的法向量;代表源/目标域在的投影中心.图1 DMM-ELM基本思想示例图Figure 1 Illustration of the motivation of DDM-ELM
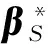
基于以上的讨论,基于ELM的基本框架,DDM-ELM将源域分类器fS、域均值匹配和目标域的流形正则化于一体,最终构建一个更加适合于目标域样本的分类器.本文在公共数据集Office、Caltech-256、MNIST和USPS上,实施了大量的对比试验,验证了DDM-ELM的有效性.
1 背景和相关数学模型介绍
1.1 极限学习机模型
建立准确的模式识别和分类模型是人工智能的基本任务.通常,对数据的识别和分类,需要依赖于人类专家建立的专家系统或启发式的智能算法.神经网络的发展极大地支持了专家系统的发展和完善,使数据特征的识别和提取变得更加智能化、精确化,从而极大地提高了数据处理和辨识的能力.
hk(x)=g(x;wk,bk).
其中,g(·)是隐含层的激励函数,通常取sigmoid函数或tanh函数等非线性函数.
ELM的输出记为f(x)=h(x)β,h(x)是L个隐含层结点组成的隐含层输出向量,β是输出权重,通过解最小二乘问题求得
(1)
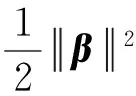
(2)
其中,T是期望输出矩阵;H是隐含层输出矩阵.将目标函数关于β的梯度设为0,可得最优的β满足
β*-CHT(T-Hβ*)=0.
(3)
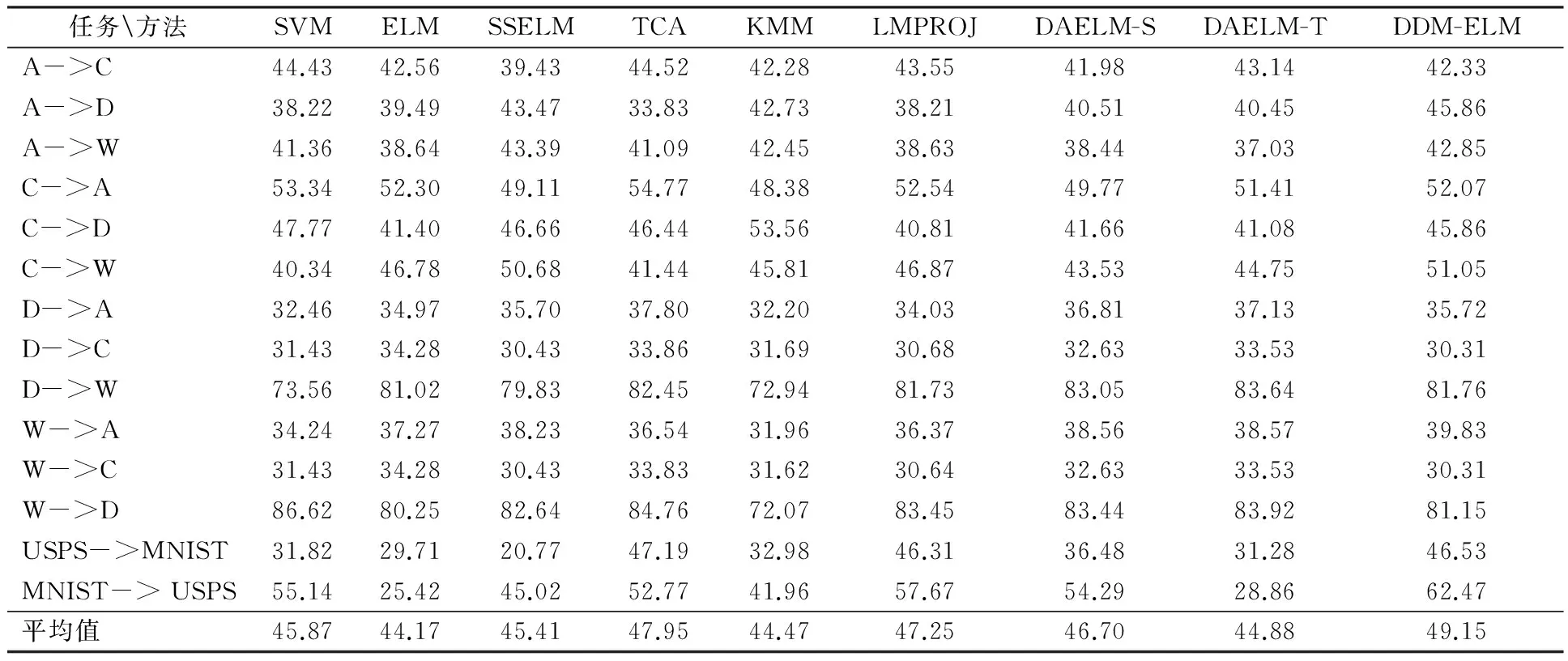
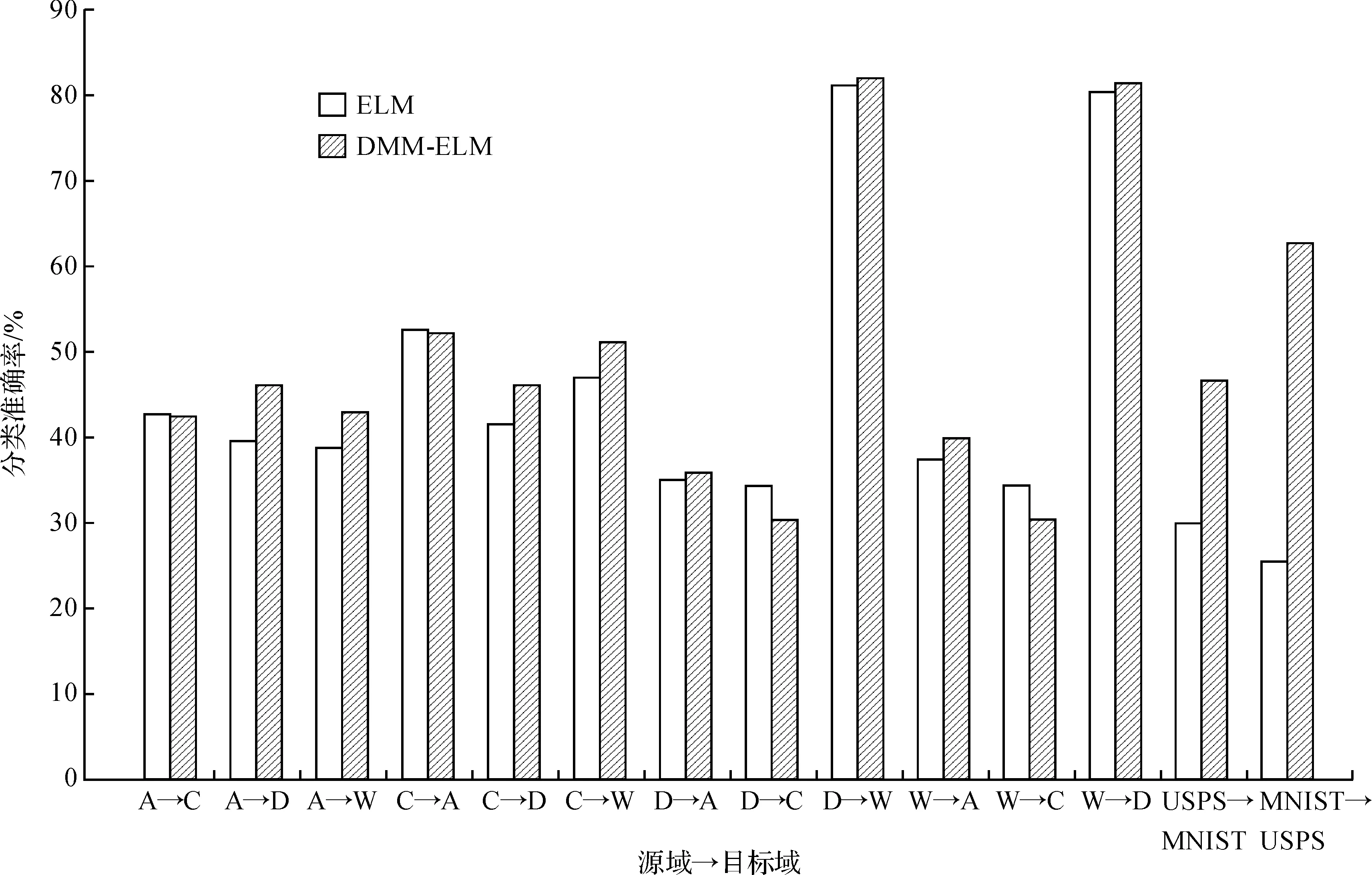
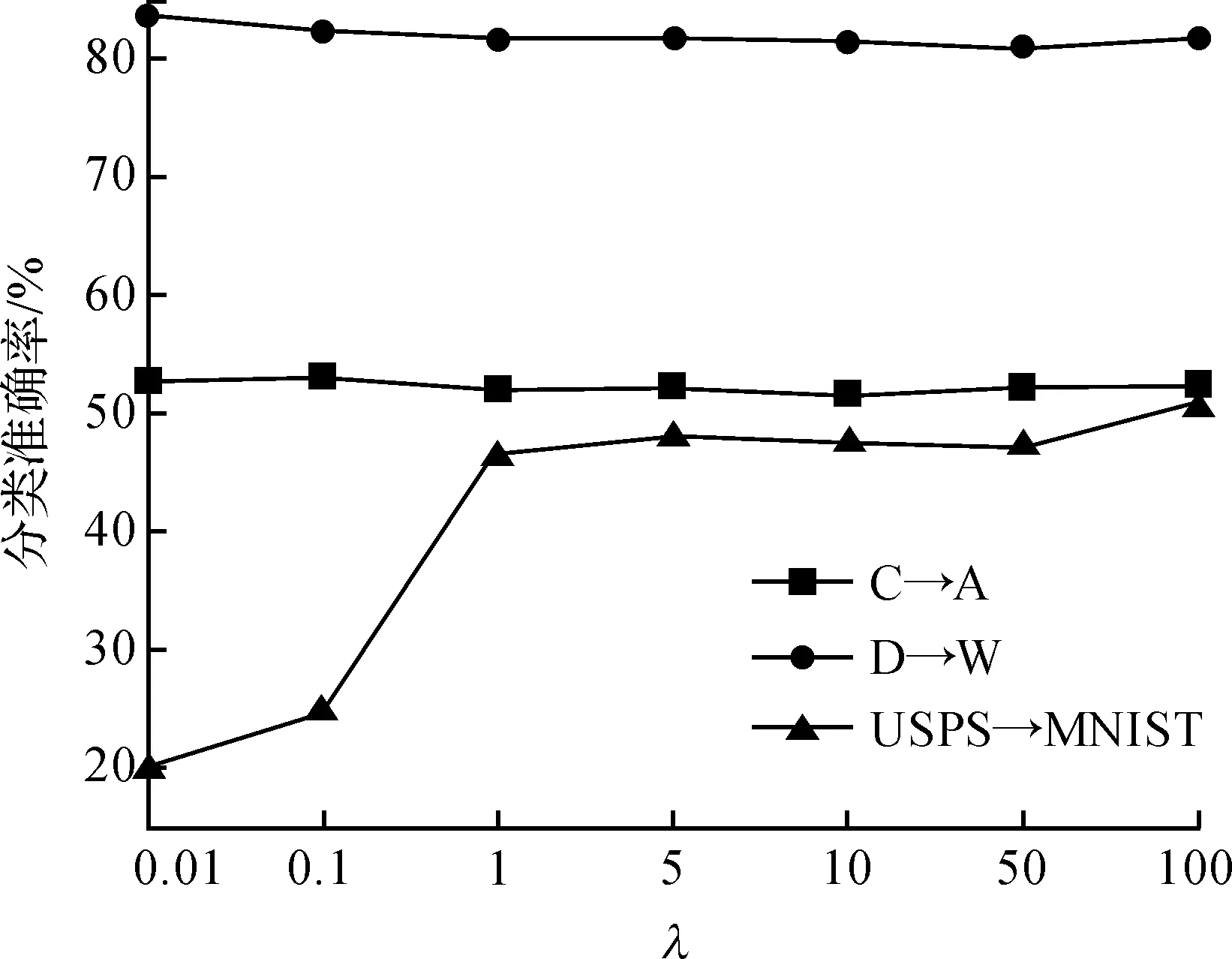
当训练样本数小于隐含层节点数,即N (4) 而当训练样本数不少于隐含层节点数,即N≥L时,解为 (5) 其中,I表示单位阵;下标L为矩阵维数. 文献[15]已证明,当隐含节点数足够多时,ELM可以无限逼近任意连续函数.由于ELM的网络权重可以分析得出,避免了一般的单向神经网络中运用BP算法反复地训练网络参数,所以效率可得到显著提升. 由本文所提出的DDM-ELM能够通过减小投影MMD的距离,而有效的减小源域和目标域的分布距离,从而使得DDM-ELM可以很好地处理域自适应问题. 本文提出跨领域分布适配超限学习机(Domain Distribution Matching Extreme Learning Machine,DDM-ELM)算法,主要解决域自适应问题中的3个关键点:充分利用有标签的源域样本,减小源域和目标域分布的距离和挖掘大量目标域样本的几何特征.所以,DDM-ELM的目标函数包含以下3个部分:有标签源域样本的分类误差,投影MMD正则项来减小源域和目标域的分布距离,目标域样本的流形正则化.则DDM-ELM的目标函数可以表示为 h(xTj)β=f(xTj)j=1,2,…,nt. (6) 2.1.1 源域样本分类误差损失 在本文中,我们主要解决域自适应问题,其中目标域样本都是没有标签的,故只能借助于大量的有标签源域样本来设计分类器,即 (7) 将式(7)中的等式约束带入目标函数,可得如下等价的无约束优化问题: (8) 可以看出式(8)仅仅使用了有标签的源域样本来训练源域分类器,该分类器如果不加修正是不能直接用在目标域上的,所以我们引入了减小投影MMD距离来减小源域和目标域样本的差距,使得目标域分类器能够准确应用于目标域样本. 2.1.2 投影MMD MMD是一种非参数化的衡量不同概率分布之间距离的度量方法,如同文献[16],我们使用投影MMD作为一种惩罚项引入DDM-ELM算法中,来有效地减小源域和目标域样本的距离.投影MMD可以如下式进行计算: (9) 式(9)可以用矩阵的方式表示为 (10) DDM-ELM成功的在ELM框架下引入投影MMD损失项,使得该算法可以有效地减小源域和目标域的分布距离,从而便于最后的分类. 2.1.3 流形正则化 流形正则化已经被广泛的应用在半监督学习领域,它使得目标分类器要给出较为平滑的预测,不能随意穿过高密度的区域.简单来说,如果两个目标域样本离得很近,我们就可以认为他们有很大的概率是同类的,这可以帮助模型更好的挖掘目标域的几何特性,从而提高分类效果.经验流形正则化项可以表示为 s.t.h(xTj)β=f(xTj)j=1,2,…,nt. (11) 其中相似度αij可以简单表示为 (12) 式(12)中Np(xTi)是样本xTi的p-近邻点.我们可以将式(11)用表示为矩阵形式: (13) 可以看出,DDM-ELM可以同时满足目标域分类器对源域样本有很好的分类效果,有效地减小源于和目标域样本的分布距离,最大化目标域的预测一致性.下一小节会详细介绍DDM-ELM的求解方法. 根据式(6)~(13),可以得到DDM-ELM的最终损失函数为 (14) (15) 式(15)是一个二次规划问题,最优解满足β+HTW(Hβ-Y)+λHTVHβ+γHTΓHβ=0. (16) 可知式(16)存在解析解,当样本数小于隐含层结点数时,解析解为 (17) 当样本数多于隐含结点数时,有 (18) DDM-ELM可以有效地将源域样本的信息迁移到目标域样本中,而且有闭式的解析解,这也延续了ELM框架的优点. 为了验证本文提出的方法,实验中采用了经典的图像数据集OFFICE+Caltech 256、MNIST和USPS,其中部分图像示例如图2. 图2 实验所用数据集部分图片示例Figure 2 Samples of images from MNIST, USPS, Amazon, Caltech-256, DSLR and Webcam 在实验中,与文献[2-4]类似,OFFICE+CALTECH256的SIFT特征是800维数据集,其中包含4个子数据集C、A、D、W,每个子数据集包含10类数据,每一类代表一种物体的图像;任意取出两个子数据集作为源域和目标域,可以形成12组实验任务,即“A->C”、 “A->D”,……, “W->C”和“W->D”. MNIST和USPS数据集是经典的手写数字数据集,包含数字0到9共10类.我们将MNIST和USPS缩放至16×16的大小,从USPS中选取1800张图片,从MNIST中选取2000张图片,可以组成“USPS->MNIST”和“MNIST->USPS”两组实验任务. 其中数据集的详细信息如表1. 表1 OFFICE+CALTECH256和MNIST+USPS数据集详细描述Table 1 Description of OFFICE+CALTECH256 and MNIST+USPS datasets 为了全面地验证DDM-ELM的有效性,我们对比了8种相关的机器学习算法,分别为ELM[10]、SVM[18]、SS-ELM[19]、TCA[2]、KMM[5]、LMPROJ[16]、DAELM-S[20]和DAELM-T[20].其中ELM和SVM为普通的机器学习算法,我们用有标签的源域样本训练分类器,然后将该分类器预测目标域样本;SS-ELM为半监督学习算法,我们将源域样本作为有标签样本和目标域样本作为无标签样本,共同训练分类器预测目标域样本;TCA、KMM和LMPROJ为经典的域自适应分类算法,而DAELM-S和DAELM-T算法需要少量的有标签目标域样本,故我们随机选取5个目标域样本作为有标签样本用于训练. 在DDM-ELM中有3个可以调整的参数:C、λ和γ,其中C控制目标域分类器对源域样本的分类准确度,λ控制着源域和目标域样本的投影MMD距离,γ控制着目标域样本流形正则化的作用.在实验当中,参数C的选择和ELM的交叉验证选取的C一致,因为我们期望DDM-ELM能够准确的分类源域样本.在所有的实验中我们设定λ=1,对于MNIST+USPS,我们选取γ=0.01,对于OFFICE+CALTECH256,γ=0.000 1.在后续的参数敏感度分析的实验当中,表明在很大范围内DDM-ELM都能有很好的结果.为了对比的公平性,我们将所有的对比方法和DDM-ELM的实验都跑10遍,并列出平均值进行对比. 在数据集OFFICE+CALTECH256和MNIST+USPS上的实验结果如表2. 表2 图像数据集从源域到目标域(A=Amazon, C=Caltech, D=DSLR, W=webcam)的平均分类准确率 从表2我们可以得出以下结论: 1)在OFFICE+CALTECH256和MNIST+USPS的图像数据集上,DDM-ELM在所有任务上的平均分类准确率比其他的算法都要高,达到了49.15%.TCA是所有对比算法中结果最好的,但是TCA要花费大量的时间去求得子空间,而DDM-ELM延承了ELM框架的快速性,有很高的计算效率. 2)像SVM和ELM这种传统机器学习算法,都是基于训练集和测试集服从相同的分布这个前提,但是在现实生活中,经常会碰到如图3中,每一个领域的图片的分布相差较大的情况,导致SVM和ELM的结果不尽如人意,这也显示出域自适应算法的重要性.SSELM是处理半监督学习的ELM算法,结果比纯粹的ELM效果好,这也说明了利用大量无标签的目标域样本的几何特性能提高目标域分类器的效果. 3)DAELM-S和DAELM-T实际上需要少量的有标签目标域样本,但是这两种算法并没有致力于减小源域和目标域分布的差距,而是根据这些少量的有标签目标域样本建立起源域和目标域的联系.从表2可以看出,即使DDM-ELM只需要无标签的目标域样本来训练模型,但是结果仍然优于DAELM-S和DAELM-T,这表明了减小源域和目标域的投影MMD可以有效地利用所有样本的信息. 4)值得注意的是,在“USPS->MNIST”和“MNIST-> USPS”两个任务中,ELM表现得十分不理想,但是DDM-ELM较ELM的准确率提高很多,这个也表现出DDM-ELM的有效性. 为了清晰地对比ELM和DDM-ELM算法的结果,如图3.可以看出在绝大多数任务上(14个任务中的10个),DDM-ELM都比ELM表现出色,尤其是在“USPS->MNIST”和“MNIST-> USPS”两个任务中.这也证明了在域自适应问题中,考虑源域和目标域样本的差距和利用大量目标域样本的几何特性是十分必要的. 图3 ELM和DDM-ELM在图像数据集上的结果对比Figure 3 Results comparison of ELM and DMM-ELM on all the image datasets 为了验证DDM-ELM中参数λ和γ在大范围值域内都能有很好的效果,我们画出DDM-ELM在“C->A”,“D->W”和“USPS->MNIST”任务上参数λ和γ对分类结果的影响.我们这里只探索λ和γ的影响,是因为在DDM-ELM中的参数C是和ELM中的C选择一样. 如图4(a)是DDM-ELM在固定参数C和γ时,改变λ值对分类准确率的影响.由于λ主要控制投影MMD对模型的影响,于是可以看出除了“USPS->MNIST”以外,其他的任务对λ并不敏感.理论上,如果λ的值很小时,DDM-ELM不能很好地匹配两个域样本的分布,则结果应该会有一定程度的下降.当λ的值变大时,结果相对变得稳定,这也表明减小源域和目标域样本的差异的必要性.尤其是对于“USPS->MNIST”任务,这两个数据集相差很大,我们应该选择一个相对较大的λ来弥补源域和目标域样本的差距,从而使DDM-ELM有很好的效果. 图4(b)是DDM-ELM随着γ改变时,分类准确率的改变.探究目标域样本的流形特性能使得目标域分类器更加适应于目标域样本.然而γ选取太大时,会降低最终的分类准确率.所以说,我们可以选取一个相对较小的γ来平衡流形正则化的作用. 本文提出了一种基于ELM网络结构的跨领域分布适配超限学习机(DDM-ELM)算法,DDM-ELM旨在解决几个域自适应领域的关键问题,同时在满足最小化源域样本的分类准确率、减小源域和目标域分布距离和探索目标域样本的几何特性的前提下,构建一个适应于目标域的分类器.DDM-ELM能有效地把源域样本信息迁移到目标域中,且和ELM框架一样,DDM-ELM能高效地给出解析解.DDM-ELM在保持算法高运算效率的同时,实现了具有较高准确度的跨域分类,其模型优越性在大量的图像数据集上都得到了实验验证. [1] TORRALBA A, EFROS A A. Unbiased look at dataset bias[C]//ComputerVisionandPatternRecognition(CVPR),2011IEEEConferenceon. Washington, D.C.: IEEE Computer Society, 2011: 1521-1528. [2] PAN S J, TSANG I W, KWOK J T, et al. Domain adaptation via transfer component analysis [J].IEEETransactionsonNeuralNetworks, 2011, 22(2): 199-210. [3] LONG M S, WANG J M, DING G G, et al. Transfer feature learning with joint distribution adaptation [C]//ProceedingsoftheIEEEinternationalconferenceoncomputervision. Washington, D.C.: IEEE Computer Society, 2013: 2200-2207. [4] LONG M S, WANG J M, DING G G, et al. Transfer joint matching for unsupervised domain adaptation [C]//ProceedingsoftheIEEEconferenceoncomputervisionandpatternrecognition. Washington, D.C.: IEEE Computer Society, 2014: 1410-1417. [5] HUANG J Y, SMOLA A J, GRETTON A, et al. Correcting sample selection bias by unlabeled data [C]//AdvancesinNeuralInformationProcessingSystems. Cambridge: MIT Press, 2006:601-608. [6] ZHANG L, ZUO W M, ZHANG D. LSDT: Latent sparse domain transfer learning for visual adaptation [J].IEEETransactionsonImageProcessing, 2016, 25(3): 1177-1191. [7] JHUO I H, LIU D, LEE D T, et al. Robust visual domain adaptation with low-rank reconstruction[C]//ComputerVisionandPatternRecognition(CVPR), 2011IEEEConferenceon. Washington, D.C.: IEEE Computer Society, 2012:2168-2175. [8] SHAO M, KIT D, FU Y. Generalized transfer subspace learning through low-rank constraint[J].InternationalJournalofComputerVision, 2014, 109(1):74-93. [9] GRETTON A, BORGWARDT K, RASCH M J, et al. A kernel method for the two-sample-problem [C]//AdvancesinNeuralInformationProcessingSystems. Vancouver, British Columbia: DBLP, 2007: 513-520. [10] HUANG G B, ZHU Q Y, SIEW C K. Extreme learning machine: A new learning scheme of feedforward neural networks[C]//2004IEEEInternationalJointConferenceonNeuralNetworks.Budapest, Hungary: IEEE, 2005:985-990. [11] HUANG G B, WANG D H, LAN Y. Extreme learning machines: a survey [J].InternationalJournalofMachineLearning&Cybernetics, 2011, 2(2):107-122. [12] HUANG G B, ZHU Q Y, SIEW C K. Extreme learning machine: Theory and applications [J].Neurocomputing, 2006, 70(1-3):489-501. [13] PAN S J, YANG Q. A Survey on Transfer Learning [J].IEEETransactionsonKnowledge&DataEngineering, 2010, 22(10):1345-1359. [14] HUANG G, HUANG G B, SONG S J, et al. Trends in extreme learning machines: A review [J].NeuralNetworkstheOfficialJournaloftheInternationalNeuralNetworkSociety, 2014, 61: 32-48. [15] HUANG G B, ZHOU H M, DING X J, et al. Extreme learning machine for regression and multiclass classification [J].IEEETransactionsonSystemsMan&CyberneticsPartBCybernetics, 2012, 42(2): 513-529. [16] QUANZ B, HUAN J. Large margin transductive transfer learning[C]//ACMConferenceonInformationandKnowledgeManagement. New York: ACM, 2009:1327-1336. [17] GONG B,SHI Y,SHA F. Geodesic flow kernel for unsupervised domain adaptation [C]//2012IEEEConferenceonComputerVisionandPatternRecognition. Washington, D.C.: IEEE Computer Society, 2012, 157: 2066-2073. [18] CHANG C C, LIN C J. LIBSVM: A library for support vector machines [J].ACMTransactionsonIntelligentSystemsandTechnology, 2011, 2(3): 1-27. [19] HUANG G, SONG S, GUPTA J N D, et al. Semi-supervised and unsupervised extreme learning machines [J].IEEETransactionsonCybernetics, 2014, 44(12): 2405-2417. [20] ZHANG L, ZHANG D. Domain adaptation extreme learning machines for drift compensation in E-nose systems [J].IEEETransactionsonInstrumentation&Measurement, 2015, 64(7): 1790-1801.1.2 域自适应问题背景介绍
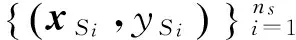
2 跨领域分布适配超限学习机
2.1 DDM-ELM算法综述

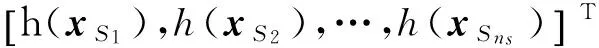

2.2 DDM-ELM算法求解

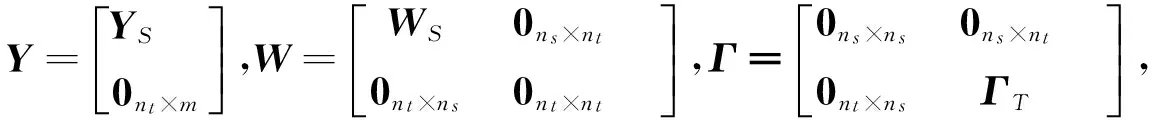
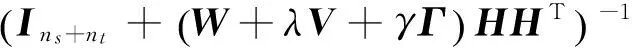
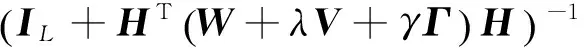
3 实验验证与分析
3.1 数据集介绍

3.2 实验设定
3.3 实验结果
3.4 参数分析
4 结 语
