通用图形处理器GPGPU的并行计算研究*
2017-09-03张鹏博郭兵黄义纯曹亚波
张鹏博,郭兵,黄义纯,曹亚波
(四川大学 计算机学院,成都 610065)
通用图形处理器GPGPU的并行计算研究*
张鹏博,郭兵,黄义纯,曹亚波
(四川大学 计算机学院,成都 610065)
随着图形处理器(GPU)从仅用来进行图形图像渲染,脱离成为并行计算平台通用图形处理器(GPGPU),其计算能力越来越强,本文在研究GPGPU体系结构的基础上对GPGPU并行计算线程调度进行深入研究,阐述了GPU线程调度原理,揭示了SIMT调度模式的不足。通过公式推导阐述了系统功耗与系统运行频率的关系。
大数据;并行计算;线程调度;GPU节能
引 言
随着大数据研究技术的进步,大数据已经进入到各行各业,美国麦肯锡公司称:“数据已经渗透到当今每个行业和业务职能领域,成为重要的生产因素。人们对于大数据的挖掘和运用,预示着新一波生产力增长和消费盈余浪潮的到来”[1]。大数据自身5V(体量大、速度快、模态多、难辨识、价值大密度低)特征决定了冯·诺依曼计算机CPU用来处理数据还远远不能满足处理要求。
由于游戏产业的带动,早期GPU多用来对图形图像进行渲染。随着工艺技术的进步,今天GPU的功能已经远远不止于此,其逐渐成为研究者进行并行计算的通用并行处理器。GPGPU的体系结构及多核硬件架构也很好地适应了并行计算的要求。
传统并行调度模式主要分为4类:单指令,多数据(Single Instruction Multiple Data SIMD);多指令,多数据(Multiple Instruction Multiple Data MIMD);单指令,单数据(Single Instruction Single Data SISD);多指令,单数据(Multiple Instruction Single Data MISD)。GPGPU采用的是SIMD执行模式,但为了获得更高的并行计算效率,主流的图形处理器又派生出单指令多线程(Single Instruction Multiple Thread SIMT)模式。
1 通用图形处理器体系结构及相关概念
目前市场上通用图形处理器厂商主要有(英伟达NVIDIA)、AMD、英特尔(Intel)三大厂商,其产品在宏观结构上没有太大差别,但在微观体系结构上各有特点。因为NVIDIA公司的通用图形处理器市场占有率比较高,所以本文关于GPU的论述皆以NVIDIA的产品为标准。
1.1 GPGPU线程层级
GPGPU对线程的管理分为3个层级:线程网格(Grid)、线程块(ThreadBlock)、线程组(Warp)。GPGPU线程结构如图1所示。
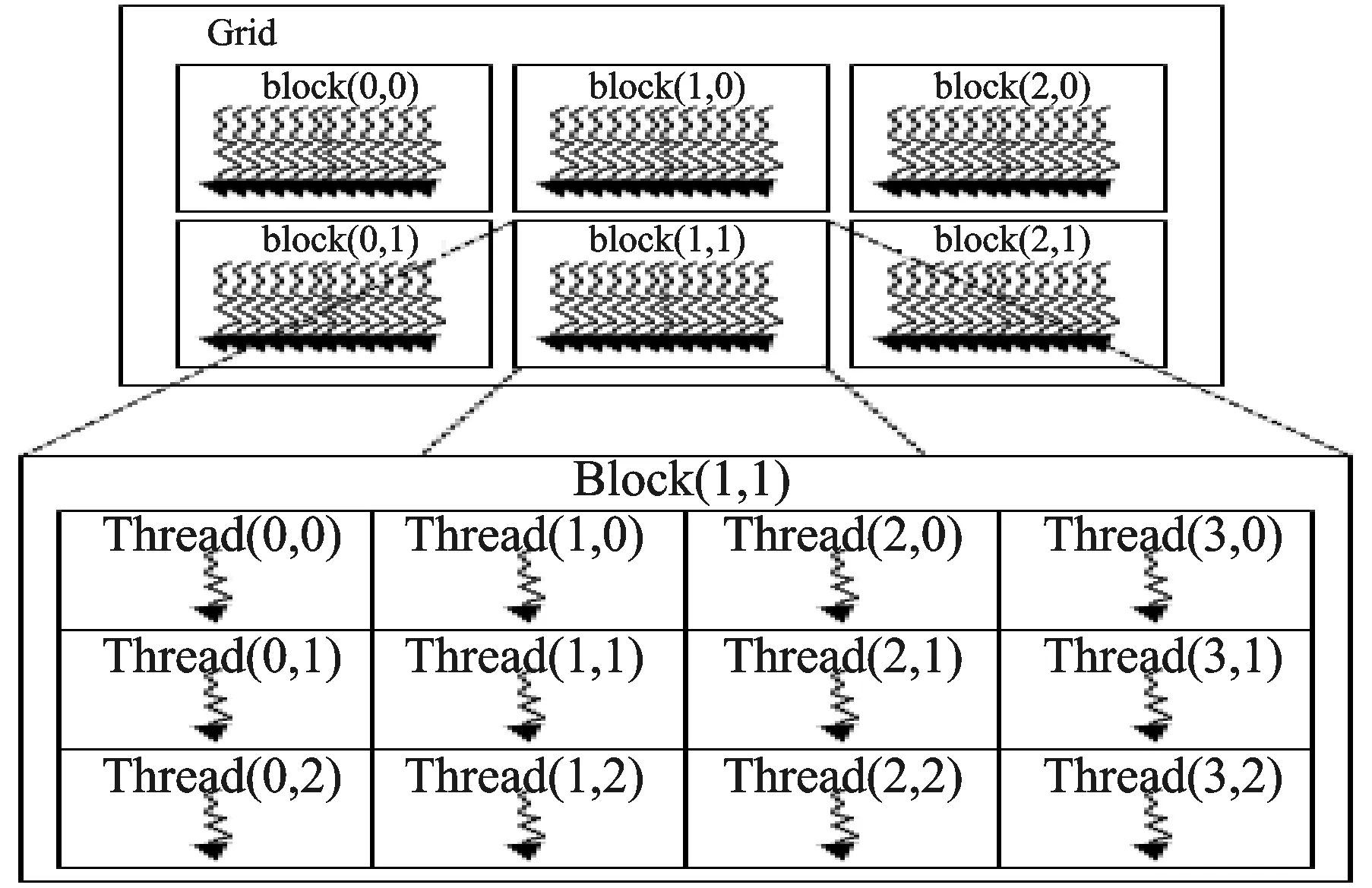
图1 GPGPU线程结构
运行在GPU上的程序称为kernel(内核函数),kernel以线程网格的形式组织,每个线程网格由若干个线程块组成,每个线程块又由若干个线程组成。实际运行时kernel以block为单位执行,引入Grid只是用来表示一系列可以被并行执行的block的集合。各线程块之间无法通信也没有执行顺序,线程块内的线程可以通过共享存储器通信。线程组(warp)则通常由32个线程组成,是线程并发执行的基本单位。GPGPU内的并行分为线程块并行和线程块内线程并行两个级别。
1.2 GPU宏观体系结构
图2为GPGPU的硬件映射。可以看出,通用图形处理器中有若干个SM(流多处理器),SM是GPGPU的计算核心。每个SM中又包含8个标量流处理器SP和少量其他的计算单元。在商业上,GPU通常被说成拥有数百个“核”,这个“核”指的是这里的SP,这种说法不够准确,因为SP只是执行单元,并不是完整的处理核心。

图2 GPGPU硬件映射
可以看出,通用图形处理器存储层次有寄存器、高速缓存、芯片外存储器三个级别。高速缓存又可以分为一级缓存、二级缓存、三级缓存,每个SM中会包含众多数量的寄存器,通常一级缓存和寄存器放在SM内部。GPGPU的宏观体系结构如图3所示。
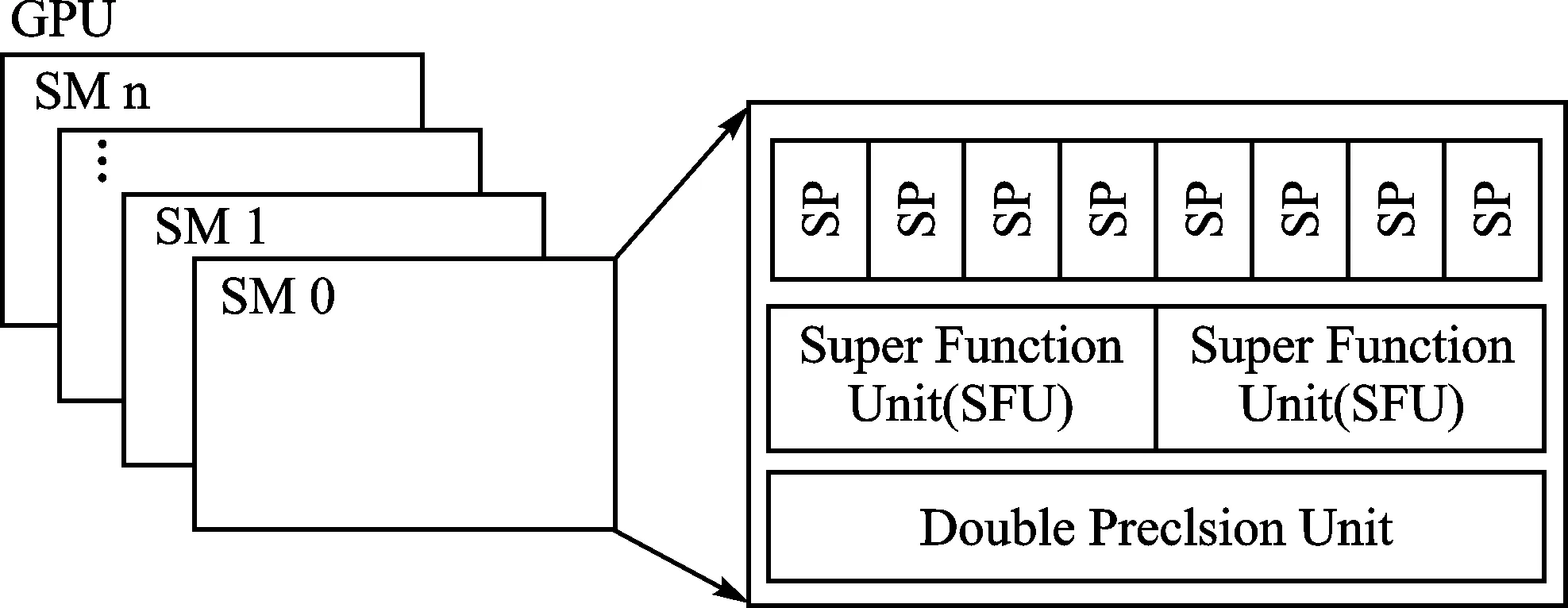
图3 GPGPU宏观体系结构
kernel函数以block为单位执行,同一block中的线程可以通过共享存储器共享数据,所以同一个block内的线程需要发射到同一个SM。而每个线程则会被发射到一个SP上执行。值得注意的是,一个线程块要被发送到同一个SM,但是同一个SM上并不一定只有一个block的上下文。因为当一个block 访存时另一个block可以抢占SM执行。
2 通用图形处理器线程调度方法
线程调度是指将计算任务分配到不同的处理单元,并按照一定的顺序执行的过程[3]。通用图形处理器中的线程调度一共分为三个级别:线程组级别、线程块级别、kernel级别。目前对线程调度的研究主要集中在线程组级别和线程块级别,相比之下,kernel级别的调度研究比较少,所以主要研究前两种调度方式。
2.1 线程组级别线程调度
32个线程组成的线程束(warp)是GPU的基本执行单元。每个线程束中的线程同时执行,在理想的情况下,如果要获取当前指令只需要访问内存一次取出指令,然后将取出的指令发射到这个线程束占用的所有SP中执行[4]。通用图形处理器的并行计算的高效率则主要是依赖于SIMT模式,NVIDIA公司GPU的SIMT调度过程分为软件调度和硬件调度。在GPGPU进行计算时,系统以一组(NVIDIA规定32个线程为一组)线程组成一个warp,然后以warp 为单位进行取指运算,而不是以线程为单位取指。warp 的调度组织形式考虑到了线程组之间的耦合性,主要体现在每一个warp中分配的线程相关性要尽量小。
如果一个warp 与另一个相邻的warp有比较高的相关性,并且该线程束需要等待另一个warp 执行结果,那么要等待warp就会被调度器暂时挂起,接着调度器会自动越过该warp去调度下一个不相关的warp执行。这样就保证在等待的warp被挂起等待相关事件的时候,释放处理器去处理其他线程束,这种措施使得线程等待处理器执行的开销接近为零。
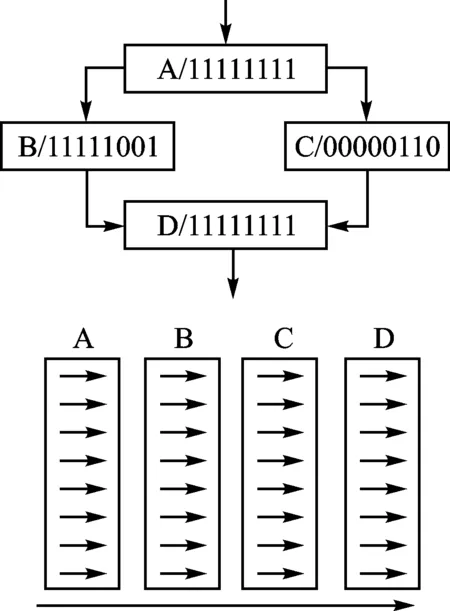
图4 分支转移执行图
然而应用程序中会普遍出现分支转移指令,按结构化属性可以分为:结构化分支转移指令和非结构化分支转移指令两类。结构化分支转移指令主要是指程序中包含if语句和for、while、switch循环分支转移指令等;非结构化则主要是指程序中包含break、continue、goto等指令或者异常处理中的异常跳转指令等。分支转移执行如图4所示。
任何的分支指令(if/for/while/switch/break)都有可能会导致线程分歧,线程遇到分歧时会顺序执行每个分支路径,同时阻止不在此路径上的线程执行,直到所有分支路径上线程执行完成,线程重新汇合到主路径执行路径。
线程分支主要有以下情况:如果一个线程束内的32个线程都只满足同一个分支,就称该warp满足“分支按warp对齐”,这时程序的分支基本不会影响系统执行效率。但是,如果一个warp的32个线程分别满足多个不同的分支,那么不满足当前正在执行分支的线程就有可能会采用插入等待或者假执行(会参加计算,但是不保留计算结果)的方式。因为,warp内的每个线程都会判定是否满足某个分支。一旦判定满足,就会立即执行分支内的代码;如果不满足,则线程会暂停执行,直到其所等待的其他线程执行完成,然后再开始下一步的执行。这种情况下总的运行时间就是多个运行分支的时间之和。
因为通用图形处理器最小的执行单位是warp,所以如果warp内不同线程的循环次数不同,就会产生另一种分支情况,并且warp的执行时间是循环次数最多的那个线程所花费的时间。
这种调度方法的缺点是在程序执行过程中,如果线程组遇到分支转移指令,则warp中的每一个线程就会根据分支指令的执行结果选择后续执行的分支路径,这种情况会出现部分线程执行不同分支路径的情形。而且通用图形处理器SIMT模式下只允许线程组在一个时刻执行一条指令,导致不同的分支路径只能串行执行,则必然导致线程级并行的效率降低。
2.2 线程块级别线程调度
通用图形处理器运行的SIMT线程调度模型需要基于NVIDIA公司的CUDA平台,利用NVIDIA CUDA编程平台编写的程序一般要分为主机端串行部分和设备端并行部分,其中串行部分依然在传统CPU上运行,而并行部分则要发射到NVIDIA公司通用图形处理器上执行。通过上文介绍我们知道,执行在GPGPU上的程序又被称为kernel程序,kernel程序在发射到通用GPU硬件执行前会形成一组并行执行的线程组。执行在GPU上的内核程序需要由程序员手动编写,同时程序员还需要编写一些准备程序,如数据从CPU存储空间向GPGPU存储空间的传递程序、指定线程数量、线程块的划分、存储空间的分配程序等。
设备端的程序从程序员编写到最终在NVIDIA的GPU上执行的全过程中会涉及到两个调度过程:线程软件调度和硬件调度过程。SIMT调度图如图5所示,软件调度过程流程见图5(a),硬件调度流程见图5(b)。
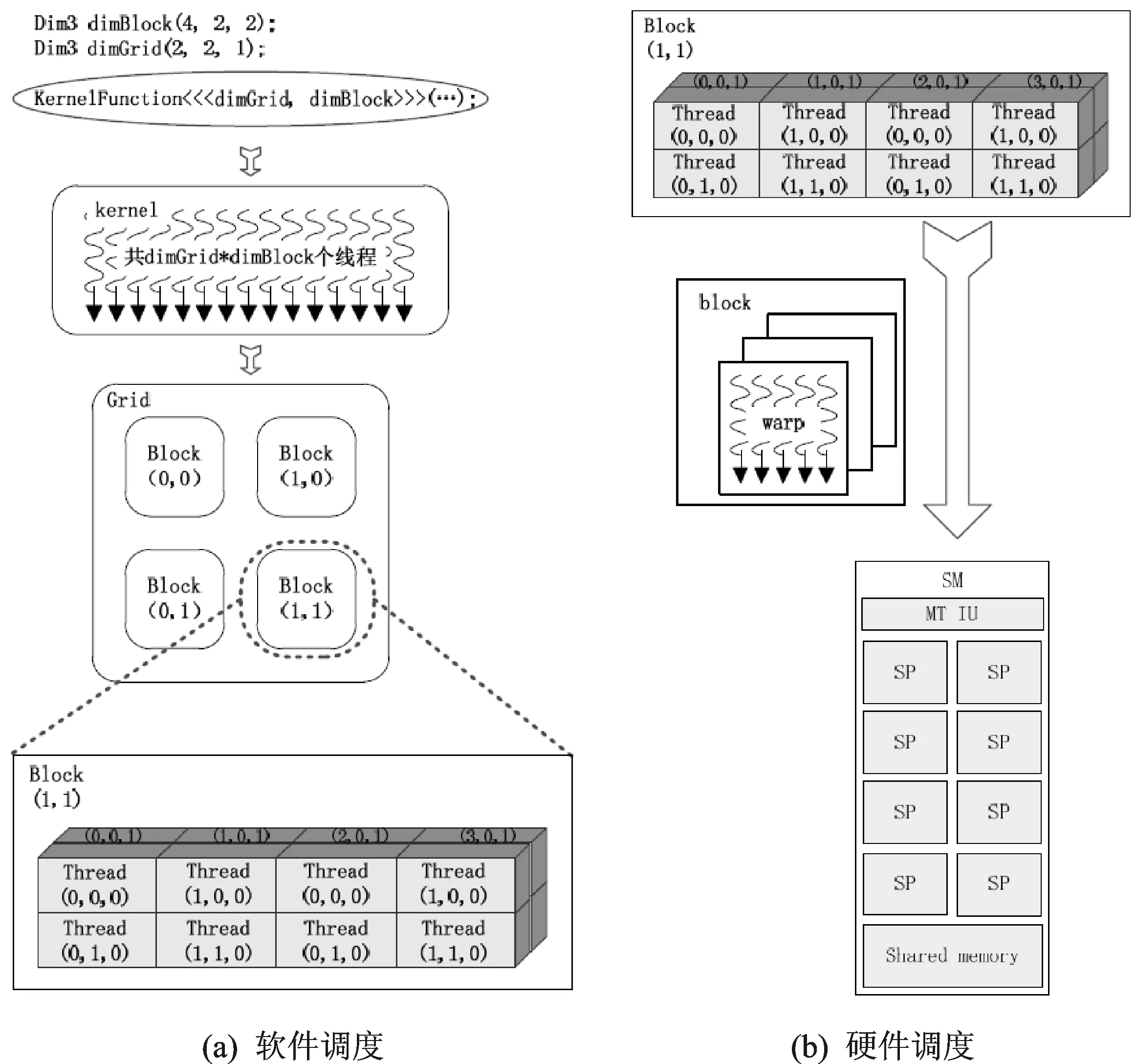
图5 SIMT调度图
在软件调度过程中,系统中内核代码会根据程序员指定的线程数量形成一定数量的线程。软件调度将这组线程分成若干个线程块(block),线程块的数目也是由程序员在编程时显示指定的,每个block中都会包含一定数量的线程。最终形成的这些block就是由软件调度的结果,接着以这些block为单位进入硬件调度过程。
在硬件调度过程中,block中的线程又会重新组合形成warp。在内核线程被执行时,以整个线程块的形式发射到GPGPU上的SM,每一个block发射到同一个SM,然后以warp为单位进行SIMT 调度执行。warp中线程指令载入到指令缓存后会被译码单元译码,每个线程取自己的操作数进入ALU执行,等待存储器数据访问的warp进入等待区。当warp中线程全部执行完成并进入写回操作,SIMT调度全部任务执行完成。
3 通用图形处理器节能方法
目前,学术上实现计算机节能的技术主要有两类:一类考虑软件级的节能,主要从操作系统或应用软件中寻找优化方法;第二类考虑硬件级的节能,节能措施主要是设计绿色平台架构、搭建节能中心、开发低功耗设备[7]。
动态功耗的计算公式为:
(1)
其中,Pd代表动态功耗,Vdd表示系统的电压,f表示系统的频率;C1与Nsw是与电路自身特性有关的参数,当电路固定下来后可以看成一个常量K,则上述公式化简为:
(2)
由于设计的电路中,频率和电压具有线性关系,所以上述公式进一步简化为:
(3)
其中K′为一个常数,若用Wd表示系统的动态能耗,则:
(4)
由数学知识可得到如下公式:
(5)
其中,C′只与具体电路特性有关。由式(5)可知,任务执行时的频率完全决定任务运行的功耗。主要是常用的节能动态电压与频率调节(DynamicVoltageandFrequencyScaling,DVFS)技术是基于系统频率实现的。
传统DVFS技术主要用在CPU节能,在CPU利用率较低时,通过降低CPU频率实现处理器的节能。随着研究的深入,DVFS也被用来实现GPU的节能。参考文献[8]就是通过提取软件特征量优化了DVFS的算法,并提出一种CDVFS技术实现了GPU节能。
由物理知识可知,任务的运行时间与运行频率具有反比关系。所以,在系统的运行频率降低时,功耗降低,但也会使任务执行时间变长。
综上所述,系统节能的最终目标是寻找频率的一个平衡区间,既能保证系统低功耗运行,又能使任务执行时间在用户接受范围内。
结 语
本文介绍了通用图形处理器(GPGPU)的体系结构和相关概念,以及GPGPU线程调度的方法和功耗节能方法。这些方法只是在一定程度上解决了通用图形处理器的相关问题,提升了并行性能,这样就导致GPGPU性能还不能完全发挥出来。

[1] Manyika J,Chui M,Brown B,et al.Big data:The next frontier for innovation,competition,and productivity[EB/OL].[2017-013].http://www.mckinsey.com/insights/business_technology.
[2] 张舒,褚艳利.GPU高性能运算之CUDA[M].北京:中国水利水电出版社,2009:27-38.
[3] 何炎祥,张军,沈凡凡,等.通用图形处理器线程调度优化方法研究综述[J].计算机学报,2016,39(9):1733-1749.
[4] Cook S. CUDA 并行程序设计:GPU编程指南 [M].苏统华,李东,李松泽,译.[J].北京:机械工业出版社,2014.
[5] Wu H, Diamos G, Wang J, et al. Characterization and transformation of unstructured control flow in bulk synchronous GPU applications[J]. The International Journal of High Performance Computing Applications,2012,26(2):170-185.
[6] 徐元旭. SIMT 线程调度模型分析及优化[D]. 哈尔滨:哈尔滨工业大学,2013.
[7] 刘孝伍.面向Linux系统的处理器节能技术研究及应用[D].成都:四川大学,2016.
[8] Junke Li A Modeling Approach for Energy Saving Based on GA-BP Neural Network[J].Journal of Electrical Engineering &Technology,2016,11(5):1289-1298.
张鹏博(硕士在读),主要研究方向为嵌入式系统下的绿色计算、GPU并行计算、区块链溯源;郭兵(教授),主要研究方向为嵌入式实时系统、绿色计算、个人大数据、区块链溯源;黄义纯、曹亚波(硕士在读),主要研究方向为个人大数据、区块链溯源。
Research on Parallel Computing of General Purpose CPGPU
Zhang Pengbo,Guo Bing,Huang Yichun,Cao Yabo
(School of Computer Science and Technology,Sichuan University,Chengdu 610065,China)
The Graphics Processing Unit (GPU) only is been used to the graphics image rendering,so it becomes a parallel computing platform General Purpose GPU(GPGPU),the parallel computing power is growing,and the application is more and more widely.Based on the study of GPGPU architecture,the GPGPU parallel computing thread scheduling is studies,and the principle of GPU thread scheduling and the deficiency of SIMT scheduling mode are introduced.The relationship between system power consumption and system operating frequency is expounded by formula.
big data;parallel computing;thread scheduling;GPU energy saving
国家自然科学基金重点项目(项目编号:61332001);国家自然科学基金资助项目(项目编号:61272104)。
TP302
A
�迪娜
2017-03-24)
