一种用于文本复制检测的指纹特征选择算法
2017-06-23邓新洁付二帅王刘阳
张 祯,邓新洁,付二帅,王刘阳
(杭州电子科技大学网络空间安全学院,浙江 杭州 310018)
一种用于文本复制检测的指纹特征选择算法
张 祯,邓新洁,付二帅,王刘阳
(杭州电子科技大学网络空间安全学院,浙江 杭州 310018)
基于指纹特征的文本复制检测技术可以快速识别抄袭现象,但是存在指纹密度过大的问题,为此,提出了一种指纹特征选择算法——基于最优决策的指纹特征选择算法.在Winnowing算法的基础上,引入最优决策模型,构建了指纹特征选择的最优决策模型,通过对滑动窗口内各部分散列值进行评估来选择最优的指纹特征,避免了相邻窗口指纹特征重复选择的不足.实验结果表明,该算法和Winnowing算法相比,在保证文本复制检测精度的情况下,有效降低了指纹密度.
复制检测;指纹;密度;Winnowing;最优决策
0 引 言
在文本复制检测中,如果直接使用原始文本来度量文本间的相似性,系统需要大量的存储资源和计算资源,其检测效率较低.为了解决上述问题,通常利用指纹代替文本进行复制检测[1].在基于指纹特征的文本复制检测算法中,如何有效选择指纹特征是复制检测的关键技术.现有的指纹特征选择方法主要是基于滑动窗口技术,利用滑动窗口将输入文本分解为文本块,并将得到的文本块通过散列函数映射为散列值,采取一定的选择策略在散列值序列中选择一部分具有代表性的散列值作为指纹.Andrei Z. Broder等[2]提出选择全部散列值作为指纹特征;N. Heintze等[3]提出选择每个固定窗口内第i个散列值作为指纹特征;H. Nicholas[4]提出选择每个固定窗口内的极值作为指纹特征;K. Jesse等[5-7]提出基于模糊哈希的指纹特征选取算法;S. Antonio等[8-11]在模糊哈希指纹特征选取算法的基础上,通过预设多个不同的触发条件,选择指纹特征;S. Saul等[12]提出了Winnowing算法,选择滑动窗口内的极小值作为指纹特征;徐琴[13]借鉴了Winnowing算法思想,对输入文本合并整体词预处理后,通过二次特征提取方法选择指纹特征.上述算法虽然可以有效选择指纹,进行复制检测,但是均存在指纹密度过大的问题.本文提出了一种指纹特征选择算法—基于最优决策[14]的指纹特征选择算法.在Winnowing算法的基础上,将最优决策模型应用到指纹特征选择过程中,有效代表文本特征,降低了指纹密度,具有良好的可行性.
1 指纹特征选择的最优决策模型
以往的Winnowing算法通过找到窗口中的极值作为指纹特征.在指纹特征选择过程中,Winnowing算法利用滑动窗口逐个散列值滑动选择指纹特征,滑动次数较多,不仅容易导致相邻的散列值被选择为指纹特征,而且没有考虑到相邻窗口指纹特征重复的问题,导致相邻窗口选择相同指纹特征的概率较高,最终造成指纹密度过大.为了解决这一问题,本文构建了基于最优决策模型的指纹特征选择方法.其基本思想是将指纹特征的选择范围限定在窗口的特定区间内,并且以指纹特征判定滑动窗口下次滑动的起始点,使得滑动窗口内和上一窗口没有重叠的散列值,进而去除了无关散列值的干扰,避免了选择相邻散列值作为指纹特征的情况,克服了相邻窗口指纹特征重复选择的缺陷,减少了滑动窗口滑动的次数,降低了指纹密度.其基本步骤如下:
1)输入文本预处理.去除助词、标点符号等噪声干扰后的文本,用T[1,…,n]表示.通过滚动哈希函数,将T[1,…,n]中长度为k的子串映射为散列值序列t1,t2,…,tn-k+1.其中,数值ts(s=1,2,3…,n-k+1)与子串T[s,…,s+k-1]相对应.计算散列值序列的方法如图1所示.

图1 T[1,…,n]的哈希值计算
滚动哈希函数将长度为k的字符串映射为一个整数x(0≤x≤bk),设asc(c)为字符c的ASCII值,将文本T[1,…,n]中长度为k的子串T1,T2,…,Tk映射为一个散列值的计算公式,如下:
H(T1,T2,…,Tk)=asc(T1)bk-1+asc(T2)bk-2+…+asc(Tk)
(1)
则H(T2,…,Tk,Tk+1)可表示为:
H(T2,…,Tk,Tk+1)=(H(T1,T2,…,Tk)-asc(T1)bk-1)b+asc(Tk+1)
(2)
通过式(1)、式(2)计算出T[1,…,n]的散列值序列.为了便于说明,散列值序列用Hs(s=1,2,3,…,n-k+1)表示.
2)为了从Hs中选择出若干个具有代表性的散列值作为指纹,降低指纹密度,本文首先定义一个大小为w的窗口,构造一个文本块Hy.Hy为文本散列值的一个集合,可表示为Hy={t1,t2,…,tw}.然后利用最优决策模型从Hy中选择一个散列值作为其指纹特征,最优决策模型需要将Hy分为若干部分.假设将Hy分割为n部分,用Hy1,Hy2,…,Hyn表示,则Hy可表示为:
(3)
3)最优决策模型选择.将Hy1,Hy2,…,Hyi作为指纹选择的第一部分,选择其中的最小值作为Hy特征值的参照值,即:
(4)
4)最优决策模型验证.在第二部分Hyi+1,Hyi+2,…,Hyk中,验证p是否在Hyi+1,Hyi+2…,Hyk中仍是最小值,设q为Hyi+1,Hyi+2…,Hyk中的最小值,则q表示为:
q=min(Hyi+1,Hyi+2,…,Hyk)
(5)
如果p≤q,则p作为Hy特征值的参照值,否则q作为参照值.设v表示Hy特征值的参照值,则
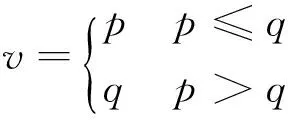
(6)
5)最优决策模型的决定.根据窗口已计算部分,选择Hy特征值的参照值v,将Hy特征值的范围限定在Hy的最后部分.为了减少搜索成本,本文定义了阈值t,并规定如果满足
(7)
则选择Hy(k-n)i作为Hy的指纹特征,并将Hy(k-n)i+1作为下个窗口的左界,依次进行,其中,Hy(k-n)i表示窗口Hy的第部分的第个散列值.
2 基于最优决策的指纹特征选择算法描述
本文所提出的基于最优决策的指纹特征选择算法,其算法步骤如下:
输出:指纹特征sT.
1)对待测文本T进行预处理,得到T′={t1,t2…,tk}.
2)对T′通过散列值映射算法进行映射,得到T″散列值序列H={h1,h2,…,hn}.
3)对H通过指纹选择的最优决策模型进行指纹选择,详细步骤如下:
①从滑动窗口H1={h1,h2,…,hw}中选择指纹特征,将H1分为n部分,表示H1,1,H1,2,…,H1,n;
②H1,1,H1,2…,H1,i作为指纹特征选择的第一部分,选择其中最小值作为H1特征值的参照值,即:p=min(H1,1,H1,2,…,H1,i);
③H1,i+1,H1,i+2,…,H1,k作为指纹特征选择的第二部分,通过式(5)、式(6)选出H1特征的参照值v1;
④顺序遍历H1中的第三部分H1,k+1,H1,k+2,…,H1,w,如果散列值H1,k+i和v1满足式(7),则选择H1,k+i作为窗口的特征值s1.
4)滑动窗口滑动k+i步.
5)重复步骤3、步骤4.
6)将得到的特征值序列,逐一通过ASCII码编码,得到文本指纹sT.
为了详细说明本文算法对输入文本选择指纹,进行文本复制检测的详细流程,本文以英文文本为例,设滑动窗口大小为6,则利用本文算法对输入文本选择指纹的详细流程如下:
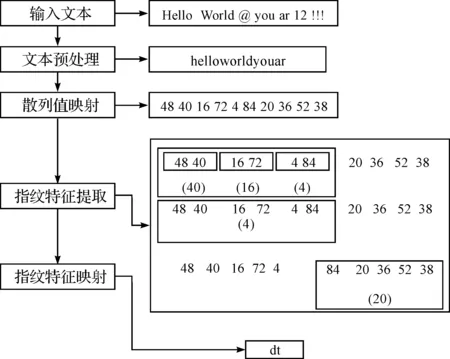
图2 基于最优决策的指纹特征选择
3 指纹密度分析
指纹密度是指纹长度和散列值序列长度的比,是衡量指纹特征选择算法性能的一个重要指标.本文将Winnowing算法与本文算法在指纹密度上进行了分析对比.
设定输入可疑文本A,A经过滚动哈希函数计算后,得到的散列值序列为N.用w表示滑动窗口大小,则指纹的长度由N和w决定.
通过分析Winnowing算法可知,相邻窗口有w-1个重复的散列值,故两相邻窗口选择相同指纹特征的概率为w-1/w.假设有w个连续的窗口,用[H1,H2,…,Hw]表示,每个窗口中散列值的个数为w.假设窗口选择的指纹特征为,为窗口中第i(1≤i≤w)个散列值.则窗口Hn(2≤n≤w),选中作为其指纹特征的概率为:
(8)
其中,n为滑动窗口的次序,w为滑动窗口的大小,i为指纹特征的位置,Pn为第n个滑动窗口的指纹特征是F1的概率.
假如散列值序列为递增序列,每次选择的指纹特征为滑动窗口内的第一个散列值,即i=1,则由式(8)可知,相邻窗口选择重复指纹特征的概率为0,这时选择的指纹特征数目最多,指纹密度最大.此时生成的指纹密度为(N-w+1)/N,因为N远大于w,则(N-w+1)/N趋近于极限值为1.
通过式(8)可知,值越大,则越多的窗口选择指纹特征的重复率越高.假设窗口的指纹特征F位置为i=w,并且F为该相邻的w个窗口的最小值时,则相邻窗口[H1,H2,…,Hw]均存在选择F作为其指纹特征.此时选择的指纹特征重复率最高,指纹去重后指纹密度最小为1/w.
本文的最优决策算法,将窗口内的散列值分为3部分.D表示窗口内第一部分的最小散列值,S表示窗口内第二部分的最小散列值,如果D≤S,则仍将D作为选择指纹特征的参考值,否则将S作为参考值.以D为例,在第三部分,只要有|H-D| (9) 其中,w为滑动窗口的大小,i为指纹特征的位置,ρ(A)为可疑文本A的指纹密度. 通过对两种算法选择的指纹密度分析,Winnowing算法生成的指纹密度为[1/w,1],指纹密度变化范围较大,本文算法生成的指纹密度为[1/w,3/(2w+3)],指纹密度变化范围较小,选择指纹特征比较稳定. 4.1 数据集 本文的实验数据来自PAN11[15]抄袭竞赛语料训练集,训练集分为抄袭文本和原文本两部分,各有近15 000个文本,文本大小为1 KByte~2.6 MByte,98%的文件小于1 MByte. 对于输入的可疑抄袭文本A,通过指纹特征选择算法得出的指纹用h(A)表示.文本库中的一个原文本B,其指纹用h(B)表示.sim(A,B)表示文本A和B之间的相似度,0≤sim(A,B)≤1,0表示文本之间没有抄袭行为,1表示两文本完全相同.sim(A,B)的计算公式如下: (10) 为了检测输入文本是否为抄袭文本,实验中设置了一个阈值t.如果sim(A,B)的值大于设定的阈值t时,则认为文本A是抄袭文本. 4.2 评价标准 为了验证本文算法在保证检测精度的前提下,达到降低指纹密度的目的.本实验采用文本复制检测中常用的查准率P、查全率R来评价检测精度,并选择相似度大于预定阈值的文本作为此次检测的结果集S.其查准率P、查全率R分别表示为: (11) (12) 在滑动窗口大小相同的情况下,指纹特征数目越多,则说明指纹密度越大. 4.3 实验结果与分析 本文实验对Winnowing算法和本文算法在文本复制检测精度及指纹特征数目上进行对比.实验参数主要由窗口大小和相似度的预设阈值决定,本文实验设置窗口的大小为集合[3,6,9,12,15],并且预设文本相似度的阈值为集合[0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9].实验结果如表1-2所示. 表1 两种方法的查准率比较 % 表2 两种方法的查全率比较 % 为了更直观说明Winnowing算法和最优决策算法检测结果的查准率和查全率情况,将表1和表2中的实验结果用折线图表示,如图3、图4所示. 图3 最优决策算法和Winnowing算法检测结果的查准率对比 图4 最优决策算法和Winnowing算法检测结果的查全率对比 由图3、图4可知,在阈值一定的情况下,最优决策算法和Winnowing算法的检测性能均随着窗口大小的增大而降低,但是下降的幅度较小.因为当窗口增大时,由第3节指纹密度分析可知,两种算法选择指纹的密度均减小.指纹代表文本特征,选择的指纹密度越大,越能有效代表文本,文本复制检测的结果也越精确.相反,如果指纹密度较小,那么丢失文本信息的可能性较大,误差率较高.但另一方面,为了提高文本复制检测的效率,在实际应用中,指纹密度不宜过大,并且需要保证检测结果的准确率和查全率.因此,窗口大小要适中,从图3、图4可以观察到,当窗口大小w=9时,选择的指纹可以使检测结果的查准率和查全率均处于理想水平,并且当阈值t=0.6时,Winnowing算法检测结果的查准率、查全率分别为81.4%,61.4%,最优决策算法检测结果的查准率和查全率分别为79.2%,59.2%.最优决策算法检测结果的查准率和查全率上略低于Winnowing算法,但均在接受范围. 为了对比两个算法的指纹密度.在实验中,设定不同大小的滑动窗口,用两种算法分别对输入文本进行指纹选择.表3给出了两种算法分别对一篇含有14 000个单词的文本进行指纹特征选择的对比情况. 图5 Winnowing和最优决策算法选择指纹的对比情况 表3 两种算法选择指纹的对比情况 算法窗口大小691215Winnowing11047869844652363最优决策算法486929341456764 为了直观对比两种算法选择指纹特征数目,将表3转换为直方图的形式,如图5所示. 在滑动窗口大小相同的情况下,输入文本生成的散列值序列相同,选择的指纹特征数目越多,说明指纹密度越大.由表3和图5可知,两种算法选择的指纹特征数目均随着滑动窗口的增大而减少,Winnowing算法选择的指纹特征数目远大于最优决策算法.本文算法利用最优决策模型以滑动窗口为单位,对滑动窗口的散列值评估分为3个阶段,即选择—验证—决定.限定指纹特征选择范围在最优决策的决定阶段,并且滑动窗口以指纹特征为下次滑动的起始点,滑动窗口内和上一窗口没有重叠的散列值,去除了无关散列值的干扰,避免了选择相邻散列值作为指纹特征的情况,并克服了相邻窗口指纹特征重复选择的缺陷,减少了滑动窗口滑动的次数.由图3—图5可知,本文算法在保证检测精度的前提下,减少了选择指纹特征的数目,降低了指纹密度. 本文提出了一种指纹特征选择算法—基于最优决策的指纹特征选择算法.在指纹特征选择过程中使用最优决策模型,通过该模型评估滑动窗口的各部分散列值,选择指纹特征.实验结果表明本文算法和Winnowing算法相比,本文算法在保证检测精度的前提下,去除了无关散列值的干扰,避免了选择相邻散列值作为指纹特征的情况,克服了相邻窗口指纹特征重复选择的缺陷,减少了滑动窗口滑动的次数,降低了指纹密度. [1]DIVAKARAN A. Multimedia Content Analysis: Theory and Applications[M]. Berlin: Springer, 2008:286-295. [2]BRODER A Z, GLASSMAN S C, MANASSE M S. Syntactic clustering of the web[J]. Computer Networks and ISDN Systems, 1997,29:1157-1166. [3]NEVIN H. Scalable Document Fingerprinting[C]//Proceedings of the Second USENIX Workshop on Electronic Commerce. Oakland: Research Gate, 1996:87-91. [4]HARBOUR N. Dfcldd[CP/OL].[2004-07-28]. http://dcfldd.sourceforge.net. [5]KORNBLUM J. Identifying Almost Identical Files Using Context Triggered Piecewise Hashing[J]. Digital Investigation, 2006,3:91-97. [6]FIGUEROLA C G, DAZ R G, BERROCAL J L A, et al. Web document duplicate detection using fuzzy Hashing[M]//Trends in Practical Applications of Agents and Multiagent Systems. Springer Berlin Heidelberg, 2011:117-125. [7]ROUSSEV V. Data fingerprinting with similarity digests[C]//IFIP International Conference on Digital Forensics. Springer Berlin Heidelberg, 2010:207-226. [8]SI A, LEONG H V, LAU R W H. Check: a document plagiarism detection system[C]//Proceedings of the 1997 ACM symposium on Applied computing. ACM, 1997:70-77. [9]BREITINGER F, BAIER H. A fuzzy hashing approach based on random sequences and hamming distance[C]//Proceedings of the conference on digital forensics, security and law. Association of Digital Forensics, Security and Law, 2012:89-100. [10]BREITINGER F, ASTEBØ l K P, Baier H, et al. mvHash-B-a new approach for similarity preserving hashing[C]//IT security incident management and it forensics (IMF), 2013 seventh international conference on. IEEE, 2013:33-44. [11]CHEN L, WANG G. An efficient piecewise hashing method for computer forensics[C]//Knowledge Discovery and Data Mining, 2008. WKDD 2008. First International Workshop on. IEEE, 2008:635-638. [12]SCHLEIMER S, WILKERSON D S, AIKEN A. Winnowing: local algorithms for document fingerprinting[C]//Proceedings of the 2003 ACM SIGMOD international conference on Management of data. ACM, 2003:76-85. [13]徐琴.基于二次特征提取的文本复制检测技术[D].重庆:西南大学,2013. [14]廖沫,陈宗基.基于满意决策的多机协同目标分配算法[J].北京航空航天大学学报,2007,33(1):81-85. [15]ARGAMON S, JUOLA P. Overview of the International Authorship Identification Competition at PAN-2011.[C]//CLEF 2011 Labs and Workshop, Notebook Papers, 19-22 September 2011, Amsterdam, The Netherlands. 2011:1-10. A Fingerprint Feature Selection Algorithm for Text Copy Detection ZHANG Zhen, DENG Xinjie, FU Ershuai, WANG Liuyang (SchoolofCyberspace,HangzhouDianziUniversity,HangzhouZhejiang310018,China) Fingerprint feature-based text copy detection can rapidly identify the plagiarism, but suffers from the excess of fingerprint density. To resolve the problem, this proposes an optimal decision-based fingerprint feature extract algorithm, based on the combination of Winnowing algorithm and optimal decision model, and it can extract fingerprint feature from the hash values in the sliding window and avoid duplicate selection of adjacent windows’ fingerprint feature. Experimental results show the proposed method can decrease the density of fingerprint effectively under the condition of same detection accuracy. copy detection; fingerprint; density; Winnowing; optimal decision 10.13954/j.cnki.hdu.2017.03.011 2017-04-22 国家保密局基础科研资助项目(BMKY 2015 S05-1) 张祯(1978-),男,山西大同人,讲师,安全与保密技术. TP391 A 1001-9146(2017)03-0051-07
4 实验结果与分析



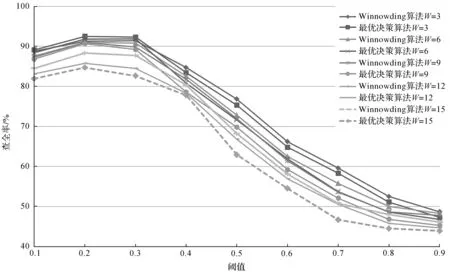


5 结束语
