基于关联规则挖掘的软件缺陷分析研究
2017-02-27颜乐鸣
颜乐鸣
(中国电子科技集团公司第七研究所,广州市 510310)
基于关联规则挖掘的软件缺陷分析研究
颜乐鸣
(中国电子科技集团公司第七研究所,广州市 510310)
软件测试是确保软件产品质量的有效技术手段,其根本目的是发现隐藏在软件中的缺陷,并通过对其的修复尽可能减少遗留在系统中的缺陷数量,以提升软件的质量。随着缺陷数据的不断积累,面对庞大、甚至海量的缺陷信息,已无法通过人工方式进行缺陷分析。基于此,作者对缺陷分类和数据挖掘技术开展研究,总结测试工程实践中的缺陷特点,提出改进的正交缺陷分类模型;结合数据挖掘中的关联规则挖掘算法,提出缺陷关联分析模型。并对上述模型进行应用说明,帮助软件技术人员定位和解决缺陷,提供软件测试缺陷分析的辅助手段。
软件测试;软件缺陷分析;正交缺陷分类;关联规则挖掘
本文著录格式:颜乐鸣. 基于关联规则挖掘的软件缺陷分析研究[J]. 软件,2017,38(1):70-76
0 引言
软件开发是一项由人进行的活动,在其过程中必定会因为人的因素而产生缺陷,因此,缺陷是软件与生俱来的特性,也是影响软件质量的重要因素和关键因素之一。软件测试是以发现缺陷为目的的确保软件产品质量的有效技术手段,近年来,软件组织对软件测试活动的重视程度日益提升,但由于工程实践中收集缺陷信息和分析方法的应用会带来较高的成本,许多软件组织并未对缺陷数据的分析给予足够重视,而且随着缺陷数据的不断积累和增长,使用传统的缺陷分析方法分析海量缺陷数据已不能满足缺陷管理的需求。
数据挖掘技术能从大量数据中发掘有重要意义的信息,为决策提供有价值的参考,可以用于解决软件测试领域中缺陷分析的问题。近年来,基于数据挖掘的方法在软件测试领域有很多应用,诸如美国、英国等发达国家,将数据挖掘技术在软件测试领域的应用作为研究热点,已经研究出较多的方法用于辅佐测试及其过程改进。这些成果包括测试数据生成、测试数据与缺陷之间的关系分析、故障定位、缺陷预测等[1,2,3,4]。目前,国内外的研究成果表明,相关技术在测试中多应用于处理庞大信息,但研究仍处于初期,尚未发布具有普适性、商业化的产品或应用,国内外目前尚无针对软件缺陷的专用数据挖掘系统。
本文试图对缺陷进行系统、全面的分类,通过建立缺陷分类模型,并在此基础上应用数据挖掘中的关联规则方法对缺陷数据进行分析,挖掘缺陷数据中有价值的信息,寻找隐藏在缺陷背后的共性原因,为缺陷预防、评估软件质量及产品决策提供参考依据。
1 软件缺陷
1.1 软件缺陷的定义
软件缺陷是存在于软件文档、程序及数据中不希望的或不可接受的偏差[5]。需求分析过程中错误的需求定义,软件设计过程中的设计错误,编码过程中出现的语法错误、逻辑错误,软件开发完成后没有实现软件功能,甚至是软件交付后出现的导致软件不能正常使用的情况等等,都可以称为软件缺陷。
不论软件规模的大小、开发语言的种类、开发技术的难易,都会因为人的错误而在软件中留下不良的影响,因此,不存在没有缺陷的软件,而且软件中的缺陷将流转于软件开发的整个生命周期,好比定时炸弹,当满足一定的触发条件时,将被激活。为了保证软件的正常运行,必须对缺陷进行有效的管理,保证每一个被激活的缺陷都得到有效的处理,尽可能减少遗留在软件产品中的缺陷,提高软件的质量。而缺陷分析则是缺陷管理中重要的内容之一,有效的缺陷分析,不仅能评估软件的质量,还能在一定程度上抑制缺陷的增长趋势,达到缺陷预防的目的。
1.2 软件缺陷分析
缺陷分析是指将软件研制过程中产生的缺陷信息进行分类和汇总,以发现各种类型缺陷发生的概率,发现缺陷集中的模块、掌握缺陷的发展规律、发掘缺陷产生的根本原因。通过缺陷分析,可以辅助软件人员定位及修复缺陷,评估软件质量,制定缺陷预防措施。缺陷分析的过程如图1所示。

图1 缺陷分析过程Fig.1 Defect analysis process
在缺陷分析过程中,完整、准确的记录缺陷是开展分析的基础。随着自动化测试技术的兴起,使用自动化工具对缺陷进行跟踪管理变得普及,缺陷管理工具为记录和采集缺陷提供了自动化的手段,使得记录和处理缺陷的效率得到了大大的提高,但是这些系统多用于缺陷跟踪,对于缺陷的分析也仅限于度量和统计等定量分析,缺陷的分类标准和属性描述也各不相同,每个系统中缺陷的属性划分均固定不变,很难适用于所有的软件组织。
通过对缺陷属性的分解和定义,对软件缺陷进行分类,是缺陷分析的关键所在。但由于缺陷的表现方式、引入时段和产生原因多种多样,对其进行分类的方法也各不相同,自20世纪70年代起,研究人员开始探索从不同角度对软件缺陷进行分类。典型的有IBM公司推出的正交缺陷分类法、IEEE制定的软件异常分类标准、Thayer分类法、我国国家军用标准《GJB 2786A军用软件开发通用要求》中定义的软件错误等[6]。其中正交缺陷分类(Orthogonal Defects Classification,ODC)的应用最为广泛,它是IBM公司经过了对大量产品的软件缺陷进行分析总结后于1992年提出的。正交缺陷分类法使用八个属性全面描述了缺陷的特征:发现缺陷的活动、缺陷引发事件、缺陷影响、缺陷载体、缺陷类型、缺陷限定词、缺陷来源和缺陷年龄[7],其中每个属性均包含各自的子属性。该方法既是缺陷分类方法,又是软件缺陷度量方法,体现了统计方法和原因分析的结合。包括IBM公司在内的许多软件组织都已接受并使用,并且已成为CMMI四级及五级的支撑工具之一,用于定量过程管理和缺陷预防。
开展缺陷分析的根本目的是预防缺陷,因此,缺陷预防成为缺陷分析过程中核心的组成部分。而预防缺陷的着力点则在于挖掘缺陷背后的共性原因。当缺陷产生后,软件人员的任务不仅仅是解决某一个缺陷,而应该通过深入、详细的分析缺陷数据去寻找缺陷的根本原因、共性原因,以防止缺陷的再次发生,不断提高软件开发团队的技术能力和软件产品质量。
2 数据挖掘
2.1 数据挖掘的定义和任务
数据挖掘是从大量的、不完全的、有噪声的、模糊的、随机的实际应用数据中,提取隐含在其中的潜在信息和知识的过程[8]。这些信息和知识对于决策分析或是寻找问题的根本原因具有重要的意义,但其并非显而易见,而往往隐藏在数据之中,需要人们去探寻和挖掘。数据挖掘技术集合了传统的数据分析方法和复杂的算法,大大增加了分析大数据量信息的可能性。
数据挖掘任务主要分为预测任务和描述任务两类[9]。预测任务的主要目标是依据已有属性的值,分析指定属性的值,以预先推测事物未知的情况;描述任务的主要目标为挖掘潜藏在数据中的联系。具体来说,数据挖掘的任务可分为如下四个方面:
(1)预测建模:以为目标变量建立模型为目的,含分类任务和回归任务;
(2)聚类分析:在相似的基础上将数据集合分组,使相同簇内对象的相似程度大,但不同簇之间的对象具有很大差异;
(3)关联分析:发掘不同数据对象间的关联;
(4)异常检测:识别与其他数据特征有明显差异的对象,发现异常和离群的现象。
在软件测试的工程实践中,导致缺陷产生的原因可谓千奇百怪、五花八门,如图2所示。传统的报表形式只是反映了缺陷表象,却无法表现缺陷之间隐含的关系。而且随着软件复杂度和规模的不断提高,缺陷存在和产生的几率将大大增加,某些大型软件项目的缺陷甚至数以千计,通过人工分析的方法对缺陷数据进行逐一筛查已不太现实。作者试图引入数据挖掘的技术手段,在对缺陷进行系统分类的基础上进行缺陷关联分析。
2.2 与关联规则有关的概念
由于人们对事物认知的局限性,导致数据存在着大量的未知关联,这些关联均无法通过数据表格的形式表现出来。随着收集和存储在数据库中的数据规模越来越大,人们开始对从这些数据中挖掘相应的关联知识越来越有兴趣。关联分析则是用于发现蕴含在大型数据信息中有价值关联的方法,并使用关联规则来描述这些数据项之间的联系,与之相关的概念主要有[9]:

图2 缺陷及其产生原因的关系Fig.2 The relationship between defect and their causes
(1)事物集合和项的集合:
使用D表示待分析的所有事务集合,则:

使用I表示事物集合D中所有项的集合,则:

(2)项集:所有项的集合中,其任何一个子集都可称为项集,倘若某个项集含有k个项,则称其为k-项集。每个事物所包含的项集都是I的子集,记为:

(3)支持度(support):X、Y同时在事物集合D中出现的概率。当项集X在事物集合D里出现的概率不小于某个支持度的阈值时,则称X为频繁项集,该支持度的阈值则为最小支持度(minsup),并使用Lk表示具有k个项的频繁项集,称为频繁k项集;
(4)置信度(confidence):在事物集合中出现项集X时,同时出现项集Y的概率,它是Y出现在包含X的事物中频繁程度的表现。在计算置信度时,通常会预设置信度的最小值,即最小置信度(minconf);
(5)关联规则(Association Rules):以X→Y的逻辑表达式表示关联规则,其中X和Y均属于事物中全体项的集合,且X∩Y=Φ,及X和Y是不相交的集合。X→Y的强度可以使用支持度support(X→Y)和置信度confidence(X→Y)的值来表示。
3 基于正交缺陷分类和关联规则挖掘的缺陷分析
3.1 改进的正交缺陷分类参考模型
通过对各种分类方法的比较和总结得出,正交缺陷分类方法从不同维度体现了缺陷的特征,分析人员可以使用这些特征对缺陷进行系统性的分析,该方法既体现了定量分析,又结合了定性分析,从软件全生命周期的角度看,使用正交缺陷分类法对缺陷数据进行分析的结果可达到总揽全局的效果,但是传统的该分类相对复杂,难以适用所有的软件组织,为了降低分类的复杂度,提高缺陷分类的准确性,提出了改进的正交缺陷分类参考模型,如图3所示。
该模型参考传统的正交缺陷分类法,在经过对实际的缺陷数据进行分析后,选择软件人员最关心的缺陷属性作为分类的标识,亦通过八个属性表示缺陷的特征,分别为缺陷的发现阶段、引发事件、严重等级、缺陷来源、缺陷定位、产生影响、引入时段、引入类型,各属性的描述如表1所示,其中引发事件、缺陷定位和产生影响的子属性从缺陷数据的缺陷描述、定位和解决措施的语义信息提炼而来。在模型中,加入了缺陷的发现和修复阶段的两个过程因素,并从不同的角度和维度描述了缺陷的特征,可以帮助和引导测试人员和开发人员从各自的立场对缺陷进行分类,为缺陷分析提供准确的数据基础。

图3 改进的正交缺陷分类模型Fig.3 Improved orthogonal defect classification model
3.2 缺陷关联分析模型
在缺陷数据中,某些看上去述毫无联系的缺陷可能会存在某种程度上的依赖关系,通过对缺陷进行分类,可以从不同的立场和角度出发,使用一定的算法发掘缺陷信息中的隐藏价值。在关联分析中,Apriori算法是最经典的关联规则挖掘算法,其也被认为是所有关联分析算法的基础。该算法由Agrawal和Verkamo于1994年提出,其基本思想是:首先从事件中集中寻找所有频繁出现的事件子集,然后在这些频繁事件子集中发现可信度较高的规则[10]。Apriori算法的整个挖掘过程围绕着频度和强度进行,其主要步骤为:
1)通过对候选k-项集Ck不断的连接和剪枝,产生频繁k-项集Lk;
2)由频繁项集Lk,确定其中不小于最小置信度的全部规则,产生强关联规则。
使用Apriori算法,对缺陷进行关联分析,建立缺陷管理分析模型如图4所示。

图4 基于Apriori算法的缺陷关联分析模型Fig.4 Defect association analysis model based on Apriori algorithm
在使用缺陷关联分析模型时,结合改进的缺陷分类模型,建立缺陷ODC属性的集合I,该集合中包含了存在缺陷的所有ODC属性项i1,i2,...in,则I={i1,i2,..in};事务集合则由产生的缺陷组成,可记为D={d1,d2,...dm},关联规则产生过程可描述为:
(1)生成候选1-项集C1,C1={i1,i2,..in},计算每个项在缺陷事务D中的支持度,删除小于minsup的项集,产生频繁1-项集L1;
(2)由频繁1-项集L1中产生候选C2-项集,删除小于最小支持度的项集,产生频繁2-项集L2;
(3)由上一步产生的频繁(k-1)-项集通过连接产生候选k-项集,并经过剪枝,产生频繁k-项集;
(4)重复执行连接步和剪枝叶步,直至不能在事务D中找出频繁项集;
(5)将所有大于最小支持度的频繁项集计为L,产生L的所有非空子集s,并根据频繁项集生成满足最小置信度的关联规则。
3.3 模型的应用
在软件测试中,测试人员希望发现的缺陷越多越好,但是穷尽测试是不现实的,而且在测试实践中,出于进度和成本的压力,需要在有限的时间内尽可能地覆盖更多的需求,找出更多的缺陷,因此,测试人员关注的核心内容是如何发现缺陷。在缺陷的ODC属性中,引发事件表示了发现缺陷时所执行的测试活动,它从不同的角度对引发缺陷的事件进行了归纳,从该属性出发,可挖掘出各种引发事件之间的关联,帮助测试人员快速发现缺陷。
选取缺陷ODC属性中的引发事件作为分析对象,假设选项的缺陷属性列表及缺陷如表2所示。采用布尔形式表示某属性值是否引发缺陷。

表2 “引发事件”属性列表Tab. 2 “Trigger” attribute list
由表1可建立事物集合D = {{功能,人机交互,业务流程},{边界,人机交互,使用场景},{功能,边界,人机交互,使用场景},{边界,使用场景}},使用符号表示则为D = {{t1,t3,t4},{t2,t3,t5},{t1,t2,t3,t5}, {t2,t5}},如表3所示。

表3 事物集合DTab. 3 Transaction set D
预设最小支持度为50%,最小置信度为50%,经过如图5所示的步骤,经过3次迭代后,产生频繁项集{t2,t3,t5},其支持度为50%。其中,在产生候选k-项集时,标识为“×”表示该项集不满足最小支持度的要求,可从集合中删除。
由频繁项集{t2,t3,t5}的非空子集产生关联规则,如图6所示。
计算各规则的置信度,满足预设最小置信度要求的关联规则如表4所示。表中所示的关联规则展现了缺陷的引发事件中边界、人机交互和使用场景之间的强关联关系。当被测软件的使用场景和人机界面产生缺陷时,必定引发边界方面的缺陷,测试人员应花费更多的精力在各种场景的边界测试设计和执行中,而开发人员则应重新审视有关的设计和代码并进行必要的审查,杜绝由此引发更多的缺陷。
4 结论
本文提出了改进的正交缺陷分类模型,从缺陷发现和修复两个视角对缺陷的属性进行了划分,在此分类的基础上,对数据挖掘在缺陷分析的应用进行了初探,基于Apriori算法提出了缺陷关联分析模型,并使用该模型对缺陷的“引发事件”属性进行分析应用。
软件测试是保证软件质量的有效手段,虽然软件测试无法发现所有的软件缺陷,但可以通过对缺陷的分析达到预防缺陷的目的。后续工作中,我们将结合软件测试的工程实践,对改进的正交缺陷分类模型中缺陷的子属性进行补充和完善,同时考虑结合数据挖掘工具选择缺陷正交分类中的多个属性展开缺陷综合分析,以挖掘埋藏于缺陷中的更深层次原因,从根本上消除缺陷存在的隐患。
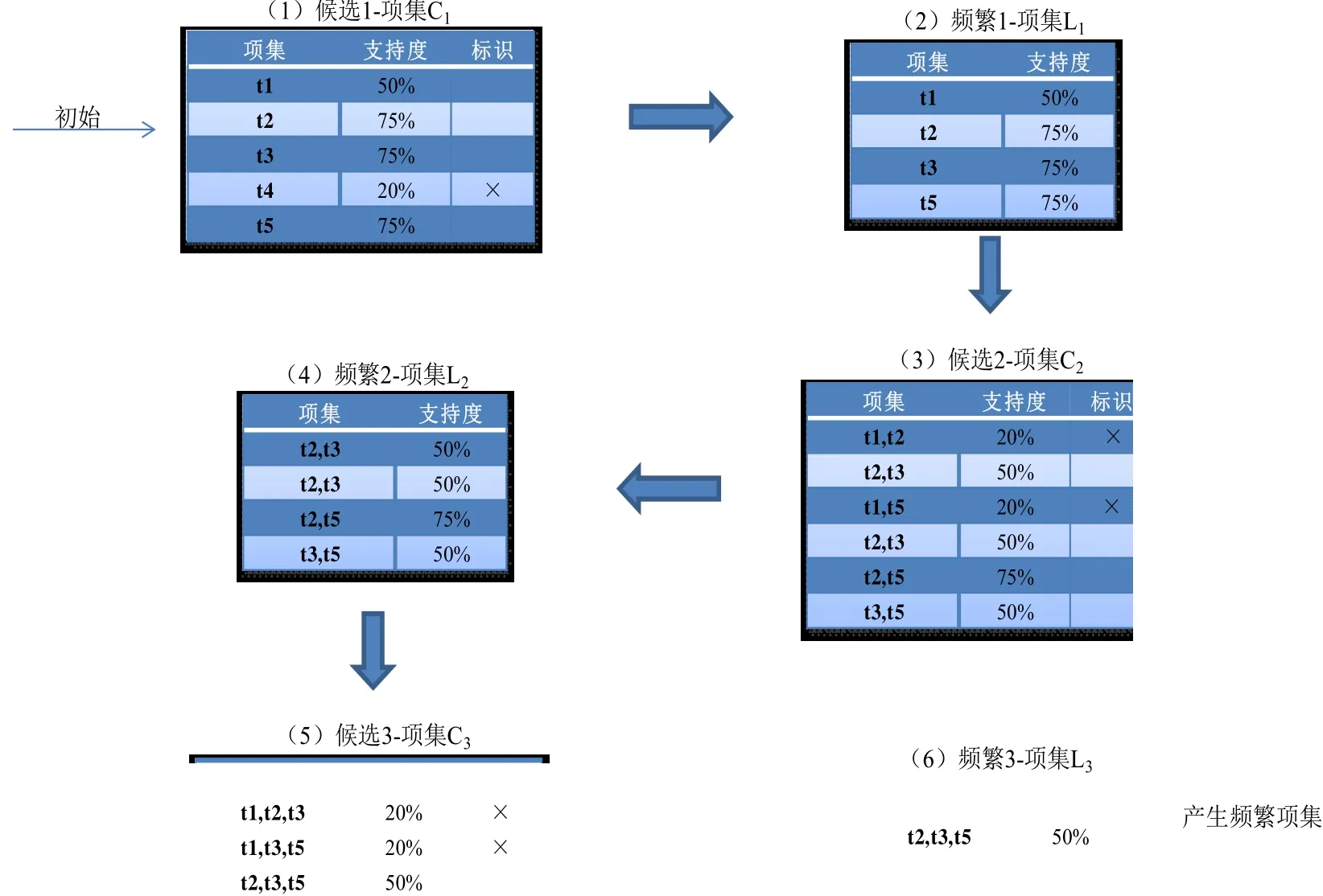
图5 频繁项集的产生Fig.5 Generate frequent itemsets

图6 关联规则的产生Fig.6 Generate association rules

表4 缺陷引发事件的关联规则Tab. 4 Association rules of trriger
[1] Chen Y, Shen X H, Du P, et al. Research on Software Defect Prediction Based on Data Mining[J]. IEEE, 2010, 1∶ 563-567.
[2] 陈翔, 顾庆, 刘望舒, 等. 静态软件缺陷预测方法研究[J].软件学报, 201627(1)∶ 1-25. Chen X, Gu Q, Liu W S, et al. Survey of Static Software Defect Prediction[J]. RuanJianXueBao/Journal of Software,2016, 27(1)∶ 1240-25.(in Chinese)
[3] LAST M, FRIEDMAN M, KANDEL A. The Data Mining Approach to Automated Software Testing[Z]. Washington. USA∶ SIGKDD, 2003.
[4] Song QB, SHEPPERD M, CARTWRIGHT M, et al. Software Defect Association Mining and Defect Correction Effort Prediction[J]. IEEE Computer Society, 2006, 32(2)∶ 69-82.
[5] 张广梅. 软件测试与可靠性评估[D]. 北京∶ 中国科学院计算技术研究所, 2006. ZHANG G M. Research on Software Testing and Reliability Evaluation Method[D]. BeiJing∶ Institute of Computing Technology, Chinese Academy of Sciences, 2006.(in Chinese)
[6] 尹相乐, 马力, 关昕. 软件缺陷分类的研究.计算机工程与设计, 2008, 29(19)∶ 4910-4913. YIN X L, MA L, GUAN X. Research of Software Defects Classification[J]. Computer Engineering and Design. 2008, 29(19)∶ 4910-4913. (in Chinese)
[7] 蔡建平, 王安生, 修佳鹏. 软件测试方法与技术[M]. 北京∶清华大学出版社, 2014. Cai J P, WANG A S, XIU J P. Software Testing Method and Technology[M]. BeiJing∶ Tsinghua University Press, 2014. (in Chinese)
[8] 韦群, 王珏. 软件缺陷及其对软件可靠性的影响分析[J].计算机应用与软件, 2011, 28(1)∶ 145-149. WEI Q, WANG Y. Software Defects and Analysis of its Impact upon Software Reliability[J]. Computer Application and Software. 2011, 28(1)∶ 145-149. (in Chinese)
[9] TAN P N, STEINBACH M, KUMAR V. 数据挖掘导论[M].范明, 范宏建. 北京∶ 人民邮电出版社, 2011. TAN P N, STEINBACH M, KUMAR V. Introduction to Data Mining[M]. FAN M, FAN H J. BeiJing∶ Posts & Telecom Press, 2011. (in Chinese)
[10] 王梦雪. 数据挖掘综述[J]. 软件导刊, 2013, 12(10)∶135-137. WANG M X. a Survey of Data Mining[J]. Software Guide. 2013, 12(10)∶ 135-137. (in Chinese)
Research of Software Defect Analysis Based on Association Rules Mining
YAN Yue-ming
(The 7th Research Institute of China Electronics Technology Group Corporation, Guangzhou 510310, China)
Software testing is an important means to ensure the quality of software products. The target of software testing is to find defects and repair them as much as possible, finally to improve the quality of software. With the continuous accumulation of defect data, it is impossible to perform defect management and analysis artificial way, automatic method is necessary for reasonable and effective use of defect information. Base on the development of software defect management and data mining technology, the author summarized the characteristics of defects in software testing, and puts forward the improved orthogonal defect classification model and defect association analysis model. The application of the above model is explained, which can help the technicians to locate and solve the defects, and to provide the auxiliary means for software testing defect analysis.
Software Testing; Software Defect Analysis; Orthogonal Defects Classification; Association Rules Mining
TP311
A
10.3969/j.issn.1003-6970.2017.01.015
颜乐鸣(1983-),女,工程师,主要研究方向:软件测试,软件工程。
