基于Weka的江苏13个地级市温度聚类分析
2016-12-17孙涛高军晖
孙涛+高军晖

摘 要:该文利用机器学习软件Weka,对江苏13个地级市的温度数据进行聚类分析研究。我们的数据来自中国气象数据网,采用1981—2010年日平均气温。我们在Weka中分别用HierarchicalCluster、SimpleKMeans、Cobweb三种方法按3个簇进行聚类。从三种聚类方法得出的结果来看,第1、2种方法结果更加相近,第3种方法更加细致,导致每个情况各成一类。对照温度聚类的结果和城市之间的空间距离,苏北城市之间的温度互相之间更加靠近,苏中、苏南城市由于处于长江两侧,互相之间温度也更加靠近。
关键词:聚类分析 Weka 城市温度
中图分类号:TP391 文献标识码:A 文章编号:1674-098X(2016)07(c)-0092-03
气温是重要的气候指标,对人类的生产生活状况以及农业生产都有着非常重要的影响,并且在自然科学领域中建立的诸多气候模型中,气温已经成为一个不可或缺的影响因素,因此有关气温空间分布规律的研究一直都是地理、气象、生态等研究和应用领域广泛关注的热点问题之一[1]。影响气温分布的主要因素包括:宏观的地理条件,观测点的海拔高度、地形(坡向、坡度等)、下垫面性质等,其中尤以海拔高度和地形的影响最显著[2]。
聚类分析是数据挖掘的重要研究内容[3,4],是计算机科学中较为前沿的研究方式,因为地理、气象等数据有时间性和空间性并具的特点,所以聚类分析方法在地理数据研究上从传统上的空间聚类发展成带有时间性质的时空聚类,其中代表性的聚类分析方法有基于密度的,有基于层次的,还有基于划分的,比如FCM算法[5,6],在聚类分析与地理结合研究这方面,国外学者如Bilgin T T等对土耳其的气象站每日的温度数据进行了聚类分析,得到趋势相同的温度区域,从而根据土耳其的气温特性进行气象区域划分[7];Moller-Levet等[8]利用模糊c均值聚类算法对短时间序列进行了聚类[9]。
1 数据来源
该文所有数据均来自中国气象数据网[10],使用的温度为1981—2010年日平均气温,单位:℃。
获取数据时,共有9列数据,分别是城市、日序、累年日平均气温、累年平均日最高气温、累年平均日最低气温、累年日平均水汽压、累年20-20时日降水量、累年08-08时日降水量、累年日平均风速。
该文基于平均气温做数据分析,时间是365天,城市为江苏省13所地级市。数据采集时的城市排序为:无锡、苏州、常州、徐州、连云港、盐城、淮安、南京、扬州、泰州、南通、宿迁、镇江。
由于部分地级市数据并未给出,所以,该文中的数据由地理位置最近的相关县级市或区的数据代替,常州数据由金坛代替,宿迁数据由宿豫代替,镇江数据由丹阳代替,南通数据由于本身产生时间分段难以处理,由通州代替。
2 聚类分析介绍
我们这里借用MBA智库百科[11]来描述聚类分析。聚类分析,英文Cluster Analysis,是根据“物以类聚”的道理,对样品或指标进行分类的一种多元统计分析方法。它们讨论的对象是大量的样品,要求能合理地按各自的特性来进行合理的分类,没有任何模式可供参考或依循,即是在没有先验知识的情况下进行的。聚类分析起源于分类学,在古老的分类学中,人们主要依靠经验和专业知识来实现分类,很少利用数学工具进行定量的分类。随着人类科学技术的发展,对分类的要求越来越高,以致有时仅凭经验和专业知识难以确切地进行分类,于是人们逐渐地把数学工具引用到了分类学中,形成了数值分类学,之后又将多元分析的技术引入到数值分类学形成了聚类分析。
聚类是将数据分类到不同的类或者簇的一个过程,所以同一个簇中的对象有很大的相似性,而不同簇间的对象有很大的相异性。聚类分析的目标就是在相似的基础上收集数据来分类。聚类源于很多领域,包括数学、计算机科学、统计学、生物学和经济学。在不同的应用领域,很多聚类技术都得到了发展,这些技术方法被用作描述数据,衡量不同数据源间的相似性,以及把数据源分类到不同的簇中。
聚类分析计算方法主要有如下几种:分裂法(partitioning methods),层次法(hierarchical methods),基于密度的方法(density-based methods),基于网格的方法(grid-basedmethods),基于模型的方法(model-based methods)。
3 数据分析方法
Weka[12]的全名是怀卡托智能分析环境(Waikato Environment for Knowledge Analysis),是一款免费的、非商业化的、基于JAVA环境下开源的机器学习以及数据挖掘软件。Weka作为一个公开的数据挖掘工作平台,集合了大量能承担数据挖掘任务的机器学习算法,包括对数据进行预处理,分类,回归、聚类、关联规则以及在新的交互式界面上的可视化。选择HierarchicalCluster聚类方法,操作流程如下[13]:
加载天气-江苏.csvs数据集,切换到Cluster选项卡,单击Choose按钮,在打开的算法选择对话框中,选择HierarchicalCluster聚类算法。
设置相似度度量方法。单击Choose按钮后面的算法文本框,在设置算法属性对话框中,设置距离函数distanceFu nction为欧氏距离EuclideanDistance,设置num集群nu mClusters为3。
在Cluster mode面板中选择Use training set选项,单击Start按钮执行挖掘,结果如表1所示。
在Result-list(right-click for options)列表中选择本次训练条目,右击,从弹出的快捷菜单中选择Visualize tree命令,打开分层聚类树,如图1所示。
从空间角度看,苏北城市之间的温度互相之间更加靠近,苏中、苏南城市由于处于长江两侧,互相之间温度也更加靠近,靠近太湖的几个城市中,只有苏州市一个离群值,推测有由于苏州的地理位置在长江和太湖之间,以及苏州市内湖泊较多使得温度产生了偏离。
4 讨论
考虑到不同的聚类方法结果可能不一样,我们有必要选择其他的方法进行聚类。
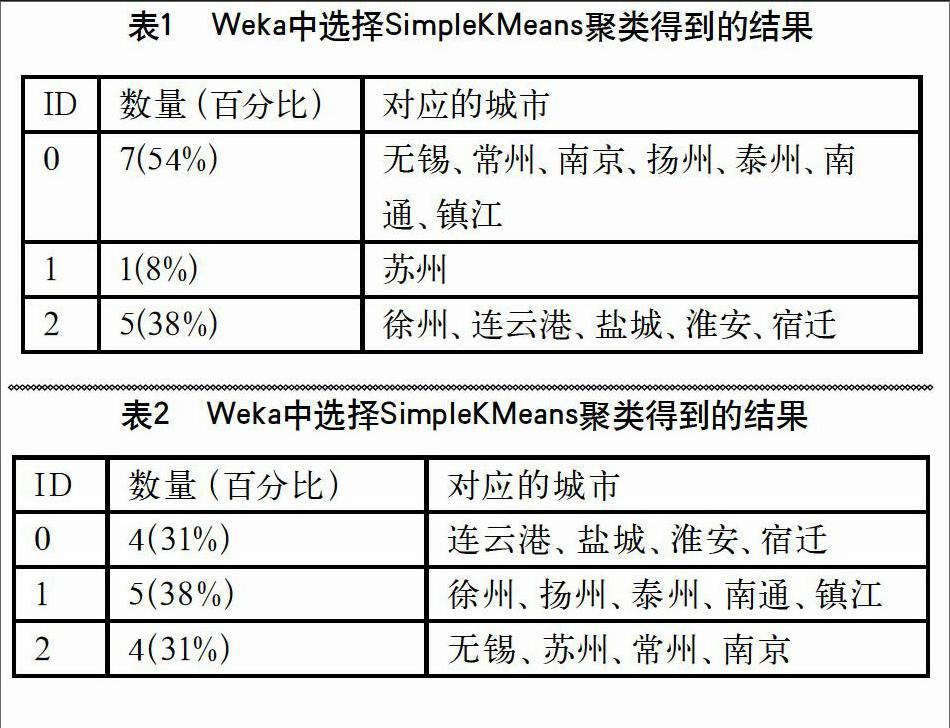
使用Weka中的SimpleKMeans聚类方法。与第1 种方法相比,加入了随机种子,数量为3。其他参数如下: displayDevs:False,distanceFunction:EuclideanDist ance -Rfirst-last,dontReplaceMissingValues: False,maxTterations:500,numClusters:3,preserveInstancesOrder:False。得到的聚类结果如表2所示。
使用Cobweb聚类方法。与第1种方法相比,加入了随机
种子,数量为3。其他参数如下:acuity:1.0,cuteoff:0.002
8209479177387815,saveInstanceData:False。结果与前面两种方法有很大的差别。除了无锡、泰州、南通、镇江4个城市在一个簇里面,其他9个城市分别形成一个簇。图2是对应的聚类树。
从三种聚类方法得出的结论看,第1、2种方法结果更加相近,第3种方法更加细致,导致每个情况各成一类。
5 结语
该文利用机器学习软件Weka,对江苏13个地级市的温度数据进行聚类分析研究。
首先回顾了其他学者对气候数据进行聚类分析的工作,接着,我们分别描述了数据来源和聚类分析的原理。在数据分析部分,我们用HierarchicalCluster进行聚类分析,指定3个簇。得到的结果是无锡、常州、南京、扬州、泰州、南通、镇江7个城市在一个簇里面,徐州、连云港、盐城、淮安、宿迁5个城市在一个簇里面,苏州单独在一个簇里面。
考虑到不同的聚类方法结果可能不一样,我们在讨论部分还利用SimpleKMeans、Cobweb两种方法对同样的数据进行聚类。我们发现第1、2种方法结果更加相近,第3种方法更加细致,导致每个情况各成一类。
对照温度聚类的结果和城市之间的空间距离,苏北城市之间的温度互相之间更加靠近,苏中、苏南城市由于处于长江两侧,互相之间温度也更加靠近。
参考文献
[1] 曾燕,邱新法,何永健,等.复杂地形下黄河流域平均气温分布式模拟[J].中国科学,2009,39(6):774-786.
[2] 袁淑杰,谷晓平,廖启龙,等,贵州高原复杂地形下月平均日最高气温分布式模拟[J].地理学报,2009,64(7):888-896.
[3] 冯立娟.基于Web数据挖掘的推荐系统算法研究[D].河北:河北工程大学,2014.
[4] 屈家安,曹杰.主成分分析与聚类分析在青岛夏季气温变化研究中的应用[J].大气科学学报,2014,37(4):517-520.
[5] Dunn J.C.Well-separated clusters and the optimal fuzzy partitions[J].Cybernet,1974(4):95-105.
[6] Bezdek J.C.Pattern recognition with fuzzy objective function algorithns[J].Plenum Press,1981,22(1171):203-209.
[7] Bilgin T T,Camuren A Y.A Data Ming Application on Air Temperature DataBase[J].Lecture Notes in Computer Science,2005(3261):68-76.
[8] C S Moller levet,F Klawonn,KH Cho,et al.Fuzzy clustering of short time-series and unevenly distributed sampling points[C]//Proceedings of the 5th International Symposium on Intelligent Data Analysis.2003.
[9] 谢娟英,蒋帅,王春霞,等.一种改进的全局K-均值聚类算法[J].陕西师范大学学报:自然科学版,2010,38(2):18-22.
[10] 聚类分析[EB/OL].http://wiki.mbalia.com/wiki/.
[11] 气候数据源:http://data.cma.cn/.
[12] Weka 3:Date Mining Software in Java [EB/OL].http://www.cs.waikato.ac.nz/ml/weka/.
[13] 戴红,常子冠,于宁.数据挖掘导论[M].清华大学出版社,2015.
