基于改进遗传算法的支持向量机微信垃圾文章识别
2016-03-25梁阔洋�k
梁阔洋�k


摘要:近几年,随着微信的快速发展和普及,微信已经成为智能移动设备必备的应用之一,但与之同时也出现了大量微信诈骗信息、垃圾广告等,给人们带来了极大的困扰。本文将从搜狗微信搜索中抽取微信文章样本,将微信垃圾文章识别看做文本分类问题,采用支持向量机对样本进行分类模型的训练,并应用改进的遗传算法对支持向量机的参数进行优化。文中详细的介绍了改进遗传算法在支持向量机上的应用,相比传统的支持向量机,采用改进遗传算法对支持向量机参数进行优化,提升了模型准确率和优化效率。在文章的最后进行了由15000篇微信文章所形成的测试集上的分类模型效果实验,实现结果表明,本方法能够达到94.7%的准确率,非常准确的识别微信垃圾文章。
关键词:支持向量机;遗传算法;特征选择;参数优化;垃圾文章
中图分类号:TP391.1文献标识码:A
1引言
随着微信应用的快速发展和普及,微信已经成为移动智能设备中必备的应用之一,与之同时也出现了大量微信诈骗信息,垃圾广告等垃圾文章。这些信息不仅浪费了用户的带宽和时间,同时也对互联网的安全构成了较大的威胁。因此如何识别此类微信文章显得格外重要。
传统的解决方案为黑名单方法,黑名单方法收集发表垃圾文章的用户,将用户ID加入垃圾用户黑名单列表。但由于微信用户量大、并且增长速度快、黑名单方法不仅实施周期长,并且工作量大。
微信垃圾文章识别的过程可视为一个文本分类的过程,对于文本分类问题,样本经过特征选择后,每一个样本被当做一个n维特征向量空间中的向量、作为机器学习算法的输入。常用的机器学习方法有:K-近邻(K-Near Neighbor)[1]、朴素贝叶斯(Na
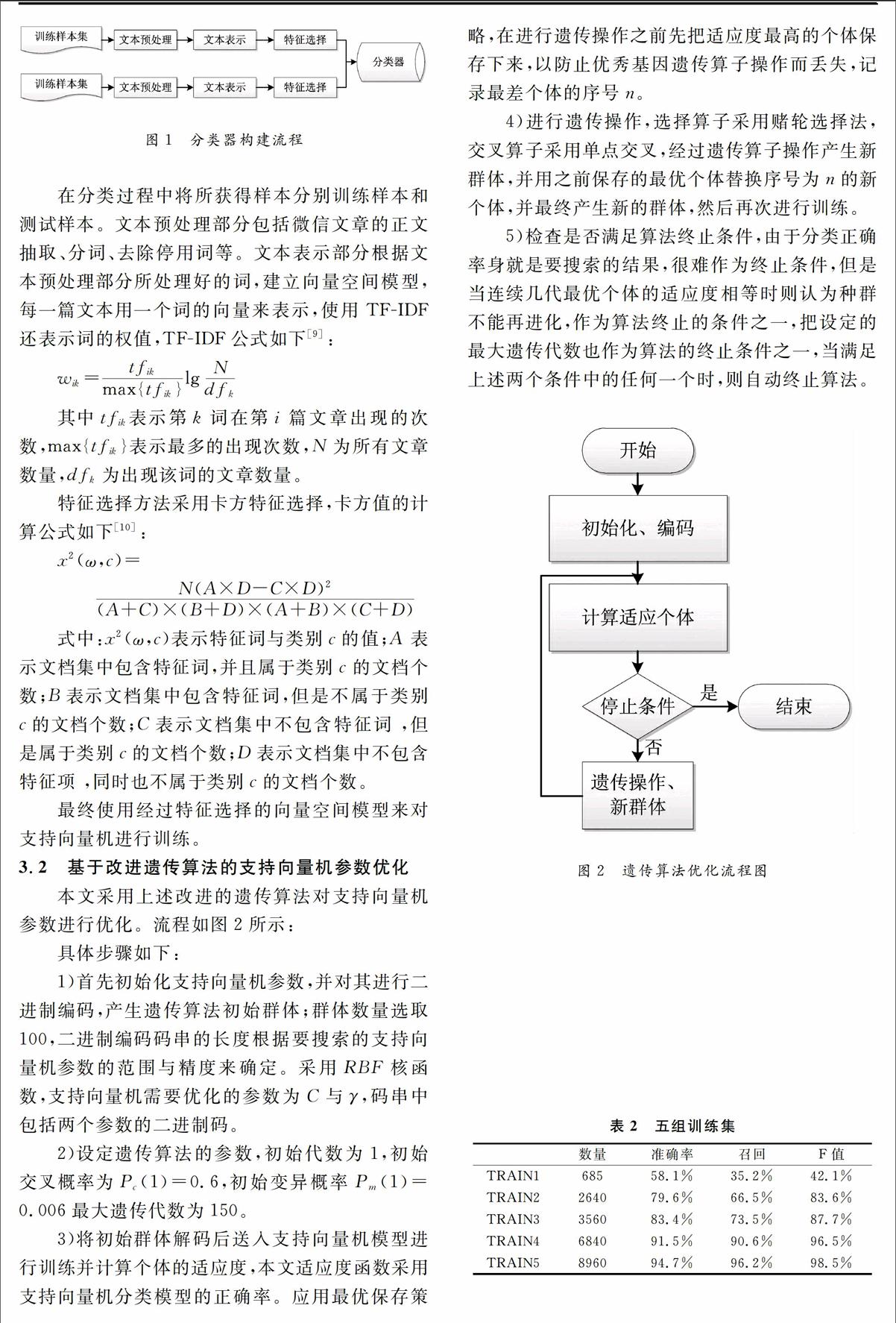
4实验结果
实验数据来源于搜狗微信搜索数据源,实验共选取了5组训练集,和2组测试集。
第一,采用不同数量的训练集对模型进行训练,记录模型训练的准确率、召回率、F值,如表2:
通过对不同数量的训练集对模型进行训练,可以看出,当采用TRAIN1,数量为685对模型进行训练,准确率、召回率、F值非常低,随着训练样本的增多,准确率、召回率、F值的提升非常快,这说明训练样本数量对模型整体的训练效果有非常大的影响。
采用TRAIN5所训练的模型,进行3组不同数量测试上的实验,几率其准确率、召回率、F值,如表3:
从上表可以看出,使用同一训练集,准确性稍有升高,幅度不大,表明模型是相当稳定的。召回率与F值稍有下降,说明训练集中并没有覆盖所有实际情况,某些特殊实例没有被包含进来。
从上面两组实验结果可以得到,基于改进遗传算法的支持向量机微信垃圾文章识别,对于搜狗微信搜索数据源具有良好的效果,其实验结果有益于后续研究的继续进行。训练所得模型的准确率、召回率、F值能够满足实际应用的需求。
5结论与展望
本文采用支持向量机对微信文章垃圾文章进行识别,并应用改进的遗传算法对支持向量机进行参数优化,最终得到最优的参数组合,从了得到了能够进行良好分类的分类器。今后的主要工作集中在优化特征选择,对某些重要特征进行加权处理,并考虑平衡数据和费平衡数据对分类器训练效果的影响,使得分类的准确率、召回率、F值获得更大程度的提高。
参考文献
[1]ANDROUTSPOULOS I,PALIOURAS G,KARKALETSIS V,et al. Learning to filter spam email: A Comparison of a Naive Bayesian and a MemoryBased Approach[C].Proceedings of the workshop on machine learning and textual information access, 4th European conference on principles and practice of knowledge discovery in databases. Lyon, France: [sn.].2000:1-13
[2]ANDROUTSOPOULOS I,KOUTSIAS J,CHANDRINOS K, et al. An evaluation of nave Bayesian antispam filtering[C].Proceedings of the 11th European conference on machine learning.Barcelona, Spain:[sn.].2000:9-17.
[3]CARRERAS X,MARQUEZ L. Boosting trees for antispam email filtering[C].The Forth International Conference on Recent Advances in Natural Language Processing. Bulgaria: Tzigov Chark.2001:58-64.
[4]CORTES C,VAPNIK V. Support vector networks[J].Machine Learning.1995,20(1):273 –329.
[5]平源. 基于支持向量机的聚类及文本分类研究[D].北京:北京邮电大学,2012.
[6]KUBAT T M,MATWIN S. Addressing the Curse of Imbalanced Training Sets: OneSide Selection[C]. Proceedings of the 14th International Conference on Machine Learning. USA: Nashville.1997:217-225.)
[7]李人厚.智能控制理论和方法[M].陕西:西安电子科技大学出版社,2005.
[8]杨淑莹,著.模式识别与智能计算—— Matlab技术实现[M].北京:电子工业出版社,2008..
[9]施聪莺,徐朝军,杨晓江. TFIDF算法研究综述[J]. 计算机应用,2009,S1:167-170+180.
[10]DASH M, LIU H. Feature Selection for Classification[J]. Intelligent Data Analysis, 1997, 1(3): 131-156.
