基于图形处理器的伪谱和高阶有限差分混合方法地震波数值模拟*
2015-12-17崔丛越张献兵王彦宾
崔丛越 张献兵 王彦宾
(中国北京100871北京大学地球与空间科学学院)
引言
地震波传播数值计算是地震学中的重要研究领域,在理解复杂地球介质中的地震波传播过程、地震波反演以及强震地面运动计算等方面起着重要作用.随着地震学研究的不断发展,对地球内部横向非均匀性、复杂界面形态分布等复杂结构的认识不断精细化,精确高效的数值方法是求解复杂介质中地震波传播颇为有效的手段之一.
常用的地震波传播数值模拟方法包括有限差分法、伪谱法、有限元法等.对于大规模二维模型或三维模型,随着对地震波场模拟的精度要求不断提高,通常需要大量的计算机内存和计算时间,为了提高计算效率,需要利用并行计算环境来实现.常见的并行计算机架构有对称多处理结构(symmetric multi-processing,简写为SMP)、大规模并行处理计算机(massive parallel processing,简写为MPP)、机群(cluster)等,软件层面多采用信息传递接口(message passing interface,简写为MPI).很多研究人员充分利用有限差分算子易于并行的特性,开发了基于机群的地震波场并行有限差分模拟方法(王德利等,2007;张明财等,2013),同时适宜于机群的有限元、伪谱法等并行技术也得以开发(Furumura et al,1998;王月英,孙成禹,2006;严九鹏,王彦宾,2008).
相比于CPU,基于图形处理器(graphic processing unit,简写为GPU)的通用计算技术(general purpose GPU,简写为GPGPU)起步较晚.早期的GPGPU直接使用图形开发接口,将计算任务映射为纹理渲染.该方法编程困难,应用范围狭窄,实用价值有限.2006年,英伟达(NVIDIA)公司推出了统一计算设备架构(compute unified device architecture,简写为CUDA)平台,极大地降低了编程难度,拓宽了应用范围,使GPGPU被广泛接受.由于GPU天然的并行性,CUDA在金融、影像处理、天文学、地球物理学等领域都有显著的优势,近年来在地震波场模拟领域的应用越来越广泛.龙桂华等(2010)实现了基于CUDA的傅里叶伪谱微分矩阵算子的加速,获得约200倍的加速比;Cai等(2012)利用CUDA实现了3D交错网格有限差分法加速,取得60—80倍的加速比;单蕊和朱伟(2013)尝试了基于GPU并行的谱元法地震波场模拟;郑亮等(2013)实现了基于GPU的三维有限单元地震波传播模拟;Okamoto等(2010)和Aoi等(2012)实现了基于多个GPU的三维有限差分领域的分解算法,Okamoto等(2012)将其应用于2011年日本东北地震的波场传播计算.
在地震波传播数值计算方法中,由于空间微分算子的局部特性,有限差分方法并行程度高;而傅里叶伪谱微分算子精度高,但是由于其全局特性,并行程度较低.魏星等(2010)给出了基于有限差分与伪谱的混合方法,即水平方向使用交错网格傅里叶伪谱法,垂直方向使用交错网格4阶有限差分法,有效利用了两种方法各自的优点.秦艳芳和王彦宾(2012)将其推广至三维模型并实现了基于机群的并行计算.
由于傅立叶微分算子的全局性,以往通过MPI实现的并行混合方法只能对垂直方向的有限差分法进行并行计算,性能提升较有限.因此,本文尝试使用GPU实现这一过程,
利用CUDA平台的cuFFT库使得水平方向也能利用伪谱法进行并行计算.
1 基本原理
1.1 交错网格混合方法
二维各向同性弹性介质中P-SV波的波动方程为
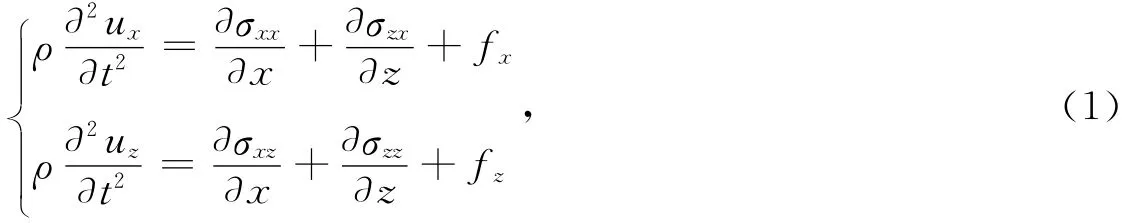
本构关系为
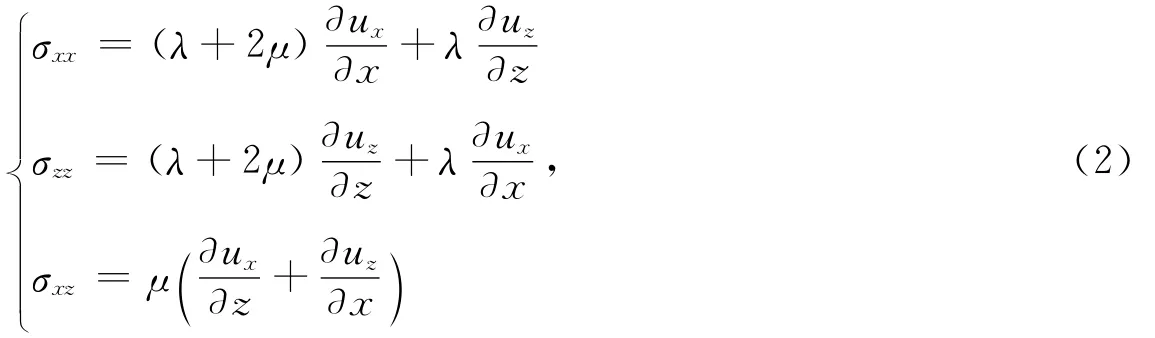
式中,ux和uz分别为水平和垂直分量位移;fx和fz分别为x和z方向的体力;σxx,σzz和σxz为应力分量;ρ为密度,λ为拉梅常数,μ为剪切模量.
按照图1所示进行网格划分.对于实际地球模型介质而言,其参数垂直方向变化较剧烈,因此在垂直方向采用4阶精度交错网格有限差分法,水平方向采用交错网格伪谱法.对于有限差分法,交错网格可在计算量相当的情况下提高其计算精度;而对于伪谱法,交错网格可有效地减小由于傅里叶变换和介质性质急剧变化所造成的噪声(魏星等,2010).
交错网格伪谱法的微分公式为(秦艳芳,王彦宾,2012)
图1 混合方法网格划分Fig.1 Arrangement of the staggered grids
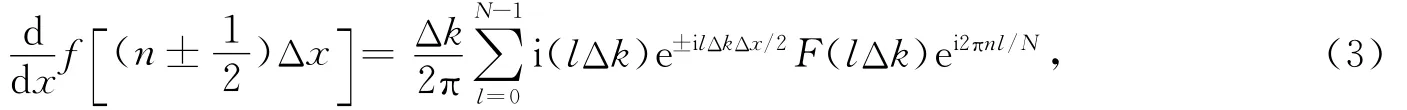
其中
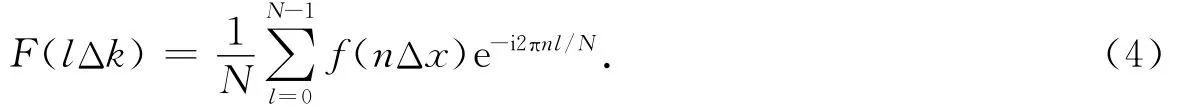
4阶精度交错网格有限差分法的内部节点计算公式为(秦艳芳,王彦宾,2012)
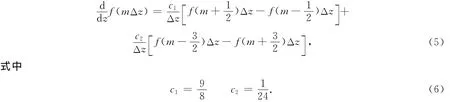
自由地表条件通过满足牵引力为零的条件来实现,模型的两侧和下部的人工边界采用以下吸收边界条件(Cerjan et al,1985):
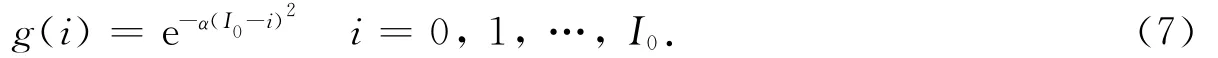
根据离散模型中的最小网格间距Δmin和最大波速vmax,垂直方向的有限差分法网格划分要求(Daudt et al,1989)

水平方向的傅里叶伪谱法网格划分要求(Kosloff,Baysal,1982)

且Δt只有小于最低限定条件才能保证解的稳定.
1.2 CUDA编程模型
本文所用的程序均采用CUDA C开发.CUDA C是基于标准C语言的扩展,使用NVCC编译器进行编译,兼容大部分NVIDIA显卡.在GPU上运行的函数称为内核函数(kernel),一个内核函数以线程块(block)为执行单位,不同线程块间并发执行,但不能通信.每个线程块中有一块共享存储器,可被线程块中的所有线程访问.同一线程块中的线程可通过同步函数保证执行顺序.图2给出了一个CUDA程序中线程块与线程的层级关系.
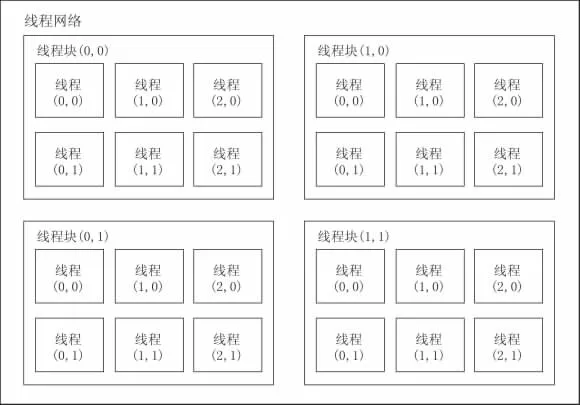
图2 CUDA程序中的线程结构Fig.2 Arrangement of threads in CUDA
内核函数运行的过程中,线程块被分为更小的线程束(warp)来执行,线程束包含的线程数量由硬件决定,目前均为32.线程束的前一半线程或后一半线程组成半线程束(halfwarp).共享存储器被分为不同的存储模块(bank),每个存储器有16或32个存储模块,每个存储模块无法在同一时间响应多个请求.若位于同一半线程束的线程同时请求访问一个存储模块中的不同地址,则会产生存储体冲突(bank-conflict),对不同地址的请求只能被串行完成,严重降低访问速度.因此,需要保证同一半线程束的线程在同一时间访问的地址相同,或位于不同的存储模块.
除了算法优化,CUDA程序的主要性能瓶颈出现在显存和内存间的带宽上.GPU并行程度足够高的程序才能弥补两者数据传输所造成的延迟,而一个内核函数中调用的线程块和线程的数量均有一定的限制.本文的测试环境中,线程块的数量上限远大于所需值,可忽略线程块的数量限制,每个线程块最多可有1 024个线程.
1.3 统一内存
统一内存是cuda 6.0引入的新特性,它可以通过cudaMallocManaged函数开辟受管理的内存,通过单一指针接受来自CPU与GPU的访问.由于内存和显存彼此独立,GPU程序必须分别在CPU和GPU开辟存储空间,而且在调用GPU函数前需将内存数据复制到显存,并在GPU执行完成后将数据复制回来.统一内存通过一个单一指针避免了这个繁琐的过程(图3).目前的显卡硬件中,统一内存本质上是将手动复制数据的操作自动化,而下一代的麦克斯韦(Maxwell)架构显卡将通过在硬件层面上引入统一虚拟内存,从而进一步提升性能.
与手动内存管理相比,统一内存主要有以下两大优点:

图3 统一内存示意图Fig.3 Skematic diagram of unified memory
1)降低编程难度,方便移植现有程序.统一内存使得GPU程序不需要引入额外变量,从而可以使原有C程序的代码基本保持不变;而手动管理内存至少要引用一个额外的变量,在多维数据等情况下还要引入更多,这使得函数的参数形式和写法均需进行较大调整.特别是在使用链表等复杂数据结构的情况下,内存与显存之间的复制会变得非常麻烦,而统一内存可以避免该问题,减小工作量和降低出错概率.
2)提升数据传输性能.统一内存会按需在内存与显存间转移数据,通过一系列复杂的算法尽量多地利用带宽,通常情况下效率会高于未经优化的手动管理内存的程序.同时,统一内存仍然支持直接开辟显存与异步内存传输,从而满足对性能要求更高的程序,在降低编程难度的同时并未牺牲灵活性.
1.4 cuFFT库
混合方法在水平方向采用傅里叶伪谱法计算空间微分,因此需要用到快速傅里叶变换.cuFFT库是CUDA自带的快速傅里叶变换函数库,与串行傅里叶变换相比加速比可达10倍(NVIDIA,2014).cuFFT库包括cuFFT和cuFFTW两个子库,其中cuFFT子库提供了较高的计算效率,而cuFFTW子库为移植使用C语言中快速傅里叶变换库的现有程序提供了方便.cuFFT库为不同规模的输入提供高度优化的算法,可以选择单精度或双精度,支持批量变换.
cuFFT库将傅里叶变换分为3大类:复数域→复数域(C2C),实数域→复数域(R2C),复数域→实数域(C2R).当输入数据为实数域的采样点时,输出数据满足Xk=X*N-K,选择以R2C的方式进行变换可利用此对称性,将计算量降至最低.
调用cuFFT库的一般步骤为:
1)利用cufftPlan1D/cufftPlan2D/cufftPlan3D创建一维、二维或三维变换计划,或利用cufftPlayMany函数创建一个批量变换计划;
2)根据变换类型,调用cufftExecC2C,cufftExecR2C或cufftExecC2R函数执行变换;
3)调用cufftDestroy函数销毁计划,释放资源.
2 计算流程实现
2.1 混合方法计算步骤
GPU程序的并行部分直接影响执行效率,因此要尽可能将相互独立的计算步骤放到GPU中执行,同时将并行执行效率低的部分交给CPU执行.其中,微分、应力及位移的计算部分由GPU完成,数据导入导出和循环控制部分由CPU完成.设水平方向网格数为m,垂直方向网格数为n,线程块数与每个线程块中线程数的比值为x,求解方程(1)、(2)的具体步骤如下:
1)开辟内存、显存,读取数据并使之初始化;
2)利用傅里叶伪谱法求出∂ux/∂x和∂uy/∂x;
3)利用有限差分法求出∂ux/∂y和∂uy/∂y;
4)根据式(2)求出σxx,σxy和σyy;
5)利用傅里叶伪谱法求出∂σxx/∂x和∂σxy/∂x;
6)利用有限差分法求出∂σxy/∂y和∂σyy/∂y;
7)利用式(1)计算ux和uy.
2.2 边界条件
式(7)中取α=0.015,I0=20.由于垂直方向采用有限差分法,无需对自由表面进行处理.计算得到大小为m×n的系数数组,由于其被多次使用且在计算过程中保持不变,适合将其放入纹理存储器.同样适合放入纹理存储器的数据还有密度等介质参数.
2.3 有限差分法
有限差分法对两个方向求空间微分在同一内核函数并行执行,调用的线程块数为2mx,线程数为n/x.根据实际测试,取x=m/64时计算效率最高.实现方式与串行代码完全类似,只需将循环改为分配给不同的线程,线程的编号与循环中的步数一一对应.运行完成后需执行一次cudaDeviceSynchronize函数,将显存中的数据同步至内存.
2.4 傅里叶伪谱法
计算中需要对2n个数组进行傅里叶正变换和反变换,可用cufftPlanMany函数创建计划批量进行.由于输入的数据均为实数,理论上正变换采用R2C类型计算效率较高,但R2C必须开辟一个实数和一个复数共两个数组.由于cuFFT支持就地变换(变换后的结果直接保存在原数组),使用C2C类型只需开辟一个复数数组.因此,在显存比较有限的情况下,使用C2C类型效率反而略高.
3 计算效率测试分析
为了测试上述流程的计算效率,本文采用二维均匀介质模型,对比CPU与GPU版本的运行时间.运行时间以循环开始作为起点,不计入数据读取、初始化及导出的时间.测试环境如表1所示.使用clock函数计量时间,波动一般在1%以内.
CPU与GPU的运行结果如表2所示,图4给出了加速比与网格数的关系.通过测试可见,使用GPU可取得明显的加速效果.随着网格数的增加,并行程度提高,加速也有明显的增加.但由于显存的限制,增幅会逐渐减缓.

表1 测试环境Table 1 Test environment

表2 计算耗时表Table 2 Elapsed time
4 应用实例
为了验证本文所给出的GPU并行方法的有效性,我们选取兰州盆地的一个二维剖面,计算点源激发的地震波在其中的传播过程.兰州盆地模型引自严武建等(2013),沉积盆地上部包含一个深度达393m的第四纪沉积层和一个深度达3.0km的第三系沉积层,底部为上地壳.模型宽70km,深35km.震源为双力偶点源,矩张量分量Mxx=1.0×1012N·m,Mzz=-1.0×1012N·m.网络总数为2 048×1 024,水平和垂直方向的网格大小均为34.2m.震源时间函数的宽度为0.1s,时间间隔为0.001s,共计算3万时间步.
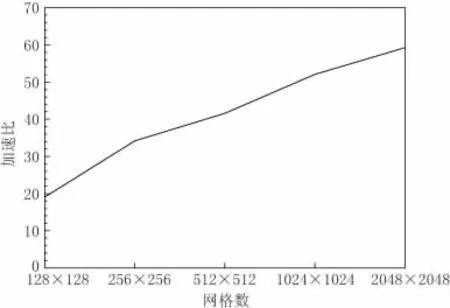
图4 不同网格数的加速比Fig.4 Speedup in various number of grids
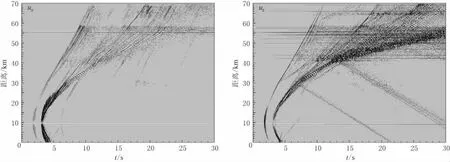
图5 兰州盆地模型地表水平分量ux和垂直分量uz的合成地震图Fig.5 Horizontal and vertical component of synthetic waveforms in Lanzhou basin model
图5 给出了地表垂直分量和水平分量的地震图.基岩地表的震相简单,可以看到直达P、SV波和上地壳底部的反射波.当直达波传播进入沉积盆地时,在30km距离上开始看到直达波及其在盆地边界上产生的转换波,同时可以看到由这些波相干叠加而形成的面波,其振幅大于直达波和转换波.当波传播到低速的第四系沉积层时,在其边界上又产生各种波的透射与转换,使得低速层内的波场比第三系沉积层更为复杂,最终形成振幅更大的面波.图6给出了4,8,10,14,22和30s的波场快照,可以看出P波和SV波在基岩中的传播、盆地边界所发生的震相转换以及面波的形成过程.
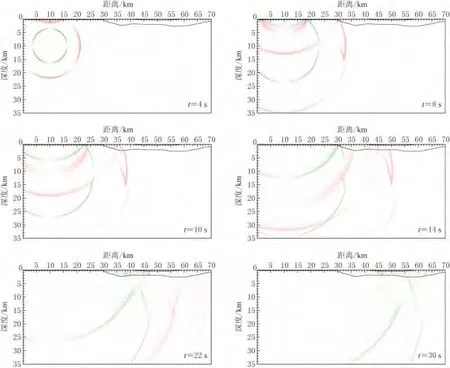
图6 不同时刻时地震波传播的波场快照.图中红色和绿色分别表示P和SV波Fig.6 Wavefield snapshots at t=4,8,10,14,22,30s,where red and green represent P and SV waves,respectively
由上述结果可以看出,低速沉积盆地造成了地震波明显的放大效应;由于各种震相的相干叠加以及边缘面波的作用,盆地内地震波的振幅会增大,地震波传播的持续时间会变长.这些模拟结果与严武建等(2013)的结果完全一致,从另一方面说明了本文的GPU并行模拟方法在实际应用中的可行性.
5 讨论与结论
有限差分/伪谱混合方法结合了有限差分和伪谱两种方法的优点,保持了较高的计算精度,是计算二维非均匀介质地震波传播的有效方法.同时,该方法能够有效处理自由表面及垂直方向的不连续面.由于水平方向与垂直方向的计算相对独立,混合方法可以较容易地推广至三维,扩展其应用范围.本文实现了该混合方法的GPU编程,显著提高了计算速度.实际算例表明,在处理好显存上限的前提下,基于GPU的混合方法程序可完全替代其CPU版本.随着显卡硬件的发展与开发工具的不断完善,基于GPU的模拟程序将越来越普遍.
由于cuFFT库的局限性,目前傅里叶变换只能从CPU中调用,因此与纯有限差分或纯伪谱法相比,混合方法增加了额外的内存拷贝时间,也无法实现伪谱与有限差分并行执行.不过NVIDIA公司已在开发支持从内核函数调用的cuFFT版本,所以此问题有望解决.
在利用混合方法计算三维模型时,单个GPU的性能和显存很难满足计算需求.因此可考虑采用MPI/CUDA混合方法,根据显存大小或线程块数量限制,沿垂直方向将模型分成多个区域,在GPU集群上进行计算.在MVAPICH等支持CUDA的MPI环境中,可以直接发送和接收GPU数据,从而方便高效地完成计算.在三维问题中,数据拷贝带来的延迟影响将更加突出,因此优化数据结构,并且更精细地控制内存与显存之间的传输将是本文所用程序亟需改进的地方.
龙桂华,李小凡,江东辉.2010.基于交错网格Fourier伪谱微分矩阵算子的地震波场模拟GPU加速方案[J].地球物理学报,53(12):2964-2971.
Long G H,Li X F,Jiang D H.2010.Accelerating seismic modeling with staggered-grid Fourier pseudo-spectral differentiation matrix operator method on graphics processing unit[J].Chinese Journal of Geophysics,53(12):2964-2971(in Chinese).
秦艳芳,王彦宾.2012.地震波传播的三维伪谱和高阶有限差分混合方法并行模拟[J].地震学报,34(2):147-156.
Qin Y F,Wang Y B.2012.Three-dimensional parallel hybrid PSM/FDM simulation of seismic wave propagation[J].Acta Seismologica Sinica,34(2):147-156(in Chinese).
单蕊,朱伟.2013.基于GPU并行的谱元法地震波数值模拟[J].中国煤炭地质,25(3):52-54,62.
Shan R,Zhu W.2013.Parallel SEM seismic wave simulation based on GPU[J].Coal Geology of China,25(3):52-54,62(in Chinese).
王德利,雍运动,韩立国,廉玉广.2007.三维粘弹介质地震波场有限差分并行模拟[J].西北地震学报,29(1):30-34.
Wang D L,Yong Y D,Han L G,Lian Y G.2007.Parallel simulation of finite difference for seismic wavefield modeling in 3-D viscoelastic media[J].Northwestern Seismological Journal,29(1):30-34(in Chinese).
王月英,孙成禹.2006.弹性波动方程数值解的有限元并行算法[J].中国石油大学学报:自然科学版,30(5):27-30.
Wang Y Y,Sun C Y.2006.Finite element parallel algorithm for numerical solution of elastic wave equation[J].Journal of China University of Petroleum,30(5):27-30(in Chinese).
魏星,王彦宾,陈晓非.2010.模拟地震波场的伪谱和高阶有限差分混合方法[J].地震学报,32(4):392-400.
Wei X,Wang Y B,Chen X F.2010.Hybrid PSM/FDM method for seismic wavefield simulation[J].Acta Seismologica Sinica,32(4):392-400(in Chinese).
严九鹏,王彦宾.2008.重叠区域伪谱法计算非均匀地球介质地震波传播[J].地震学报,30(1):47-58.
Yan J P,Wang Y B.2008.Modeling seismic wave propagation in heterogeneous medium using overlap domain pseudospectral method[J].Acta Seismologica Sinica,30(1):47-58(in Chinese).
严武建,王彦宾,石玉成.2013.基于伪谱和有限差分混合方法的兰州盆地强地面运动二维数值模拟[J].地震工程学报,35(2):302-310.
Yan W J,Wang Y B,Shi Y C.2013.2Dsimulation of the strong ground motion in Lanzhou basin with hybrid PSM/FDM method[J].China Earthquake Engineering Journal,35(2):302-310(in Chinese).
张明财,熊章强,张大洲.2013.基于 MPI的三维瑞雷面波有限差分并行模拟[J].石油物探,52(4):354-362.
Zhang M C,Xiong Z Q,Zhang D Z.2013.3Dfinite difference parallel simulation of Rayleigh wave based on message passing interface[J].Geophysical Prospecting for Petroleum,52(4):354-362(in Chinese).
郑亮,张怀,尹凤玲,石耀霖.2013.基于GPU的大规模三维地震波传播有限元程序实现[C]∥中国地球物理2013:第七分会场论文集.昆明,2013年10月13日.
Zheng L,Zhang H,Yin F L,Shi Y L.2013.Finite element program implementation of large scale seismic wave propagation modeling based on GPU[C]∥Chinese Geophysics 2013:Proceedings of the 7th Branch.Kunming,October 13,2013.
Aoi S,Nishizawa N,Aoki T.2012.Large scale simulation of seismic wave propagation using GPGPU[C]∥15th World Conference on Earthquake Engineering.Lisbon,Portugal,September 24to 28,2012.
Cai C,Chen H Q,Deng Z,Chen D,Khan S U,Zeng K,Wu M X.2012.GPGPU-aided 3Dstaggered-grid finite-difference seismic wave modeling[C/OL]∥12th International Conference on Scalable Computing and Communications(ScalCom).[2014-05-12].http:∥newtheme.hgpu.org/?p=8610.
Cerjan C,Kosloff D,Kosloff R,Reshef M.1985.A nonreflecting boundary condition for discrete acoustic and elastic wave equations[J].Geophysics,50(4):705-708.
Daudt C R,Braille L W,Nowack R L,Chiang C S.1989.A comparison of finite-difference and Fourier method calculations of synthetic seismograms[J].Bull Seismol Soc Am,79(4):1210-1230.
Furumura T,Kennett B L N,Takenaka H.1998.Parallel 3-D pseudospectral simulation of seismic wave propagation[J].Geophysics,63(1):279-288.
Kosloff D,Baysal E.1982.Forward modeling by a Fourier method[J].Geophysics,47(10):1402-1412.
NVIDIA.2014.CUFFTLibraryUser’s Guide[M/OL].[2014-04-26].http:∥docs.nvidia.com/cuda/cufft/.
Okamoto T,Takenaka H,Nakamura T,Aoki T.2010.Accelerating large-scale simulation of seismic wave propagation by multi-GPUs and three-dimensional domain decomposition[J].Earth Planets Space,62(12):939-942.
Okamoto T,Takenaka H,Nakamura T,Aoki T.2012.Large-scale simulation of seismic wave propagation of the 2011 Tohoku-Oki M9earthquake[C]∥Proceedings of the International Symposium on Engineering Lessons Learned from the 2011 Great East Japan Earthquake.Tokyo:Japan Association for Earthquake Engineering:349-360.
