基于最小方差的自适应K-均值初始化方法
2015-10-12肖洋李平王鹏邱宁佳
肖洋,李平,王鹏,邱宁佳
(长春理工大学 计算机科学技术学院,长春 130022)
基于最小方差的自适应K-均值初始化方法
肖洋,李平,王鹏,邱宁佳
(长春理工大学计算机科学技术学院,长春130022)
K-均值算法对初始聚类中心敏感,聚类结果随不同初始聚类中心波动。针对以上问题,提出一种基于最小方差的自适应K-均值初始化方法,使初始聚类中心分布在K个不同样本密集区域,聚类结果收敛到全局最优。首先,根据样本空间分布信息,计算样本方差得到样本紧密度信息,并基于样本紧密度选出满足条件的候选初始聚类中心;然后,对候选初始聚类中心进行处理,筛选出K个初始聚类中心。实验证明,算法具有较高的聚类性能,对噪声和孤立点具有较好的鲁棒性,且适合对大规模数据集聚类。
聚类;K-均值;方差;初始聚类中心
数据挖掘(Data Mining)就是从大量数据中获取有效的、新颖的、潜在有用的、最终可理解的模式的非平凡过程。数据挖掘的主要方法有分类、聚类、关联分析、回归分析等。其中聚类分析[1-3]在数据挖掘领域的应用最为广泛。聚类是一种无监督的机器学习算法,通过获取数据的内在属性,实现对数据的分类或压缩,使得同一类中的对象之间具有较高的相似性,不同类中的对象之间具有较高的相异性。聚类分析广泛应用于许多研究领域,如模式识别、数据挖掘、图像处理、市场研究、数据分析等。对于不同的问题和用户,国内外学者研究出许多具有代表性的聚类算法,大致分为基于层次的方法、基于划分的方法、基于网格的方法、基于密度的方法等。
K-均值是基于划分方法的代表算法,算法思想简单,易于实现,其实现版本广泛应用于数据挖掘工具包中,应用范围广泛。可以通过修改初始化、相似性度量、算法终止条件等部分适应新的应用环境。算法使用欧式距离度量数据对象间的相似性,对噪声和孤立点比较敏感,使得K-均值算法中需要添加去除噪声的步骤,增加了算法的复杂性。算法对初始聚类中心特别敏感,选取不同的初始聚类中心,会使算法很大程度上收敛到不同的聚类结果。如果选取较好的初始聚类中心,按照Forgy方法进行初始划分,即根据最近邻方法把样本分配到相应的初始聚类中心代表的聚簇中,将会得到全局最优的聚类结果。因此,怎样确定有效的初始聚类中心,成为研究K-均值聚类算法的重要内容。
本文在分析K-均值算法优化初始聚类中心研究的基础上,提出一种基于最小方差的自适应K-均值初始化方法。根据方差的定义可知,数据集中方差最小的样本通常位于数据分布较为密集的区域,而数据较密集的区域常常是聚类中心的潜在区域。本文通过两个步骤选取初始聚类中心。首先,根据样本方差判断样本是否处于数据密集区域,若是,则把该样本作为候选初始聚类中心,因此,可以得到一些处于数据密集区域的候选初始聚类中心;然后,对候选初始聚类中心进行筛选,选取K个聚类中心作为最终K-均值算法的初始聚类中心。在数据密集区域选取初始聚类中心,可以避免选择噪声或孤立点作为初始聚类中心,增强算法的抗噪性能,且该算法适合于大数据集聚类。
1 基于最小方差的自适应K-均值初始化方法
1.1相关研究
本文仅讨论K-均值算法初始聚类中心选择的方法。选择初始聚类中心的方法随着K-均值算法的产生而开始,最早的研究是1965年的Forgy方法。把数据集X中的每个样本随机分配给K个聚类,每个聚类的中心作为K个初始聚类中心,该方法缺少理论上的依据。Mac Queen提出两种初始聚类中心选取方法。一种是把数据集X中前K个样本作为K个初始聚类中心,该方法现应用在IBM SPSS统计软件快速聚类的过程中,但选择的初始聚类中心对数据输入顺序较敏感。另一种是K-均值算法广泛使用的选取初始聚类中心的方法,即随机选取数据集中K个样本作为K个初始聚类中心,该方法可能会选择噪声或孤立点作为初始聚类中心,因此需要多次运行算法才能得到较好的聚类结果。Onoda等人[4]通过计算数据集的K个独立成分,选择到第i个独立成分的余弦距离最小的样本作为第i个初始聚类中心。文献[5]把数据集平均分成若干等份,在每一等份上运行K-均值算法,在求出的所有聚类中心中选出相距较远的聚类中心作为整个数据集的初始聚类中心。该方法在一定程度上克服了K-均值算法对初始聚类中心敏感的问题,但时间复杂度大,不适用大数据集聚类。文献[6-8]根据样本分布密度确定初始聚类中心。文献[9]使用密度函数求出数据集的多个聚类中心,结合小类合并运算,避免算法收敛到局部最优值。对于K-均值初始聚类中心选取方法的研究已有大量的研究成果,但是没有出现公认最好的初始聚类中心选取的方法。当数据集中存在噪声或孤立点时,已有的方法很难选出正确的初始聚类中心。
1.2K-均值聚类算法
K-均值聚类算法的基本思想是:首先在数据集中随机选取k个样本作为K个初始聚类中心,根据最小距离原则,把剩余样本分配到与其距离最近的聚类中心所代表的聚簇中,计算每个聚簇的质心作为新的聚类中心,反复迭代直到误差平方准则函数SSE收敛。K-均值聚类算法的具体过程如下:
输入:数据集X={x1,x2,...,xn},聚类个数K,误差平方准则函数优化精度ξ,使用欧式距离度量样本间的相似性。
输出:聚类中心V,每个样本对应的类标签T。
(1)在数据集X中随机选取K个样本作为初始聚类中心V={v1,v2,...,vk}。
(2)把样本xi分配到与其距离最小的聚类中心所代表的聚簇中,设置类别标签为:
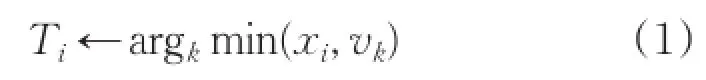
(3)计算每个聚簇的质心作为新的聚类中心;
(4)计算误差平方准则函数:
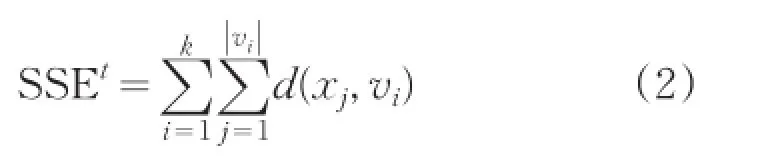
其中t是迭代次数,||vi是簇i中样本个数。
(5)若|SSEt-1-SSEt|<ξ,算法结束,输出V 和T,否则,设置t=t+1,转到(2)。
1.3基于最小方差的K-均值初始化方法
聚类中心应该位于数据集的密集区域,所以能够代表相应的类簇。但是数据的密集性并没有一个数学上的定义,而只是一个直观的概念。本文引入样本方差的概念,得到样本紧密度信息,进而发现位于数据密集区域的样本,然后对数据密集区域的样本进行处理,选出K个样本,作为K个初始聚类中心。
定义1:设数据集 X={xi|i=1,2,...,n},其中xi∈Rd,样本xi的方差定义为:
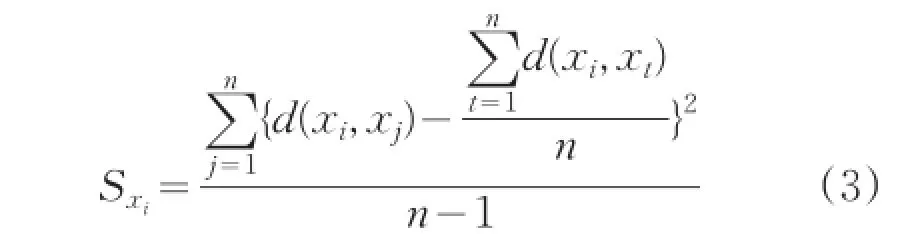
其中d(xi,xj)是xi和xj之间的距离,计算公式为:
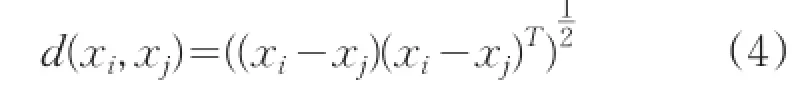
由上述定义可知,如果样本xi的方差越小,说明xi周围分布的数据越密集。反之,则说明xi周围分布的数据越稀疏。这与直观的数据密度相符。设定一个阈值ϕ,如果样本xi的方差小于ϕ,则认为样本xi处于某种程度的数据密集区域,因此,可以把样本xi作为候选初始聚类中心。这是本文提出基于最小方差的自适应K-均值初始化方法的思想来源。本文提出的选取初始聚类中心的方法分为两个过程:首先,依据样本方差的定义,将方差小于阈值ϕ的样本作为候选初始聚类中心,使用自适应方法,设置合适的阈值,使得候选初始聚类中心Vh的个数M多于给定的聚类个数K;然后,从候选初始聚类中心集Vh中选择方差最小的样本作为第一个判断中心,选择距离已有判断中心最远的样本作为下一个判断中心,直到选出K个判断中心,K个判断中心代表K个聚簇,按照最小距离原则,把候选初始聚类中心内其余样本分配到距离最近的K个聚簇中,更新每个簇的质心,重复该过程,直到聚簇中心不再变化,此时的K个聚簇中心就是本文算法得到的K个初始聚类中心。

图1 算法流程图
算法流程图如图1所示。根据方差的定义可知,计算n个样本方差的时间复杂度为O(n2),本文算法应用到大数据集时,通过对大数据集进行采样和降维操作,依然可以选择合理的初始聚类中心,进而降低时间复杂度。实验证明本文算法适合于大数据集聚类。数据集中噪声或孤立点的方差较大,且远远大于阈值,引入样本方差的概念选取候选初始聚类中心,使算法对噪声和孤立点具有较强的鲁棒性。测试数据集如表1所示。
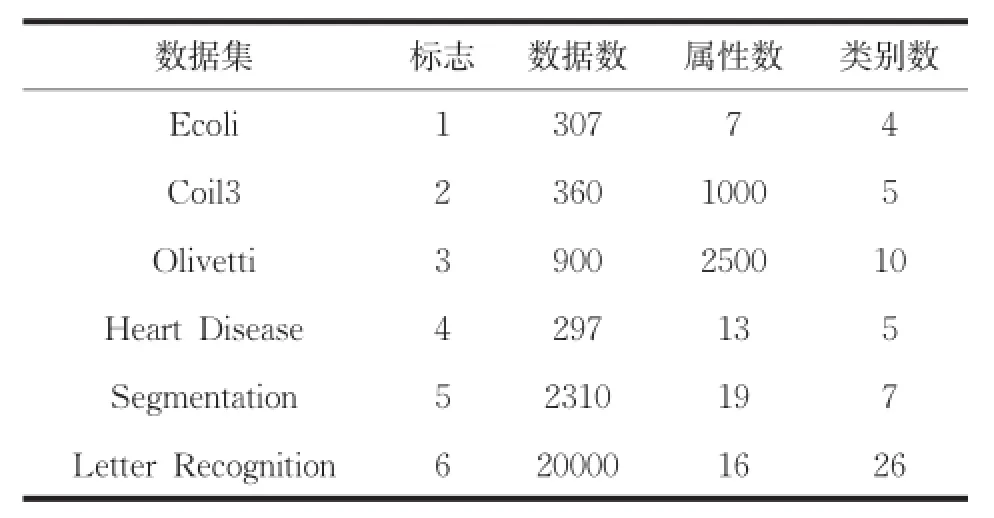
表1 测试数据集
2 实验结果与分析
硬件运行环境是Intel CPU,2.99G内存,931G硬盘;软件运行环境是WindowsXP操作系统,Visual Studio 2013开发平台,算法使用C++作为编程语言。使用UCI中的标准数据作为测试数据,如表1所示。在测试数据上分别100次运行本文算法(A1),传统K-均值算法(A2),K-Means++算法(A3),比较各个评价指标的均值。使用五个性能评价指标,验证本文算法的有效性,五个指标分别为:
(1)起始误差平方和(First SSE):度量选择的初始聚类中心的有效性,其值等于选出的初始聚类中心对应的误差平方和,值越小,说明选出的初始聚类中心越接近正确值。
(2)终止误差平方和(Last SSE):度量选择的初始聚类中心对整个聚类过程的有效性,其值等于聚类终止时对应的误差平方和,值越小,说明本文算法有效性越高。如表2所示。
(3)运行时间(Time):度量整个聚类过程所用的时间。
(4)Jaccard系数,使用正确聚类的样本占属于同一类簇的样本的比例评价聚类结果。
(5)Adjusted Rand Index参数,用来衡量聚类结果与数据的外部标准类之间的一致程度。
算法在测试数据集上的起始误差平方和(First SSE)和终止误差平方和(Last SSE)比较结果如表2所示。运行总时间如表3所示。图2是算法聚类结果的Jaccard系数比较。图3是算法聚类结果的Adjusted Rand Index参数比较。
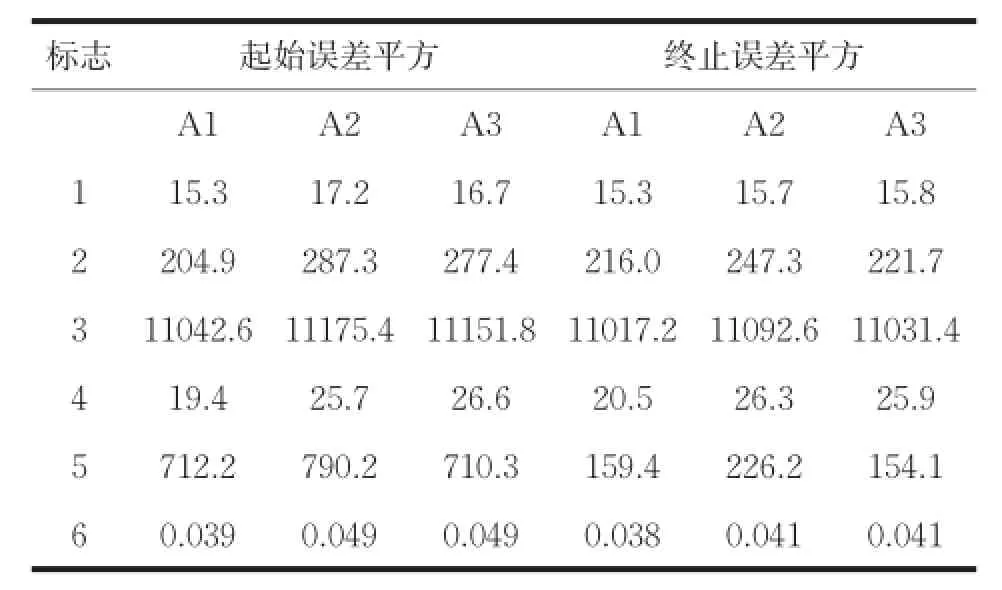
表2 起始误差平方和终止误差平方
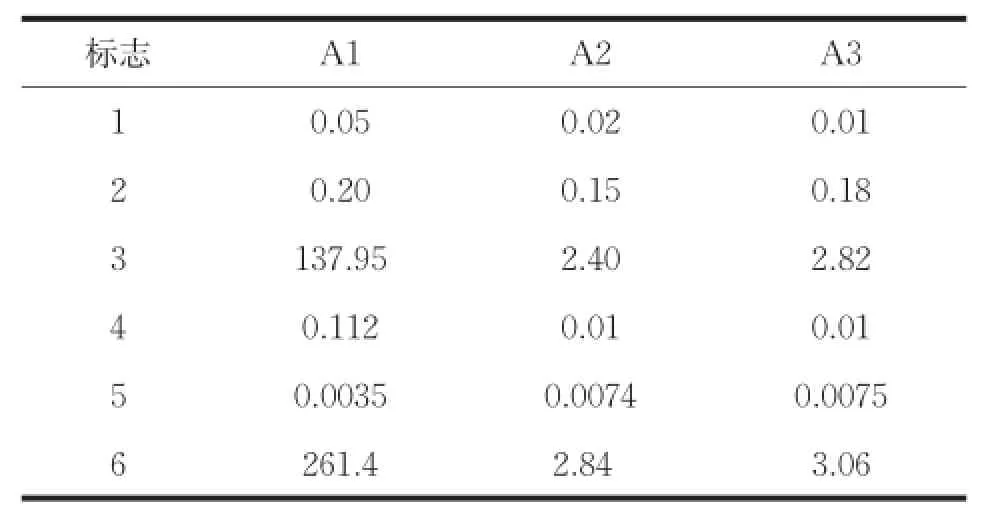
表3 运行时间
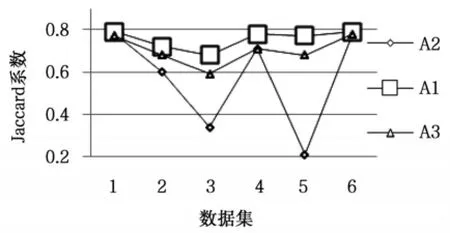
图2 Adjusted Rand Index参数比较
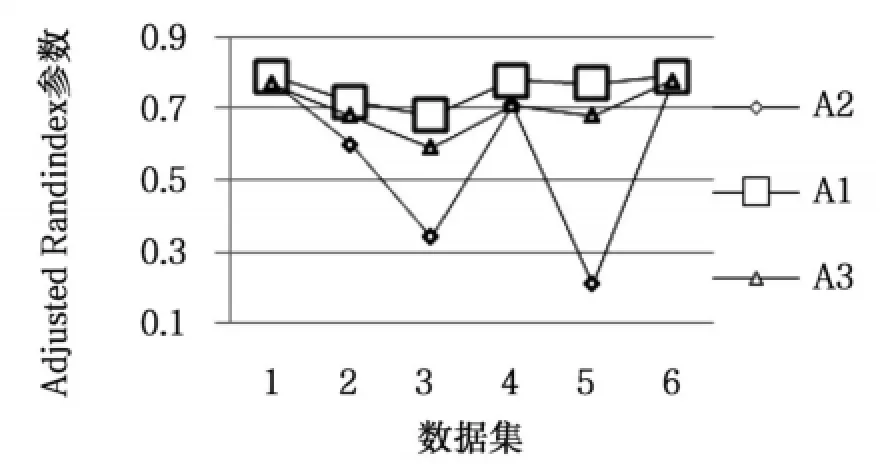
图3 Jaccard系数比较
从表2可以看出,本文算法在所有数据集上的起始误差平方和与终止误差平方和的值最小,选择的初始聚类中心与K-均值算法聚类之后的聚类中心间的距离最小。由图2和图3可知,在所有数据集上,本文算法聚类结果的各评价指标最大,在数据集Ecoli和Letter Recognition上三种算法聚类结果的评价指标比较接近,在数据集Olivetti和Segmentation上,本文算法与K-均值算法聚类结果的评价指标相差最大。其中在数据集Segmentation上,本文算法的聚类误差平方和高于K-Means++算法,但聚类评价指标均低于K-Means++算法,说明数据集Segmentation的真实分布情况是类内数据间的紧密性较弱。以上对比结果可知,本文算法优于其它两种算法,对K-均值算法的初始化具有很好的指导意义,提高了K-均值算法的聚类性能。本文算法引入样本方差的概念选取初始聚类中心,而计算样本方差是一个O(n2)时间复杂度的过程,由表3可知,本文算法的时间消耗高于其它算法,对大数据集聚类时,通过采样和降维操作,可以降低本文算法的时间复杂度且不影响算法聚类性能。
本文算法使用欧式距离度量样本间的相似度,若两个样本对应属性的取值差异较大,则这两个样本间的距离较大。即属性取值差异的大小,直接影响样本间距离的大小。基于以上思想,对大数据集聚类时,首先对大数据集进行采样操作,然后排除数据集中取值范围较小的属性(降维操作),最后使用本文算法进行初始聚类中心的选取。为了证明对大数据集进行采样和降维操作,不影响本文算法的有效性。使用不同的采样率对数据集Olivetti和Letter Recognition进行采样,采样之后本文算法的聚类结果如表4所示。其中采样率为1/2表示随机选取原数据集的1/2进行初始聚类中心的选取。把数据集Olivetti和Letter Recognition中的属性按照取值范围由大到小降序排列,使用不同比例值进行降维。降维之后本文算法的聚类结果如表5所示。其中比例值1/2表示降序排列后选择前1/2部分属性进行初始聚类中心的选取。
由表4可知,使用不同采样率,起始误差平方和与终止误差平方和的变化量非常小,但是运行时间却大幅度减少。由表5可知,数据集3的维数较大,比例值低于1/9时,起始和终止误差平方和出现略微变化,数据集5的维数较小,比例值低于1/2时,起始和终止误差平方和出现略微变化。为了减小本文算法对大数据集聚类的时间复杂度,且不影响聚类效果,使用不同的采样率对数据进行采样,设置比例值为1/2对数据进行降维,然后使用本文算法选取初始聚类中心,聚类结果如表6所示。由表6可知,同时对大数据集进行采样和降维,加大了聚类时间减小幅度,且不影响聚类效果。比例值为1/2对数据进行降维,适合数据集3的采样率为1/5~1/10,适合数据集6的采样率为1/6~1/2。实验证明本文算法适合对大数据集聚类。
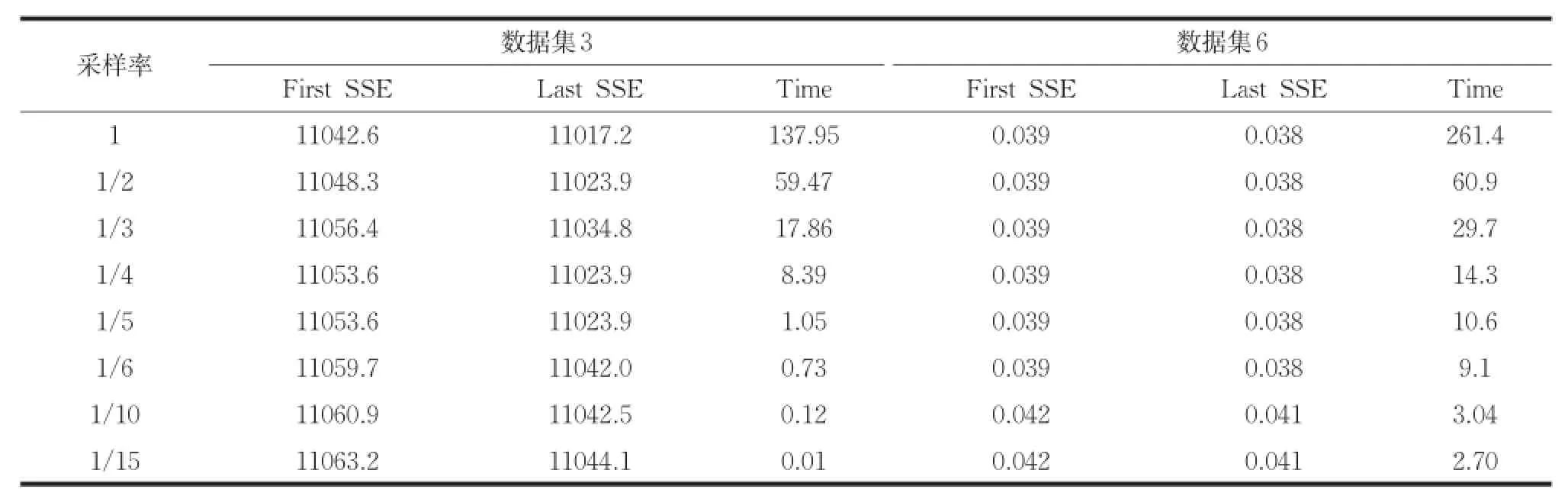
表4 采样数据的聚类结果

表5 降维数据的聚类结果

表6 采样和1/2降维数据的聚类结果
3 结论
本文提出基于最小方差的自适应K-均值初始化方法,可以发现数据集中较密集的区域,使选择的初始聚类中心均分布在数据密集区域,进而保证初始聚类中心的准确性;算法可以避免选取噪声或孤立点作为初始聚类中心,提升聚类性能;算法思想简单,容易实现,且适合于大数据集聚类。
[1] Yu H,Li Z,Yao N.Research on optimization method for K-Means clustering algorithm[J].Journal of Chinese Computer Systems,2012,33(10):2273-2277.
[2] 倪巍伟,陈耿,崇志宏,等.面向聚类的数据隐藏发布研究[J].计算机研究与发展,2012,49(5):1095-1104.
[3] 韩忠明,陈妮,张慧,等.一种非对称距离下的层次聚类算法[J].模式识别与人工智能,2014,27(5):410-416.
[4]OnodaT,SakaiM,YamadaS.CarefulSeeding Method based on Independent Components AnalysisforK-meansClustering[J].JournalofEmerging Technologies in Web Intelligence,2012,4(1):51-59.
[5] 韩晓红,胡彧.K-means聚类算法研究[J].太原理工大学学报,2009,40(3):236-239.
[6]Lai Yuxia,Liu Jianping.Optimization study on initial centerofK-meansalgorithm[J].ComputerEngineering and Applications,2008,44(10):147-149.
[7] Han Lingbo,Wang Qiang,Jiang Zhengfeng.Improved K-means initial clustering center selection algorithm[J].Computer Engineering and Applications,2010,46 (17):150-152.
[8]汪中,刘贵全,陈恩红.一种优化初始中心点的K-Means算法[J].模式识别与人工智能,2009,22(2):299-304.
[9] Mao Shaoyang,Li Kenli.Research of optimal K-means initialclusteringcenter[J].ComputerEngineering and Applications,2007,43(22):179-181.
An Adaptive K-means Initialization Method Based on Minimum Deviation
XIAO Yang,LI Ping,WANG Peng,QIU Ningjia
(School of Computer Science and Technology,Changchun University of Science and Technology,Changchun 130022)
K-means algorithm is sensitive to the initial cluster center;fluctuation of clustering results are following with different initial cluster centers.To solve these problems,in this paper,an adaptive K-means initialization method is proposed based on minimum variance;the initial clustering center is distributed in the K different sample density regions,clustering results of convergence to the global optimum.Firstly,according to the information of the space distribution of samples,the information of samples close degree is got by calculation of sample variance.In addition,based on samples close degree the qualified candidate initial cluster centers is selected;Then,the candidate initial cluster centers are dealt with and k initial cluster centers are filtered.The experiment proved that this algorithm has high clustering performance and good robustness for processing of the noise and the isolated point;it is suitable for clustering the large-scale data set.
clustering;K-means;deviation;initialized clustering centers
TP391
A
1672-9870(2015)05-0140-05
2015-03-30
肖洋(1989-),男,硕士研究生,E-mail:978996354@qq.com
李平(1958-),女,教授,E-mail:liping@cust.edu.cn
