Workload-aware request routing in cloud data center using software-defned networking
2015-01-17HaitaoYuanJingBiandBohuLi
Haitao Yuan,Jing Bi,and Bohu Li
1.School of Automation Science and Electrical Engineering,Beihang University,Beijing 100191,China;
2.Department of Automation,Tsinghua University,Beijing 100084,China
Workload-aware request routing in cloud data center using software-defned networking
Haitao Yuan1,∗,Jing Bi2,and Bohu Li1
1.School of Automation Science and Electrical Engineering,Beihang University,Beijing 100191,China;
2.Department of Automation,Tsinghua University,Beijing 100084,China
Large latency of applications will bring revenue loss to cloud infrastructure providers in the cloud data center.The existing controllers of software-defned networking architecture can fetch and process traffc information in the network.Therefore,the controllers can only optimize the network latency of applications.However,the serving latency of applications is also an important factor in delivered user-experience for arrival requests.Unintelligent request routing will cause large serving latency if arrival requests are allocated to overloaded virtual machines.To deal with the request routing problem,this paper proposes the workload-aware software-defned networking controller architecture.Then,request routing algorithms are proposed to minimize the total round trip time for every type of request by considering the congestion in the network and the workload in virtual machines(VMs).This paper fnally provides the evaluation of the proposed algorithms in a simulated prototype.The simulation results show that the proposed methodology is effcient compared with the existing approaches.
cloud data center(CDC),software-defned networking,request routing,resource allocation,network latency optimization.
1.Introduction
Nowadays,the cloud data center(CDC)supports multiple different types of applications concurrently and provides services to many application users by sharing the IT resources[1,2].Furthermore,virtualization mechanisms have been commonly used to realize the effcient use of physical resources in the CDC[3].With virtualization mechanisms,the CDC can support multiple applications in virtualized CDC infrastructure.Physical servers are pooled and separated into many isolated virtual machines(VMs) in CDC infrastructure.Each VM in underlying virtualized computing pool only deploys one single type of applications.The arrival requests admitted by the CDC need to traverse the network in the CDC and to be served by a specifc VM in the computing pool in the CDC.Consequently the total round trip time(RTT)of requests consists of the network latency in the network and the serving latency in VMs.It has been shown that the latency of applications in the CDC has a signifcant impact on user-experience and will bring revenue loss to cloud infrastructure providers. For example,authors in[4]showed that both Amazon and Google experienced the losses of sales and workload under longer application latency.What is more,a half-second latency will result in a 20%loss of traffc in Google,and a tenth of the second latency will bring a loss of one percent of Amazons sales.
Recently,the newly emerging software-defned networking(SDN)can provide centralized control of the network by programmable OpenFlow-enabled network devices including the SDN controller and forwarding elements(switches or routers)[5].SDN realizes the separation of the control plane and the data plane and provides centralized and globally optimized routing decision for the network in the CDC.The control and management plane in traditional network elements is moved to the remote SDN controller.The OpenFlow-enabled network element only needs to contain the data plane in SDN and to provide public OpenFlow application programming interfaces(APIs) to the remote SDN controller.The OpenFlow is the standard protocol for information exchange between the controller plane and the data plane[6].The SDN controller needs to control the network and to provide the functions including forwarding,virtual private network(VPN),security,bandwidth allocation,quality of service(QoS),network virtualization and load balancing.
More specifcally,the SDN controller periodically queries real-time network statistics including network link usage and network element state.Furthermore,SDN makes it easy to scale and manage the CDC network for meeting application needs in real time.Therefore,SDNgreatly realizes better network management,higher availability and utilization by high-performance,fne-grained traffc engineering for different applications.Google has announced[7]that it is applying SDN to interconnect multiple data centers because of the fexibility and effciency in realizing traffc engineering.It expects that the SDN architecture will bring higher network utilization and reduced losses.
There are many open challenges involved in the existing SDN architecture.The existing controllers only query traffc information in the network,thus they can only control OpenFlow-enabled switches and optimize the network latency.However,the serving latency in VMs also plays an important role in user-experienced latency.Large serving latency may occur if the arrival requests are allocated to an already overloaded VM.Besides,the routing mechanism in the existing controller such as Floodlight[8]only selects the shortest routing path to the destination VM.This may cause large RTT due to the network congestion or large serving delay in VMs.What’s more,each application in the CDC is deployed on multiple homogeneous or heterogeneous VMs for the sake of scalability or stability[1,9]. Therefore,there are multiple corresponding VMs which can serve the requests of each application in the CDC.
In order to deal with this problem,this paper presents the workload-aware SDN controller architecture.In the architecture,the workload-aware SDN controller consists of the traditional SDN controller and the cloud controller. The SDN controller can periodically update information of links in the network while the cloud controller can query the workload in VMs.Based on the architecture,this paper proposes the workload-aware request routing algorithms (WARRA)to minimize the RTT for every type of requests (CPU-intensive or network-intensive)by considering the congestion in network and the workload in VMs.The proposed algorithms can determine the optimal combination of the routing path and the destination VM to minimize the total RTT for every type of application.
To address the challenge of workload-aware request routing in CDC,the work aims to:
(i)Propose a workload-aware SDN controller architecture to consider both the congestion in the network and the workload in VMs.
(ii)Propose WARRA to minimize the total RTT for different types of requests.
(iii)Evaluate the proposed algorithms by comparing with the existing methods.
The rest of the paper is organized as follows.Section 2 reviews the related works.Section 3 provides the workload-aware SDN controller architecture and formulates the workload-aware request routing problem.Section 4 describes the proposed WARRA in detail.Section 5 evaluates the proposed WARRA by trace-driven simulation using the publicly available real-world workload traces.Section 6 concludes the paper.
2.Related work
This section presents an overview of related papers in this research area and compares the proposed request routing with the existing works.
2.1Traffc engineering
There have been some existing research on the traffc engineering in software-defned networking[10–12].Authors in[10]evaluated the effectiveness of traffc engineering in an existing network where SDNs are incrementally introduced.In particular,they show the way to leverage the controller to signifcantly improve network utilization and reduce average delays and packet losses.The work solves the traffc engineering in a hybrid network consisting of traditional switches and OpenFlow-enabled SDN switches. In contrast to the work,we consider the request routing problem in the CDC where all switches support the OpenFlow protocol and can be controlled by the centralized SDN controller.Authors in[11]employed a measurement-based approach to schedule fows through both the shortest and non-shortest paths according to the temporal utilization in the network.They also proposed a fow scheduling algorithm which can allocate spare data center network capacity to improve the performance of heavily overloaded links.Authors in[12]presented the effectiveness of applying traffc-aware placement of VMs to enhance the scalability of network.The analysis of the characteristics of traffc patterns among VMs can produce the optimal allocation of VMs on host machines.However, the aforementioned methods only consider the link utilization or congestion in the network.For a given type of request,the workload in the destination VM also plays an important role in user-experienced latency.
2.2Load-balancing problem
Several recent papers have proposed different methods to tackle the load-balancing problem in data center networks using the concept of controller in SDN[13–16].Authors in[13]proposed that the network performance can suffer in the presence of inconsistent global network view.Uncoordinated changes to the physical network state may generate routing loops,sub-optimal load-balancing,and other undesired application-specifc actions.In order to solve the problem,the authors present an arrival-based load balancer control mechanism.The objective of the load balancer is to minimize the maximum link utilization(MLU)in the se-lected network.However,the minimization of MLU can not guarantee the lowest latency for a given type of requests.Authors in[14]presented algorithms which compute specifc wildcard rules for the given traffc distribution.The algorithms can automatically adapt to the loadbalancing changes without destroying the existing connections.The main goal is to split workload over the server replicas using wildcard rules.Authors in[15]proposed a scheme that brings no communication overhead between servers and users based on job arrival.This scheme can remove the scheduling overhead brought by the critical path of each job.However,they do not distinguish the types of jobs and treat every job equally.The high-priority jobs do not have the privilege to traverse the network.Authors in [16]proposed methods to realize the load-balancing between requests in unstructured networks.This work proposes an OpenFlow-based server system to realize the load-balancing for web traffc.The system can effectively reduce the response time of web services in unstructured networks built with cheap commodity hardware.This approach can specify the destination server after considering the workload of all servers.However,this work treats every request equally.However,the performance requirements of the arrival requests are different.
In contrast to the previous work,this paper proposes the workload-aware request routing mechanism.The routing mechanism considers both the congestion in the network and the workload in the destination VM.In addition,the routing mechanism distinguishes the types of requests and always tries to ensure the performance of high-priority requests.
3.Scenario and performance metrics
This section frstly presents the workload-aware softwaredefned networking controller architecture.Then,it presents the formulation of the workload-aware request routing problem in the CDC.
3.1Architecture overview
The overall response time of requests includes the time spent in the network and VMs.The consideration of both the congestion in network and the workload in VMs can minimize the overall response time of requests by intelligently choosing the routing path and the destination VM. In typical SDN architecture,the traditional controller only fetches and processes traffc information in the network, thus the controller only manages and schedules the forwarding elements(OpenFlow-enabled switches)in the network.The traditional controller can only optimize the network latency,i.e.,time spent in the network.However,the serving latency,i.e.,time spent in the VM,is also important in user-experience.A new arrival request may experience large serving latency if it is unintelligently allocated to an overloaded VM.The proposed workload-aware SDN controller architecture,which is illustrated in Fig.1,consists of two major components:the traditional SDN controller and the cloud controller.The former component periodically probes the traffc information(network topology and utilization of each link)in network and makes decision about selection of the routing path for requests.The latter component periodically reports the information about VMs including utilization,the remaining requests in each VM,etc.to the SDN controller.The combination of the two components builds the proposed workload-aware SDN controller.

Fig.1 Workload-aware SDN controller architecture
Based on the architecture,the proposed workload-aware request routing mechanism aims to minimize the RTT for different types of requests by considering the congestion in the network and the workload in VMs.The optimal request routing can be achieved by considering many essential factors including the request arrival rates,the types of different requests,etc.
Nowadays,each application is deployed on several homogeneous or heterogeneous VMs for the sake of scalability or stability in the CDC.Therefore requests of each application cannot be served by all VMs in the CDC.For a specifc type of request,there are several corresponding VMs that can serve the requests.Note that the workloadaware SDN controller does not process the requests but decides the routing path and installs fow entries into switches in the routing path to the destination VM.Given a type of request,the workload-aware SDN controller needs to make two decisions.The frst decision determines the potential available VMs which are deployed to the corresponding application.The second decision specifes the routing pathto the selected destination VM.For each routing path to the destination VM,the workload-aware SDN controller can periodically fetch the link information including the remaining bandwidth and utilization of the link.The optimal combination of the routing path and the destination VM can minimize the total RTT.However,the routing mechanism in the existing controller,e.g.,Floodlight[8],just chooses the routingpath accordingto the shortest path frst (SPF)policy.This simple SPF policy may cause the congestion in the network or large serving delay in VMs,thus the unintelligent policy will cause large RTT.
For a given type of request,the controller needs to specify the destination VM to serve the requests.There may be several reachable routing paths to the destination VM.The RTT of the specifc type of request is the sum of the time spent in the network and the time spent in the destination VM.The requests can be divided into several types including the CPU-intensive requests and the network-intensive requests.Compared with the network-intensive requests, the CPU-intensive requests need to take longer time in VMs and shorter time in the network.
3.2Problem formulation
Based on the proposed workload-aware SDN controller architecture,the section formulates the problem of workload-aware request routing in the CDC.
The workload-aware request routing problem is formulated as follows.Given fxed network topology,the request routing considers the congestion in the network and the remaining workload in VMs.In order to minimize the RTT, the request routing can determine the optimal combination of the destination VM and the routing path in the network. In this way,the request routing can realize load balancing of both the VMs and the network,and fnally minimize the RTT of requests.We summarize the main notations used throughout this paper in Table 1 for clarity.
Assume each VM only supports a single application corresponding to a type of request.This work sets the priorities of different types to each requests in advance.A specifc type of request can only be served by VMs deployed with the corresponding type of application.
Given a specifc topology and requests of type f,the workload-aware SDN controller needs to specify the fnal destination VM and the routing path to the destination VM, i.e.,dfand pf.
For given requests of type f,the RTT is the sum of the time spent in network,TpfNetworkand the time in a specifc VM,TdfVM.For simplicity,it is assumed that the time spent in the network from and that to the corresponding VM are the same.
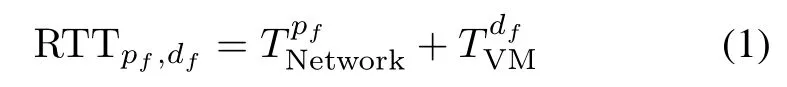

Table 1 Notations


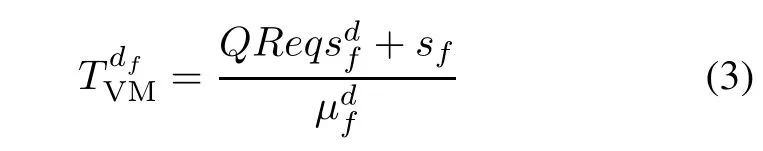
Given requests of type f,there are multiple destination VMs which can serve the requests.For each destination VM,df,there are multiple routing paths which connect the gateway switch and df.Let pfdenote an admissible routing path for requests of type f.Therefore,given all possible combinations(pf,df),the optimal combination can be achieved by minimizing the RTT.Therefore,the optimization problem(P1)can be formulated as follows:

s.t.

The constraint(4)shows that for each e∈pf,pf∈APf,s,d, the sum of the total bandwidth requirements of the newly assigned requests which can traverse the link e must be less than the capacity of link e,Cape.Here,APf,s,ddenotes the set of admissible paths for requests of type f from gateway switch s to the destination VM d.The constraint(5) shows that in order to ensure the response time of requests, it is assumed that admission policies for requests have been used to control the admitted request arrival rate of each switch in the routing path.
4.WARRA
Based on the proposed workload-aware SDN controller architecture which considers both the congestion in the network and the workload in VMs,this section presents the WARRA to realize the intelligent request routing.These algorithms run periodically in the workload-aware SDN controller.In order to solve the problem presented in Section 3.2,the following several algorithms describe the proposed routing mechanism in this section.Algorithm1 aims to fnd the optimal combination of the destination VM and the routing path to minimize RTT.Algorithm 2 describes the method to transform Reachf,s,dto APf,s,d.The function Knapsack in Algorithm 2 is described in Algorithm 3.
Algorithm 1 Find the optimal combination of VM and the routing path
Input:
Number of request types:T
Output:
Optimal combination of VM and the routing path for each request type
f:pf,df
1:for f=1 to T do
2: minimalRTTf=positivein finite;
3: for d=1 to nfdo
4: minimalRTTdf=positivein finite;
5: for all path p∈APf,s,ddo

7: if RTTp<minimalRTTdfthen
8: minimalRTTdf=RTTp;
9: end if
10: end for
11: if minimalRTTdf<minimalRTTfthen
12: minimalRTTf=minimalRTTdf;
13: df=d;
14: pf=p∗;/*Routing path p∗corresponding to minimalRTTf*/
15: end if
16: end for
17:end for
18:return pf,df
Algorithm 2 Transform Reachf,s,dto APf,s,d
Input:Reachf,s,d
Output:APf,s,d
1:for all request type f in T do
2: for all routing path p∈Reachf,s,ddo
3: for all link e in p do
4: RTe=Knapsack(e)
5: if f is not in RTethen
6: Reachf,s,d=Reachf,s,d−{p}
7: APf,s,d=Reachf,s,d
8: end if
9: end for
10: end for
11:end for
12:return APf,s,d
Algorithm 3 aims to assign different types of requests to each link e.Different types of requests unfairly share the bandwidth capacity in each link e.The assignment of requests can be formulated as a knapsack problem(KP). The algorithm frst orders different types of requests by the reqLevel property in the descending order.Then the algorithm assigns requests to the link e according to the corresponding priority on the condition that the total bandwidth occupied by the assigned requests does not exceed Cape. It may be possible that the total bandwidth requirements of requests which can traverse the link e is smaller than Cape.In this case,the remaining bandwidth of the link e will be allocated to all types of requests.The amount of bandwidth allocated to each type of request is proportional to the actual bandwidth requirement of requests.For example,given two types of requests,f1and f2,the actual bandwidth requirements of f1and f2are 300 MBytes/s and 100 MBytes/s,respectively.Assume that the capacity of the link e is 500 MBytes/s.Thus the remaining bandwidth,100 MBytes/s,will be allocated to f1and f2with the amounts of 75 MBytes/s and 25 MBytes/s,respectively.Therefore,the fnal bandwidths of f1and f2will be 375 MBytes/s and 125 MBytes/s,respectively.
Algorithm 3 Knapsack(Solving 0-1 knapsack problem with the
genetic algorithm)
Input:
e:the link
elitism:whether to use elitism or not
popSize:number of chromosomes in every population
chromoSize:length of every chromosome
generationSize:number of generations
crossRate:crossover ratio
mutateRate:mutation ratio
volumes:set of bandwidth requirements of request fows in T
priorities:set of priorities of request fows in T
Output:
RTefor link e
1:initialize the data(volumes and priorities)
2:initialize the frst population by randomly initializing a population of popSize chromosomes,and the length of each chromosome is chromoSize
3:while the number of generations is smaller than generationSize or the percentage of the chromosomes with the same ftness(total priorities)in the latest population is smaller than 90%do
4: rank(popSize,chromoSize);/*rank the chromosomes in the current population*/
5: select(popSize,chromoSize,elitism);/*randomly select chromosomes to reproduce new population using the combination of roulette-wheel selection and elitism.*/
6: crossover(popSize,chromoSize,crossRate);/*perform crossover by randomly specifying a position and exchanging the subsequences after the position between two chromosomes to create new offspring for the next population*/
7: mutation(popSize,chromoSize,mutateRate);/*perform mutation on the chromosomes after crossover*/
8: replace the current population with the new population
9:end while
10:RTe=Ø
11:Re=Cape
12:for all request type f in T do
13: if the bit corresponding to request fow f in the calculated best chromosome(solution)is 1 then
14: if BWf?Rethen
15: Re=Re−BWf
16: RTe=RTe+{f}
17: else
18: break;
19: end if
20: end if
21:end for
22:return RTe
For each link e,there are multiple types of request fows,which may traverse the link.All request fows compete with each other for a limited bandwidth capacity of the link.The bandwidth requirement of requests of different types is different.The workload-aware SDN controller needs to specify the set of request fows traversing the link to maximize the total priorities of the set without exceeding the bandwidth capacity of the corresponding link e.Let total Pedenote the total priorities of request fows which can traverse the link e.Thus this can be formulated as 0-1 KP,which is a typical combinatorial optimization problem. Here the bandwidth capacity of a link denotes the volume of a knapsack.Each request fow denotes a distinct item that may be put into the knapsack.The bandwidth requirement and the priority of each request fow correspond to the volume and the beneft of the item,respectively.The KP(P2)that we intend to solve can be briefy formulated as follows.
For each link e,maximize totalPe,i.e.,
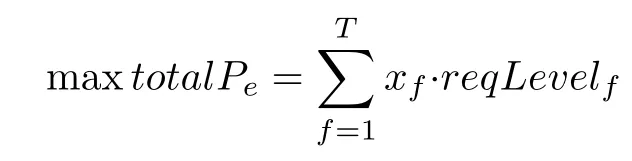
s.t.
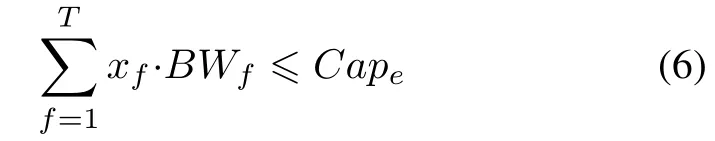

The constraints(6)and(7)show that the occupied bandwidth of request fows selected to traversing link e cannot exceed the bandwidth capacity of the corresponding link. The 0-1 KP is a typical NP-hard problem,and traditional algorithms including dynamic programming,branch and bound,backtracking cannot effectively solve it.However, the genetic algorithm(GA)proves to be an effcient algorithm in fnding approximately optimal solutions for larger NP problems traditionally viewed as computationally infeasible such as the 0-1 KP.GA can search for close-tooptimal solutions to a problem from a set of potential solutions[17].GA begins with some possible solutions(chromosomes)called population.Then a new population is created from chromosomes of the old population in oder to get a better population.Solutions selected to create new solutions(offspring)are chosen based on their ftness.The more suitable solutions,the more chances to reproduce. The process is repeated until the termination condition is satisfed.The basic elements of GA include populations of chromosomes,selection based on ftness,crossover to reproduce new offspring,and possible mutation of the new offspring.So,this paper adopts GA to solve the 0-1 KP for each link in the network.
The implementation of GA combines the most used selection method,roulette-wheel and the elitism,which can signifcantly improve the performance of the roulettewheel selection.Roulette-wheel is a typical method of supporting ftness-proportionate selection.The elitism is an approach which frst directly copies some of the fttest chromosomes in the old population to the new one,and then generates the rest of the new population.In this way the elitism can preserve the best solutions.Moreover,the implementation adopts binary encoding where each chromosome is coded as a string of bits,0 or 1.In addition, the implementation uses single point crossover and performs crossover with a certain probability.What’s more, mutation is implemented to prevent GAs from falling into a local extreme.The mutation is performed on each bit position of the chromosome with a small probability,0.1%. The optimization goal of Algorithm 3 is to assign different kinds of request fows to every link in the network within each computational period,such that the total RTT is minimized and the total bandwidth requirement for different fows assigned to each link cannot exceed the corresponding link bandwidth capacity.Let N denote the number of request fows in every link e.The function which initializes the chromosomes in the frst generation has a complexity of O(N).The ftness function,crossover function,and mutation function also have complexities of O(N).Thus,the total complexity of Algorithm 3 is O(N).
Note that there is a knapsack problem in each link,but note that every link is independent of each other so that the multiple knapsack problems can be solved in parallel.Authors in[18]proved that the employment of parallelism can scale the ability of a controller to 20 million fows per second.Therefore,the calculation of the routing path will not bring too much overhead in the experiment.
5.Performance evaluation
To realistically evaluate the performance of the proposed workload-aware request routing,a prototype is developed in Java in this section.This work evaluates the proposed WARRA by trace-driven simulation using the publicly available real-world workload traces from Google production systems[19].
Fig.2 shows the dataset which describes the resource requirement of CPU and memory from Google compute cells for over six hours(370 min)in the period of a month in May2011.During the period of time this website recorded 1 352 804107 requests.The workload can be predicted accurately as shown in previous works[20],so the simulation simply adopts the measured requests traffc as the request arrival rates.The information including the link utilization in the network,and workload of VMs needs to be updated every fve minutes.For the clear demonstration,the evaluation focuses on the requests that arrive during the six hours period.The arrival rates of requests of four types are illustrated in Fig.2.Besides,the priorities of four request fows(task type 1,task type 2,task type 3 and task type 4) illustrated in Fig.2 are set to 1,2,3 and 4,respectively.

Fig.2 Google’s request arrival rates
5.1Simulation experiment setup
This section evaluates the performance of the proposed WARRA based on the typical data center network topology,Fat-tree[21].Note that the proposed routing algorithms are applicable for any type of data center network topology but the proposed algorithms are only evaluated based on the commonly used pod-4 Fat-tree,as illustrated in Fig.3.The Fat-tree topology with three-layer topology contains edge tier,aggregation tier,and core tier,respectively.The core tier bridges the data center with the Internet.There are multiple corresponding VMs for every type of request fow in Fig.3.Each VM can only serve a specifc type of request fow.Thus,it is meaningful and important to intelligently route the hybrid request fows to minimize the total RTT for every type of request fow.It is assumed that the link rates between hosts and switches are 1 Gbps.In addition,the link rates between switches are also 1 Gbps.The simulation environment consists of 16hosts and 20 OpenFlow-enabled switches.The switches can collect fow information and report it to the centralized workload-aware SDN controller.
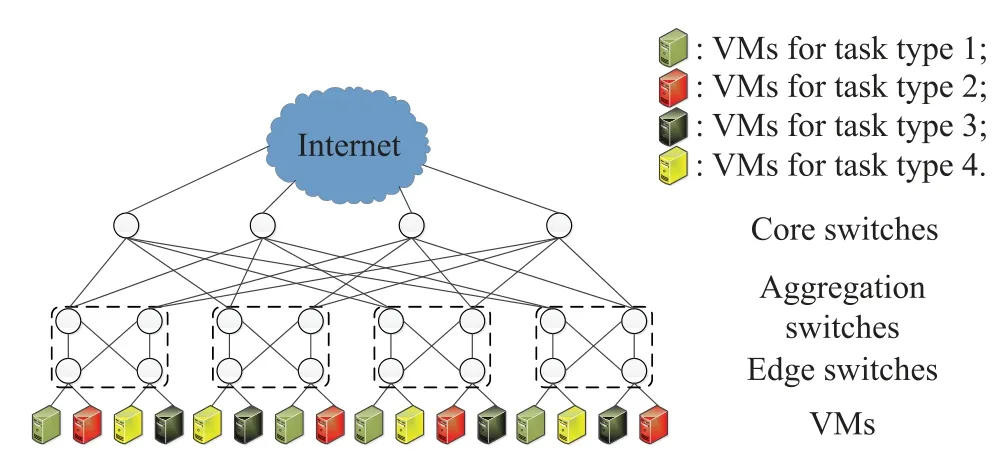
Fig.3 Fat-tree data center network topology
The size of the large amount of requests in the current data center is small(≤10kB)[22].However,the work[23] shows that the mixture of large and small requests is more realistic.Therefore,Table 2 shows the setting of average sizes of four different types of request fows.In addition, the setting of the serving rate of request fow f in VM d, μdf(f=1,2,3,4)is also shown in Table 2.

Table 2 Realistic parameter setting
5.2Simulation experiment
This section evaluates the proposed WARRA by comparing it with the typical baselines including open shortest path frst(OSPF)[24]and random routing[25].The distance in the OSPF denotes the number of links between the gateway switch and the destination VM.It is assumed that the OSPF always chooses the leftmost destination VM for a given type of request.The random routing algorithm differs from the OSPF because the random routing algorithm can select any destination VM other than just the leftmost destination VM for a given type of request.Therefore,random routing means that the fnal destination VM is selected randomly from the available corresponding multiple VMs. Figs.4,5,6 and 7 show the comparison result of the total RTT for requests of type 1,2,3 and 4 respectively,using WARRA,random routing and OSPF.It can be shown in the four fgures that the proposed WARRA performs better than the other two routing algorithms,OSPF and random routing.The OSPF algorithm always chooses the shortest routing path to the destination VM,therefore large RTT will occur if the arrival requests are always scheduled to the shortest routing path.However,the random routing algorithm performs better than the OSPF algorithm because it specifes the routing path randomly and can lower the RTT.
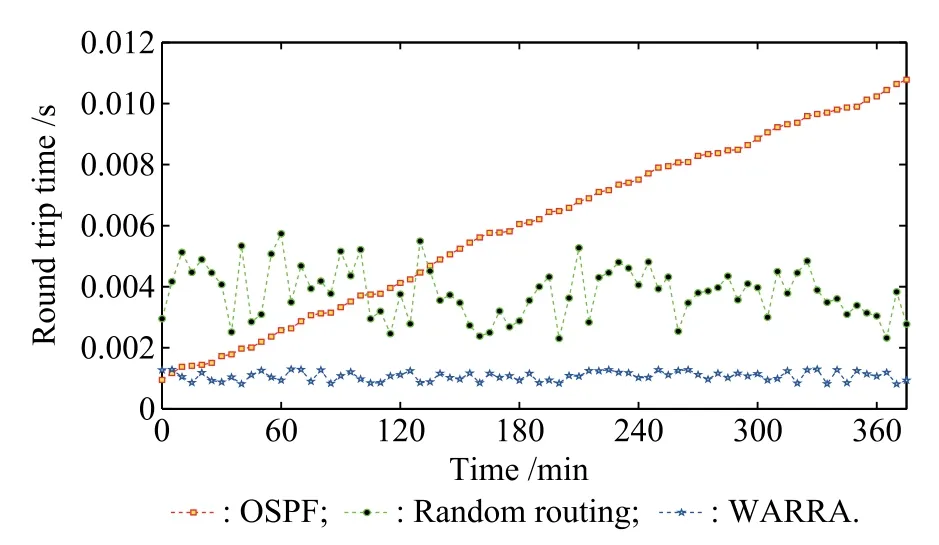
Fig.4 Comparison result of type 1 requests

Fig.5 Comparison result of type 2 requests

Fig.6 Comparison result of type 3 requests

Fig.7 Comparison result of type 4 requests
Fig.8 shows the variance of average utilization of the corresponding VMs for different types of requests using three routing algorithms including WARRA,random routing and OSPF.The utilization of four VMs for the same type of request over the period of time is different due to the corresponding routing algorithm.Therefore,this paper calculates and compares the average utilization variances of four VMs for the same type of requests with three routing algorithms.It is shown that compared with the other two routing algorithms,OSPF and random routing,the utilization variations of WARRA are the lowest for every type of request.This means that the WARRA can optimally choose the routing path and the destination VM by considering the congestion in network and the workload in VMs.The random routing algorithm just chooses the routing path and the destination VM randomly.Therefore this algorithm performs better than the OSPF in most cases.It is understandable that the OSPF always selects the shortest routing path to schedule the requests.Therefore,its performance is the worst compared with the other routing algorithms including WARRA and random routing.

Fig.8 Variance of average utilization
Then,Fig.9 illustrates the average request delays of three routing algorithms.Compared with the baselines including OSPF and random routing,the WARRA decreases the average packet delays of all types of requests.Besides, Fig.10 shows the packet drop ratios of three routing algorithms.In this fgure,the WARRA lowers the packet drop ratio by 0.289%compared with the random routing,and 0.64%compared with the OSPF,respectively.Therefore, with the consideration of both the network latency of applications and the serving latency in destination VMs,the WARRA performs better than the existing two routing algorithms.Then,the WARRA can minimize the total roundtrip time for every type of request by considering the congestion in the network and the workload in VMs.

Fig.9 Average packet delays of WARRA and the baselines
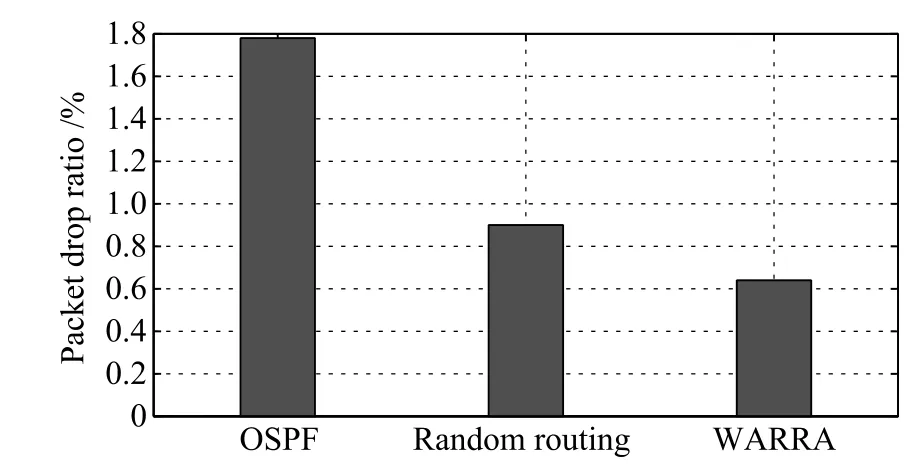
Fig.10 Packet drop ratios of WARRA and the baselines
6.Conclusions and future work
The existing controllers in the typical software-defned networking architecture can only optimize the network latency and cannot affect the serving latency in virtual machines,so that large serving latency may occur if the arrival requests are allocated to overloaded virtual machines.In order to solve the problem,this paper frstly presents the workload-aware software-defned networking controller architecture.Then,this paper proposes the WARRA to minimize the total round trip time for each type of request by considering the congestion in the network and the workload in VMs.Given a type of request,the proposed algorithms can determine the optimal combination of the routing path and the destination VM to minimize the corresponding total round trip time.Then,the trace-driven simulation is presented by using the publicly available realworld workload traces.The simulation result demonstrates that compared with two existing baselines including OSPF and random routing,the proposed algorithms can realize less round trip time for every type of request.In future research,we would like to design an SDN-based request routing algorithm for minimizing the round trip time of requests in multiple distributed cloud data centers.
[1]J.Bi,H.T.Yuan,M.Tie,et al.SLA-based optimisation of virtualised resource for multi-tier Web applications in cloud data centres.Enterprise Information Systems,2014:1–25.
[2]M.Armbrust,A.Fox,R.Griffth,et al.A view of cloud computing.Communications of the ACM,2010,53(4):50–58.
[3]G.H.Wang,T.S.EugeneNg.The impact of virtualization on network performance of amazon EC2 data center.Proc.of the 29th Conference on Computer Communications,2010:19.
[4]J.M.Zhu,Z.B.Zheng,M.R.Lyu.DR2:dynamic request routing for tolerating latency variability in online cloud applications.Proc.of the IEEE 6th International Conference on Cloud Computing,2013:589–596.
[5]M.Casado,M.J.Freedman,J.Pettit,et al.Ethane:taking control of the enterprise.SIGCOMM Computer Communication Review,2007,37(4):1–12.
[6]N.McKeown,T.Anderson,H.Balakrishnan,et al.Openfow: enabling innovation in campus networks.SIGCOMM Computer Communication Review,2008,38(2):69–74.
[7]C.Y.Hong,S.Kandula,R.Mahajan,et al.Achieving high utilization with software-driven WAN.Proc.of the ACM SIGCOMM Conference,2013:15–26.
[8]D.Erickson.The beacon openfow controller.Proc.of the 2nd ACM SIGCOMM Workshop on Hot Topics in Software Defned Networking,2013:13–18.
[9]J.Bi,Z.L.Zhu,R.Tian,et al.Dynamic provisioning modeling for virtualized multi-tier applications in cloud data center.Proc.of the 3rd IEEE International Conference on Cloud Computing,2010:370–377.
[10]S.Agarwal,M.Kodialam,T.V.Lakshman.Traffc engineering in software defned networks.Proc.of the 32nd IEEE International Conference on Computer Communications,2013: 2211–2219.
[11]F.P.Tso,G.Hamilton,R.Weber,et al.Longer is better:exploiting path diversity in data center networks.Proc.of the IEEE 33rd International Conference on Distributed Computing Systems,2013:430–439.
[12]X.Q.Meng,V.Pappas,L.Zhang.Improving the scalability of data center networks with traffc-aware virtual machine placement.Proc.of the 29th IEEE International Conference on Computer Communications,2010:1–9.
[13]S.Schmid,J.Suomela.Exploiting locality in distributed SDN control.Proc.of the 2nd ACM SIGCOMM Workshop on Hot Topics in Software Defned Networking,2013:121–126.
[14]R.Wang,D.Butnariu,J.Rexford.Openfow-based server load balancing gone wild.Proc.of the 11th USENIX Conference on Hot Topics in Management of Internet,Cloud,and Enterprise Networks and Services,2011:12–12.
[15]A.Nahir,A.Orda,D.Raz.Schedule frst,manage later: network-aware load balancing.Proc.of the 32nd IEEE International Conference on Computer Communications,2013: 510–514.
[16]N.Handigol,S.Seetharaman,M.Flajslik,et al.Plug-n-serve: load-balancing Web traffc using openfow.Proc.of the ACM International Conference on the Applications,Technologies, Architectures,and Protocols for Communication,2009.
[17]D.E.Goldberg,J.H.Holland.Genetic algorithms and machine learning.Machine learning,1988,3(2):95–99.
[18]X.D.Wang,Y.J.Yao,X.R.Wang,et al.Carpo:correlationaware power optimization in data center networks.Proc.of the 32nd IEEE International Conference on Computer Communications,2012:1125–1133.
[19]C.Reiss,A.Tumanov,G.R.Ganger,et al.Heterogeneity and dynamicity of clouds at scale:Google trace analysis.Proc.of the Third ACM Symposium on Cloud Computing,2012:397–403.
[20]J.M.Tirado,D.Higuero,F.Isaila,et al.Reconciling dynamic system sizing and content locality through hierarchical workload forecasting.Proc.of the 18th IEEE International Confe-rence on Parallel and Distributed Systems,2012:77–84.
[21]M.A.-Fares,A.Loukissas,A.Vahdat.A scalable,commodity data center network architecture.ACM SIGCOMM Computer Communication Review,2008,38(4):63–74.
[22]T.Benson,A.Akella,D.A.Maltz.Network traffc characteristics of data centers in the wild.Proc.of the 10th ACM SIGCOMM Conference on Internet Measurement,2010:267–280.
[23]M.A.Adnan,R.Gupta.Path consolidation for dynamic rightsizing of data center networks.Proc.of the IEEE 6th International Conference on Cloud Computing,2013:581–588.
[24]S.U.Malik,S.K.Srinivasan,S.U.Khan.Convergence time analysis of open shortest path frst routing protocol in Internet scale networks.Electronics Letters,2012,48(19):1188–1190.
[25]A.Chatterjee,N.D.Georganas,P.Verma.Analysis of a packet-switched network with end-to-end congestion control and random routing.IEEE Trans.on Communications,1977, 25(12):1485–1489.
Biographies

Haitao Yuan was born in 1986.He obtained his B.E.and M.E.degrees both from Northeastern University,China,in 2010 and 2012 respectively, and is currently working toward his Ph.D.degree at the School of Automation Science and Electrical Engineering,Beihang University,China.He is now doing research in cloud computing and simulation under the direction of Professor Bohu Li.He received Google Excellence Scholarship 2011.His research interests include cloud computing,resource allocation and management,software defned networking,and energy effciency.
E-mail:cityu.yuan@gmail.com

Jing Bi was born in 1979.She received her Ph.D. degree in the School of Information Science and Engineering from Northeastern University,China in 2011.At present,she is a postdoctoral fellow at Department of Automation,Tsinghua University,Beijing,China.From September 2009 to October 2010, she was a visiting student supported by IBM Ph.D. Fellowship Award in IBM Research-China.She has published more than 20 research papers in journals and conferences.Her research interests include service computing,service recommendation, cloud computing and Internet data centers.
E-mail:bijing@tsinghua.edu.cn

Bohu Li was born in 1938.He graduated from Tsinghua University in 1961 and was a visiting scholar at the University of Michigan,USA,from 1980 to 1982.He was elected a member of the Chinese Academy of Engineering in 2001.He is the president of Chinese Association for System Simulation, a member of the board of directors in the Chinese Society of System Engineering,and the vice director of Manufacturing Committee in the Chinese Society of Automation.He has received two prizes from China Science Convention,one First Class Scientifc Advancement Award and two Second Class Scientifc Advancement Awards from the State,twelve Scientifc Advancement Awards from the Chinese Aerospace and Astronautics Ministry.He is a member of the Advisory Committee of the international journal Simulation Theory& Practice.His research expertise is in the areas of distributed simulation and cloud computing.
E-mail:bohuli@moon.bjnet.edu.cn
10.1109/JSEE.2015.00020
Manuscript received March 18,2014.
*Corresponding author.
This work was supported by the National Postdoctoral Science Foundation of China(2014M550068).
杂志排行

Journal of Systems Engineering and Electronics的其它文章
- Dynamic channel reservation scheme based on priorities in LEO satellite systems
- Adaptive beamforming and phase bias compensation for GNSS receiver
- Novel dual-band antenna for multi-mode GNSS applications
- Nonparametric TOA estimators for low-resolution IR-UWB digital receiver
- Effcient hybrid method for time reversal superresolution imaging
- Adaptive detection in the presence of signal mismatch