模糊粗糙集中基于测试代价敏感的属性约简
2015-01-16颜旭徐苏平窦慧莉
颜旭,徐苏平,窦慧莉
(江苏科技大学 计算机科学与工程学院,江苏 镇江 212003)
粗糙集理论[1]是由波兰学者Z.Pawlak教授于上世纪80年代初提出的一种用于处理不确定性和含糊性问题的数学工具,其基本思想是在目标近似逼近的基础上,通过知识约简,生成简化的决策规则。目前,粗糙集理论在模式识别、机器学习、决策分析与支持、知识获取、知识发现等领域[2-4]取得了成功的应用,并成为软计算方法的重要分支。
众所周知,经典粗糙集只能有效地处理离散型数据,对连续型数据的处理能力非常有限。因此,用经典模型对连续型数据进行规则分类之前,需对数据进行离散化处理,而基于离散化的“硬划分”又降低了原始数据的精度,造成了一定程度的信息损失。庆幸的是,1990年Dubois和Prade提出了模糊粗糙集[5]理论利用模糊隶属函数的“软划分”思想很好地解决了这一问题,他们采用一对∧和∨算子对模糊粗糙下、上近似集进行了定义,该方法的提出为模糊粗糙集理论的深入发展打下了坚实的基础。
值得注意的是,目前很多粗糙集方法并不涉及代价问题,但代价普遍存在于现实工业应用中的各个角落。一方面,数据的获取往往不是免费的,是需要付出一定成本的,可称其为测试代价;另一方面,分类错误是会增加额外成本的,可称之为误分类代价,决策粗糙集就是考虑误分类代价的典型方法。文中着重考虑测试代价敏感的粗糙集约简问题,这是因为该问题近年来已引起了众多粗糙集研究学者的关注,如Min等人[6]将测试代价引入到粗糙集的约简问题中,并设计了求解具有最小代价约简的回溯算法;Yang等人[7]将测试代价问题引入到多粒化粗糙的建模中,使得粗糙集模型变的代价敏感。
上述工作都是建立在经典粗糙集模型的基础上,但考虑到经典粗糙集在实际应用中固有的局限性,故本文在模糊粗糙集的基础之上,考虑模糊粗糙集的测试代价敏感约简问题。首先利用高斯核函数求得模糊等价关系,在此基础上设计了一种融合近似质量与测试代价的适应度函数,最后借助遗传算法进行约简问题的求解。
本文主要内容安排如下:第1节介绍相关的基本知识,第2节提出了新的适应度函数,并分别采用启发式算法与遗传算法对测试代价敏感模糊粗糙集进行约简求解,分析了相关的实验结果,第3节总结全文。
1 基本知识
1.1 测试代价敏感决策系统
一个测试代价敏感决策系统S可表示为一个五元组S=(U,AT∪D,V,f,C*),其中 U={x1,x2,…,xm}为研究对象的有限集合,称为论域;AT={a1,a2,…,an}为描述对象的全部条件属性所组成的集合;D为决策属性集合且 AT∩D=Ø;V=Ua∈ATUDVa为所有属性的值域,其中Va为属性a的值域;f:U×AT→V为信息函数,表示∀x∈U,∀a∈AT∪D, 有 f(x,a)∈Va。 C*:{a1,a2,…,an}→R+∪{0}为测试代价函数,其中 C*(ai)表示单个属性ai的测试代价。
1.2 模糊粗糙集
令U≠Ø为一论域,从U到单位区间[0,1]的一个映射F:U→[0,1]称为论域 U 上的一个模糊集[5],F~(U)为论域 U 上的所有模糊集的集合,F(x)称为模糊集F的隶属函数。
定义1[8]令U为一非空论域,R是U上的一个模糊二元关系,若∀x,y,z∈U,R 满足如下 3 个性质:
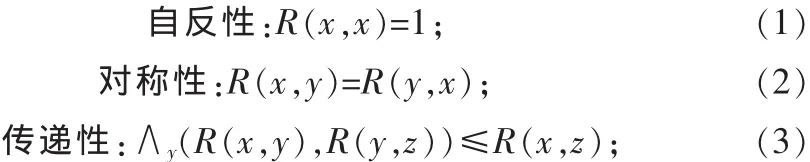
则称R是论域U上的一个模糊等价关系。
与Pawlak经典粗糙集类似,模糊等价关系是对数据矩阵进行关系提取的产物,是模糊粗糙集的核心部分。在此基础上,模糊粗糙集的定义如下所示。
定义2[5]令U为一非空论域,R是U上的一个模糊等价关系,∀F∈F~(U),F在模糊等价关系R上的模糊粗糙下近似集和模糊粗糙上近似集分别记为 R(F)和 R(F),∀x∈U,其隶属函数分别为:
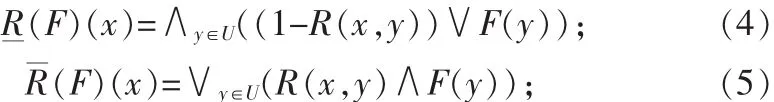
称(R(F),R(F))为 F 的一个模糊粗糙集。
1.3 近似质量
近似质量是评判条件属性A相对于决策属性D的分类能力的标准,基于模糊粗糙集的近似质量定义如下所示。
定义 3 令 S=(U,AT∪D,V,f,C*)为一个测试代价敏感决策系统,∀A⊆AT,U/IND(D)={d1,d2,...,dp}为由决策属性集 D所诱导的论域上的划分,那么D的近似质量定义为:
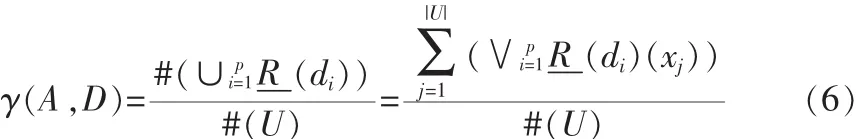
其中 #(X)表示集合 X 的基数,∨di∈U/IND(D),di为一决策类。
2 测试代价敏感模糊粗糙集的属性约简
属性约简是粗糙集理论的重要组成部分,其目的是在保持信息系统分类和决策能力不变或变化不大的情况下,删除无关或冗余属性以得出简洁、正确的决策规则。
2.1 启发式算法
定义 4 令 S=(U,AT∪D,V,f,C*)为一个测试代价敏感决策系统,A⊆AT 为一个约简当且仅当 γ (A,D)=γ (AT,D)且∀B⊆A,γ(B,D)≠γ(AT, D)。
由定义4可以看出,决策系统S中基于近似质量不变的属性约简实际上是选择保持近似质量不变的最小属性子集的过程。
令S为一测试代价敏感决策系统,∀A⊆AT,∀ai∈A,ai的重要度定义为:
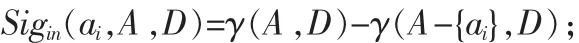
由上式可以看出,Sigin(ai,A,D)表示在条件属性子集A中删除属性ai时近似质量的变化程度。类似的,亦可定义:
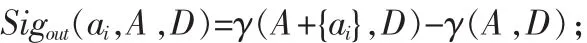
其中,∀ai∈AT-A,Sigout(ai,A,D)表示在条件属性子集 A中增加条件属性ai时近似质量的变化程度。
根据上述重要度的定义,在测试代价敏感决策系统中,一种基于贪心策略的启发式算法如下所示。

算法1.启发式算法输入:测试代价敏感决策系统S,近似质量变化的阈值ε;输出:约简的测试代价 c*(red).1)计算近似质量 γ(AT,D);2)A←Ø;3)∀ai∈AT,计算属性 ai的重要度 Sigin(ai,AT,D);4)选取 aj满足 Sigin(aj,AT,D)=max{Sigin(ai,AT,D):∀ai∈AT},A←aj,计算 γ(A,D);5)若 γ(AT,D)-γ(A,D)>ε,则执行如下循环:①∀ai∈AT-A,计算 Sigout(ai,A,D);②选取 aj满足 Sigout(aj,A,D)=max{Sigout(ai,A,D):∀ai∈AT-A},A=A∪{aj};③计算 γ(A,D);6)∀ai∈A, 若 γ(AT,D)-γ(A-{ai},D)≤ε,则 A=A-{ai};7)输出 c*(red)=c*(A).
然而值得注意的是,测试代价敏感决策系统中属性约简的目标是获得较小的测试代价,而并非具有较少的属性个数,换言之,属性个数不能直接决定约简的测试代价。算法1以选择较高重要度的属性为标准,并未切实考虑到测试代价对属性约简结果的影响。为解决这一问题,需综合考虑属性的近似质量与测试代价,并在此基础上设计新的度量标准,以求得具有较小测试代价的约简。
2.2 遗传算法
遗传算法是另一种常用的求解约简的算法。在遗传算法进化搜索较优解的过程中,适应度函数是用于评价属性集合是否满足条件的标准,是属性约简的驱动力。由算法1可以看出,测试代价敏感决策系统中属性约简的本质是在近似质量变化不大的情况下(近似质量的变化小于等于给定的阈值ε),求解相应的属性子集。因而,可重新定义一种同时考虑近似质量与测试代价的适应度函数如下所示。
定义 5 令 S=(U,AT∪D,V,f,C*)为一个测试代价敏感决策系统,适应度函数为:
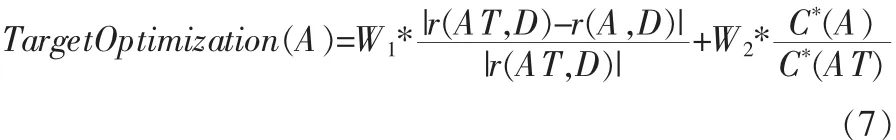
其中,γ(AT,D)和 γ(A,D)为属性约简前后的近似质量,C*(AT)和C*(A)为属性约简前后条件属性集合的测试代价。根据专家经验可给出权值W1,W2以平衡近似质量和测试代价对适应度函数造成影响的程度。
根据上述适应度函数的定义,在测试代价敏感决策系统中,一种考虑到属性测试代价的遗传算法设计如下所示。

算法2.遗传算法输入:测试代价敏感决策系统S;输出:约简的测试代价 c*(red).1)计算近似质量 γ(AT,D);2)t←1,随机产生P个长度为|AT|的二进制串组成初始种群 Pop(t);3)∀Popi(t)∈Pop(t), 计算个体 Popi(t)的适应度;4)若最优个体适应度未保持恒定,则执行如下循环:①选择:依“轮盘赌策略”选择个体,采用“最优保存策略”,从 Pop(t)中选择下一代 Pop(t+1);②交叉:依交叉概率Pc并采用“单点交叉方式”,产生由新染色体构成的新种群Pop(t+1);③变异:依变异概率Pm并采用“基本位变异方式”,生成新种群 Pop(t+1);④∀Popi(t+1)∈Pop(t+1),计算个体 Popi(t+1)的适应度;⑤t←t+1;5)最优个体对应转化为最优属性,即约简A;6)输出 c*(red)=c*(A).
遗传算法具有全局优化和并行性的特点,且充分考虑了属性的测试代价,因此用其求解测试代价敏感模糊粗糙集的约简,通常会降低计算的复杂性,减小约简的测试代价。
2.3 实验分析
本小节将通过相关实验,对启发式算法和遗传算法所求得的测试代价进行对比分析。
表1列出了实验中使用的8组测试数据集的基本信息,所有数据集均源于UCI机器学习库。由于UCI中大部分数据集不含有测试代价,所以在本组实验中为每组数据集的属性随机分配10组[0,100]之间的测试代价。实验选用高斯核函数计算数据集中每个属性ai所构建的模糊相似关系Ri,其中对象xj与xk之间的相似度记为:
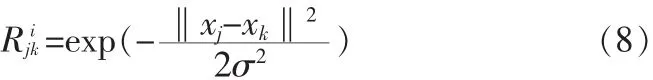
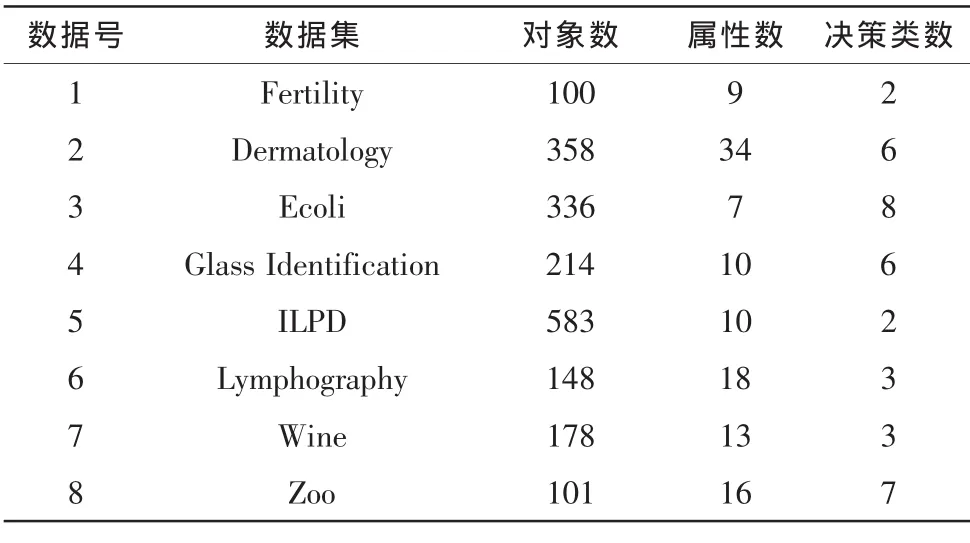
表1 数据集基本信息Tab.1 Data sets description
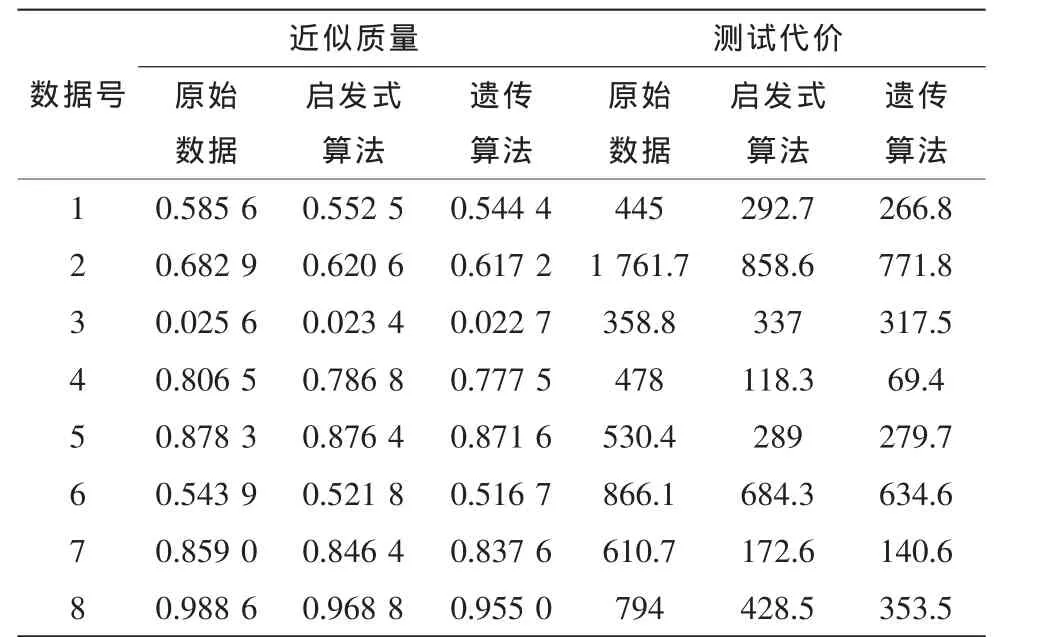
表2 两种约简算法所求得的近似质量和测试代价与原始值对比Tab.2 The comparison of approximate qualities and test costs between two algorithms and raw data
根据表2可以看出,启发式算法和遗传算法得到的近似质量与原始数据的近似质量差距不大,但根据遗传算法所求得约简的测试代价要低于由启发式算法所求得约简的测试代价。所以新提出的考虑属性测试代价的适应度函数在测试代价敏感模糊粗糙集的属性约简中有较好的表现力。
3 结束语
为满足实际应用的需求,本文在充分考虑了数据测试代价的基础之上,提出了一种基于新适应度函数的遗传算法以获得较小测试代价的约简,并从实验分析的角度,将其与原先的启发式算法进行了对比。通过实验可以发现,以新设计的适应度函数为目标的遗传算法相比启发式算法在一定程度上能够获得较小的测试代价的约简。
在本文研究工作的基础之上,下一步工作可围绕以下方面展开:
1)在模糊环境下,综合考虑数据的误分类代价和测试代价,设计行之有效的适应度函数以获得具有较小整体代价的约简;
2)基于测试代价敏感模糊粗糙集的分类器设计并与其它分类器的对比。
[1]Pawlak Z.Rough sets[J].International Journal of Computer and Information Sciences,1982,11(5):341-356.
[2]Chen J K,Li J J.An application of rough sets to graph theory[J].Information Sciences,2012,201:114-127.
[3]Yeh C C,Lin F,Hsu C Y.A hybrid KMV model, random forests and rough set theory approach for credit rating[J].Knowledge-Based Systems, 2012, 33:166-172.
[4]Yang X B,Song X N,Qi Y S,et al.Constructive and axiomatic approaches to hesitant fuzzy rough set[J].Soft Computing,2014,18(6):1067-1077.
[5]Dubois D,Prade H.Rough fuzzy sets and fuzzy rough sets[J].International Journal of General System,1990,17(2-3):191-208.
[6]Min F,He H P,Qian Y H,et al.Test-cost-sensitive attribute reduction[J].Information Sciences,2011,181(22):4928-4942.
[7]Yang X B,Qi Y S,Song X N,et al.Test cost sensitive multigranulation rough set:model and minimal cost selection[J].Information Sciences,2013(250):184-199.
[8]Wu W Z,Mi J S,Zhang W X.Generalized fuzzy rough sets[J].Information sciences,2003(151):263-282.
