基于虚拟化的声纹识别系统性能研究
2015-01-05潘松松田文洪
佘 堃,潘松松,田文洪
(电子科技大学,四川成都611731)
0 引言
在认证技术领域中,使用密码进行加密和解密是最常见的、最简单的技术,得到了广泛的应用。然而这种身份认证方式存在很大的弊端,简单的容易被破解,复杂的容易被遗忘。随着互联网系统的爆发式发展、计算机技术和密码学的深入研究,密码的安全性面临着严峻的考验,传统的密码身份认证很难满足现代安全、便捷的需求[1]。
相对地,生物特征识别成为了一种很好的技术创新突破口。声纹识别(又称说话人识别)是一种通过语音数据识别说话人身份的生物识别技术,近年来受到众多研究机构和企业的追捧,加快了理论研究和实际应用开发的进展[2]。人的声道结构、说话习惯都是唯一的、长期稳定的,这使得每个人发出来的声音都具有独特性。声纹识别就是从说话人说话语音中提取具有代表性的声纹特征,以此识别说话人的真实身份。因为声纹识别具有经济性、非接触性、准确性的特点,可以打破局域和时间的限制,得到电话社保身份确认、公安司法案件侦破、银行或证券身份识别、国防安全等领域的青睐[3]。
但是在实际应用中,声纹模型训练和身份识别会涉及到大量的语音数据存储和声纹信号处理算法运算。随着用户数量的急剧增加,需要处理的语音数据量就越多,它对数据中心和计算资源的要求也越高,依赖性也就越强,相应的应用种类也就会增加,功能变得更多,系统更复杂,管理也就变得更困难,成本更高[4]。
而云计算正是从服务提供者的角度给出的一种解决办法。通过虚拟化技术把物理资源(CPU、存储空间、操作系统、应用程序开发环境等)分成多个虚拟化空间,彼此互不影响。用户无需关心具体物理机的位置或性能,直接通过网络获得高效的计算和存储能力。
文中引入云计算技术,把声纹识别系统运用于虚拟化环境中,实现一个结合虚拟化技术的声纹识别系统,评估系统的整体运算性能。
1 相关工作
人依靠听觉能够分辨说话人的身份,那么说话人语音中必然包含独特的身份信息。但是机器是无法直接识别的,需要从声纹中提取出机器能够识别的数据和理解的识别公式。在声纹识别技术的研究中,从声纹中提取说话人的身份特征信息,称为声纹特征向量[5]。
根据文献[6]的研究显示,特征提取的根本目标就是降维,用少量的矩阵维数记录说话人的语音特征。线性预测倒谱系数(LPCC)、线谱对(LSP)、线性预测残差等线性预测分析出来的特征参数无法准确地表达出听觉特征,人耳对于不同频率的感知能力与声纹频率不是呈现线性关系。对此提出了Mel频率的特性,更能符合并表达出实际听觉特征,在与文本无关的声纹识别应用领域中,MFCC(Mel-Frequency Cepstrum Coefficients)的特征提取方法比线性预测方法在识别方面更占优势。
声纹特征提取后,就需要模型进行描述声纹特性,模型的选择和建立都至关重要,直接影响声纹识别的性能。根据文献[7]和文献[8]的研究表明,混合模型(Gaussian Mixture Model,GMM)具有卓越的性能优势,在多种领域中被广泛使用。高斯混合模型是一种多组高斯分布(亦称正态分布)的线性迭代模型。由于多组正态概率密度函数的线性加权和可以模拟任意分布,所以一个人的声纹特征也可以由GMM来描述。每个人的声纹特征都是不一样的,即其统计出来的声纹特征分布也是有区别的、唯一的,所以可以通过GMM建立生成的声纹特征模型对比说话人的身份。但是随着GMM的训练阶数的增加,就会造成系统花更多的计算资源和计算时间,这将对声纹识别系统带来很大的性能挑战。
文献[9]研究了在云计算环境中,虚拟机粒度对工作负载性能的影响。采用HPL作为代表紧密耦合的计算工作量,性能评估的结果显示了虚拟机粒度对计算工作量的性能有显著的影响。在配置有8个CPU的服务器,处理问题大小为4096的HPL,采用8个虚拟机的性能效果比4或16个虚拟机的性能高出4倍,是最为出色的。而12个CPU的服务器处理问题大小为256到1024的HPL,采用24个虚拟机达到了性能最佳状态。文献[9]还表明VM粒度对Web系统的性能的影响并不重要,VM粒度只是动态改变了VM延展性策略,可用于提高紧密耦合的计算工作负荷的性能。
而把声纹识别系统运用于虚拟化环境中,实现一个结合虚拟化技术的声纹识别系统,此过程会变得更加复杂,涉及到声纹识别算法的大量计算、与前台进行信息交互、虚拟机的调用等,会是一个紧密耦合的综合性云系统[10]。
2 结合虚拟机技术的声纹识别系统设计
研究如何把虚拟机技术结合到声纹识别系统之中,最常见的设计想法就是在物理机上运行多台虚拟机,同时把物理机上原来的运行环境系统重新部署到虚拟机里,形成虚拟机集群,那么一台物理机就可以并发运行声纹识别系统,提高系统的效率。但上述理论模型在实际应用过程中可能会出现如下的情况:如果有些识别任务被分配到正在运行识别任务的虚拟机(忙状态的虚拟机)上,这些识别任务就会等待,呼叫中心(前台)的请求就会延迟,甚至请求超时,得不到响应,这样反而降低了系统的性能和使用效果。这就相应地引出一个致命的问题——如何合理调度虚拟机资源,结合整个系统的基本架构,对此制定了两套调度方案:方案一是在虚拟机服务器上做修改,每个虚拟机上添加一个监视器,监视虚拟机的运行状况(忙状态还是闲状态);在物理机上添加虚拟机调度模块,根据虚拟机的状况,调度一台空闲状态的虚拟机给呼叫中心使用,运行识别算法。具体执行方案如图1所示。
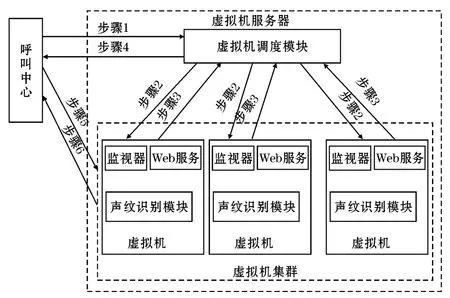
图1 基于监视器的调度方法
步骤1:呼叫中心需要获取虚拟机资源时,向虚拟机服务器的调度模块发送调用虚拟机的请求。
步骤2::调度模块接收到呼叫中心的请求后,会向所有开启的虚拟机发送检测虚拟机运行状况的请求。
步骤3:如果虚拟机接收到调度模块发送过来的服务请求,虚拟机的监视器会监测到本台虚拟机的CPU使用率、内存消耗情况、运行时间、调度的次数,根据这些反馈的参数得到虚拟机的状态(忙状态还是闲状态),然后响应调度模块的请求。
步骤4:调度模块接收到所有虚拟机的响应后,选择出一个空闲状态的虚拟机,把这台虚拟机的ip地址发送给呼叫中心,作为步骤1的响应数据。
步骤5:呼叫中心获得虚拟机的ip地址后,就可以调用这台虚拟机的Web服务,向其发送声纹识别的运算请求。
步骤6:虚拟机将识别结果反馈给呼叫中心,完成整个识别任务。
6个步骤全部完成才能实现整个后台调用运算,只要其中任何一步出现问题,就会造成识别任务的失败。监视器监测虚拟机的运行情况,时时刻刻在后台运行,反馈虚拟机的健康情况。再由调度模块根据具体参数设计合理地调度算法,分配空闲的虚拟机资源,这个过程会一直抢占服务器和虚拟机的资源。从开发和系统结构角度考虑,基于监视器和虚拟机调度模块的系统架构设计加重了系统的任务模块和复杂度,增加了耦合性和开发周期,系统崩溃的风险也随之提高[11]。
另一套方案是根据语音卡本身的调度机制,拓展并实现调度虚拟机的功能。语音卡支持的分路线数是有限的,是跟网络接口所拥有的网络物理线数一一对应的[12]。一般情况下模拟语信号音卡支持的语音通道线数大多为8条或16条;而数字信号语音卡的语音通道线数依据E1接口的数量决定的,每个E1接口支持30个语音通道线数。多块语音卡也可以一起使用来共同完成语音处理功能,语音卡之间不需要经过计算机总线,可以直接通过语音卡内部语音总线相互连接通信,实现数据的交换和通信。语音卡本身就有自动调用语音通道的机制,提供调用空闲语音通道、释放语音通道、等待语音通道等功能。就可以利用语音卡的语音通道调度机制,结合一个闲状态的虚拟机ip池,实现一种高效的、精简的虚拟机调度模块。具体执行方案如图2所示。
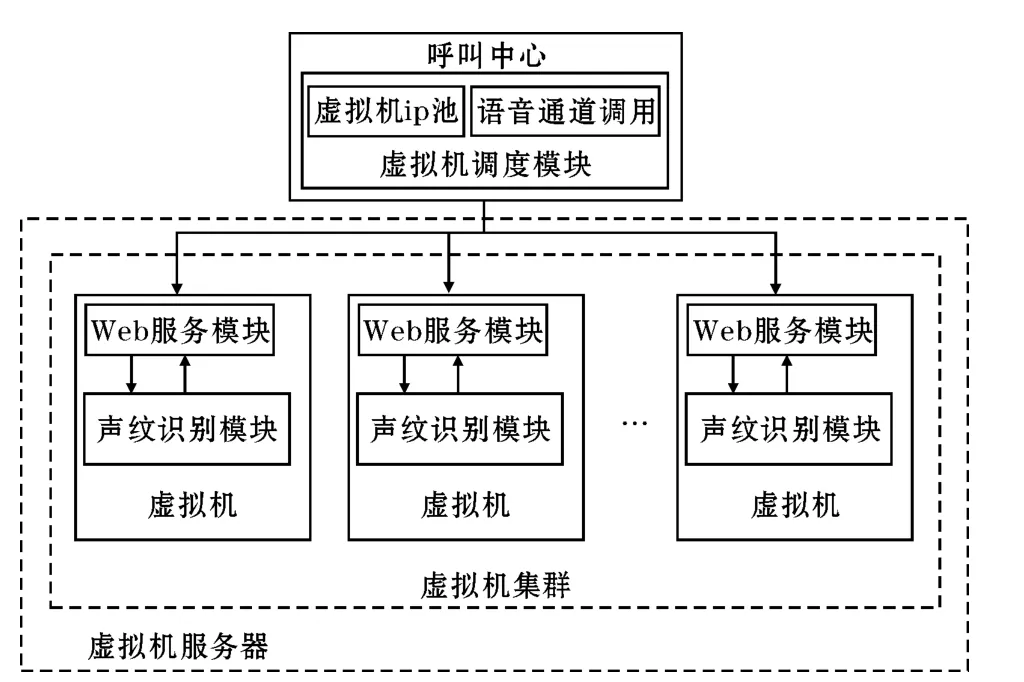
图2 基于语音通道调度机制的虚拟机调度方法
这种虚拟机调度方法明显比上一个方案的方法要简单很多,虚拟机调度模块的实现直接在呼叫中心实现,不需要在虚拟机或虚拟机服务器物理机上添加其他系统模块,降低了系统的耦合性,减轻了虚拟机服务的运行负担。当一个空闲的语音通道被启用时,系统会从闲状态的虚拟机ip池中分配给此语音通道一个有效的、空闲状态的虚拟机ip地址,提供虚拟机资源。当语音通道资源被释放时,系统就随之把虚拟机ip资源还原到闲状态的虚拟机ip池中,释放虚拟机资源。
3 结果与分析
系统所采用的语音样本库是由20位测试者录制而成的,其中男女各有10人,年龄跨度从20多岁到50多岁,语言限制为普通话。每个测试人员录制了一组包含8段短语音的训练语音样本,以及3组(每组包括3段短语音)以上的识别语音。录制的内容都是根据制定的问题回答的,应答时间设置为10秒,完全能够保证用户淡定自然、语速缓和、吐字清晰地应答问题。每个测试人员在进行语音注册和识别阶段用的是同一部手机,手机的品牌和型号选择也加以限制,确保语音样本的质量。所有的语音采集过程都是在安静的测试环境中完成的,经过呼叫中心生成unsigned 8 bit、A-Law编码方式、采样率8000 Hz、位速64 kbps、单声道的WAV格式语音样本。
系统采用Pentium Dual-Core CPU E5300@2.60 GHz(1 个 CPU)、4 GB(海力士 DDR3 1333 MHz)、Microsoft Windows Server 2008(64 bit)操作系统的2台服务器。其中一台直接部署声纹识别系统,用于顺序执行识别任务的计算性能。另一台开启了4台Oracle VM VirtualBox虚拟机,每台虚拟机都搭建声纹识别系统,用于并发执行识别任务的计算性能。通过获取样本语音库中的所有训练模型语音和一组识别语音,在两台服务器中都执行4次模型训练和身份识别任务,并统计相应的运行时间。
3.1 模型训练的性能比较
按照测试执行方案,统计出建模训练在物理机上顺序执行所耗时间,如表1所示。
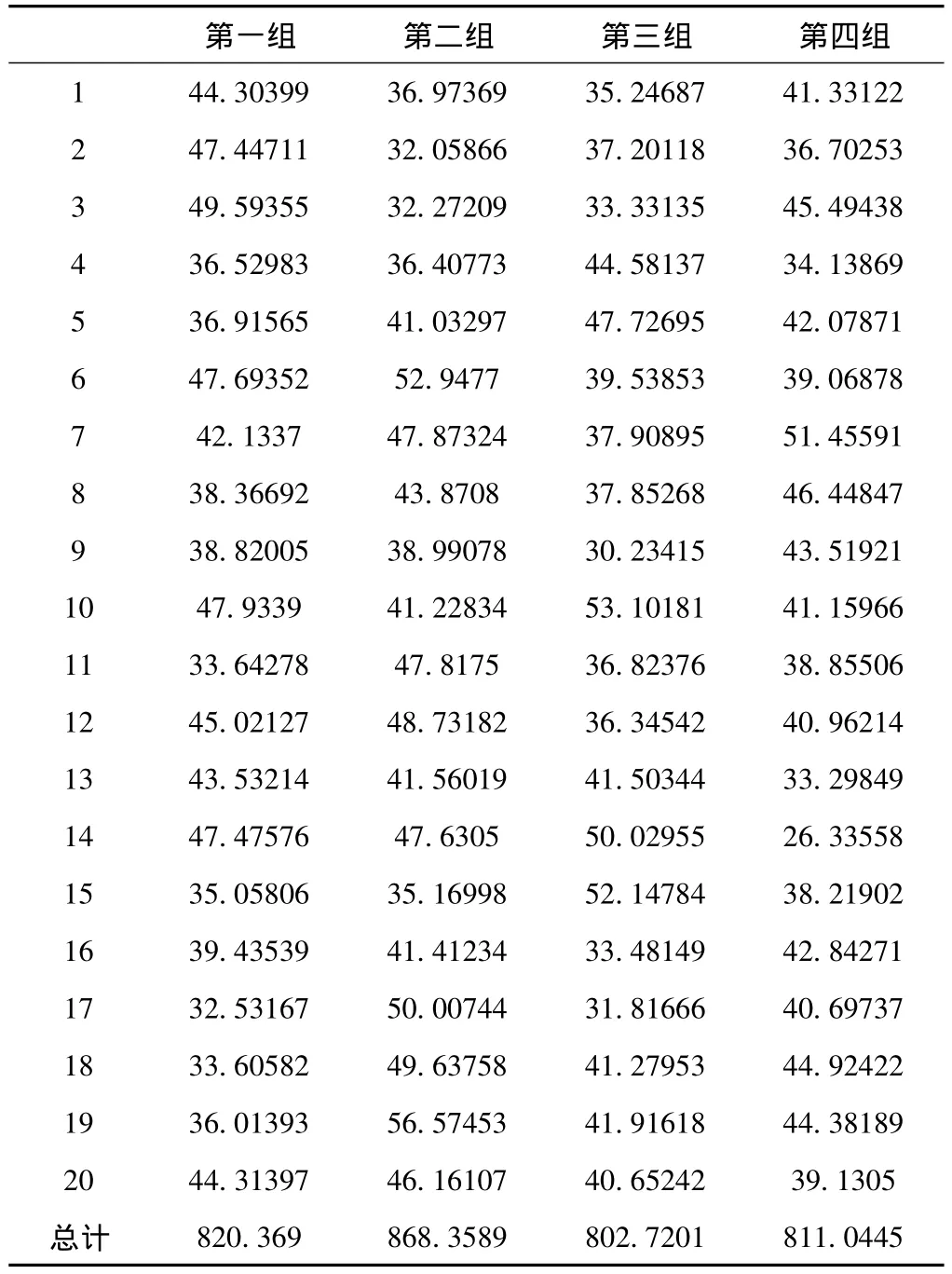
表1 建模训练在物理机上顺序执行所耗时间/s
由于本次系统是对20位测试者的模型进行顺序执行的训练,所以表1中的合计时间是20位测试者进行模型训练所耗时间的总和,最终的测试所耗平均时间是825.623125秒。
建模训练在虚拟机群上并发执行所耗的时间,如表2所示。
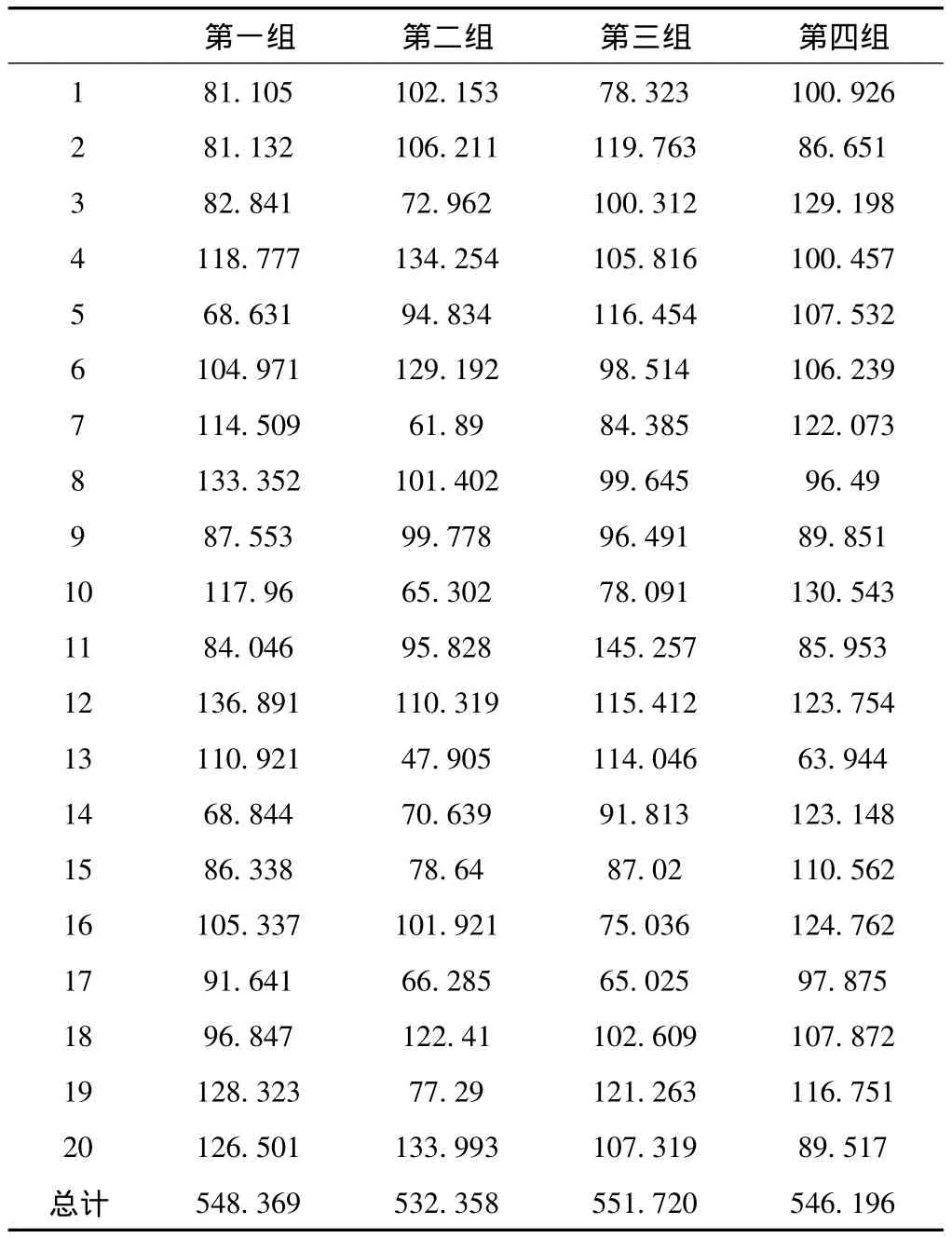
表2 建模训练在虚拟机群上并发执行所耗时间/s
由于虚拟机服务器系统的最大并发执行能力是同时运行4台虚拟机,所以共同执行20位测试者的模型训练任务,所耗时间如表2所示的所用总时间,所耗的平均时间是544.66075秒。在声纹建模阶段,顺序执行和并发执行的时间比对,如图3所示。
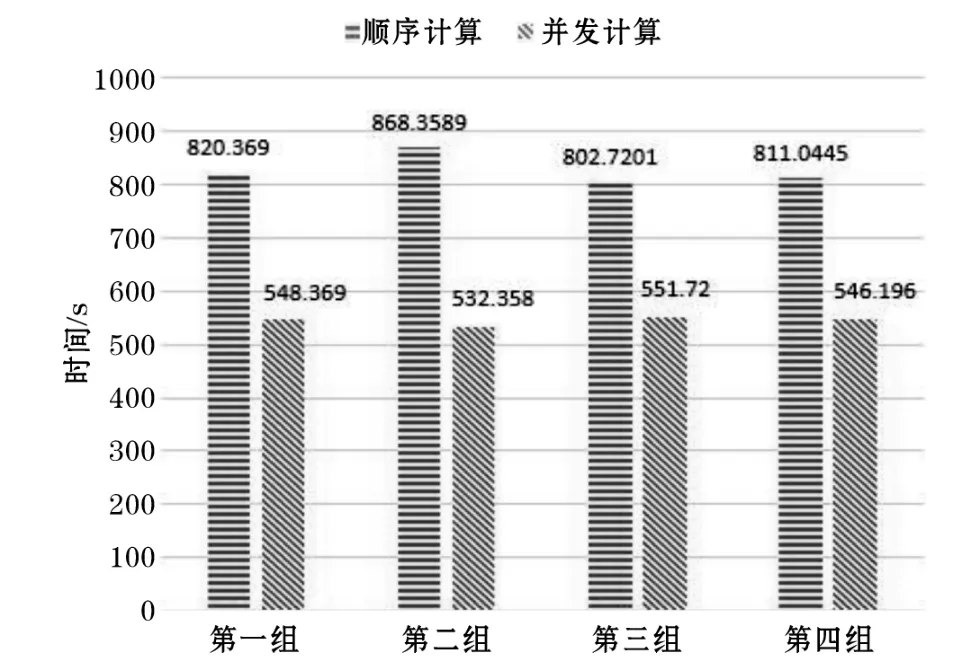
图3 顺序和并发执行模型训练所耗平均时间
根据图3,虚拟机并发在执行建模训练的性能比顺序执行提高了34.03%。
3.2 声纹确认的性能比较
声纹确认的性能测试,跟模型训练的测试一样。统计出声纹确认在物理机上顺序执行所耗时间,如表3所示。
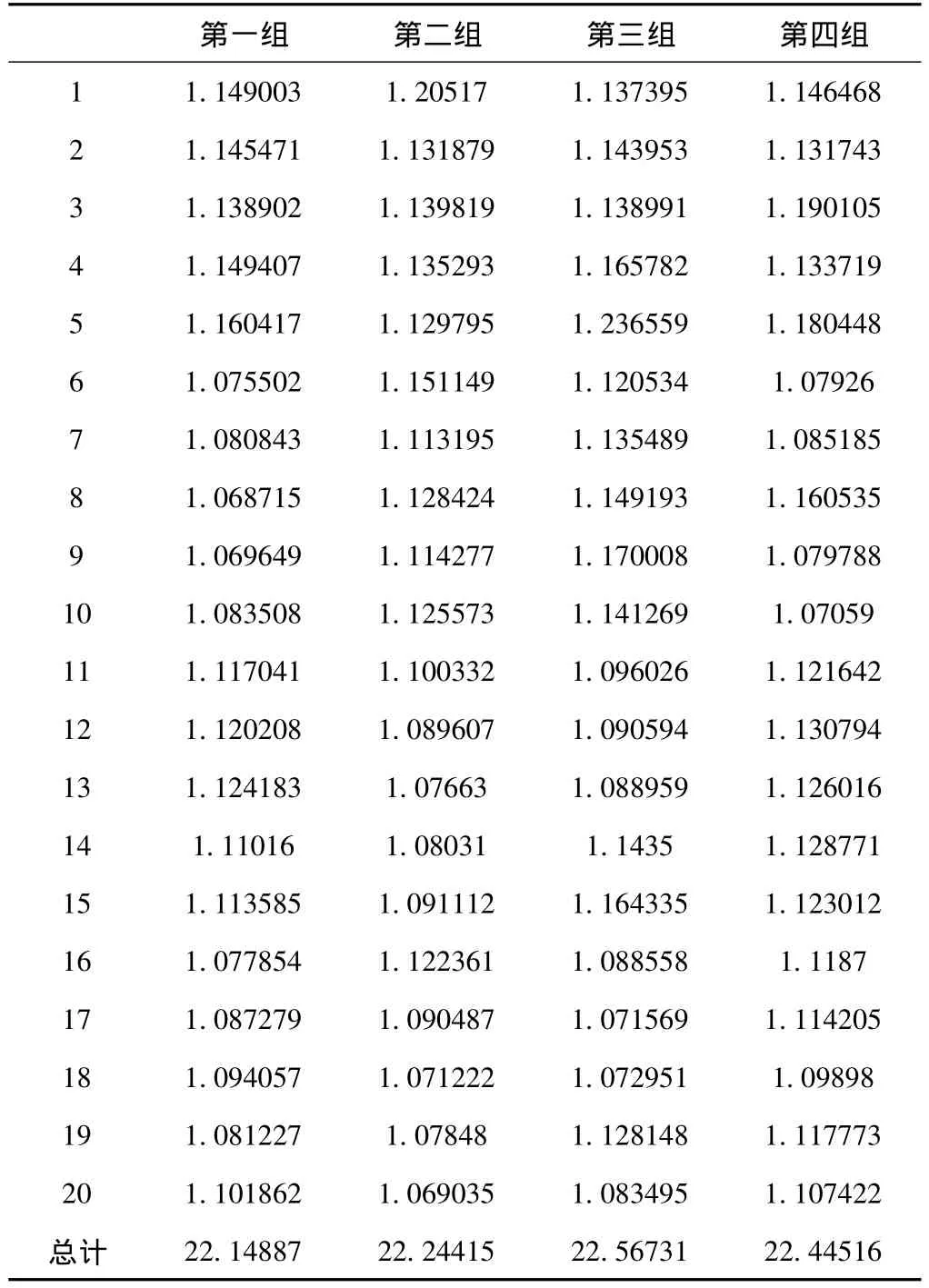
表3 声纹确认在物理机上顺序执行所耗时间/s
由于系统是顺序执行20位测试者的声纹确认,所以表3中的合计时间是20位测试者声纹确认所耗时间的总和,最终的测试平均时间是22.35125秒。声纹确认在虚拟机群上并发执行所耗时间,如表4所示。
由于虚拟机服务器系统的最大并发执行能力是同时运行4台虚拟机,所以共同执行20位测试者的身份识别任务,所耗时间如表4所示的所用总时间,所耗的平均时间是7.06125秒。在声纹确认阶段,顺序执行和并发执行的时间比对,如图4所示。
根据图4所示,虚拟机并发在执行声纹确认的性能比顺序执行提高了68.41%。
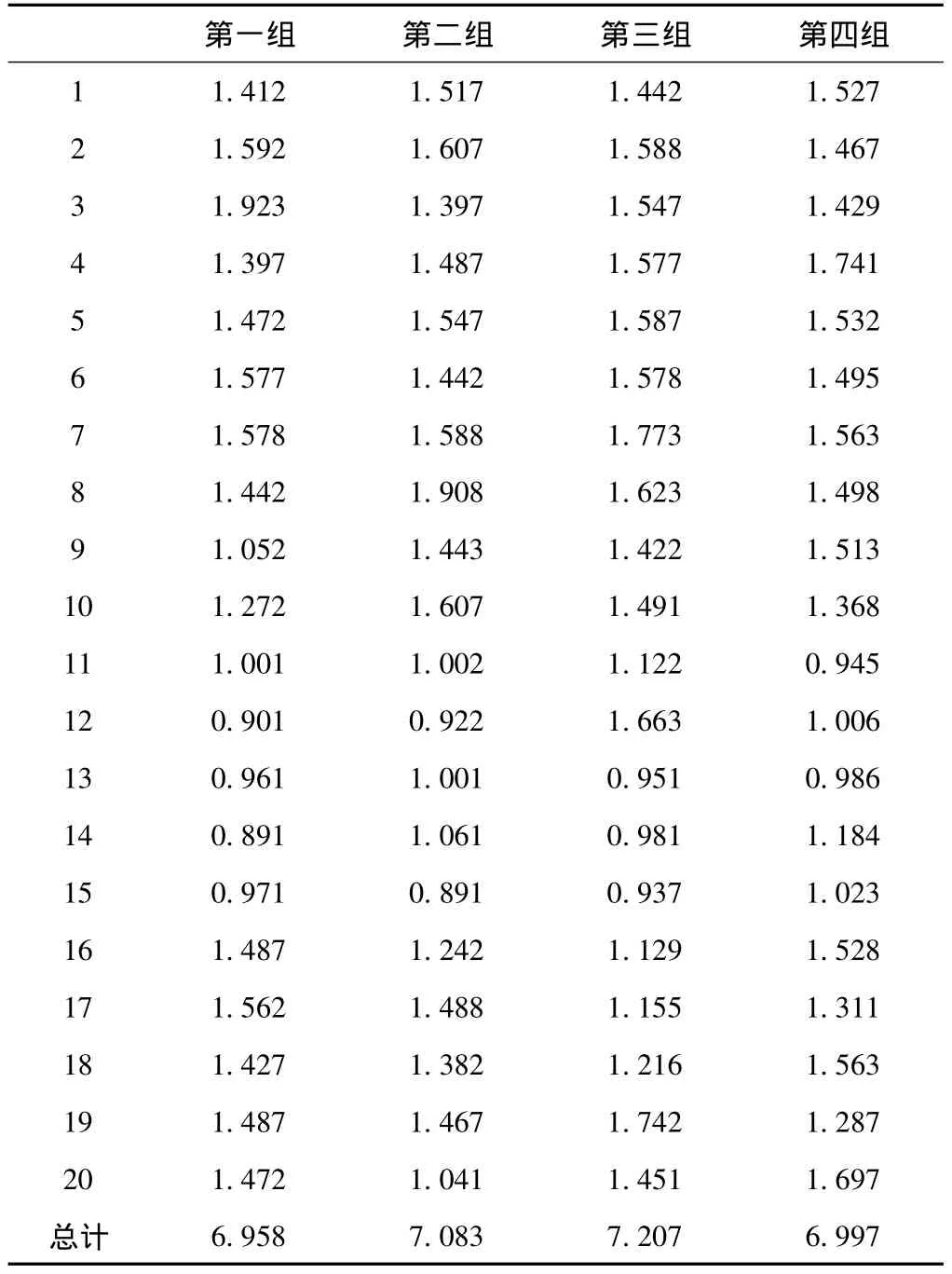
表4 声纹确认在虚拟机群上并发计算所耗时间/s
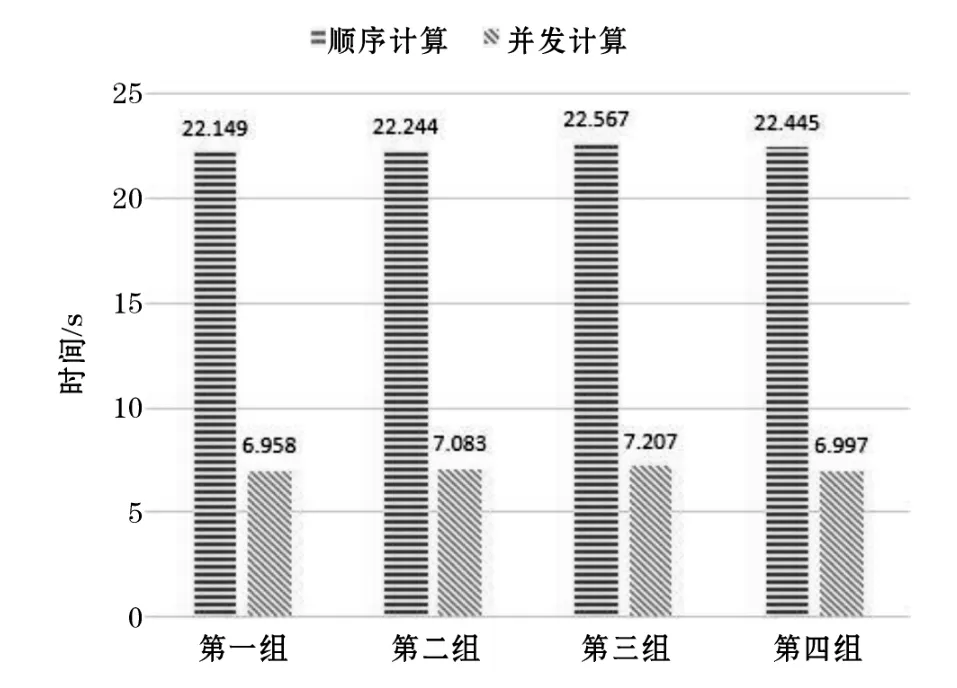
图4 顺序和并发执行声纹确认所耗平均时间
4 结束语
论文主要是将声纹识别系统与虚拟化技术相结合,解决声纹模型训练和身份识别的大量数据分析运算,提高整体系统的执行效率。在单CPU服务器的环境中,比对了部署4台虚拟机与单独物理机的执行性能。虚拟机并发在执行建模训练的性能比物理机执行提高了34.03%,执行声纹确认的性能比物理机执行提高了68.41%。
[1] 李建华.探究网络信息安全管理中多因素身份认证的使用[J].电子技术与软件工程,2015,(4):231-232.
[2] 白燕燕,胡晓霞,郑三婷.基于听觉特性的声纹识别系统的研究[J].电子设计工程,2015,(4):85-87.
[3] 庞景旭.关于音频司法鉴定技术的研究[J].法制博览,2014,(19).
[4] 孙熙领,陈超,丁治明,等.云计算环境中基于访问量和依赖性评价的数据分配算法[J].计算机科学,2012,39(5):141-146.
[5] 尹许梅.基于MFCC和矢量量化的说话人识别算法研究[D].长沙:湖南大学,2011.
[6] 胡政权,曾毓敏,宗原,等.说话人识别中MFCC参数提取的改进[J].计算机工程与应用,2014,(7):217-220.
[7] 于娴,贺松,彭亚雄,等.基于GMM模型的声纹识别模式匹配研究[J].通信技术,2015,(1).
[8] 许东星.基于GMM和高层信息特征的文本无关说话人识别研究[D].合肥:中国科学技术大学,2009.
[9] Ping W,Wei H,Varela C A.Impact of Virtual Machine Granularity on Cloud Computing Workloads Performance[C].Grid Computing(GRID),2010 11th IEEE/ACM International Conference on.2010:393-400.
[10] 谢霞.基于数字语音卡的智能语音外呼系统[J]. 电子技术与软件工程,2015,(5).
[11] 陈任之,黄立波,陈顼颢,等.单节点多GPU集群下HPL动态负载均衡优化[J].计算机科学,2013,40(3):107-110.
[12] Kochut A.On Impact of Dynamic Virtual Machine Reallocation on Data Center Efficiency[C]//Modeling,Analysis and Simulation of Computers and Telecommunication Systems,2008.MASCOTS 2008.IEEE International Symposium on.IEEE,2008:1-8.
[13] Desell T,Maghraoui K E,Varela C A.Malleable applications for scalable high performance computing[J].Cluster Computing,2007,10(3):323-337.
