基于Hadoop高性能查询的空间数据库设计与实现
2014-04-01,,b
, ,b
(河南大学 a.计算机与信息工程学院; b.数据与知识工程研究所, 河南 开封 475001)
随着现代科学的发展,要求大量空间数据的高性能查询被用于越来越多的学科领域。数据和计算密集型的大规模空间数据的出现对管理和查询海量空间数据提出了挑战。本文以Hadoop为基础提出了一种Hadoop Spatial的空间数据管理和查询系统的设计思想,用于在Hadoop上运行的高性能空间查询的可扩展的分布式空间数据仓库系统。Hadoop Spatial的中心是Hadoop框架。Hadoop由一个数据存储层或Hadoop分布式文件系统(HDFS)和一个数据处理层或MapReduce的框架组成[1-2],通过支持多种类型的空间分区,以Hadoop的数据仓库检索工具在MapReduce的隐式并行空间执行查询。它采用全局分区索引与可自定义的按需局部空间索引相结合的方式来实现高效的查询处理[3]。
传统的空间数据库管理系统(Spatial DataBase Manager System,SDBMS)虽然采用并行RDBMS架构,具有可扩展性,但是并不能管理和查询大量的空间数据。并行SDBMS一般通过多个并行磁盘数据来分区,以减少I/O瓶颈和计算密集型操作步骤。对于多个数据库分区的平衡数据和任务负载来说,并行SDBMS架构缺乏有效的空间分割机制。高数据负载的开销是SDBMS解决方案的一大瓶颈。通过并行数据库向外扩展的空间查询研究虽然可行,但其代价昂贵,需要复杂调整,以获得最佳性能。因此,用廉价的硬件设备通过高速的网路连接取代传统的空间数据库管理系统是大数据研究与应用的发展趋势。本文将具有查询高响应和高可扩展性的Hadoop Spatial与并行SDBMS系统进行对比来证明Hadoop Spatial的可行性。
1 Hadoop Spatial设计
Hadoop Spatial的主要目标是开发一个高可扩展、高性价比、高效率和表现力的综合空间查询处理的数据和计算密集型应用的空间查询系统,以便将基于大数据查找的任务在Hadoop Spatial上借助MapReduce的优势化解成分布式任务运算。为了实现这样的系统,本文将其分解成小的任务且并行处理这些任务。将空间数据按照经纬度方格划分成区域(Area),并行处理这些区域,生成的区域成为单元,可用于查询处理。查询处理的问题就变成了设计一个以区域为单元查找的可以并行运行的任务。基于此,本文提出一个基于MapReduce的典型空间查询步骤:①将空间数据和图片数据按经纬度进行划分,按照经纬度方格划分为Area区域;②将数据按照空间数据模型进行处理,将数据存储在HDFS中;③在执行查询时,将空间查询语句解析成MapReduce任务;④执行MapReduce任务并将执行结果存储到HDFS中,然后输出。
1.1 空间数据库结构设计
由于Hadoop Spatial是一个基于Hadoop的数据存储和计算的查询系统,因此其数据库架构模式和普通数据库的大致结构没有太大的区别,都有自己的查询语言、编译器,以及围绕查询语言编译器的查询语言解析器和优化工具。只不过Hadoop Spatial是基于Hadoop进行数据存储,并采用基于MapReduce的Hive查询工具扩展实现的分布式空间数据库系统。具体的数据库架构模式如图1所示。
(1)空间数据的录入:空间数据的录入主要功能是将空间数据整理并录入,包括图片数据的录入。图片数据的录入主要是对图片数据进行编号整理以及图片数据的压缩存储功能。
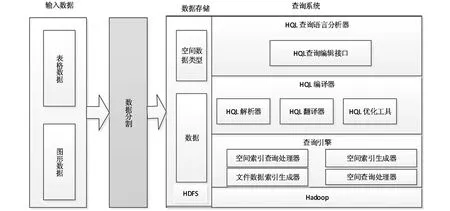
图1 Hadoop Spatial空间数据库基本架构
(2)空间数据的存储:空间数据的存储主要是以Hadoop平台为基础,将数据分布式的储存在各个不同的数据节点中。数据的存储和读取依赖于HDFS系统。只需要按照Hadoop进行配置即可。
(3)HQL查询语言分析器:作为空间数据库的查询语句分析器,实现了查询语句的编辑功能。
(4)HQL编译器:以Hadoop的一个数据仓库工具Hive为基础实现。由于Hive不支持空间查询,因此需扩充Hive功能,以支持空间查询分析。其中的解释器、编译器、优化器完成 HQL 查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在 HDFS 中,随后由MapReduce调用执行。
(5)空间索引生成器:进行空间查询的一个基本要求就是快速响应,使用空间索引来支持空间查询是大多数并行空间数据库的方法。分布式的数据库不同于并行空间数据库,分布式索引强调如何实现索引数据的分布式查找。
(6)文件数据索引生成器:这是根据图片数据的需要构建的索引。在本系统中,图片数据的索引建立在通过文件名称的索引机制上。
(7)空间查询处理器:作为空间查询引擎的关键,通过条件过滤掉的数据,进行空间逻辑运算。
1.2 空间数据模型建立
空间数据模型是描述GIS空间数据组织和进行空间数据库设计的理论基础[4]。本文在Hadoop Spatial中采用了最新的、以Geodatabase数据模型为基础设计的面向对象的空间数据模型。Geodatabase是将空间对象的属性和行为结合起来的智能化地理数据模型。它以关系数据库为基础,利用关系数据库的数据处理能力对空间数据和非空间数据进行统一管理[4]。地理数据库对空间数据的存储、管理和应用功能是通过SDE(Spatial Database Engine 空间数据库引擎)来具体实现的。
1.3 空间数据的分区
空间数据分区可提供数据分割,并生成一组瓦片用于查询任务的处理单元。空间分区实现了数据分区和计算的并行化。空间数据分区可减缓空间数据在进行分布式查询时的数据倾斜问题。
由于MapReduce拥有自己的作业调度平衡方案,因此对空间数据的分区主要专注于突破密度区域,将空间数据分成若干小的区域并采取递归分割数据。每个切片的文件大小可能很小,比如几MB,不能直接存储到HDFS。这是由HDFS对大数据块批量处理而优化的特性决定的[5]。因此,数据暂存到HDFS中,需要将所有切片合并成大型文件,而不是将每个切片作为一个单独的文件存储。
1.4 Hive
Hive是一个开源的基于MapReduce[6]的Hadoop的数据仓库工具。它可以将结构化的数据文件映射为一张数据库表,并提供完整的查询功能,也可将查询语句转换为MapReduce任务来运行,极大地简化了开发中的MapReduce应用程序[7]。其查询语言类似于SQL,可命名为HQL,可以通过类SQL语句快速实现简单的MapReduce任务,不必开发专门的MapReduce应用,十分适合用作数据仓库工具。
2 系统扩展与空间数据库查询的实现
Hadoop Spatial在数据查询方面借用了Hadoop的分布式计算,以加快数据查询的速度。因此,为了实现Hadoop的空间查询能力,给MapReduce提供一个集成的查询语言,就要实现Hive查询工具对空间查询的支持,扩展Hive的翻译器功能,实现翻译器对一些空间查询操作符、空间计算方法以及空间数据类型的支持,可命名为Hive for SP。
2.1 Hive支持空间查询扩展的实现
在开发Hive for SP时,本文以当前流行的空间数据查询方式对SQL进行扩展,以支持空间查询。SQL作为发展成熟的结构化查询语言,具有面向问题和接近自然语言的良好特征,而空间数据中的查询和分析是空间和属性的双重相关。SQL3是最新的SQL标准,不仅对SQL的语法规则做出了更加详细和准确的定义,而且对空间数据库的支持做了统一描述,使得长期以来令GIS开发者困扰的空间数据存储问题得到了解决。在SQL的基础上进行扩展将是管理和分析空间数据的一个趋势[8]。
由于HQL是类似于SQL的基于Hadoop的分布式查询语言,因此只要扩展HQL对空间查询的支持即可。
Hive for SP支持以下基本的空间查询:空间操作符、常用的空间计算方法、空间数据类型、空间关系的比较以及高效的查询空间的访问方法处理等。本文参考文献[9]的相关理论对Hive进行了处理。这里不再具体描述。
2.2 空间数据查询、访问的实现
Hive中编译器处理的HiveQL字符串可能是一条DDL、DML查询语句。编译器将字符串转化为策略(plan)。策略仅由元数据操作和HDFS操作组成。元数据操作只包含DDL语句,HDFS操作只包含LOAD语句。对插入和查询而言,策略由MapReduce任务中的具有方向的非循环图(directedacyclic graph,DAG)组成[7]。因此,在对Hive进行扩展,实现控件查询的支持时,只对编译器进行扩展即可。
Hive采用传统的plan-first, execute-next方法[10]进行查询处理的步骤有3个:查询翻译、逻辑计划生成和物理计划生成。用SQL表达式查询时,首先解析查询并生成一个抽象语法树。接着对由抽象语法树转换为运算符树的逻辑方案以及诸如谓词下推的查询优化技术进行应用;然后根据操作树生成一系列MapReduce任务;最后将产生的MapReduce任务提交给Hive运行。因此,在对Hive扩展时,在查询翻译中增加对上文2.1中的查询关键字的支持,并在逻辑计划生成的步骤中生成对应的查询任务即可。
由于空间连接是在最常用和昂贵的查询中进行的,因此有必要讨论空间连接查询映射到MapReduce的计算模型。
以图2的交叉查询为例,详细描述如何将HQL语句转化为MapReduce任务。

图2 一个空间交叉查询的例子
首先在Map阶段,输入表进行扫描,按照where条件进行数据筛选。满足条件的数据被筛选出来,生成下一步进行Reduce操作的key/value对。数据key为该对象所在的区域ID(AreaID),value是SELECT子句中指定的列组合。
其次在Shuffle阶段,Hadoop内部执行机将Map阶段查到的数据按照Key进行分组。
最后在Reducer阶段,对符合条件的记录,通过调用Hive建立基于R *树的索引,并执行查询,进行空间运算。
查询转换的具体伪代码如图3所示。

图3 空间连接查询的MapReduce伪代码
在Hadoop Spatial中,数据按照划分的区域被存储。包含查询以及聚集查询的数据可以根据查询进行过滤和筛选。这仅是一个简单的数据查找过程,不在这里具体描述。
3 实验与分析
为了验证Hadoop Spatial数据库的系统性能,本文针对空间数据库的一些常用操作进行了性能测试,并与当前的商业用分布式数据库系统进行对比。
3.1 实验设备
使用10台Hadoop Spatial方面的服务器搭建该系统。该系统硬件设备的主要配置如下:单服务器8核CPU、4 GB主存、500 GB的硬盘存储空间、1 GB的互连网络。操作系统为CentOS 5.6(64位)。以Hadoop 2.1.0作为MapReduce平台,以Apache Hive 0.7.1为基础开发的Hive for SP 1.0的大部分配置参数都被设为默认值。
为将Hadoop Spatial和并行SDBMS进行比较,实验安装了一个商业SDBMS(Oracle 10g spatial)。它具有4个节点的空间扩展和分区功能。每个节点都配备了8核、16 GB内存、1T硬盘存储空间的机架式服务器。实验以1 GB的互连网络用于节点间通信。
3.2 实验数据集
本文数据从OpenStreetMap(OSM)中下载,包含了大量的地理信息数据,如湖泊、森林、建筑物和道路等。图片数据使用的是开封市城区png格式的切片数据。以此为基本的实验数据,格式化数据后,以文件的形式将图片存储到空间数据库中,以文件名为检索条件检索图片数据。
3.3 Hadoop Spatial的性能测试
通过系统搭建,在两个系统参数设定大致一样的情况下,对Hadoop Spatial与并行空间数据库在查询方面的性能以及Hadoop Spatial的扩展性进行实验,并对实验结果进行分析。
3.3.1 Hadoop Spatial与并行空间数据库的比较
空间数据库的操作对数据的编辑要求并不高,要求高的约半数集中在查询方面。因此,更快、更好查询才是高性能空间数据库的标准。由于许多复杂的查询都可以被分解成空间连接查询、包含查询和聚集查询这3种典型的查询,因此本文以这3种典型查询为基准进行了性能实验(见图4)。
对于连接查询来说,两个系统都具有良好的可扩展性。但是,Hadoop Spatial总体上与已经得到调整的SDBMS相比有更好的性能;在相同的CPU核数下,Hadoop Spatial的查询速度比SDBMS快,如图4(a)所示。分析可知,SDBMS可以智能存储数据,并且可以使用索引记录读取来减少I/O开销,因此对I/O繁重的任务会表现出更好的性能。然而,空间连接涉及繁杂的几何计算,并且由数据库管理系统生成的查询计划任务对SDBMS是不理想的。尽管SDBMS内置的分区功能可平衡数据分发,但其处理计算偏移的能力有限。Hadoop具有按需任务调度机制,可以解决这种计算倾斜问题。
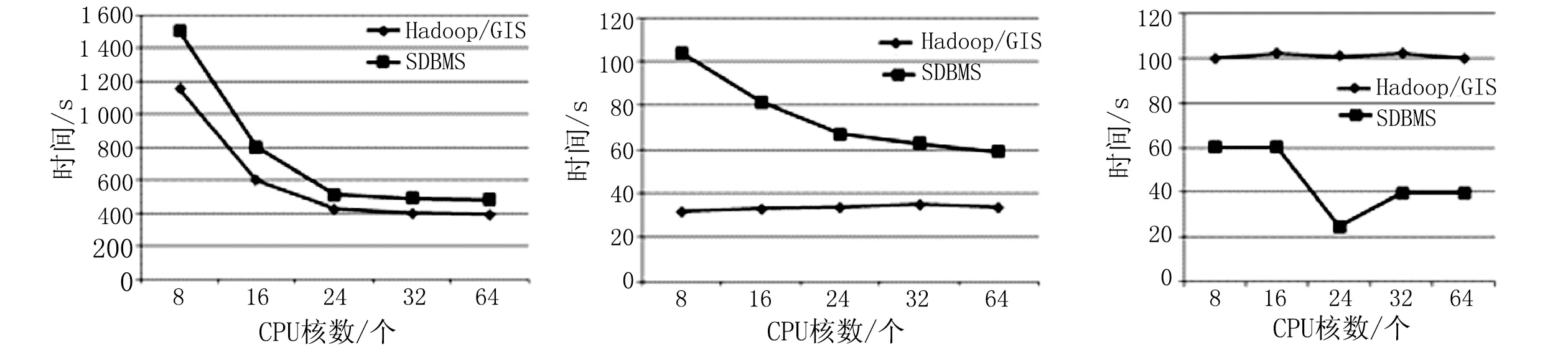
(a)连接查询 (b)包含查询 (c)聚集查询
对于包含查询来说,Hadoop Spatial优于规模较小的SDBMS,在具有不同数量CPU的基础上性能表现平稳,如图4(b)所示。然而,SDBMS具有更好的可扩展性,特别是扩展数量较大时。Hadoop Spatial的包含查询被实现为只有MapReduce作业,并且查询本身与连接查询相比具有较小的计算量。因此,时间实际上是被用在了读出文件分割、解析对象以及查询该对象是否被包含在查询区域内。SDBMS可以发挥空间索引的优势,迅速过滤掉不相关的记录。因此,SDBMS的包含查询性能稍好。
在聚集查询中,SDBMS的性能比Hadoop Spatial稍好,如图4(c)所示。这主要是由于Hadoop Spatial具有记录解析的。这两种系统都具有类似的查询计划,都是对一个全表进行扫描后进行空间列的聚集操作,且有类似的I/O开销聚合操作。然而,Hadoop Spatial中的记录需要实时进行解析,而SDBMS的记录只是预解析和存储的二进制格式。因此,SDBMS在聚集查询方面有更好的查询性能。
3.3.2 Hadoop Spatial的扩展性
Hadoop Spatial系统的可扩展性能如图5所示。
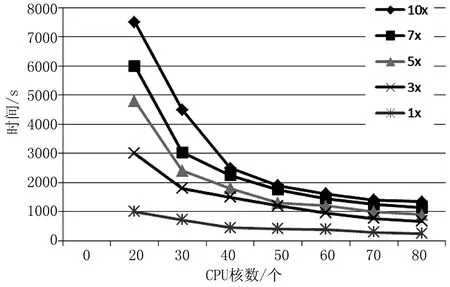
图5 扩展性能测试性能图
图5显示出了Hadoop Spatial系统具有良好的可扩展性能。实验采用的数据包括1×、3×、5×、10×的数据集以及不同的CPU核数。当reducer的数量增加时,查询时间连续下降,几乎实现了线性加速。例如,当reducer的数量从20增加到40时,查询时间对应减少了50%,1×数据集与10×数据集的平均查询时间均有很大幅度的提高。这说明该系统具有良好的向上扩展性能。
4 结 语
通过对分布式空间数据库的框架结构和技术方案的研究, 提出和设计了基于Hadoop技术建立分布式空间数据库的总体方案和技术路线。通过构建空间数据库引擎(Hadoop Spatial Engine),将空间数据和属性数据以统一的数据模型存储在空间数据库管理系统(Hadoop Spatial)中,对数据统一管理,可以直接利用DBMS的管理功能,充分利用关系数据库查询优化的许多方法,提高数据的访问速度。同时,Hadoop能有效地进行分布式处理,为基于C/S体系结构空间数据库的数据互操作和信息共享提供技术支持。
本文只是简单构建空间数据库,在实际应用过程中还有许多需要优化之处,比如数据的安全性、数据的完整性、监控数据库的使用和运行、数据安全策略和用户安全策略、用户的可操作性等还需要进一步的实践验证。下一步要进行探索的是分布式空间数据的索引研究与空间数据的时态研究。
参考文献:
[1] The Apache Software Foundation.Hadoop [EB/OL].[2014-04-20].http://hadoop.apache.org.
[2] Konstantin S,Hairong K,Sanjay R.The Hadoop Distributed File System[C]//第26届IEEE研讨会海量存储系统与技术(MSST'10)论文集.美国内华达州:IEEE,2010:1-10.
[3] 章建涛.并行数据仓库环境下基于B_树的分布式索引研究[D].秦皇岛:燕山大学,2010.
[4] 肖明.基于Geodatabase的空间数据库系统设计与实现[D].武汉:武汉大学,2005.
[5] 蔡斌,陈湘平.Hadoop技术内幕:深入解析Hadoop Common和HDFS架构设计与实现原理[M].北京:机械工业出版社, 2013:236-362.
[6] Dean J, Ghemawat S.MapReduce: a flexible data processing tool[J].Communications of the ACM, 2010, 53(1): 72-77.
[7] Ashish T, Joydeep S, Narnit J, et al.Hive——A Warehousing Solution Over a MapReduce Framework[J].VLDB,2009(2):1626-1629.
[8] 吴信才.空间数据库[M].北京:科学出版社, 2009:159-190.
[9] Ravi K, Albert G, Euro B.Oracle Spatial空间信息管理——Oracle Database 11g[M].管会生译.北京:清华大学出版社,2009:257-320.
[10] 董西成.Hadoop技术内幕:深入解析MapReduce架构设计与实现原理[M].北京:科学出版社,2013:107-120.
