基于熵信息处理和PCA的肿瘤基因表达谱分类识别
2014-03-26汪沁紫鲍文霞
汪沁紫, 王 年, 宋 豪, 鲍文霞
(安徽大学 计算智能与信号处理教育部重点实验室, 合肥 230039)
肿瘤类型的识别一直是生物医学研究的重点和难点。近年来随着DNA微阵列技术[1]的发展,利用肿瘤基因表达谱进行深入地研究可以了解肿瘤的发生发展机制,有助于人们发现新的疾病亚型,进而提高治疗效果。但是由于基因表达谱数据的分析难度远远超出传统分析方法所能处理的范畴,因此采用快速有效的方法分类处理肿瘤基因对推进肿瘤医学的发展有至关重要的作用。
自从Golub等人[2]在1999年首次提出一种以“信噪比”为指标成功地对白血病的两个亚型样本进行分类研究以后,面对基因表达谱数据样本少、维数高和冗余基因多等难题,诸多研究提供了新的思路。如2000年,Alizadeh等人[3]通过聚类分析的方法发现了两种淋巴瘤的亚型;除此之外还出现了人工神经网络法[4]、贝叶斯法[5]和支持向量机法[6]。随着解决方案的不断更新完善,能够分析处理的能力也在不断增强。2002年,Singh等人[7]利用“信噪比”为指标,结合K近邻算法实现了对前列腺癌样本进行了分类研究;孔薇等人[8]利用改进稀疏非负矩阵分解技术对乳腺癌基因表达谱数据进行双向聚类从而挖掘与乳腺癌发病密切相关的基因及其生物过程;阮晓钢等人[9]提出一种CLUSTER_S2N的方法对急性白血病的基因表达谱进行分类预测实验。与此同时,近年来多种理论的融合方法也得到快速发展:像使用熵信息处理与支持向量机结合[10]的方法对前列腺癌基因表达数据进行了有效处理;结合了主成分与独立成分分析方法被用于识别胃癌相关差异表达基因以提高结果的准确度和可信度[11];以及邻接矩阵分解结合主成分分析的方法寻找结肠癌信息基因等[12]。这些方法通常相对于单一理论,其效果具有一定的优势。
通过分析已有的肿瘤分类方法及考虑到基因表达谱研究的广泛应用前景和价值,本文提出一种基于熵信息处理和PCA理论对肿瘤基因进行分类处理的方法。首先对基因表达数据进行筛选并计算各个基因的熵,然后提取出熵最大的若干基因作为特征基因,为了进一步减少冗余,最后本文采用PCA方法进行降维处理从而得到样本的主成分量。经真实数据实验及其他方法的对比,本文方法的有效性得到了验证。
1 熵信息
熵信息[13]描述的是信源的不确定性,是信源中所有目标的平均信息量。这种信息度量的方法是由香农( C E Shannon)提出的,一个消息出现的概率越小, 它所带来的信息量就越大, 反之, 它所带来的信息量就越小。近年来,熵信息的应用[14-16]十分地广泛。下面是熵信息的具体描述:熵信息在信息论中是作为度量信息量的一种尺度,变量的不确定性越大,熵就越大,则包含的信息量也就越大。现假设基因变量X的概率分布为:
(1)
则X的熵信息定义如下形式:
(2)
对每个基因,计算相应的H,依据H的大小对基因进行筛选, 挑选熵值大的基因作为特征基因。在本文实验中,假设所有基因符合均值为μi,方差为0.5的正态分布,以此初步去除不相关基因从而达到数据规模的降低。
2 PCA
PCA,即主成分分析[17],作为一种有效地线性数据压缩和降维的工具,其应用越来越广泛[18-20]。其实质是确定原变量xj(j=1,2,…,p)在诸主成分zi(i=1,2,…,m)上的荷载lij,把原来多个变量划分为少数几个综合指标的一种统计分析方法。现就PCA给出如下简要描述:假定有n个样本,每个样本有p个变量,构成一个n×p阶的数据矩阵X如下:
设xi,x2,…,xp为原变量指标,z1,z2,…,zm(m≤p)为新变量指标,满足式(6)
(6)
其中系数lij的确定原则为:1)zi与zj(i≠j;i,j=1,2,…,m)相互无关;2)z1是x1,x2,…xp的一切线性组合中方差最大者;z2是与z1不相关的x1,x2,…,xp的所有线性组合中方差最大者;…;zm是与z1,z2,…,zm-1都不相关的x1,x2,…,xp的所有线性组合中方差最大者。则lij的计算为:
(7)
新变量指标z1,z2,…,zm分别称为原变量指标x1,x2,…,xp的第1,第2,…,第m主成分。 一般取累计贡献率达80%以上的特征值为λ1,λ2,…,λm所对应的第1、第2、…、第m(m≤p)个主成分。
3 实验
3.1 实验步骤
本文以急性白血病基因表达谱数据以及前列腺癌基因表达谱数据为例。白血病基因表达谱数据中含有52个样本,其中24个为急性淋巴性白血病(AML),28个为急性粒性白血病(ALL),每个样本中含有12564个基因;前列腺癌基因表达数据共有102个样本,其中正常样本50个,癌症样本52个,每个样本包含12600条基因(数据来自于http://www.broad.mit.edu/cgi-bin/cancer/datasets.cgi)。
分类算法具体步骤如下:
1)运用熵信息对超高维基因表达谱数据进行初选取,对所有基因进行重要性记分并按降序排列;得到特征基因子集;
2)由于特征基因子集间仍存在相关性,进而利用PCA对子集进行进一步冗余剔除;
3)利用SVM分类器对得到的无冗余且具有正交性信息的基因特征进行真实实验验证在各类中客观地、真实地表达值,消去各种外界因素导致的出格点,即突变值;
4)对二组公开的基因表达谱数据集进行分类验证并给出分析。
3.2 实验结果与分析
本文首先利用熵信息处理对白血病数据集进行了实验,保留了ALL类和AML类中客观地基因表达值,同时剔除了一些异常值(即出格点),再获取基因特征子集,通过PCA方法的变换,将白血病样本映射到一个低维特征空间,其实验结果如图1和图2所示。

图1 熵信息处理选取白血病数据80个基因的表达谱
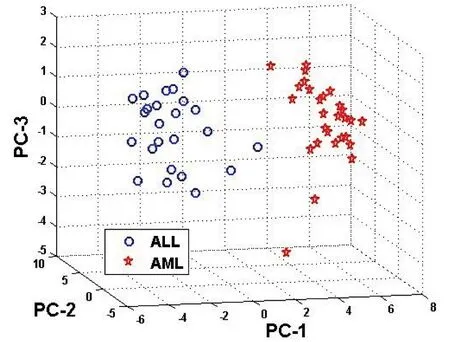
图2 3维空间下白血病样本分布
利用熵信息方法对白血病样本的每个基因进行重要性记分,降序排列后选取记分高的80个基因,通过颜色等级划分并归一化后显示于图1,由蓝色趋红表明基因表达值越来越大,同时可以发现有一定的颜色分块现象,说明选取的基因具有较好的分类信息。但是选取的基因间仍然存在着信息冗余,导致颜色分块现象还不够显著,因此通过主成分分析进行主要分类信息提取与冗余信息压缩,在提取基因子集信息的主成分为3时,图2给出了白血病样本的空间位置分布,其中尤其是在第一主成分坐标轴上,所有ALL类样本的PC-1<2,而所有AML 类样本的PC-1>2,从而实现了一个很好的区分与识别。
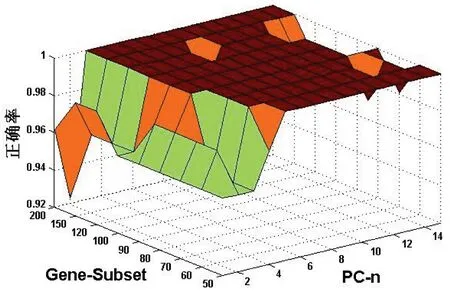
图3不同基因子集与不同主成分组合下的分类识别率
图3给出了由不同规模基因子集与不同主成分组合下的白血病数据分类效果,主成分个数PC-n小于6时,其识别率波动较大,但都呈现增长趋势,随着PC-n的增加,即使基因子集规模Gene-Subset不断变化,其识别率都能稳定在近乎100%,说明本方法识别白血病数据是有效的,可行的。
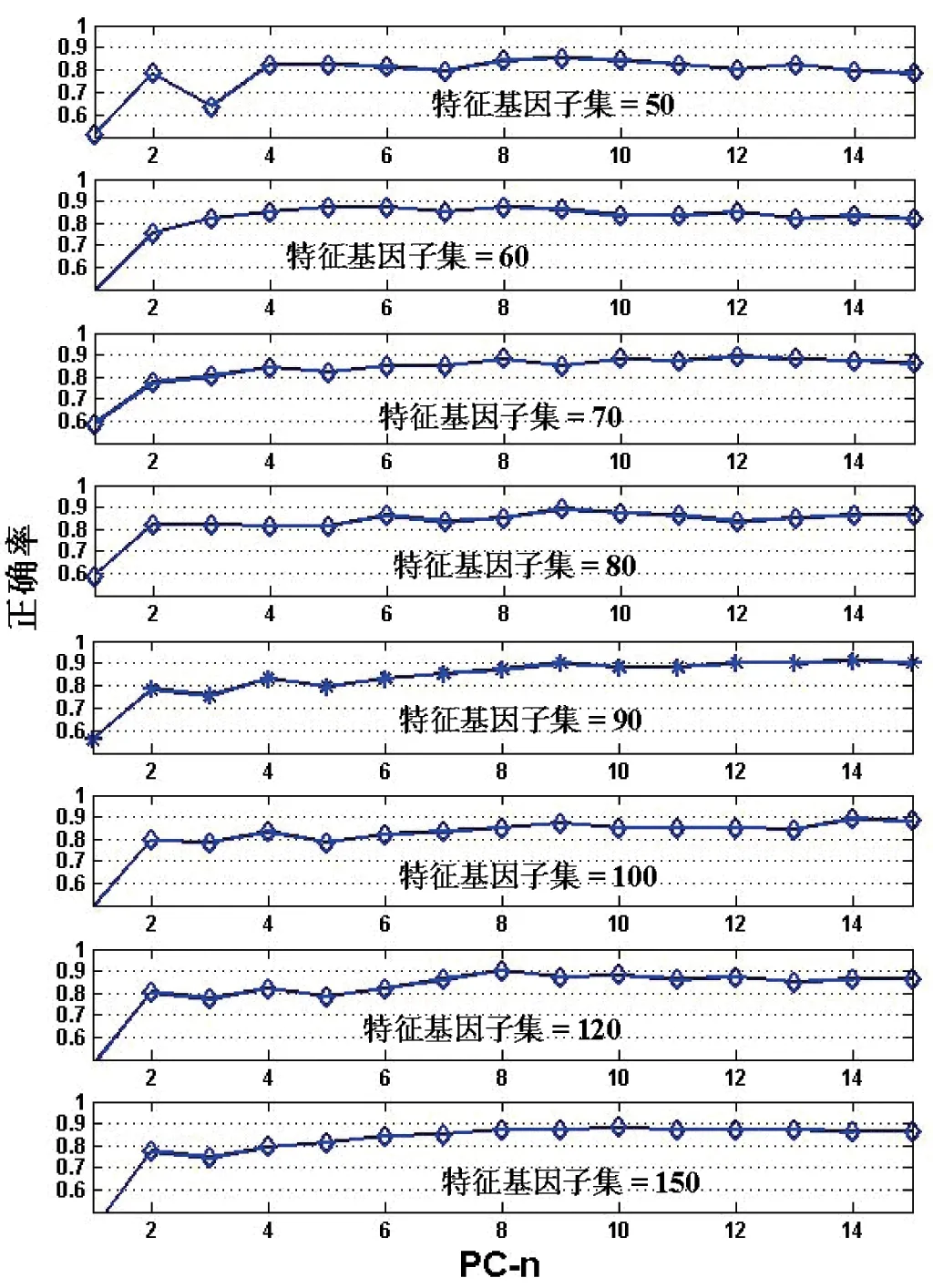
图4 前列腺癌数据在不同特征基因子集下的分类结果
按同样思路给出结肠癌数据的实验结果,以实现正常样本与癌症样本的正确识别。
在图4的8个子图中,前列腺癌数据分类识别率随着PC-n的增加呈上升趋势并趋于稳定,当PC-n>8时,识别率均在90%左右,发现利用PCA选取有限个主分量就能较好地表达样本特征,以及实现对数据中冗余信息的压缩,最终得到较高地识别效果。
本文将Sigh等人[7]以“信噪比”作提取特征基因指标以及阮晓刚等人[9]提出了CLUSTER_S2N方法提取特征基因等方法与本文方法进行比较,结果如表1所示。

表1 实验结果比较
近来,SVM作为一种流行的、有效的分类方法,得到了广泛关注。同时SVM对高维小样本的处理能力具有独特的优势。因此,本文选用SVM方法来实现肿瘤的识别。经过多次实验, SVM在选则高斯核函数(σ=3)、C=200的参数设置下,上述3种方法都能等到较高且稳定的识别率,由于本文主要是对比3种方法选取基因特征的有效性,所以对SVM不再过多阐述。本文方法与其他方法的对比结果如表1所示,可以发现本文的方法在识别精度上具有一定优势。在处理白血病数据时,由于本文方法很好地将熵信息处理和PCA方法的优势相结合,信息熵的算法在筛选基因时可以最大程度不损坏基因的总信息量,PCA算法则可以对筛选后的基因特征子集进行冗余信息的有效消除,其实验结果可以达到100%。而对于样本数较多的前列腺癌数据,其实验结果中的正确率相比其他方法而言也是非常可观的。
4 结论
利用DNA微阵列,本文提出了一种结合熵信息处理和PCA技术的肿瘤分类方法,经过实验验证了该方法对肿瘤类型识别的可行性与有效性。由于本方法利用了PCA除冗余,在处理信息量大的基因特征子集时会降低正确率,因此在第一步粗选取时特征基因子集的保留方法有待改善。
通过实验证明了本方法对肿瘤类型识别的可行性与有效性,与其他方法相比具有一定的普适性。
参考文献:
[1]杨春梅, 万柏坤, 梁慧嫒,等. DNA微阵列技术及其在生物医学中的应用[J]. 国外医学.生物医学工程分册, 2002, 25(5): 203-206.
[2]Golub T R, Slonim D K, Tamayo P, et al. Molecular classification of cancer: class discovery and class prediction by gene expression monitoring [J]. Science, 1999, 286(5439): 531-537.
[3]Alizadeh A A, Elsen M B, Davis R E, et al. Distinct types of diffuse large B-cell lymphoma identified by gene expression profiling[J]. Nature, 2000, 403(12): 503-511.
[4]Khan J, Wei J S, Ringner M, et al. Classification and diagnostic prediction of cancers using gene expression profiling and artificial neural networks[J]. Nature Medicine, 2001,7( 6): 673-679.
[5]Haferlach T, Kohlmann A, Wieczorek L, et al. Clinical utility of microarray-based gene expression profiling in the diagnosis and sub classification of leukemia: report from the international microarray innovations in Leukemia study group [J]. Journal of Clinical Oncology, 2010, 28 (15): 2529-2537.
[6]王 晶, 周 旷. 基于支持向量机的肿瘤基因识别[J]. 计算机与数字工程, 2011, 39(9): 3-6.
[7]Singh D, Febbo P G, Ross K, et al. Gene expression correlates of clinical prostate cancer behavior [J]. Cancer Cell, 2002, 1(2): 203-209.
[8]孔 薇, 王 娟, 牟晓阳. 基于改进稀疏非负矩阵分解方法的乳腺癌微阵列表达数据分析[J]. 安徽医科大学学报, 2013, 48(7): 725-729.
[9]阮晓钢, 晁 浩. 肿瘤识别过程中特征基因的选取[J].控制工程,2007,14(4):373-380.
[10]庄振华, 王 年, 李学俊, 等. 癌症基因表达数据的熵度量分类方法[J]. 安徽大学学报, 2010, 34(2): 73-76.
[11]陈战雷, 李博宇, 李 益, 等. 结合主成分与独立成分分析识别胃癌相关差异表达基因的方法研究[J]. 生物医学工程学杂志, 2013, 30(5): 915-918.
[12]陈 乐, 王 年, 苏亮亮, 等. 基于邻接谱主分量分析的肿瘤分类方法[J]. 安徽大学学报:自然科学版, 2011, 35(4): 86-91.
[13]Shannon C E. A mathematical theory of communication[J]. Bell System Technical Journal, 1948, 27: 379-423, 623-656.
[14]Wu Y, Zhou Y, Saveriades G, et al. Local Shannon entropy measure with statistical tests for image randomness [J]. Information Sciences, 2013, 222(10): 323-342.
[15]Liu C, Li K, Zhao L, et al. Analysis of heart rate variability using fuzzy measure entropy [J]. Computers of Biology and Medicine, 2013, 43(2): 100-108.
[16]Chou Y C, Yen H Y, Sun C C, et al. An integrate method for performance of women in science and technology based on entropy measure for objective weighting [J]. Quality & Quality , 2014, 48(1): 157-172.
[17]Abdi H, Williams L J. Principal component analysis [J]. Wiley Interdisciplinary Reviews: Computational Statistics, 2010, 2(4): 433-459.
[18]Ding S, Zhang P, Ding E, et al. On the application of PCA technique to fault diagnosis[J]. Tsinghua Science & Technology, 2010, 15(2): 138-144.
[19]Kremic E, Subasi A, Hajdarevic K, et al. Face recognition implementation for client server mobile application using PCA[J]. Information Technology Interfaces, 2012, 25(28): 435-440.
[20]Molenaar P, Wang Z, Newell K M. Compressing movement information via principal components analysis (PCA): contrasting outcomes from the time and frequency domains[J]. Human Movement Science, 2013, 32(6): 1495-1511.
